NormGenesis: Multicultural Dialogue Generation via Exemplar-Guided Social Norm Modeling and Violation Recovery
Paper Translate
Author: Minki Hong, Jangho Choi, Jihie Kim
Affilation: Dongguk University
Venue: EMNLP 2025
Comments: SAC Highlights Award
Date: September 2025
Paper Link: link
⭐️ Key Takeaways
1. NormGenesis 프레임워크는 영어, 중국어, 한국어에 걸쳐 사회적으로 근거한 대화를 생성하기 위해 예시 기반 반복 정제 전략을 도입하는데, 이는 완전한 대화 생성이 시작되기 전에 언어적, 사회문화적 기대치와의 조기 정렬을 가능하게 하여 저자원 언어의 화용론적 일관성을 향상시킨다.
2. 이 논문은 규범 위반 이후의 인식 및 사회적으로 적절한 복구(repair) 과정을 모델링하는 V2R(Violation-to-Resolution)이라는 새로운 대화 유형을 제안하며, 이는 윤리적으로 민감한 상황에서 모델의 향상된 화용론적 역량을 보여주는 훈련 신호로서의 유용성을 강조한다.
3. 이 프레임워크를 사용하여 규범 준수, 화자 의도 및 감정적 응답에 대해 발화 수준으로 주석이 달린 10,800개의 다중 턴 다문화 대화 데이터셋을 구축했으며, 인간 및 LLM 기반 평가 결과 정제 품질, 대화 자연스러움, 일반화 성능 측면에서 기존 데이터셋을 크게 능가한다는 것이 입증되었다.
Abstract
사회적 규범은 의사소통에서 문화적으로 적절한 행동을 규율하며, 대화 시스템이 일관성 있을 뿐만 아니라 사회적으로도 수용 가능한 응답을 생성할 수 있도록 한다. 논문에서는 영어, 중국어, 한국어 전반에 걸쳐 사회적으로 근거한 대화를 생성하고 주석을 달기 위한 다문화 프레임워크인 NormGenesis를 제시한다.
정적인 규범 분류를 넘어 사회적 상호작용의 역동성을 모델링하기 위해, 저자들은 규범 위반 이후의 대화 진행 과정을 인식 및 사회적으로 적절한 복구를 통해 모델링하는 새로운 대화 유형인 V2R(Violation-to-Resolution)을 제안한다. 소수 언어(underrepresented languages)에서 화용론적 일관성을 개선하기 위해, 논문은 대화 합성 프로세스의 초기 단계에서 사례 기반 반복 정제(exemplar-based iterative refinement)를 구현한다. 이 설계는 완전한 대화 생성이 시작되기 전에 언어적, 감정적, 사회문화적 기대치와의 정렬을 도입한다.
이 프레임워크를 사용하여, NormGenesis는 규범 준수, 화자의 의도 및 감정적 응답에 대해 발화 수준(turn level)으로 주석이 달린 10,800개의 다중 턴 대화 데이터셋을 구축한다. 인간 및 LLM(대규모 언어 모델) 기반 평가는 NormGenesis가 정제 품질, 대화 자연스러움, 일반화 성능 측면에서 기존 데이터셋보다 훨씬 우수함을 입증한다. 논문은 V2R이 보강된 데이터로 훈련된 모델이 윤리적으로 민감한 상황에서 향상된 화용론적 역량을 보여준다는 것을 입증한다. 이 연구는 문화적으로 적응 가능한 대화 모델링을 위한 새로운 벤치마크를 확립하고, 언어적, 문화적으로 다양한 언어 전반에 걸쳐 규범 인식 생성(norm-aware generation)을 위한 확장 가능한 방법론을 제공한다.
1. Introduction
사회 규범은 특정 맥락에서 적절한 행동을 안내하는 문화적으로 정의된 기대치이다. 인간의 의사소통에서, 사회 규범은 공손함, 공감, 그리고 사회적 조화를 뒷받침한다. 대화 시스템의 경우, 사회 규범에 맞추는 것은 구문적 정확성이나 작업 완료를 초월하는 응답을 가능하게 하며, 화용론적 및 대인관계적 적절성에 기여한다. 대화형 에이전트가 사회적으로 내재되고 공개 도메인 설정에 점차적으로 배포됨에 따라, 문화적 규범을 인식하고 준수하는 능력은 사회적 및 화용론적 역량의 중요한 지표가 되었다.
최근 연구들은 사회 규범을 대화 데이터셋과 언어 모델에 통합해 왔다. 이전 연구들은 언어 모델에서의 도덕적 추론(Social chemistry 101), 규범 기반 라벨링(Normdial), 감정 정보에 기반한 규범 해석(RENOVI), 그리고 교차 문화 일반화(NormAd) 등을 탐구했다. 이러한 노력들이 규범 인식 생성(norm-aware generation)을 위한 기초를 다지고 있지만, 주로 고자원 언어인 영어에 초점을 맞추고 있다. 중국어는 증가하는 관심을 받아왔지만, 저자원 언어에 대해서는 문화적으로 적절한 행동 모델링이 여전히 미흡하다. 이러한 한계는 한국어에서 특히 두드러지는데, 기존 모델들은 존칭 사용의 불일치, 부적절한 감정적 정렬, 역할 기반 사회 역학의 오해(misrepresentation)를 자주 보인다. 이는 그림 1에 나타나 있다.

Figure 1: Comparison of generation outputs in Korean
기존 대화 데이터셋의 문화적 및 화용론적 한계를 해결하기 위해, 이 연구는 영어, 중국어, 한국어 전반에 걸쳐 사회적으로 근거한 대화를 생성하고 정제하기 위한 다문화 프레임워크를 제시한다. 영어는 광범위한 데이터와 모델링 성숙도의 이점을 누리지만, 저자원 언어 생성은 화용론적 불일치, 특히 어조와 형식성(formality)에서 어려움을 겪고 있다. 이 연구는 예시 기반 반복 정제 전략을 통해 이러한 격차를 완화한다. 대상 시나리오가 주어지면, 시스템은 의도, 감정적 어조, 담화 패턴(예: 화자 역할 및 인접성)과 같은 특징을 사용하여 의미론적 및 구조적으로 정렬된 예시를 검색한다. 이러한 예시는 대규모 인간 주석 없이도 문화적 정렬을 보장하기 위해 수정(revision)을 안내한다.
또한 이 연구는 화자가 맥락적으로 적절한 복구(repair)를 통해 규범 위반으로부터 어떻게 회복하는지를 포착하는 새로운 대화 범주인 V2R(Violation-to-Resolution)을 도입한다. 이는 규범 준수와 사회적 복구 메커니즘을 모두 반영하는 화용론적으로 역동적인 상호작용 모델링을 가능하게 한다. NormGenesis는 대화 행위 이론에 근거하여 규범 준수, 위반, 화자 의도 및 감정적 응답에 대해 발화 수준(turn level)으로 주석이 달린 10,800개의 고품질 대화 데이터셋을 구축한다. 연구에서는 정제 품질, 대화 유창성, 사회적 적절성 및 일반화에 대한 인간 및 LLM 기반 평가를 통해 이 연구의 접근 방식을 평가한다. 실험 결과는 NormGenesis의 데이터로 훈련된 모델이 사회적으로 복잡하고 감정적으로 민감한 시나리오에서 기존 기준선보다 훨씬 뛰어난 성능을 보인다는 것을 보여준다. 이러한 결과는 유형학적으로 다양한 언어 전반에 걸쳐 문화적으로 적응 가능한 대화 생성을 가능하게 하는 NormGenesis의 효능을 입증한다.
이 논문의 기여는 다음과 같다:
- 영어, 중국어, 한국어로 사회적으로 근거한 대화를 생성하기 위한 다문화 프레임워크를 제시한다. 저자원 환경에서의 문화적 및 화용론적 품질 저하를 해결하기 위해, 의미론적으로 관련된 예시를 사용하는 예시 기반 반복 정제 전략을 제안한다.
- 규범 위반이 사회적으로 적절한 복구(repair)로 이어지는 방식을 모델링하는 새로운 대화 유형인 V2R(Violation-to-Resolution)을 제안하며, 이는 동적이고 문화적으로 의미 있는 상호작용 패턴의 표현을 가능하게 한다.
- 대화 행위 이론에 근거하여 규범 준수, 화자 의도 및 감정적 응답에 대한 발화 수준 주석이 달린 10,800개의 다문화 대화 데이터셋을 구축한다.
- 연구에서 생성된 데이터셋으로 훈련된 모델이 인간 및 자동 평가 모두에서 확인된 바와 같이 규범 정렬, 감정적 일관성 및 복구 측면에서 이전 자원보다 뛰어난 성능을 보인다는 것을 보여준다.
2. Related Work
2.1 Social Norms in Dialogue Systems
대화 시스템에 사회 규범을 통합하는 것은 문맥적으로 적절하고 사회적으로 일관된 응답을 생성하는 데 중요하다. Social chemistry 101은 도덕적 판단을 통해 규범적 신호를 제공했지만, 대화 구조가 부족했다. NormDial은 다중 턴 대화에 규범 주석을 추가했지만, 위반에 대한 응답을 모델링하지 않고 주로 규범 준수 분류에 중점을 두었다. RENOVI는 대화에서의 규범 복구(norm repair)를 모델링하기 시작했다. 그러나 이 연구는 단일 언어(monolingual)이며, 화자의 의도와 감정적 응답을 포착하는 세밀한 주석이 부족하다는 한계를 가진다.
이러한 격차를 해소하기 위해, 이 연구에서는 사과와 설명과 같은 복구 전략을 포착하는 독립적인 응답 유형인 V2R(Violation-to-Resolution)을 도입한다. 또한, NormGenesis 프레임워크는 의사소통 의도와 감정 상태에 대한 발화 수준 주석을 통해 이를 지원하며, 더욱 미묘하고 사회적으로 유능한 생성을 가능하게 한다.
2.2 Prompt-Based and Exemplar-Guided Generation
LLM(대규모 언어 모델)의 등장은 인컨텍스트 학습(in-context learning) 및 프롬프트 튜닝(prompt tuning)과 같은 기술을 통해 프롬프트 기반 합성 데이터 생성을 가능하게 했다. 이러한 방법은 고자원 환경에서는 효과적이지만, 저자원 언어에서는 문화적 및 감정적 뉘앙스를 포착하지 못하는 경우가 많다. 최근 접근 방식(PromptRefine)은 예시 기반 생성을 탐색하고 있지만, 일반적으로 고정된 예시에 의존하며 화용론적 적합성보다는 유창성을 우선시한다. SADAS 또한 예시 기반 개선을 통해 규범 개입을 조사했지만, 이는 협상 대화에서 위반이 발생한 후 사후적(reactively)으로 예시를 적용하며, 사후 복구에만 국한되었다.
이러한 한계를 해결하기 위해, 연구는 예시 기반 반복 정제 전략을 제안한다. 추론 시점에 정적 예시를 사용하는 퓨샷(few-shot) 프롬프팅과 달리, 이 방법은 의미론적 및 구조적으로 관련된 예시를 동적으로 선택하여 생성을 안내한다. 이 과정은 언어적 일관성과 문화적 정렬을 개선하며, 특히 한국어와 같은 저자원 언어에서 대규모 인간 주석 없이도 데이터 부트스트래핑을 가능하게 한다.
2.3 Culturally Adaptive Dialogue
대화형 AI 시스템이 다양한 문화적 맥락으로 확장됨에 따라, 문화적 적응성이 필수적이다. BITOD 및 MULTI3WOZ와 같은 초기 다국어 데이터셋은 이중 언어 대화를 도입했지만, 번역에 의존했기 때문에 문화적 주석이 부족했고 화용론적 뉘앙스를 포착하는 데 실패했다. CARE 및 CULTUREPARK를 포함한 최근 연구들은 문화적 선호도를 통합하고 LLM을 통해 교차 문화적 상호작용을 시뮬레이션한다. 그러나 이러한 리소스는 고자원 언어에 초점을 맞추고 있으며, 문화적으로 적절한 생성에 필요한 세밀한 발화 수준 주석이 부족하다.
이러한 격차는 존칭어와 관계 화용론이 중심인 한국어와 같은 소수 언어에서 더욱 두드러진다. 이를 해결하기 위해, 연구자들은 언어별 하위 규범과 발화 수준 주석을 갖춘 다문화 프레임워크를 제안한다. 예시 기반 반복 정제를 사용하여, 이 방법은 특히 저자원 환경에서 문화적 및 화용론적 일관성을 향상시킨다.
3. Method
이 연구는 사회적으로 근거한 대화를 생성하고 정제하기 위한 다문화 프레임워크인 NormGenesis를 도입한다. 이 프레임워크는 미국식 영어, 중국어, 한국어 전반에 걸친 대화를 다룬다.
이 연구는 프레임워크에서 "영어"를 광범위하게 언급하지만, 이 데이터셋은 주로 미국 코퍼스 및 사회문화적 프레임워크에서 파생된 미국 기반의 사회 규범을 반영한다는 점을 명확히 한다. 이러한 명시는 문화적 정확성을 보장하며 다른 영어 사용 맥락(예: 영국, 호주, 캐나다)의 다양한 규범적 관행과 혼동되는 것을 피하고자 한다.
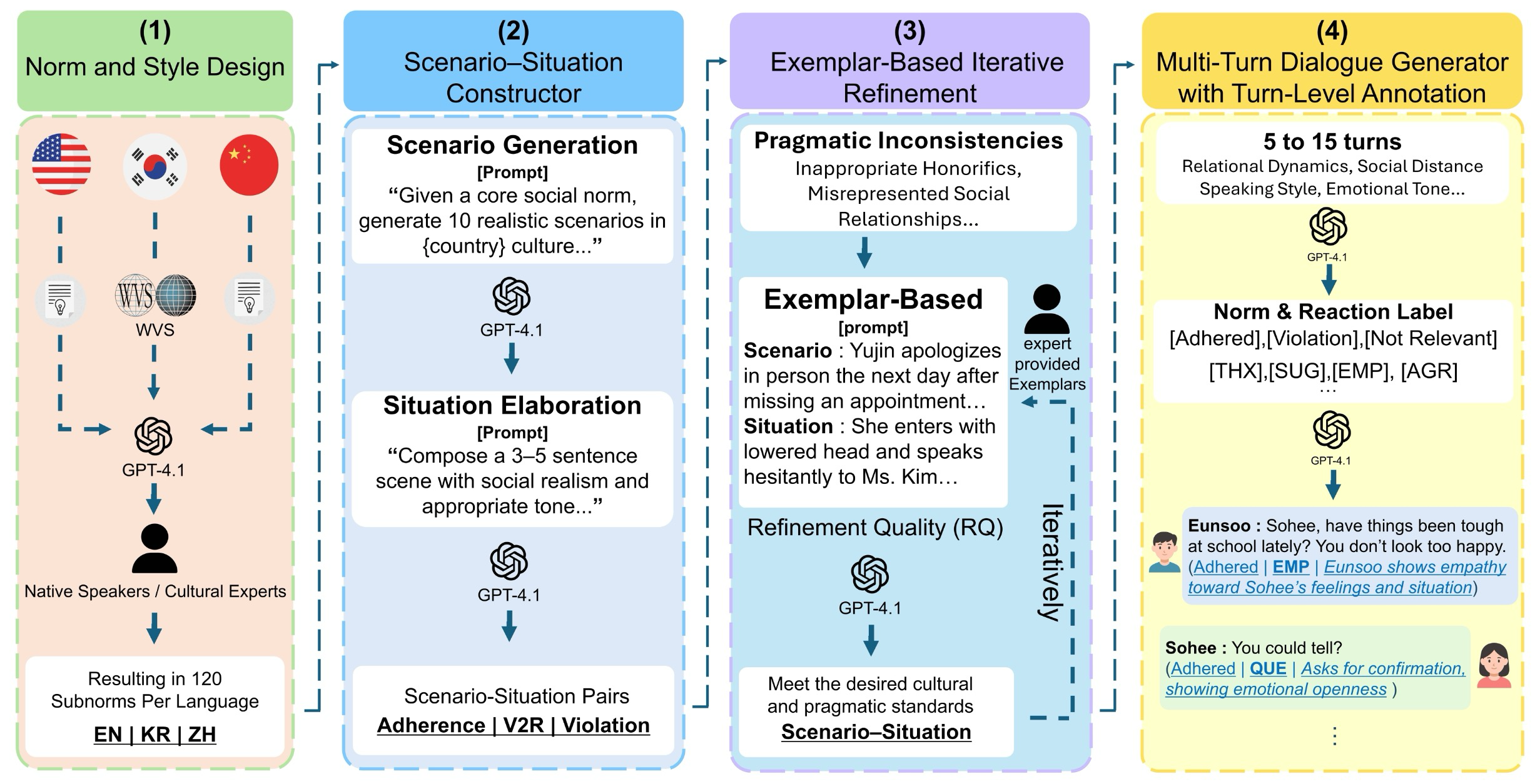
이 프레임워크는 사회적 의사소통을 모델링하는 네 가지 핵심 단계로 구성된다. 네 단계는 다음과 같다:
- 규범 및 스타일 설계 (norm and style design)
- 시나리오-상황 구성 (scenario-situation constructor)
- 예시 기반 반복 정제 엔진 (exemplar-based iterative refinement engine)
- 발화 수준 주석이 있는 다중 턴 대화 생성기 (multi-turn dialogue generator with turn-level annotation)
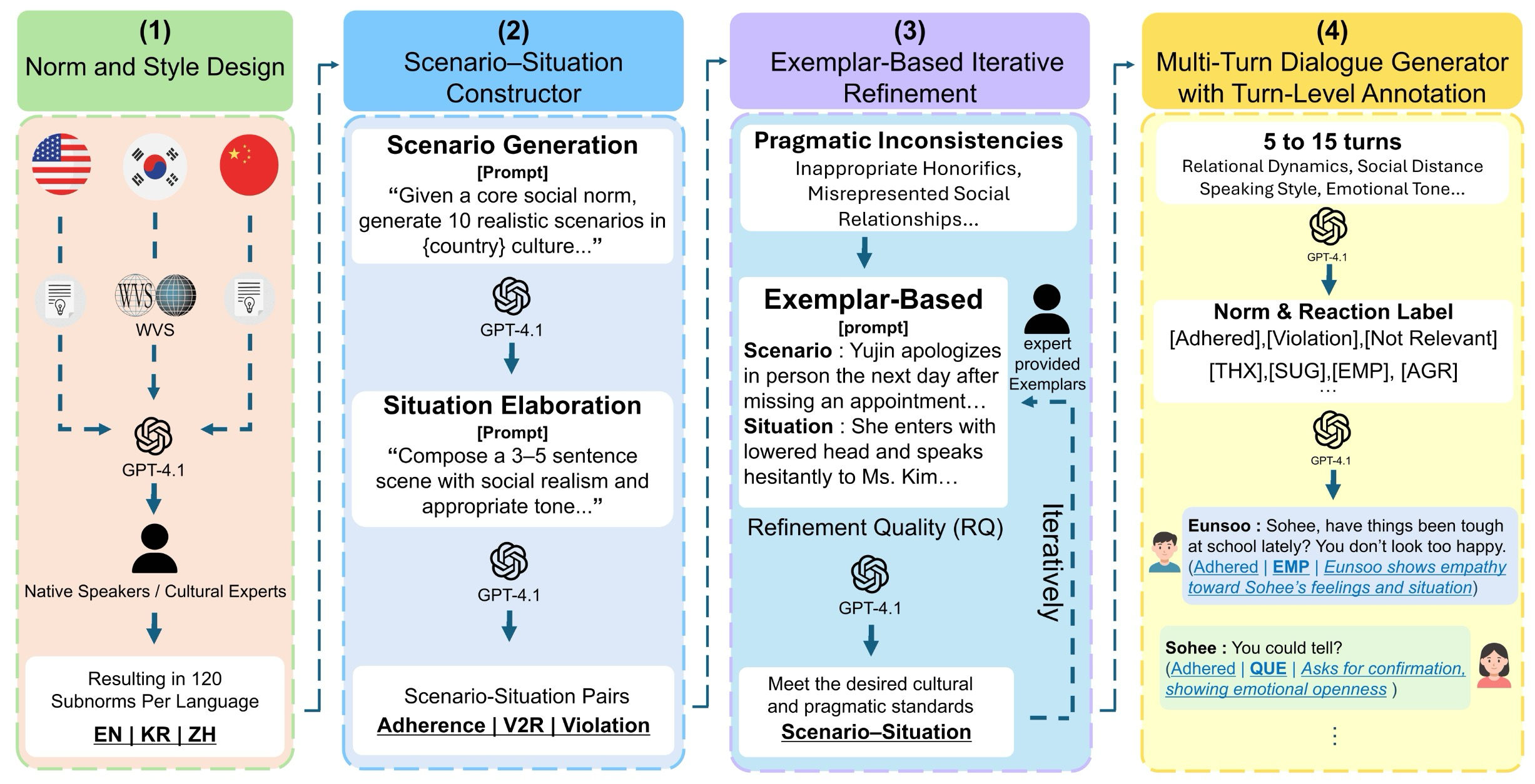
Figure 2: NormGenesis Overview
그림 2는 전체 파이프라인과 단계 흐름을 보여준다.
3.1 Norm and Style Design
NormDial에서 제안된 10가지 범주를 확장하여 12가지 대화 사회 규범 범주의 분류 체계를 구축한다. 대화 기능에 대한 이전 연구(Stolcke et al., 2000; Bunt et al., 2020)에 근거하여 공감(Empathy)과 존중(Respect)이라는 두 가지 유형을 추가하여 범주를 확장했다. 전체 범주 목록은 표 1에 나열되어 있다.
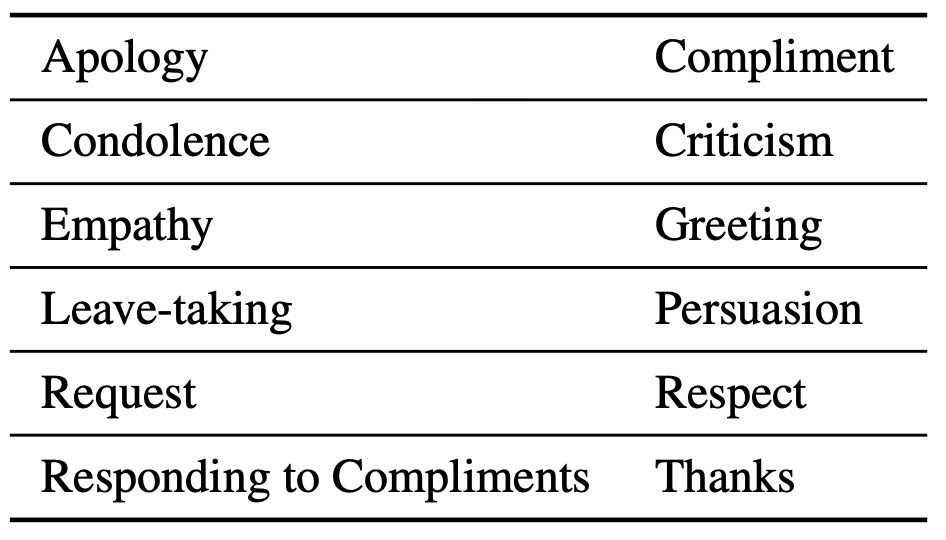
Table 1: Social norm categories
각 범주에 대해, 대상 언어별로 10개의 문화적으로 근거한 하위 규범(subnorms)을 정의한다. 한국어에 특화된 하위 규범을 생성하기 위해, LLM에게 세계 가치 조사(WVS Wave 7, South Korea)의 가치 중심 응답을 프롬프트로 제공했다. 영어 및 중국어 하위 규범은 NormDial에서 채택되었으며, LLM 가이드 정렬을 통해 한국어 결과물에 맞춰 조정된다.
유창성과 문화적 타당성을 보장하기 위해, 모든 하위 규범은 원어민 또는 문화 전문가에 의해 검증되었으며, 그 결과 언어당 120개의 하위 규범이 생성되었다 (그림 2 (1)). 또한 시나리오 구성과 대화 생성을 모두 안내하는 화용론적 및 스타일적 매개변수를 정의한다. 이러한 매개변수에는 어조(격식 vs. 비격식), 존칭 사용, 관계적 거리(동료 vs. 계층적), 그리고 감정적 정렬이 포함된다.
3.2 Scenario-Situation Constructor
각각의 하위 규범에 대해, 다음으로 구성된 시나리오-상황 쌍을 구축한다: (a) 시나리오: 간결하며 실제 세계의 맥락을 제공한다. (b) 상황: 관계 역할, 감정 상태, 그리고 어조 및 존칭과 같은 스타일적 특징을 3~5문장으로 구체화하여 시나리오를 확장한다.
각 인스턴스는 세 가지 상호작용 유형 중 하나로 레이블이 지정된다:
- 규범 준수(Norm Adherence).
- 규범 위반(Norm Violation).
- 위반-해결(Violation-to-Resolution, V2R).
앞의 두 유형이 기존의 규범 순응 또는 위반을 반영하는 반면, V2R은 위반 후 복구 전략을 모델링한다. 이는 상호작용 역량의 핵심 측면을 포착한다. V2R은 이전 규범 기반 대화 데이터셋에 거의 없었으며, 이 작업이 V2R을 사회적 대화 모델링에 공식적으로 정의하고 통합한 최초의 작업이다.
그림 2 (2)에 나타나 있듯이, 시나리오는 먼저 하위 규범과 상호작용 유형을 사용하여 LLM에게 프롬프트로 제공되어 생성된다. 그런 다음 이 시나리오는 대인 관계 및 감정적 신호가 풍부한 두 번째 프롬프트를 통해 상황으로 확장된다. 특히, 영어 결과물은 일반적으로 유창했지만, 한국어 및 중국어 생성 결과는 종종 화용론적 불일치(예: 어조 불일치, 부정확한 존칭)를 포함했다. 이러한 문제는 3.3절에 설명된 예시 기반 정제(refinement)를 사용해야 할 동기가 되었다
3.3 Exemplar-Based Iterative Refinement
대화 생성 후 사후 필터링이나 수동 교정에 의존하는 기존 접근 방식(Lambert et al., 2024; Occhipinti et al., 2024)과 달리, 이 프레임워크는 문화적 및 화용론적 제약의 조기 실행을 가능하게 하는 상류 정제 메커니즘을 시나리오-상황 수준에서 도입한다. 각 규범 범주에 대해, 문화적으로 근거하고 스타일적으로 적절한 행동을 반영하는 소수의 고품질 예시(exemplars)를 수동으로 큐레이션한다. 정적인 프롬프트를 사용하는 대신, 모델은 의사소통 의도, 감정적 어조, 담화 패턴(예: 화자 역할 및 인접성)을 기반으로 의미론적 및 구조적으로 유사한 예시를 검색하며, 대규모 인간 주석 없이 수정 프로세스를 안내한다.
추가 정제가 필요한지 결정하기 위해, 원본 입력과 비교하여 수정된 결과물의 품질을 평가하는 정제 품질(RQ) 프로토콜을 사용하여 반복 루프를 구현한다. 모델은 다음 삼중항(triplet)을 수신한다:
여기서 는 원본 시나리오-상황 쌍을, 는 예시 기반 프롬프팅에서 수정된 결과물을 나타내며, 은 RQ 프로토콜을 통해 계산된 스칼라 값이다. 이를 통해 모델은 수정의 사회적 및 스타일적 적절성을 평가하고 정제를 계속할지 여부를 결정한다.
이러한 조기 통합은 생성 우선 파이프라인에서 흔히 발생하는 품질 병목 현상을 완화하고, 대화 구성 이전에 일관된 사회문화적 정렬을 보장한다.
3.4 Multi-Turn Dialogue Generator with Turn-Level Annotation
정제 과정을 거친 후, 각 시나리오-상황 쌍은 다중 턴 대화(5~15턴)로 확장되었으며, 그 결과 사회적으로나 맥락적으로 적절한 상호작용이 생성된다.
각 발화는 다음과 같은 요소로 주석이 달린다:
- (a) 규범 준수 (norm adherence).
- (b) 의도 및 감정 상태를 포함한 화자 반응 (speaker reaction).
- (c) 할당된 레이블에 대한 정당화 (justification).
이러한 구조는 규범 준수를 식별하고 화자의 행동을 설명함으로써 사회적 역학에 대한 세분화된 모델링을 가능하게 한다. 대화 행위 이론(dialogue act theory)에 근거한 반응 레이블은 LLM 기반 프롬프팅 및 전문가 검증을 통해 할당된다. 결과적으로 생성된 데이터셋은 문화를 초월하여 규범 추론 및 사회적으로 민감한 대화 모델링을 지원한다.
4. Evaluation Framework
4.1 Datasets and Experimental Conditions
Dataset Composition and Baselines
영어, 중국어, 한국어로 된 다문화 데이터셋을 구축했다. 이 데이터셋은 세 가지 상호작용 유형(규범 준수(Norm Adherence), 규범 위반(Norm Violation), 그리고 위반-해결(Violation-to-Resolution, V2R))에 걸쳐 언어당 1,200개의 인스턴스로 구성되며, 총 10,800개의 인스턴스를 생성했다. 8시간 동안 4개의 NVIDIA A100 GPU를 사용하여 실험을 수행했다.
베이스라인 비교를 위해 다음의 기존 리소스들을 사용했다:
- NORMDIAL (Li et al., 2023): 발화 수준의 규범 준수 및 위반 주석이 포함된 이중 언어(영어-중국어) 코퍼스이다.
- SODA (Kim et al., 2023): 사회적 상식에 기반한 사회적으로 적절한 대화의 영어 코퍼스이다.
Model Configuration and Evaluation Protocol
모든 시나리오-상황 정제 및 대화 생성은 GPT-4.1을 사용하여 수행되었다. 이는 수동으로 수정된 모델 출력에서 파생된 전문가가 큐레이션한 소수의 예시(exemplars)의 가이드를 받았다. 이 예시들은 문화적으로, 화용론적으로 적절한 응답을 반영하며, 특히 저자원 언어에서 반복적인 정제를 유도하는 데 사용된다.
다운스트림 실험(5절)을 위해, 폐쇄형 모델인 GPT-4o-mini와 오픈 소스 베이스라인인 LLaMA-3-8B, Qwen-2.5-14B, Qwen-2.5-32B를 미세 조정(fine-tune)했다. 모든 모델은 비교 가능성을 보장하기 위해 각 언어에 대해 동일한 구성으로 훈련되었다.
인간 평가는 언어적 유창성과 문화적 친숙도를 위해 선정된 원어민 중국어 및 한국어 화자들에 의해 수행되었다. 저자원 문화 환경에서의 모델 성능을 평가하기 위해, 6명의 독립적인 대학원생(한국인 4명, 중국인 2명)을 주석가로 모집했다. 각 평가를 위해, 유형당 100개의 대화를 무작위로 샘플링했으며, 주석가들은 유창성, 관련성, 사회 규범 준수 측면에서 Likert 척도 판단을 사용하여 결과를 평가했다. 이러한 인간 평가는 제안된 측정 지표를 기반으로 한 자동 평가로 보완되었다.
4.2 Evaluation Objectives and Design
프레임워크를 세 가지 축(axes)을 따라 평가한다:
-
정제 품질 (Refinement Quality, RQ): 정제 방법이 저자원 언어에서의 생성 품질을 개선하는가?
-
대화 품질 (Dialogue Quality, DQ): 생성된 대화가 규범 및 화용론적 기대치에 부합하는가?
-
일반화 품질 (Generalization Quality, GQ): NormGenesis로 훈련된 모델이 품질 및 인간 선호도 측면에서 기준선보다 뛰어난가?
Refinement Quality
정제 전후의 시나리오-상황 쌍을 한국어와 중국어에서 비교한다. 표 2는 정제 품질을 평가하는 데 사용되는 세 가지 핵심 기준을 요약한다.

Table 2: Evaluation criteria used for refinement quality
평가는 LLM 및 전문가 주석가 모두를 사용하여 5점 리커트 척도를 사용한다.
Dialogue Quality
다중 턴 대화를 (Kim et al., 2023; Li et al., 2023)에서 채택된 여섯 가지 기준에 따라 평가한다. 이 평가 기준은 표 3에 자세히 나와 있다. LLM 및 인간 주석가들은 독립적으로 평가를 수행한다.
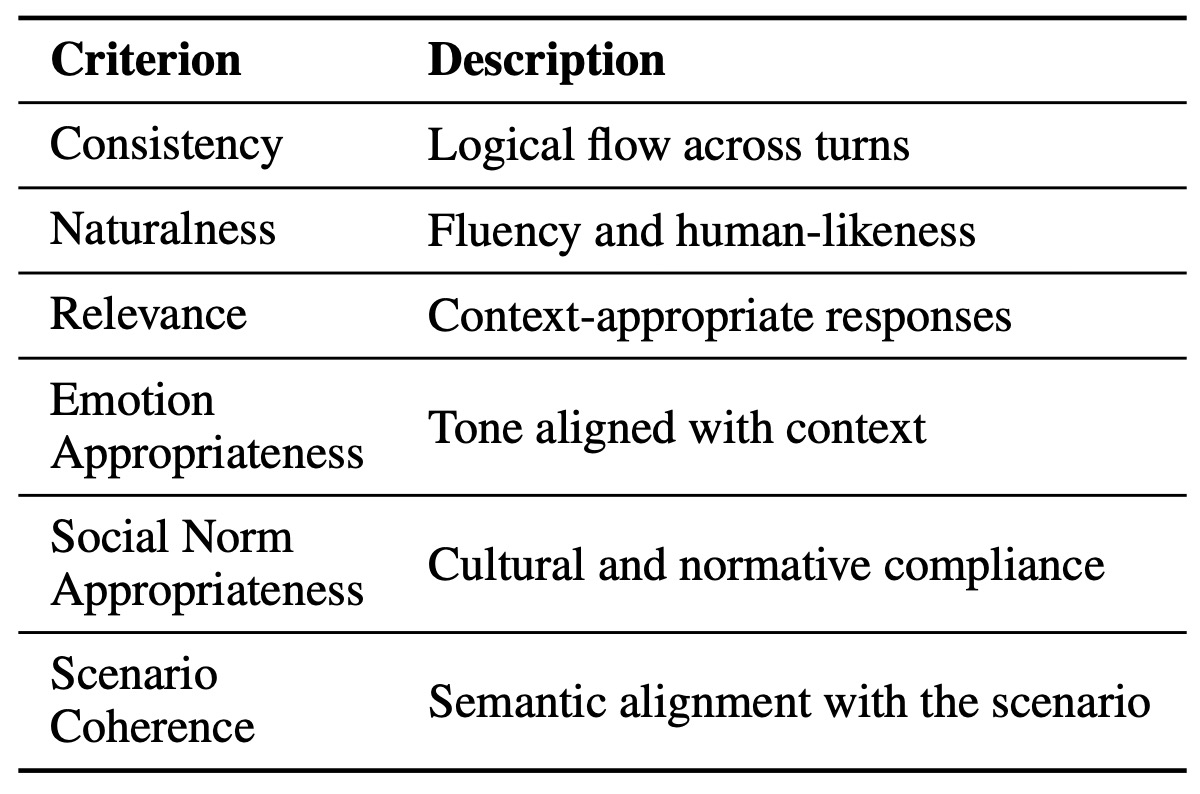
Table 3: Evaluation criteria used for dialogue quality
Generalization Quality
세 가지 데이터셋에서 규범 준수 대화(norm-adherent dialogues)로 네 가지 언어 모델을 파인 튜닝한다. 훈련을 위해, NormGenesis *데이터셋에서 영어와 중국어 인스턴스 각각 1,200개를 사용한다. 추가적으로, NORMDIAL에서 영어 1,265개와 중국어 1,116개 인스턴스, 그리고 SODA***에서 무작위로 샘플링한 영어 대화 1,200개를 사용한다.
모델들은 DAILYDIALOG (영어) 및 LCCC (중국어)에서 평가되며, 각 모델은 벤치마크 대화 맥락이 주어졌을 때 5턴의 이어지는 대화를 생성하도록 프롬프트로 제공된다. 평가는 사회적 적절성, 유창성, 그리고 전반적인 응답 품질을 기반으로 판단하는 A/B 선호도 테스트와 인간 평가를 수행한다.
5. Results
4절에서 정의된 세 가지 평가 축을 따라 결과를 제시한다. 또한, V2R(Violation-to-Resolution) 모델링의 영향을 추가로 분석한다. NormGenesis 프레임워크는 모든 설정에서 언어적 유창성, 화용론적 일관성, 그리고 사회적 적절성을 지속적으로 개선하는 결과를 보였다.
5.1 Refinement Quality
예시 기반 정제(exemplar-based refinement)의 효과를 평가하기 위해, 두 가지 저자원 언어인 한국어와 중국어에서 정제 전후의 시나리오-상황 쌍을 비교한다.
표 4에 나타나 있듯이, 정제는 두 언어 모두에서 모든 평가 차원을 일관되게 개선한다.
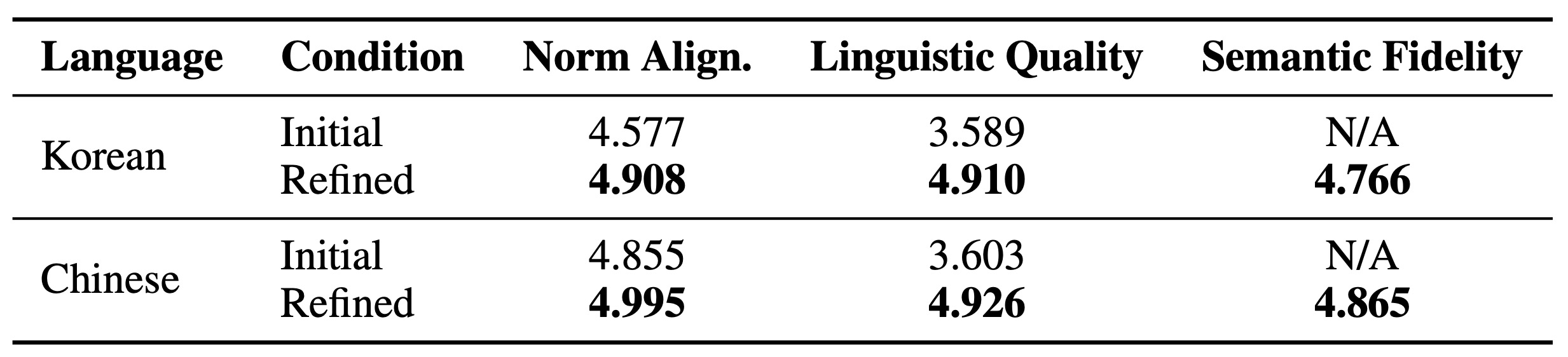
Table 4: Refinement evaluation results
- 한국어의 경우, 언어적 품질이 실질적으로 개선되었으며, 규범 정렬(norm alignment) 및 의미론적 충실도(semantic fidelity)에서도 이득을 보였다.
- 중국어에서도 유사한 패턴이 관찰되었는데, 언어적 품질에서 +1.32 증가를 보였고, 규범 정렬 점수는 거의 최고치(near-ceiling)를 기록했다.
정제 과정은 LLM(대규모 언어 모델)이 더 이상 수정이 필요 없다고 판단할 때까지 반복되었다. 평균적으로 각 인스턴스는 1.2회의 정제 라운드를 거쳤다. 이러한 결과는 저자원 언어 생성에서 유창성, 일관성, 그리고 사회문화적 적절성을 향상시키는 NormGenesis 접근 방식의 유용성을 강조한다.
동아시아 유형론을 넘어서는 일반화 가능성을 테스트하기 위해, 실용론적으로 구별되는 두 언어인 말레이어와 우르두어에서 파일럿 정제 실험을 수행했다. 표 4와 동일한 평가 설정을 사용했을 때, 관찰된 개선 사항은 주요 실험 결과와 일치했다.
5.2 Dialogue Quality
LLM 및 인간 기반 채점(scoring)을 모두 사용하여 여섯 가지 차원에 걸쳐 대화 품질을 평가한다. 평가 기준은 표 3에 요약되어 있다.
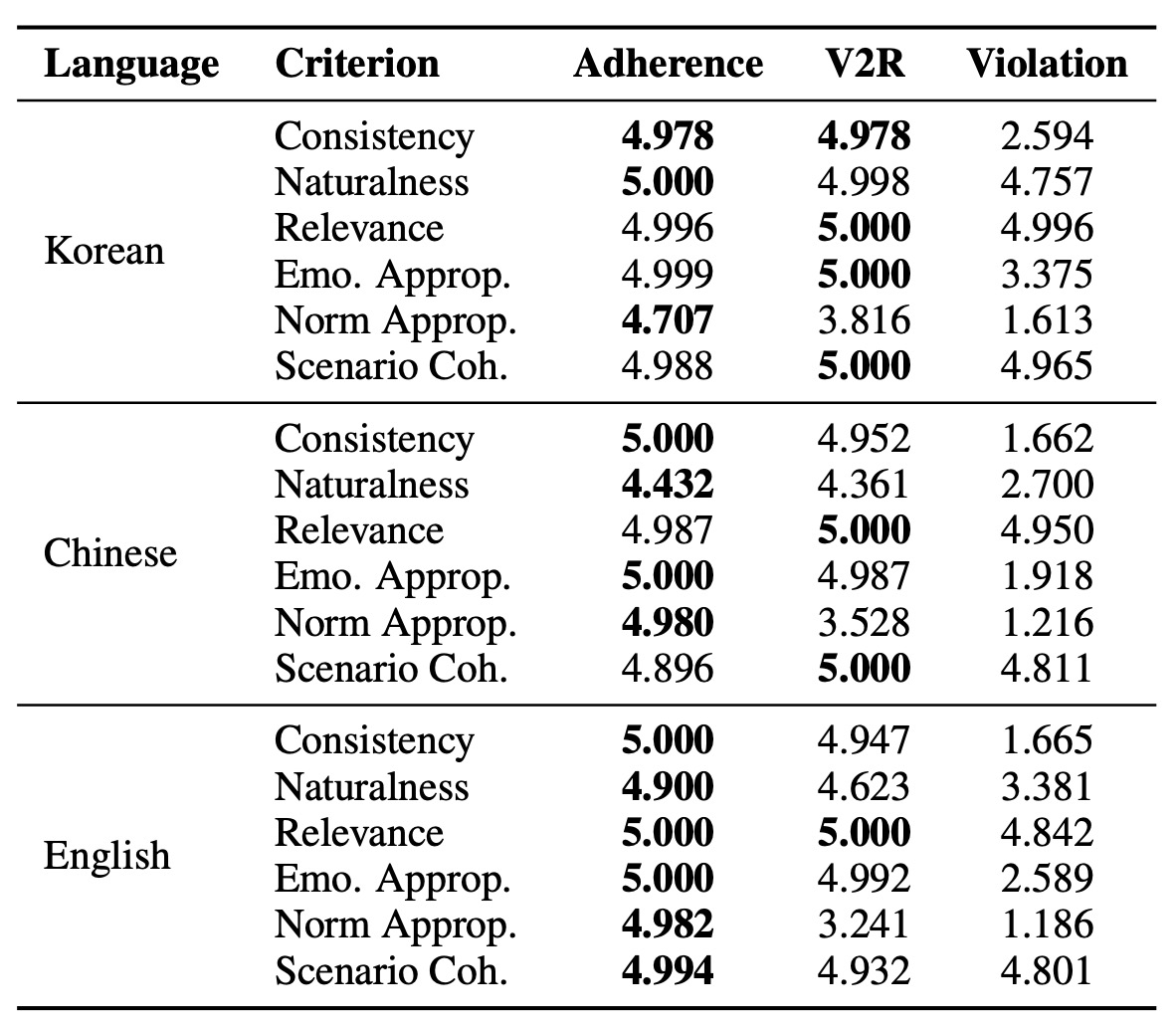
Table 5: Dialogue quality results
표 5는 한국어, 중국어, 영어의 준수(Adherence), V2R(Violation-to-Resolution), 위반(Violation) 시나리오에 대해 LLM 기반 평가에서 얻은 평균 점수를 제시한다. 준수 및 V2R 범주의 대화는 특히 일관성, 감정 적절성, 시나리오 일관성 측면에서 일관되게 높은 점수(평균 4.9점 초과)를 달성했다. V2R 대화는 감정 적절성 및 시나리오-대화 정렬(alignment) 측면에서 다른 유형보다 약간 더 우수한 성능을 보였는데, 이는 사회적으로 복잡하고 복구(repair) 중심의 상호작용을 모델링하는 프레임워크의 강점을 강조한다. 대조적으로, 위반 대화는 모든 언어에서 자연스러움 및 감정 적절성 측면에서 낮은 점수를 받았는데, 이는 사회적으로 부적절한 상호작용을 포착하도록 설계된 목적을 반영한다.
Human Evaluation
LLM 기반 평가의 견고성을 검증하고 저자원 환경에서의 생성 품질을 조사하기 위해, 한국어와 중국어에서 병렬적인 인간 평가를 수행했다. 표 6에 나타나 있듯이, 인간 평점은 표 5에 보고된 LLM 점수와 매우 일관된 패턴을 보였다.
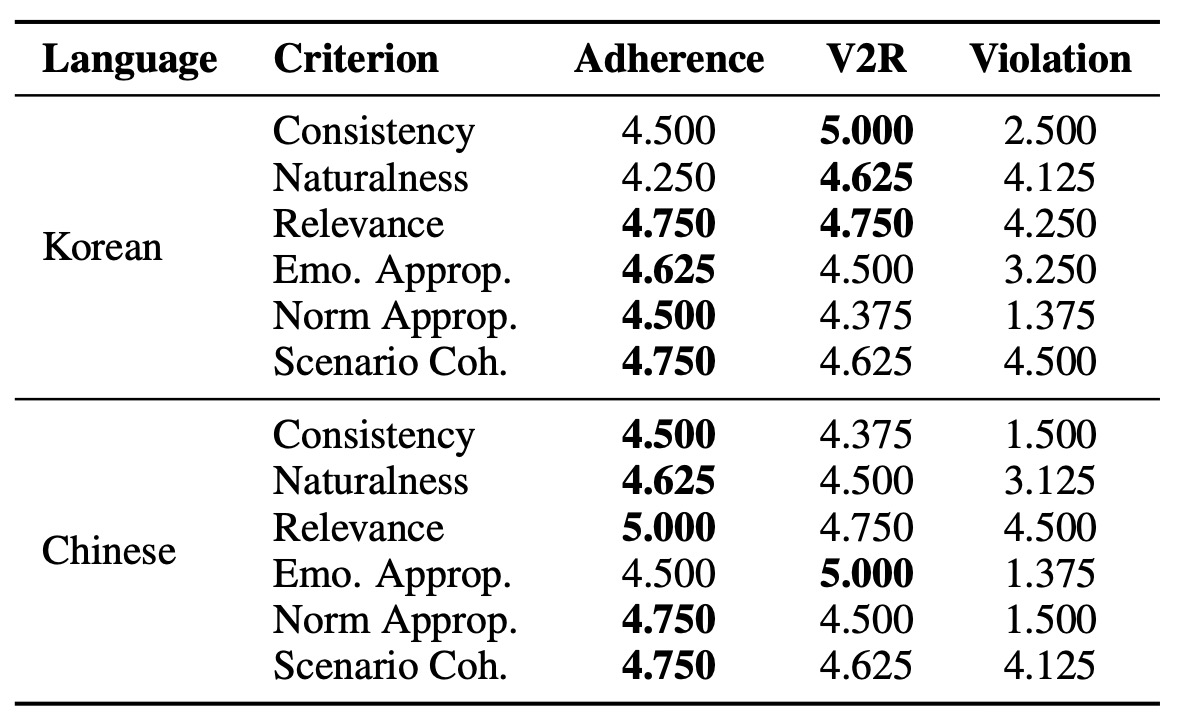
Table 6: Human evaluation results
피어슨 상관관계(Pearson correlation)를 사용하여 LLM 및 인간 평가 간의 정렬(alignment) 정도를 추가로 정량화했다. 그 결과, r = 0.928 (한국어) 및 r = 0.945 (중국어)의 계수로 두 언어 모두에서 강한 일치를 나타냈다. 이러한 결과는 자동 평가 프로토콜의 신뢰성을 확인하고, 이를 통해 도출된 결론의 타당성을 뒷받침한다.
5.3 Generalization Quality
자동 평가 결과는 표 7에 요약되어 있다. NormGenesis 데이터셋은 모든 모델과 언어에 걸쳐 NORMDIAL 및 SODA보다 지속적으로 높은 선호도를 보였다. 예를 들어, GPT-4o-mini는 NORMDIAL에 비해 영어에서 65%, 중국어에서 75%의 경우에서 선호되었으며, SODA에 비해서도 영어에서 65% 선호되었다. Qwen-2.5-32B와 같은 더 큰 모델들도 유사한 경향을 보였으며, 중국어에서 가장 강력한 선호도가 관찰되었다.
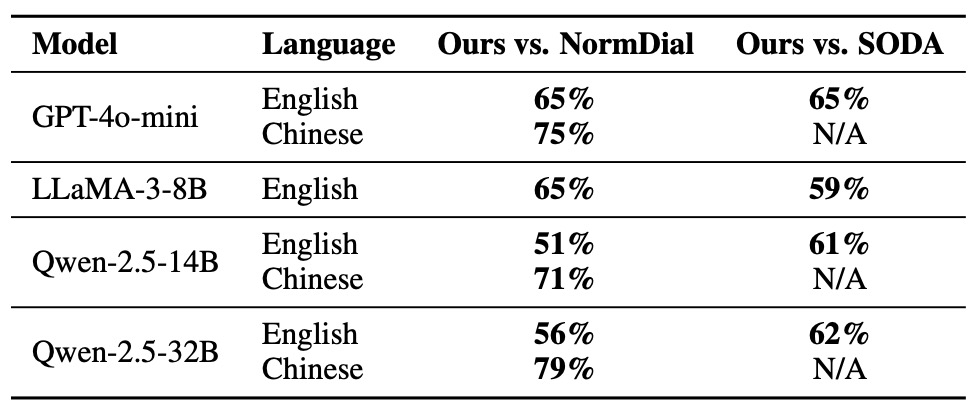
Table 7: A/B test results
이러한 결과를 검증하기 위해, 한국어와 중국어로 블라인드 인간 평가를 수행했다 (표 8). 원어민들은 한국어에서 68%, 중국어에서 77%의 경우에서 NormGenesis **데이터셋을 **선호했는데, 이는 LLM의 선호도와 매우 근접하게 일치했다. 이러한 결과는 NormGensis **데이터셋으로 **훈련된 **모델이 언어와 도메인 전반에 걸쳐 더 잘 일반화되어, 사회적으로 더욱 적절하고 문맥적으로 정렬된 응답**을 생성한다는 것을 시사한다.

Table 8: Human preference results
튜닝되지 않은 모델이 미묘한 감정적 전환 없이 빠른 사과가 필요한 맥락에서는 간결하고 직접적인 응답을 생성했고, 일부 평가자들은 이를 선호했다는 점을 언급한다. 그러나 이러한 사례는 제한적이었으며, 전반적으로 NormGenesis 데이터셋은 베이스라인보다 두 배 이상의 선호도를 달성했다. 이 결과는 예시 기반 정제가 전반적인 품질을 향상시킬 뿐만 아니라, 응답 스타일과 감정 표현의 미세 조정에 대한 유연한 프레임워크를 제공함을 시사하며, 향후 연구에서 이를 조사할 계획이다.
5.4 Effect of Violation-to-Resolution
규범 민감 생성(norm-sensitive generation)에 대한 위반-해결(V2R) 훈련의 영향을 평가하기 위해, 윤리적으로 어려운 시나리오를 위한 벤치마크인 PROSOCIALDIALOG를 사용하여 집중적인 비교 연구를 수행한다.
비교 가능한 조건 하에 두 개의 GPT-4o-mini 모델을 미세 조정했다. 하나는 전체 NormDial 데이터셋으로, 다른 하나는 세 가지 유형의 NormGenesis 데이터셋을 포함하는 동일 크기의 데이터 하위 집합으로 훈련했다. 두 모델 모두 100개의 규범 위반 맥락에 대한 프롬프트를 받았으며, 각 맥락은 5턴의 이어지는 대화를 요구했다.

Table 9: Human preference results on PROSOCIALDIALOG
블라인드 A/B 인간 평가 결과, V2R이 보강된 모델이 82%의 경우에서 선호된다는 것을 보여주었다 (표 9). 주석가들은 모델의 공감 능력, 맥락적 적합성, 그리고 규범 복구를 모델링하는 능력을 일관되게 선호했다. 이러한 결과는 V2R이 윤리적으로 민감한 대화에서 화용론적 역량을 향상시키는 훈련 신호로서의 유용성을 강조하며, 규범 기반 생성 프레임워크에 V2R을 통합하는 것을 지지한다.
6. Discussion
저자원 맥락에서 프롬프트 기반 생성의 한계
이 연구에서의 정제 프레임워크는 사회 규범 생성을 위한 기존의 프롬프트 기반 접근 방식(Li et al., 2023; Zhan et al., 2024)이 가진 한계에 부분적으로 동기 부여되었다. 이러한 방법들은 일반적으로 최소한의 규범 신호만 담은 정적인 프롬프트에 의존하며, 생성의 부담을 전적으로 언어 모델에 맡긴다. 이러한 접근 방식은 영어와 같은 고자원 언어에서는 유창하고 맥락적으로 적절한 응답을 생성할 수 있지만, 한국어와 중국어와 같은 저자원 환경에서는 화용론적 실패를 자주 초래한다.
- 한국어의 경우, 생성된 대화는 어휘적 중복성(예: 반복되는 표현)과 어조 불일치(예: 격식 있는 맥락에서의 비격식적인 사과)를 자주 보인다.
- 중국어에서는 부자연스러운 구문, 과장된 감정적 응답, 반복적인 존칭, 그리고 레지스터 혼합에서 오는 일관성 없는 어조 등의 문제가 포함된다.
이러한 한계들은 프롬프트만을 사용하는 방법으로는 세밀한 사회문화적 규범을 포착하기 어렵다는 점을 강조한다. 이 문제들을 완화하기 위해, 이 논문에서는 저자원 환경에서 유창성과 규범 정렬을 개선하기 위한 정제 프레임워크를 도입한다.
사회문화적 정렬을 위한 초기 정제
5.1절에서 보았듯이, 이 단계에서 소수의 고품질 예시만으로도 저자원 언어의 유창성과 규범 정렬이 개선된다. 정제 전, 모델이 생성한 결과물과 원어민이 수정(revision)한 결과물 간의 비교 분석을 수행했는데, 여기서 상투적인 표현의 과용, 제한된 몸짓 다양성, 레지스터와 맥락의 불일치, 그리고 약화된 계층적 신호와 같은 반복적인 문제가 발견되었다. 이 분석에서 얻은 핵심 통찰력은 표면적 정확성(surface accuracy)과 문화적 적절성 사이의 구별이다. 모델의 출력은 문법적으로나 의미론적으로는 정확할 수 있지만, 화용론적 기대치에 필수적인 의례적이거나 정서적인 요소(예: 사과, 애도)를 포함하지 못하는 경우가 있다.
생성 파이프라인의 초기 단계에서 최적화될 때, 시나리오-상황 쌍은 응집력 있고 문화적으로 정렬된 대화 구성을 안내하는 강력한 사회적 신호를 제공한다. 이러한 초기 단계 정제 접근 방식은 일관성과 목표 정렬에서 명시적 맥락 모델링의 역할을 강조하는 통제 가능한 생성 및 구조화된 계획에 대한 최근 연구(Moryossef et al., 2019; Rashkin et al., 2021)와도 일치한다. 사회 규범은 관계적 역할, 권력 역학, 상황적 맥락과 본질적으로 얽혀 있기 때문에, 상황적 사전 정보를 정제하는 것은 화용론적으로 그리고 문화적으로 적절한 행동이 자연스럽게 나타나도록 보장한다. 따라서 정제 단계는 사후 교정 계층이 아니라, 생성 과정에 사회문화적 정렬을 내재화하는 핵심 메커니즘으로 기능한다.
교차 언어 복구 전략에 대한 질적 통찰
위반-해결(V2R) 대화에 대한 질적 분석을 통해, 제안된 프레임워크가 보편적인 복구 전략과 문화 특유의 복구 전략을 모두 효과적으로 모델링한다는 것을 보여준다. 표 10에 요약된 바와 같이, 사과(Apology)와 설명(Explanation)은 영어, 중국어, 한국어 전반에서 지배적인 전략이다. 그러나 복구 순서 패턴은 문화적으로 의미 있는 방식으로 다르게 나타난다.
- 영어 대화는 가장 자주 설명 → 사과 → 보상의 순서를 따른다.
- 중국어 대화는 사과 → 설명 → 보상 순서를 따른다.
- 한국어 대화는 공감 → 사과 → 설명의 순서를 따른다.
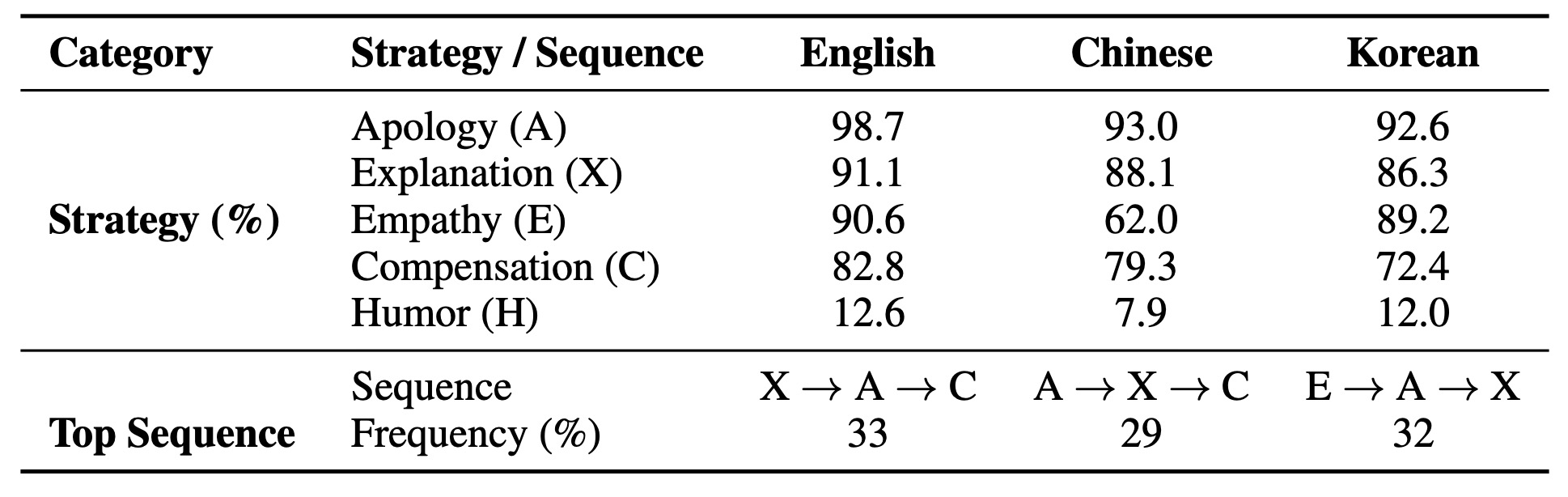
Table 10: Strategy usage rates and most frequent recovery sequences in V2R
사과 및 공손함 연구의 기존 분류 체계(Radu et al., 2019; Zhang and Wang, 2024)에 근거한 이러한 결과는 프레임워크가 미묘한 교차 언어적 변화를 포착하는 능력을 검증한다. 특히, V2R 대화의 85% 이상이 다단계 복구(multi-step recovery)를 사용했는데, 이는 사회적으로 일관된 복구가 단일 행위를 통해 거의 발생하지 않음을 확인해 준다. 예시 기반 정제를 통합함으로써, 이 논문의 **접근 **방식은 이러한 다층적인 역학을 모델링하고, 컴퓨터 대화 생성과 사회 언어학적 통찰력을 연결한다. 이러한 발견들은 V2R 패러다임의 이중 가치, 즉 현실적인 대화 복구를 위한 확장 가능한 스키마를 제공하고 문화적 변이에 대한 진단적 렌즈 역할을 한다는 점을 강조한다. 이러한 적응성은 또한 유형론적으로 다양한 언어(예: 아랍어, 스와힐리어, 힌디어)로 NormGenesis를 확장할 수 있는 유망한 방향을 제시한다.
7. Conclusion
이 연구는 영어, 중국어, 한국어로 사회적으로 근거한 대화를 생성하고 정제하기 위한 다문화 프레임워크인 NormGenesis를 제시한다. 기존 대화 시스템, 특히 저자원 환경에서의 문화적 및 화용론적 한계를 해결하기 위해, 시나리오-상황 수준에서 적용되는 예시 기반 반복 정제를 도입한다. 이 상류(upstream) 정제 설계는 전체 대화 합성이 시작되기 전에 언어적, 감정적, 그리고 사회문화적 기대치와의 조기 정렬을 가능하게 하며, 생성 오류를 줄인다.
나아가 규범 위반 이후의 복구 과정을 모델링하는 새로운 대화 유형인 V2R(Violation-to-Resolution)을 제안한다. V2R은 복구 전략을 통해 사회적 상호작용 역학에 대한 더 현실적이고 맥락에 민감한 모델링을 용이하게 한다. 실험 결과는 V2R이 윤리적으로 민감한 시나리오에서 화용론적 역량을 개선할 뿐만 아니라, 언어와 도메인 전반에 걸쳐 일반화 성능을 향상시킨다는 것을 보여준다.
포괄적인 인간 및 LLM 기반 평가를 통해, NormGenesis가 규범 정렬, 감정적 일관성, 복구 품질을 포함한 다차원에서 NORMDIAL 및 SODA와 같은 기존 데이터셋보다 지속적으로 우수한 성능을 보인다는 것을 입증한다. 언어적 및 문화적으로 다양한 규범, 세밀한 발화 수준 주석, 그리고 구조화된 정제를 통합함으로써, NormGenesis는 다국어 및 다문화 맥락에서 규범 인식 대화 모델링을 위한 확장 가능하고 강력한 토대를 제공한다.
