Author: Mingyue Cheng, Jie Ouyang, Shuo Yu, Ruiran Yan, Yucong Luo, Zirui Liu, Daoyu Wang, Qi Liu, Enhong Chen
Affilation: University of Science and Technology of China
Venue: arXiv, under review
Comments:
Date: November 2025
Paper Link: https://arxiv.org/abs/2511.14460
⭐️ Key Takeaways
1. 이 논문은 LLM 에이전트의 다중 턴 상호 작용, 확률적 환경 피드백, 그리고 과정 보상(process rewards)을 포괄적으로 모델링하기 위해 고전적인 마르코프 결정 과정(MDP) 프레임워크를 체계적으로 확장하고 명확히 한다.
2. Agent-R1은 RL 기반 LLM 에이전트를 위한 모듈식의 유연한 훈련 프레임워크로 소개되었으며, Tool 및 ToolEnv 모듈을 통해 복잡한 다중 턴 롤아웃과 정확한 신뢰 할당(credit assignment)을 지원한다.
3. 다중 홉 질의응답 작업에 대한 실험 결과, Agent-R1로 훈련된 모든 강화 학습 에이전트(PPO, GRPO 등)는 단순한 베이스라인(Naive RAG 및 Base Tool Call)보다 실질적으로 더 나은 성능을 보여, 동적 환경에서 정책 최적화를 위한 프레임워크의 효능을 입증한다.
Abstract
대규모 언어 모델(LLM)은 도구 사용 등을 통해 능동적인 환경 상호작용 능력을 갖추고 복잡한 문제를 해결하는 에이전트 구축을 위해 점차 탐색된다. 강화 학습(RL)은 이러한 에이전트를 훈련하기 위한 상당한 잠재력을 가진 핵심 기술로 간주된다. 그러나 LLM 에이전트에 RL을 효과적으로 적용하는 것은 아직 초기 단계에 있으며 상당한 어려움에 직면한다. 현재 이 신흥 분야는 LLM 에이전트 환경에 특별히 맞춤화된 RL 접근 방식에 대한 심층적인 탐구가 부족하며, 이를 위해 설계된 유연하고 쉽게 확장 가능한 훈련 프레임워크도 부족한 상황이다. 이 분야를 발전시키는 데 도움을 주기 위해, 본 논문은 먼저 마르코프 결정 과정(MDP) 프레임워크를 체계적으로 확장하여 LLM 에이전트의 핵심 구성 요소를 포괄적으로 정의함으로써 LLM 에이전트를 위한 강화 학습 방법론을 재검토하고 명확히 한다. 둘째, 우리는 Agent-R1을 소개한다. Agent-R1은 다양한 작업 시나리오와 상호작용 환경에 쉽게 적용할 수 있도록 설계된, RL 기반 LLM 에이전트를 위한 모듈식이며 유연하고 사용자 친화적인 훈련 프레임워크이다. 우리는 Multihop QA 벤치마크 작업에 대한 실험을 수행했으며, 제안된 방법론과 프레임워크의 효과에 대한 초기 검증을 제공한다.
1. Introduction
최근 몇 년 동안, 대규모 언어 모델(LLMs)은 자연어 이해 및 생성에서 놀라운 능력을 보여주었으며, 점점 더 복잡한 지능형 작업에 적용되고 있다. LLM이 "에이전트" 역할을 맡게 될 때, 그들은 추론 및 의사 결정과 같은 인지 작업을 수행할 뿐만 아니라, 자율적으로 행동하고, 지속적으로 학습하며, 상호 작용 환경 내의 변화에 적응할 것으로 기대된다. 전통적인 정적 추론 작업과는 달리, 에이전트로서 기능하는 LLM은 여러 대화 라운드에 걸쳐 기억을 유지해야 하며, 순차적 의사 결정 능력을 보여주어야 하고, 환경 피드백에 효과적으로 반응해야 한다—이는 LLM을 실제 자율 지능 시스템에 더 가깝게 만든다. 이 방향은 자기 진화 및 문제 해결 능력을 갖춘 범용 인공 지능을 구축하기 위한 새로운 가능성을 열어준다.
강화 학습(RL)은 수학 문제 해결 및 코드 생성과 같이 비교적 잘 정의된 작업에서 LLM 능력을 향상시키는 데 주목할 만한 성공을 보여주었지만, 자율적이고 상호 작용적인 에이전트로서 LLM을 개발하는 데 대한 RL의 적용은 비교적 초기 단계에 있다. 에이전트 환경은 본질적으로 모델이 순차적인 결정을 내리고, 턴(turn)에 걸쳐 기억을 유지하며, 확률적인 환경 피드백에 적응할 것을 요구하며, 이는 더 정적인 작업과는 구별되는 고유한 도전을 제시한다. 이는 RL을 적용할 때 특정한 어려움으로 이어진다. 특히 다중 턴 상호 작용 시나리오에서 에이전트 훈련은 불안정성과 복잡한 보상 신호 설계에 직면할 수 있으며, 또한, 일반화가 제한되는 문제에 직면한다. 따라서 RL 방법론이 LLM 에이전트에 체계적으로 적용되고 조정될 수 있는 방법에 대한 보다 자세한 탐구가 필요하며, 유연하고 확장 가능한 훈련 프레임워크에 대한 필요성도 남아 있다.
이러한 측면들을 체계적으로 다루기 위해, 본 논문은 개념적 관점과 실용적 관점 모두에서 기여를 제시한다. 개념적으로, 우리는 LLM 에이전트에 대한 강화 학습의 적용을 명확히 하는 데 중점을 둔다. 우리는 표준 마르코프 결정 과정(MDP) 프레임워크를 확장하여, 상태 공간, 행동 공간, 상태 전이 확률, 보상 함수와 같은 그 핵심 구성 요소들이 LLM 에이전트의 다중 턴 상호 작용적 특성을 포괄적으로 모델링하기 위해 어떻게 조정될 수 있는지에 대한 자세한 설명을 제공한다. 이러한 조정된 MDP 공식화를 바탕으로, 우리는 다중 턴 궤적으로부터 에이전트 정책을 최적화하기 위한 메커니즘을 더 자세히 설명한다. 특히 에이전트가 생성한 행동을 환경 피드백과 구별하고, 학습을 효과적으로 안내하기 위해 중간 (프로세스) 보상을 통합하는 것의 중요성을 강조한다. 또한, 이러한 개념들의 실용적인 적용을 용이하게 하기 위해, 우리는 RL 기반 LLM 에이전트를 위한 유연하고 사용자 친화적인 훈련 플랫폼인 Agent-R1을 개발한다. Agent-R1은 모듈식 아키텍처 덕분에 다양한 환경 인터페이스와 작업 시나리오의 신속한 통합을 지원하며, 상이한 계산 자원 요구 사항에 동적으로 적응할 수 있다. 이는 복잡하고 다양한 응용 분야로의 쉬운 확장성을 가능하게 한다.
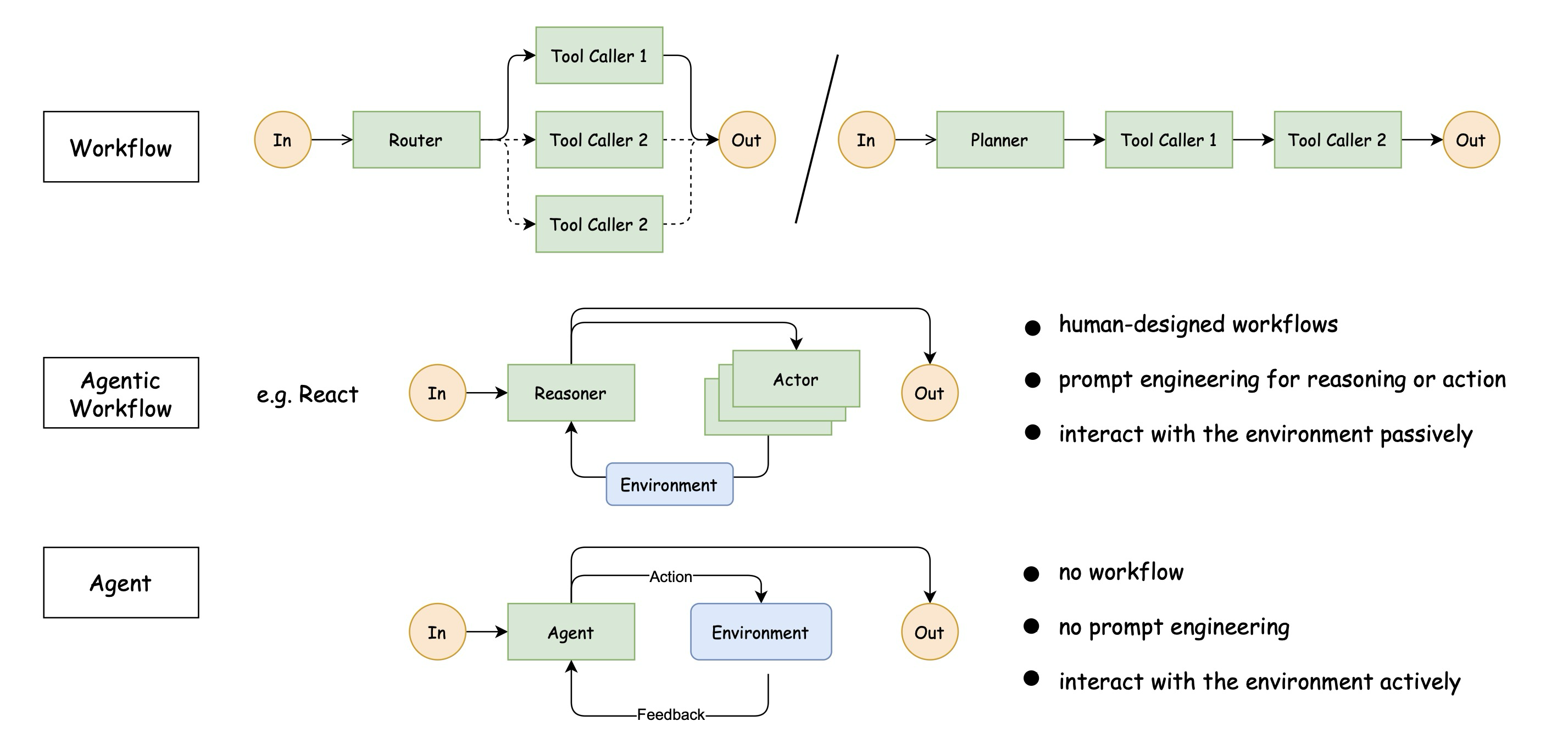
Figure 1: Comparison of workflows, agentic workflows, and autonomous agents
다중 홉 질의응답(Multi-hop QA)이라는 어려운 작업에 대한 체계적인 실험을 통해, 우리는 우리의 접근 방식과 프레임워크의 효과를 검증한다. 이 작업은 문서 간 논리적 연결 및 정보 검색을 포함하는 복잡한 추론에 중점을 두며, 에이전트의 다단계 의사 결정 능력, 환경 피드백에 대한 적응성, 그리고 지식 구성 과정에 높은 요구 사항을 부과한다. 실험 결과는 우리의 방법과 프레임워크가 이러한 동적 상호 작용 환경에서 모델의 성능을 향상시킬 수 있음을 입증한다.
2. From Large Language Models to Agents: An MDP Perspective
대규모 언어 모델(LLM) 애플리케이션에 내재된 순차적 의사 결정 과정은 단순한 텍스트 생성을 위한 것이든 LLM 에이전트의 복잡한 상호 작용을 위한 것이든 관계없이 마르코프 결정 과정(MDP) 프레임워크 내에서 효과적으로 공식화될 수 있다. 그러나 MDP 공식화를 정적이고 단일 턴 텍스트 생성 작업(예: 수학 또는 코드 생성)의 LLM 적용 맥락에서, 본질적으로 동적이며, 다중 턴이고, 풍부하게 상호 작용하는 환경 대화에 참여하는 LLM 에이전트에 적합한 형태로 발전시키려면 상당한 확장이 요구된다. 본 절에서는 정적 LLM과 LLM 에이전트의 핵심 MDP 구성 요소를 대조하여 이러한 중요한 차이점들을 기술한다.
MDP 구성 요소의 관점에서 정적 LLM과 LLM 에이전트의 차이는 다음과 같이 구분된다.
2.1 State Space (S)
Static LLM: 단일 턴 텍스트 생성에서 상태 는 주로 현재 텍스트 컨텍스트를 캡슐화한다. 여기에는 초기 프롬프트 와 지금까지 생성된 토큰 시퀀스 가 포함된다:
상태 공간은 일관된 시퀀스에서 다음 토큰을 예측하는 데 필요한 정보를 포착하는 데 초점이 맞추어진다.
LLM Agent: 다중 턴 상호 작용에 참여하는 에이전트의 경우, 상태 는 현저하게 더 포괄적이어야 한다. 이는 텍스트 컨텍스트뿐만 아니라 상호 작용 기록 및 환경 피드백도 유지해야 한다. 따라서 상태는 다음과 같이 확장된다:
여기서 각 는 완전한 상호 작용 턴을 나타낸다. 이는 에이전트가 생성한 토큰 과 후속 환경 피드백 , 즉 로 구성된다. 용어 은 현재 진행 중인 턴에서 부분적으로 생성된 시퀀스를 의미한다. 이러한 풍부해진 상태 표시는 에이전트가 대화 및 환경 결과(예: 도구 활용 결과)의 포괄적인 기록에 기반하여 결정을 내릴 수 있도록 한다.
2.2 Action Space (A)
Static LLM: 행동 는 LLM의 어휘 집합 에서 다음 토큰 을 선택하는 것에 해당한다. 행동 공간 는 일반적으로 집합 이다.
LLM Agent: 마찬가지로, 에이전트의 행동 는 에서 다음 토큰을 선택하는 것이다. 하지만, 행동 시퀀스의 함의는 더 광범위할 수 있다. 에이전트가 생성하는 특정 토큰 시퀀스는 외부 도구 또는 API를 호출하는 명령으로 해석될 수 있다. 따라서, 근본적인 행동은 토큰 생성으로 남아 있지만, 그 기능적 결과는 단순한 텍스트 생성을 넘어 능동적인 환경 개입으로 확장될 수 있다.
2.3 State Transition Probability (P)
Static LLM: 정적 LLM의 텍스트 생성에서 상태 전이는 결정론적이다. 현재 상태 와 행동 (토큰 선택)가 주어지면, 다음 상태 은 을 현재 시퀀스에 덧붙임으로써 고유하게 결정된다. 이 관계는 수학적으로 다음과 같이 표현된다:
여기서, 는 시퀀스 연결을 나타낸다.
LLM Agent: 에이전트의 상태 전이 메커니즘은 환경 상호 작용을 통합함으로써 중요한 구분을 도입하며, 이는 확률적일 수 있다. 전이는 행동이 그러한 상호 작용을 유발하는지 여부에 따라 분류될 수 있다:
(생성적 전이)는 정적 LLM 토큰 생성의 결정론적 특성을 반영하며, 일 때 이 되고, 그렇지 않으면 이 된다. 반면, (환경적 전이)는 도구 실행 및 환경 응답에 내재된 불확실성을 반영한다. 다음 상태 은 에이전트의 행동뿐만 아니라 외부 환경으로부터의 결과 (예: API 응답, 계산 결과)에도 의존하며, 이러한 결과는 환경 피드백 의 일부를 형성한다.
2.4 Reward Function (R)
Static LLM: 보상은 일반적으로 희소하며, 완전한 생성 시퀀스의 끝, 즉 종료 상태 에 도달했을 때 제공된다. 이는 종종 생성된 텍스트의 전반적인 품질(예: 일관성, 관련성)을 평가하는 결과 기반 보상 이다.
LLM Agent: 에이전트의 부상 구조는 작업의 다중 턴 특성을 수용하여 종종 더 풍부하고 밀집된다. 보상 은 다음과 같이 정의될 수 있다:
여기서 은 작업 완료에 대한 최종 결과 보상이다. 중요하게도, 에이전트는 효과적인 도구 호출이나 목표를 향한 실질적인 진전과 같은 중간 단계를 성공적으로 실행한 것에 대해 과정 보상 을 받을 수도 있다. 이러한 중간 신호는 더 빈번한 피드백을 제공하여 학습 과정을 더 효과적으로 안내한다.
요약하자면, 정적 LLM에서 LLM 에이전트로 MDP 프레임워크를 조정하는 것은 논의된 핵심 구성 요소 전반에 걸쳐 중요한 개선 사항을 포함한다. 상태 공간은 상호 작용 기록과 환경 피드백을 통합하도록 확장된다. 행동은 근본적으로 토큰 생성에 해당하지만 외부 효과를 유발할 수 있다. 상태 전이는 환경적 확률성을 통합한다. 그리고 보상 시스템은 과정 보상의 포함으로 더욱 세분화된다. 이러한 확장은 강화 학습 알고리즘이 동적 환경 내에서 복잡하고 다단계적인 추론 및 상호 작용이 가능한 정교한 에이전트를 훈련할 수 있도록 하는 데 필수적이다.
3. Agent-R1 Framework
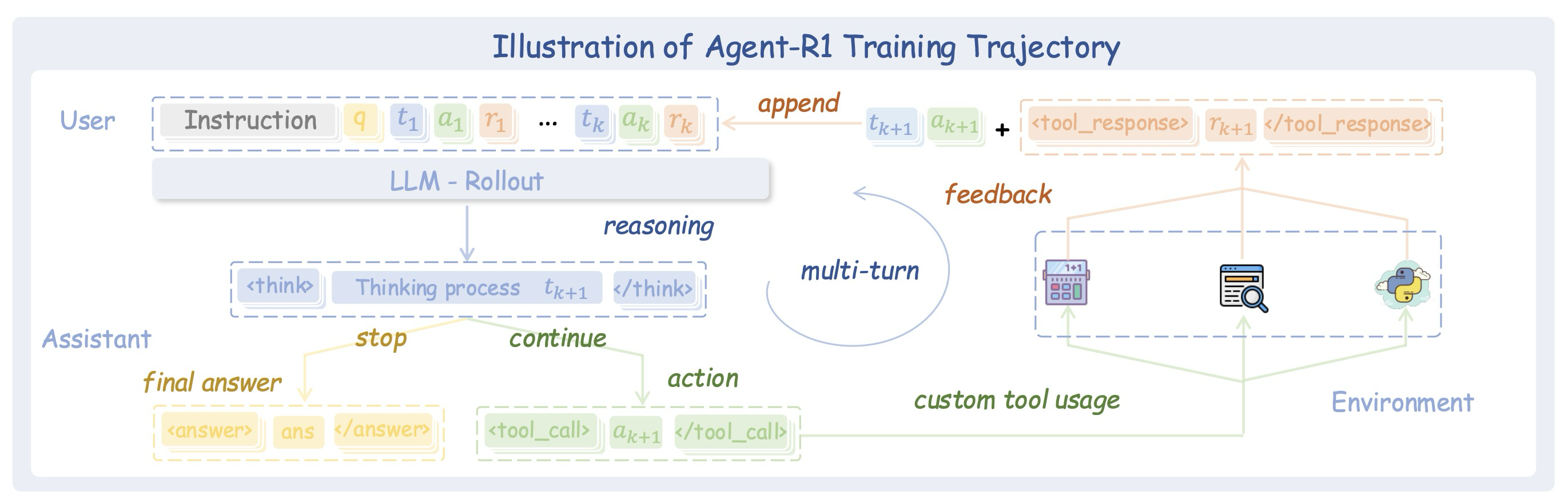
Figure 2: Illustration of the Agent-R1 training trajectory
LLM 에이전트의 강화 학습 요구 사항을 더 잘 수용하기 위해, 우리는 Figure 2에 나타난 바와 같이 유연하고 확장성이 뛰어난 에이전트 강화 학습 훈련 프레임워크인 Agent-R1을 소개한다. 기존의 효율적인 강화 학습 인프라를 활용하여, 우리는 전통적인 단일 턴 강화 학습 훈련 프레임워크를 확장하여 에이전트의 다중 턴 상호 작용 특성에 완전히 적응하도록 한다. 이는 다양한 작업 환경과의 원활한 통합과 점점 더 복잡해지는 에이전트 환경 전반에 걸친 확장 가능한 훈련을 가능하게 한다.
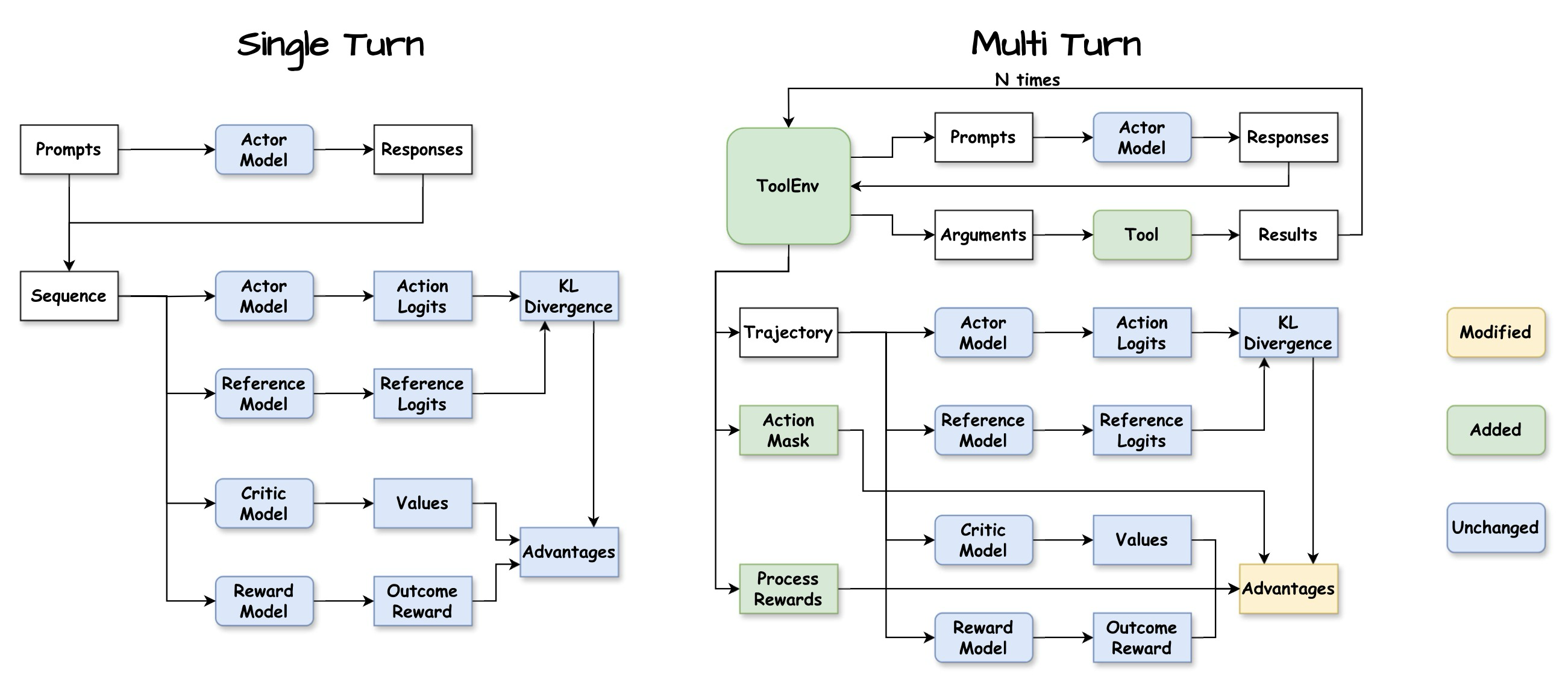
Figure 3: Flow diagram of Single-Turn RL and Multi-Turn RL (Agent-R1) in generation stage
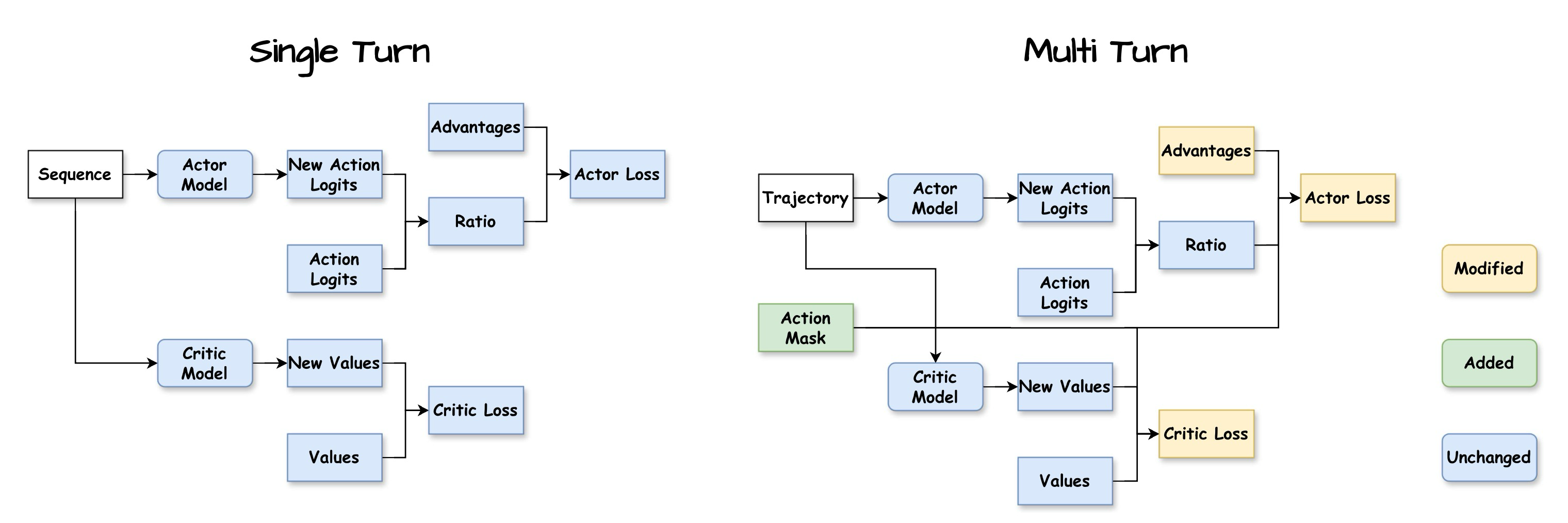
Figure 4: Flow diagram of Single-Turn RL and Multi-Turn RL (Agent-R1) in learning stage
Figure 3과 Figure 4는 전통적인 단일 턴 강화 학습 훈련 프레임워크와 Agent-R1의 다중 턴 강화 학습 훈련 간의 워크플로우 비교를 보여주며, Figure 3은 생성 단계(generation stage)를, Figure 4는 학습 단계(learning stage)를 보여준다. 단일 턴과 다중 턴 강화 학습 간의 가장 중요한 차이점은 롤아웃(rollout) 단계에 있다: 단일 턴 롤아웃 프로세스는 액터 모델(Actor Model)이 응답을 한 번만 생성하도록 요구하는 반면, 다중 턴 롤아웃은 여러 번의 복잡한 상호 작용을 포함한다. 유연하고 쉽게 확장 가능한 다중 턴 롤아웃을 달성하기 위해, 우리는 Tool 및 ToolEnv라는 두 가지 핵심 모듈을 신중하게 설계했다.
3.1 Tool and ToolEnv: Core Modules for Interactive Rollout
LLM 에이전트 훈련의 중심인 상호 작용 롤아웃 프로세스는 두 가지 핵심 구성 요소인 Tool과 ToolEnv에 크게 의존한다. 이 모듈들 간의 명확한 책임 분할은 Agent-R1 설계 철학의 기본이 된다.
Tool은 특정하고 원자적인 행동의 실행자로 구상된다. 그 주요 역할은 외부 API 호출, 코드 조각 실행 또는 데이터베이스 액세스와 같은 고유한 기능을 캡슐화하는 것이다. 호출될 때, Tool은 그 행동을 수행하고 해당 행동의 직접적이고 가공되지 않은 결과를 반환한다. 이는 본질적으로 "무슨 일이 일어났는지" 사실적으로 보고한다.
반대로, ToolEnv는 강화 학습(RL) 환경 내에서 오케스트레이터이자 해석자 역할을 한다. 이는 Tool로부터 받은 가공되지 않은 출력을 가져와 그 출력이 에이전트가 인지하는 상태와 전반적인 작업 진행에 어떻게 영향을 미치는지 결정한다. ToolEnv는 RL 루프 내의 상태 전이를 관리하고, 이러한 전이 및 도구 결과를 기반으로 적절한 보상 신호를 계산하며, 에이전트를 위한 새로운 상태 정보를 패키징하는 책임을 진다. 이는 "이 결과가 에이전트와 작업에 무엇을 의미하는지"를 지시한다.
3.1.1 Tool Design
Tool은 에이전트와 외부 환경 또는 기능성을 연결하는 중요한 인터페이스 역할을 수행한다. Agent-R1 프레임워크에서, 우리는 Tool을 에이전트-환경 상호 작용을 위한 통합된 인터페이스로 활용하며, 모든 외부 기능성은 에이전트가 표준화되고 직접 호출 가능한 "도구"로 캡슐화된다. OpenAI의 Function Calling 패러다임에서 영감을 받아, Agent-R1 프레임워크는 BaseTool 추상 기본 클래스를 통해 Tool의 고수준 추상화 및 표준화를 제공한다. 그 설계는 두 가지 핵심 모듈에 중점을 둔다:
핵심 실행 논리 (Core Execution Logic): BaseTool 클래스 내에서 가장 중요한 추상 메서드로서, 모든 구체적인 도구 서브클래스는 실행(execute) 메서드를 구현해야 한다. 이 메서드는 도구의 핵심 논리를 캡슐화하며, 입력 매개변수를 처리하고, 특정 작업(예: 외부 API와 상호 작용, 코드 실행 또는 데이터베이스 액세스)을 수행하며, 구조화된 결과를 반환하는 방식을 정의한다.
도구 메타데이터 명세 (Tool Metadata Specification): 도구 호출의 표준화 및 구문 분석 가능성을 보장하기 위해, 다음 메타데이터 속성들이 정의된다:
- 식별 및 설명: 이름(name) 속성 (고유한 문자열 식별자)과 설명(description) 속성 (도구의 기능, 사용 사례 및 예상 효과에 대한 자세한 정보 제공)은 시너지 효과를 내며 작동한다. 에이전트는 현재 컨텍스트에 기반하여 적절한 도구를 식별하고 선택하기 위해 이들을 이해한다.
- 매개변수 구조 정의: 매개변수(parameters) 속성은 도구 호출에 필요한 입력 매개변수 구조를 정의하기 위해 JSON 스키마 명세를 따른다. 여기에는 매개변수 이름, 데이터 유형, 상세 설명, 그리고 필수 여부가 포함된다. 매개변수의 표준화는 에이전트가 예상되는 형식에 부합하는 도구 호출 매개변수를 생성할 수 있도록 보장한다.
행동 수행에서 execute 메서드의 중추적인 역할과 에이전트의 이해를 가능하게 하는 명확한 메타데이터 명세에 중점을 둔 이 설계는 LLM 에이전트가 구조화된 인터페이스를 통해 외부 환경과 효과적으로 상호 작용할 수 있도록 한다. 도구 실행의 결과는 이후 ToolEnv 모듈에 의해 처리되며, 이 모듈은 해당 환경 상태 전이를 관리할 책임이 있다. 이러한 상호 작용은 에이전트가 다중 턴 상호 작용에서 복잡한 문제를 해결하는 데 필수적이며, ToolEnv의 상태 관리 설계와 응집력 있는 연결을 형성한다.
3.1.2 ToolEnv Design
ToolEnv 모듈은 Agent-R1 강화 학습 프레임워크 내에서 동적 환경 역할을 한다. 이는 특히 도구가 관련될 때 에이전트와 세상의 상호 작용을 관리하는 책임이 있다. 이 모듈은 RL 환경에 요구되는 두 가지 핵심 기능, 즉 상태 전이와 보상 계산을 구현하며, 특히 다중 턴 상호 작용 및 도구 사용으로 인한 비결정론적 결과의 맥락에서 그러하다. 이 설계는 BaseToolEnv 추상 기본 클래스를 통해 공식화된다.
핵심 상태 전이 및 보상 논리 (Core State Transition and Reward Logic): 가장 중요한 추상 메서드는 step이다. 이 메서드는 환경 상호 작용을 위한 주요 엔진이다. 이는 에이전트의 가공되지 않은 출력(예: 도구 호출을 잠재적으로 포함하는 생성된 텍스트)을 수신하고, 이 출력을 처리하여 Tool 모듈과 조정하여 도구 호출을 식별하고 조직한다. 에이전트의 행동과 도구 실행의 피드백을 기반으로, step은 이후 환경의 내부 상태를 업데이트한다. 또한 행동의 결과와 새로운 상태를 반영하는 적절한 보상 신호를 계산한다. 마지막으로, 이는 에이전트에게 새로운 상태, 보상 및 기타 관련 정보(예: 성공 상태 및 활동 플래그)를 반환한다. 이 메서드는 표준 생성적 상태 전이와 도구 상호 작용으로 인한 더 복잡하고 잠재적으로 확률적인 전이 모두에 대한 논리를 캡슐화한다.
상호 작용 관리를 위한 지원 메커니즘 (Supporting Mechanisms for Interaction Management): step 메서드의 포괄적인 역할을 용이하게 하고 도구 기반 상호 작용의 미묘한 차이를 관리하기 위해, BaseToolEnv 내에는 몇 가지 핵심 보조 메서드가 정의된다. process_responses_ids 메서드는 LLM이 생성한 가공되지 않은 토큰 ID 시퀀스 내에서 도구 호출 트리거를 식별하는 사용자 정의 가능한 논리를 제공하여 정확한 호출 지점을 결정한다. 이어서, extract_tool_calls는 이러한 가공되지 않은 LLM 응답을 구문 분석하여 도구 이름과 매개변수를 포함한 의도된 도구 호출 요청을 식별하고 구조화할 책임이 있다. 도구 실행 후, format_tool_response는 가공되지 않은 결과(Tool.execute에서 얻은)를 새 환경 상태의 일부로 LLM에 제시하기에 적합한 문자열 형식으로 변환된다. 이러한 메서드를 보완하여, stop 메서드는 LLM 출력, 작업 완료, 오류 상태 또는 미리 정의된 제한을 기반으로 현재 상호 작용을 종료해야 하는지 여부를 평가하는 궤적 종료 조건을 결정하기 위한 논리를 구현한다.
→ 전처리 및 후처리 하는 애들
환경 역학을 주도하는 step 메서드의 중추적인 역할에 중점을 두고 도구 호출 및 궤적 수명 주기를 관리하기 위한 명확한 메커니즘으로 지원되는 이 설계는 Agent-R1 프레임워크가 복잡한 상호 작용 시나리오를 효과적으로 시뮬레이션할 수 있도록 한다. 이는 에이전트 학습에 결정적인, 결정론적 텍스트 생성과 도구 사용으로 도입되는 비결정론적이고 환경을 변경하는 상태 변화를 신중하게 구분한다.
3.2 Optimizing Agent Policy from Multi-Turn Trajectories
롤아웃 단계를 거친 후, 우리는 포괄적인 다중 턴 상호 작용 궤적을 확보하게 된다. 각 궤적은 상태 시퀀스, 에이전트의 행동(생성된 텍스트 부분), 그리고 보상 신호를 포함한다. 언급된 바와 같이, 환경은 잠재적인 최종 결과 보상 외에도, 과정 보상 이라고 불리는 보상 신호를 각 상호 작용 턴에 대해 제공한다. 궤적 내에서 LLM 에이전트가 생성한 토큰(즉, 에이전트의 행동)을 환경 피드백이나 초기 프롬프트와 명확하게 구분하기 위해, 우리는 액션 마스크(Action Mask)를 도입한다. 이 마스크는 시퀀스의 어느 부분이 에이전트의 학습 가능한 행동에 정확히 해당하는지 식별한다.
강화 학습은 기대 누적 보상을 최대화하도록 정책 모델의 행동을 최적화한다. Agent-R1 프레임워크는 학습 단계(Figure 4 참조) 동안 이러한 목표를 달성하기 위해 액션 마스크와 과정 보상을 포함하는 이 다중 턴 궤적의 상세 정보를 활용한다. 이 정보가 활용되는 핵심 측면들은 다음과 같다:
정제되고 정렬된 이점 계산 (Refined and Aligned Advantage Calculation): 생성 단계(Figure 3 참조)에서 볼 수 있듯이, "이점(Advantages)"은 더 이상 최종 결과 보상과 Critic 모델로부터의 가치 추정치에만 전적으로 기반하지 않는다. 롤아웃 중에 ToolEnv로부터 수집된 "과정 보상(Process Rewards)"이 명시적으로 통합된다. 이는 궤적 내의 각 관련 단계 에서의 이점 가 미래 할인 보상(결과 보상과 가치 함수 추정치에서 파생됨)뿐만 아니라, 효과적인 도구 호출과 같은 중간 단계의 즉각적인 성공(과정 보상으로 포착됨)까지 반영함을 의미한다. Figure 3의 “Advantages” 블록은 이것이 “Values” (Critic 모델), “Outcome Reward” (Reward 모델), 및 ”Process Rewards”로부터 입력을 받는 것을 보여준다. 결정적으로, 이러한 이점 의 계산(예를 들어, 일반화된 이점 추정 - GAE 사용)은 액션 마스크에 의해 식별된 에이전트의 행동과 정렬되도록 수행된다. 보상은 상태 전이를 기반으로 누적되고 가치 함수는 상태의 좋음을 추정하지만, 정책 업데이트에 사용되는 최종 이점은 에이전트가 행동을 생성한 특정 시점과 관련이 있다. 이는 (긍정적 또는 부정적 이점 형태의) 신뢰 할당(credit)이 프롬프트 토큰이나 고정된 환경 응답과 같이 에이전트가 통제하지 않은 시퀀스 부분이 아닌, 에이전트가 내린 실제 결정에 할당되도록 보장한다. 이러한 행동 정렬 이점은 이후 학습 단계(Figure 4 참조)로 전달된다.
마스킹된 정책 최적화 (Actor Loss): 학습 단계(Figure 4)에서 Actor 모델(정책)은 더 높은 이점으로 이어지는 행동의 확률을 높이도록 업데이트된다. "Trajectory" 데이터는 Actor 모델에 공급되어 "New Action Logits"를 생성한다. 여기서 액션 마스크가 결정적인 역할을 수행한다. Actor 손실(종종 PPO의 클리핑된 대리 목적 함수와 같은 정책 기울기 손실)을 계산할 때, 마스크는 손실이 에이전트가 생성한 토큰에 대해서만 계산되도록 보장한다. 새로운 정책의 행동 확률과 이전 정책의 행동 확률("New Action Logits"와 생성 단계의 "Action Logits"에서 각각 파생됨) 간의 "비율(Ratio)"은 이러한 정렬된 이점에 의해 조정되며, 이 계산은 액션 마스크에 의해 유도된다.
가치 함수 업데이트 (Critic Loss): Critic 모델은 다른 상태로부터의 예상 누적 보상(가치)을 더 정확하게 추정하도록 훈련된다. "Trajectory" 데이터를 사용하여, 이는 "New Values"를 생성한다. Critic 손실은 일반적으로 이 "New Values"와 궤적에서 관찰된 반환값 (과정 보상과 결과 보상 모두를 포함) 또는 이러한 반환값과 기존 가치 추정치에서 파생된 목표 가치(예: TD 학습에서) 간의 평균 제곱 오차이다. 이는 Critic이 후속 반복에서 이점 계산을 위한 더 나은 기준선 추정치를 제공하는 데 도움을 준다.
"Advantages"가 에이전트의 실제 행동과 일치하도록 보장하고 (그리고 이후 정책 최적화 중에 "Action Mask"와 함께 사용되도록 보장함으로써), Agent-R1은 더욱 정확하고 효과적인 학습 신호를 제공한다. 이 상세한 피드백 메커니즘은 Actor 및 Critic 모델이 복잡하고 확장된 대화 및 도구 사용 시나리오로부터 더 효율적으로 학습할 수 있도록 하며, 에이전트가 정교한 작업을 숙달하도록 이끈다.
4. Empirical Study
우리는 LLM이 외부 검색을 사용하는 도전적인 다중 홉 질의응답 시나리오에서 Agent-R1의 효능과 설계 기여도를 경험적으로 평가한다. 이 연구는 먼저 다양한 강화 학습(RL) 알고리즘을 사용하여 다중 턴 상호 작용 작업에 대한 LLM 에이전트 훈련에서 프레임워크의 효과를 검증한다. 둘째, 손실 계산을 위한 액션 마스크("손실 마스크")와 이점 정렬을 위한 액션 마스크("이점 마스크")라는 핵심 정책 최적화 개선 사항의 영향을 조사하는 절제 분석(ablation analysis)을 수행한다. 전반적인 목표는 도구 호출 및 정보 검색에 대한 LLM의 학습된 능력을 평가하여, Agent-R1의 유용성을 강조하는 것이다.
4.1 Experimental Setup
Tasks and Datasets
우리의 연구는 다중 홉 질의응답 (MultihopQA) 데이터셋을 사용한다. 훈련 셋은 HotpotQA 및 2WikiMultihopQA training split에서 무작위로 균등하게 추출된 51,200개의 샘플로 구성된다. 우리는 HotpotQA 및 2WikiMultihopQA (in-domain)의 전체 development 세트와 Musique (out-of-domain)의 전체 development 세트를 대상으로 평가를 수행하며, 이 모든 데이터셋은 다단계 검색 및 추론을 요구한다.
Models and Tools
실험은 Qwen2.5-3B-Instruct 모델을 NousToolEnv 내에서 자체적인 함수 호출을 사용하여 진행한다. 에이전트는 단일 wikisearch 도구를 사용하며, 이 도구는 KILT Wikipedia 코퍼스를 bge-large-en-v1.5 임베딩을 사용하여 질의하고 상위 5개의 문서를 반환한다.
RL Algorithms and Baselines
우리는 Agent-R1의 적응성을 평가하기 위해 PPO, GRPO, REINFORCE++, REINFOCE++Baseline, 그리고 RLOO 알고리즘을 평가한다. 이 알고리즘들은 두 가지 베이스라인, 즉 Naive RAG (단일 통과 검색) 및 Base Tool Call (wikisearch 도구를 사용하는 기본 함수 호출)과 비교된다.
Reward Formulation
희소한 최종 결과 보상 가 사용되며, 다음과 같이 정의된다:
여기서 는 정확 일치 (Exact Match) 점수이다. 포맷팅 점수 는 올바른 최종 답변 표현( 및 유효한 도구 호출 구문()에 대한 이진 지표의 평균이다. 이 구조는 완벽하게 포맷되고 정확한 답변에 엄격하게 보상을 제공하며, 모든 포맷팅 오류에 대해 벌칙을 부과한다.
4.2 Main Results
Agent-R1에 의해 지원되는 다양한 강화 학습(RL) 알고리즘의 성능을 기준선 방법과 비교하여 평가한 프레임워크 검증의 주요 결과는 표 3에 제시된다. 실험은 세 가지 다중 홉 질의응답 데이터 세트를 대상으로 수행된다. HotpotQA와 2WikiMultihopQA (2Wiki)는 도메인 내 데이터 세트 역할을 수행했으며, Musique는 도메인 외 데이터 세트로 사용된다. 보고된 점수는 작업 성공의 주요 메트릭을 나타내는 정확 일치(Exact Match, EM) 값이다.
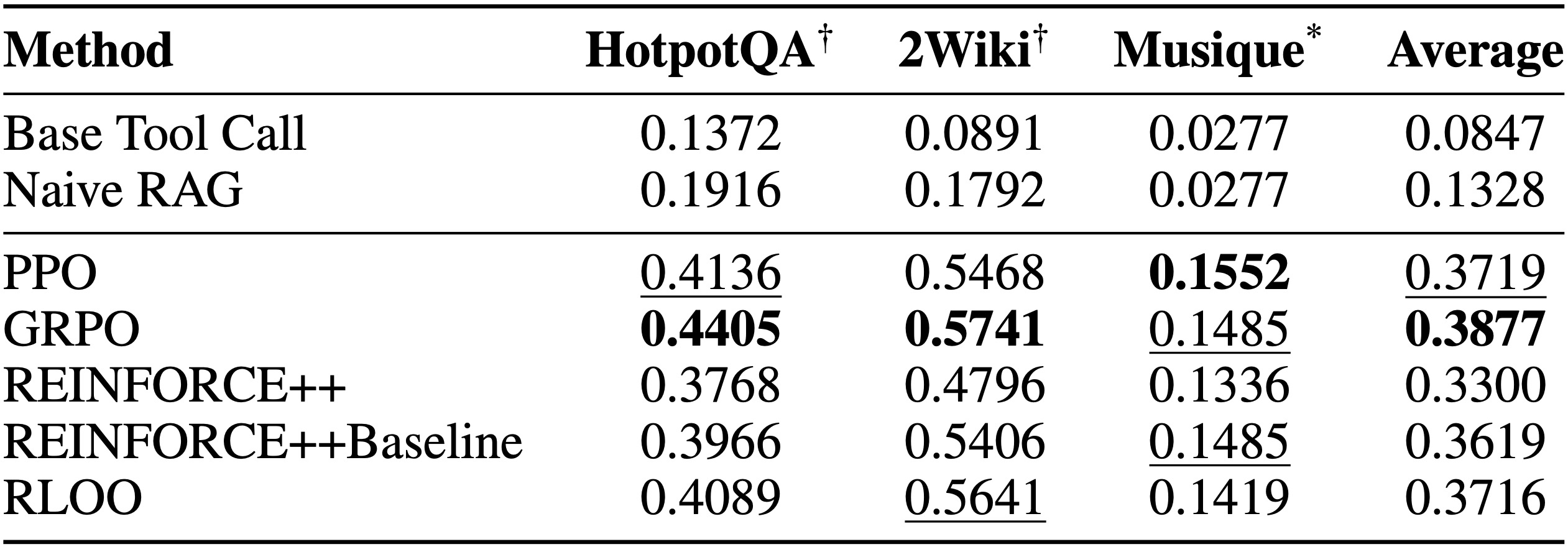
Table 3: EM Performance Comparison of RL Algorithms and Baselines on MultihopQA Datasets
표 3은 모든 RL로 훈련된 에이전트가 Base Tool Call (0.0847)과 Naive RAG (0.1328) 베이스라인보다 실질적으로 더 나은 성능을 보임을 명확하게 입증한다. 예를 들어, 가장 약한 RL 에이전트(REINFORCE++, 평균 EM 0.3300)조차도 RAG를 약 2.5배의 요인으로 능가했다. 이 상당한 차이는 더 단순한 발견적 방법이나 단일 통과 방법을 넘어, 복잡한 다중 턴 의사 결정 및 효과적인 도구 사용이 가능한 능숙한 LLM 에이전트를 훈련하는 데 있어 RL의 중요한 역할을 강조한다.
RL 방법들 중에서 GRPO(평균 EM 0.3877)가 전반적으로 가장 좋은 성능을 보였으며, PPO(0.3719)와 RLOO(0.3716)가 그 뒤를 바짝 쫓는다. PPO는 도전적인 도메인 외 Musique 데이터 세트에서 특히 뛰어난 성능을 보였다. REINFORCE++(0.3300)는 RL 수행자 중 가장 약했지만, REINFORCE++Baseline(0.3619)에 베이스라인을 통합함으로써 명확한 이점을 제공했으나, 최고 수준의 알고리즘에는 미치지 못한다. 이러한 결과는 Agent-R1이 end-to-end RL을 통해 강력한 LLM 에이전트를 훈련하는 데 있어 효능을 강력하게 검증하며, 다양한 데이터 세트와 RL 알고리즘 전반에 걸쳐 기준선 대비 일관되고 실질적인 이득을 보여준다. 이는 상호 작용 설정에서 에이전트 정책을 최적화하기 위한 우리 프레임워크의 가치를 확증한다.
4.3 Ablation Study on Policy Optimization Refinements
Agent-R1 프레임워크 내에서 특정 정책 최적화 개선 사항들, 즉 손실 계산을 위한 액션 마스크("손실 마스크"라고 명명됨)와 이점 정렬을 위한 액션 마스크("이점 마스크"라고 명명됨)의 중요성을 조사하기 위해, 우리는 절제 연구를 수행한다. 이 연구는 PPO 및 GRPO 알고리즘을 활용한다. 정확 일치(Exact Match, EM) 점수 측면의 결과는 표 4에 제시되며, 여기서 각 절제 단계는 해당 알고리즘 내에서 바로 이전 행의 구성과 비교하여 표시된다.
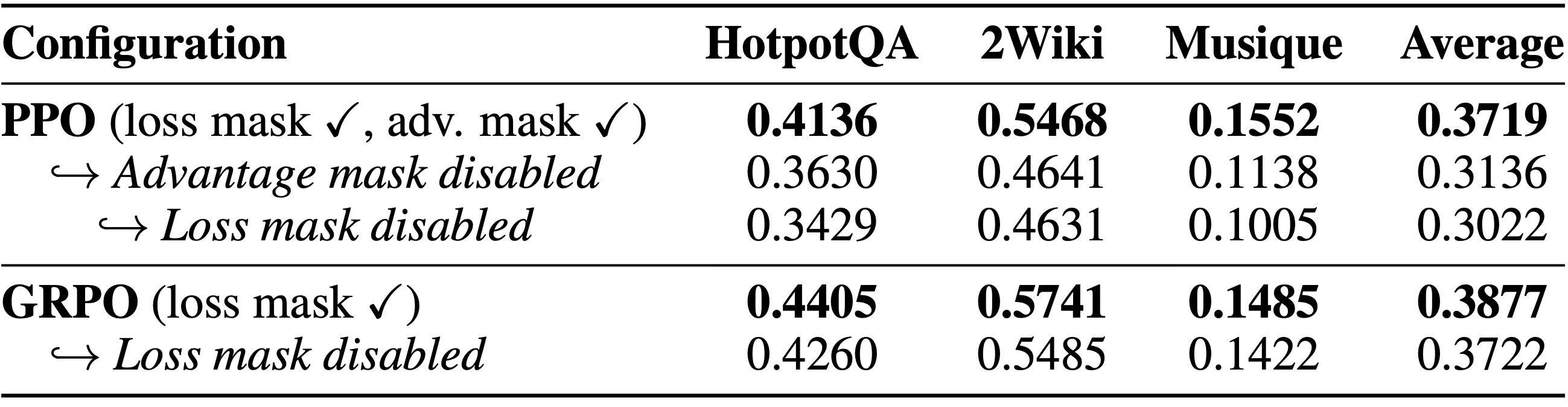
Table 4: Ablation Study on Policy Optimization Components
절제 실험(표 4)은 손실 마스크와 이점 마스크 모두의 결정적인 역할을 강조한다. 손실 마스크를 비활성화하면 PPO(예: 이점 마스크가 이미 비활성화된 PPO 변형에서 제거했을 때 평균 EM이 0.3136에서 0.3022로 하락함)와 GRPO(평균 EM이 0.3877에서 0.3722로 하락함) 모두에서 일관되게 성능이 저하된다. 이는 에이전트가 생성한 토큰에 그래디언트(gradients)를 집중시키는 것의 필요성을 보여준다. 마찬가지로, PPO의 경우 이점 마스크를 비활성화하면(손실 마스크가 활성화된 상태에서, 처음 두 PPO 행을 비교함) 평균 EM이 0.3719에서 0.3136으로 실질적인 성능 하락을 야기하며, 정확한 신뢰 할당(credit assignment)의 중요성을 확증한다. 이러한 발견은 이러한 마스킹 전략들이 상호 작용하는 LLM 에이전트의 효과적인 정책 최적화를 위해 Agent-R1 내에서 매우 중요한 설계 선택임을 검증한다.
5. Conclusion
본 연구는 고전적인 마르코프 결정 과정(MDP) 프레임워크를 확장하여 다중 턴 상호 작용, 환경 피드백, 그리고 과정 보상을 포착함으로써, 강화 학습(RL)이 대규모 언어 모델 에이전트에 효과적으로 적용될 수 있는 방법을 명확히 한다. 이러한 통찰을 바탕으로, 우리는 Agent-R1을 소개한다. Agent-R1은 다중 턴 롤아웃, 정확한 신뢰 할당(credit assignment), 그리고 도구와 환경의 유연한 통합을 지원하는 모듈식이며 확장 가능한 프레임워크이다. 다중 홉 질의응답 작업에 대한 실험은 Agent-R1이 LLM 에이전트가 베이스라인 방법보다 실질적인 성능 향상을 달성하도록 지원함을 입증한다. 또한, 절제 연구 결과는 핵심 정책 최적화 구성 요소 (예: 손실 및 이점 마스크)의 중요성을 확인한다. 우리는 Agent-R1이 에이전트 LLM을 위한 확장 가능하고 통합된 RL 훈련의 미래 연구에 토대를 제공하기를 희망한다.
