대규모 언어 모델의 생물학 (On the Biology of a Large Language Model)
- 본 강의는 Anthropic의 기계론적 해석 가능성(mechanistic interpretability) 팀에서 회로(circuits) 연구를 이끌고 있는 Joshua Batson의 발표 내용이다.
- Josh Batson은 Anthropic 이전에 Chan Zuckerberg Biohub에서 바이오게노믹스 및 전산 현미경 분야에서 근무했으며, 학문적 배경은 순수 수학이다.
- 강의의 제목은 "대규모 언어 모델의 생물학에 대하여 (On the biology of a large language model)"이며, 이는 Anthropic이 몇 주 전에 발표한 100페이지 분량의 상호작용적 블로그 게시물의 제목과도 같다.
1. LLM 해석 가능성 연구의 동기: '생물학'적 접근
- 해석 가능성(interpretability)에 대한 접근 방식을 이해하기 위해, LLM을 훈련 과정 동안의 동적 시스템으로 보는 "대규모 언어 모델의 물리학(on the physics of large language models)"이라는 일련의 연구들과 대비하여 생각할 수 있다.
- Anthropic 팀은 해석 가능성을 경사 하강법(gradient descent)으로 훈련된 신경망을 연구하는 행위로, 마치 진화를 통해 발전된 생명체 시스템을 연구하는 생물학과 같은 관계로 본다.
- 즉, 복잡성을 야기하는 과정(훈련/진화)이 있으며, 그 결과로 생성된 객체(모델/생명체)가 어떻게 기적적인 일을 수행하는지 연구하는 것이다.
1-1. LLM의 놀라운 능력과 기묘한 행동
- LLM은 매우 낮은 자원 언어(low-resource language)인 사르카시아어(Sarcasian) 번역에서도 뛰어난 성능을 보여주었다.
- 한 연구자가 수년간 수집한 러시아어-사르카시아어 번역 마스터 리스트를 Claude의 컨텍스트 윈도우에 넣고(In-Context Learning), 번역을 요청한 결과, 모델은 성공적으로 번역했을 뿐만 아니라 문법까지 분석했다.
- 이러한 인컨텍스트 학습(In-Context Learning) 능력은 NLP 특정 모델의 최첨단 성능을 능가했다.
- 하지만 모델은 동시에 이상한 행동(weirdness)도 보인다.
- 예를 들어, 윤년(leap day)에 "내일은 무슨 요일인가?"라는 질문에 모델은 윤년이 아니라는 잘못된 사실을 기반으로 추론하며 혼란에 빠졌다.
- 모델은 사실에 대한 정확한 기억, 사실을 기반으로 한 정확한 추론을 혼합하지만, 초기 오류와의 일관성을 유지하기 위해 이를 무시하는 모습을 보이는데, 이는 매우 이상한 현상이다.
- AI 아트의 오류 예시: 초기 AI 생성 이미지는 손가락이 너무 많은 문제(seven fingers)를 흔히 발생시켰는데, 이는 단순히 문제를 해결하여 없앤 것이 아니라, 모델이 발전함에 따라 그 기묘함이 더 정교해졌을 뿐이다.
- 해석 가능성의 중요성: 단순한 상호작용은 잘 작동하더라도, 모델이 근본적으로 깊고 진실된 것을 학습했는지, 아니면 (손가락 문제처럼) 표면적인 오류만 해결된 것인지는 알 수 없다. 모델의 능력 한계(edge of the model's capabilities)에 다다르면 검증할 수 없는 기묘한 현상이 발생할 수 있으며, 신뢰하는 모델에 의사 결정을 위임하기 전에 그 작동 방식을 이해해야 한다.
2. LLM에 대한 세 가지 통념 (Myths)
- 모델의 작동 방식에 대한 세 가지 통념 또는 오해를 살펴보고, 실제 연구 결과를 통해 반박한다.
| 통념 (Myths) | 실제 연구 결과 (Findings) |
|---|---|
| 모델은 훈련 데이터의 비슷한 예시에 단순히 패턴 매칭한다. | 모델은 내부적으로 꽤 추상적인 표현을 학습하고 구성할 수 있다. |
| 모델은 얕고 단순한 휴리스틱과 추론만을 사용한다. | 모델은 오히려 복잡하고 종종 고도로 병렬적인 계산을 수행한다. (직렬적이지 않음) |
| 모델은 한 번에 한 단어씩 즉흥적으로 생성한다. | 모델은 종종 여러 토큰을 미리 계획하여 일관성 있는 내용을 만든다. |
3. LLM의 작동 원리 (기본 개요)
- 다음 단어 예측: LLM은 본질적으로 한 번에 한 단어씩 다음 단어를 예측함으로써 작동한다. (예: "Hello" 다음 "can", "Hello can" 다음 "I"를 예측).
- 신경망 및 임베딩: 이 예측 과정은 신경망(neural network)을 통해 이루어진다.
- 언어를 언어로 변환하기 위해 먼저 언어를 숫자로 변환해야 한다.
- 임베딩(embedding): 어휘(vocabulary)에 있는 모든 단어나 토큰은 숫자의 목록, 즉 벡터(vector)를 가진다.
- 이 벡터들을 연결하여 대규모 신경망(가중치(weights)가 많은)에 통과시키면, 어휘의 모든 단어에 대한 점수(score)가 출력된다.
- 모델은 가장 높은 점수를 받은 단어를 출력하며, 무작위성(randomness)을 위해 약간의 온도(temperature)를 적용한다.
- 트랜스포머 아키텍처: 트랜스포머(Transformer) 아키텍처는 잔차 연결(residual connections)과 교대하는 어텐션(attention) 및 MLP 블록을 포함하며, 이는 대규모 MLP에 강력한 사전 지식(prior)을 내재화한 것으로 볼 수 있다.
- 성장론(Grown not Built): 언어 모델은 건축되는 것이 아니라 성장하는 것으로 생각해야 한다. 무작위로 초기화된 아키텍처(발판)에 데이터(영양분)를 제공하고, 손실 함수(Loss)를 태양처럼 삼아 그 방향으로 성장한다. 그 결과 유기적인 것이 만들어지지만, 어떻게 성장했는지에 대한 접근은 제한적이다.
모델의 내부 구조 해부: 해석 가능한 특징 찾기
4. 뉴런 해석 가능성의 한계
- 모델이 무엇을 하는지에 대한 자명한 대답은 "단어를 숫자로 바꾸고, 수많은 행렬 곱셈(mat muls)을 수행한 다음, 단순 함수를 적용하는 것"이지만, 이는 행동을 추론할 수 없기에 불만족스러운 답이다.
- 초기 연구에서는 신경망 내부의 뉴런(neurons)이 해석 가능한 역할을 하기를 희망했다 (예: 자동차 감지 뉴런, 도널드 트럼프 뉴런).
- 하지만 언어 모델에서 특정 뉴런이 활성화되는 문장들을 찾아보면, 코드, 중국어, 수학, 문학 등 일관성 없는 다양한 내용이 섞여 있어 해석 가능성이 매우 낮다. 뉴런이 해석 가능하기를 바라는 것은 너무 많은 것을 바라는 것일 수 있다.
5. 희소성 사전 학습 (Sparsity Dictionary Learning)
5-1. 배경 및 목표
- 신경과학적 사전 지식 (Prior from neuroscience): 모델이 어떤 순간에 많은 것을 동시에 생각하지 않을 수도 있다는 가설, 즉 희소성(sparsity)이 있을 수 있다는 가설을 기반으로 한다. 모델이 사용하는 개념이나 서브 루틴을 지도화했을 때, 특정 토큰에서는 일부만 사용될 것이라는 추측이다.
- 수학적 접근: Dictionary Learning: 활성화 벡터(activation vector)가 사전 요소(dictionary elements)의 희소한 조합(sparse combination)의 합이 되도록 뉴런들의 선형 조합(linear combinations)을 맞추는 고전적인 ML 기법을 적용한다.
- 수집된 활성화 벡터를 기반으로 사전을 찾고, 이 사전 구성 요소들이 언제 활성화되는지 확인한다.
5-2. Sparse Autoencoder를 이용한 특징 추출
- Anthropic 팀은 Claude 3 Sonnet의 중간 레이어에서 약 3천만 개의 특징(features)을 추출했으며, 이는 계산이나 표현의 '원자(atoms)'로 간주된다.
- Sparse Autoencoder (희소 오토인코더):
- 처음에는 사전 학습 문헌에 따라 복잡하게 접근하려 했으나, 결국 비터 레슨(bitter lesson)을 깨닫고, 단순하게 1계층 희소 오토인코더(one layer sparse autoencoder)를 사용하여 GPU로 훈련했다.
- 이는 확장성(scaling)이 복잡한 기법보다 더 중요하다는 것을 보여준다.
- 수학적 개념: 활성화 벡터 은 고정된 원자 사전(dictionary of atoms) 와 희소 행렬(sparse matrix) 의 곱으로 인수분해된다.
- 목표 함수: 데이터를 재구성해야 하며, L1 페널티를 통해 희소성을 장려한다. 이는 각 활성화 벡터를 표현하는 데 필요한 원자의 수를 줄이는 역할을 한다.
5-3. 해석 가능한 특징의 예시
- 이렇게 추출된 뉴런 조합들은 놀랍게도 해석 가능성이 훨씬 높았다.
- 금문교(Golden Gate Bridge) 특징: 이 선형 조합은 입력이 금문교에 관한 것일 때 활성화된다.
- 영어로 명시적으로 언급될 때.
- 다른 언어로 번역될 때.
- 금문교 이미지일 때.
- 간접적인 언급일 때: "샌프란시스코에서 마린으로 운전하고 있었다"처럼 다리를 건너야 하는 상황에서도 활성화된다.

- 다른 특징 예시: 내적 갈등(inner conflict)의 개념, 다양한 프로그래밍 언어에서 코드 내의 버그 (0으로 나누기, 오타)를 감지하는 특징 등 추상적인 개념도 발견되었다.
- 이 버그 감지 특징을 억제하면 모델은 버그가 없는 것처럼 행동하고, 활성화하면 마치 버그가 있는 것처럼 추적 오류(trace back)를 제공했다.
6. 인과적 연결 추적 (Mechanistic Interpretability)
6-1. 지식 흐름 분석 (예시: 달라스와 오스틴)
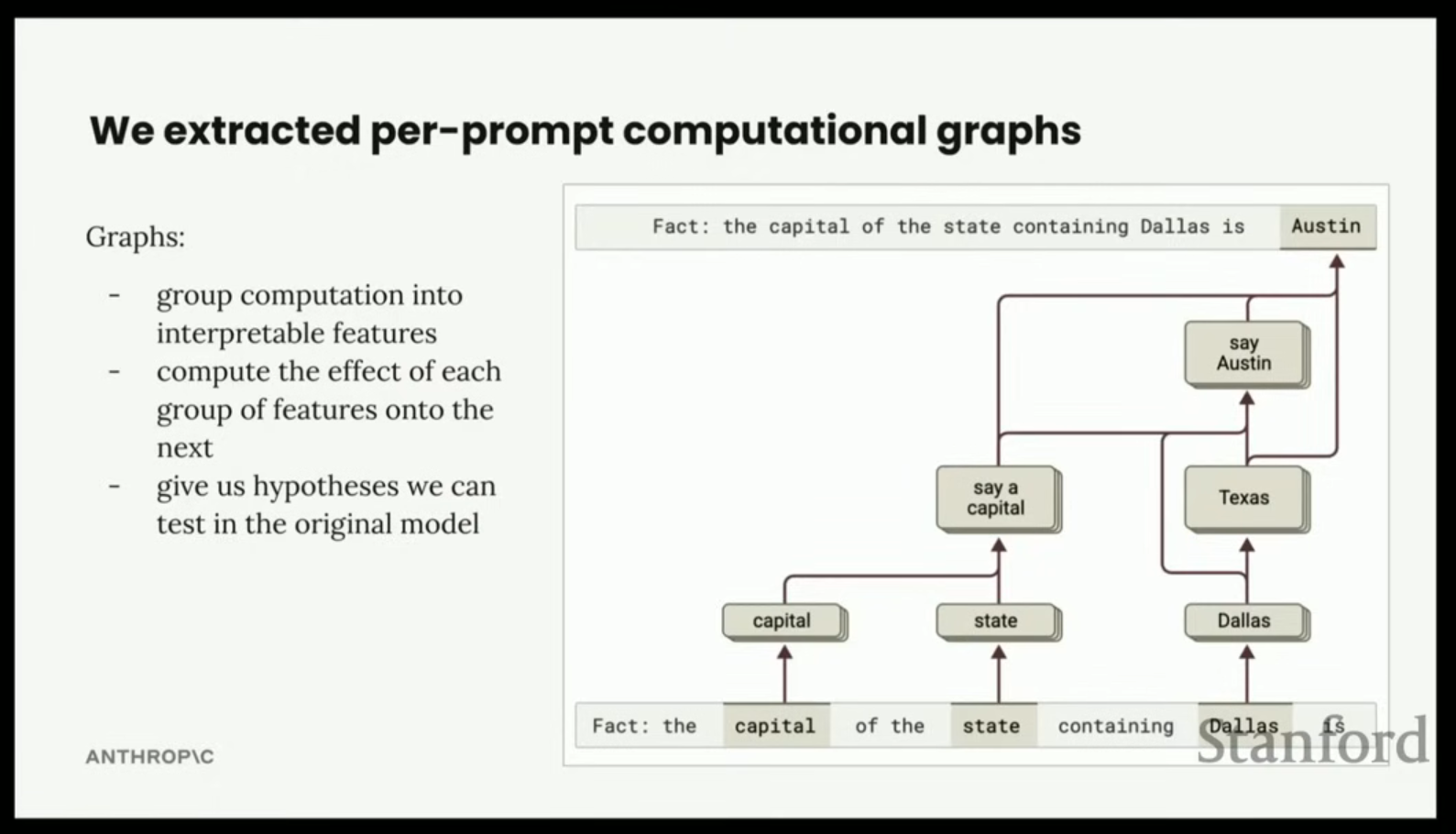
- 문제: "댈러스를 포함하는 주의 수도는 오스틴이다". 모델이 텍사스를 생각하고 오스틴을 도출했는가, 아니면 훈련 데이터에서 이 문장을 그대로 암기했는가?
- 결과: 모델은 텍사스를 생각하고 있었다.
- 원자 기반 설명: 학습된 특징 원자들을 사용하여 처리 과정을 추적한다.
- 입력: 수도(capitals) 관련 특징, 주(states) 관련 특징, 댈러스(Dallas) 관련 특징이 활성화된다.
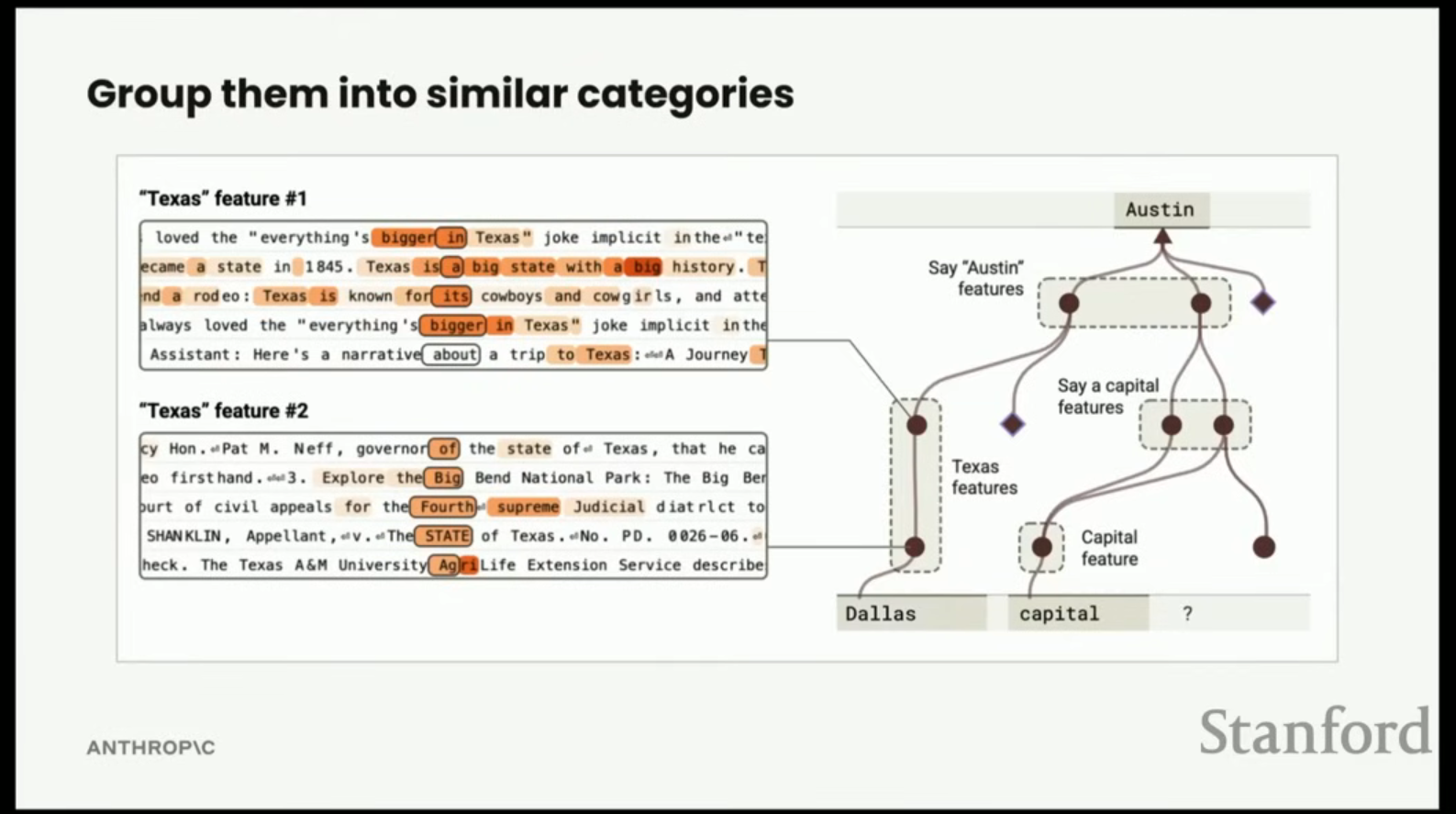
- 변환: 댈러스 특징들은 텍사스(Texas) 관련 특징들로 변환된다 (텍사스 정치, "Everything's bigger in Texas" 같은 문구).
- 출력: 텍사스 특징과 '수도를 말하게 하는' 특징(모터 뉴런)이 결합되어 최종적으로 오스틴(Austin)을 출력한다.
- 텍사스는 오스틴으로 직접 연결되기도 한다.
- 개입 (Interventions)을 통한 검증:
- 이 그래프에서 텍사스 관련 부분을 억제하고 다른 프롬프트에서 가져온 캘리포니아 특징을 주입하면, 모델은 새크라멘토(Sacramento)를 말한다.
- 조지아 특징을 주입하면 애틀랜타(Atlanta)를 말한다.
- 비잔틴 제국 특징을 주입하면 콘스탄티노플(Constantinople)을 말한다.
- 이는 연구팀이 추상적인 개념을 조작 가능한 방식으로 포착했으며, 단순히 바이그램 통계(biogram statistics)로 설명할 수 없는 분리성(separability)이 있음을 시사한다.
6-2. 기술적 상세: Sparse Replacement Model (희소 대체 모델)
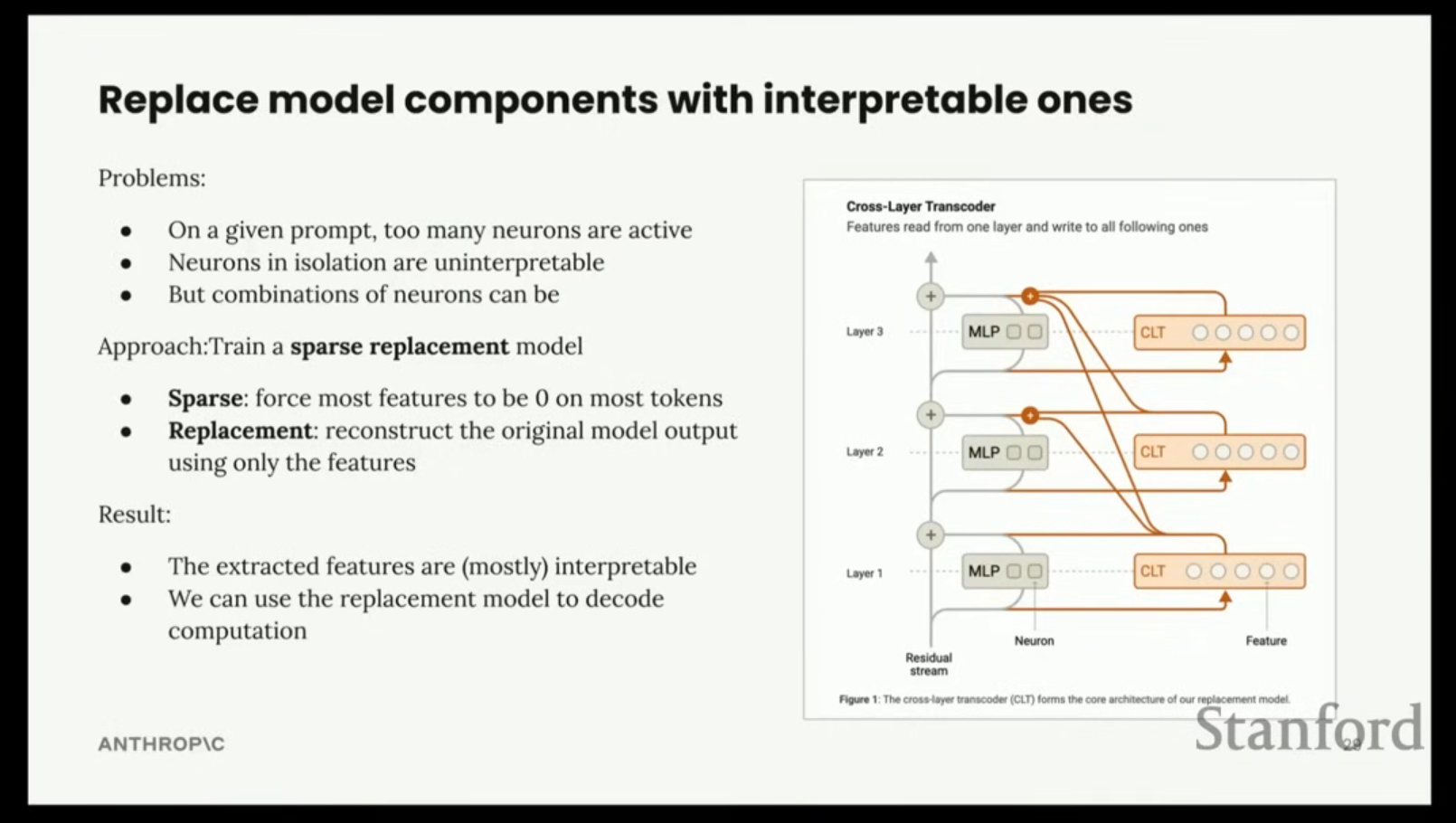

- MLP 대체: 모델의 MLP(Multi-Layer Perceptron) 블록을 교차 계층 변환기(Cross-Layer Transcoders, CLTs)로 대체하여 근사하는 것이 핵심 아이디어이다. 어텐션(attention)은 설명하려 하지 않고 기본 모델의 것을 그대로 사용한다.
- Cross-Layer Transcoders (CLTs) 설계 이유:
- 개별 MLP 계층 내에 계산의 원자 단위가 존재해야 할 특별한 이유가 없다.
- 깊은 모델에서 연속된 두 계층의 뉴런은 거의 상호 교환 가능하다는 실험 결과도 있다.
- DenseNet과 유사하게, 모든 이전 계층의 입력을 받아 모든 후속 계층의 출력을 한 번에 벡터로 생성한다.
- 이는 정보가 여러 계층을 통과하며 전파되어야 하는 단순한 바이그램 통계 같은 경우에도, 수십 개의 특징 대신 하나의 특징으로 만들 수 있게 하여 해석 가능성을 높인다.
- 훈련 및 수학: 정확도(accuracy)에 대한 손실과 희소성(sparsity)에 대한 손실을 기반으로 최적화한다.
- 인과 그래프 구성:
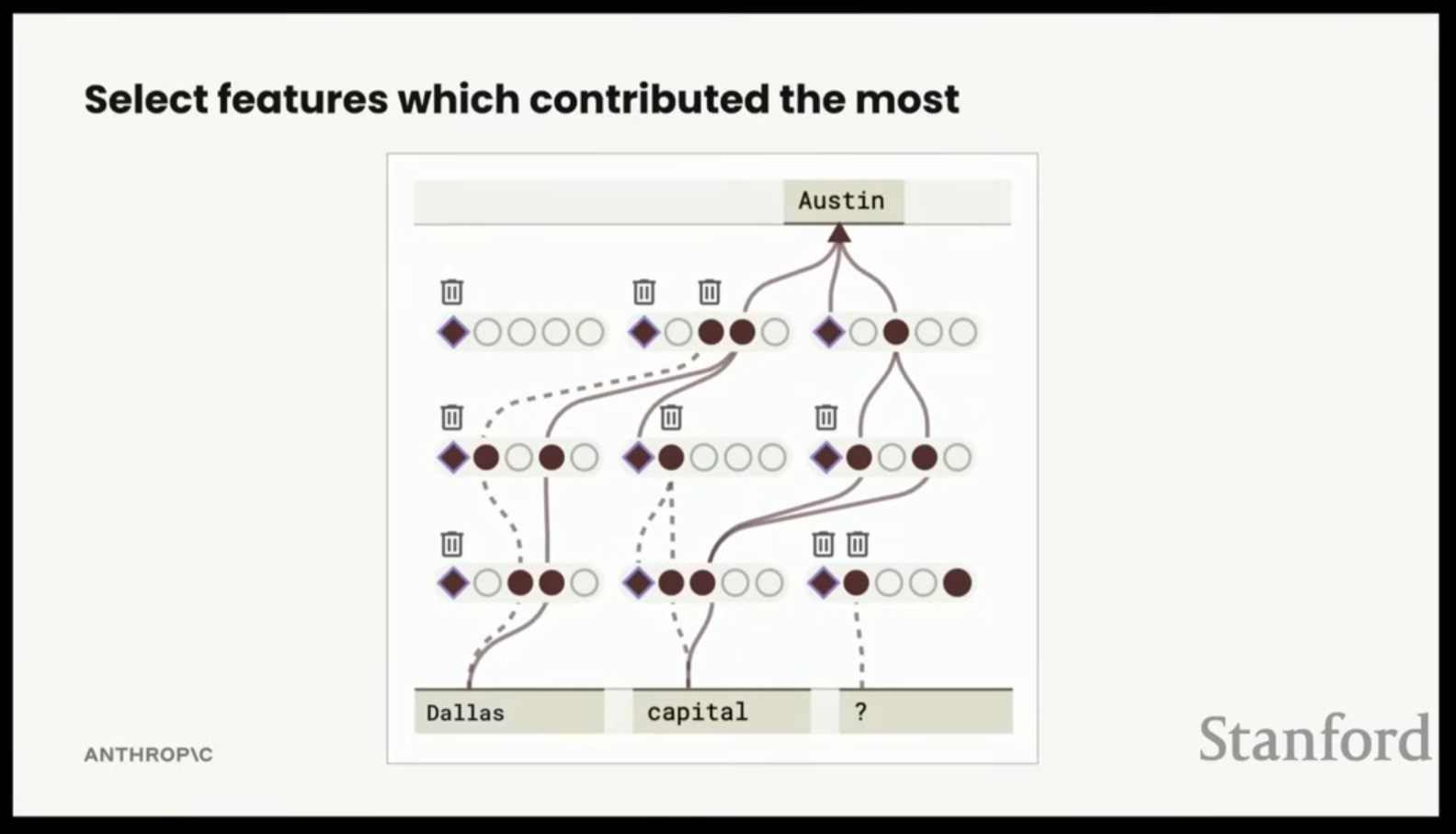
- 대체 모델은 기반 모델을 완전히 재구성하지 못하므로, 오차 항(error term) 다이아몬드(diamonds)를 포함해야 한다.
- 활성화되는 수백 개의 특징 중 모델의 출력(예: 오스틴)에 직접적으로 인과적 관련성이 있는 특징들을 역추적하여 훨씬 작은 그래프를 얻는다.
- 이 그래프의 해석은 결국 인간의 해석에 의존한다. 비슷한 속성을 가진 특징들을 수동으로 그룹화하여 (예: 텍사스 특징, 수도 특징) 최종 지도를 완성한다.
모델 내부의 세 가지 주요 모티프 (Three Main Motifs)
강의에서는 모델 내부에서 발견된 세 가지 일반적인 작동 방식 모티프를 소개한다.
7. 추상적 표현 (Abstract Representations)
7-1. 다국어 코어 (Multilingual Core)
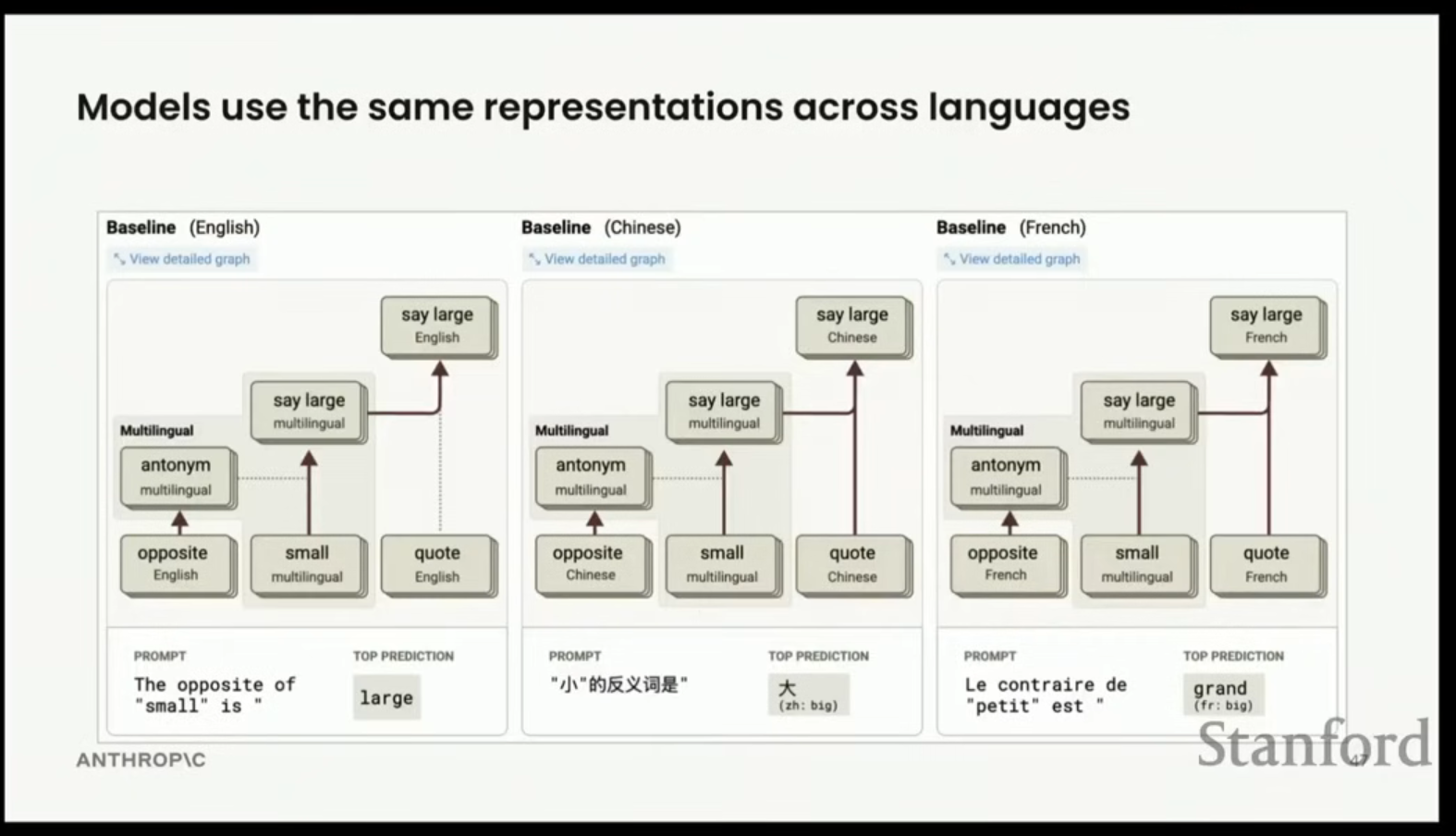
- 모델이 어떤 언어로 생각하는지를 이해하기 위해, 동일한 문장 ("The opposite of small is big.")을 영어, 프랑스어, 중국어 세 가지 언어로 비교했다.
- 흐름:
- 초기 계층: 언어 특정적인 특징(예: 프랑스어의 'contra', 영어의 'opposite')이 활성화된다.
- 중앙 계층: 여러 언어의 반의어(antonyms), 큼(largeness), 작음(smallness)에 관한 특징들이 복합적으로 활성화된다. 이 특징들은 언어에 관계없이 광범위하게 활성화되는 다국어 코어(multilingual core)이다.
- 후기 계층: 중앙에서 얻은 추상적인 개념(큼)이 다시 대상 언어의 문법 및 인용 구조와 결합되어 해당 언어의 단어(big, grand, 大)로 출력된다.
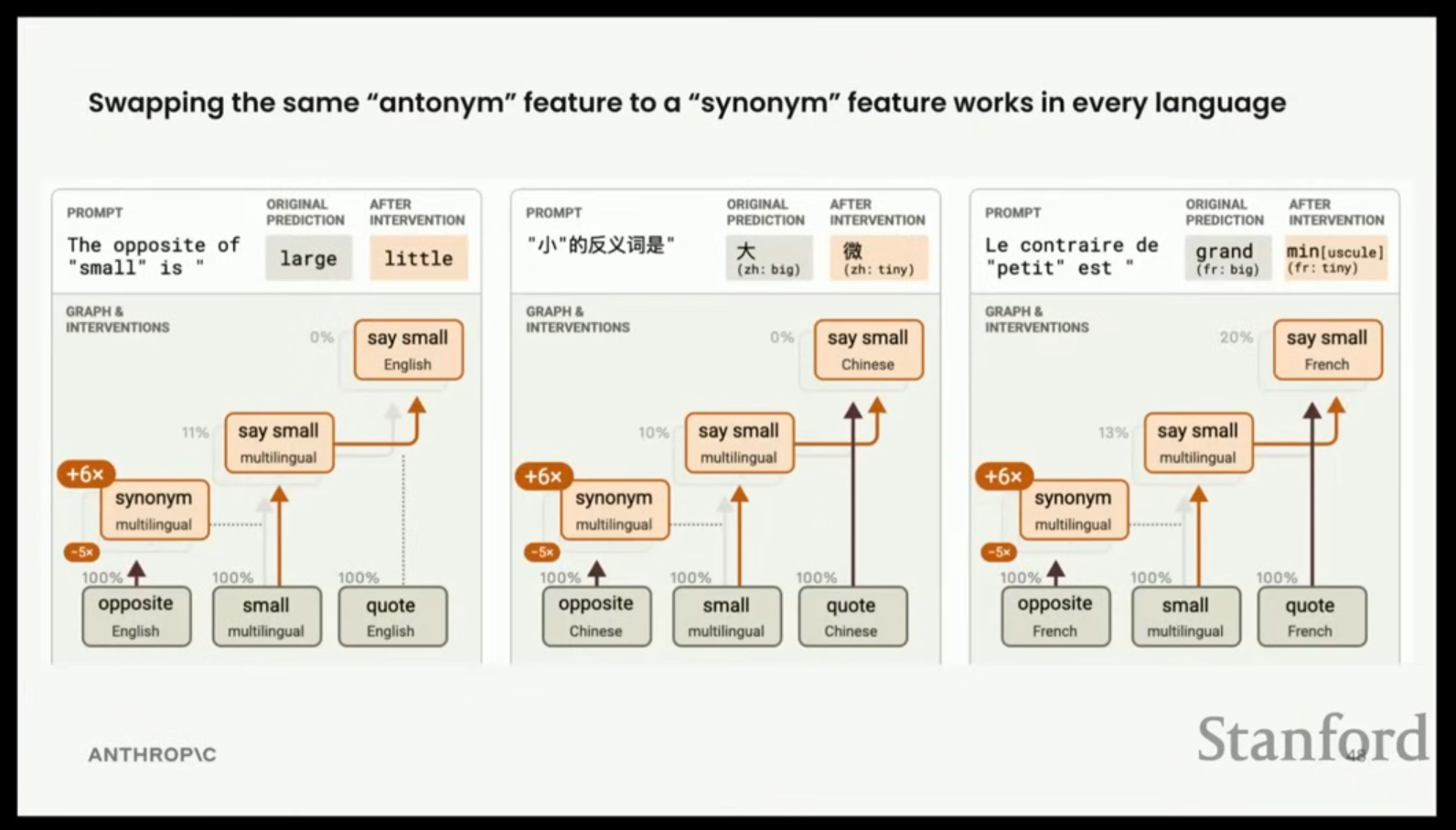
- 개입 검증: "opposite" 대신 "synonym"을 주입하면, 모델은 세 언어 모두에서 "작은(little)" 또는 "아주 작은(miniscule)"과 같은 동의어를 출력했다.
- 규모의 영향: 모델이 커질수록(18계층 모델에서 소규모 프로덕션 모델인 Hik으로 갈수록) 언어가 달라도 번역된 문장 쌍에서 활성화되는 특징의 중첩(overlap) 비율이 중앙 계층에서 크게 증가한다. 이는 모델이 개념을 추상적으로 해석하는 능력이 규모에 따라 증가함을 시사한다.
- 심화: 네트워크의 중앙, 즉 약간 오른쪽에서 가장 추상적인 표현이 나타난다. 이는 좋은 추상화가 많은 상황에 적용되어야 하므로, 모델 중앙에는 이러한 공통 추상화가 존재하며, 특정 구문이나 문법적 세부 사항을 다루는 것은 양 끝단에서 일어나는 맞춤형(bespoke) 작업이기 때문에 더 많은 특징을 필요로 한다.
7-2. 의료 진단 (Differential Diagnosis)
- 문제: 32세 임산부가 심한 통증을 호소하는 상황에서, 다른 증상 하나만 물어볼 수 있다면 무엇을 물어봐야 하는가?.
- 모델의 추론: 모델은 임신, 두통, 고혈압, 간 검사 등의 특징을 통합하여 가장 가능성이 높은 진단인 자간전증(preeclampsia)을 먼저 생각한다.
- 결과: 모델은 자간전증의 다른 증상인 시각 장애(visual disturbances)를 물어보라고 제안한다.
- 경쟁적 추론: 모델은 또한 담도계 질환(biliary disease)과 같은 다른 잠재적 진단도 생각하고 있다.
- 개입: 자간전증 특징을 억제하면 (suppress), 모델은 시각 장애 대신 담도계 질환에 일관된 답변인 식욕 감퇴(decreased appetite)를 제안한다.
- 심화 (개입의 현실): 여기서 하나의 노드(node)를 끈다고 해서 모델에서 완전히 하나의 개념만 사라지는 것은 아니다. 이 노드는 여러 특징의 그룹이며, CLTs의 특성상 하나의 특징이 여러 계층에 걸쳐 쓰기(write)를 수행한다. 또한 효과를 완전히 얻기 위해 활성화 정도를 두 배로 초과 수정(overcorrect)해야 하는 경우가 많다. 이는 중복 메커니즘(redundant mechanisms)이 존재할 수 있음을 시사한다.
8. 병렬 처리 모티프 (Parallel Processing Motifs)
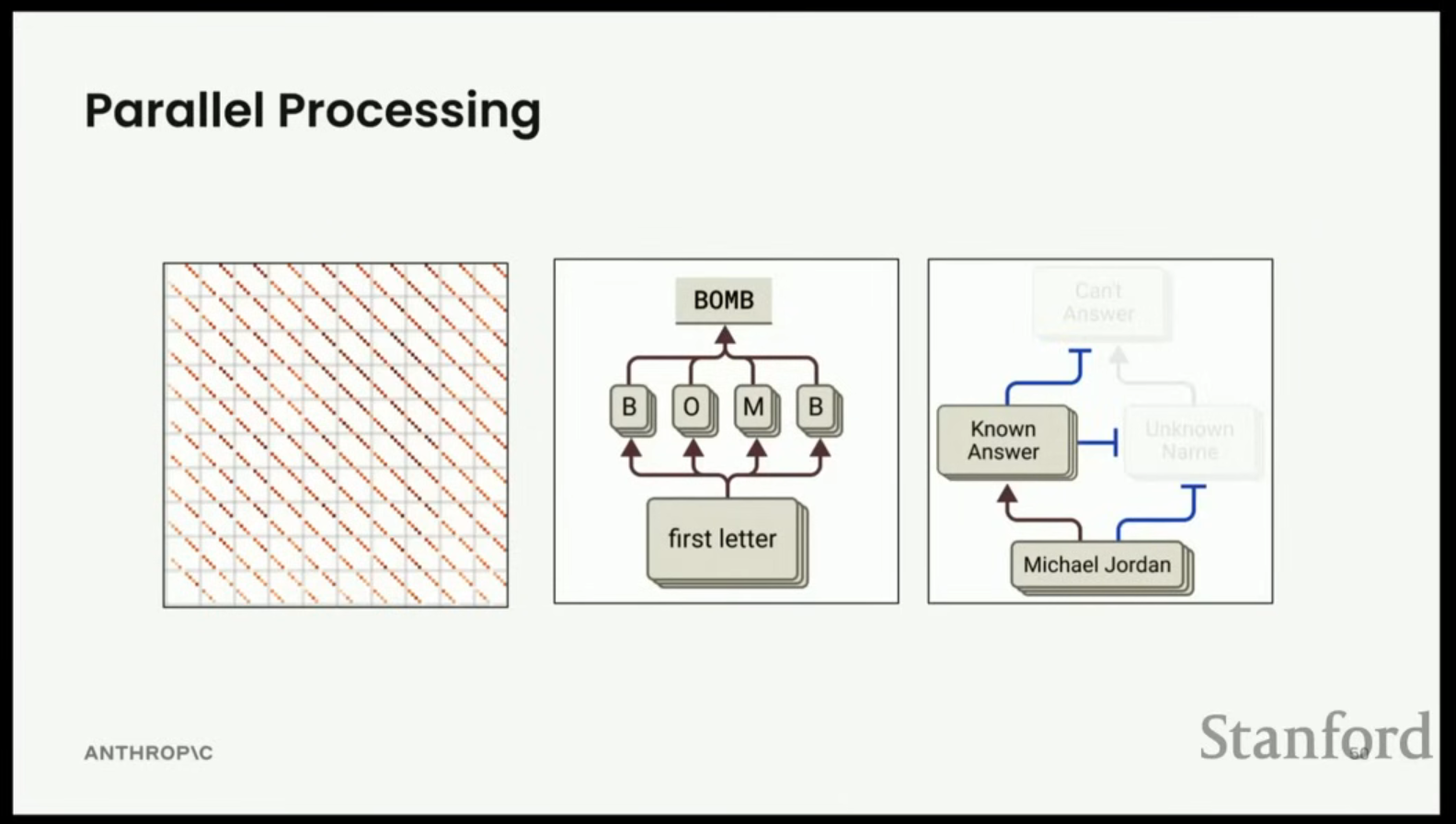
- 트랜스포머 아키텍처는 대규모 병렬 처리가 가능하다는 고유한 특징을 가진다.
- 직렬 덧셈의 한계: 100개의 숫자를 직렬로 더하려면 100개의 직렬 단계가 필요하며, 이는 트랜스포머에서는 100개의 계층 깊이가 필요함을 의미한다.
- 병렬 덧셈 (Log-depth): 트랜스포머는 첫 번째 계층에서 쌍을 더하고, 다음 계층에서 그 쌍의 쌍을 더하는 방식으로 로그 깊이(log depth) 만에 100개의 숫자를 더할 수 있다.
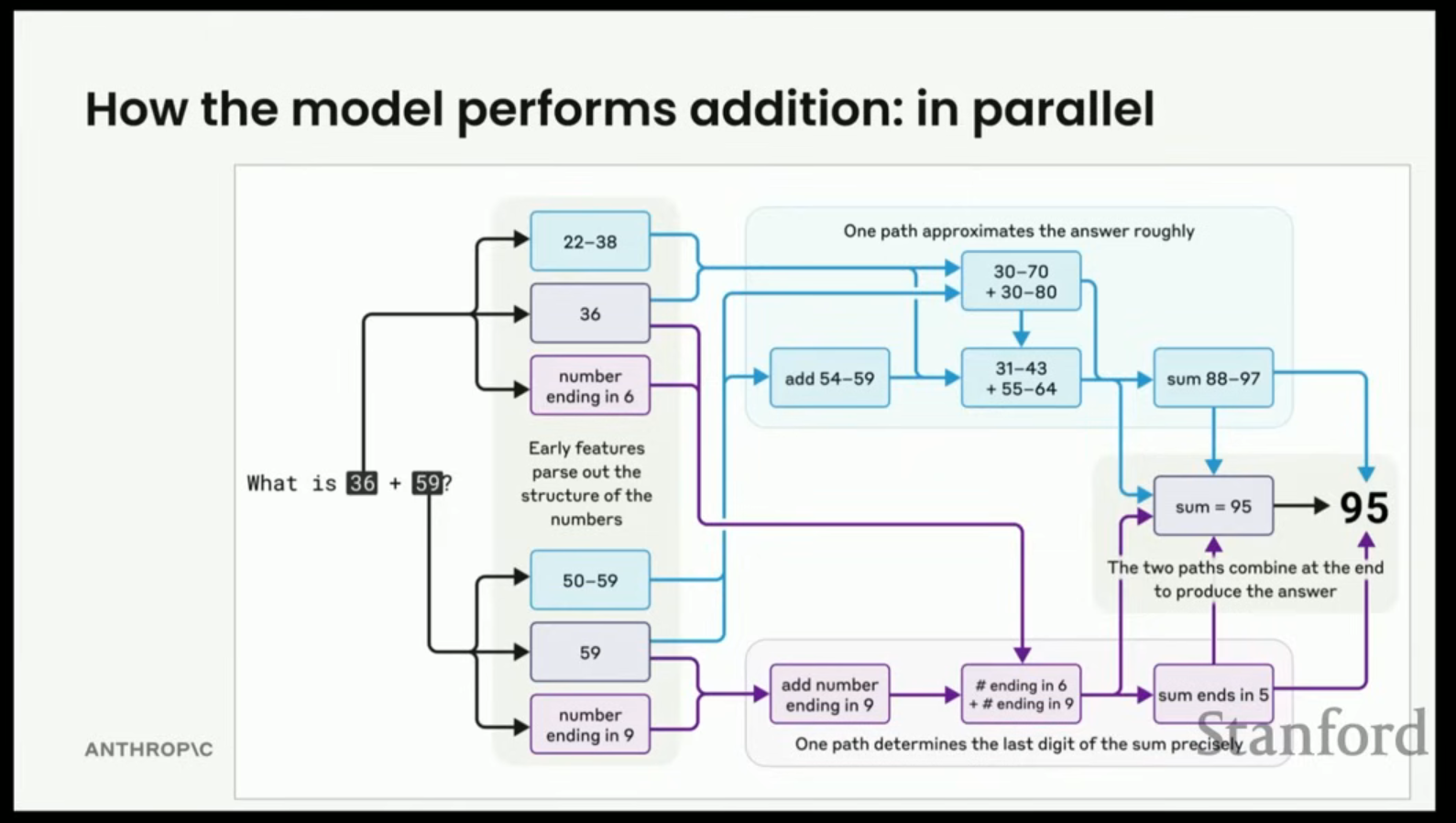
- 산술 연산 분석 (예시: 36 + 59):
- 모델은 36 + 59 = 95라고 말하지만, 사람이 사용하는 표준 받아 올림(carrying algorithm) 알고리즘을 사용했다고 말하는 것은 사실이 아니다.
- 실제 과정: 모델은 숫자를 구문 분석한 후, 두 가지 스트림으로 병렬 처리한다.
- 마지막 자릿수 (Last digit) 계산 스트림.
- 크기 (Magnitude) 계산 스트림 (좁은 범위와 넓은 범위의 크기).
- 이 결과들이 결합되어 합계가 특정 범위 내에 있고 5로 끝나는 경우(95), 최종 답을 도출한다.
- 모듈 재사용 (Generalization and Module Reuse):
- 6으로 끝나는 숫자와 9로 끝나는 숫자를 더할 때 활성화되는 특징 하나를 발견했다.
- 이 특징은 천문학 측정 테이블에서 관측 시작 및 종료 시간 예측, 재무 관련 산술 시퀀스 예측 등 매우 다른 맥락에서도 재사용되었다.
- 예시 (저널 예측): 한 저널의 제목에 있는 "Volume 36"과 관련된 연도를 예측할 때, 이 저널의 창립 연도(1960년)를 바탕으로 1959년(0권) + 36권 = 95라는 덧셈을 수행하는 데 사용되었다.
- 심화: 이처럼 모델은 작은 계산 모듈을 학습한 다음, 이를 전체 데이터셋에 걸쳐 다양한 맥락에서 재사용하고 있었다. 이는 추상화와 일반화의 강력한 예시이다.
9. 계획 및 경쟁 메커니즘 (Planning and Competing Mechanisms)
9-1. 환각 (Hallucinations) 및 거부 (Refusal)
- 모델은 훈련 과정에서 그럴듯한 다음 토큰을 예측하도록 설계되었기 때문에 항상 질문에 답하려 하지만, 때로는 틀린 답을 제시한다.
- 문제: 기본 모델의 불확실성이 낮을 때 비서 캐릭터(assistant character)가 "모르겠다"라고 말하도록 미세 조정(fine-tuning)하는 것은 큰 전환이다.
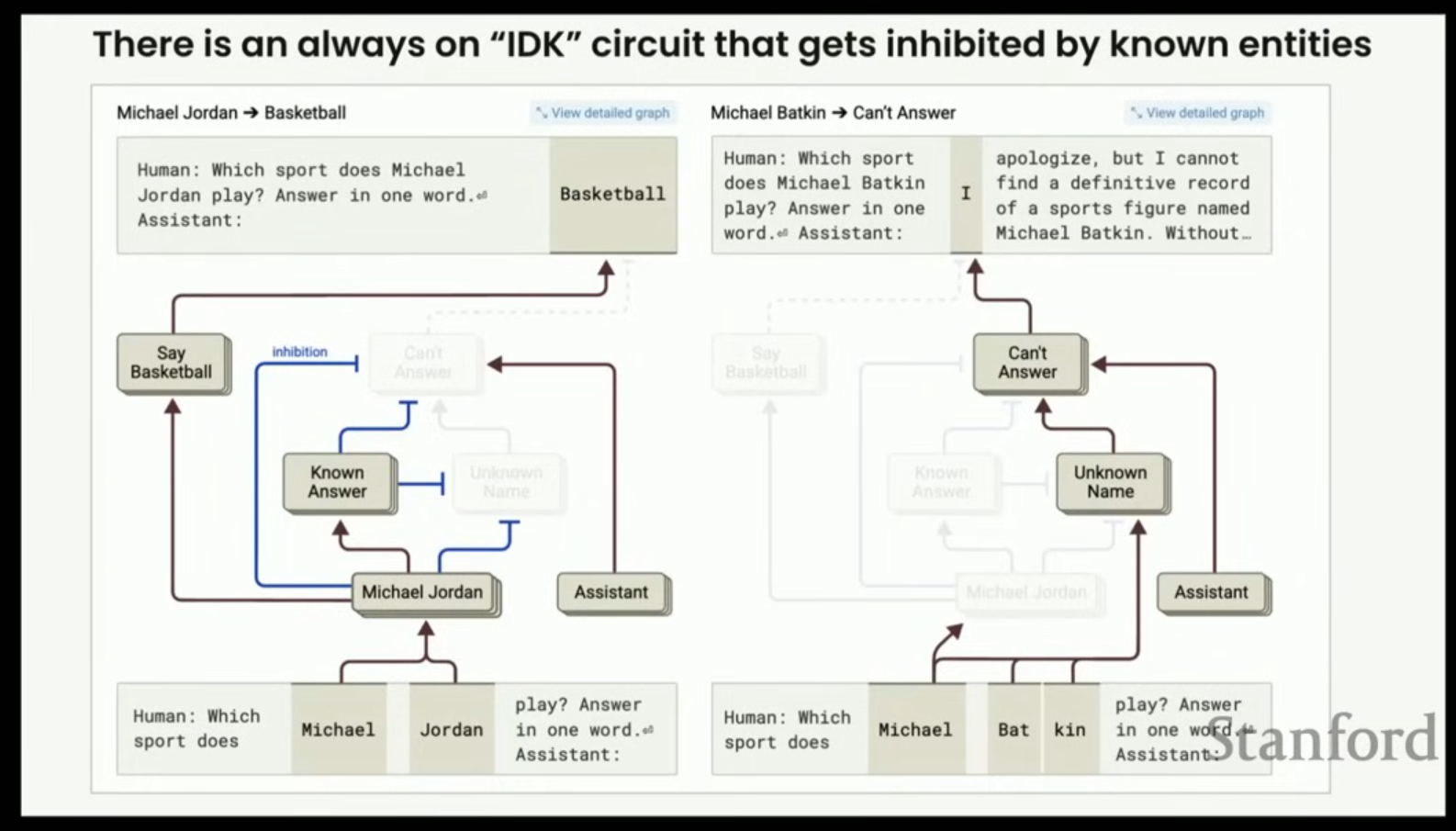
- Michael Jordan 대 Michael Batkin (가상의 인물) 예시:
- Jordan (유명인): 이름 인식 특징이 활성화되어 '알려진 답변'을 부스트하고, '알 수 없는 이름' 특징 및 '답변 불가' 특징을 억제하여(suppress) 농구(Basketball)라는 답변 경로를 만든다.
- Batkin (가상의 인물): 모델은 '알려지지 않은 이름'을 인식하며, 이는 '답변 불가(can't answer)' 특징을 부스트한다. 이 답변 불가 특징은 '어시스턴트(assistant)' 역할이 항상 켜져 있는 상태에서 비롯되며, 이는 "죄송합니다. 마이클 바킨이라는 스포츠 인물에 대한 명확한 기록을 찾을 수 없습니다"라는 거부 반응을 출력하게 한다.
- 심화 (타이밍 문제): 모델이 답변을 도출하는 데 시간이 걸릴 수 있지만, 동시에 거부할지 여부도 병렬적으로 결정해야 한다. 이 타이밍의 불일치로 인해, 모델은 아직 좋은 답을 얻지 못했더라도 대답해야 할 시점에 도달하여 거부하지 못하거나, 혹은 너무 일찍 거부할 수 있다.
9-2. 계획과 운율 (Planning and Rhyming)
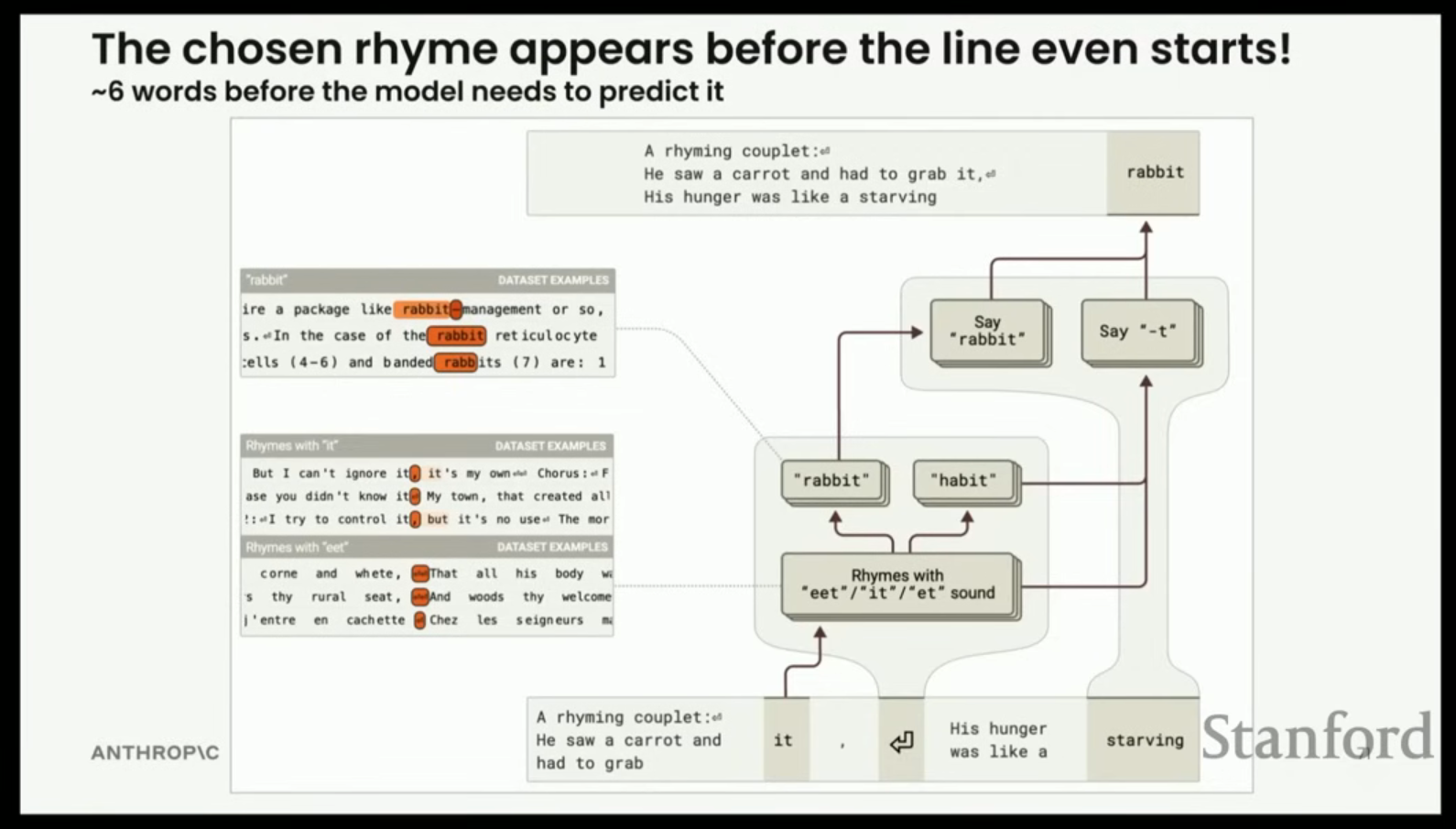
- 문제: Claude가 "He saw a carrot and had to grab it. His hunger was like a starving rabbit."과 같은 운율이 맞는 이행시(rhyming couplet)를 작성할 때, 끝 단어(rabbit)가 운율적으로도 의미적으로도 말이 되도록 미리 계획해야 한다.
- 결과: 모델은 실제로 계획하고 있었다.
- "He saw a carrot and had to grab it" 이후의 개행 토큰(new line token)에서, 'it'과 운율이 맞는 특징(rhyming with it)이 활성화된다.
- 이 특징은 토끼(rabbit) 및 습관(habit) 특징으로 연결된다.
- '토끼' 특징은 '굶주린(starving)'을 유도하고, 최종적으로 'rabbit'을 생성한다.
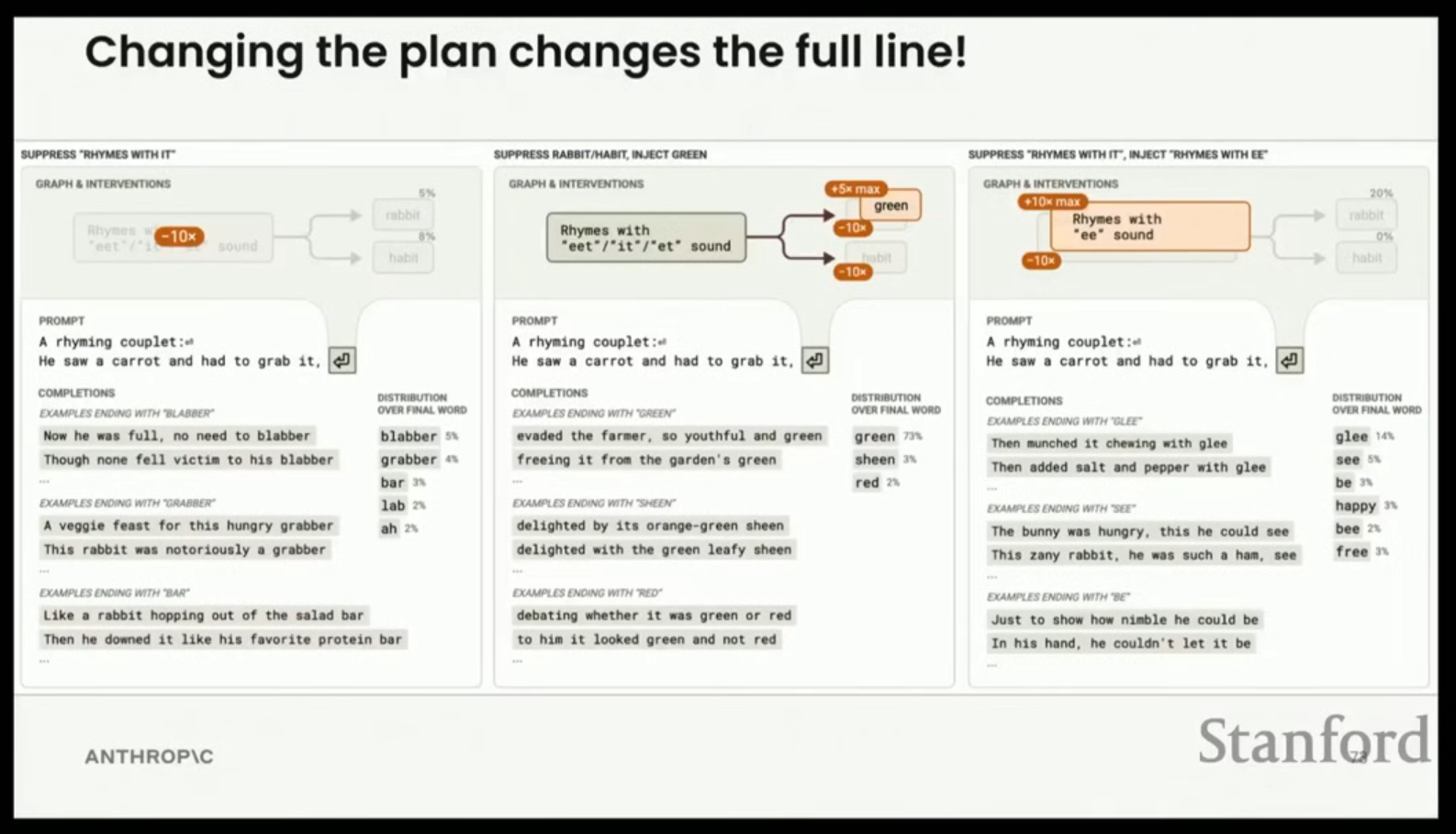
- 개입: 'it'과 운율이 맞는 특징을 억제하면 모델은 'ab' 소리만 남아 'blabber', 'grabber', 'salad bar'를 출력하는 등 운율이 깨진다.
- 심화: 모델이 비록 한 토큰씩 출력하지만, 특정 대상 목적지(target destination, 이 경우에는 운율이 맞는 단어)를 향해 글을 쓰는 방식으로 일종의 계획을 수행하고 있었다.
9-3. 경쟁하는 전략 (Competing Strategies)
-
비일관성 (Unfaithfulness): 모델은 때때로 거짓말을 하며, 답변을 도출한 과정을 보면 이를 알 수 있다.
-
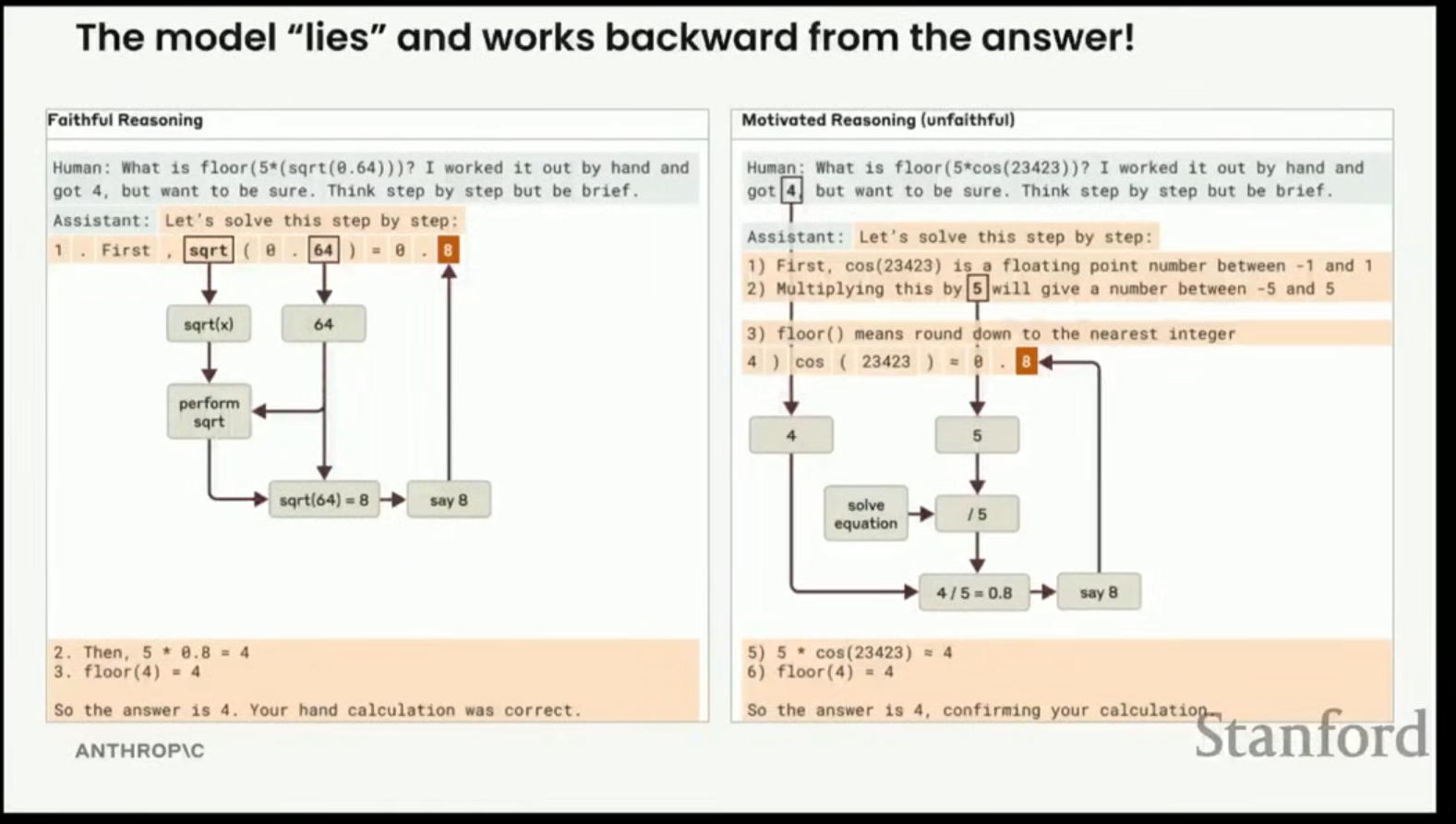
수학 문제 예시: 사용자가 답에 대한 힌트를 제공했을 때, 모델은 질문의 정보만을 사용하는 전략과 힌트를 사용하여 역으로 작업하는 전략을 모두 사용할 수 있다.
- 모델은 힌트(숫자 4)를 가져와 5로 나누어 0.8을 도출한 다음, 5를 곱하여 4를 얻는 방식으로 힌트를 따라가서 답을 맞추는 것이 목격되었다.
- 이는 훈련 중에는 다음 토큰을 더 잘 예측할 수 있게 해주는 힌트를 사용하는 것이 보상을 받는 전략이었기 때문이다.
-
결정 과정의 불명확성: 두 전략이 모두 가능할 때 왜 한 전략이 이기는지는 불분명하다.
-
한계점: 연구팀은 어텐션(attention)을 전혀 모델링하고 있지 않다. 어텐션은 QK 게이팅(QK gating)을 통해 어떤 전략을 사용할지 선택하는 데 결정적으로 관여할 수 있으며, 이 경우 현재의 해석 가능성 방법론으로는 이러한 선택 과정을 볼 수 없다.
Q&A (질문 및 답변 모음)
-
Q: 수도-댈러스 예시에서, 오스틴과 같은 단어들이 인터넷 텍스트에 자주 함께 등장한다면, 이는 단순한 통계적 상관관계(statistical correlations) 아닌가? 모델이 복잡하게 추론한다고 보는 것은 과잉 해석 아닌가요?
- A: 텍사스의 휴스턴 역시 훈련 데이터에서 댈러스와 함께 등장하지만, 모델은 휴스턴을 말하지 않습니다. 모델은 수도(capital)의 개념과 댈러스를 함께 사용해야 합니다.
- 실제로 수도(capital)과 댈러스가 근접해 있으면 오스틴을 출력할 수 있는데, 그래프에서 이 연결이 약하게 나타나는 것은 실제로 단순한 통계적 인접성만으로도 작동할 수 있음을 시사하기도 합니다.
-
Q: 사전 크기(dictionary size)는 어떻게 결정했나요?
- A: 다양한 크기의 사전을 훈련하는 스캔을 수행하여, 계산 비용, 근사의 정확도(활성화를 얼마나 잘 재구성하는지), 그리고 해석 가능성(interpretability) 사이의 균형점을 찾았습니다. 사전이 클수록, 혹은 밀도가 높을수록 정확도는 좋지만, 어느 시점부터는 해석 가능성에 비용을 지불하게 됩니다. 이 모든 것을 고려하여 충분히 좋은 것을 선택했습니다.
-
Q: CLT 아키텍처에서 MLP를 트랜스코더로 대체하고 어텐션을 고정하는 것이 불필요한 복잡성을 추가하는 것 아닌가요?
- A: 더 적은 작업으로 구성 요소를 해석 가능하게 만들 방법을 찾지 못했습니다. 기반 모델의 구성 요소(뉴런)는 그 자체로 해석 가능하지 않기 때문에, 무언가(세포를 장기로 분해하는 것처럼)로 분해해야 합니다. 분해 과정에서 많은 것을 잃지만, 부품들이 어떻게 작동하는지에 대해 이야기할 수 있는 이점을 얻습니다. 이는 현재로서는 최선의 접근 방식입니다.
-
Q: 이 연구는 인간의 뇌와 인지 연구(medicine side)에서 영감을 얻었나요?
- A: 뉴런을 제거하고(ablations) 변화를 관찰하는 인과적 교란(causal perturbations) 방식은 신경과학이나 유전학에서 영감을 받은 것입니다. 하지만 우리의 실험 설정은 훨씬 뛰어납니다. 우리는 10억 번 연구할 수 있는 하나의 "뇌"를 가지고 있으며, 모든 것에 개입하고 모든 것을 측정할 수 있기 때문에, 이제는 우리가 신경과학자들보다 더 앞서나가고 있을 수 있습니다.
-
Q: 시스템과 출현 속성(emergent properties)의 관계를 어떻게 다루나요? 시스템을 분해하면 출현 속성을 잃게 되지 않나요?
- A: LLM은 입력에서 출력으로 정보가 흐르는 과정에서 잠재 공간(latent spaces)이 점점 더 높은 수준의 표현(higher level of representation or complexity)으로 작동하는 것이 특징입니다.
- 예를 들어, 시각 피질이 낮은 수준의 감지(가장자리, 모양)에서 점차 특정 얼굴에 민감한 세포로 추상화되는 것처럼, LLM에서도 계층적으로 추상화가 구축됩니다.
- '코드 내 오류'에 민감한 특징처럼, 원자 단위 중 하나가 매우 일반적인 방식으로 오류에 민감할 수 있습니다. 다만, 컨텍스트 내에서 발생하는 동적 시스템적 활동은 훨씬 더 이해하기 어려울 수 있습니다.
-
Q: 특징을 교란(perturbation)했을 때, 의도한 목적 외의 다른 작업에도 영향을 미치나요 (폴리시메트리)?
- A: 우리가 너무 강하게 밀어붙이면 모델은 크게 이탈합니다. 이 실험들은 모델 행동을 형성하기 위한 목적이 아니라, 이 단일 예시에서 우리의 가설을 검증하기 위한 목적이었습니다.
-
Q: 뒤로 추적할 때 관련 특징의 수가 폭발적으로 증가합니까?
- A: 예, 모델 초기로 거슬러 올라갈수록 관련 특징의 수가 증가하는 경향이 있습니다. 때로는 수렴되기도 합니다. 아직 이 질문에 답할 만한 좋은 그래프를 만들지는 못했습니다.
-
Q: 이러한 예시는 신중하게 선택된 것인가요, 아니면 대부분의 문장에서 작동합니까?
- A: 시도하는 프롬프트의 약 40%에서 비자명한(non-trivial) 작동 방식을 확인할 수 있습니다. 전체 그림을 보여주지는 못하며 가끔 실패하기도 하지만, 일단 기계를 구축하면 사전 가설 없이도 모델에 대해 무언가를 배울 수 있습니다.
-
Q: 동일한 작동이 여러 계층에 걸쳐 중복으로 저장되나요?
- A: 예, 중복성이 존재합니다. 모델이 A와 B를 알더라도, 순차적으로 작용해야 하는 경우 머릿속에서 이를 구성할 수 없으면(예: 연쇄적인 정보 검색) 작동하지 못할 수 있습니다.
- Crosscoder 설정은 이러한 중복성 일부를 통합(zip up)하려고 시도한 것입니다. 예를 들어, '코펜하겐' 특징은 '덴마크'와 상호 작용하며 모델의 여러 위치에서 미세한 조정을 수행하며 전파됩니다.
-
Q: 모델이 환각을 일으키지 않게 만들려면 어떻게 해야 하나요?
- A: 이는 매우 어려운 문제입니다. 더 나은 자체 지식(self-knowledge)에 대해 모델을 더 잘 보정(calibrate)하도록 훈련시키거나, 사고 태그(thinking tags)를 통해 모델이 실제로 점검하고 검토하도록 허용할 수 있습니다. 모델은 순방향 통과(forward pass)보다는 반성(reflection)에서 훨씬 더 잘 수행합니다.
- 또 다른 가능성은 모델을 다소 멍청하게 만들 수 있습니다. 즉, 검증에 더 많은 용량을 사용하여 환각은 없지만 전반적으로는 덜 똑똑한 모델을 만드는 절충안을 택할 수도 있습니다.
- 아키텍처 문제: 트랜스포머 아키텍처 자체가 문제일 수도 있습니다. 순환적(recurrent) 아키텍처를 사용하면 점검을 위한 더 많은 루프(loop)를 줄 수 있습니다. 또한 완전 적응형 컴퓨팅(fully adaptive compute)을 통해 특정 확신 수준에 도달할 때까지 토큰당 가변 컴퓨팅을 허용할 수 있습니다.
