0. 3줄 핵심 요약
- 본 논문은 이기종 로봇(휴머노이드, 매니퓰레이터 등)을 하나의 통합된 행동 공간(Unified Action Space)으로 제어하기 위해 5단계(L0~R2) 커리큘럼 학습을 제안한 범용 VLA 프레임워크(Green-VLA)입니다.
- 기술적으로는 단순 패딩(Padding)을 배제한 의미론적 행동 매핑과 마스킹, 광학 흐름(Optical Flow) 기반의 궤적 시간 정렬, 그리고 OOD(Out-of-Distribution) 탐지 및 JPM(Joint Prediction Module)을 결합한 가이던스 메커니즘을 통해 정밀도와 안정성을 극대화했습니다.
- 실험 결과, 기존 행동 복제(Behavior Cloning)의 한계를 넘어 강화학습(RL) 정렬을 통해 장기(Long-horizon) 작업에서의 성공률과 복구 능력을 크게 향상시켰으며, 시뮬레이션 및 실제 다관절 휴머노이드 환경 모두에서 SOTA(State-of-the-Art) 성능을 달성했습니다.
1. 배경 및 문제 정의
최근 로봇 공학에서 대규모 언어 및 비전 모델을 제어에 결합하는 VLA(Vision-Language-Action) 모델이 등장하며, 자연어 명령에 따라 다양한 환경에서 행동할 수 있는 범용 에이전트의 가능성이 열리고 있습니다. , OpenVLA, GR00T 등 기존 연구들은 데이터 확장을 통해 단일 엔드투엔드(End-to-End) 프레임워크 내에서 인지와 행동을 통합하려 시도했습니다.
그러나 기존 방법론은 실제 환경 적용 시 명확한 한계를 지닙니다. 첫째, 로봇 데이터셋은 관측치, 행동 공간(Action Space), 샘플링 속도 측면에서 이질성이 매우 높으며, 단순한 데이터 확장은 지터(Jitter)나 노이즈까지 학습하게 만듭니다. 둘째, 로봇 제어의 지배적인 학습 방식인 행동 복제(Behavior Cloning, BC)는 모델이 장기적인 목표를 달성하거나 복잡한 접촉 작업(Contact-rich manipulation)을 수행할 때 누적 오차로 인해 빠르게 성능이 포화됩니다. 셋째, 추론 능력을 강화하기 위한 최근의 자기회귀(Autoregressive) 기반 VLM 제어는 지연 시간(Latency)이 길어 실시간 제어에 부적합합니다.
따라서 본 논문은 단순히 데이터와 모델의 크기를 키우는 것을 넘어, '데이터 품질 정렬', '이기종 행동 공간의 시맨틱 통합', 그리고 '강화학습을 통한 장기 작업 정렬'을 포괄적으로 해결하는 Green-VLA 프레임워크를 제안하여 이 문제를 해결하고자 합니다.
2. 제안 방법 (Method)
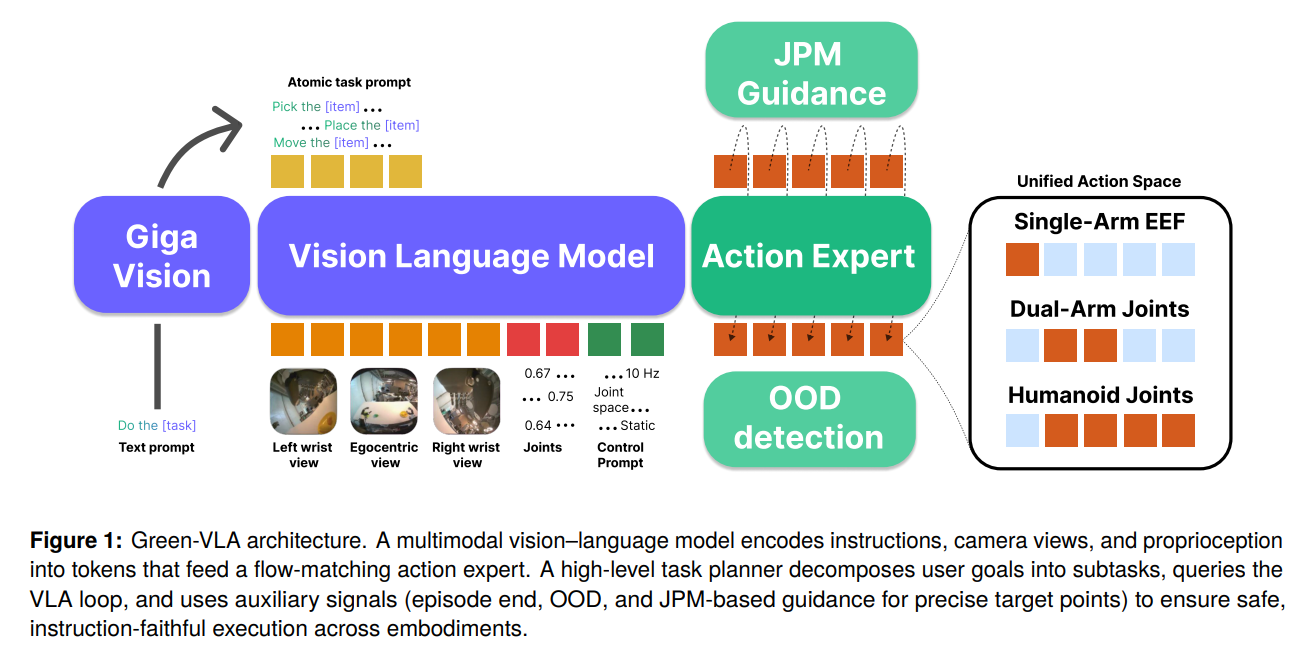
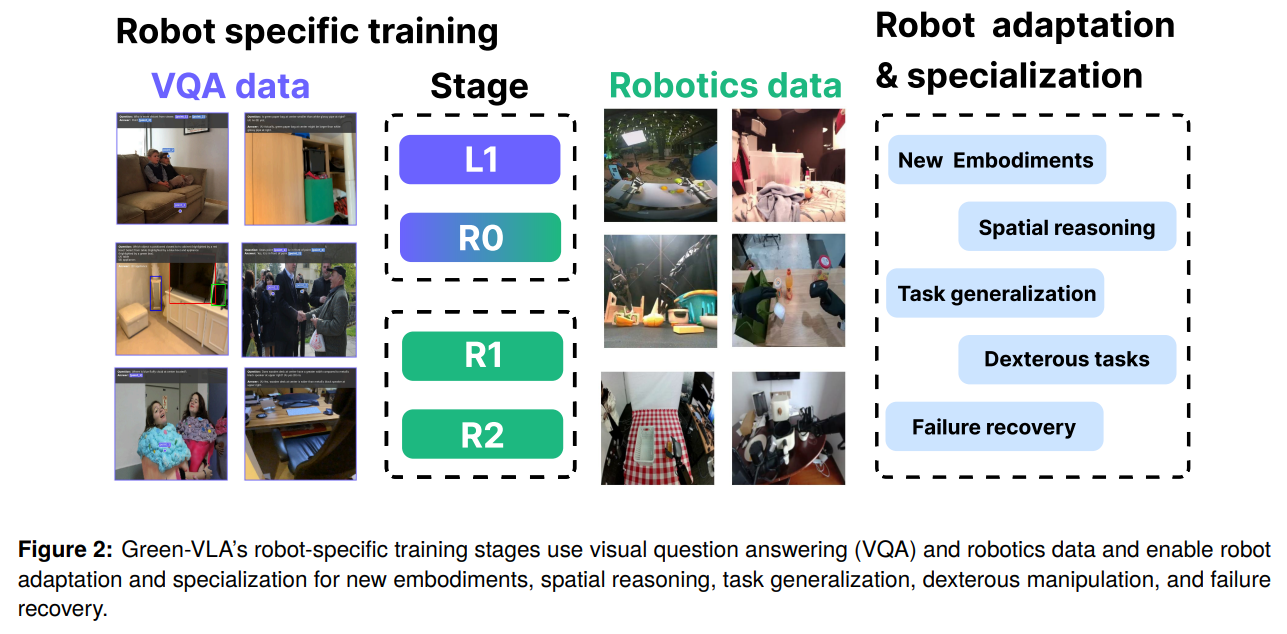
Green-VLA는 웹 스케일의 사전 지식과 이기종 로봇의 제어 데이터를 통합하기 위해 5단계의 커리큘럼(L0: Base VLM L1: Web Pretrain R0: General Robotics Pretrain R1: Embodiment SFT R2: RL Alignment)을 거칩니다.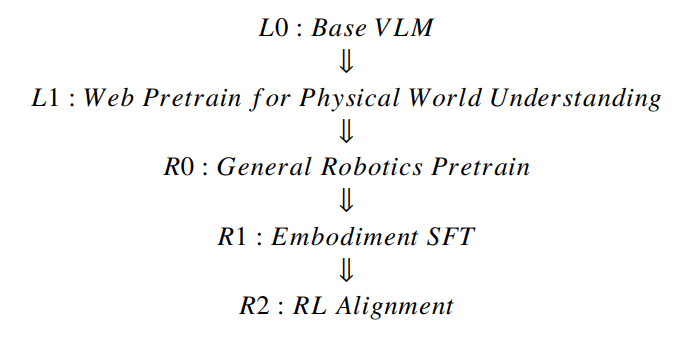
입력 데이터의 표현 및 전처리 방식
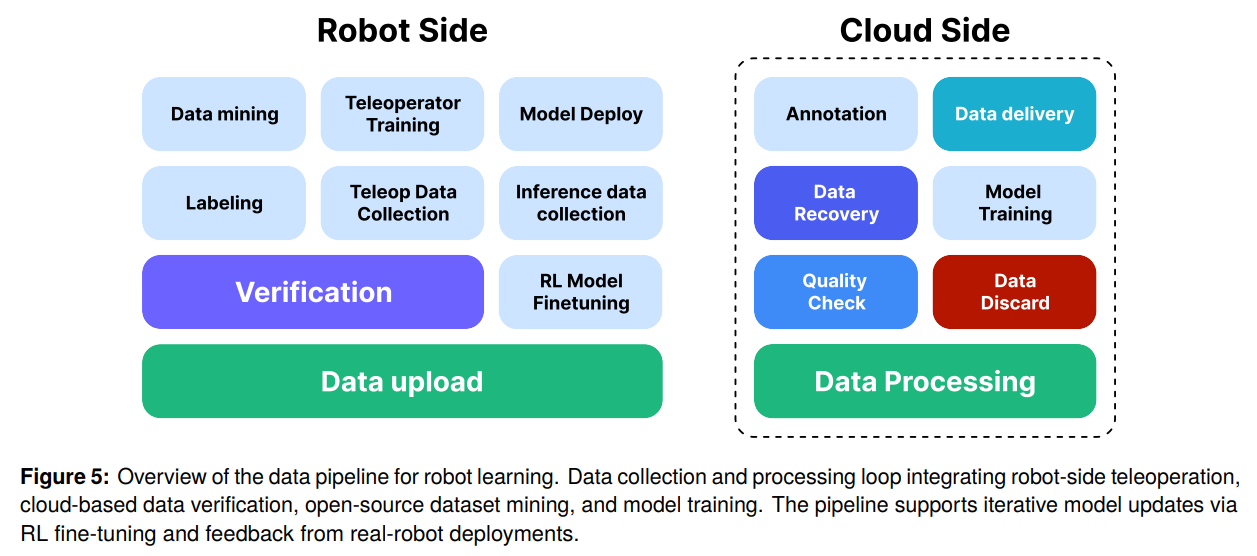
수집된 로봇 데이터는 이질적인 샘플링 속도와 품질을 가집니다. 이를 정규화하기 위해 DataQA 파이프라인이 궤적 부드러움(), 이미지 선명도(), 시각적 다양성(), 상태 분산()을 기준으로 데이터를 필터링합니다. 데이터가 모델에 주입되기 전, 광학 흐름(Optical Flow)의 크기를 기반으로 각 데이터셋의 모션 속도를 추정하고, 단조 3차 스플라인(Monotonic Cubic Splines)을 이용해 행동을 보간(Interpolation)하거나 리샘플링하여 시공간적 동역학을 정규화합니다.
통합 행동 공간(Unified Action Space) 및 네트워크 구조
네트워크는 1. GigaChat 기반의 상위 작업 계획기(Task Planner), 2. VLM 인코더, 그리고 3. 플로우 매칭(Flow-matching) 기반의 행동 전문가(Action Expert)로 구성됩니다. 핵심은 기존 연구들이 이기종 행동 공간을 맞추기 위해 사용하던 '단순 제로 패딩(Zero-padding)'을 제거한 것입니다. Green-VLA는 차원의 고정된 의미론적 슬롯 레이아웃()을 정의합니다.
모델은 실시 중인 제어 타입 프롬프트 와 활성화된 마스크 를 입력받아 다음의 마스킹된 BC 목적 함수를 최소화합니다.
사용되지 않는 좌표()에 대해서는 손실을 계산하지 않음으로써, 이기종 데이터 혼합 시 발생하는 의미론적 충돌과 거짓 페널티(Spurious penalty)를 방지합니다.
또한, 행동 전문가의 은닉 상태 에 행동 속도 인자 를 조절하는 RMSNorm 기반 모듈레이션을 적용하여, 장기-단기(Long-short horizon) 제어에 대한 해상도를 동적으로 조절합니다.
학습(Training)과 추론(Inference) 단계의 파이프라인
- 학습 파이프라인 (특히 R2 RL 단계): 행동 복제(R0, R1) 이후 모델은 두 가지 오프라인/온라인 RL 방식을 거칩니다. 첫째, IQL(Implicit Q-Learning)을 사용해 행동 가치 함수 를 학습하고, 를 통해 궤적을 최적화하여 데이터셋을 갱신합니다. 둘째, 플로우 매칭 모델의 초기 노이즈 소스 분포 를 최적화하는 Actor를 학습시켜, 기존 모델의 가중치를 직접 변경하지 않으면서도 보상을 극대화하는 노이즈를 샘플링하도록 유도합니다.
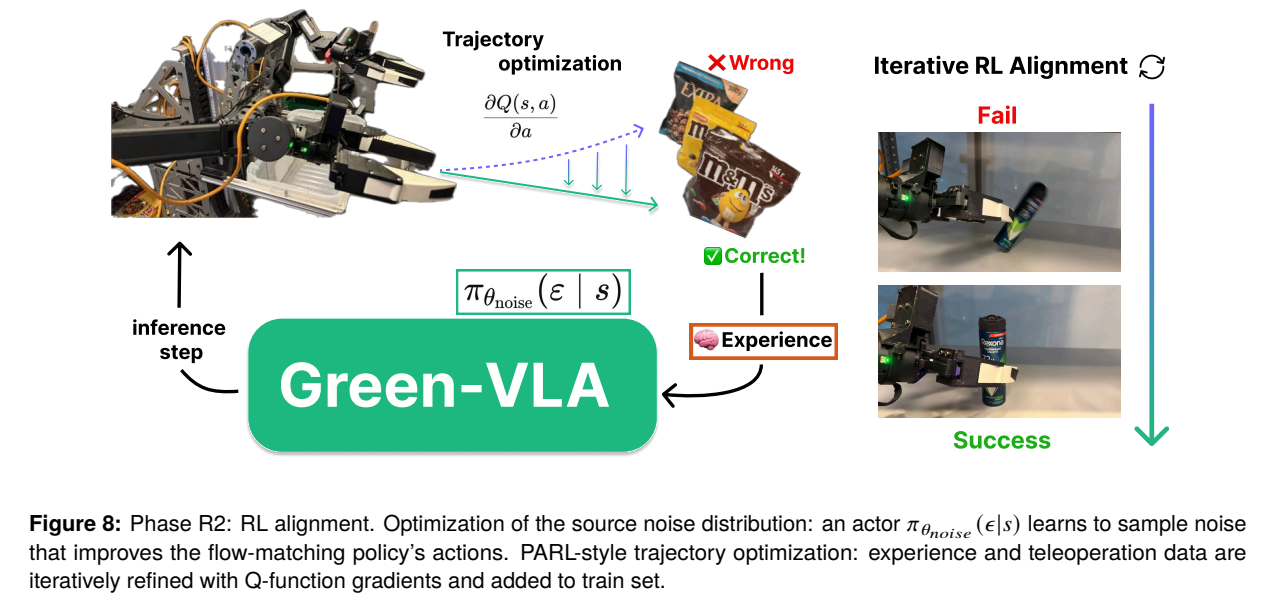
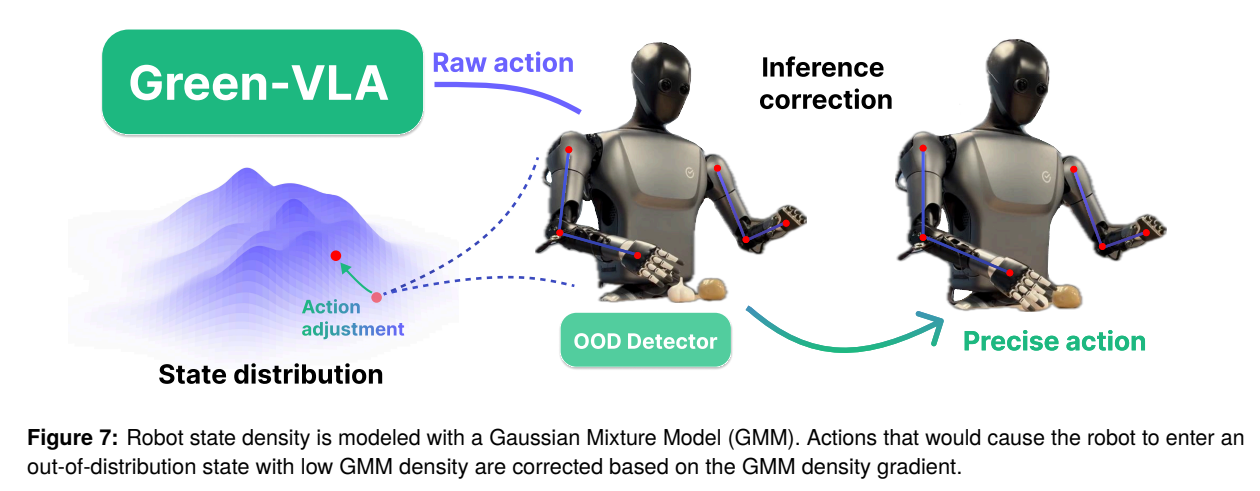
- 추론 파이프라인: 상위 VLM은 언어 명령을 원자적 하위 작업(Atomic subtasks)으로 분해합니다. JPM(Joint Prediction Module)은 2D 어포던스(Affordance) 포인트를 예측한 후 카메라 파라미터를 통해 3D 역기구학 목표 지점 로 변환합니다. 행동 생성 시 의사역행렬 가이던스(GDM)를 적용해 플로우 매칭의 속도장 를 해당 목표 지점으로 편향시킵니다. 생성된 행동이 학습 데이터 분포를 벗어나면 GMM(Gaussian Mixture Model) 밀도의 그래디언트를 이용해 상태를 궤도 내로 보정합니다().
3. 실험 결과 (Experiments)
평가는 AgileX Magic Cobot, Simpler(WidowX, Google Robot), 그리고 32 DoF의 상반신 제어가 필요한 Green Humanoid 환경에서 진행되었습니다. 비교군으로는 , OpenVLA, Flower, RT-1X 등이 사용되었습니다.
- 다중 임바디먼트 전이 (R0): 테이블 정리 작업(Pick-and-place)에서 추가적인 미세조정(SFT) 없이도 와 유사하거나 이를 능가하는 성공률 및 실행 효율성(가장 빠른 작업 완료 시간)을 보였습니다.
- RL 정렬의 효과 (R2): CALVIN 환경과 WidowX 환경 모두에서 R2 강화학습 미세조정 후 장기 작업 일관성과 평균 체인 길이(Average Chain Length, ACL)가 극적으로 향상되었습니다. 행동 복제의 포화 문제를 극복하고 접촉 오류 상황에서의 복구(Recovery) 역량이 크게 상승했습니다.
- OOD 및 정밀 제어: E-commerce 환경 실험에서 JPM과 가이던스가 결합된 Green-VLA는 처음 보는 SKU(재고 유지 단위)나 복잡한 시각적 방해물(Clutter)이 있는 상황에서도 압도적인 객체 식별 및 파지 성공률을 기록했습니다.
4. 한계점 및 시사점
한계점 및 고려 과제
논문은 다기종 데이터를 대상 임바디먼트로 투영하는 '리타게팅(Retargeting)'의 충실도에 따라 모델 성능이 영향을 받을 수 있다고 명시합니다. 데이터셋에 내재된 편향(Bias)이나, 정밀한 손가락 제어(Dexterous skills)를 위한 절대적인 데이터 부족 현상은 여전히 해결해야 할 과제입니다. 또한 실시간 제어를 위해 상위 VLM의 빠른 추론과 하위 플로우 매칭 네트워크 간의 지연 시간(Latency) 최소화 등 엔지니어링 최적화가 필수적입니다.
학술적 및 실무적 시사점
Green-VLA는 로보틱스 파운데이션 모델이 단순히 파라미터를 키우는 방향성에서 벗어나, 정교한 데이터 품질 관리, 이기종 행동의 올바른 의미론적 맵핑, 그리고 타겟 보상 기반의 강화학습 정렬이 결합되어야만 실제 현장에서 신뢰성 있게 동작할 수 있음을 증명했습니다. 향후 다국어(Multilingual) 추론 기능과 궤적 메모리 기능이 통합된다면, 산업용/가정용 등 다양한 환경에 즉각적으로 투입 가능한 범용 지능형 로봇의 확장을 가속화할 것입니다.
