Author: Zixin Zhang, Kanghao Chen, Hanqing Wang, Hongfei Zhang, Harold Haodong Chen, Chenfei Liao, Litao Guo, Ying-Cong Chen
Affilation: HKUST(GZ), HKUST, SJTU, Knowin
Venue: arXiv
Comment:
Date: December 2025
Paper Link: https://arxiv.org/abs/2512.14442
⭐️ Key Takeaways
1. A4-Agent는 어포던스 예측 작업을 고수준 추론과 저수준 근거 제시로 분리하고, 전문화된 기반 모델들(VLM, 생성 모델, 비전 모델)을 조정하여 훈련 없이 뛰어난 제로 샷 성능을 달성하는 새로운 에이전트 프레임워크이다.
2. 이 프레임워크는 생성 모델을 사용하여 잠재적인 상호작용 상태를 시각화하는 '상상 지원 추론' 패러다임(Dreamer)을 도입하여, 특히 텍스트만으로는 불충분할 수 있는 복잡한 시나리오에서 어포던스 이해를 향상시킨다.
3. 훈련 없는 제로 샷 접근 방식인 A4-Agent는 복잡한 추론을 요구하는 벤치마크에서 기존의 지도 학습 방식들을 능가하는 최첨단 성능을 달성하며, 실제 개방형 세계 시나리오에서도 강력한 일반화 능력을 입증했다.
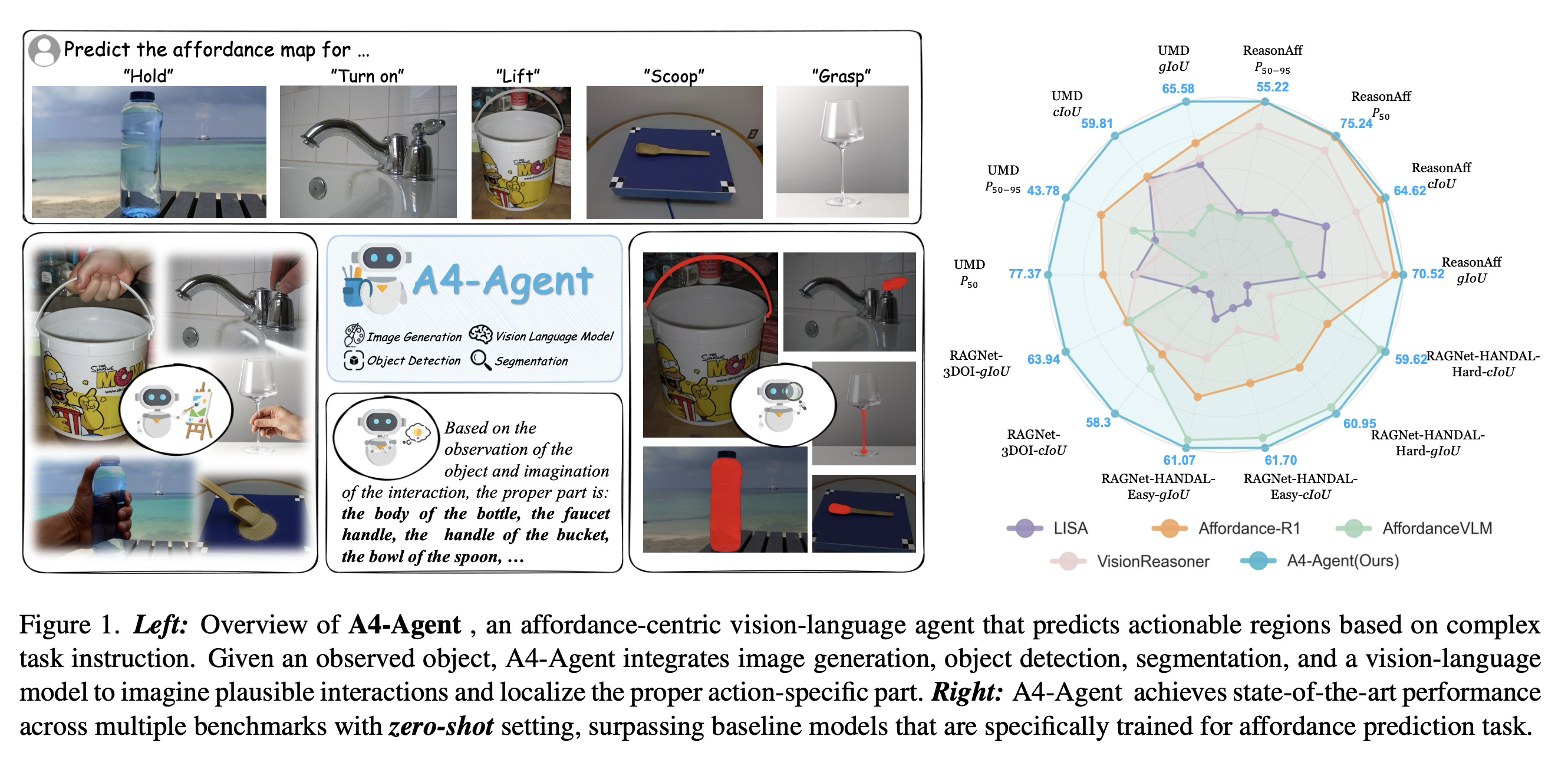
Abstract
언어 명령어에 기반하여 객체 상의 상호작용 영역을 식별하는 어포던스 예측(Affordance prediction)은 임베디드 AI에 중요하다. 일반적인 엔드 투 엔드 모델들은 고수준 추론(high-level reasoning)과 저수준 근거 제시(low-level grounding)를 단일 모놀리식 파이프라인으로 결합하고, 주석이 달린 데이터셋을 통한 훈련에 의존하므로, 새로운 객체 및 미지의 환경에서 일반화 성능이 저조하다. 본 논문에서는 이러한 패러다임을 벗어나 어포던스 예측을 3단계 파이프라인으로 분리하는 A4-Agent라는 훈련 없는 에이전트 프레임워크를 제안한다. 본 프레임워크는 테스트 시점에 특화된 기반 모델들을 조정한다. (1) 상호작용이 어떻게 보일지 시각화하기 위해 생성 모델을 사용하는 Dreamer; (2) 어떤 객체 부분과 상호작용할지 결정하기 위해 대규모 비전-언어 모델을 활용하는 Thinker; (3) 상호작용 영역이 정확히 어디에 위치하는지 찾기 위해 비전 기반 모델들을 조직하는 Spotter. 어떠한 작업별 미세 조정 없이 사전 훈련된 모델들의 상호보완적인 강점을 활용함으로써, 본 제로 샷 프레임워크는 여러 벤치마크에서 최첨단 지도 학습 방법보다 현저히 우수한 성능을 보이며 실제 환경에서 강력한 일반화 능력을 입증한다.
1. Introduction
어포던스(Affordance)는 객체가 에이전트에게 제공하는 행동 가능성을 설명하는 개념으로, 시각적 인식과 물리적 상호작용 사이의 중요한 연결고리 역할을 한다. 임베디드 AI 및 로봇 조작의 맥락에서, 어포던스 예측은 자연어 명령에 기반하여 작업 관련 상호작용을 가능하게 하는 객체의 특정 영역을 식별하는 것을 목표로 한다. 예를 들어, "냉장고를 열어라"라는 명령이 주어지면, 모델은 손잡이를 실행 가능한 영역으로 인식해야 한다. 이러한 능력은 작업 계획, 로봇 파지, 인간-로봇 협업을 포함한 후속 애플리케이션의 기본이 되며, 여기서 어떤 객체가 존재하는지뿐만 아니라 그것들과 어디서, 어떻게 상호작용할 것인지 이해하는 것이 성공적인 작업 실행에 필수적이다.
어포던스 예측은 근본적으로 두 가지 상호보완적인 능력, 즉 (1) 자연어 명령을 해석하고 작업 관련 객체 부분을 식별하는 고수준 추론과 (2) 픽셀 좌표로 이 부분을 정확하게 지역화하는 저수준 근거 제시(grounding)를 요구한다. 전통적인 접근 방식은 주로 근거 제시(grounding)에 초점을 맞추어, 이를 회귀 문제로 취급하며, 어포던스 유형이 주어지면 모델이 어포던스 맵을 예측한다. 그러나 이러한 접근 방식은 고수준 추론 능력이 부족하여 복잡한 명령을 처리하는 데 어려움을 겪는다. 최근 연구는 대규모 언어 모델(LLM)을 통합하고 추론과 근거 제시를 모두 수행하는 통합 모델을 훈련하려고 시도한다. 어포던스 데이터셋을 통해 미세 조정함으로써, 이러한 모델들은 어포던스 맵을 출력하는 능력을 부여받는다. 하지만 이러한 긴밀하게 결합된 설계는 추론과 근거 제시 간의 상충 관계, 제한된 일반화, 그리고 유연성 저하를 포함한 몇 가지 문제를 야기하며, 이는 궁극적으로 실제 시나리오에서의 적용 가능성을 저해한다. 엔드 투 엔드 시스템의 매력에도 불구하고, 고수준 추론과 저수준 근거 제시를 얽매는 것이 어포던스 예측을 위한 진정으로 올바른 경로인지 의문이 제기된다.
본 논문에서는 기초 모델(foundation models)들의 훈련 없는 조정을 통해 어포던스 예측에 맞춰진 에이전트 프레임워크인 A4-Agent를 예비적으로 탐구하여 제시한다. 본 연구의 핵심 통찰력은 추론 및 근거 제시 프로세스를 분리하는 데 있다. 우리는 이 작업을 강력한 기초 모델을 활용하는 전문화된 전문가가 관리하는 3단계 파이프라인으로 분해한다. (1) Dreamer: 인간의 인지 과정에서 영감을 받아, Dreamer는 상상 단계를 시작한다. Dreamer는 상호작용이 어떻게 보일지 묘사하는 시각적 시나리오(예: 손이 손잡이를 잡는 모습, 문이 부분적으로 열리는 모습)를 합성하기 위해 생성 모델들을 사용한다. (2) Thinker: Thinker는 선도적인 비전-언어 모델(VLM)들을 활용하여 작업 명령을 해석한다. 시각적 관찰을 상상된 시나리오와 통합하여, 무엇과 상호작용할지를 명시하는 구조화된 텍스트 설명을 생성한다. (3) Spotter: Spotter는 강력한 비전 기초 모델들을 조직하여 정확한 공간 지역화를 실행하고, 시각적 입력 내에서 상호작용 영역이 정확히 어디에 있는지 정확히 찾아낸다.
놀랍게도, 그림 1에 나타난 바와 같이, 어떠한 작업별 훈련 없이 강력한 사전 훈련된 모델들을 조정함으로써, 본 연구의 제로 샷 프레임워크인 A4-Agent는 여러 벤치마크에서 현재 최첨단 지도 학습 방법들보다 상당히 우수한 성능을 보이며 실제 환경에 대한 강력한 일반화 능력을 입증한다. 요약하면, 본 연구의 주요 기여는 다음과 같다.
- 본 연구는 우수한 성능을 달성하고 강력한 제로 샷 일반화 능력을 입증하는 훈련 없는 에이전트 프레임워크인 A4-Agent를 소개한다.
- 본 연구는 추론 및 근거 제시 프로세스를 분리하여 어포던스 예측을 위한 새로운 접근 방식을 검증한다. 이를 통해 각 해당 작업에 대해 최첨단 모델을 통합할 수 있으며, 본 연구는 이 방법의 효과를 실험적으로 입증한다.
- 본 연구는 어포던스 추론 과정에서 명시적인 상상의 결정적인 역할을 보여주는 상상 보조 어포던스 추론 패러다임을 제안한다.
2. Related Work
Affordance Learning. 깁슨(Gibson)에 의해 도입된 어포던스 개념은 에이전트가 행동 가능성을 기반으로 환경 내 객체를 어떻게 인지하고 상호작용하는지 설명한다. 이 기초 개념은 로봇 시스템을 위한 어포던스 학습에 대한 광범위한 연구에 영감을 주었다. 전통적인 접근 방식은 인간-객체 상호작용(HOI) 이미지, 인간 시연 영상, 그리고 포인트 클라우드 또는 3D 가우시안 스플래팅(Gaussian Splatting)을 통한 3D 인지로부터 학습하는 것을 포함하여 다양한 학습 패러다임을 탐구해 왔다.
최근 발전은 어포던스 이해를 향상하기 위해 다중 모드 대규모 언어 모델(MLLM)을 활용한다. 예를 들어, AffordanceLLM 및 Seqafford는 분할 출력을 위해 어휘에 특수 토큰을 도입하고 어포던스 영역을 토큰 임베딩에 매핑한다. LISA는 언어 기반 분할 작업을 위한 추론 능력을 통합하여 이러한 패러다임을 확장한다. 더 최근에는, Affordance-R1이 프로세스 보상을 통해 MLLM의 어포던스 추론 및 경계 상자 및 핵심점 근거 제시(grounding)를 강화하기 위해 강화 학습을 사용한다. 그러나 이러한 방법들 대부분은 단일 모델 아키텍처 내에서 추론 및 근거 제시 능력을 공동으로 최적화하는 엔드 투 엔드 훈련 패러다임을 채택한다. 이들은 종종 추론 복잡성과 공간 정밀도 사이의 내재적 상충 관계에 직면하며 새로운 시나리오에 대한 일반화 성능이 저조함을 보인다. 대조적으로, 본 연구의 방법은 명시적인 추론 및 근거 제시를 통해 제로 샷 어포던스 예측을 달성하기 위해 기초 모델들을 조정하는 훈련 없는 에이전트 프레임워크를 제안한다.
Multimodal Reasoning in MLLMs. MLLM은 시각적 이해, 생성 및 다중 모드 추론에서 놀라운 능력을 입증해 왔다. 최근 발전은 추론 시간 확장을 통해 추론 능력을 상당히 향상시켰다. OpenAI o1은 우수한 성능을 달성하기 위해 CoT(Chain-of-Thought) 추론 프로세스를 확장하며, DeepSeek-R1은 추론 능력을 더욱 발전시키기 위해 GRPO와 함께 강화 학습을 활용한다. 이러한 성공을 바탕으로, 여러 연구들은 이러한 추론 패러다임을 비전 작업으로 확장하여 다중 모드 맥락에서 향상된 추론의 잠재력을 보여준다. 텍스트 기반 추론을 넘어, 새로운 패러다임은 시각적 표현을 사용한 추론을 탐구해 왔다. VoT는 동적 추론을 위한 텍스트 이미지 표현을 도입한다. 강력한 생성 모델의 이점을 활용하여, 접근 방식들은 추론을 돕기 위해 명시적인 시각적 상상을 활용하려고 시도한다. 이러한 접근 방식들은 중간 시각 자료를 생성하는 것이 추론과 해석 가능성을 향상시키며, 복잡한 공간 및 상호작용 이해를 요구하는 어포던스 추론에 귀중한 통찰력을 제공함을 보여준다. 어포던스 예측을 위한 기존의 엔드 투 엔드 방법과 달리, 본 연구의 에이전트 프레임워크는 추론과 근거 제시를 분리하여 이러한 다중 모드 추론 기술의 원활한 통합을 허용한다.
3. Motivation
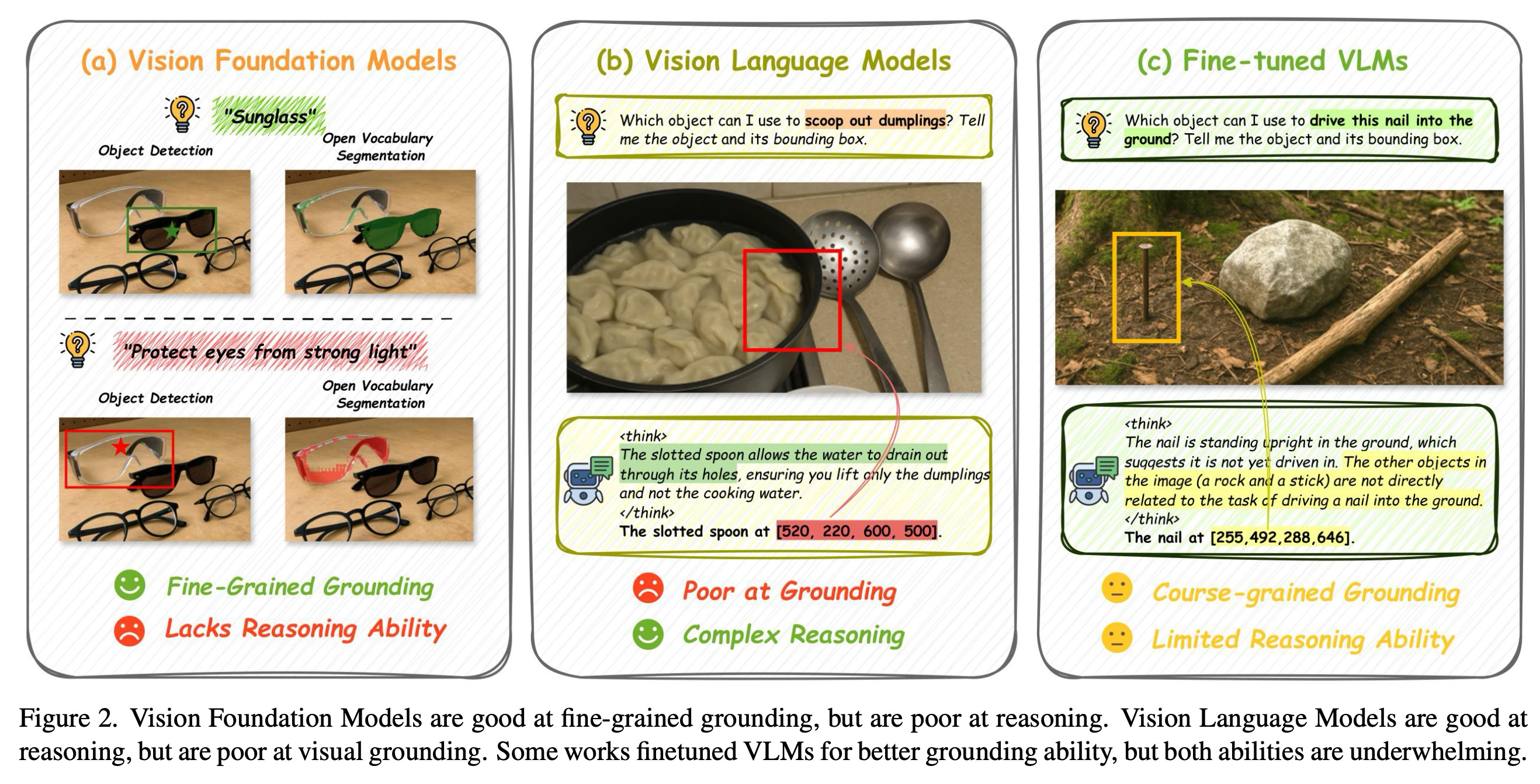
어포던스 예측은 근본적으로 객체 부분에 대한 명령을 해석하는 고수준 추론과 정확하게 지역화하는 저수준 근거 제시(grounding)라는 두 가지 상호보완적인 능력을 요구한다. 그림 2 (a)에서 보듯이, 전문화된 비전 기반 모델들은 세밀한 지역화에 탁월하지만, 복잡한 작업 명령을 해석하는 데 필요한 의미론적 이해가 부족하다. 반대로, 그림 2 (b)에서 보듯이, 최근의 다중 모드 대규모 언어 모델(MLLM)들은 인상적인 추론 능력을 보여주지만, 종종 조악하거나 부정확한 공간 예측을 생성하여 정밀한 어포던스 예측에는 불충분하다.
기존 패러다임은 단일의 엔드 투 엔드 모델을 통해 이러한 이분법을 해결하려고 시도한다. 이러한 접근 방식은 시각적 근거 제시 데이터(예: 경계 상자, 핵심점, 마스크)를 통해 MLLM을 훈련하여 추론 모델의 근거 제시 능력을 향상시키려고 노력한다. 그러나 그림 2 (c)가 보여주듯이, 이러한 긴밀하게 결합된 패러다임은 이상적이지 않다. 여전히 근본적인 한계를 내포한다. (1) 제한된 일반화: 제한된 데이터셋으로 훈련하는 것은 실제 시나리오의 다양성을 포괄할 수 없으며, 새로운 객체와 환경에 대해 취약하게 만든다. (2) 능력 상충 관계: 추론과 근거 제시를 동시에 최적화하는 것은 모델이 서로 다른 목표 사이에서 균형을 맞추도록 강제하며, 한 능력의 개선이 다른 능력의 저하를 초래할 수 있다. (3) 낮은 유연성: 단일 통합 설계는 더 강력한 기반 모델이 등장할 때 독립적인 업그레이드를 방해하며, 전체 시스템에 대한 비용이 많이 드는 재훈련을 요구한다. (4) 폐쇄형 모델과의 격차: 이러한 파이프라인은 오픈 소스 체크포인트에 국한되므로, 가장 유능한 폐쇄형 모델을 활용할 수 없어 추론 능력의 상한선을 제한한다.
따라서, 본 연구는 근본적으로 다른 접근 방식을 탐구하는 것을 목표로 한다: 추론과 근거 제시를 전문화되고 조정된 에이전트로 분리하는 것이다. 우리는 어포던스 예측이 본질적으로 다단계적이라고 주장한다. 단일 모델이 두 가지 능력을 모두 습득하도록 강요하기보다는, 우리는 최첨단 기반 모델들을 사용하여 각 구성 요소를 독립적으로 설계하고, 테스트 시점에 에이전트 프레임워크를 통해 이들을 조직한다.
이러한 패러다임의 전환은 다음과 같은 매력적인 이점을 제공할 수 있다. (I) 훈련 없는 일반화: 사전 훈련된 모델의 광범위한 지식을 활용하여, 시스템은 작업별 미세 조정이나 비용이 많이 드는 데이터 수집 없이 다양한 시나리오로 일반화한다. (II) 모듈식 전문화: 각 구성 요소는 서로 다른 모델들의 상호보완적인 강점을 활용하며, 더 나은 모델을 사용할 수 있게 될 때 독립적으로 업그레이드될 수 있다. (III) 해석 가능한 추론: 명시적인 중간 단계는 의사 결정 과정을 투명하고 디버깅 가능하게 만들며, 오류 진단 및 시스템 개선을 용이하게 한다.
4. A4-Agent: Agentic Affordance Reasoning
4.1 Problem Definition
우리는 어포던스 예측을 자연어 명령에 의해 조건화된 시각적 근거 제시(visual grounding) 문제로 공식화한다. 입력 이미지 와 작업 설명 (예: “냉장고를 열어라”)가 주어졌을 때, 목표는 지정된 상호작용을 가능하게 하는 어포던스 영역 를 식별하는 것이다. 이 영역은 다음 식과 같이 표현된다:
여기서 는 작업 관련 상호작용이 발생하는 공간 영역을 나타낸다. 후속 애플리케이션에 따라, 이 영역은 경계 상자 , 핵심점 , 또는 분할 마스크 로 표현될 수 있다. 최근 연구(Affordance-R1, RAGNet)를 따라, 우리는 픽셀 수준 정밀도를 위해 분할 마스크를 주된 표현으로 채택한다.
4.2 Framework Overview
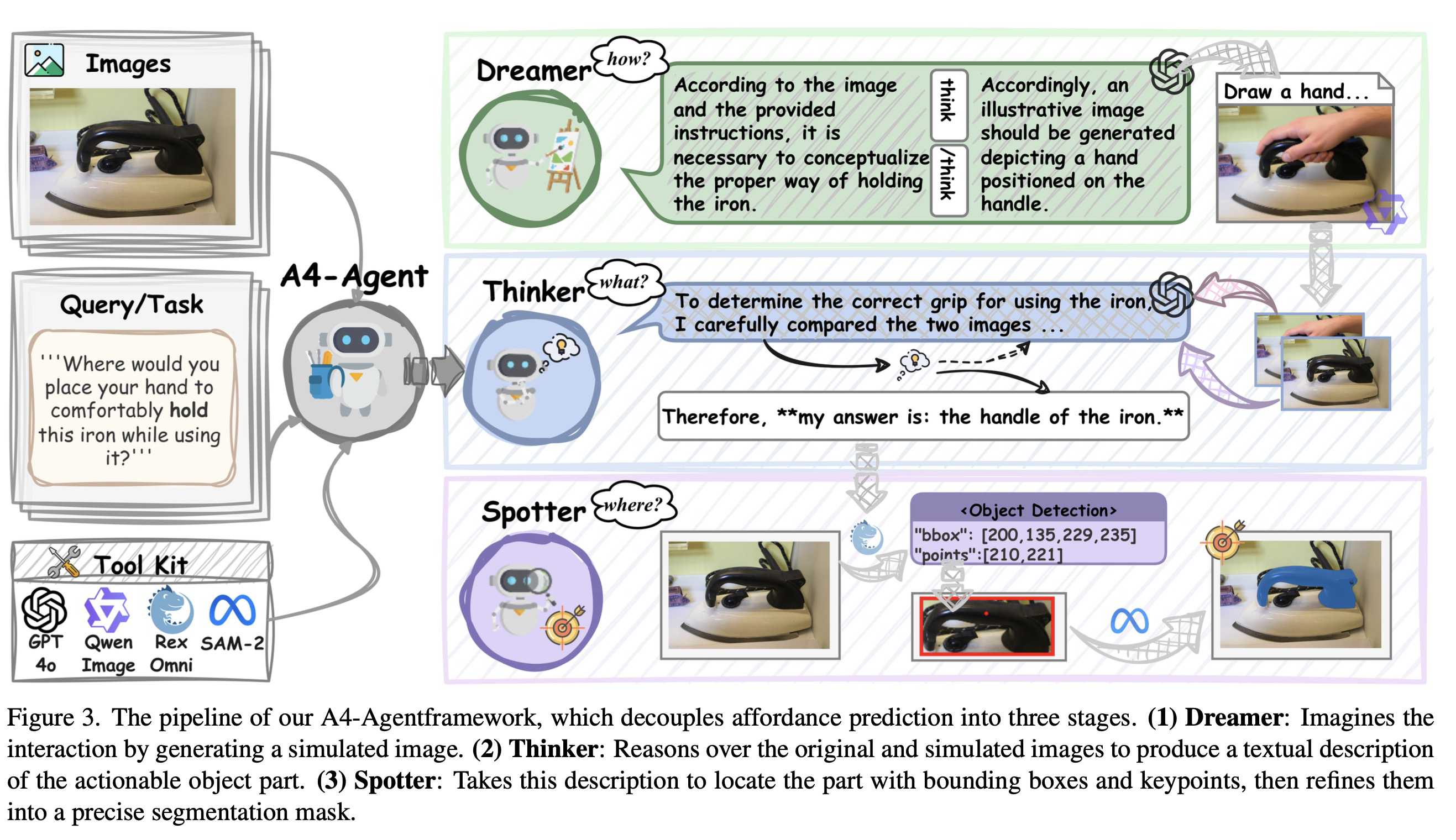
3절에 요약된 동기를 바탕으로, 본 연구는 분리 원칙을 구현하는 훈련 없는 에이전트 프레임워크인 A4-Agent를 제안하며, 이는 제로 샷 어포던스 예측을 위한 것이다. 로부터 을 직접 회귀(regress)하는 엔드 투 엔드 모델과 달리, A4-Agent는 상호작용이 필요한 객체 부분(추론)을 먼저 추론한 다음, 그 위치(근거 제시)를 결정한다.
구체적으로, 추론 과정은 두 단계 파이프라인을 따른다: Dreamer는 작동 방식(Sec. 4.3)을 상상하고, Thinker는 작동할 부분(Sec. 4.4)을 결정한다. 그런 다음 근거 제시 과정은 Spotter에 의해 처리되어, 조대-정밀(coarse-to-fine) 접근 방식을 사용하여 작동할 위치(Sec. 4.5)를 찾는다. Spotter는 초기에는 경계 상자 및 핵심점을 통해 넓은 영역을 식별하고, 이후 분할 모델에 의해 픽셀 수준의 정확한 마스크를 생성하도록 정제된다. 전반적인 프레임워크는 그림 3에 제시되어 있다.
4.3 Dreamer: Imagine how to Operate
인간이 도구의 어포던스에 대해 추론할 때, 종종 손이 도구와 어떻게 상호작용할지 정신적으로 시뮬레이션하고 더 넓은 사용 시나리오를 구상하는 것부터 시작한다. 이러한 과정에서 영감을 받아, 본 연구는 Dreamer를 설계한다. 어포던스 예측을 위해 텍스트 기반 추론에만 의존하는 대신, 우리는 먼저 에이전트에게 이미지 생성 모듈을 사용하여 관찰 와 작업 를 기반으로 그럴듯한 상호작용 상태(예: 손잡이를 잡는 손, 부분적으로 열린 문)를 시각화하도록 요청한다.
이 상상 단계를 유도하는 이미지 편집 프롬프트를 구성하기 위해, 우리는 와 쌍에 적용된 명령 템플릿으로 대규모 비전-언어 모델(VLM)에 질의한다. 공식적으로,
여기서 은 VLM을 나타내고 는 명령 템플릿을 나타낸다 (자세한 내용은 부록에 있음). 이 템플릿은 모델에게 다음을 수행하는 짧고 시각적으로 실행 가능한 설명을 출력하도록 요청한다: (i) 에 보이는 대상 객체와 기능적 부분의 이름을 지정한다. (ii) 최소한의 상호작용과 접촉 구성을 명시한다 (예: “오른손이 수직 냉장고 손잡이를 잡는 모습”). (iii) 이미지에서 지원되지 않는 속성을 피한다. 이로써 이미지 편집에 적합하고 다양한 장면에서 강력하게 작동하는 간결한 프롬프트가 생성된다. 이어서, 우리는 생성 모델을 사용하여 상호작용 시나리오를 합성한다. 원본 이미지 와 작업 명령에서 도출된 시뮬레이션 프롬프트 ("손이 냉장고 손잡이를 잡는 모습"과 같은 예)가 주어지면, 모델은 편집된 이미지 을 생성한다.
여기서 는 이미지 생성 모델을 나타낸다. 상상된 이미지 은 그럴듯한 접촉 및 동작 단서를 묘사함으로써 상호작용이 어디서 발생해야 하는지 명시적으로 강조하며, 에이전트가 행동 패턴이 합리적인지 평가하도록 추가적으로 안내할 수 있다. 이는 어포던스 추론의 성공률과 해석 가능성을 모두 향상시킨다. 이 과정은 생성 모델의 사전 지식, 즉 상호작용 상태에 대한 이해를 활용하여 추론 모델의 추론 과정을 돕는 방식으로 생성 모델의 우선순위를 완전히 활용할 수 있게 한다. 이러한 원활한 통합은 본 연구의 에이전트 프레임워크에 의해 가능해진다.
4.4 Thinker: Decide what to Operate
다음 단계는 적절한 상호작용 영역을 텍스트 형태로 추론하는 것이다. 원본 이미지 , 상상된 상호작용 이미지 , 그리고 작업 가 주어졌을 때, 우리는 미리 설정된 템플릿(정확한 프롬프트는 부록 참조)을 사용하여 대규모 비전-언어 모델(VLM)에 다음 세 단계를 수행하도록 요청한다: (1) 에서 핵심 구성 요소와 상호작용 후보 지점을 인지한다. (2) 을 참조하여 어포던스(행동 유도성)와 일치하는 접촉/동작 단서를 추론한다. (3) 작동 가능한 부분을 에서 다시 근거 제시하고, 간결하고 기계가 읽을 수 있는 명세를 반환한다.
VLM은 두 부분, 즉 Thinking(자유 형식의 근거)과 Output(기계가 읽을 수 있는 JSON)을 반환한다. 우리는 Thinking 섹션을 무시하고 "task", "object name", 그리고 "object part"의 세 가지 필드를 포함하는 Output JSON만 구문 분석한다. 객체 부분은 "the [객체 부분] of the [객체 이름]" (예: "가위의 칼날")과 같이 표현된다. 이는 공간 좌표 없이 무엇과 상호작용할지를 명시하는 간결한 텍스트 어포던스 설명 를 산출한다. 이러한 설계는 명시적인 명령 따르기를 통해 분산을 줄이고, 추론 과정을 해석 가능하게 유지하며, 모듈성을 보존한다. 즉, 더 강력한 VLM이 재훈련 없이 대체될 수 있다.
4.5 Spotter: Locate where to Operate
Spotter는 추론 과정에서 나온 의미론적 어포던스 설명 (예: "오른쪽 냉장고 문의 손잡이")을 정밀한 픽셀 수준 지역화로 변환한다. 우리는 조대-정밀(coarse-to-fine) 공간 근거 제시를 달성하기 위해 두 가지 상호보완적인 비전 기반 모델을 사용한다. 먼저 초기 영역 식별을 위한 개방형 어휘 탐지기(open-vocabulary detector)를 사용하고, 이어서 픽셀 수준의 정확한 마스크 정제를 위한 분할 모델을 사용한다. 이러한 2단계 접근 방식은 기존 기반 모델의 상호보완적인 강점에 의해 동기 부여된다. 분할 모델은 정밀한 경계를 생성하는 데 탁월하지만, 텍스트보다는 신뢰할 수 있는 시각적 프롬프트(예: 상자 또는 점)를 필요로 하며, 이는 의미론적-기하학적 격차를 해소하기 위한 초기 탐지 단계가 필요함을 의미한다.
Open-Vocabulary Detection. 우리는 Thinker가 제공한 텍스트 설명 로부터 초기 공간 지역화를 수행하기 위해 최첨단 개방형 어휘 객체 탐지기인 Rex-Omni를 사용한다. Rex-Omni는 다음을 출력한다: Bounding Boxes : 어포던스 부분을 대략적으로 둘러싸는 직사각형 영역. Key Points : 각 어포던스 영역 내의 대표적인 공간 앵커 (예: 손잡이의 중심).
Fine-Grained Segmentation with SAM. 다음으로, 우리는 Rex-Omni가 예측한 경계 상자 와 핵심점 를 프롬프트로 SAM(SAM2-Large를 사용함)에 전달한다. SAM은 어포던스 영역의 정밀한 경계를 나타내는 상세한 분할 마스크 를 생성한다. 이 프롬프트 기반 접근 방식은 대규모 사전 훈련을 통해 개발된 SAM의 강력한 일반화 능력을 직접 활용하기 때문에 추가적인 훈련을 필요로 하지 않는다. 최종 어포던스 예측은 다중 세분화된 공간 정보를 통합한다:
이는 신속한 장면 이해를 위한 조대 경계 상자, 상호작용 타겟팅을 위한 핵심점, 그리고 정밀한 조작 계획을 위한 세밀한 분할 마스크 등 다양한 다운스트림 애플리케이션에 적합한 포괄적인 공간 표현을 제공한다.
우리의 Spotter에서, 각 모델은 자신의 강점을 활용하며, 향상된 모델이 등장할 때 엔드 투 엔드 재훈련 없이 독립적으로 업그레이드될 수 있다.
5. Experiment
5.1 Experimental Settings
Implementation Details. A4-Agent는 사전 훈련된 기반 모델들을 조정하는 훈련 없는 프레임워크이다. 본 연구의 완전한 에이전트에서, 사용된 VLM은 GPT-4o이고, 생성 모델은 Qwen-Image-Editing이다. 개방형 어휘 객체 탐지를 위해서는 Rex-Omni를 사용하며, 분할을 위해서는 SAM2-Large를 사용한다.
Datasets. 본 연구는 추론 인식 어포던스 예측과 다양한 시나리오로의 일반화 능력을 모두 평가하기 위해 세 가지 정량적 벤치마크와 일련의 개방형 세계 이미지를 사용하여 A4-Agent를 평가한다. 중요한 점은, 본 프레임워크는 완전히 제로 샷 방식이며, 이러한 데이터셋 중 어느 것도 훈련하거나 미세 조정하지 않았다는 것이다.
- ReasonAff: 깊은 의미론적 이해를 요구하는 복잡한 지침을 포함하는 Instruct-Part를 기반으로 구축된 추론 중심의 데이터셋이다. 본 연구는 600개의 이미지-작업 쌍을 포함하는 테스트 분할을 사용한다.
- RAGNet: 대규모 추론 기반 어포던스 분할 데이터셋이다. 본 연구는 총 3,018개의 이미지-작업 쌍을 포함하는 RAGNET-3DOI와 RAGNET-HANDAL의 두 하위 데이터셋으로 평가한다.
- UMD Part Affordance: 17개의 객체 범주와 7가지 어포던스 유형을 다루는 표준 어포던스 데이터셋이다. 이전 연구를 따라, 본 연구는 프레임의 10분의 1을 샘플링하여 1,922개의 테스트 이미지를 얻는다.
- 개방형 세계 이미지(Open-World Images): 표준 벤치마크(주로 주방 및 가정용 장면에 초점)를 넘어 일반화 능력을 평가하기 위해, 본 연구는 정성적 평가를 위해 Phys-ToolBench와 웹 소스에서 다양한 이미지를 수집한다.
5.2 Quantitative Results
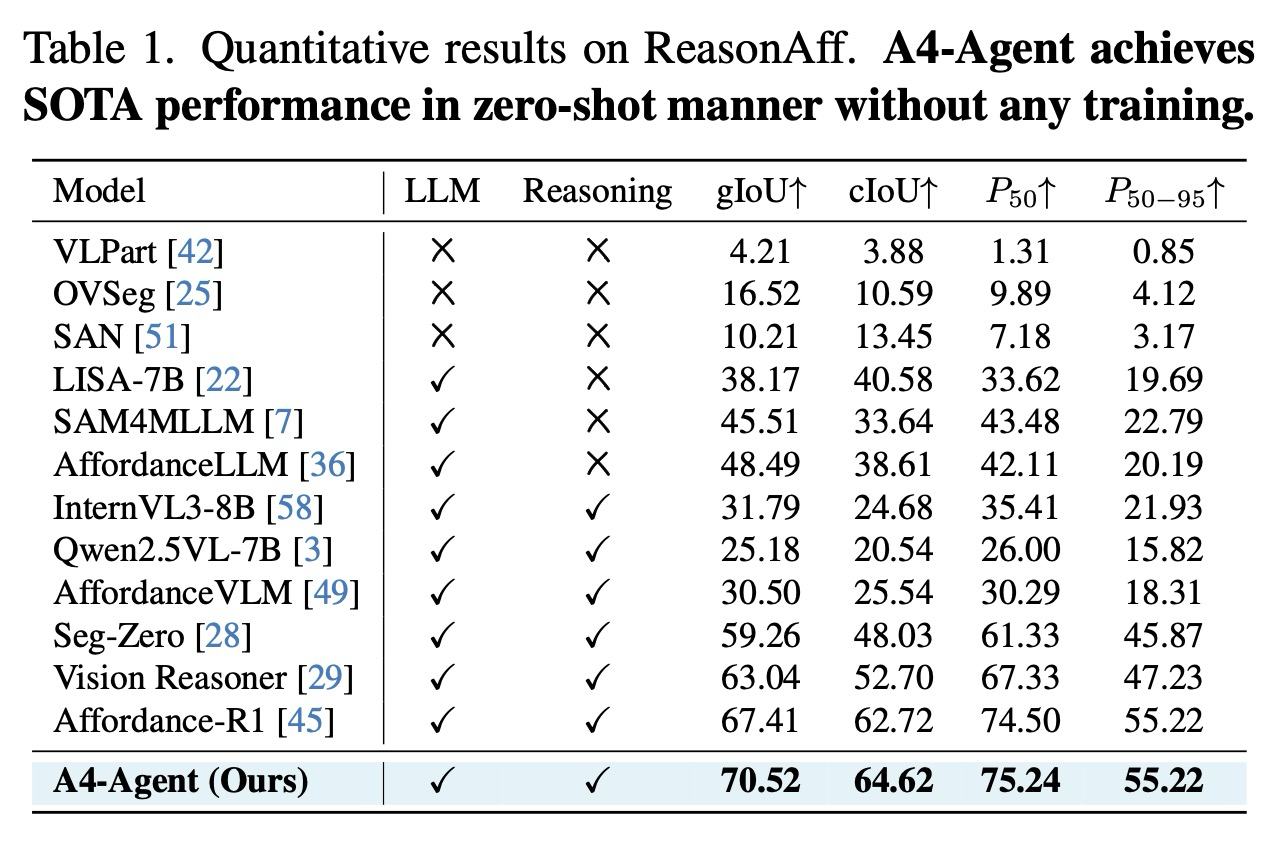
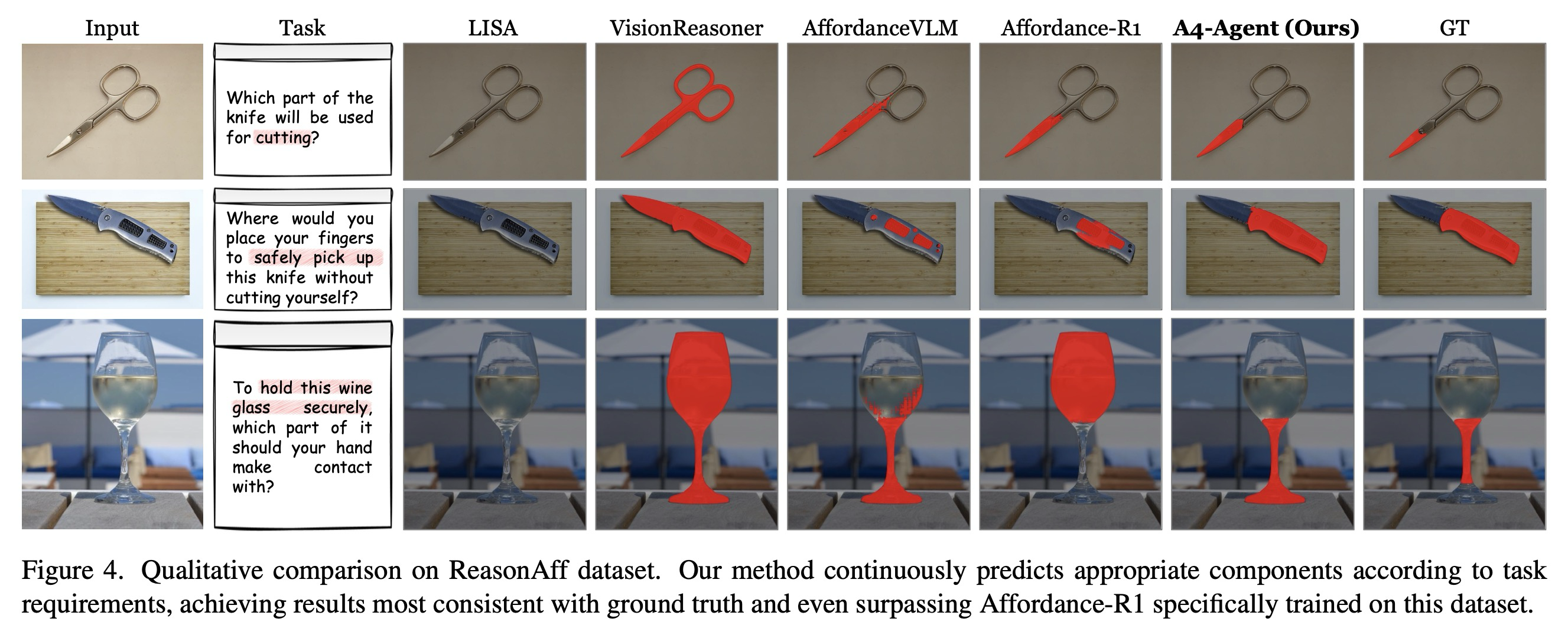
Results on ReasonAff Dataset. 표 1과 그림 4는 암묵적인 상황별 지침에 대한 깊은 추론을 요구하는 ReasonAff의 결과를 제시한다. A4-Agent는 어떠한 훈련 없이 모든 측정 기준에서 최첨단 성능을 달성한다. 지도 학습 방법인 AffordanceLLM(48.49 gIoU) 및 추론 강화 접근 방식인 Vision Reasoner(63.04 gIoU)와 Affordance-R1(67.41 gIoU)과 비교할 때, A4-Agent는 71.83 gIoU에 도달하며 우수한 추론 능력과 일반화 능력을 입증한다.
이러한 성능은 세 가지 설계 원칙에서 비롯된다. 첫째, 추론을 근거 제시로부터 분리하는 것은 상호보완적인 강점을 활용한다. 즉, VLM은 의미론적 해석에 탁월한 반면, 전문화된 비전 모델은 정밀한 지역화를 제공한다. 둘째, "상상을 통한 사고(think-with-imagination)" 메커니즘은 추상적인 지침을 합성된 시각적 표현에 근거 제시하여 복잡한 시나리오에서 어포던스 이해를 향상시킨다. 셋째, 훈련 데이터에 의해 제약을 받는 엔드 투 엔드 모델과 달리, 본 연구의 제로 샷 접근 방식은 ReasonAff의 다양한 지침에 자연스럽게 일반화된다.
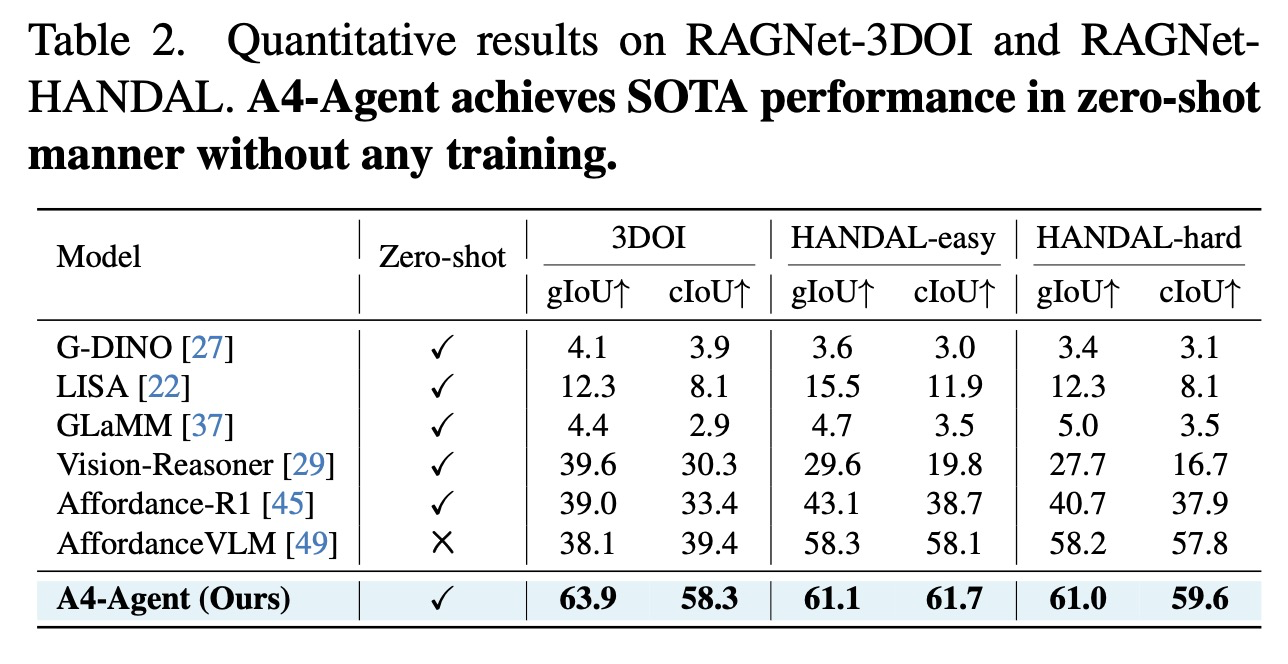

Results on RAGNet Dataset. 표 2는 추론 기반 어포던스 분할에 초점을 맞춘 RAGNet의 결과를 보여준다. 본 연구의 프레임워크는 탁월한 제로 샷 성능을 입증하며, 모든 기준선을 크게 능가한다. A4-Agent는 3DOI에서 63.9 gIoU를 달성하여 Vision-Reasoner를 24점 이상 능가한다. 이 성능은 HANDAL-hard 및 HANDAL-easy로 확장되며, 여기서도 A4-Agent는 가장 높은 점수를 달성한다. 정성적 비교는 그림 5에 제시되어 있다.
결정적으로, A4-Agent는 이 데이터셋으로 훈련된 지도 학습 AffordanceVLM을 능가하며, 기초 모델의 에이전트적 조정이 복잡한 추론 작업에 대한 작업별 미세 조정을 능가함을 입증한다. 이는 추상적인 지침을 실행 가능한 단계로 분해하고 시각적으로 정확하게 근거 제시하는 본 연구의 능력에서 비롯되며, 이는 분리된 아키텍처의 핵심 이점이다.
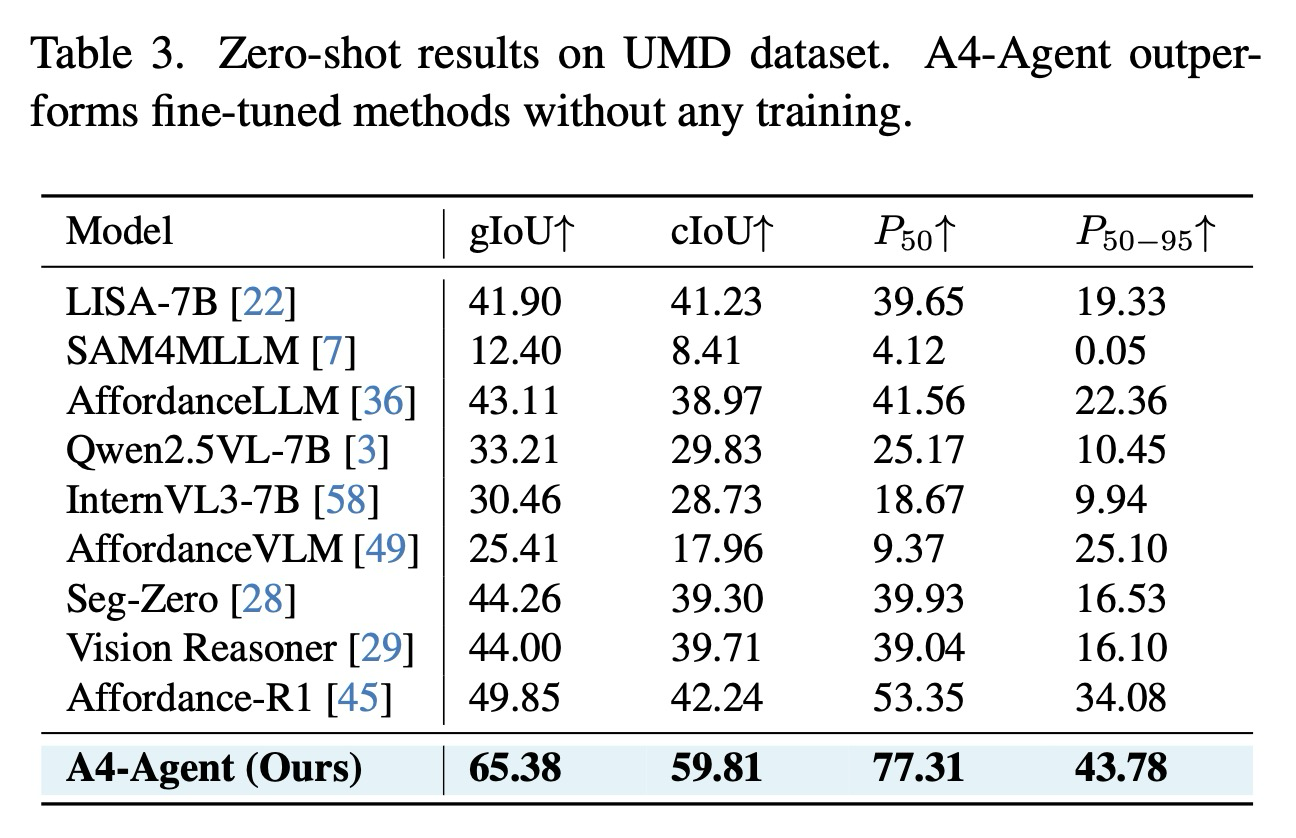
Results on UMD Dataset. 복잡한 추론 집약적 어포던스 예측 작업 외에도, A4-Agent는 행동 개념으로부터 어포던스를 예측하는 더 전통적인 작업에서도 탁월한 성능을 보인다. 표 3에 제시된 바와 같이, A4-Agent는 여전히 최첨단 성능을 달성하며, 기준선을 15.53 gIoU만큼 크게 능가하여 일반적인 객체의 다양한 사용 가능성에 대한 깊은 이해를 입증한다. 이러한 결과는 강력한 사전 훈련 모델에게 이러한 기본적인 능력이 비교적 단순하다는 점에서 예측 가능한 결과이다. 이는 전문화된 기초 모델의 훈련 없는 조정이 이미 충분히 풍부한 일반 지식을 보유하고 있으므로 강력한 일반화 능력을 나타낼 수 있다는 본 연구의 동기를 더욱 뒷받침한다.
5.3 Qualitative Results on Open-World Images

개방형 세계 시나리오에서 A4-Agent의 성능을 추가로 검증하기 위해, 우리는 개방형 세계 이미지에 대한 정성적 실험을 수행한다. 그림 6은 A4-Agent가 다음과 같은 어려운 시나리오 전반에 걸쳐 강력한 성능을 보여줌을 나타낸다: (1) 새로운 객체(Novel objects): 표준 벤치마크에는 없는 객체(예: 디지털 장비)에 대한 작동 가능한 영역을 성공적으로 식별한다. (2) 복잡한 장면(Complex scenes): 복잡한 환경에서 도구의 가장 적합한 부분(예: 스크루드라이버의 끝)을 정확하게 식별한다. (3) 심층 추론(Deep reasoning): 강력한 추론 능력을 사용하여 적절한 도구를 논리적으로 추론한다(예: 물을 빼는 데 사용할 수 있는 구멍 뚫린 숟가락, 못을 박는 망치 대용으로 사용할 수 있는 돌).
분포에서 벗어난(out-of-distribution) 객체에서 종종 실패하는 기준선과 달리, A4-Agent는 웹 규모의 사전 훈련된 모델로부터 얻은 폭넓은 지식을 활용하여 일관된 성능을 유지한다. 이는 훈련 없는 조정이 실제 애플리케이션에 대한 큰 잠재력을 가지고 있음을 확인시켜 준다.
5.4 Ablation Study
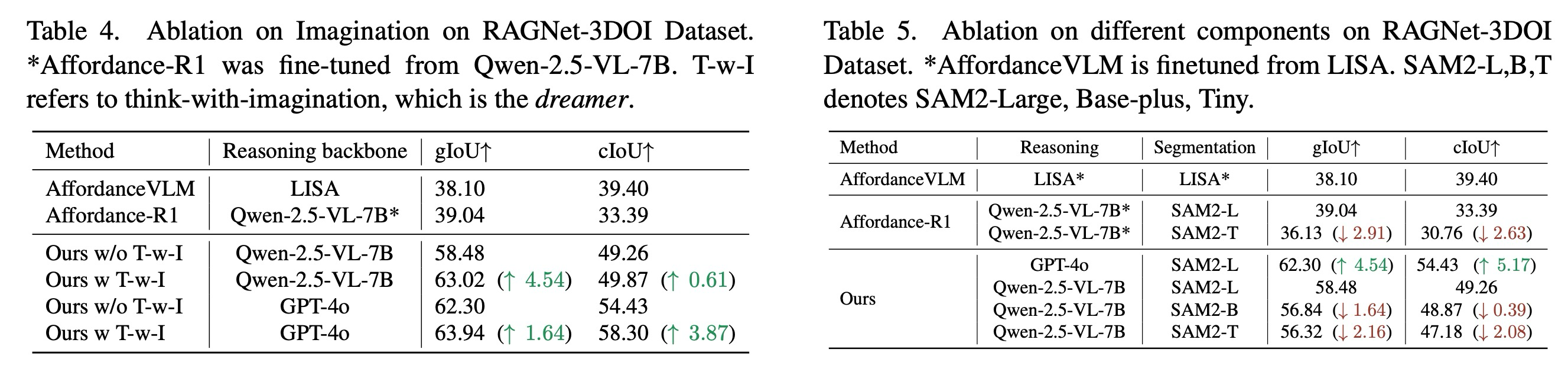
Importance of Imagination in Affordance Reasoning. 표 4는 시각적 상상(imagination)이 기여하는 바를 평가한다. 상상 메커니즘은 모든 기준 모델에 걸쳐 모든 측정 기준에서 일관된 향상을 제공한다. 특히, 상상력을 사용한 오픈 소스 Qwen-2.5-VL (7B)은 텍스트 기반 추론만을 사용한 폐쇄형 소스 GPT-4o보다 뛰어난 성능을 보인다. 이는 추론을 합성된 시각적 표현에 근거 제시하는 것이, 특히 텍스트 설명만으로는 불충분할 때, 어포던스 이해를 향상시킨다는 것을 입증한다. 시각적 상상 메커니즘은 추론 모델이 생성 모델 내에 캡슐화된 상호작용에 대한 방대한 사전 지식을 효과적으로 활용할 수 있도록 하는 다리 역할을 한다.
Robustness to Different Components. 우리는 A4-Agent가 다른 구성 요소 선택에 대해 얼마나 견고한지 분석한다.
Reasoning Backbone. 표 5는 Qwen-2.5-VL을 더 강력한 GPT-4o로 대체하면 성능이 크게 향상됨을 보여준다. 이는 A4-Agent가 더 강력한 기반 모델이 사용 가능해질 때 원활하게 통합할 수 있는 유연성을 입증한다.
Segmentation Backbone. SAM2-Large를 더 작은 변형(SAM2-Base-Plus/Tiny)으로 대체하면 성능이 약간 떨어지지만, 이 프레임워크는 여전히 매우 효과적이며 기준선보다 훨씬 뛰어난 성능을 보인다. 성능 하락 폭 또한 기준선 방법인 Affordance-R1보다 작다. 이는 더 약한 근거 제시 구성 요소에도 불구하고 우리 접근 방식의 견고성을 강조한다.
6. Conclusion
본 논문에서는 어포던스 예측을 위한 새로운 훈련 없는 프레임워크인 A4-Agent를 제시한다. 우리의 주요 기여는 이 작업을 고수준 추론과 저수준 근거 제시로 분리하여, 시각-언어 모델(vision-language models)은 의미론적 해석을 위해, 비전 기반 모델(vision foundation models)은 지역화를 위해 사용할 수 있도록 한 것이다. 또한 우리는 추론 과정에 상상 메커니즘을 도입했으며, 여기서 생성 모델은 잠재적인 상호작용을 시각화하여 이 과정을 개선한다. 광범위한 실험은 이 제로 샷 접근 방식이 어려운 벤치마크에서 지도 학습 방법을 능가하며, 개방형 세계 시나리오에 잘 일반화됨을 보여준다. A4-Agent의 성공은 복잡한 어포던스 예측을 위한 기반 모델들의 에이전트적 조정의 잠재력을 강조한다.
