Author: Kangrui Wang, Pingyue Zhang, Zihan Wang, Yaning Gao, Linjie Li, Qineng Wang, Hanyang Chen, Chi Wan, Yiping Lu, Zhengyuan Yang, Lijuan Wang, Ranjay Krishna, Jiajun Wu, Li Fei-Fei, Yejin Choi, Manling Li
Affilation: Northwestern University, University of Washington, Stanford University, Microsoft, University of Wisconsin-Madison, University of Illinois Urbana-Champaign
Venue: NeurIPS 2025
Comment:
Date: October 2025
Paper Link: https://arxiv.org/abs/2510.16907
⭐️ Key Takeaways
1. VLM 에이전트의 추론 과정을 상태 추정(StateEstimation)과 전환 모델링(TransitionModeling)으로 구조화하여 명시적인 시각적 상태 추론을 통해 내부 월드 모델을 구축하도록 강화 학습(RL)으로 보상하는 것이 다중 턴 작업 성능을 크게 향상시킨다.
2. 논문은 에이전트의 내부 상태 시뮬레이션의 정확도를 평가하는 WorldModeling Reward와 장기간 크레딧 할당 문제를 해결하는 Bi-Level GAE를 도입하여 VLM 추론의 품질과 작업 성공률을 일관되게 향상시킨다.
3. VLM 에이전트의 내부 믿음을 표현하는 최적의 시각적 상태 표현 방식은 작업에 따라 달라지며, 일반적인 목적의 작업에서는 자연어가, 높은 정밀도의 조작 작업에서는 구조화된 형식이 필수적이다.
Abstract
LLM 에이전트와 비교하여 VLM 에이전트를 훈련하는 데 있어 주요 과제는 상태가 단순한 텍스트에서 복잡한 시각적 관찰로 전환된다는 것이며, 이는 부분적 관찰 가능성(partial observability)을 유발하고 강력한 월드 모델링을 요구한다. 우리는 VLM 에이전트가 명시적인 시각적 상태 추론을 통해 내부 월드 모델을 구축할 수 있는지 질문한다. 본 연구에서는 강화 학습(RL)을 통해 VLM 에이전트의 추론 프로세스를 구조적으로 강제하고 보상하며, 이 문제를 부분 관찰 가능 마르코프 결정 과정(POMDP)으로 공식화한다. 우리는 다섯 가지 추론 전략을 연구함으로써 에이전트의 추론을 상태 추정(StateEstimation)("현재 상태는 무엇인가?")과 전환 모델링(TransitionModeling)("다음은 무엇인가?")으로 구조화하는 것이 중요함을 입증한다. 에이전트가 시각적 상태를 어떻게 접지(ground)하고 이러한 내부 믿음을 어떻게 표현해야 하는지 조사한 결과, 최적의 표현 방식이 작업에 따라 달라진다는 사실을 밝혀낸다. 자연어는 일반적인 작업에서 의미론적 관계를 포착하는 데 탁월하지만, 구조화된 형식은 높은 정밀도의 조작에 필수적이다. 이러한 통찰은 우리의 보상 설계(reward shaping) 및 크레딧 할당(credit assignment) 접근 방식에 동기를 부여한다. 우리는 에이전트의 턴별 상태 예측에 대해 밀집된 보상을 제공하는 월드 모델링 보상(WorldModeling Reward)을 활용하며, 한편 Bi-Level GAE(Bi-Level General Advantage Estimation)는 턴을 인식하는 크레딧 할당을 가능하게 한다. 이러한 월드 모델 추론을 통해 우리는 3B 모델이 다섯 가지 다양한 에이전트 작업 세트에서 0.82의 성능을 달성하도록 만들며, 이는 훈련되지 않은 모델(0.21)에 비해 거의 3배 향상된 수치이고, GPT-5(0.75), Gemini 2.5 Pro(0.67), Claude 4.5(0.62)와 같은 독점적인 추론 모델을 능가한다. 모든 실험은 다양한 시각적 환경에서 다중 턴 VLM 에이전트를 훈련하고 분석하기 위한 확장 가능한 시스템인 VAGEN 프레임워크의 지원을 받아 수행한다.
1. Introduction
다중 턴 에이전트 작업의 핵심 과제는 동적 환경을 정확하게 해석하고 추적하는 것인데, 에이전트가 텍스트가 아닌 시각을 통해 세상을 감지할 때 이 과제는 훨씬 더 어려워진다. 시각-언어 모델(VLM) 에이전트 작업은 본질적으로 복잡하며, 이는 종종 부분적이고 노이즈가 많은 관찰인 시각적 상태를 이해하는 데 어려움이 있기 때문이며, 이로 인해 문제는 근본적으로 마르코프 결정 과정(MDP)에서 더 어려운 부분 관찰 가능 마르코프 결정 과정(POMDP)으로 재구성된다. POMDP 내에서 에이전트는 단순히 행동하는 것이 아니라, 관찰을 통해 먼저 세상의 진정한 상태를 추정한다. 에이전트가 보는 것과 알아야 할 것을 연결하는 다리가 본 연구의 주요 초점인 내부 월드 모델이다. 이 모델은 시각적 관찰을 기반으로 진정한 상태에 대한 내부적인 믿음(belief)을 유지하는 인지 엔진 역할을 한다. 게임, embodied AI, 컴퓨터 사용과 같은 시각적 에이전트 작업을 위해 VLM 에이전트가 제안되었지만, 이러한 다중 턴 에이전트 작업의 현재 접근 방식은 시각적 상태 추론을 강화하기 위한 명시적인 내부 월드 모델링이 부족한 경우가 많다. 이는 "명시적인 시각적 상태 추론을 통해 VLM이 내부 월드 모델을 구축하도록 효과적으로 가르칠 수 있는가?"라는 질문으로 이어진다.
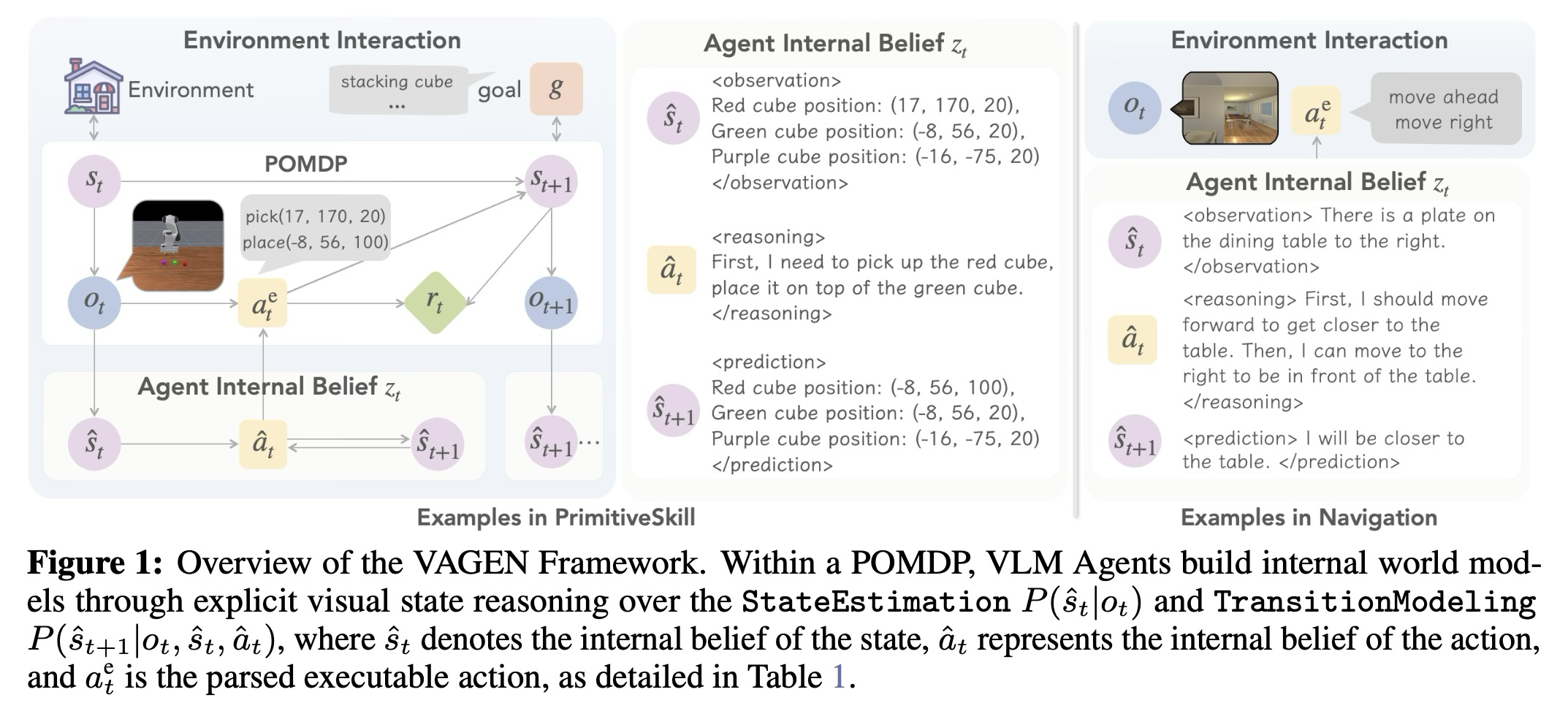
우리는 이 문제를 해결하기 위해 강화 학습(RL)을 통해 VLM에게 보상을 제공하여, 그들의 사고 과정이 상태 추정(StateEstimation)(현재 시각적 상태를 설명)과 전환 모델링(TransitionModeling)(다음 상태 예측)으로 구조화되도록 장려하며, 이는 월드 모델링의 두 가지 필수 구성 요소이다. 우리는 에이전트가 상호 작용이 전개됨에 따라 내부 믿음을 유지하고 업데이트할 수 있도록 전체 상호 작용 궤적을 최적화하기 위해 다중 턴 RL에 중점을 둔다. 이러한 원칙적인 추론 구조를 검증하기 위해, 우리는 RL에서 형식 보상(format reward)을 제어하여 다섯 가지 추론 전략을 체계적으로 비교한다. 이 전략에는 암묵적 시각적 상태 추론으로서의 NoThink 및 FreeThink뿐만 아니라, <observation> 토큰을 통한 상태 추정, <prediction> 토큰을 통한 전환 모델링, 그리고 이들을 결합한 월드 모델링(WorldModeling)을 통한 명시적 추론이 포함된다. 우리의 발견은 상태 추정 및 전환 모델링과 같은 명시적인 시각적 상태 추론을 RL 훈련 중 VLM의 사고 과정에 통합하는 것이 작업 성능을 향상시킬 수 있음을 나타낸다. 특히, 완전한 추론 전략인 월드 모델링은 전체 성능 0.76을 달성하며, FreeThink(0.67)보다 나은 결과를 보였고 NoThink(0.28)를 명확히 능가한다.
VLM 에이전트가 현재 보는 것(상태 추정)과 다음에 보게 될 것(전환 모델링)에 대해 추론할 때 더 나은 결정을 내릴 수 있다는 통찰을 바탕으로, 근본적인 질문은 표현 방식에 있다. 즉, 에이전트가 시각적 세계에 대해 "생각"하기 위한 내부 독백의 최적 표현은 무엇인가에 대한 것이다. 우리는 픽셀을 추론할 수 있는 정신적 모델로 변환하기 위해 다양한 표현 가능성을 탐구했으며, 우리의 발견은 표현 선택이 보편적이지 않고 작업의 요구 사항에 따라 결정된다는 중요한 설계 원칙을 제시한다. 자연어는 강력하고 본질적으로 의미론 중심적인 표현을 제공하여 VLM이 방대한 사전 훈련된 지식을 사용하도록 허용함으로써 일반적인 목적의 작업에서 탁월한 성능을 발휘한다. 그러나 자연어의 본질적인 모호성 때문에 정확한 좌표를 제공하는 구조화된 형식이 필수적인 로봇 조작과 같은 고정밀 작업에는 부적합하다. 세 번째 대안인 기호 표현은 더 추상적인 표현을 제공한다. 놀랍게도, 이러한 추상화는 더 일반화 가능한 해결책을 제시하지 못하며, 대신 우리의 실험에서 가장 비효율적인 방법으로 판명되는데, 모델이 특정 훈련 없이 추상적인 기호를 원시 시각적 입력과 연결하는 데 어려움을 겪는 접지(grounding) 문제를 야기한다.
VLM 에이전트가 무엇에 대해 추론해야 하는지, 그리고 어떤 방식으로 추론할 수 있는지 확립했으므로, 남은 질문은 보상 설계 및 우위 추정을 통해 이러한 추론을 어떻게 효과적으로 최적화할 것인가이다. 이를 위해, 우리는 LLM-as-a-Judge 프레임워크에서 파생된 밀집된 보상인 턴 수준의 월드 모델링 보상(WorldModeling Reward)을 도입하며, 이는 에이전트의 명시적인 상태 설명 및 예측의 정확도를 참 상태와 비교하여 평가한다. 나아가, 다중 턴 설정에서의 크레딧 할당은 우리가 제안하는 Bi-Level GAE(Bi-Level General Advantage Estimation)를 통해 최적화될 수 있으며, 이는 각 단일 단계 월드 모델링에서 크레딧 전파를 장려한다. 궤적의 끝에서 토큰별로 역방향으로 우위를 계산하는 표준 GAE 방법은 희소한 궤적 끝 신호가 장기간에 걸쳐 이동해야 하기 때문에 불안정한 보상 전파를 초래할 수 있다. 이 문제를 해결하기 위해, 우리는 먼저 턴 수준에서 우위를 계산하여 단일 단계 월드 모델링에서 VLM의 응답이 전반적으로 효과적인지 평가한 다음, 이 신호를 토큰 수준으로 전파하여 각 VLM 생성 토큰에 세밀한 우위를 제공하여 생성 프로세스를 최적화한다. 우리의 결과는 월드 모델링 보상과 Bi-Level GAE를 포함하는 우리의 VAGEN-Full 접근 방식이 이러한 메커니즘이 없는 VAGEN-Base보다 지속적으로 우수한 성능을 보여주며, 이는 조정된 전달 메커니즘을 통해 밀집된 보상을 제공함으로써 향상된 추론 품질과 더 높은 작업 성공률로 이어진다는 것을 입증한다.
우리는 환경 설정과 모델 훈련을 분리하여 효율적인 실험과 알고리즘 확장성을 가능하게 하는 확장 가능한 훈련 프레임워크인 VAGEN을 제시한다. 모든 실험은 다양한 시각적 환경에서 다중 턴 VLM 에이전트를 훈련하고 분석하기 위한 확장 가능한 시스템인 VAGEN 프레임워크의 지원을 받는다. 종합적으로, 본 연구는 명시적인 시각적 추론을 통해 내부 월드 모델을 구축할 수 있는 VLM 에이전트를 개발하기 위한 원칙적인 경로를 확립한다.
2. Build Internal World Models via Visual State Reasoning in Multi-Turn RL
2.1 Problem Formulation
우리는 다중 턴 VLM 에이전트 작업을 부분 관찰 가능 마르코프 결정 과정(POMDP)으로 구성하며, 이는 튜플 로 표현된다. 여기서 는 환경 상태 공간, 는 에이전트가 인지하는 관찰 공간, 는 행동 공간을 나타낸다. 각 턴 에서, 에이전트는 행동 를 생성한다. 이에 반응하여, 환경은 상태 전이 함수 에 따라 상태 에서 새로운 상태 로 전이하고, 스칼라 보상 를 방출한다. 그런 다음 에이전트는 새로운 상태의 부분적인 뷰인 새로운 관찰 를 수신하며, 이는 에서 샘플링된다. 에이전트의 목표는 궤적에 걸쳐 기대 누적 할인 보상(expected cumulative discounted return)을 최대화하는 정책 를 학습하는 것이며, 이는 이다. 여기서 는 할인 인자(discount factor)이다. VLM 에이전트 설정에서, 정책 는 이미지와 텍스트 설명을 관찰로 입력받아 언어 토큰 시퀀스를 행동으로 출력하는 VLM에 의해 매개변수화된다. 중요한 표기법 요약은 표 1에서 찾을 수 있다.
2.2 Visual State Reasoning as an Internal World Model
기존 VLM 추론을 위한 강화 학습(RL) 프레임워크는 주로 단일 턴 최적화에 기반을 두고 있으며, 이는 진화하는 상호 작용 맥락을 포착하는 능력을 제한한다. 다중 턴 에이전트 작업의 요구 사항을 더 잘 해결하기 위해, 우리는 [Ragen, Search-r1]에 영감을 받아 전체 상호 작용 궤적을 최적화하며, 시간이 지남에 따라 진화하는 내부 상호 작용 믿음(internal belief)을 유지하도록 제안한다. 우리는 시각적 상태 추론을 위한 다중 턴 궤적 최적화에 월드 모델링을 통합하는 훈련 프레임워크를 설계한다 (그림 1 참조).
Reasoning Trajectory Rollout for Multi-Turn VLM Agents. 각 궤적은 초기 상태 , 관찰 및 목표 로 시작한다. VLM 에이전트의 턴 에서의 관찰 는 시각적 이미지이며, 우리는 일반적으로 이를 해당 텍스트 프롬프트와 함께 VLM에 입력한다. 이후 VLM 에이전트는 현재 정책 를 사용하여 행동 를 생성한다. 시각적 상태를 추론하고 내부 믿음을 구축하기 위해, 생성된 행동 는 추론 토큰 와 실행 가능한 행동 를 모두 포함하는 텍스트 토큰의 시퀀스이다 (). 가 구문 분석되고 실행된 후, 환경은 피드백으로 보상 를 생성하고 새로운 상태 로 전이하며, 에이전트에게 새로운 관찰 을 제공한다. 이 과정은 턴에 걸쳐 반복되어 궤적 를 수집한다.
Visual State Reasoning as World Modeling. VLM 에이전트가 단순히 보이는 것에 따라 행동하는 대신, 우리는 환경의 내부 믿음을 구축하기 위해 시각적 상태에 대해 명시적으로 추론한다. 에이전트 작업, 특히 POMDP로 정의된 작업에서 에이전트의 시각적 관찰 는 실제 월드 상태 에 대한 뷰를 제공한다. 효과적으로 행동하기 위해, 에이전트는 현재 시각적 관찰이 실제로 무엇을 나타내는지 해석하고 미래 상태 변화를 예측해야 한다. 우리는 VLM 에이전트가 현재를 해석하는 상태 모델(상태 추정, StateEstimation)과 미래를 예측하는 전이 모델(전이 모델링, TransitionModeling)을 포함하는 구조화된 월드 모델의 내부 믿음을 구축하도록 명시적으로 추론 토큰 를 생성함으로써 이를 수행하도록 훈련한다. 구체적으로, 상태 추정은 시각적 관찰 를 은닉된 실제 상태 에 근사하는 상태 믿음 로 접지(grounding)하며, 이는 완전 관찰 가능 MDP와 비교하여 POMDP의 중심 과제를 강조한다. 한편, 전이 모델링은 잠재적인 다음 상태 의 믿음에 대해 추론하며, 에이전트가 턴 에서의 행동이 상태를 어떻게 전이시킬지 내부적으로 시뮬레이션할 수 있게 한다. 이 예측 단계는 다중 턴 궤적 계획에 중요하다. 우리는 시각적 상태에 대한 내부 믿음을 포착하고 업데이트하기 위해 추론 토큰 를 다르게 구성함으로써, 최소한의 전략(NoThink, FreeThink)부터 구조화된 월드 모델링(StateEstimation, TransitionModeling, WorldModeling)에 이르기까지 여러 추론 전략을 구현한다. 우리가 연구한 다섯 가지 추론 전략은 다음과 같다:
- NoThink: 우리는 VLM 에이전트가 오직 실행 가능한 행동 만 생성하도록 훈련하며, 출력 행동 토큰 는
<think></think><answer>ae t</answer>형식이고, 이다. - FreeThink: 우리는 VLM 에이전트가 미리 정의된 구조 없이 시각적 상태 추론이 나타나도록 허용하면서, 모든 형태의 자연어 추론을 생성하도록 훈련한다. 에이전트는
<think>zt</think><answer>ae t</answer>형식으로 행동 토큰을 생성하며, 는 비어 있지 않고 자연어 토큰이다. - StateEstimation: 우리는 VLM 에이전트가 시각적 관찰 가 주어졌을 때 현재 상태 믿음 를 명시적으로 언어화하도록 훈련하며, 이는 근본적인 실제 상태 에 근사하고 실행 가능한 행동 를 더 잘 예측하도록 돕는다. 행동 토큰 는
<think><observation></observation><reasoning></reasoning></think><answer></answer>로 구성되며, 이고, 에 근사하도록 학습한다. - TransitionModeling: 우리는 VLM 에이전트가 내부 믿음 공간에서 다음 상태 에 대해 명시적으로 시뮬레이션하도록 훈련하며, 이는 최상의 기대 보상으로 실행 가능한 행동 에 대해 추론하는 데 도움을 준다. 출력 행동 토큰 는
<think><reasoning></reasoning><prediction></prediction></think><answer></answer>로 구조화되며, 이고, 에 근사하도록 학습한다. - WorldModeling: 는 현재 상태를 설명하고 다음 상태를 예측하는 두 가지 모두를 요구한다:
<think><observation></observation><reasoning></reasoning><prediction></prediction></think><answer>/answer>형식이며, 이고, 및 에 근사하도록 학습한다.
이러한 구조화된 행동 형식에 엄격하게 따르도록 장려하기 위해, 우리는 DeepSeek-R1의 전략에 따라 훈련 중에 형식 보상 를 통합한다. 보상 설계에 대한 세부 사항은 2.3절에서 다룬다.
Policy Optimization. 궤적이 수집되면, 우리는 액터-크리틱 접근법을 사용하여 최적화 단계에 착수한다. 액터의 정책 는 근접 정책 최적화(PPO) 목적 함수를 사용하여 업데이트된다. 인코더 를 사용하여 궤적 로부터 변환된 토큰 시퀀스를 로 나타내고, 현재 정책과 이전 정책 간의 확률 비율을 로 나타내며, PPO 손실은 다음과 같이 정의된다:
여기서 는 행동 토큰에 대해 1이고 관찰 토큰에 대해 0인 마스크이며, 는 토큰별 우위(advantage)이고 는 클리핑 하이퍼파라미터이다.
Advantage and Value Estimation. 동시에, 가치 함수 의 크리틱 매개변수 는 예측값과 목표 가치 간의 제곱 오차를 최소화함으로써 업데이트된다.
액터와 크리틱 업데이트는 토큰별 우위 와 목표 가치 를 계산해야 한다. VAGEN-Base 설정에서, 우리는 토큰 수준 일반화 우위 추정(Token-Level GAE)을 사용한다. 각 토큰 인덱스 에서, 우리는 현재 정책 가 고정된 참조 정책 에 가깝게 유지되도록 장려하는 토큰별 KL 페널티를 적용하며, 이 페널티는 계수 에 의해 조정된다. 모든 중간 행동 토큰에 대해 보상 는 KL 페널티로 설정되며, 최종 행동 토큰 에서는 보상 가 KL 페널티와 전체 궤적 반환 로 설정된다.
그런 다음 우리는 할인 인자 와 GAE 매개변수 를 사용하여 시간차(TD) 오차 와 우위 를 계산한다.
이 재귀는 시퀀스 끝에서 로 초기화된다. 크리틱 업데이트를 위한 목표 가치는 로 정의된다. 궤적 수집, 우위 추정 및 정책 업데이트의 반복 과정은 수렴할 때까지 계속된다. 우리는 다중 턴 에이전트 RL 프레임워크에 대한 자세한 설명을 알고리즘 1에서 제시한다.
2.3 Reward Design in Different Environments and Tasks for VLM Agents

VLM 에이전트의 학습 역학 및 시각적 추론 능력을 체계적으로 분석하기 위해, 우리는 다섯 가지 고유한 에이전트 작업(그림 2)을 특징으로 하는 평가 도구를 개발한다. 이 작업들은 다양한 시각적 상태 표현과 행동 공간을 포함하여 광범위한 도전 과제를 다루도록 선택된다. 여기에는 고전 격자 퍼즐(Sokoban 및 FrozenLake), 체화된 3D 탐색(Navigation), 상세 객체 조작(PrimitiveSkill), 추상 기하학적 재구성(SVG Reconstruction)이 포함된다.
Sokoban: 이 고전 퍼즐에서 에이전트는 모든 상자를 목표 위치로 밀어야 한다. 시각적 상태는 2D 격자이며, 행동 공간은 이산적이다(위, 아래, 왼쪽, 오른쪽).
FrozenLake: 에이전트는 구멍을 피하면서 목표에 도달하기 위해 2D 격자를 탐색한다. 시각적 상태 및 이산 행동 공간은 Sokoban과 유사하며, 우리는 결정론(determinism)을 위해 "미끄러운(slippery)" 설정을 비활성화한다.
Navigation. 이 3D 체화 작업에서, 에이전트는 지침에 따라 객체를 찾고, 1인칭 시점으로 세상을 인지하며 이산적인 행동(예: 앞으로 이동)을 사용한다.
PrimitiveSkill. 에이전트는 Panda Arm을 제어하여 복잡한 조작을 수행하며, 하이브리드 행동 공간(예: pick(x,y,z))을 사용한다. 에이전트는 3인칭 3D 장면에서 객체를 좌표 목록에 접지해야 한다.
SVG Reconstruction. 에이전트의 목표는 개방형 텍스트 행동 공간을 사용하여 대상 이미지를 복제하는 SVG 코드를 생성하는 것이다.
Reward Strategy and Metrics. SVG 작업의 경우, 보상 는 생성된 이미지 와 대상 간의 밀집된 유사도이며, 이는 DreamSim 및 DINO 점수의 가중 조합으로 계산된다. 작업 성능은 최종 출력의 평균 DreamSim 및 DINO 유사도로 보고된다. 다른 작업들의 경우, 는 궤적이 목표를 완료했는지 여부를 나타내는 조정된 이진 보상(예: )이며, 성능은 평균 성공률 로 측정되며, 여기서 이다. 효율적인 RL 훈련을 가능하게 하기 위해 일부 환경은 원래 설정에서 수정되었으며, 전체 구현 세부 사항은 부록 A.4에 제공된다.
2.4 What Can We Reason About Visual States?
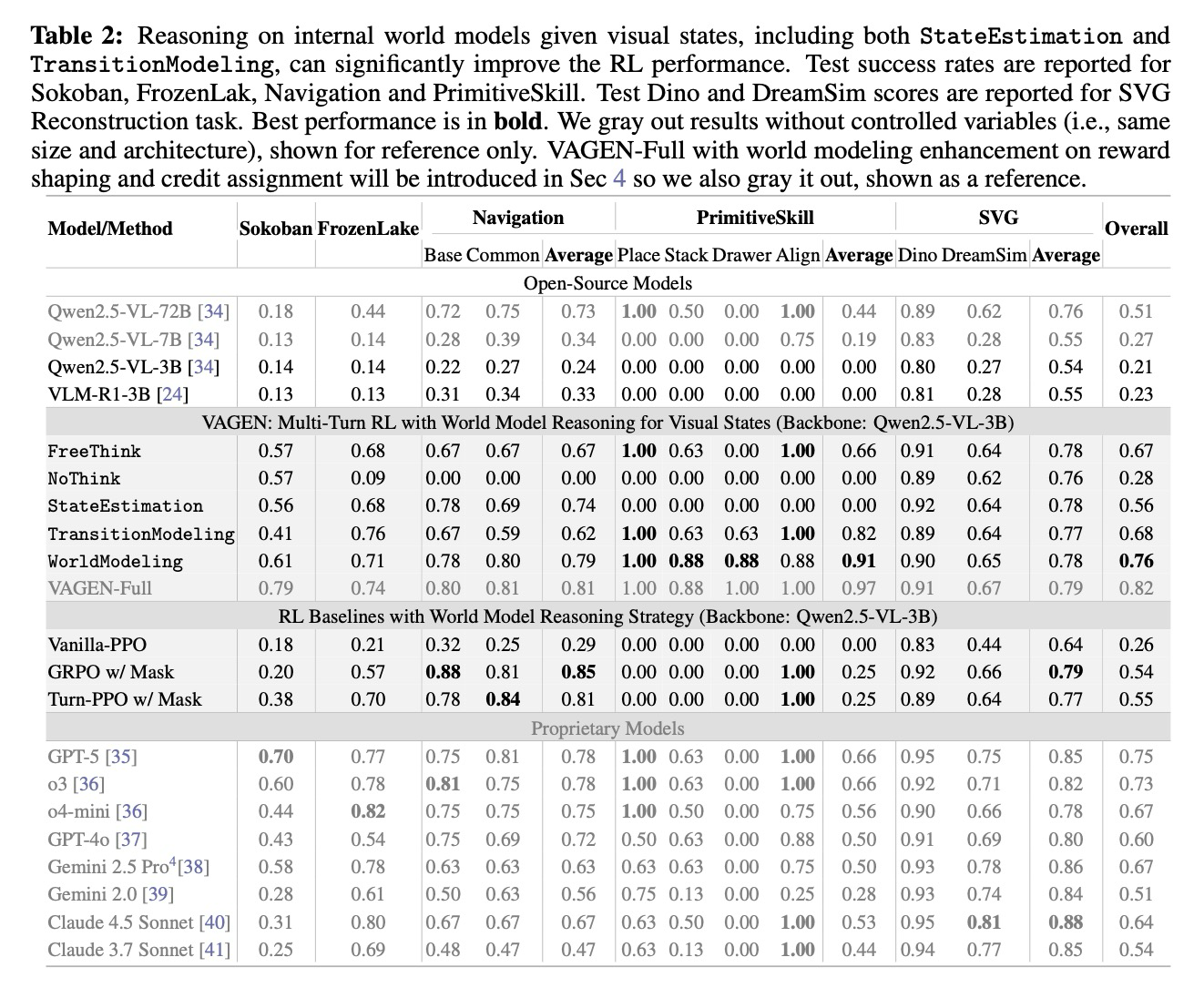
Off-the-Shelf VLMs struggle to solve multi-turn agentic tasks. 우리는 표 2에서 독점 모델과 오픈 소스 모델을 포함한 7가지 모델을 벤치마킹한다. 우리는 다양한 추론 전략을 사용하여 모델에 프롬프트를 제공하며, 이는 부록 B.1에 자세히 설명한다. 특히, VLM-R1과 같이 비 에이전트 작업을 해결하도록 훈련된 VLM은 다중 턴 에이전트 작업에서 이점을 보이지 않는다. 대신, 대부분의 모델이 이러한 작업에서 어려움을 겪으며, 최고 성능의 GPT-5도 전체 점수 1점 중 0.75점에 도달한다. 특히, PrimitiveSkill Drawer 작업에서는 성공한 모델이 없다. 이러한 결과는 복잡한 다중 턴 시각적 에이전트 작업에 대해 추론하는 현재 VLM의 능력에 중대한 격차가 있음을 나타낸다.
World Modeling can improve visual reasoning via multi-turn RL. 시각적 상태에 대한 명시적인 추론이 성능을 향상시키는지 확인하기 위해, 우리는 VAGEN-Base(2.2절)를 사용하여 다섯 가지 추론 전략으로 Qwen2.5-VL-3B 모델을 훈련한다. 표 2에 나타난 바와 같이, FreeThink는 NoThink보다 일관되게 우수한 성능을 보이며, 특히 Navigation 및 PrimitiveSkill과 같은 체화된 환경에서 그러한데, 이는 다중 턴 의사 결정 작업에서 명시적인 추론의 중요성을 나타낸다.
다양한 추론 전략 중에서 StateEstimation과 TransitionModeling은 작업별 강점을 보인다. StateEstimation은 현재 관찰을 이해하는 것이 핵심인 Navigation 작업에서 우수한 성능을 발휘한다. 이와 대조적으로, TransitionModeling은 미래 상태 예측이 조작에 필수적인 PrimitiveSkill에서 강력한 결과를 달성한다. 그러나 각 전략만으로는 모델의 사전 지식이 작업 구조나 상태 복잡성과 덜 일치하는 작업에서 성능 저하를 초래할 수 있다. 반면에, 결합된 WorldModeling 전략은 모든 작업에서 강력하고 안정적인 성능을 가져오며, 훈련된 모델은 훈련되지 않은 모델(+0.55)에 비해 상당한 개선을 이루고 규모가 작음에도 불구하고 모든 독점 모델보다 뛰어난 성능을 보인다. 이러한 결과는 명시적인 시각적 상태 추론이 VLM 에이전트에게 중요하다는 것을 입증한다. 후속 연구에서는 WorldModeling을 일반적인 시각적 추론 전략으로 사용한다.
Existing RL methods are inadequate for multi-turn VLM agents. 우리는 또한 VAGEN 프레임워크를 다른 RL 기준선과 비교한다. Vanilla PPO는 관찰 토큰 마스킹의 부족으로 인해 실패한다. 이미지/텍스트-텍스트 모델의 경우, 이미지 토큰이 모델의 생성 프로세스의 일부가 아니기 때문에 관찰 토큰으로부터 학습하는 것은 근본적으로 부정확하다. 이미지/텍스트-이미지/텍스트 모델의 경우에도 관찰 토큰으로부터 학습하는 것은 문제가 될 수 있는데, (1) 관찰 토큰이 에이전트 자신의 정책에 의해 생성되지 않고, (2) 긴 관찰 시퀀스가 학습 가중치 분포를 지배할 수 있기 때문이다. 마스킹이 적용된 Group Relative Policy Optimization (GRPO)는 장면 변화로 인한 높은 궤적 다양성 때문에 불충분하며, 감당할 수 없는 샘플 크기를 요구한다. 마스킹이 적용된 턴 수준 PPO는 턴 내 액션 토큰에 대한 균일한 우위 추정치가 정책 성능에 대한 개별 토큰 기여를 포착할 수 없기 때문에 저조한 성능을 보인다. 이러한 한계는 효과적인 VLM 에이전트 훈련을 위한 우리의 VAGEN 프레임워크 설계를 동기 부여한다.
3. How Can We Present Internal Beliefs about the World?
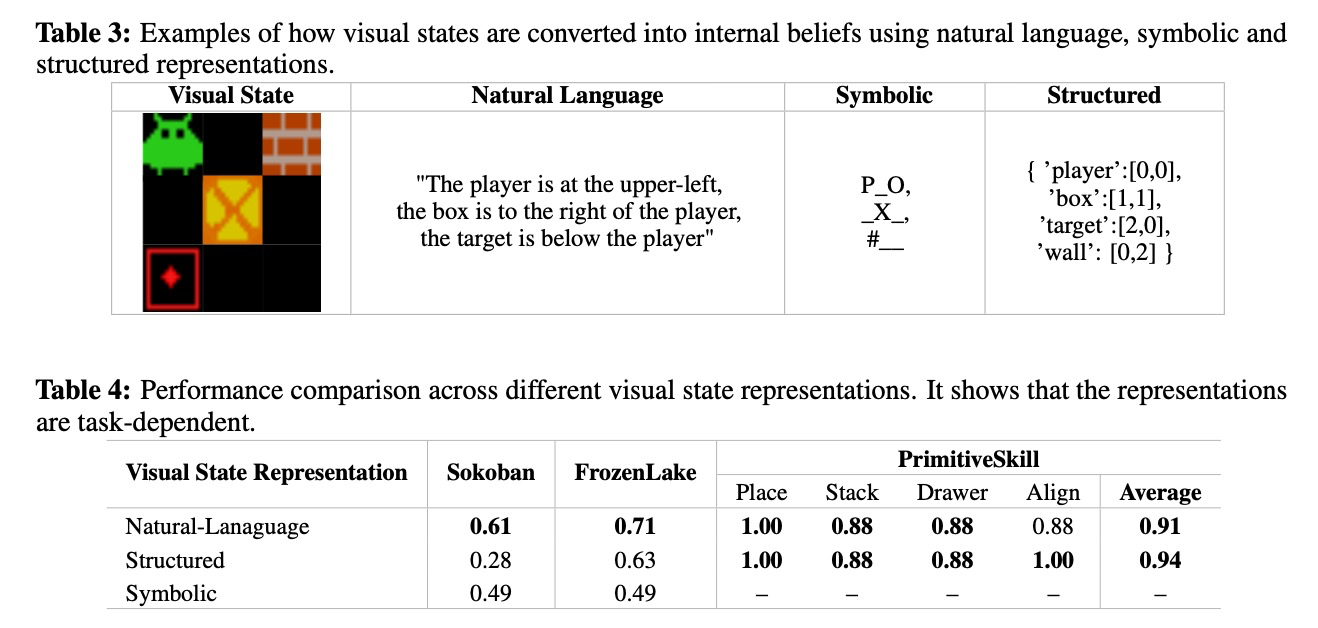
시각적 상태 추론을 더 깊이 이해하기 위해, 우리는 다양한 시각적 상태 표현이 작업 성능에 어떤 영향을 미치는지 조사한다. 우리는 표 3의 예시와 같이 세 가지 표현 방식인 자연어(Natural-Lanaguage), 기호(Symbolic), 구조화된 형식(Structured format)고려한다. 구체적으로, RL 훈련 중에 우리는 모델이 월드 모델링 추론 전략을 사용하도록 프롬프트하며, <observation> 및 <prediction> 필드에 특정 형식으로 출력하도록 요구한다. 우리는 이 실험을 FrozenLake, Sokoban, PrimitiveSkill 세 가지 작업에서 수행한다. FrozenLake와 Sokoban에서는 세 가지 형식을 모두 비교한다. 자연어 형식은 자유 형식의 텍스트 설명을 포함한다. 기호 형식은 환경 고유의 격자 기반 기호를 사용하며, 구조화된 형식은 플레이어, 목표물, 상자의 위치와 같은 작업별 정보가 포함된 딕셔너리를 출력하도록 모델에 요구한다 (자세한 내용은 부록 C에 있다). PrimitiveSkill 작업의 경우, 자연어 형식과 구조화된 형식을 비교한다.
Results and Insights. 우리의 실험은 시각적 상태 표현 방식의 선택에 있어 작업 의존적인 절충 관계가 있음을 보여준다. 표 4에 제시된 바와 같이, 최적의 형식은 작업의 특성에 따라 달라진다. FrozenLake와 Sokoban에서 자연어는 기호 및 구조화된 형식을 능가한다. 이는 모델이 기호 레이아웃을 효과적으로 해석하기 위한 충분한 사전 지식이 부족하고, 이미지 입력만으로 파생된 구조화된 출력은 접지 능력(grounding capabilities)의 한계로 인해 노이즈가 발생할 가능성이 높기 때문이다. 이러한 환경에서 자연어의 유연성과 친숙함은 사전 훈련 단계에서 모델이 습득한 능력과 더 잘 일치한다. PrimitiveSkill의 경우, 구조화된 형식이 자연어 형식을 약간 능가한다. 이는 모델에게 구조화된 객체 위치 목록을 프롬프트로 제공하여, 모델이 이해도를 더 정확하게 접지하고 다음 상태 예측을 더 용이하게 할 수 있었기 때문일 수 있다. 결과적으로, 우리는 후속 연구에서 자연어를 기본적이고 일반적인 목적의 상태 표현으로 채택하며, PrimitiveSkill 작업에는 구체적으로 구조화된 형식을 사용한다.
4. Can World Modeling Help with Reward Shaping and Credit Assignment?
VLM이 상태 추정(StateEstimation) 및 전환 모델링(TransitionModeling)에 대한 월드 모델로서 명시적으로 추론하도록 강제하는 것의 효과를 인식하고, 우리는 이러한 신호를 명시적으로 활용하여 보상 구조를 알리고 강화 학습 프레임워크에 대한 우위 추정(advantage estimation)을 최적화하는 방법을 추가로 탐색한다.
4.1 WorldModeling Reward
보상 형성(Reward shaping)은 특정 에이전트 행동을 유도하기 위한 일반적인 관행이다. 우리는 에이전트의 시각적 상태 이해를 감독하는 보상을 도입하는 것을 목표로 한다. 구체적으로, 우리는 에이전트의 응답에서 <observation> 및 <prediction> 필드를 추출하고, 이를 참값 시각적 상태(ground-truth visual states)와 비교하여 일치 점수를 기반으로 보상을 제공한다.
CLIP 기반 이미지-텍스트 유사성을 사용하여 보상을 계산하려는 초기 시도가 있었지만, CLIP은 미세한 공간 및 기하학적 세부 사항에 충분히 민감하지 않아 결과 보상 신호가 신뢰할 수 없음을 발견했다.
이러한 한계를 해결하기 위해, 우리는 LLM-as-a-Judge 접근 방식을 채택한다. 우리는 환경으로부터 시각적 상태에 대한 텍스트 기반 참값 정보를 얻으려고 시도한다. 예를 들어, Sokoban에서는 플레이어, 상자, 목표물의 2D 위치를 얻고, FrozenLake에서는 플레이어, 목표물, 구멍의 2D 위치를 추출한다. PrimitiveSkill의 경우, 객체 이름과 해당 좌표를 도출하고, Navigation의 경우, 객체로부터 플레이어까지의 상대 거리와 방향을 계산한다.
이러한 텍스트 기반 상태 정보를 활용하여, 우리는 에이전트의 추론( <observation> 및 <prediction> 내)과 참값 상태( 및 ) 간의 정렬 상태를 평가함으로써 월드 모델링 보상()을 계산한다. 이는 LLM-as-a-Judge가 직접적인 판단을 제공하거나, 규칙 기반 비교(예: F1-점수)를 위해 에이전트의 텍스트에서 구조화된 정보를 먼저 추출하는 하이브리드 평가 프로토콜을 통해 달성된다. 각 턴 에서의 보상은 다음과 같이 정의된다:
여기서 는 일반화된 일치 점수(직접 판단으로부터의 이진 점수 또는 규칙 기반 메트릭으로부터의 연속적인 정규화된 점수)이며, 는 보상 계수이다. 자세한 LLM-as-a-Judge 프롬프트와 평가 프로토콜은 Appendix D.1.에 있다.
4.2 Bi-Level General Advantage Estimation (GAE)
2.2절에서 설명된 VAGEN-Base 프레임워크는 월드 모델링 보상(WorldModeling Reward)을 통합할 때 핵심적인 한계를 드러낸다. 이는 궤적의 최종 토큰에서 모든 작업 보상을 집계함으로써, 단지 궤적 수준의 피드백만 제공하기 때문이다. 이 거친 신호는 단일 GAE 계산을 통해 역전파되며, 턴(turn)별 성공이나 실패에 대한 크레딧을 할당하기 어렵게 만든다. 이는 단계별 시각적 추론을 강화하는 데 특히 중요하다. 이 문제를 해결하기 위해, 우리는 더 세분화된 크레딧 할당 메커니즘인 Bi-Level GAE를 도입하며, 이는 미세 조정된 턴 수준의 보상 신호를 전달하도록 설계된다. 그림 3에 설명된 바와 같이, 이 접근 방식은 두 단계로 작동하며, 턴 간의 전이를 위한 턴 수준 할인 인자()와 단일 행동 내의 토큰을 위한 토큰 수준 할인 인자()를 도입한다.
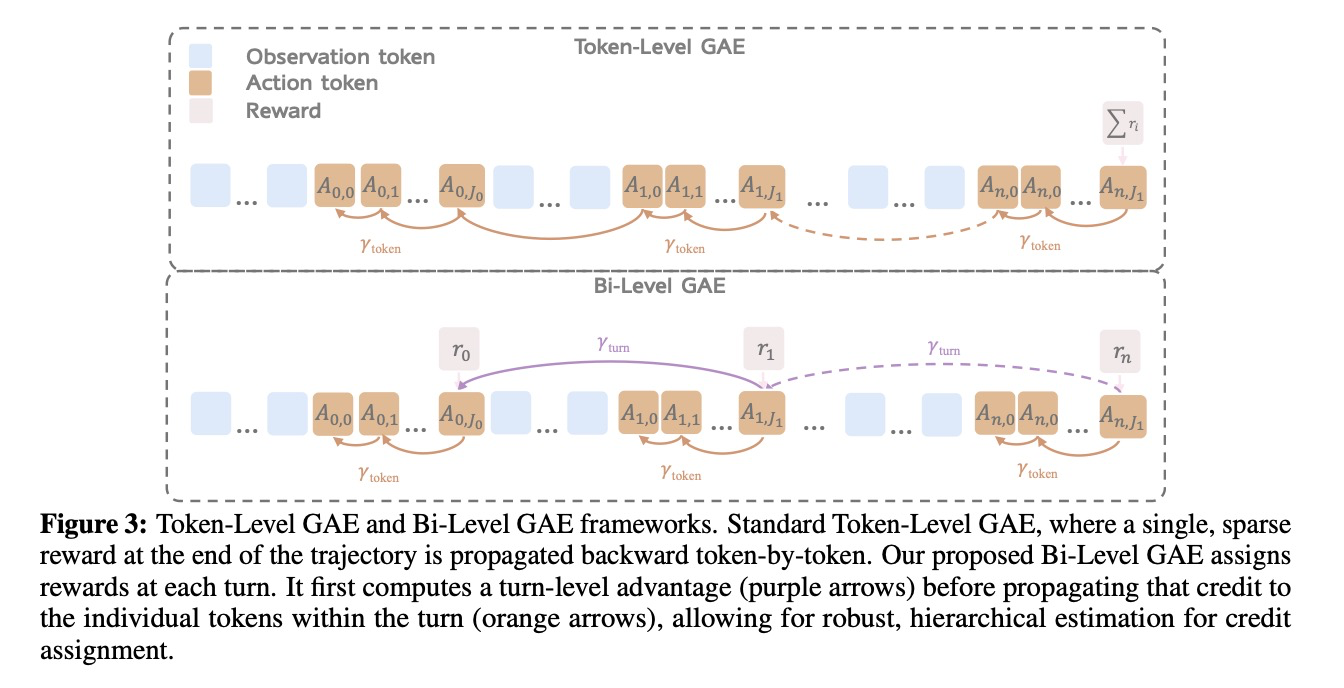
Turn-level advantage estimation: 우리는 궤적의 각 턴에 대한 우위 추정치를 계산한다. 주어진 턴 에 대해, 를 해당 턴에 할당된 총 보상이라고 하자 (그 구성은 4.3절에서 자세히 설명한다). 우리는 각 행동 시퀀스 끝에서의 크리틱의 가치 추정치 를 사용하여 턴 수준 TD 오차()를 정의한다:
여기서, 는 행동 까지의 궤적의 전체 토큰 접두사를 나타낸다. 최종 턴 의 경우, 다음 상태 가치 는 0으로 간주된다. 그런 다음 턴 수준 우위()는 GAE를 사용하여 재귀적으로 계산된다:
이 역방향 통과(backward pass)는 로 초기화되며, 여기서 는 턴 간 크레딧 할당을 위한 GAE 매개변수이다.
Token-level advantage estimation: 모든 턴 수준 우위 를 계산한 후, 우리는 각 행동 내의 토큰에 대해 두 번째 내부 GAE 계산을 수행한다. 행동 내의 주어진 토큰 에 대한 보상 는 KL 페널티 로 정의된다. 토큰 수준 TD 오차 및 우위는 행동 에 속하는 모든 토큰에 대해 계산된다:
두 수준을 연결하는 핵심 단계는 다음과 같이 발생한다: 토큰 수준 우위의 역방향 통과는 행동 의 최종 토큰의 우위를 미리 계산된 턴 수준 우위 로 설정하여 초기화된다. 이는 턴별 피드백을 행동의 끝에 주입하고, 생성된 모든 토큰으로 피드백이 역전파되도록 허용한다. 이 상세한 절차는 부록의 알고리즘 2에 제시되어 있다.
4.3 VAGEN-Full Multi-Turn Reinforcement Learning Framework

우리는 구조화된 추론 전략을 Bi-Level GAE 메커니즘과 결합하여 VAGEN-Full을 소개한다. 이 설정에서 우리는 명시적인 접지(grounding) 및 월드 모델링을 장려하기 위해 월드 모델링 보상(WorldModeling Reward)을 사용하여 에이전트를 훈련한다. Bi-Level GAE 계산에 사용되는 턴 수준 보상 ()은 다음과 같이 복합적인 합으로 정의된다:
여기서 는 시각적 상태( 및 )에 대한 월드 모델 추론의 품질에 대한 보상이고, 는 지정된 출력 구조를 준수하는 것에 대한 보상이며 (2.4절), 는 환경으로부터 오는 희소한(sparse), 작업별 보상이다. 나머지 훈련 파이프라인은 표준 GAE 모듈이 우위 추정을 위해 Bi-Level GAE로 대체된 VAGEN-Base 절차(2.2절)를 따른다.
Experiment Setup. 이제 우리는 VAGEN-Base와 VAGEN-Full을 모든 작업에 걸쳐 비교한다. VAGEN-Base(2.4절)는 형식 및 작업별 보상과 함께 월드 모델링 추론 전략을 사용한다. VAGEN-Full은 여기에 월드 모델링 보상과 Bi-Level GAE를 통합하며, 보상 계수 와 는 0.5로 설정된다. SVG 재구성의 경우, Bi-Level GAE만 적용된다. SVG 재구성은 월드 다이내믹스(world dynamics)가 없는 다중 턴 추론 작업이기 때문에, 우리는 Bi-Level GAE 구성만 적용하며, VAGEN-BASE에 Bi-Level GAE를 적용한 결과를 VAGEN-FULL 결과로 보고한다.
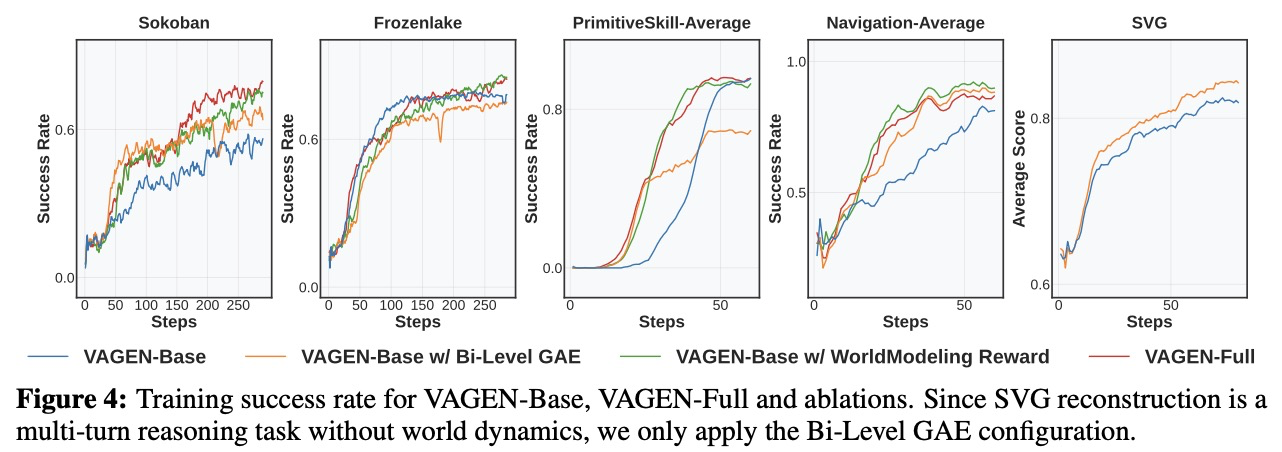
Results and Insights. 표 5에 나타난 바와 같이, VAGEN-Full은 VAGEN-Base에 비해 모든 작업에서 일관되게 더 나은 테스트 시점 성능을 달성한다. 이러한 격차는 PrimitiveSkill에서 특히 두드러지는데, 두 방법 모두 유사한 훈련 정확도에 도달함에도 불구하고 (그림 4), VAGEN-Full은 테스트 세트에서 VAGEN-Base보다 훨씬 우수한 성능을 보인다. 이는 상태 추정(StateEstimation)과 전환 모델링(TransitionModeling)이 에이전트가 새로운 장면에 적응하는 능력을 향상시켜 더 나은 견고성과 일반화 능력을 가져온다는 것을 시사한다.
4.4 Ablations
이 절에서는 Bi-Level GAE와 월드 모델링 보상(WorldModeling Reward)이 VAGEN에 기여하는 독립적인 요소를 연구한다. SVG 재구성은 월드 다이내믹스가 없는 다중 턴 추론 작업이므로, 우리는 Bi-Level GAE 구성만 적용한다,. 그림 4에서 흥미로운 패턴을 관찰한다:
- Bi-Level GAE 단독은 상당하지만 일관되지 않은 이득을 제공한다. 이는 보상 희소성과 정확도에 매우 민감하며, 밀집되고 정확한 중간 보상이 부족한 환경에서는 훈련 불안정성을 초래할 수 있다.
- 월드 모델링 보상 단독은 시각적 이해를 위한 중요한 학습 신호를 제공함으로써 기준선보다 일관되게 성능을 향상시킨다. 그러나 그 효과는 표준 강화 학습(RL)의 거친, 궤적 수준의 크레딧 할당에 의해 제한된다.
- VAGEN-Full은 모든 방법 중에서 가장 안정적이며 모든 작업에서 전반적으로 우수한 성능을 보인다.
이러한 관찰은 세분화된 크레딧 할당(Bi-Level GAE)과 고품질 추론 감독(월드 모델링 보상)이 VLM 추론을 효과적으로 개선하는 데 모두 필수적임을 입증한다. 모델(크기 및 계열별) 및 방법에 대한 추가 결과는 표 26에 보고되어 있다.
4.5 Case Studies and Findings

학습 역학을 더 잘 이해하기 위해, 우리는 그림 5에 나타난 Navigation, Sokoban, FrozenLake 세 가지 환경에 걸쳐 사례 연구를 수행한다. 에이전트 행동을 분석함으로써, 우리는 몇 가지 핵심적인 현상을 식별하며, 이는 부록 E에 자세히 설명한다.
Enhanced Spatial Understanding and Planning. 명시적인 시각적 상태 추론은 에이전트의 공간 인식과 다단계 계획 능력을 향상시킨다. VAGEN-Full로 훈련된 에이전트는 공간적 관계를 식별하고 차단 제약(blocking constraints)을 인식하는 능력을 개발하여, 더욱 효과적인 탐색 및 문제 해결 전략으로 이어진다. Navigation 작업에서 에이전트는 단순히 목표 객체를 식별할 뿐만 아니라 직접적인 경로를 방해하는 차단 객체도 인식하게 된다.
Response Convergence and Reduced Exploration. 응답 수렴의 명확한 패턴이 관찰되며, 이는 훈련이 진행됨에 따라 엔트로피의 꾸준한 감소로 정량적으로 반영될 수 있다. 이 현상은 월드 모델링 보상(WorldModeling Reward) 유무와 관계없이 발생하며, 이는 RL 훈련의 일반적인 패턴임을 시사한다. 질적으로는, 초기 단계 에이전트는 다양하고 서술적인 응답을 보이는 반면, 후기 단계 에이전트는 간결하고 템플릿화된 응답을 개발한다. 이러한 수렴은 에이전트가 작업 효율성을 위해 커뮤니케이션 패턴을 자연스럽게 최적화하는 학습 과정의 근본적인 측면을 나타낸다.
Reward Hacking and Over-optimization. 특정 시나리오에서 에이전트는 보상을 해킹하는 것을 학습한다. 그들은 깊은, 상태별 추론을 반드시 반영하지 않으면서도 LLM-as-a-Judge의 기준을 충족하는 일반적이고 광범위하게 적용 가능한 응답을 개발한다. 이러한 행동은 보상 과최적화의 한 형태로, 특히 Bi-Level GAE로 훈련된 에이전트에서 두드러지게 나타난다 (이는 보상 최대화에 있어서 Bi-Level GAE의 효과를 강조한다). 예를 들어, "플레이어는 선물 위치에 있을 것이다"와 같은 응답은 다양한 상태 구성에 적용될 수 있는 보편적인 패턴으로 나타난다. 우리는 이러한 과최적화를 완화할 수 있는 몇 가지 방법을 개발했으며, 이는 부록 D.2에서 다룬다.
5. Related Work
RL for LLMs and VLMs. 최근 연구들은 LLM 및 VLM 모두를 위한 RL을 탐구하며, 접근 방식은 Ziegler et al.부터 Bai et al.과 같은 인간 피드백을 통한 RLHF부터 DeepSeek-r1, Gemini, Sun et al.과 같은 규칙 기반 보상 함수에 이르기까지 다양한다. 다중 턴 RL 훈련의 경우, Zhai et al.에서는 VLM에 PPO를 적용하지만, 이 연구에서는 시각적 추론을 위한 과거 맥락을 활용하여 POMDP 시나리오를 더 잘 지원하는 궤적 기반 최적화 전략을 채택한다. 이와 동시에 Archer 및 Sweet-rl에서는 텍스트 전용 환경에서 LLM 정렬을 위한 계층적 RL 프레임워크를 개발한다. 이 연구는 Archer의 계층적 설계와 유사하지만, 완전히 다른 최적화 전략을 가진 Bi-Level GAE를 제안한다.
Multi-turn Agent Training for LLMs and VLMs. 다중 턴 상호 작용은 LLM을 위한 에이전트 작업의 기본이다. VLM의 경우, 이러한 도전 과제는 상호 작용 전반에 걸쳐 일관된 시각적 상태 표현을 유지하는 더 복잡한 영역으로 확장된다. 이전 연구에서는 Voyager, Wang et al., Mobile-agent와 같은 프롬프트 기법과 Szot et al. 및 Chen et al.과 같은 추가 어댑터가 있는 고정 LLM/VLM을 포함한 다양한 접근 방식을 탐색했다. 이 연구는 다중 라운드 시각적 상태 추론을 강화 학습과 통합하는 더 근본적인 수준으로 확장한다. 이러한 접근 방식은 Embodiedbench, Maniskill-hab, ALFWorld, Starvector, Partnr를 포함한 다양한 벤치마크에서 일반화 가능성을 보여주며, VLM은 핵심 추론 엔진으로 점점 더 활용되고 있다. 이 연구와 동시에, 다중 턴 VLM 에이전트를 훈련하기 위한 여러 프레임워크가 등장했다. GiGPO는 장기적인 크레딧 할당을 목표로 하며, AReaL은 대규모 추론/에이전트 모델을 위한 완전 비동기식의 확장 가능한 RL 시스템을 제공하고, DART는 분리된 훈련 및 적응형 데이터 큐레이션을 통해 GUI 에이전트를 개선한다. 이 연구는 다중 턴 VLM 에이전트 훈련에서 명시적인 시각적 상태 추론을 통해 내부 월드 모델을 구축하는 데 중점을 둔다.
World Model Reasoning and Visual State Reasoning. 시각적 추론에 대한 최근 연구는 Sarch et al. 및 Tong et al.과 같은 시각적 인식 및 접지(grounding)와 Palit et al.과 같은 VLM에서의 인과 관계 추적, 그리고 Basu et al.과 같은 단일 턴 시나리오에서의 시각적 정보 흐름을 탐색했다. 그러나 내부 월드 모델 구축과 같이 여러 상호 작용 턴에 걸쳐 시각적 상태 추론을 유지하는 것은 여전히 충분히 탐색되지 않은 도전 과제이다. 이 연구와 동시에, 월드 모델링이 CWM에 의해 코드 생성에 적용되었다. 이 연구는 VLM이 연속적인 턴에 걸쳐 환경 역학에 대한 추론을 개선하는 데 중점을 두고, 다중 턴 상호 작용 중에 시각적 상태에 대한 내부 믿음을 일관되게 유지하고 업데이트하는 방법을 조사함으로써 이러한 격차를 해소한다.
6. Conclusion and Limitations
우리는 상태 추정(StateEstimation, 접지) 및 전환 모델링(TransitionModeling, 예측)에 대한 명시적인 시각적 상태 추론을 통해 내부 월드 모델을 구축하도록 추론 과정에 보상을 제공하는 다중 턴 강화 학습 프레임워크를 소개한다. 이러한 방식으로, VLM 에이전트는 환경을 탐색하여 인과/전환 동역학을 이해하고, 다중 턴 상호 작용이 전개됨에 따라 내부 믿음을 업데이트하는 것을 학습한다. 에이전트의 월드 모델 추론을 최적화하기 위해, 우리는 에이전트의 내부 상태 시뮬레이션의 정확도를 참값과 비교하여 평가하기 위한 밀집된 턴 수준 보상인 턴 수준 월드 모델링 보상(WorldModeling Reward)을 제안한다. 또한, 장기간 크레딧 할당이라는 중요한 문제를 해결하기 위해, 우리는 Bi-Level GAE를 제안하며, 이는 먼저 전체 턴 추론의 가치를 계산한 다음, 해당 크레딧을 개별 토큰에 정확하게 전파한다. 우리의 VAGEN 프레임워크는 에이전트 작업에서 VLM의 작업 성능과 시각적 추론 품질을 크게 향상시킨다. 한계점으로는 제한된 모델 아키텍처 및 평가 환경이 포함된다. 향후 연구에는 추가 VLM 계열 탐색 및 다중 턴 시각적 이해를 위한 지도 미세 조정이 포함될 것이다.
