논문 리뷰
1.[논문 리뷰] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning

논문링크 : DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning주요 요약:DeepSeek-R1-Zero은 DeepSeek-V3에 large-scale reinforcemen
2.[논문 리뷰] Dual-Channel Deepfake Audio Detection : Leveraging Direct and Reverberant Waveforms
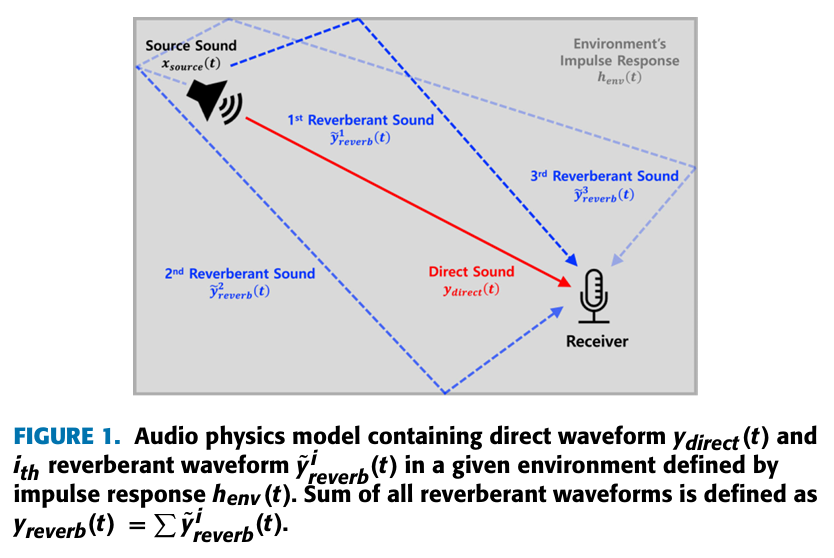
논문링크 : Dual-Channel Deepfake Audio Detection : Leveraging Direct and Reverberant Waveforms: 환경 요인이 반영된 Dual-channel을 사용해서 DeepFake Audio를 더 잘 구분할 수 있다
3.[논문 리뷰] Attention Is All You Need
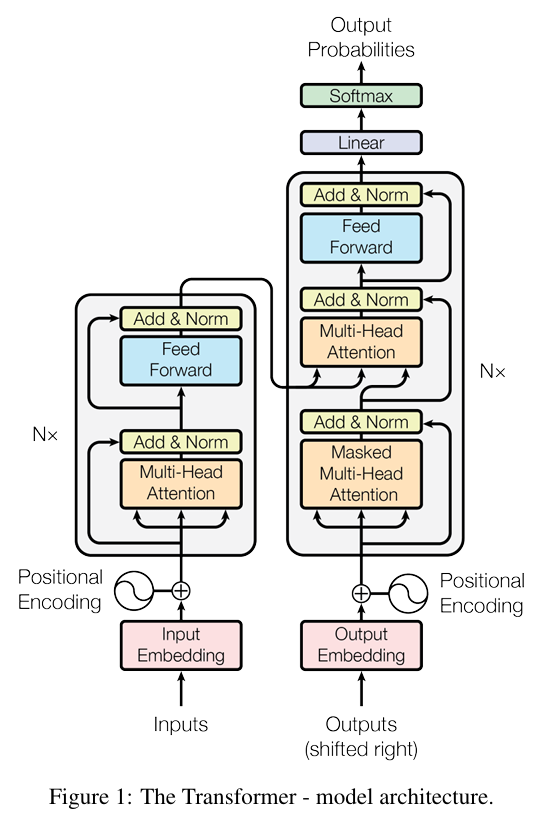
논문링크 : Attention Is All You Need: GPT를 통해서 더 이상 공부하지 않을 수 없는 NLP에서 Transformer의 중요성을 알게 되어 한 번쯤 공부하고 싶었습니다. 그리고, SuperGlue 논문을 통해서 attention이 다양한 영역에도
4.[논문 리뷰] Denoising Diffusion Probabilistic Models
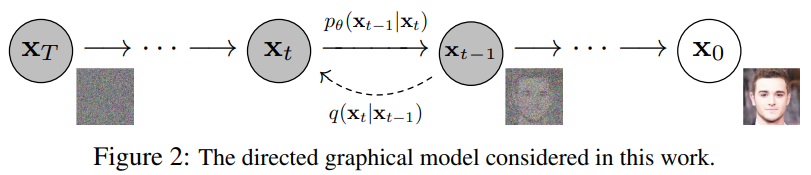
논문링크 : Denoising Diffusion Probabilistic Models: Diffusion 모델의 성능이 상당히 좋다는 점에서 감명받았고, transformer와 같은 중요한 논문이라고 판단해서 리뷰하게 됐습니다.이 논문에서 소개할 diffusion pr
5.[논문 리뷰] Link Prediction Based on Graph Neural Networks
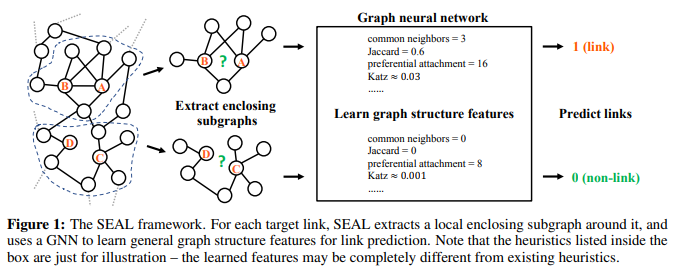
논문링크 : Link Prediction Based on Graph Neural Networks: GNN을 공부하다보니 Link Prediction에 대한 내용이 많이 나오고 그에 따른 유명한 논문을 찾아보다 보게 됐습니다.각각의 target link 주변의 local
6.[논문 리뷰] GNNExplainer: Generating Explanations for Graph Neural Networks
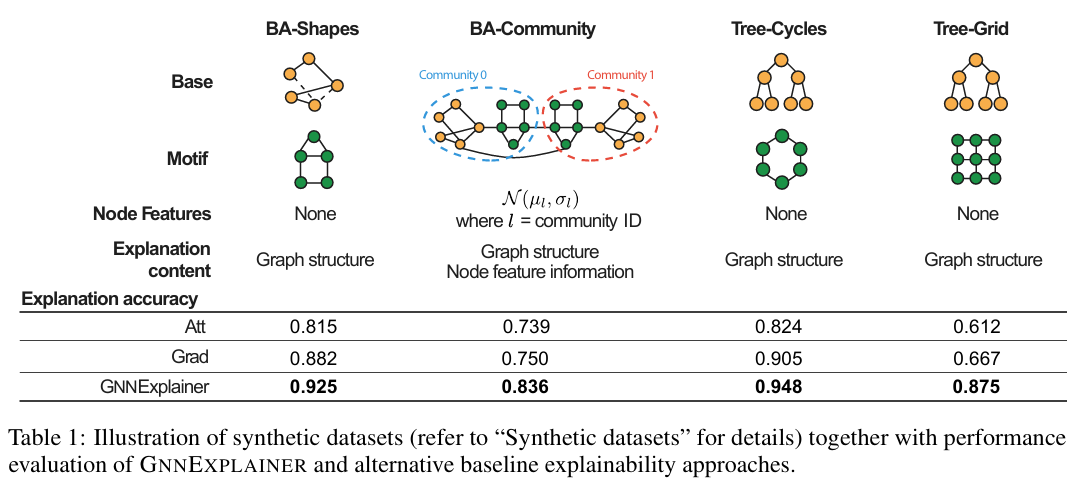
논문 링크 : GNNExplainer: Generating Explanations for Graph Neural Networks: GNN에 대한 폭넓은 지식 습득을 위해 시도입니다.다음 3가지 이유 때문에, GNN prediction을 이해하는 것은 유용한다.GNN m
7.[논문 리뷰] Hierarchical Graph Representation Learning with Differentiable Pooling
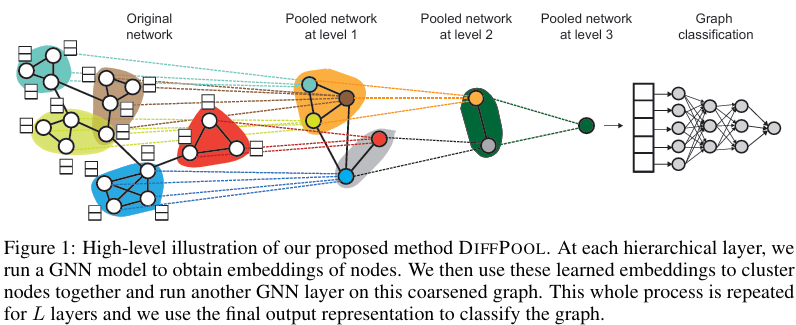
논문 링크 : Hierarchical Graph Representation Learning with Differentiable Pooling: 그래프 관련해서 기본 지식들을 탑재하고자 state-of-the-art의 코드가 많은 순서대로 공부하던 중 관심이 생겼습니다.
8.[논문 리뷰] SuperGlue : Learning Feature Matching with Graph Neural Networks
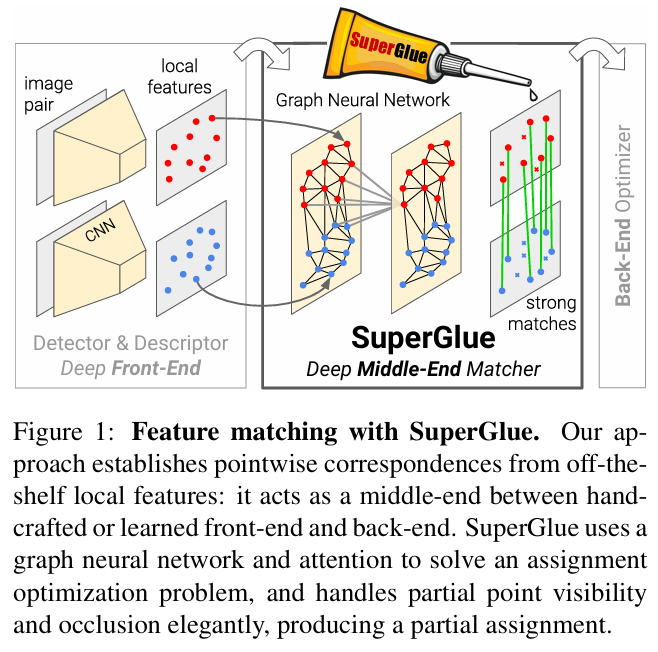
논문 : SuperGlue : Learning Feature Matching with Graph Neural Networks: GNN이라는 기술에 관심이 생겨서 논문을 읽어보려고 하는데, 최신 기술 중 가장 구현이 많이 된 논문이라서 선택하게 됐습니다.SuperGlue
9.[논문 리뷰] Revisiting Deep Learning Models for Tabular Data
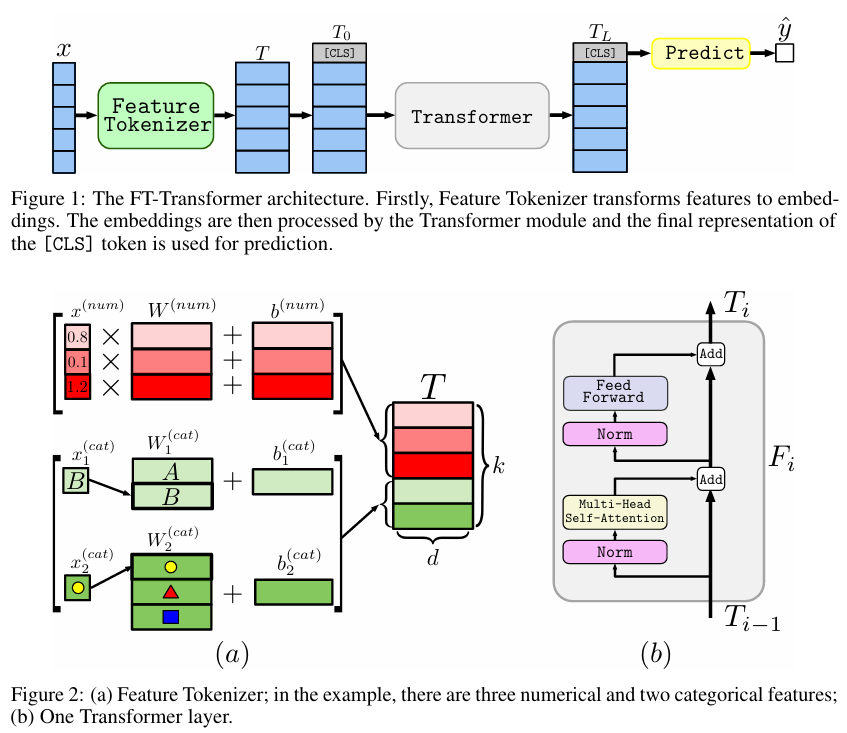
Title: Revisiting Deep Learning Models for Tabular DataConference: NeurIPS 2021Authors: Yury Gorishniy et al.주요 모델: FT-Transformer (Feature Tokenizer
10.[논문 리뷰] T2G-FORMER: Organizing Tabular Features into Relation Graphs Promotes Heterogeneous Feature Interaction
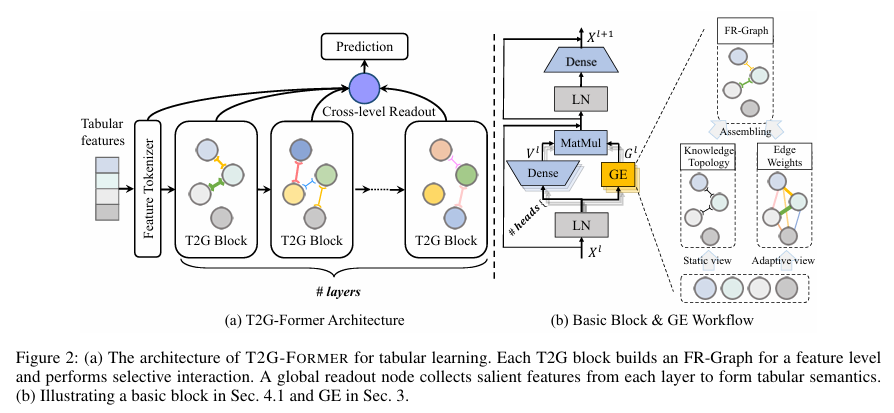
제목: T2G-FORMER: Organizing Tabular Features into Relation Graphs Promotes Heterogeneous Feature Interaction학회: AAAI 2023한 줄 요약:테이블 데이터를 그냥 attention으로
11.[논문 리뷰] Why do tree-based models still outperform deep learning on typical tabular data?
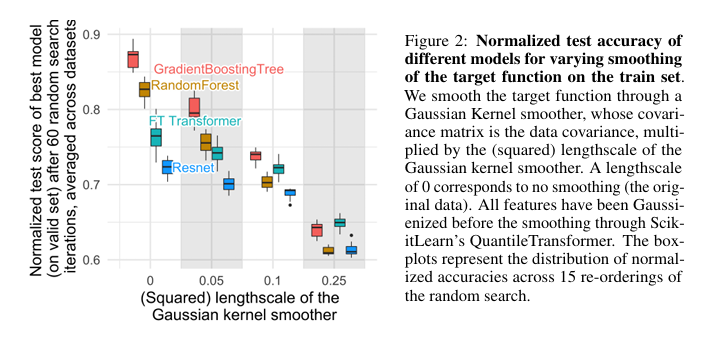
사용자가 작성해주신 T2G-Former 블로그 포스트의 흐름과 문체, 그리고 시각적 요소를 완벽하게 반영하여 "Why do tree-based models still outperform deep learning on typical tabular data?" 논문을 다시
12.[논문 리뷰] TabTransformer: Tabular Data Modeling Using Contextual Embeddings
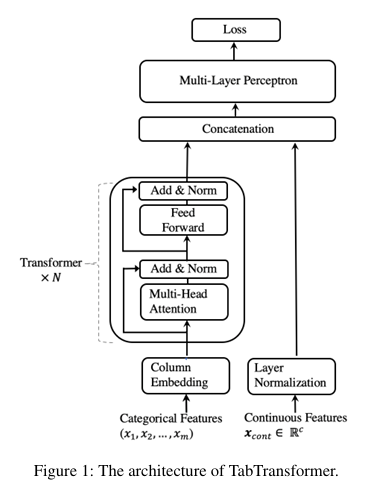
제목: TabTransformer: Tabular Data Modeling Using Contextual Embeddings학회/연도: arXiv 2020 (Amazon AWS)한 줄 요약:범주형 변수를 단순 숫자로 바꾸지 말고, Transformer를 통해 피처 간
13.[논문 리뷰] Large Scale Transfer Learning for Tabular Data via Language Modeling
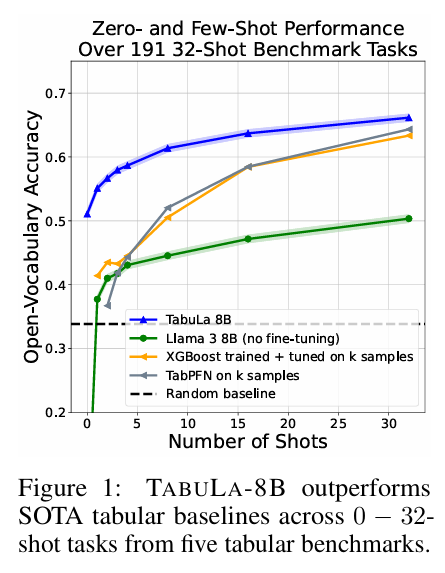
제목: Large Scale Transfer Learning for Tabular Data via Language Modeling학회/연도: arXiv 2024 (NeurIPS 2024 제출 추정)내가 정의한 한 줄 요약:"방대한 20억 개(2.1B)의 테이블 데이터로
14.[논문 리뷰] Large Language Models on Tabular Data - A Survey

제목:Large Language Models on Tabular Data – A Survey학회/연도:arXiv, 2024년 2월내가 정의한 한 줄 요약:“트리 기반 모델의 한계를 넘어, LLM의 추론 및 생성 능력을 정형 데이터에 이식하기 위한 전 과정을 체계적으로
15.[논문 리뷰] Binning as a Pretext Task: Improving Self-Supervised Learning in Tabular Domains
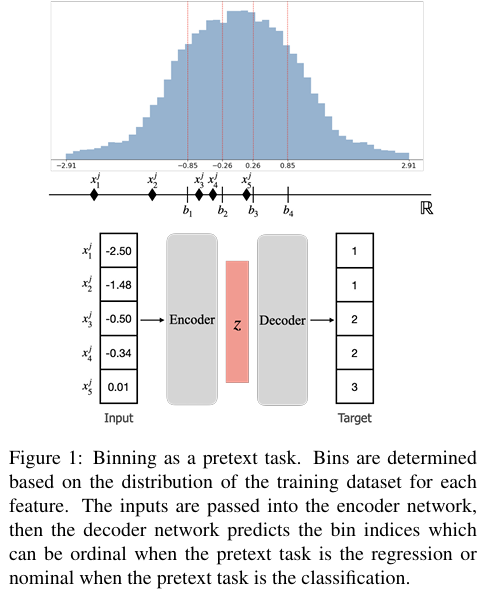
제목:Binning as a Pretext Task: Improving Self-Supervised Learning in Tabular Domains학회/연도:ICML 2024 (accepted), arXiv, 2024년 5월내가 정의한 한 줄 요약:연속형/이질적인 T
16.[논문 리뷰] Representation Space Augmentation for Effective Self-Supervised Learning on Tabular Data
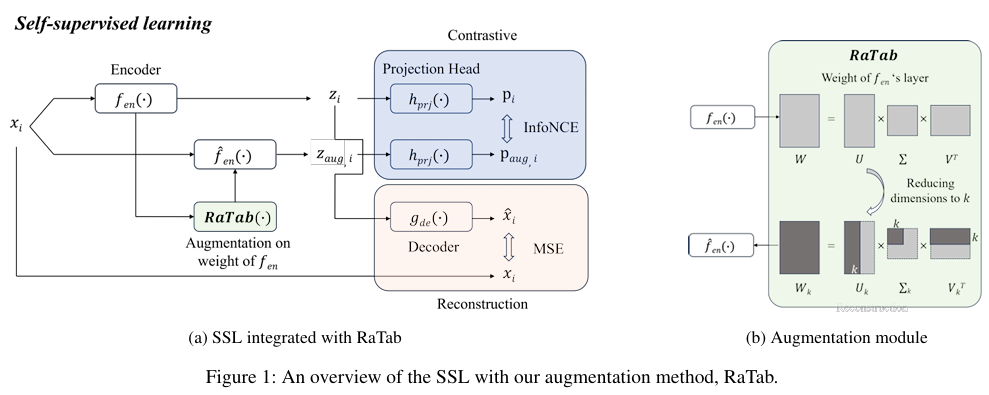
제목: Representation Space Augmentation for Effective Self-Supervised Learning on Tabular Data(AAAI Conference on Artificial Intelligence 2025)학회/연도:AAA
17.[논문 리뷰] AGATa: Attention-Guided Augmentation for Tabular Data in Contrastive Learning
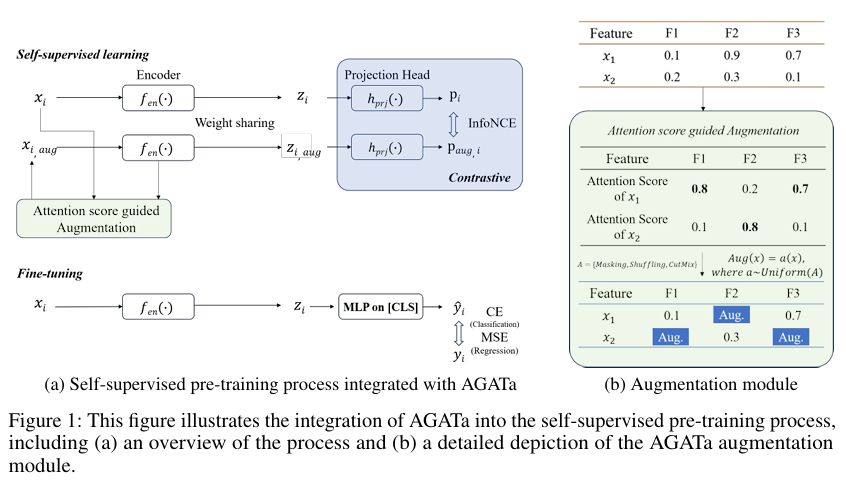
제목: AGATa: Attention-Guided Augmentation for Tabular Data in Contrastive Learning(https://openreview.net/forum?id=l5VGHbRVW0\* 저자: Moonjung Eo, K
18.[논문 리뷰] TabGLM: Tabular Graph Language Model for Learning Transferable Representations Through Multi-Modal Consistency Minimization
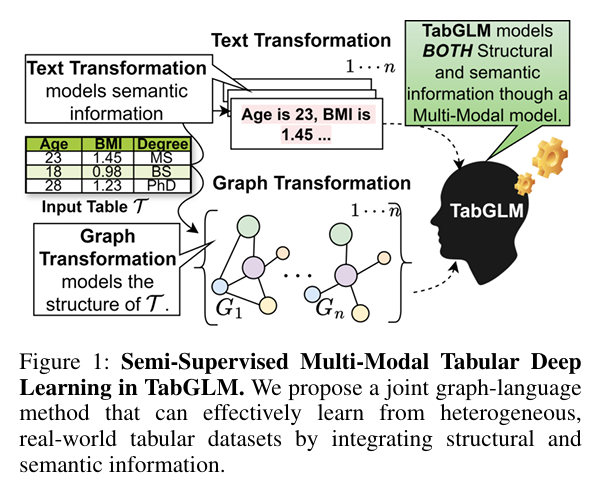
제목: TabGLM: Tabular Graph Language Model for Learning Transferable Representations Through Multi-Modal Consistency Minimization저자: Anay Majee, Maria X
19.[논문 리뷰] MultiTab: A Scalable Foundation for Multitask Learning on Tabular Data
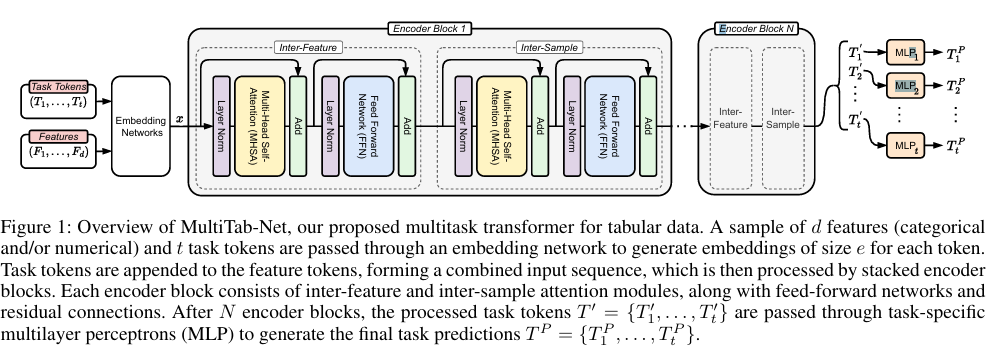
제목: MultiTab: A Scalable Foundation for Multitask Learning on Tabular Data저자: Dimitrios Sinodinos, Jack Yi Wei, Narges Armanfard소속: McGill University,
20.[논문 리뷰] Audio Description Generation in the Era of LLMs and VLMs: A Review of Transferable Generative AI Technologies
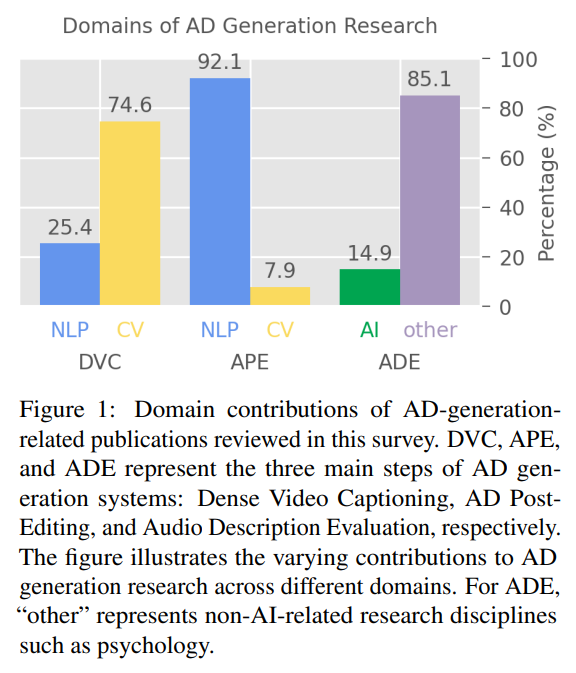
제목: Audio Description Generation in the Era of LLMs and VLMs: A Review of Transferable Generative AI Technologies저자: Yingqiang Gao, Lukas Fischer, Ale
21.[논문 리뷰] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
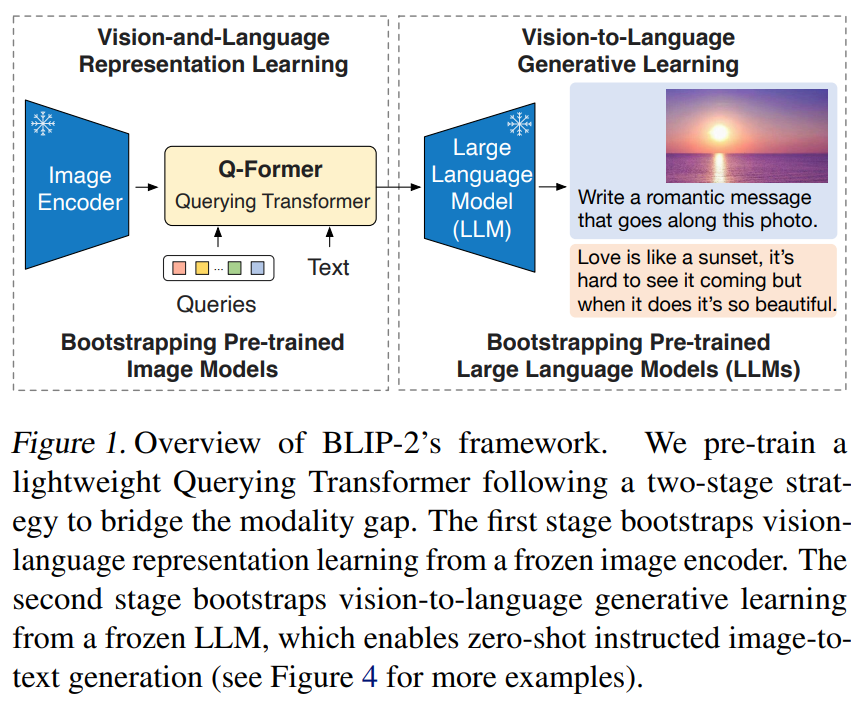
제목: BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models저자: Junnan Li, Dongxu Li, Silvio Savarese, S
22.[논문 리뷰] DANTE-AD: Dual-Vision Attention Network for Long-Term Audio Description
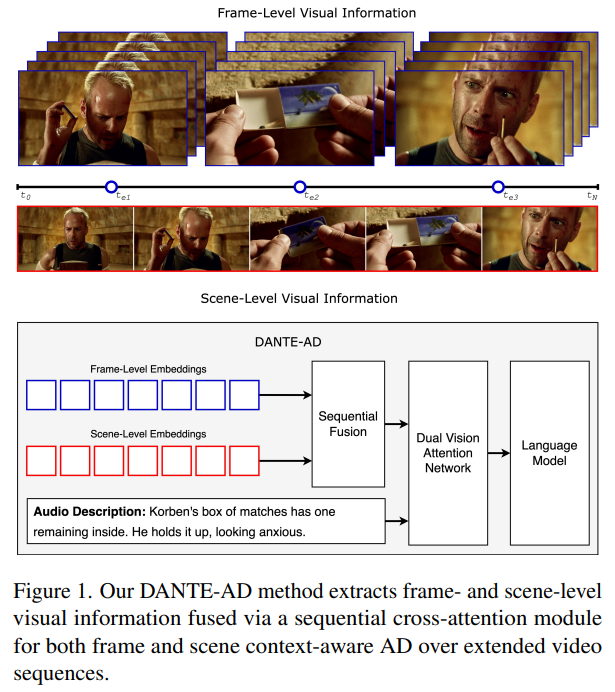
제목: DANTE-AD: Dual-Vision Attention Network for Long-Term Audio Description 저자: Adrienne Deganutti, Simon Hadfield, Andrew Gilbert 소속: University of S
23.[논문 리뷰] MMAD: Multi-modal Movie Audio Description
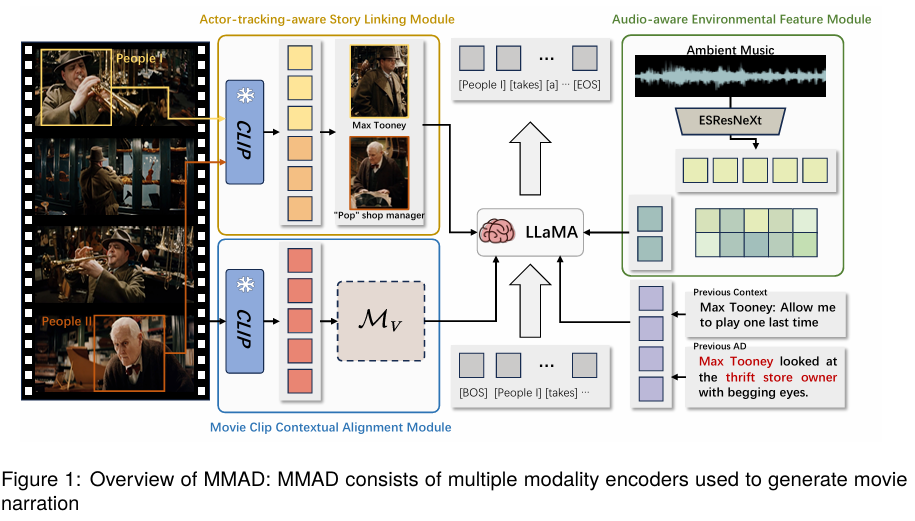
제목: MMAD: Multi-modal Movie Audio Description저자: Xiaojun Ye, Junhao Chen, Xiang Li, Haidong Xin, Chao Li, Sheng Zhou, Jiajun Bu 학회: Proceedings of the
24.[논문 리뷰] Qianfan-VL: Domain-Enhanced Universal Vision-Language Models
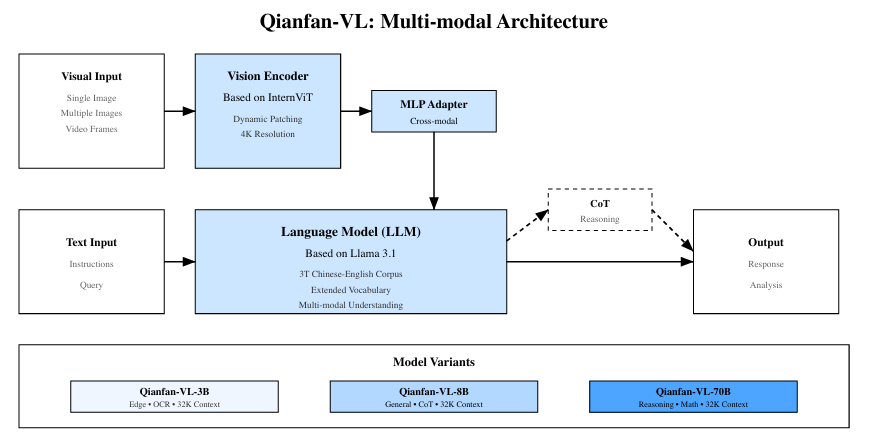
제목: Qianfan-VL: Domain-Enhanced Universal Vision-Language Models저자: Daxiang Dong 외 다수 (Baidu AI Cloud / Qianfan 팀)제출: 2025년 9월 (arXiv preprint)분야: Vis
25.[논문 리뷰] ERNIE4.5 Technical Report

제목: ERNIE 4.5 Technical Report저자: Baidu ERNIE Team형식: 기술 보고서 / 모델 기술 리포트발행: 2025 (ERNIE 공식 블로그 공개)ERNIE 4.5는 Baidu가 발표한 차세대 대규모 언어 및 멀티모달 모델 계열로, 이 기술
26.[논문 리뷰] An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale
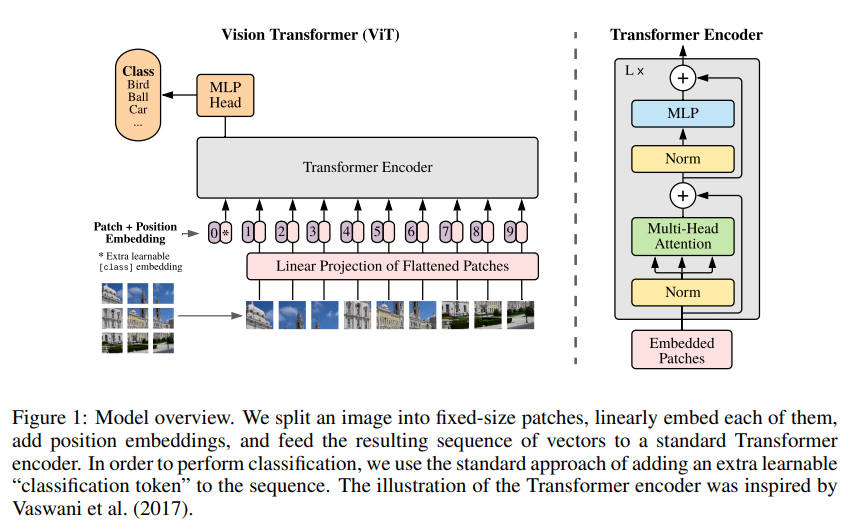
제목: An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale저자: Alexey Dosovitskiy et al. (Google Research)형식: 학술 논문 (ICLR 2021)발행:
27.[논문 리뷰] Learning Transferable Visual Models From Natural Language Supervision
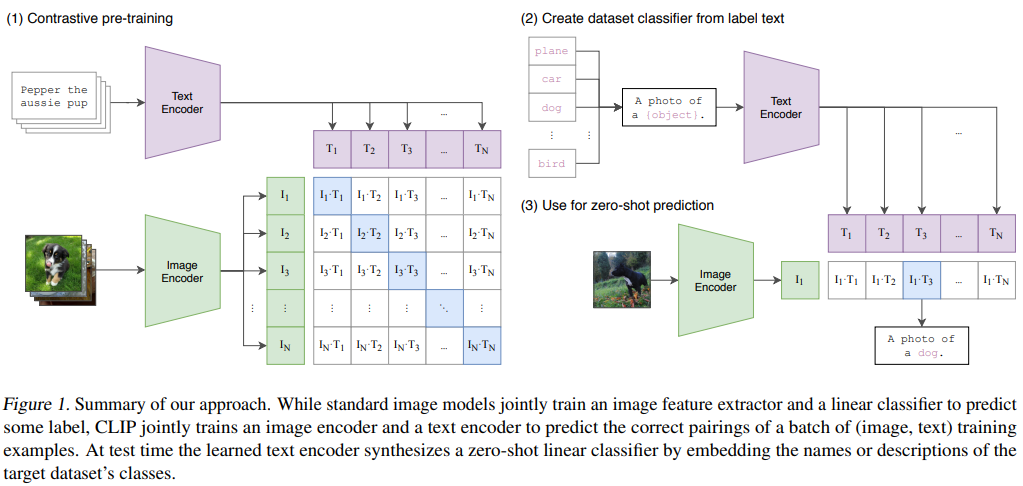
제목: Learning Transferable Visual Models From Natural Language Supervision저자: Alec Radford et al. (OpenAI)형식: 학술 논문발행: 2021 (ICML)CLIP은 이미지와 자연어를 동일한 임
28.[논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
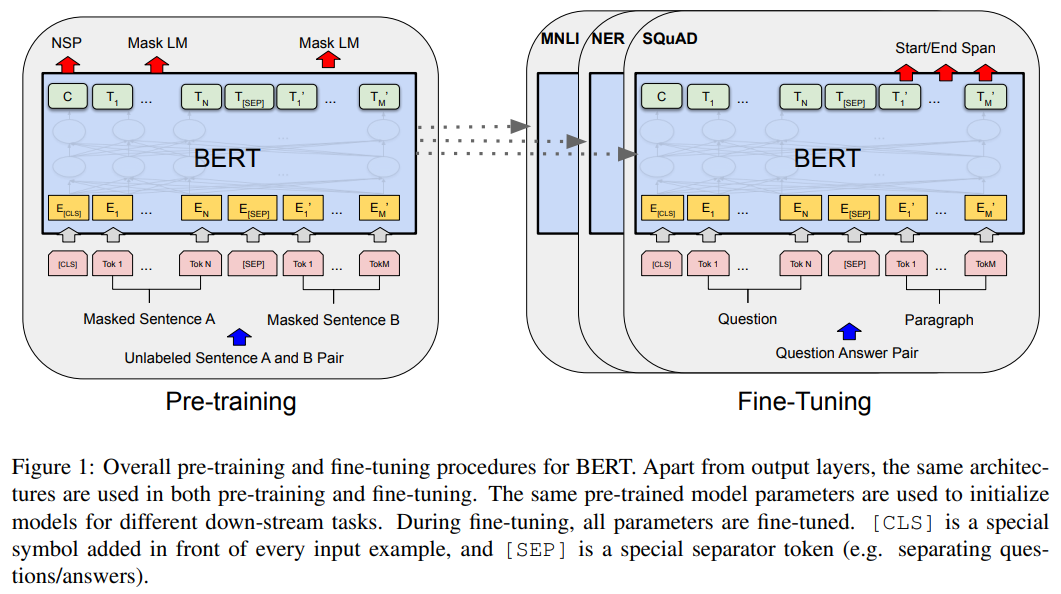
제목: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding저자: Jacob Devlin et al. (Google AI Language)형식: 학술 논문 (NAACL 2019)
29.[논문 리뷰] Visual Instruction Tuning
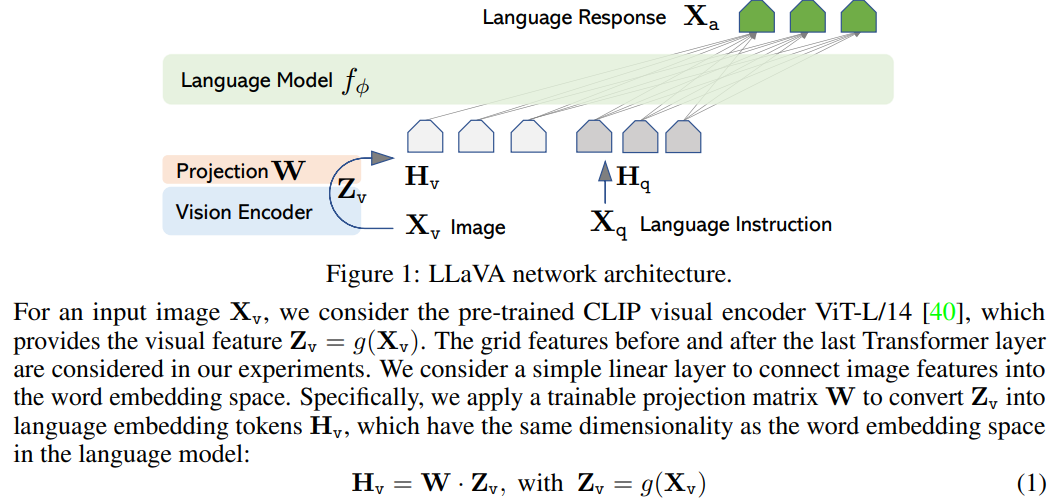
제목: Visual Instruction Tuning저자: Haotian Liu et al. (UW–Madison, Microsoft Research)형식: 학술 논문 (NeurIPS 2023)발행: 2023 (arXiv)LLaVA는 이미지 인코더가 생성한 시각적 표현
30.[논문 리뷰] V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs
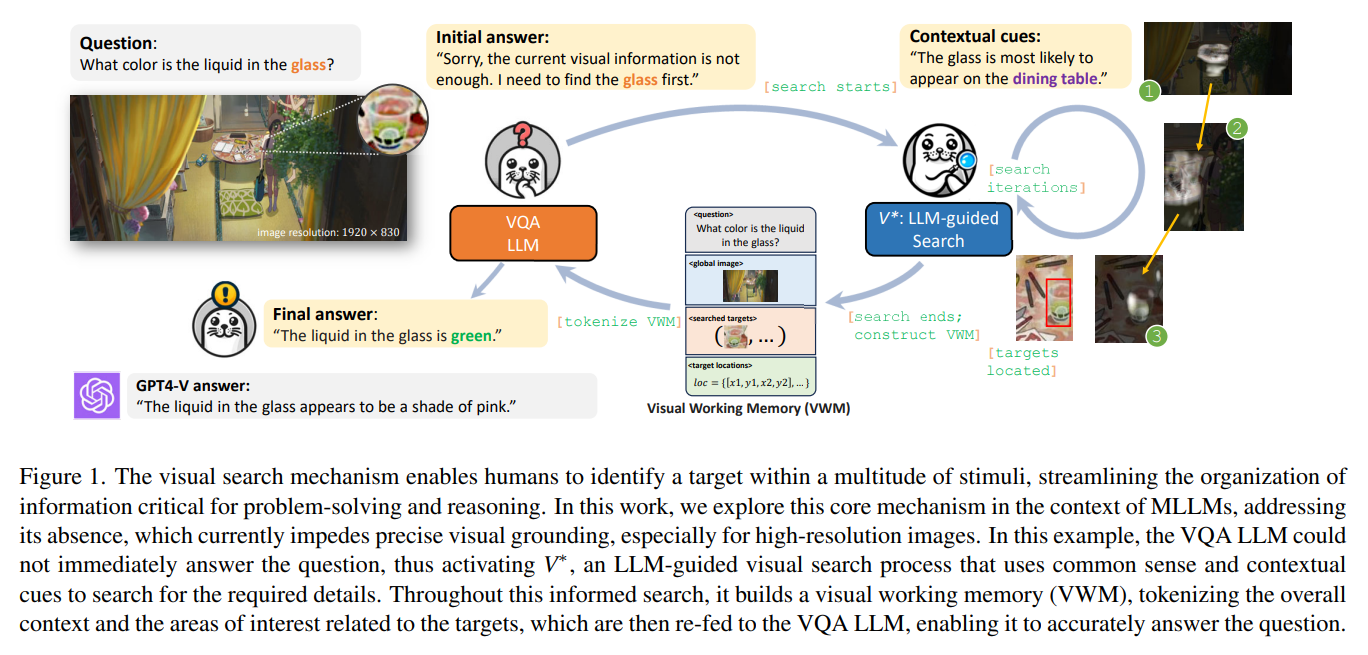
최근 멀티모달 대형 언어 모델(MLLM)은 이미지 기반 질의응답(VQA), 설명 생성, 시각적 추론 등에서 뛰어난 성능을 보이고 있다. 그러나 대부분의 구조는 다음과 같은 한계를 가진다.단일 패스의 비전 인코더에 의존고해상도 이미지에서 세부 정보 손실질문에 따라 필요한
31.[논문 리뷰] Efficient Semantic Uncertainty Quantification in Language Models via Diversity-Steered Sampling

자유 생성(Free-form Generation) 환경에서 LLM의 예측 불확실성(uncertainty) 을 정량화하는 문제를 다룬다.QA와 같은 태스크에서는 단순 토큰 확률 기반 entropy가 의미적 중복 때문에 왜곡된다.불확실성은 다음 두 항으로 분해된다:Alea
32.[논문 리뷰] ARC Is a Vision Problem!
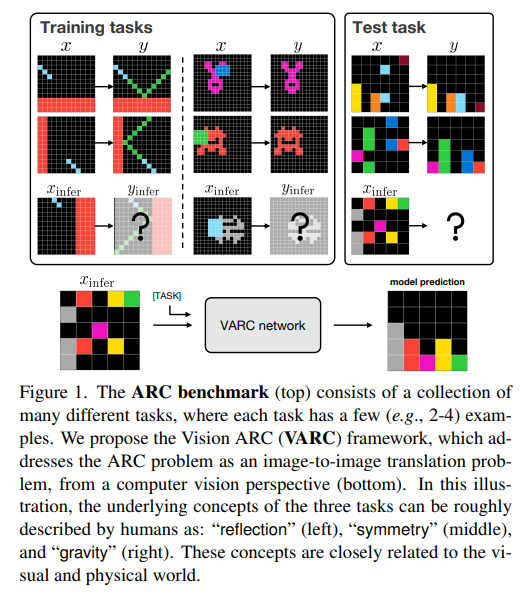
ARC 작업은 소수의 입력-출력 예시만 주어지고, 테스트 입력에 대해 정답 출력 이미지를 생성해야 하는 추상적 패턴 추론 문제다. 각 작업은 환경/패턴 인식, 공간 관계 파악, 색 및 객체 분류 등 시각적 추론 요소를 포함한다.기존 연구는 LLM 중심 또는 순차적 추
33.[논문 리뷰] Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail
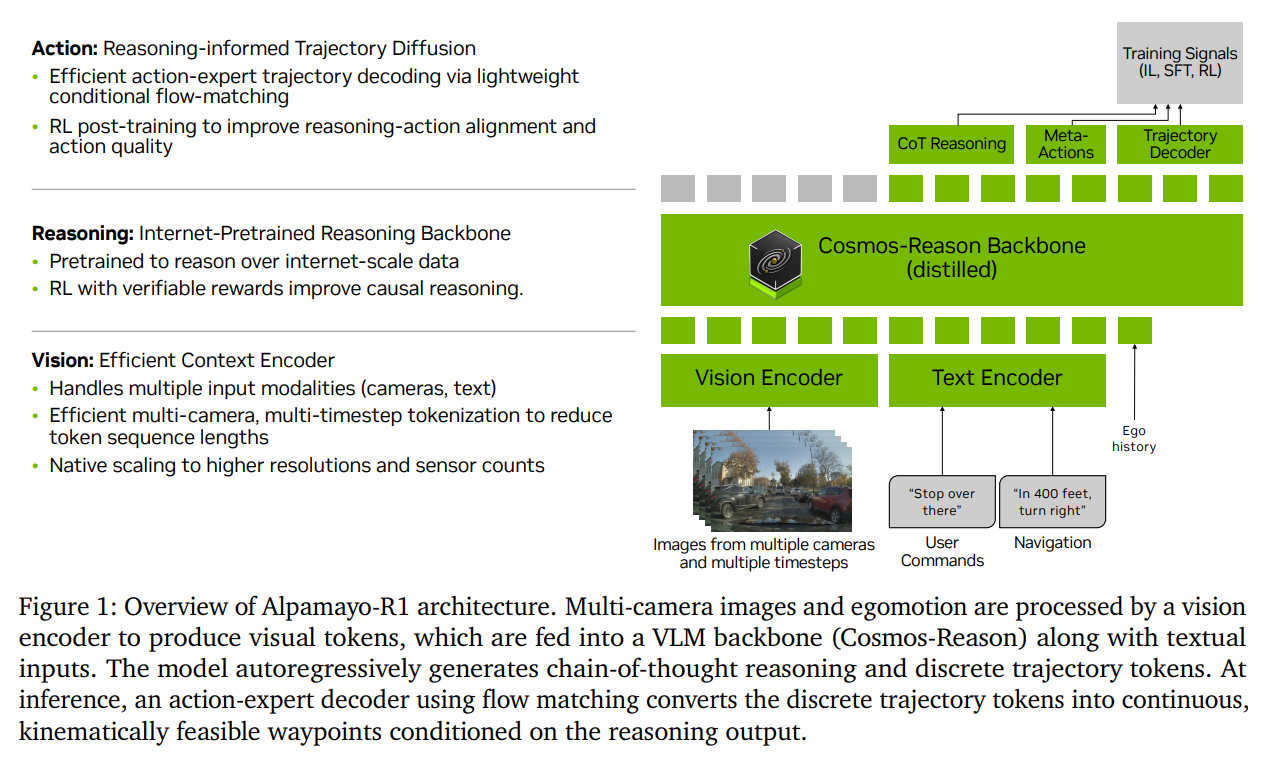
자율주행 모델은 최근까지 주로 “보고 → 바로 운전하기” 방식으로 발전해왔다. 카메라나 센서로 주변 상황을 입력받으면, 그걸 바로 차량의 움직임(trajectory)으로 바꾸는 방식이다. 이런 방법은 데이터가 많을수록 잘 동작하지만, 예상하지 못한 상황에서는 쉽게 무너
34.[논문 리뷰] Adaptive Action Chunking at Inference-time for Vision-Language-Action Models
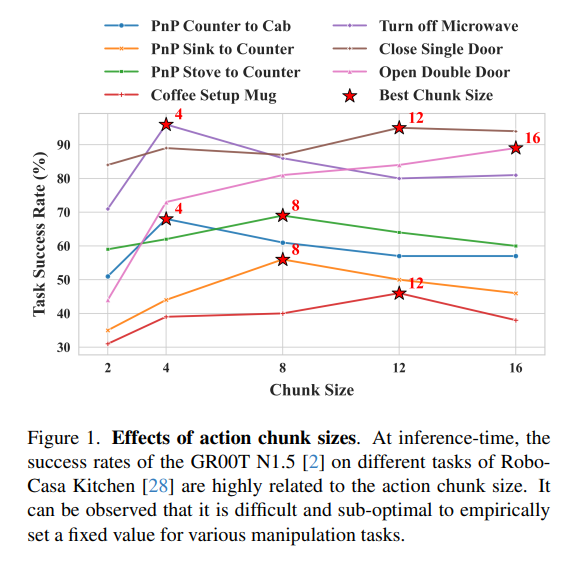
최근 로봇 공학에서는 시각, 언어, 행동 데이터를 하나로 통합하여 처리하는 VLA(Vision-Language-Action) 모델이 핵심 기술로 활용되고 있습니다. 이 모델들이 로봇의 조작 능력을 높이기 위해 기본적으로 채택하는 방식이 액션 청킹(Action Chunk
35.[논문 리뷰] A1: A Fully Transparent Open-Source, Adaptive and Efficient Truncated Vision-Language-Action Model
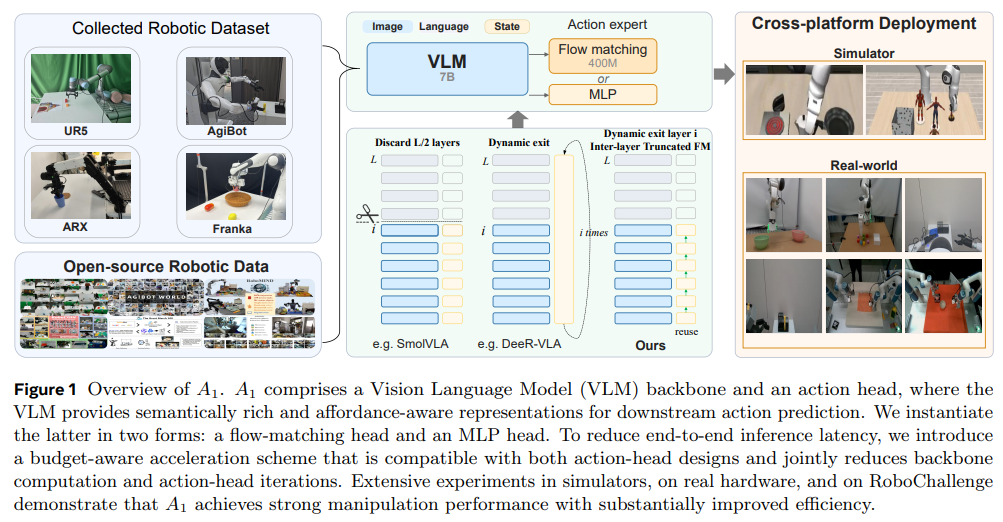
연구가 등장한 배경최근 로봇 공학 분야에서는 복잡한 시각적 환경을 이해하고 정밀한 제어를 수행하기 위해 시각-언어-행동(Vision-Language-Action, VLA) 모델이 핵심 패러다임으로 자리 잡았습니다. 대규모 시각-언어 모델(VLM)을 백본으로 사용하여 다
36.[논문 리뷰] ViVa: A Video-Generative Value Model for Robot Reinforcement Learning
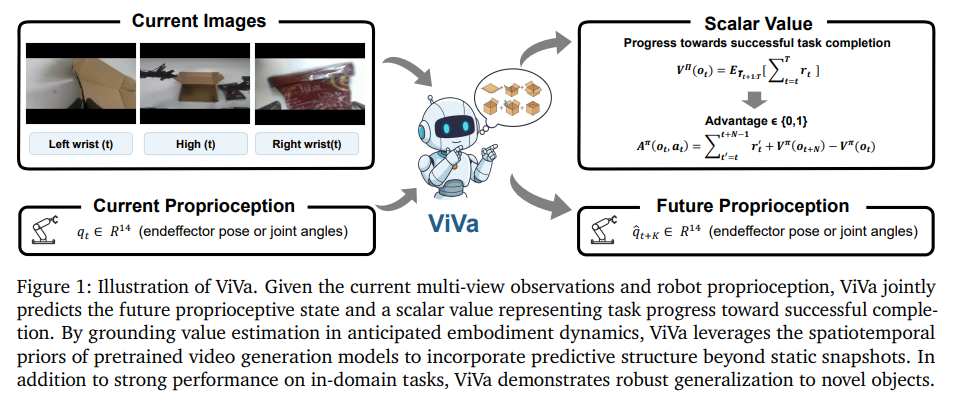
로봇 조작 분야는 대규모 사전 학습을 거친 비전-언어-행동(Vision-Language-Action, VLA) 모델의 등장으로 큰 발전을 이루었습니다. 그러나 실제 환경에서의 로봇 제어는 부분적 관찰성(partial observability)과 지연된 피드백(delay
37.[논문 리뷰] RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE
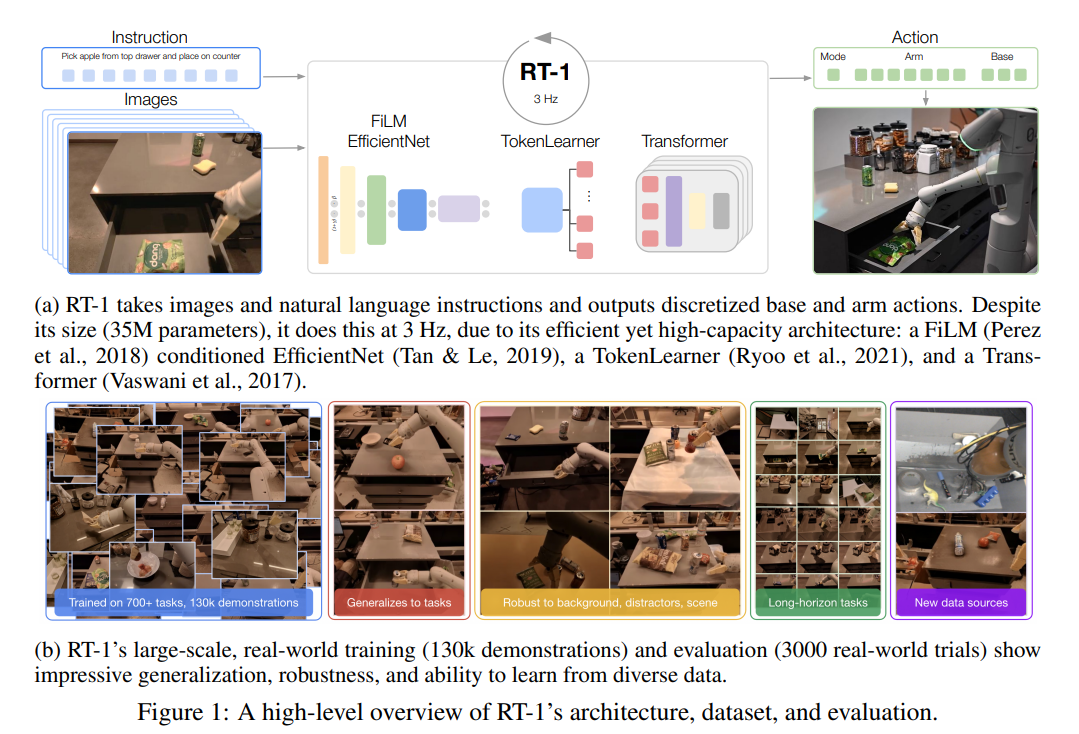
컴퓨터 비전(CV)과 자연어 처리(NLP) 분야는 소규모의 특정 작업 맞춤형 데이터셋에서 벗어나, 방대한 범용 데이터셋으로 사전 학습된 대규모 모델(Large General Models) 패러다임으로 전환하며 눈부신 발전을 이루었습니다. 이러한 모델들은 풍부한 데이터를
38.[논문 리뷰] RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
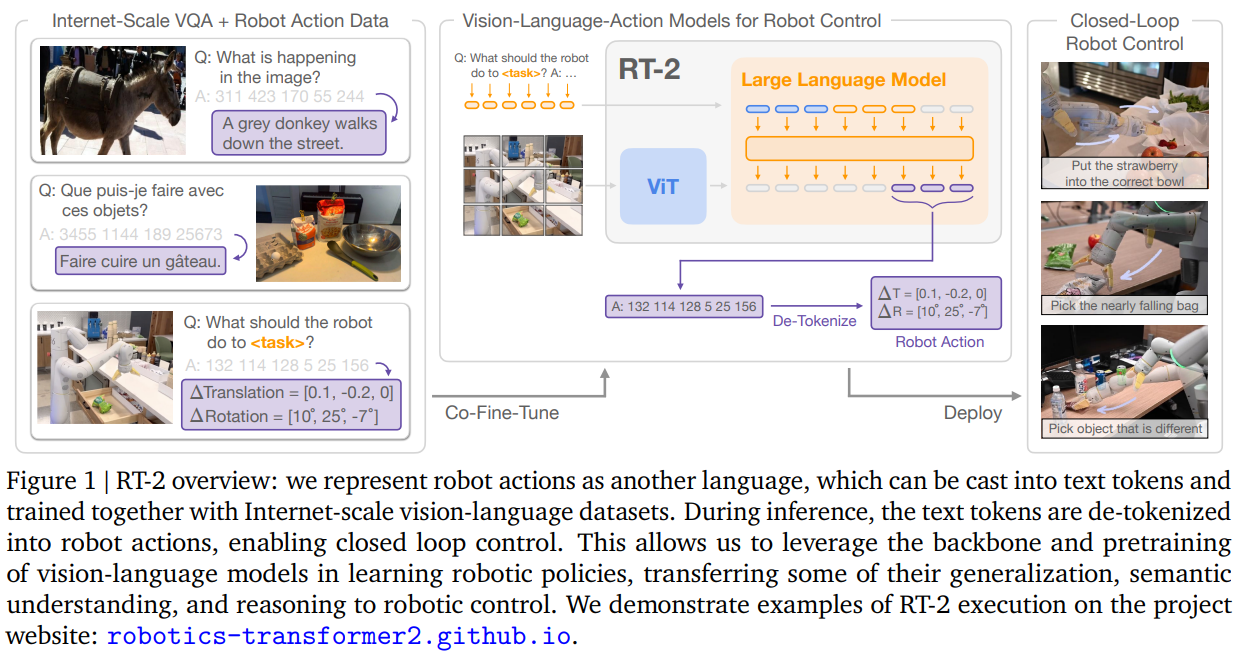
로봇 학습 분야의 오랜 숙제는 일반화(Generalization)입니다. 기존의 로봇 제어 모델들은 특정 환경과 사물에 국한된 데이터를 학습하여, 훈련 데이터에 없는 새로운 사물이나 명령어를 접했을 때 대응 능력이 현저히 떨어졌습니다.기존 방법론: 주로 ImageNet
39.[논문 리뷰] Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
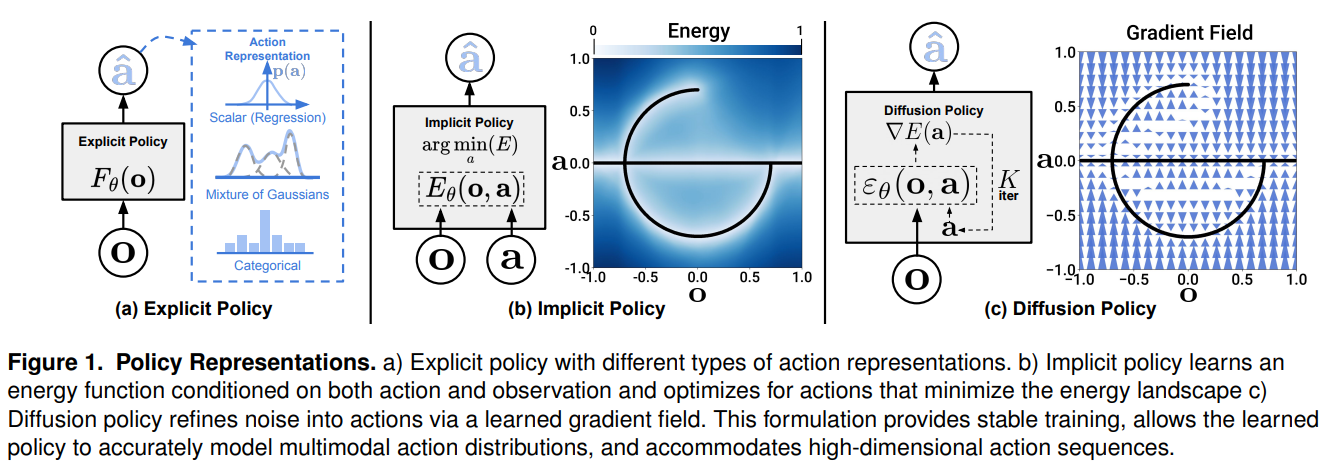
로봇 비전-운동 정책(Visuomotor Policy) 학습은 시각적 관측값을 로봇의 제어 명령으로 변환하는 모방 학습(Imitation Learning)의 핵심 과제입니다. 하지만 로봇 제어 데이터는 인간 시연자의 다양한 의사결정이 섞인 다중 모달리티(Multimod
40.[논문 리뷰] Octo: An Open-Source Generalist Robot Policy
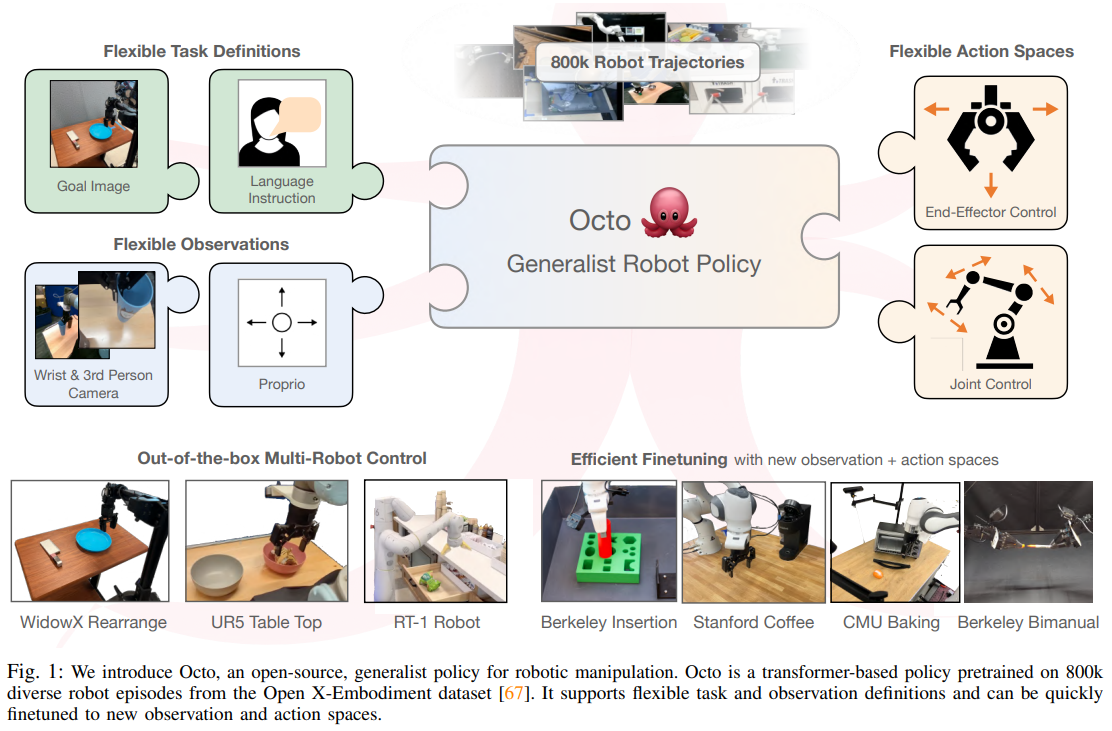
로봇 제어 분야에서는 특정 태스크와 환경에 종속된 정책(Policy)을 밑바닥부터 학습시키는 방식이 주를 이루었습니다. 그러나 최근 대규모 로봇 궤적 데이터를 활용하여 사전 학습(Pre-training)된 범용 로봇 정책(Generalist Robot Policies,
41.[논문 리뷰] OpenVLA: An Open-Source Vision-Language-Action Model
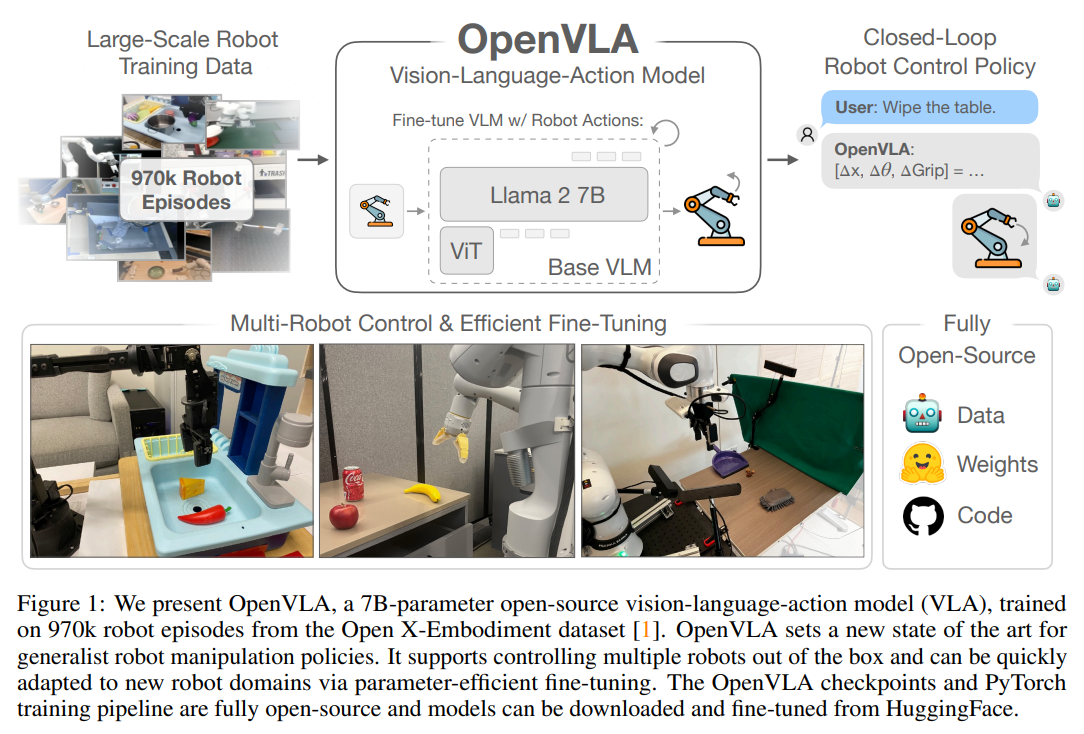
로봇 공학에서 학습 기반 제어 정책(Learned Policies)의 가장 큰 약점은 학습 데이터의 범위를 벗어난 환경(새로운 객체, 조명, 지시어 등)에 대한 일반화(Generalization) 능력이 부족하다는 점입니다. 반면, 인터넷 규모의 데이터로 사전 학습된
42.[논문 리뷰] Green-VLA: Staged Vision-Language-Action Model for Generalist Robots
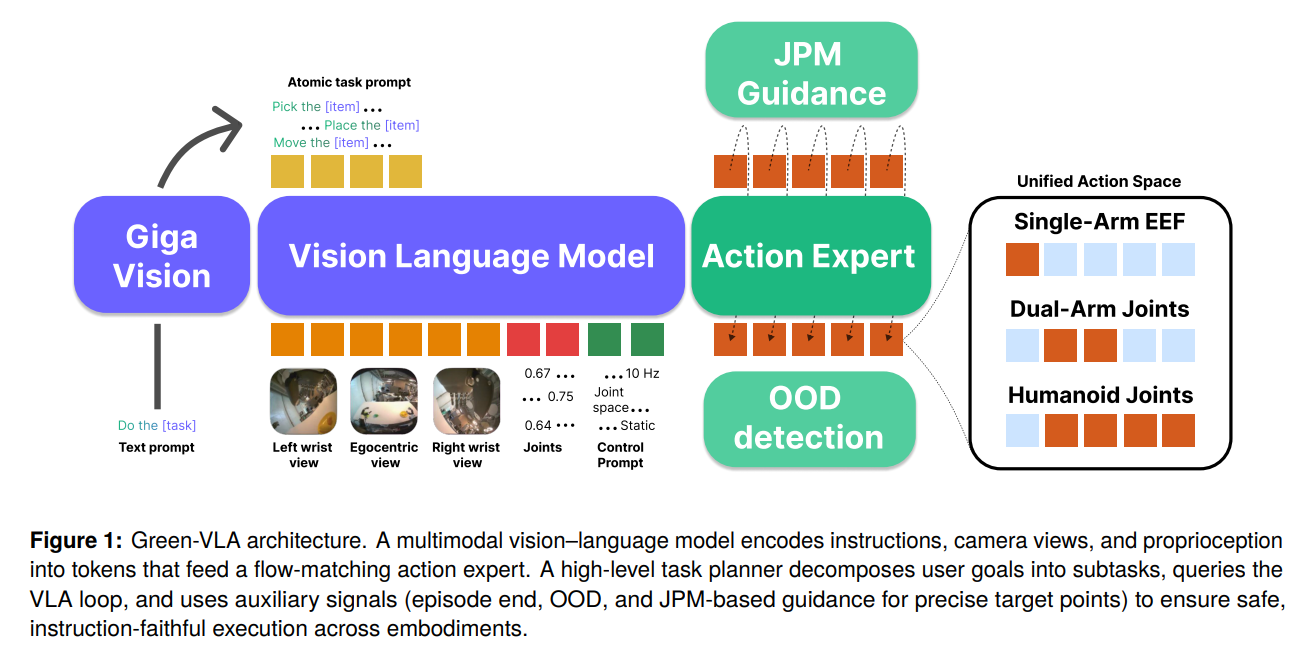
본 논문은 이기종 로봇(휴머노이드, 매니퓰레이터 등)을 하나의 통합된 행동 공간(Unified Action Space)으로 제어하기 위해 5단계(L0~R2) 커리큘럼 학습을 제안한 범용 VLA 프레임워크(Green-VLA)입니다.기술적으로는 단순 패딩(Padding)을
43.[논문 리뷰] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model

본 논문은 대규모 시각-언어 모델(VLM)과 막대한 사전 학습에 의존하는 기존 VLA(Vision-Language-Action) 모델의 한계를 극복하기 위해, 0.5B 수준의 극도로 작은 백본만으로 시각-언어 공간을 행동 공간으로 효과적으로 연결하는 'VLA-Adapt
44.[논문 리뷰] OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
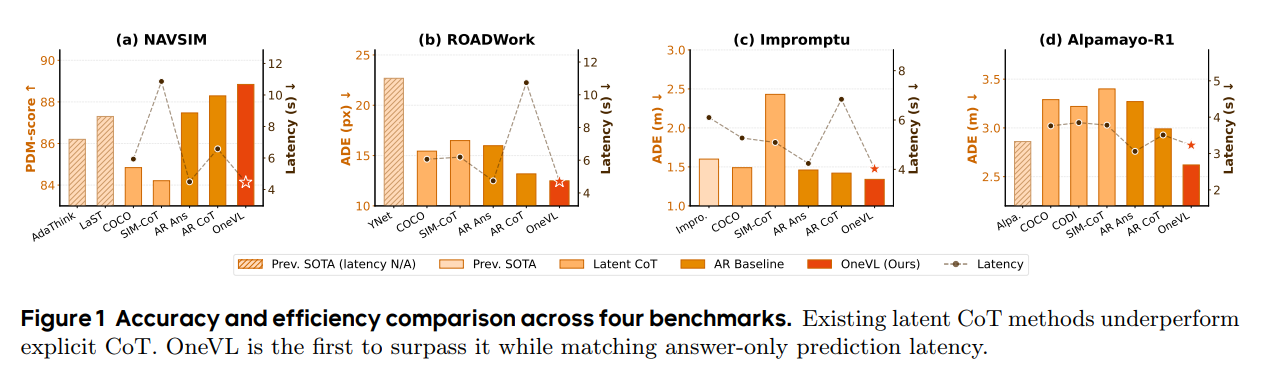
본 논문은 자율주행의 궤적 예측 시 자율회귀(Autoregressive) 기반 Chain-of-Thought(CoT)가 유발하는 막대한 추론 지연 시간 문제를 해결하기 위해, 잠재 공간(Latent space) 내에서 단일 단계로 추론과 계획을 수행하는 'OneVL'
45.[논문 리뷰] LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
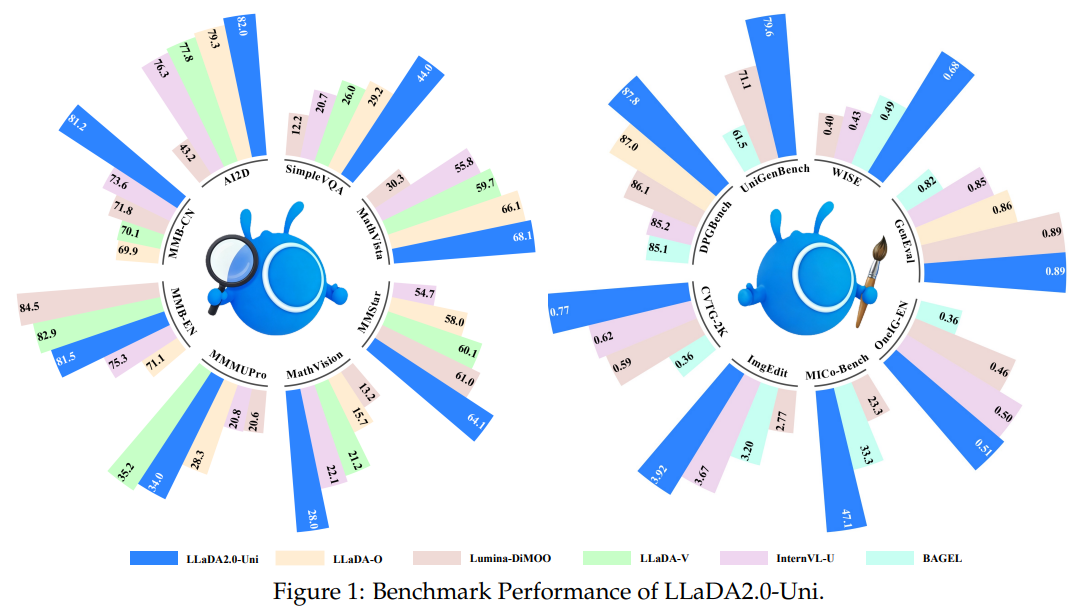
본 논문은 다중 양상(Multimodal)의 이해와 생성을 하나의 통합된 프레임워크에서 처리하기 위해, 완전히 이산화된 의미론적 토크나이저와 확산 대형 언어 모델(dLLM)을 결합한 'LLaDA2.0-Uni'를 제안합니다.기존의 픽셀 재구성 기반 VQ-VAE 대신 Si
46.[논문 리뷰] DiPO: Disentangled Perplexity Policy Optimization for Fine-grained Exploration-Exploitation Trade-Off
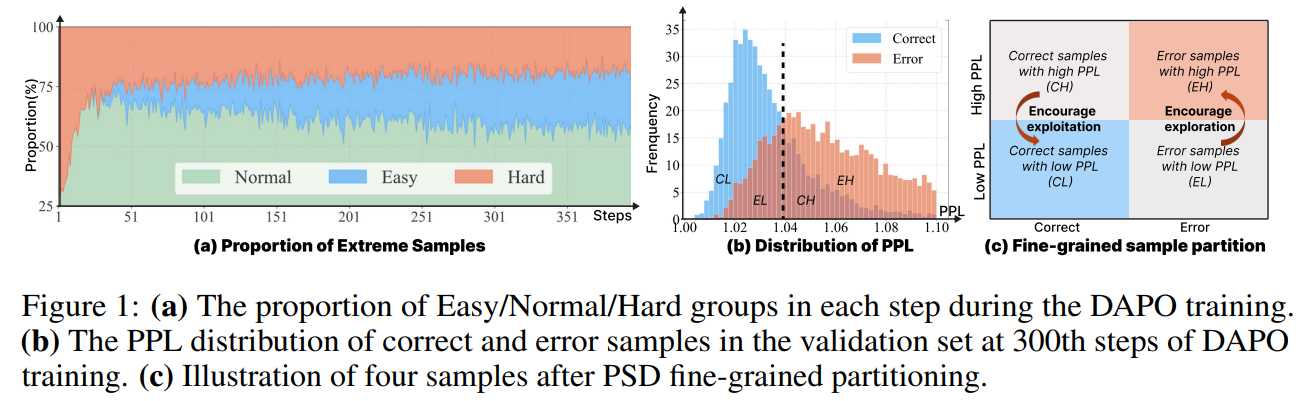
본 논문은 대형 언어 모델(LLM)의 강화학습 과정에서 발생하는 극단적 샘플(전체 정답 또는 전체 오답)의 기울기 소실 및 비효율적 탐색-활용 딜레마를 해결하기 위한 DiPO(Disentangled Perplexity Policy Optimization)를 제안한다.퍼
47.[논문 리뷰] Near-Future Policy Optimization
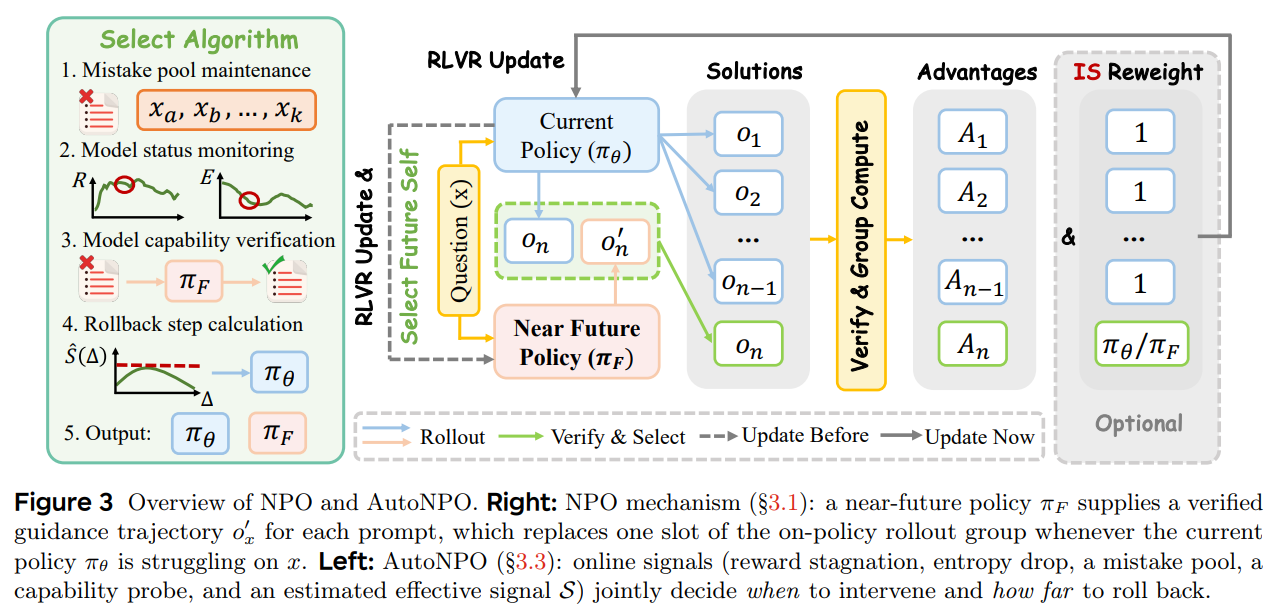
본 논문은 강화학습(RLVR) 기반의 언어 모델 튜닝에서, 현재 정책보다 조금 앞선 '가까운 미래(Near-Future)' 체크포인트가 생성한 정답 궤적을 활용하여 학습을 최적화하는 NPO(Near-Future Policy Optimization)를 제안한다.외부 교사
48.[논문 리뷰] PersonaVLM: Long-Term Personalized Multimodal LLMs
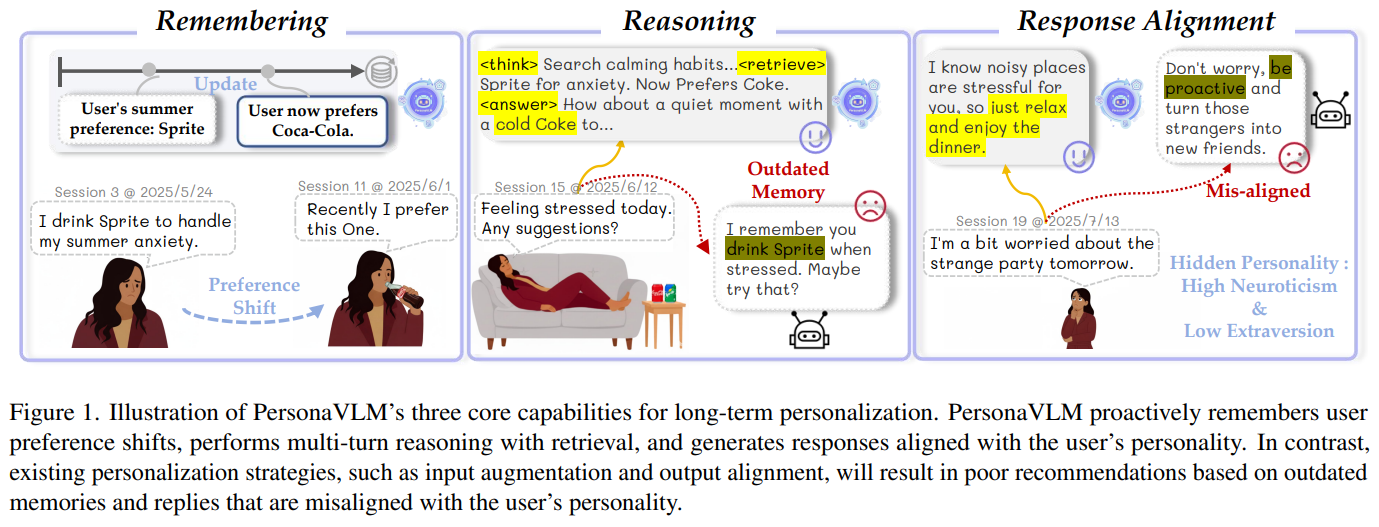
본 논문은 멀티모달 대형 언어 모델(MLLM)이 사용자의 진화하는 선호도와 성격을 장기적으로 학습하고 유지하지 못하는 문제를 해결하기 위해 PersonaVLM 프레임워크를 제안함.기억(Memory), 추론(Reasoning), 응답 정렬(Response Alignmen
49.[논문 리뷰] Long-Horizon Manipulation via Trace-Conditioned VLA Planning
목적 및 제안 방법: 긴 시계열(Long-horizon) 로봇 조작의 복잡성을 해결하기 위해 고수준의 작업 관리자(VLM)와 저수준의 실행기(VLA)를 분리하고, 2D 시각적 궤적(Trace)을 매개체로 연결하는 LoHo-Manip 프레임워크를 제안함.기술적 차별성:
50.[논문 리뷰] CodeGraphVLP: Code-as-Planner Meets Semantic-Graph State for Non-Markovian Vision-Language-Action Models
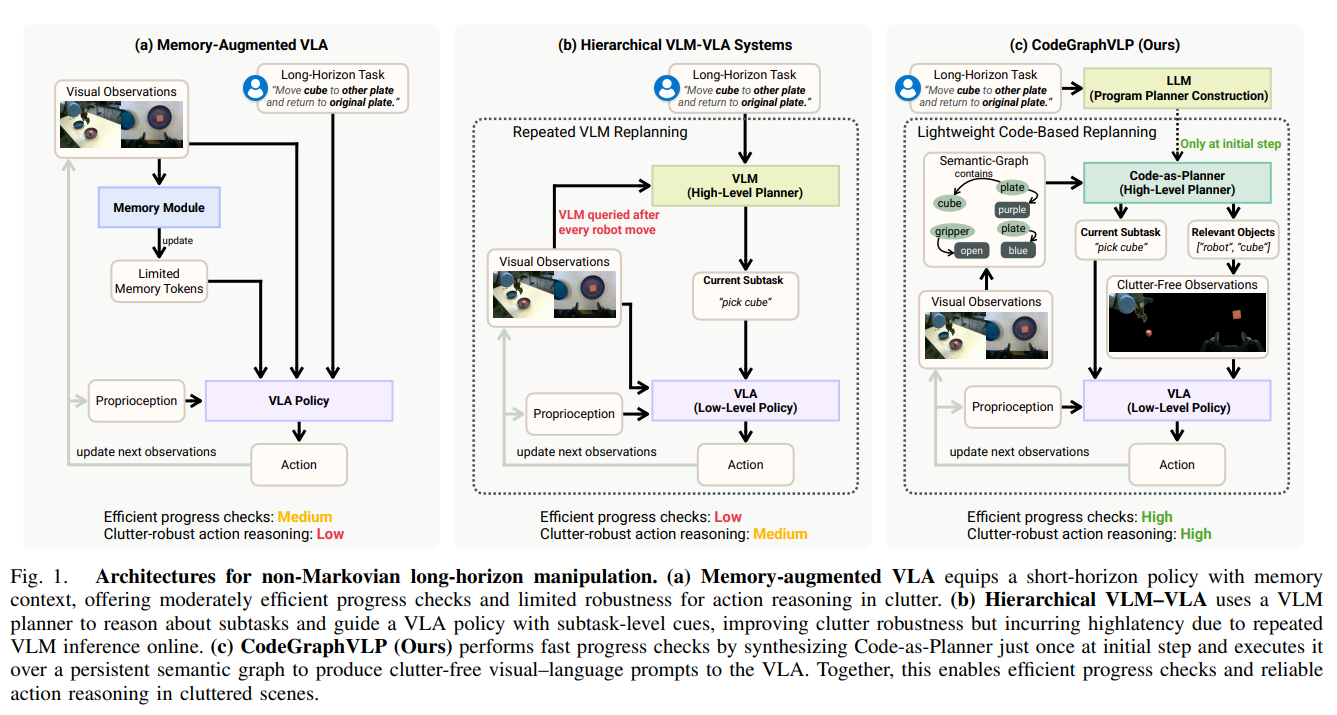
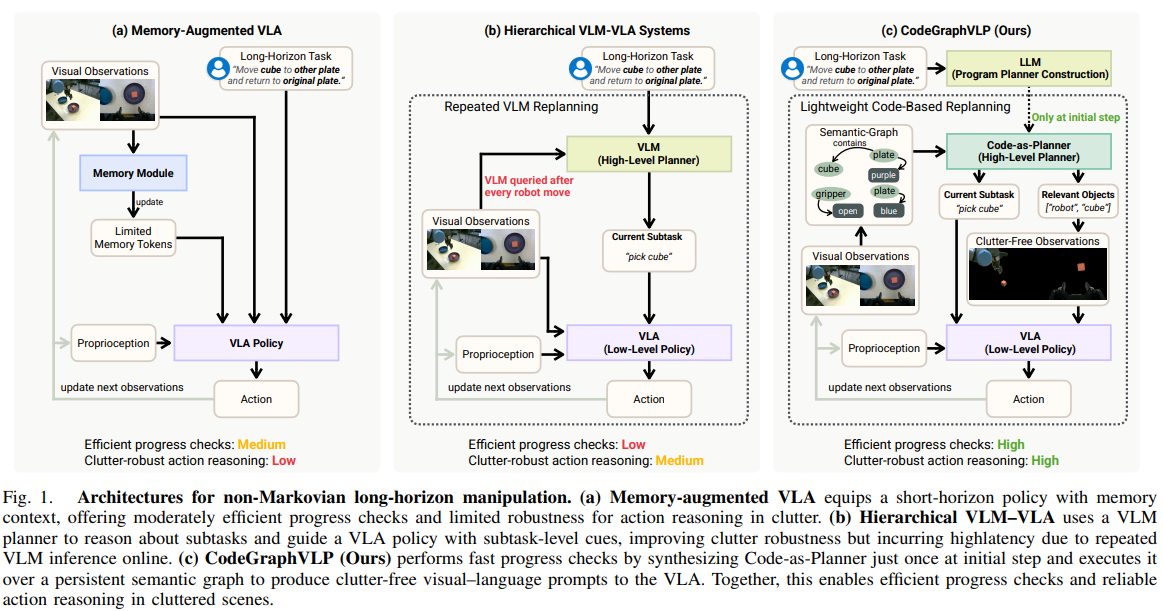
본 논문은 비마르코프(Non-Markovian) 환경의 장기(Long-horizon) 로봇 조작 한계를 극복하기 위해, 지속적인 '의미론적 그래프(Semantic-Graph)' 상태와 '코드 기반 계획기(Code-as-Planner)'를 결합한 CodeGraphVLP
51.[논문 리뷰] VLA-RFT: VISION-LANGUAGE-ACTION REINFORCEMENT FINE-TUNING WITH VERIFIED REWARDS IN WORLD SIMULATORS
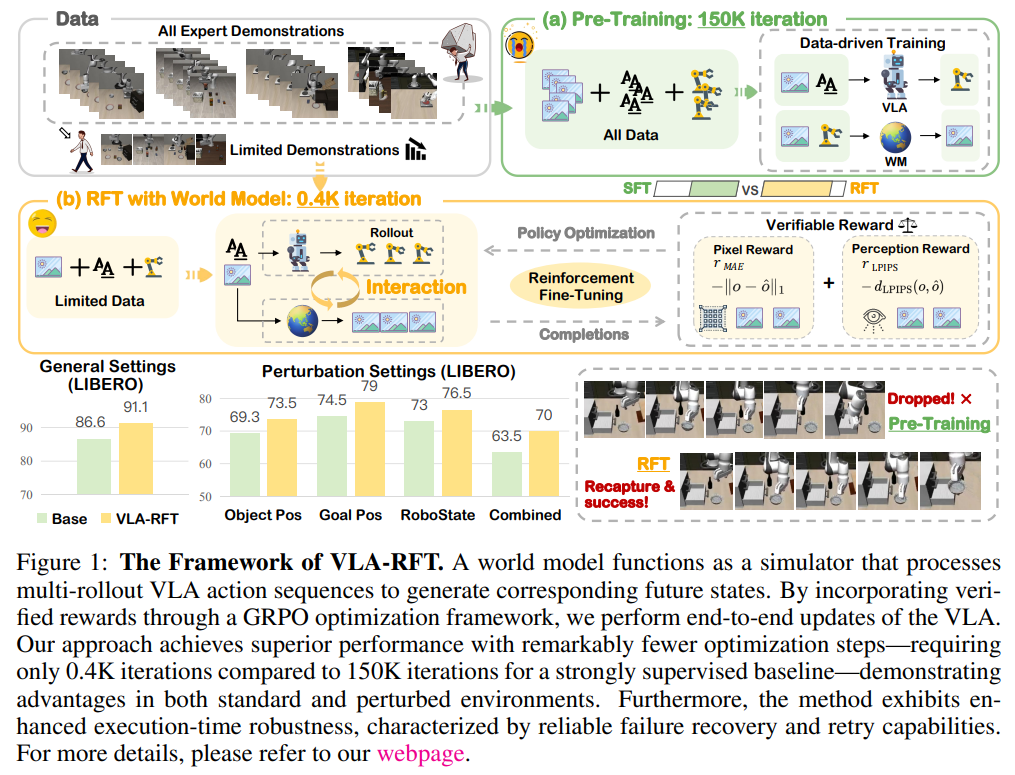
본 논문은 Vision-Language-Action(VLA) 모델의 모방 학습(Imitation Learning)이 지닌 한계를 극복하기 위해, 데이터 기반의 세계 모델(World Model)을 시뮬레이터로 활용하는 강화 미세조정(Reinforcement Fine-Tu
52.[논문 리뷰] SPATIAL FORCING: IMPLICIT SPATIAL REPRESENTATION ALIGNMENT FOR VISION-LANGUAGE-ACTION MODEL
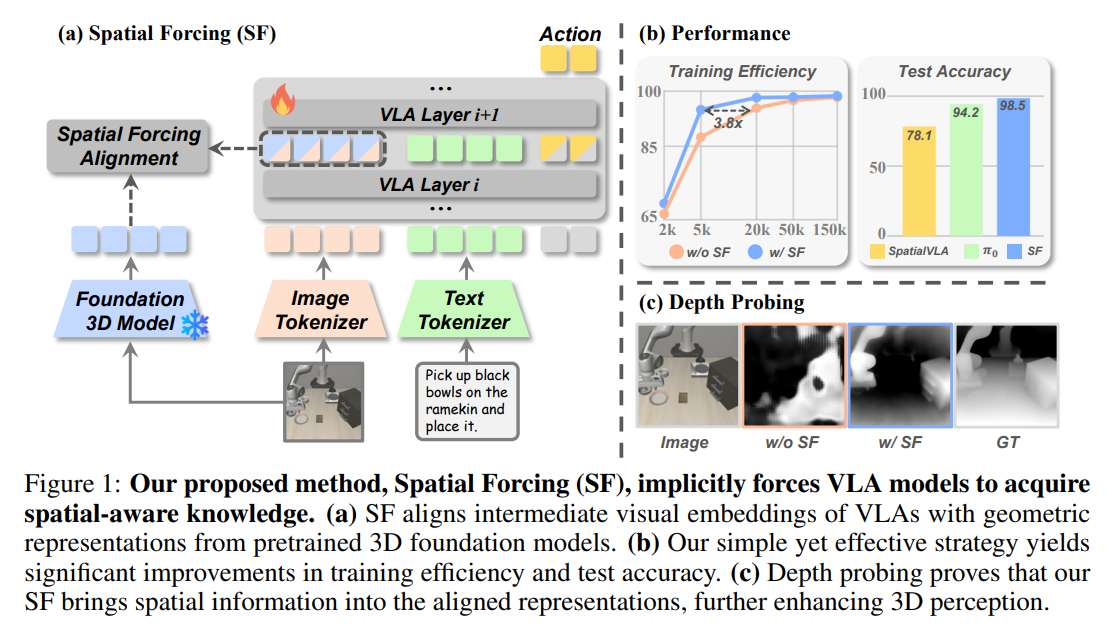
기본 정보: 본 논문은 "Spatial Forcing: Implicit Spatial Representation Alignment for Vision-Language-Action Model" (Fuhao Li 외, 2025년 10월)으로, 2D 시각 정보에 국한된 VL
53.[논문 리뷰] NATURE-INSPIRED POPULATION-BASED EVOLUTION OF LARGE LANGUAGE MODELS
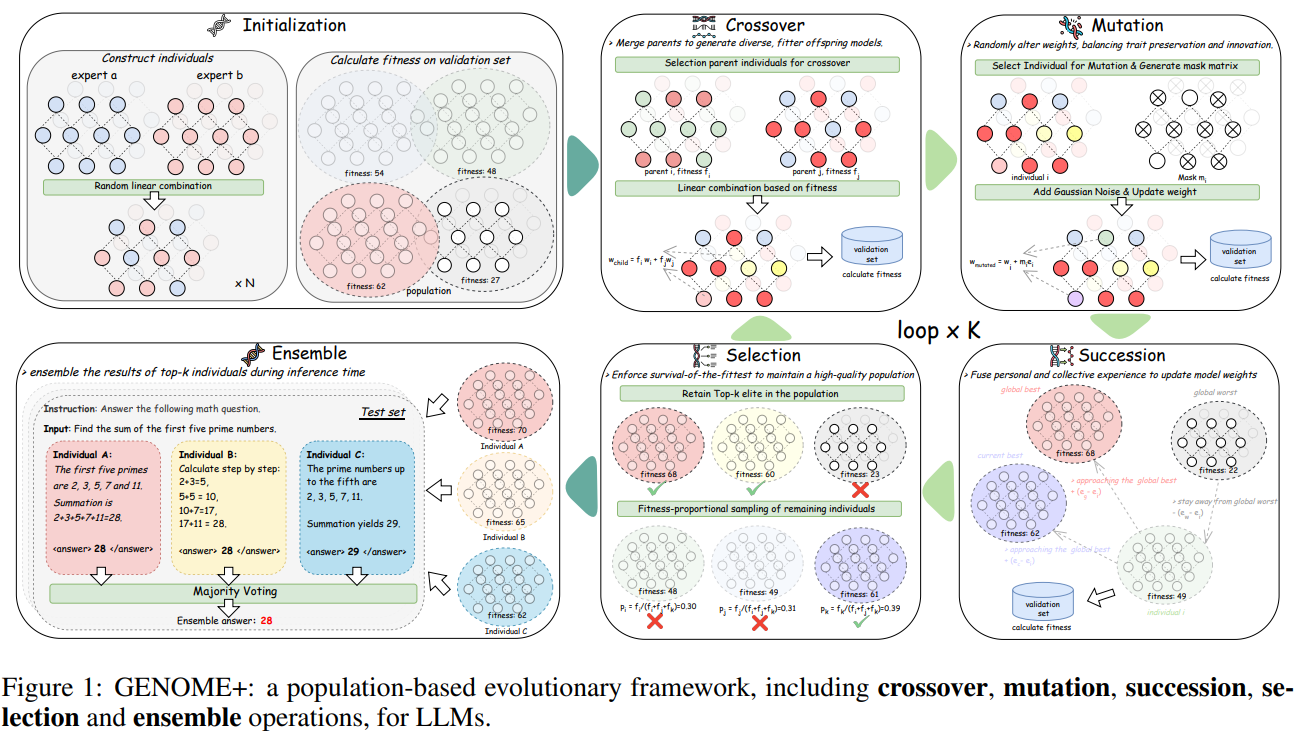
기본 정보: 본 논문은 "NATURE-INSPIRED POPULATION-BASED EVOLUTION OF LARGE LANGUAGE MODELS"라는 제목으로 Yiqun Zhang 등(Northeastern University, Shanghai AI Lab)이 202
54.[논문 리뷰] THE LOTTERY TICKET HYPOTHESIS: FINDING SPARSE, TRAINABLE NEURAL NETWORKS
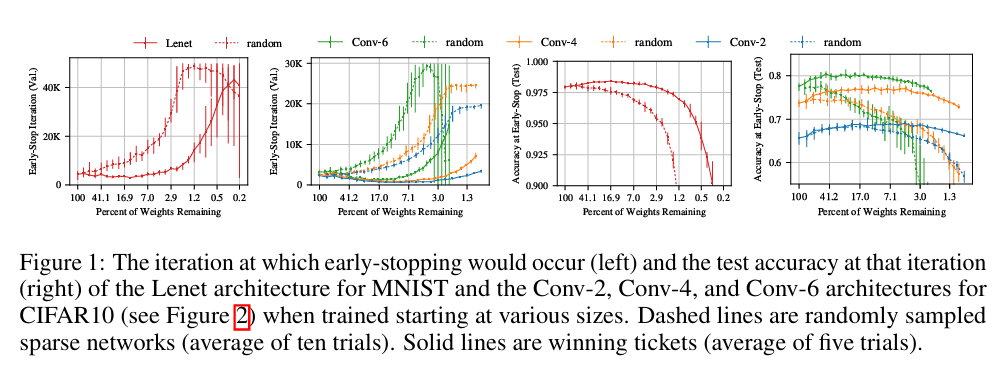
기본 정보: ICLR 2019에서 발표된 Jonathan Frankle과 Michael Carbin(MIT CSAIL)의 논문 "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks"입니다.목
55.[논문 리뷰] What Do Vision Transformers Learn? A Visual Exploration
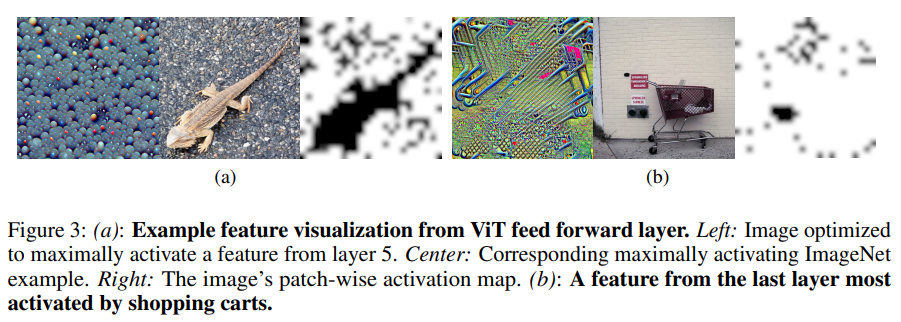
논문 정보: What Do Vision Transformers Learn? A Visual Exploration은 Amin Ghiasi, Hamid Kazemi, Eitan Borgnia, Steven Reich, Manli Shu, Micah Goldblum, And
56.[논문 리뷰] Vision Transformer Visualization: What Neurons Tell and How Neurons Behave?
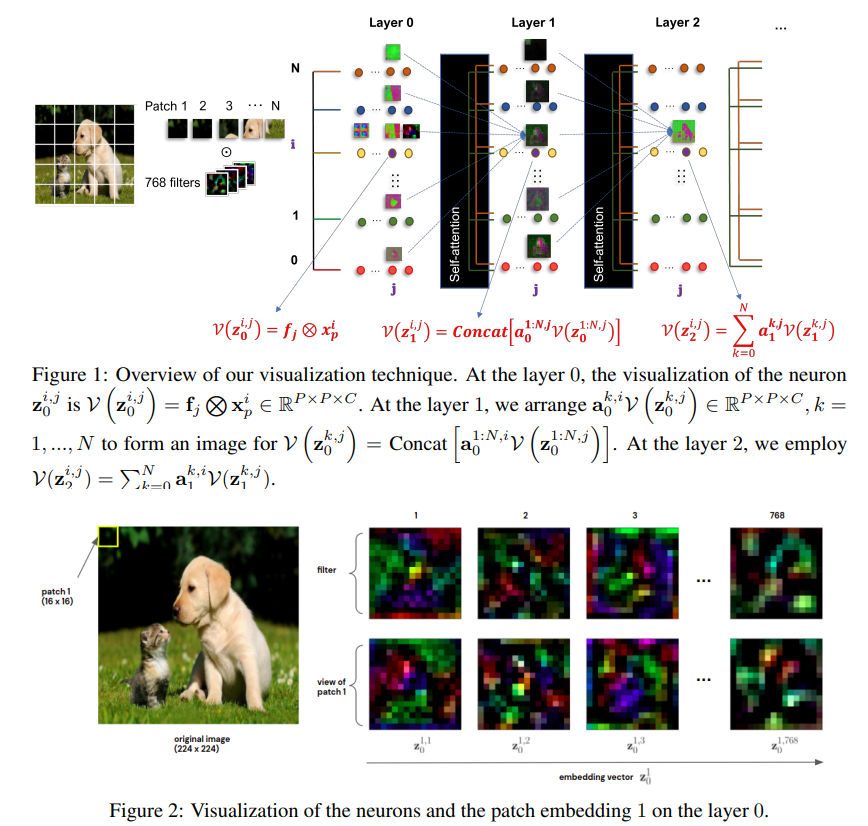
논문 기본 정보: 본 리뷰는 Van-Anh Nguyen 등이 2022년 작성한 "Vision Transformer Visualization: What Neurons Tell and How Neurons Behave?" 논문을 다루며, 비전 트랜스포머(ViT)의 특징 임
57.[논문 리뷰] Attention and Beyond: Explainability Techniques for Vision Transformers
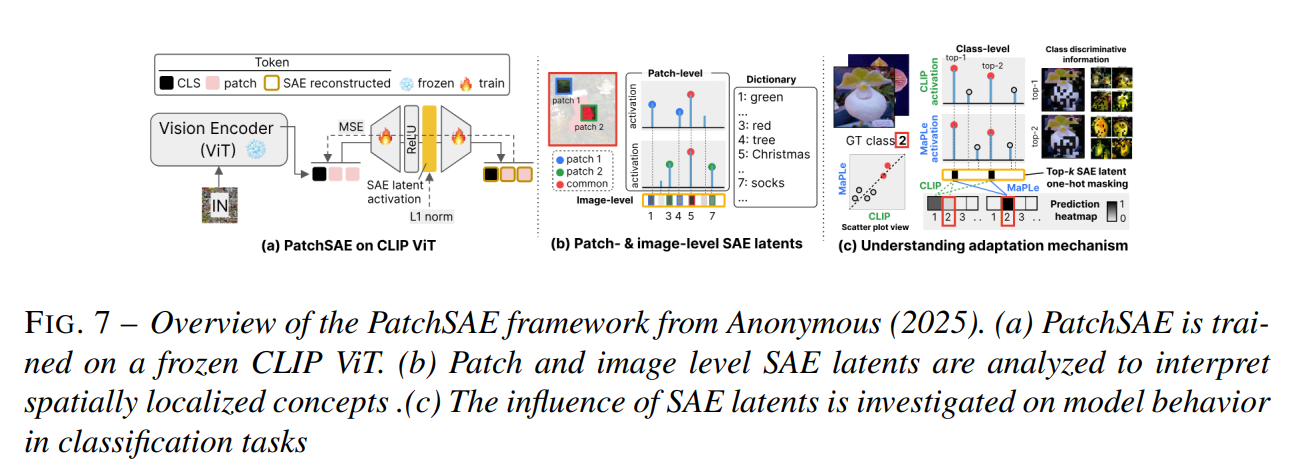
논문 정보: "Attention and Beyond: Explainability Techniques for Vision Transformers" (주저자: Wadie El Amrani, 발표 연도: 2024/2025년 추정, 소속: Made In Tracker 및 UT
58.[논문 리뷰] DASViT: Differentiable Architecture Search for Vision Transformer
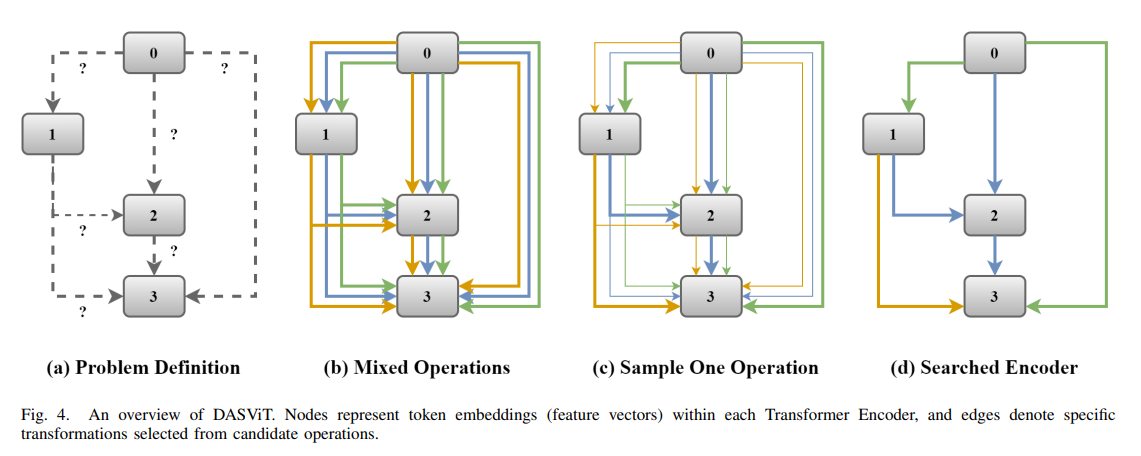
기본 정보 및 핵심 목적: 영국 Surrey 대학교의 Pengjin Wu, Ferrante Neri 및 중국 강남 대학교의 Zhenhua Feng 연구진이 arXiv를 통해 발표한 본 연구는, 최초로 경사하강법 기반의 미분 가능한 아키텍처 탐색(DARTS) 기법을 Vi
59.[논문 리뷰] AutoFormer: Searching Transformers for Visual Recognition
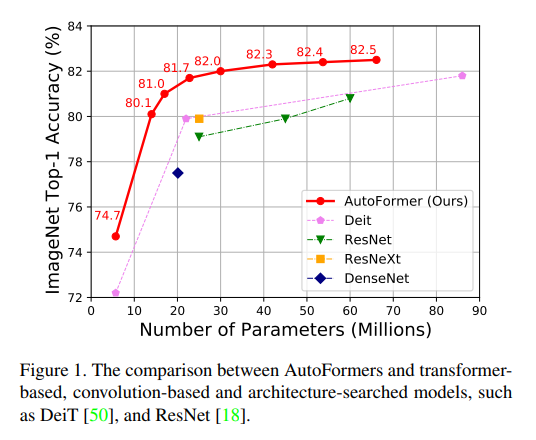
기본 정보: AutoFormer: Searching Transformers for Visual Recognition, Minghao Chen, Houwen Peng, Jianlong Fu, Haibin Ling 저, 2021년 발표 (Stony Brook Univers
60.[논문 리뷰] S3: Searching the Search Space of Vision Transformers
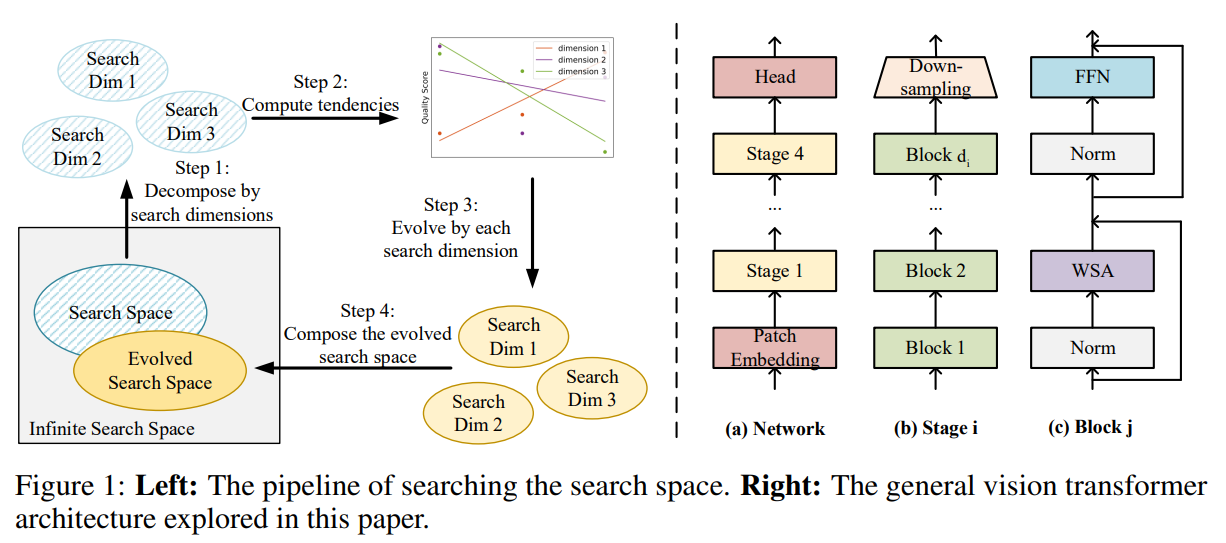
기본 정보: 본 논문의 제목은 "Searching the Search Space of Vision Transformer"이며, Stony Brook University, Sun Yat-sen University, CAS, Microsoft Research Asia 소속