Spatial-Aware VLA Pretraining through Visual-Physical Alignment from Human Videos
Paper Translate
Author: Yicheng Feng, Wanpeng Zhang, Ye Wang, Hao Luo, Haoqi Yuan, Sipeng Zheng, Zongqing Lu
Affilation: Peking University, Renmin University of China, BeingBeyond
Venue: arXiv
Comment:
Date: December 2025
Paper Link: https://arxiv.org/abs/2512.13080
⭐️ Key Takeaways
1. 기존 VLA 모델의 2D 시각 입력과 3D 물리 공간 사이의 간극을 해결하기 위해, 대규모 인간 영상에서 추출한 3D 시각 및 행동 주석을 활용하여 시각 공간과 물리 공간을 명시적으로 정렬하는 '공간 인식 VLA 사전 학습' 패러다임을 제안한다.
2. 의미론적 인코더와 3D 시각 인코더를 결합한 이중 인코더 아키텍처인 VIPA-VLA와 인간의 조작 활동을 3D로 정밀하게 주석 처리한 Hand3D 데이터셋을 통해, 로봇이 2D 화면을 넘어 입체적인 물리 세계를 이해하도록 돕는다.
3. 이 모델은 사전 학습 단계에서 로봇 데이터 없이 인간의 시연만으로도 정밀한 3D 공간 추론 능력을 습득하여, 시뮬레이션 및 실제 로봇 조작 작업에서 기존 베이스라인 모델보다 뛰어난 일반화 성능과 실행 견고함을 입증한다.
Abstract
VLA(Vision-Language-Action) 모델은 시각적 인식과 언어 가이드 정책 학습을 통합함으로써 로봇 학습을 위한 유망한 패러다임을 제공한다. 그러나 대부분의 기존 접근 방식은 3차원 물리적 환경에서 행동을 수행하기 위해 2차원 시각적 입력에 의존하며, 이는 인식과 행동 접지(grounding) 사이에 상당한 격차를 발생시킨다. 이러한 격차를 해소하기 위해, 본 연구는 사전 학습 중에 시각 공간과 물리 공간 사이의 명시적인 정렬을 수행하여 모델이 로봇 정책 학습 전에 3차원 공간 이해를 습득할 수 있게 하는 공간 인식 VLA 사전 학습(Spatial-Aware VLA Pretraining) 패러다임을 제안한다. 사전 학습된 시각-언어 모델(VLM)에서 시작하여, 대규모 인간 시연 영상을 활용해 3차원 시각 및 3차원 행동 주석을 추출하며, 이를 통해 2차원 시각 관측과 3차원 공간 추론을 정렬하는 새로운 감독 소스를 형성한다. 본 연구는 의미론적 시각 표현을 3차원 인식 기능으로 보강하기 위해 3차원 시각 인코더를 통합한 이중 인코더 아키텍처인 VIPA-VLA를 통해 이 패러다임을 구체화한다. 하위 로봇 작업에 적응할 때, VIPA-VLA는 2차원 시각과 3차원 행동 사이의 접지 능력을 대폭 향상시켜 더욱 견고하고 일반화 가능한 로봇 정책을 도출한다.
1. Introduction
대규모 시각-언어 모델(VLM)의 급격한 발전은 모달리티 전반에 걸친 공동 표현 학습에서 주목할 만한 능력을 보여주었다. 이러한 진전은 로봇 정책 학습을 위한 새로운 기회를 열어주었으며, 여기서 VLM은 시각적 관측과 언어 명령을 모두 이해하기 위한 견고한 토대를 제공하여 로봇이 물리적 세계와 상호작용하도록 안내한다. 이러한 토대 위에서, VLA(Vision-Language-Action) 패러다임은 최근 광범위한 작업에서 일반화된 로봇 정책을 개발할 수 있는 잠재력을 보여주었다.
그럼에도 불구하고, 현재의 VLA 모델들은 일반적으로 3차원 물리적 환경에서 행동을 수행하면서도 세계를 인식하기 위해 2차원 시각적 입력에 의존하며, 이는 시각적 인식과 구현된 행동(embodied action) 사이에 상당한 격차를 남긴다. 이러한 약한 대응 관계는 물리적 공간에서 행동을 접지(grounding)하는 능력을 제한한다. 효과적인 정책 학습을 위해 에이전트는 픽셀을 해석할 뿐만 아니라, 이러한 시각적 단서가 3차원 기하학에 어떻게 매핑되는지, 그리고 물리적 행동이 주변 환경과 어떻게 상호작용하는지 이해해야 한다. 인간은 2차원 시각 신호로부터 3차원 공간을 추론할 수 있는 반면, 기존 VLA 모델들은 이 측면을 대체로 간과하여 열악한 공간 접지와 제한된 일반화 성능을 초래한다.
이러한 격차를 해소하기 위해, 본 연구는 모델이 로봇 정책을 학습하기 전에 3차원 공간 인식을 습득할 수 있게 하는 새로운 공간 인식 VLA 사전 학습(Spatial-Aware VLA Pretraining) 패러다임을 도입한다. 사전 학습된 VLM에서 시작하여, 2차원 시각 관측과 3차원 물리적 행동 사이의 암시적 대응 관계가 자연스럽게 존재하는 대규모 인간 시연 영상을 풍부한 감독 소스로 활용한다. 로봇 데이터와 비교할 때, 인간 시연은 다양한 환경에서 획득하기가 더 쉬우며 다양한 시각적 맥락 하에서 물리적 세계의 행동이 어떻게 수행되는지에 대한 풍부한 증거를 자연스럽게 제공한다. 본 연구는 이러한 영상에서 손-객체 관계 및 이동 궤적과 같은 3차원 단서를 추출함으로써, 모델이 2차원 시각을 3차원 공간 이해와 정렬하도록 가르치는 사전 학습 작업을 구성하며, 이를 시각-물리적 정렬(visual-physical alignment)이라고 정의한다. 이러한 공간적으로 접지된 사전 학습은 후속 VLA 사후 학습(post-training)을 위한 강력한 토대를 제공하여 모델이 로봇 조작 작업에서 더욱 효과적으로 학습하고 일반화할 수 있게 한다.
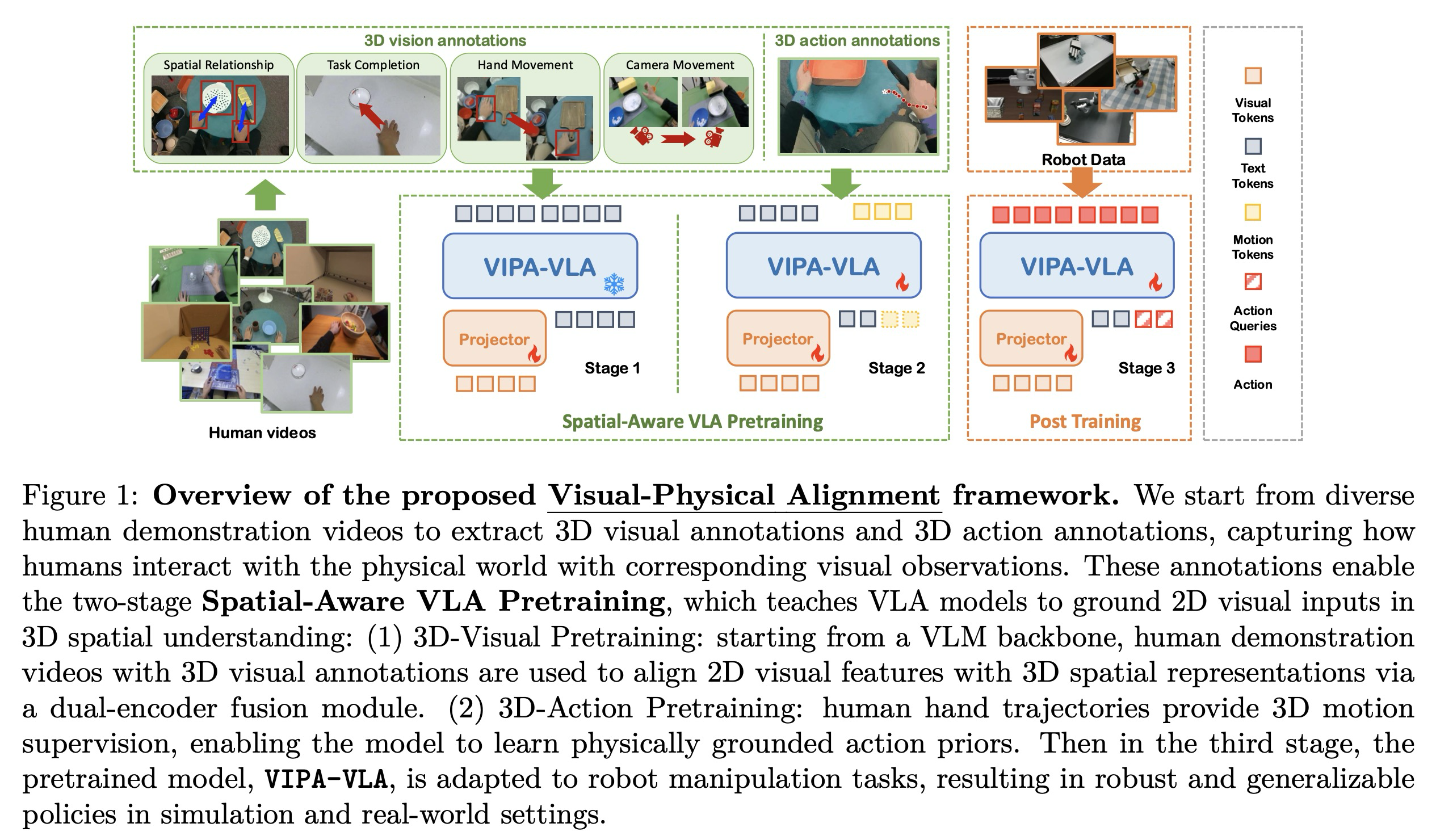
이 패러다임을 구체화하기 위해, 본 연구는 의미론적 시각 표현을 명시적인 3차원 공간 기능으로 보강하는 이중 인코더 아키텍처인 VIPA-VLA(Visual-Physical-Alignment-VLA)를 제시한다. 시각, 언어 및 3차원 행동 사이의 정렬은 주석이 달린 손 포즈를 포함한 다양한 인간 조작 기록으로 구축된 본 연구의 데이터셋인 Hand3D에서의 공간 인식 VLA 사전 학습을 통해 달성된다. 이러한 영상으로부터 두 가지 형태의 공간 감독 정보를 도출한다. 첫 번째는 시각적 입력과 물리적 구성 사이의 거친 수준(coarse-grained)의 공간 접지를 제공하는 3차원 시각 주석이며, 두 번째는 인간 조작 역학을 인코딩하는 3차원 궤적을 통해 미세한 수준(fine-grained)의 운동 감독을 제공하는 3차원 행동 주석이다. 사전 학습된 모델은 이후 사후 학습을 통해 로봇 작업에 적응하며, 학습된 공간 추론 능력을 로봇 제어로 전이한다. 요약하자면, 본 연구의 기여는 다음과 같다:
- 대규모 인간 영상 데이터를 통해 2차원 시각 인식과 3차원 물리적 행동 사이의 가교 역할을 하는 새로운 공간 인식 VLA 사전 학습 패러다임을 제안한다.
- 시각-물리적 정렬 감독을 가능하게 하는 3차원 시각 및 행동 주석을 포함한 인간 조작 영상 데이터셋인 Hand3D를 구축한다.
- 본 연구의 패러다임으로 사전 학습된 이중 인코더 VLA 아키텍처인 VIPA-VLA를 제시하며, 이는 하위 로봇 작업에서 공간 접지 및 일반화 성능을 크게 향상시킨다.
2. Related Work
2.1 VLA models
시각-언어-행동(VLA) 모델은 시각적 관측과 언어 명령의 공동 표현을 활용하여 물리적 환경에서 행동 실행을 가능하게 하는 것을 목표로 한다. 일부 이전 연구들은 로봇 행동을 토큰화하고 로봇 데이터셋에서 사전 학습된 VLM을 미세 조정한다. 이러한 사전 학습 패러다임을 지원하기 위해 대규모 로봇 데이터셋이 도입되었다. 다른 연구들은 행동 생성의 품질을 향상시키기 위해 추가적인 행동 전문가를 통합한다. 일부 접근 방식은 표현 학습을 위해 시연 영상을 활용하거나, 행동 학습을 강화하기 위해 미래 상태 예측을 활용한다. 보다 최근에는 GR00T-N1 및 가 대규모 VLA 사전 학습을 위해 방대한 멀티모달 인터넷 데이터와 로봇 데이터셋을 결합하여 일반화 성능을 크게 향상시킨다. 이와 대조적으로, 본 연구는 인간 영상으로부터의 공간 인식 VLA 사전 학습을 통해 환경 내 행동을 더 잘 접지하기 위한 3차원 물리적 공간 이해에 초점을 맞춘다.
2.2 3D Aware Models
최근 3차원 시각-언어 모델(3D VLM)의 발전은 3차원 공간 정보를 통합함으로써 멀티모달 모델의 지각 능력을 2차원 영상을 넘어 확장하는 것을 목표로 한다. 일부 접근 방식은 명시적인 3차원 주석이 포함된 데이터셋을 활용하는 반면, 다른 방식들은 단안 시각 입력에서 3차원 구조를 추론하기 위해 기하학적 사전 정보나 깊이 추정 모델에 의존한다. 이러한 방법들은 공간적 관계, 객체 기하학 및 장면 구조에 대해 추론하는 VLM의 능력을 향상시켰다. 그러나 기존 3차원 VLM의 초점은 행동보다는 주로 인식에 맞춰져 있다. 이들은 정적인 관측에 대한 공간적 이해를 강화하지만, 로봇 정책 학습에 필요한 3차원 인식과 물리적 행동 공간 사이의 대응 관계를 명시적으로 구축하지는 않는다. 결과적으로 VLA 모델 학습에 있어 이들의 유용성은 여전히 제한적이다.
최근 연구들은 또한 3차원 공간 추론을 통해 VLA를 강화하는 방안을 탐구해 왔다. 예를 들어, 3D-VLA는 미래 영상 및 포인트 클라우드의 확산 기반 렌더링을 포함하는 생성적 세계 모델을 도입하며, SpatialVLA는 자기 중심적 위치 인코딩과 적응형 행동 그리드를 통해 정책 학습을 개선한다. 본 연구는 인간 영상에서 추출한 3차원 인식 주석을 활용하고 3차원 인코더를 통합하여 2차원 시각 관측을 3차원 물리적 공간과 명시적으로 정렬함으로써, 사전 학습 단계를 통해 VLA에 3차원 공간 이해 능력을 부여하고자 한다는 점에서 차별화된다. 이러한 공간 인식 사전 학습은 하위 정책 학습 전에 VLA가 더 강력한 3차원 접지(grounding) 능력을 갖추도록 한다.
2.3 Learning from human videos
한 연구 분야에서는 로봇 정책 학습을 촉진하기 위해 인간 시연 영상을 활용하는 방안을 탐구해 왔다. 일부 연구는 인간 활동에서 잠재 특징(latent features)을 추출하기 위해 표현 학습 접근 방식을 채택하지만, 이러한 표현은 일반적으로 암시적이며 명시적인 행동 접지(grounding)를 위한 제한적인 지침만을 제공한다. 다른 방법들은 인간의 행동 공간을 로봇의 행동 공간과 직접 정렬하려고 시도한다. 그러나 이러한 접근 방식은 인간과 로봇의 물리적 능력과 운동학이 크게 다르기 때문에 구현(embodiment)의 불일치 문제를 겪는다. 또한, 여러 연구에서 행동 유도성(affordance)이나 파지(grasping) 전략과 같이 인간 영상에서 상호작용 관련 지식을 추출하는 방안을 탐구하며, 이는 유용한 단서를 제공하지만 3차원 물리적 공간에서 인식과 행동을 명시적으로 연결하는 데까지는 이르지 못한다. 이 외에도, Being-H0는 VLA 사전 학습을 위해 인간 영상을 활용하지만, 주요 초점은 조작 동작 시퀀스를 학습하는 데 있다. 이와 대조적으로, 본 연구는 구현의 격차에도 불구하고 인간 영상이 다양한 시각적 맥락에서 3차원 물리적 세계 내 행동이 어떻게 수행되는지에 대한 풍부한 정보를 담고 있다는 점을 강조한다. 본 연구는 이러한 정보를 공간 인식 사전 학습을 위한 감독 정보로 활용하여, VLA 모델이 하위 정책 학습 전에 2차원 시각 관측과 3차원 행동 공간 사이의 접지된 대응 관계를 습득할 수 있게 한다.
3. Method
본 절에서는 먼저 시각-언어 모델(VLM) 및 시각-언어-행동 모델(VLA)에 대한 예비 지식을 제공한다 (3.1절). 이어서 3.2절에서는 공간 인식 데이터셋인 Hand3D(3.2.1절), 모델 아키텍처인 VIPA-VLA(3.2.2절) 및 공간 인식 VLA 사전 학습(3.2.3절)을 포함한 시각-물리적 정렬(Visual-Physical Alignment)에 대해 상술한다. 마지막으로 3.3절에서는 모델을 로봇 작업에 적응시키기 위한 사후 학습(post-training) 절차를 기술한다.
3.1 Preliminaries
먼저 시각-언어 모델(VLM)과 시각-언어-행동 모델(VLA)의 설정을 간략하게 공식화한다. VLM은 일련의 시각적 입력 (예: 이미지 또는 비디오 프레임)와 언어 명령 (예: 질문 또는 명령)을 정렬된 임베딩 공간으로 매핑하여 답변이나 캡션과 같은 텍스트 출력 를 생성하도록 설계된다:
이와 대조적으로, VLA는 이러한 공식을 행동 영역으로 확장한다. 여기서 모델은 시각과 언어 사이의 의미론적 정렬을 포착할 뿐만 아니라, 3차원 물리적 환경에서 실행 가능한 행동을 생성해야 한다. 시각적 관측 와 명령 이 주어지면, VLA는 다음과 같이 행동 청크(action chunk) 를 예측한다:
이러한 차이점은 본 연구에서 다루는 핵심 과제를 강조한다. VLM은 시각-의미론적 추론에 탁월하지만, VLA는 추가적으로 시각적 인식을 3차원 물리적 행동 공간에 접지(grounding)하는 능력을 요구하며, 이는 본 연구가 제안하는 공간 인식 VLA 사전 학습 패러다임의 동기가 된다.
3.2 Visual-Physical Alignment
3.2.1 Hand3D
기존의 3차원 시각-언어 모델(VLM)은 일반적으로 명시적인 3차원 주석이 포함된 데이터셋이나 2차원 입력으로부터의 깊이 추정을 통해 3차원 감독 정보를 획득한다. 본 연구는 이러한 원칙을 따르되, 3차원 공간에서 행동이 전개되는 방식을 본질적으로 보여주는 인간 시연 영상에 집중한다. 이러한 영상은 시각-물리적 대응 관계에 대한 풍부한 소스를 자연스럽게 제공하며, 이를 통해 2차원 시각 관측을 행동 관련 3차원 정보와 정렬하는 주석을 구축하여 VLA 모델의 시각-물리적 정렬을 위한 토대를 형성한다.
Human video collection. 다양한 작업과 상호작용 시나리오를 아우르는 인간 조작 영상 수집에서 시작한다. UniHand를 따라, 본 연구는 다음과 같은 광범위한 소스로부터 데이터를 통합한다: (1) 모션 캡처 데이터셋: Arctic, HOI4D, FPHA, H2O, OAKINK2, TACO, Dex-YCB, (2) VR 기록 데이터셋: EgoDex, (3) 의사 주석(pseudo-annotated) 데이터셋: Taste-Rob. 각 데이터셋은 객체 중심 조작을 수행하는 인간의 기록과 그에 상응하는 손 동작 시퀀스를 제공한다. 이질적인 데이터셋 간의 일관성을 보장하기 위해, 모든 손 주석을 인간 손 포즈 및 형태의 표준 파라메트릭 모델인 통합된 MANO 표현으로 정렬한다. 3차원 손 관절 주석이 있는 데이터셋의 경우, 경사 최적화를 통해 MANO 파라미터를 피팅한다. Taste-Rob과 같이 영상으로만 구성된 데이터셋의 경우, HaWoR를 사용하여 손의 MANO 파라미터를 추정한다. 이러한 정렬을 통해 시각적 프레임과 직접 연결될 수 있는 고품질의 정규화된 손 궤적 주석을 획득할 수 있다.
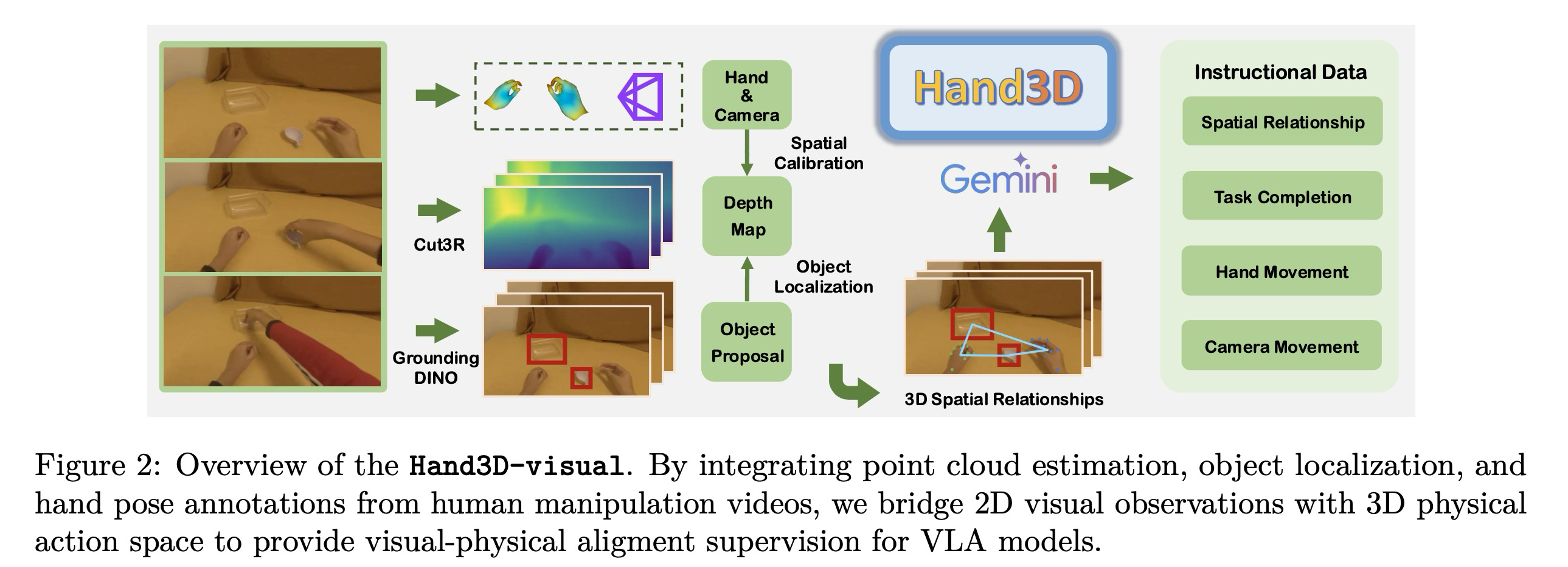
3D aware annotations. 기존 연구들이 인간 영상으로부터의 학습을 탐구해 왔으나, 대부분 2차원 시각 공간에 국한되어 로봇 조작의 3차원 행동 실행에 필요한 물리적 접지 능력을 포착하는 데 한계가 있었다. 본 연구는 인간 시연으로부터 3차원 시각 주석과 3차원 행동 주석을 추출함으로써 이를 해결한다.
그림 2에 나타난 바와 같이, 포인트 클라우드 추정, 객체 제안(proposal), 손 포즈 정보를 결합하여 인간 조작 영상으로부터 3차원 시각 주석을 구축한다. 구체적으로, 먼저 Cut3R 모델을 채택하여 각 이미지 픽셀에 대한 3차원 좌표를 제공하는 프레임별 조밀한 포인트 클라우드 추정치 를 얻는다. Cut3R은 동적인 장면에서의 견고함과 인간-객체 상호작용 데이터에 대한 사전 학습 덕분에 선택되었다. 객체 로컬라이제이션을 위해, Gemini-2.5-flash를 적용하여 객체 제안을 생성하고 GroundingDINO를 사용하여 이미지 내 각 객체의 공간적 범위를 근사하는 2차원 경계 상자 를 얻는다. 이러한 경계 상자를 로부터 얻은 깊이 추정치와 결합하여, 3차원 공간에서 각 객체의 위치를 특정하고 대략적인 공간적 위치를 획득한다.
이와 병행하여, 카메라 외부 파라미터 및 내부 파라미터 와 함께 데이터셋에서 제공되는 MANO 기반 손 포즈 주석 을 활용한다. MANO 파라미터를 카메라 좌표계로 변환하여 3차원 관절 위치 를 산출한다. 이러한 관절 좌표를 이미지 평면에 투영하고, 투영된 관절의 가시성을 확인하여 손이 시야 밖에 있는 프레임은 필터링한다.
이전 연구들은 3차원 정보를 도입하기 위해 깊이 추정 모델에 의존해 왔으나, 이러한 모델이 제공하는 상대적 스케일은 실제 물리적 공간과 일치하지 않아 정렬 오류를 유발할 수 있다. 행동은 실제 세계의 물리적 스케일에서 실행되므로 이러한 불일치는 행동 학습에 문제가 될 수 있다. 상대적인 포인트 클라우드 추정치 와 물리적 공간 사이의 스케일을 통일하기 위해, 절대적인 공간 위치인 손 관절 위치 를 상응하는 포인트 클라우드 좌표와 매칭하여 스케일 보정(scale calibration)을 수행한다.
이 과정을 공식화하기 위해, 를 절대적 물리 공간에서의 손 관절 깊이 집합이라 하고, 를 포인트 클라우드 추정치 로부터 얻은 상응하는 깊이라 한다. 스케일 인자 를 가시성 및 유효 깊이 추정치에 의해 결정된 유효 관절 집합 에 대하여 로 추정한다. 스케일 인자 를 포인트 클라우드 에 적용하여 보정된 표현 를 얻으며, 이는 손과 객체가 일관된 3차원 물리 좌표계 내에서 표현되도록 보장한다. 결과적으로, 연속된 프레임에서 손과 객체의 3차원 기하학적 정보를 인코딩하는 공간적으로 정렬된 주석을 획득한다.
Instructional data curation. 인간 조작 영상에서 도출된 공간 주석을 바탕으로, 2차원 시각 관측과 3차원 행동 정보 사이의 관계를 명시적으로 인코딩하는 일련의 시각-질의-응답(VQA) 스타일 레이블을 구축한다. 이 단계는 시각적 입력을 물리적 행동에 접지하여, VLA 모델이 3차원 움직임이 시각 공간에서 어떻게 나타나는지 이해하도록 하는 데 중요하다. 이를 위해 Gemini-2.5-flash를 활용하여 다음과 같은 네 가지 상호 보완적인 범주의 질의-응답 쌍을 생성한다: (1) 공간적 관계(Spatial Relationship): 여러 연속 프레임 내의 손과 객체 정보를 주어, 마지막 프레임에서의 3차원 공간 관계(예: 상대적 위치, 거리, 접촉 상태)를 설명하는 자연어 질의응답을 생성한다. (2) 작업 완료(Task Completion): 작업 설명과 상응하는 영상 프레임을 조건으로, 대상 객체와 상호작용하기 위해 손이 3차원에서 어떻게 움직여야 하는지에 대한 지침을 수립한다. (3) 손 동작(Hand Movement): 두 프레임이 주어졌을 때, 이동 방향과 거리를 포함하여 그 사이의 손의 3차원 궤적을 주석으로 단다. (4) 카메라 움직임(Camera Movement): 프레임 쌍에 대하여 회전 방향 및 각도로 표현된 카메라의 상대적인 3차원 변환을 나타낸다.
범주 1~3에서 사용되는 3차원 공간 관계나 손 및 카메라 움직임의 경우, 각 요소를 (방향, 거리) 쌍으로 표현한다. 를 두 개체 사이의 상대적인 3차원 오프셋을 특징짓는 변위 벡터라고 하자. 거리는 유클리드 노름으로 정의된다. 방향은 단위 벡터 로부터 유도되며, 무시할 수 있는 성분을 필터링하기 위한 성분별 임계값 를 사용하여 축 정렬된 언어 토큰으로 이산화된다:
카메라 움직임의 경우, 두 카메라 포즈 사이의 상대적 변환을 고려하여 이를 회전축 와 회전 각도 로 나타낸 회전 로 나타낸 회전, 그리고 방향 벡터와 크기로 표현된 평행 이동으로 분해한다.
이 과정을 통해 조밀한 3차원 기하학 정보가 물리적으로 접지된 행동과 인간의 시각 시연을 연결하는 콤팩트하고 언어적으로 접지된 레이블로 변환된다. 이러한 공식화는 모델이 공간 구성을 인식할 뿐만 아니라 손 동작, 작업 지향 조작, 나아가 카메라 움직임과 같은 역동적인 변화에 대해 추론할 수 있게 하여 2차원 시각 관측과 3차원 행동 정책 사이의 가교를 강화한다. 9개의 이질적인 인간 조작 영상 소스로부터 대규모 인간 데이터를 활용하여 주석 작성을 위해 약 4,000개의 클립을 균등하게 샘플링했으며, 본 연구의 파이프라인을 통해 약 30만 개의 지침-응답 쌍을 생성하여 이를 Hand3D-visual이라 명명한다.
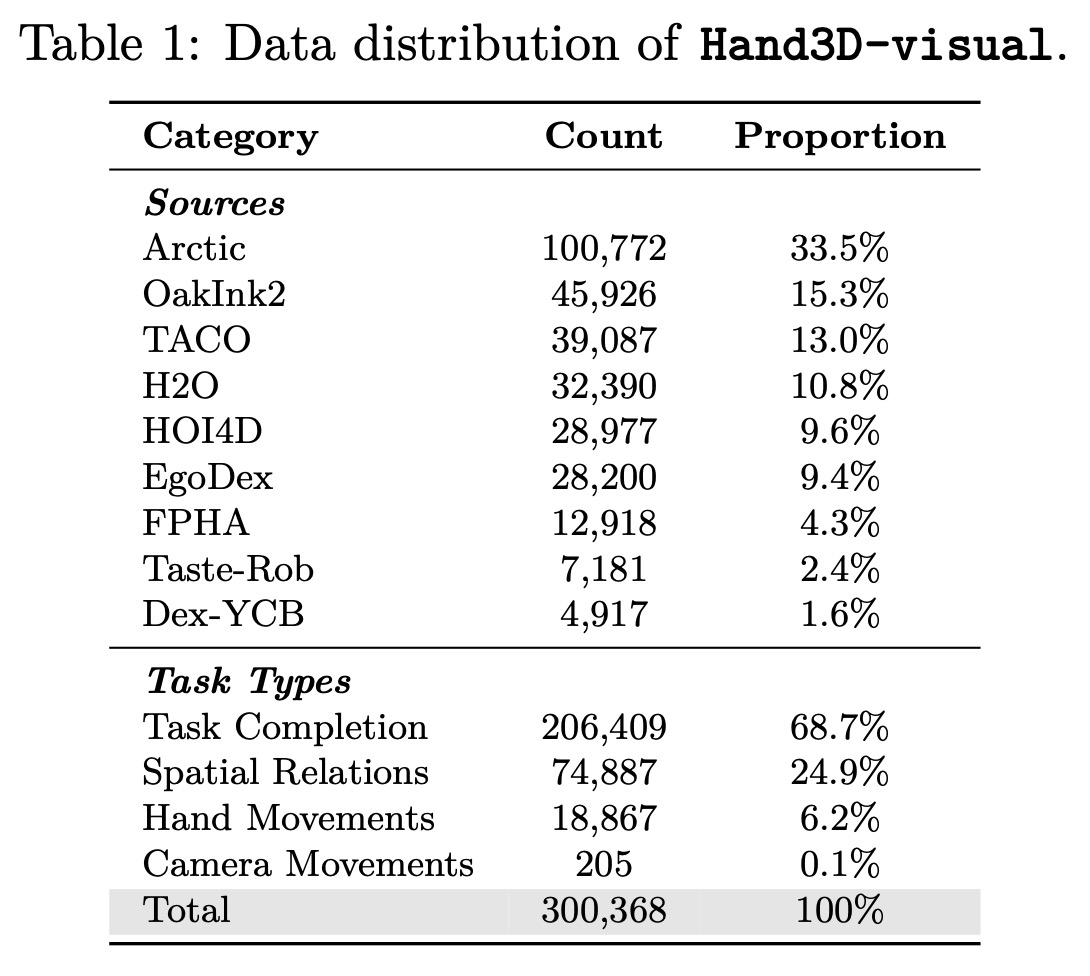

우리는 Hand3D-visual의 몇 가지 예시를 그림 3에서 보여준다. 데이터셋은 4가지 카테고리를 포함한다.
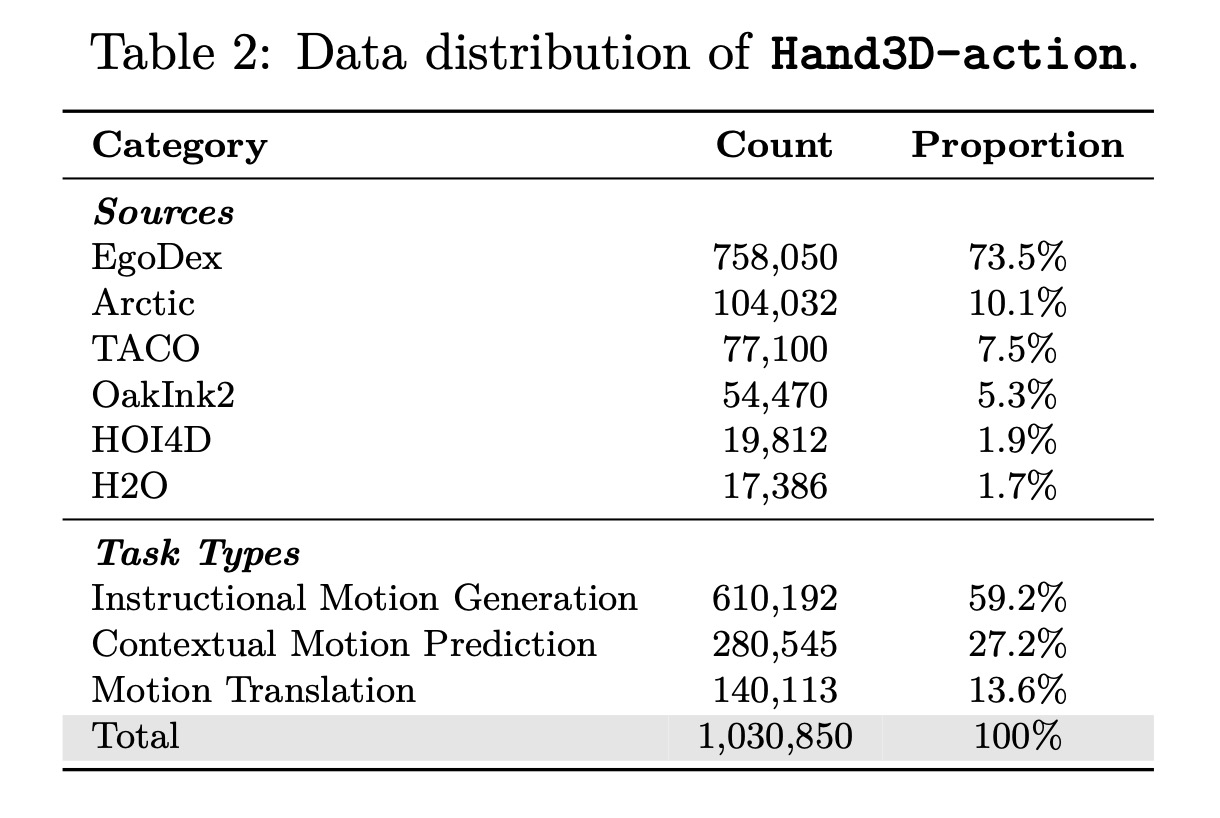
3차원 시각 주석을 보완하기 위해, 물리 공간에서 인간 조작의 역동적인 측면을 포착하는 3차원 행동 주석을 추가로 구축한다. 인간 영상의 손 동작 시퀀스로부터 손목 궤적을 3차원 좌표 시퀀스로 추출하며, 이는 균등 빈닝(uniform binning)을 통해 동작 토큰으로 이산화된다. UniHand를 따라 영상에 대한 텍스트 지침을 획득하여 400만 개의 영상-지침-동작 쌍을 얻는다. 구체적으로, 각 영상은 먼저 10초 단위의 청크로 분할되며 Gemini-2.5-flash를 적용하여 청크 수준 및 초 수준의 주석을 생성한다. 그 다음 Gemini-2.5-Pro를 사용하여 주석을 기반으로 세 가지 종류의 VQA 스타일 작업(지침 기반 동작 생성, 동작 번역, 맥락적 동작 예측)을 구축한다. 3차원 손 움직임이 미미한 샘플을 추가로 필터링하여 100만 개의 선별된 데이터셋인 Hand3D-action을 구축하며, 이는 세밀한 3차원 동작 패턴과 공간 궤적뿐만 아니라 객체 유도성(affordance) 및 작업 분해와 같은 고차원적인 물리적 추론 지식을 제공한다.
3.2.2 VIPA-VLA
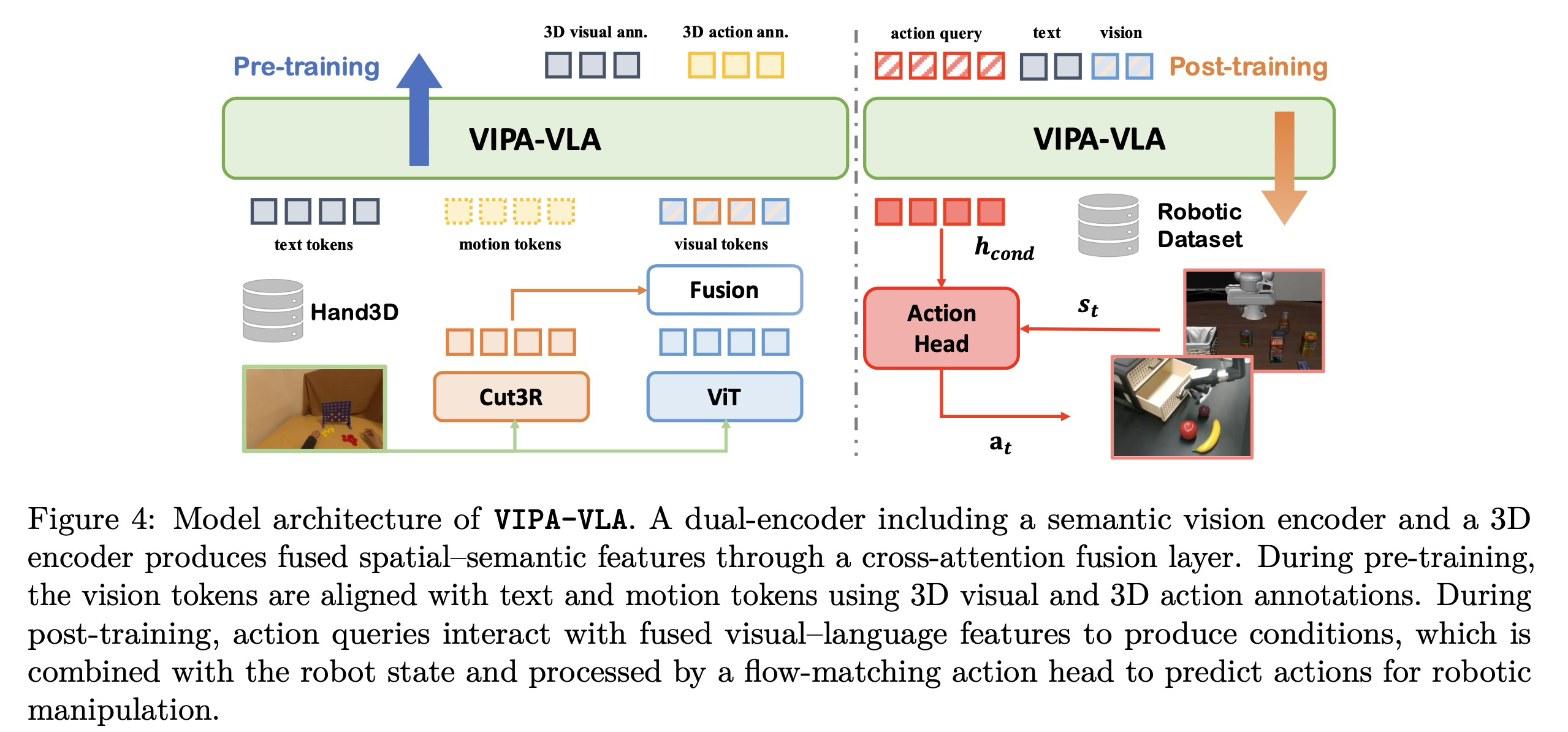
기존의 VLA 모델은 일반적으로 고수준의 시각적 의미론을 추출하기 위해 의미론적 시각 인코더를 채용한다. 그러나 이러한 인코더는 3차원 공간 구조에 대한 특징을 제공하는 능력이 부족하다. 이러한 한계를 해결하기 위해, 의미론적 표현과 공간적 시각 표현을 모두 통합하는 이중 인코더 아키텍처인 VIPA-VLA를 제안한다 (Figure 4 좌측). 구체적으로, 의미론적 시각 인코더 외에도 장면의 명시적인 기하학적 이해를 제공하는 3차원 시각 인코더 Cut3R를 통합한다. 의미론적 인코더는 시각 임베딩 을 생성하고, 3차원 인코더는 공간 임베딩 를 출력한다.
이러한 보완적인 특징을 효과적으로 결합하기 위해 교차 주의(cross-attention) 모듈로 구현된 융합 레이어를 도입한다. 융합 레이어 설계는 교차 주의 메커니즘을 따르는 VLM-3R에서 영감을 얻었으며, 여기서 의미론적 시각 특징은 3차원 인코더에 의해 추출된 3차원 공간 특징을 참조(attend)한다. 시각 특징 과 공간 특징 가 주어지면, 먼저 이들을 공유된 주의 공간으로 투영한 후 시각 토큰이 3차원 공간 토큰을 쿼리하는 교차 주의를 수행한다. 출력은 출력 투영을 사용하여 시각 특징 차원으로 다시 투영되어 가 도출된다. 사전 학습된 시각 의미론을 유지하면서 공간 정보를 통합하기 위해, 융합 레이어는 학습 가능한 스케일링 파라미터 를 사용하는 잔차 연결(residual connection)을 적용한다:
마지막으로 최적화를 안정화하기 위해 드롭아웃(dropout)과 레이어 정규화(layer normalization)를 적용한다. 모델이 인간 시연에서 추출된 세밀한 3차원 동작 궤적을 이해할 수 있도록, 두 번째 사전 학습 단계에서 3차원 물리 공간을 이산화하는 동작 토큰(motion tokens) 세트를 도입하여 LLM의 토큰 임베딩 공간을 확장한다. 구체적으로, 각 손목 궤적 지점 을 세 개의 이산 동작 토큰으로 토큰화한다. 연속적인 3차원 좌표를 이산 인덱스로 변환하기 위해 사전 정의된 유계 범위(bounded ranges)에 대해 균등 이산화(uniform discretization)를 적용한다. 각 축 에 대해 클리핑 범위를 정의하며, 본 구현에서는 축과 축기 [-0,5, 0.5] 범위를 공유하고 축은 [0, 1]을 사용한다. 이는 카메라 바로 앞의 물리적 공간을 구조화된 토큰 공간으로 효과적으로 이산화한다. 각 좌표는 개의 빈(bin) 중 하나로 이산화되며, 실험에서는 를 사용한다. 따라서 각 3차원 웨이포인트 는 동작 토큰 트리플렛으로 변환되어 최종적인 토큰화된 동작 시퀀스 ****를 생성한다.
3.2.3 Spatial-Aware VLA Pretraining
의미론적 인식과 물리적 이해를 효과적으로 정렬하기 위해, 시각-물리적 정렬의 점진적 학습을 가능하게 하는 두 단계로 구성된 공간 인식 VLA 사전 학습 전략을 설계한다 (Figure 1). 먼저 의미론적 이해를 상속받기 위해 사전 학습된 VLM을 사용하여 모델을 초기화하는 한편, 사전 학습된 3차원 시각 인코더와 무작위로 초기화된 융합 레이어를 통합한다. 1단계에서는 모든 사전 학습된 파라미터를 동결하고 3차원 시각 주석 VQA 데이터를 사용하여 융합 레이어만 학습시킨다. 목표는 융합 레이어를 통해 의미론적 임베딩 과 공간적 임베딩 를 정렬하여 3차원 공간 관계에 대한 추론을 촉진하는 것이다.
2단계에서는 일련의 동작 토큰을 포함하도록 LLM 어휘를 확장한 다음, 3차원 행동 주석에 대해 모델을 학습시킨다. 이 단계에서 의미론적 및 공간적 인코더는 동결되며, 융합된 시각 및 텍스트 입력을 조건으로 동작 토큰을 예측하도록 LLM을 학습시킨다. 이 단계는 모델이 세밀한 공간 추론과 행동 수준의 이해를 습득할 수 있게 하며, 시각적 단서가 물리적으로 접지된 동작 패턴과 어떻게 대응하는지 학습하게 한다. 공간 인식 VLA 사전 학습을 통해, VIPA-VLA는 2차원 의미론적 인식, 3차원 공간 이해 및 행동 추론을 점진적으로 정렬하여 하위 로봇 정책 학습을 위한 포괄적인 시각-물리적 정렬을 달성한다.
3.3 Post-Training
사전 학습을 거친 후, VIPA-VLA는 2차원 관측값과 3차원 물리적/행동 표현 사이의 정렬을 습득한다. 사후 학습 단계에서는 액션 헤드(action head)를 부착하고 이를 훈련하여 실행 가능한 행동 청크(action chunks)를 생성하도록 함으로써, 다운스트림 로봇 작업에 대해 초기화된 모델을 미세 조정한다. 구현을 위해 로 매개변수화된 디퓨전 트랜스포머(DiT) 모델을 사용한다.
와 을 각각 시각적 프레임과 언어 명령이라 하고, 를 고정된 액션 질의(action queries) 집합이라고 정의한다. 사전 학습된 VLM 백본으로부터 조건부 맥락(conditional context)을 와 같이 추출하며, 여기서 에 해당하는 은닉 상태(hidden states)가 DiT의 조건 정보로 사용된다. 타임스텝 에 대한 정답(ground-truth) 행동 청크는 , 로봇 상태 임베딩은 로 표기한다. 플로우 매칭(flow matching) 기법을 따라, 무작위 노이즈 벡터 과 정답 행동 사이를 선형 보간하여 노이즈가 섞인 행동 궤적을 생성한다:
DiT는 와 상태 임베딩 의 결합인 를 입력 표현으로 받는다. 를 조건으로 하여, DiT는 순간 플로우 벡터(instantaneous flow vector) 를 예측한다. 훈련 목표는 이 예측값과 으로 주어지는 오라클 전송 방향(oracle transport direction) 사이의 편차를 최소화하는 것이다:
훈련 과정에서는 모델을 행동 실행에 적응시키기 위해 LLM 백본과 액션 헤드 만 업데이트한다. 이에 대한 구조적 설명은 Figure 4(우측)에 나타나 있다.
4. Experiment
4.1 Implementation Details
VIPA-VLA는 InternVL3.5-2B로부터 초기화한다. 첫 번째 사전 학습 단계에서 공간적 관계 및 작업 완료 작업의 경우, 모델에 1~4개의 무작위로 샘플링된 연속 프레임을 입력으로 제공하며, 손 동작 및 카메라 움직임 작업의 경우 두 개의 프레임을 제공한다. 모든 비디오 프레임은 1 fps로 샘플링한다. 두 번째 사전 학습 단계와 사후 학습 단계에서는 단일 프레임을 시각적 입력으로 사용한다. 훈련은 세 단계로 구성되며, 세부 사항은 다음과 같다.
Stage 1. 첫 번째 단계에서는 Hand3D-visual을 사용하여 VIPA-VLA를 1 에폭(epoch) 동안 사전 학습하며, 8개의 NVIDIA A800 GPU에서 약 6시간이 소요된다. 이 단계에서는 융합 레이어(fusion layer)만 최적화하며, 1e-5의 학습률로 AdamW 옵티마이저를 사용한다. 웜업(warm up) 비율은 0.03, 가중치 감쇠(weight decay)는 0.01로 설정하고 코사인 스케줄러를 적용한다. 전체 배치 크기는 32이다. 융합 레이어의 공간 스케일링 파라미터 α는 0.5로 초기화하며, 이미지 프레임은 448 × 448 크기로 조정한다.
Stage 2. 두 번째 단계에서는 Hand3D-action을 사용하여 VIPA-VLA의 융합 레이어와 LLM 백본을 최적화하며, 8개의 NVIDIA A800 GPU에서 약 20시간이 소요된다. 훈련 하이퍼파라미터는 1단계와 동일하게 유지한다.
Stage 3. 사후 학습 단계에서는 시각 인코더와 3차원 인코더를 동결한다. 전체 배치 크기는 LIBERO 및 실제 로봇 작업의 경우 128, RoboCasa의 경우 256으로 설정하며, 학습률은 5e-5를 사용한다. 웜업 비율은 0.05, 가중치 감쇠는 1e-5이다. LIBERO 벤치마크와 실제 로봇 작업에 대해서는 모델을 30K 스텝 동안 훈련하며 약 5시간이 소요된다. RoboCasa 벤치마크의 경우 60K 스텝 동안 훈련하며 약 40시간이 소요된다. 모든 훈련은 8개의 NVIDIA A800 GPU를 사용하여 수행한다.
4.2 Simulation Robot Tasks
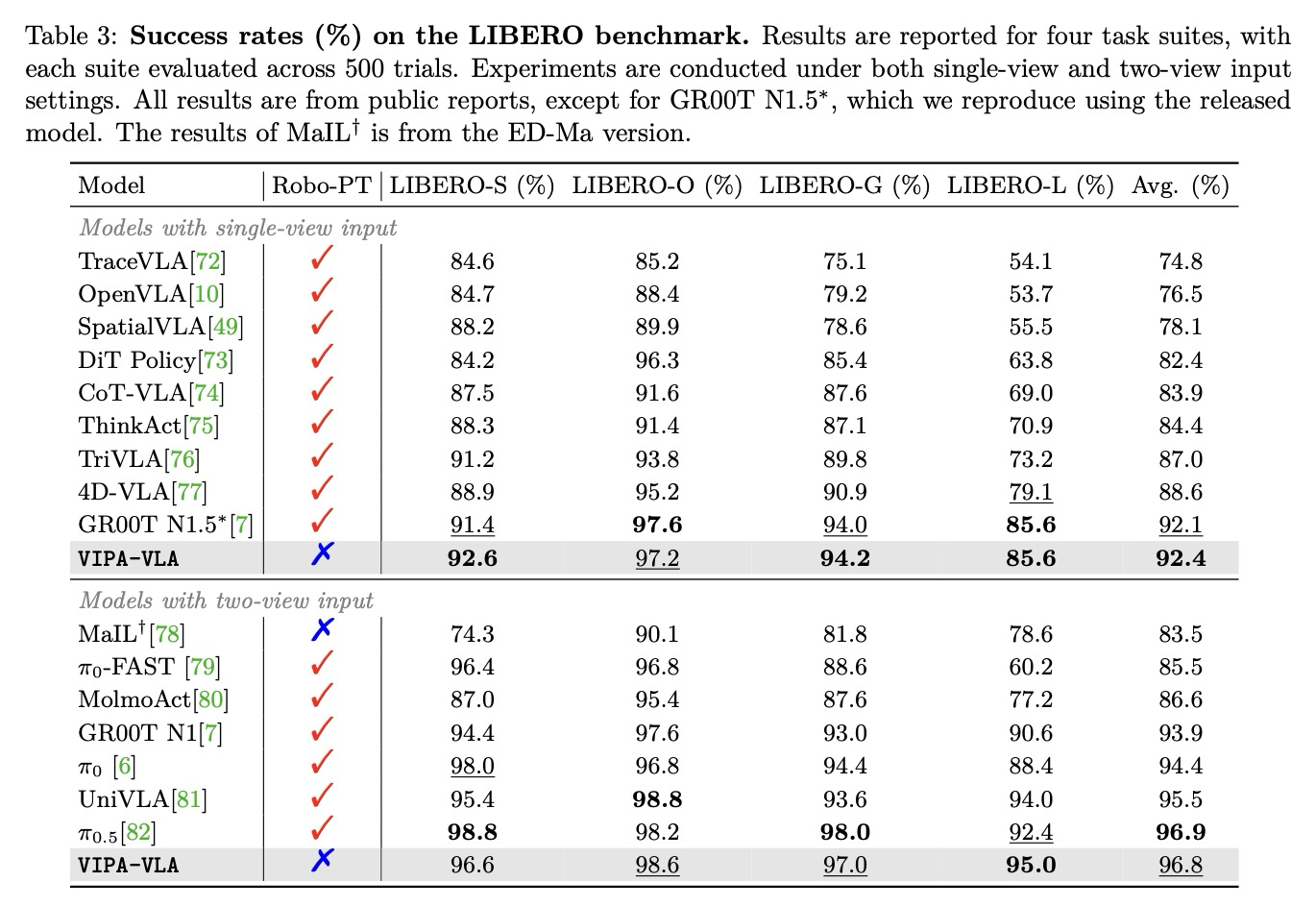
Benchmarks. 인간 시연으로부터 얻은 공간적으로 접지된 추론이 로봇 시나리오로 얼마나 잘 일반화되는지 평가하기 위해 시뮬레이션 환경에서 VIPA-VLA의 성능을 측정한다. 구체적으로, 로봇 조작 능력 평가를 위한 표준 벤치마크인 LIBERO와, 이보다 훨씬 더 도전적인 과제인 RoboCasa를 채택한다. RoboCasa는 더 다양한 배치, 복잡한 장면 및 시각적 관측을 특징으로 하여 VLA 모델에 더욱 정확하고 견고한 3차원 공간 이해를 요구한다. LIBERO는 각기 다른 작업 설정과 장면 배치를 포함하는 네 가지 작업 세트(Spatial, Object, Goal, Long)로 구성된다.
Results on LIBERO. 각 작업 세트에 대한 500회 시행의 평균 성공률을 Table 3에 보고한다. VIPA-VLA는 단일 뷰 및 듀얼 뷰 입력 설정 모두에서 모든 LIBERO 작업 세트에 걸쳐 강력한 성능을 달성한다. 이는 인간 영상에서 학습된 공간 인식 VLA 사전 학습이 시뮬레이션된 로봇 환경으로 효과적으로 일반화됨을 입증한다. 주목할 점은 본 모델이 사전 학습 과정에서 로봇 데이터를 전혀 사용하지 않았음에도 불구하고, 대규모 로봇 데이터셋으로 사전 학습된 강력한 베이스라인인 *π*-시리즈 및 GR00T 모델과 대등한 결과를 얻었다는 것이다. 이는 인간 시연에서 습득한 공간 추론 능력이 시뮬레이션 환경의 로봇 조작에도 큰 도움이 될 수 있음을 시사한다. 또한 SpatialVLA, TraceVLA, MolmoAct 등 공간 추론을 명시적으로 모델링하는 다른 베이스라인들과 비교했을 때도 본 모델이 일관되게 더 나은 성능을 보이며, 다양한 인간 시연으로부터 시각-물리적 정렬을 학습하는 것의 효과를 입증한다.
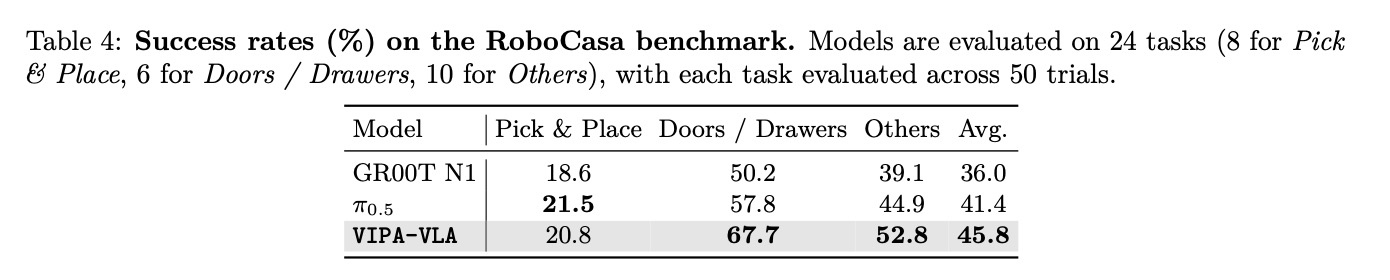
Results on RoboCasa. RoboCasa 실험에서는 3중 뷰 입력 구성을 채택하고 작업당 단 50개의 인간 시연만을 사용하여 VIPA-VLA를 훈련한다. Table 4에서 볼 수 있듯이, 다양한 RoboCasa 작업에 걸쳐 VIPA-VLA는 가장 우수한 전체 성능을 기록하며 멀티 뷰 관측 및 제한된 시연 데이터 하에서도 강력한 일반화 능력을 보여준다. 특히 정밀한 공간 로컬라이제이션이 필요한 Doors/Drawers 범주에서 상당한 개선(+9.9%)을 달성한다. 이러한 결과는 공간 인식 사전 학습이 모델에 더 신뢰할 수 있는 2차원-3차원 접지 능력을 부여하여, 기하학적으로 도전적인 환경에서도 정확한 공간 추론을 가능하게 함을 강조한다.
4.3 Real Robot Tasks
더 나아가 현실적인 3차원 물리적 설정과 정확한 공간 인식 및 행동 접지가 요구되는 실제 로봇 조작 작업에서 모델을 평가한다. 이는 인간 영상을 활용한 공간 인식 VLA 사전 학습의 이점을 평가하는 데 이상적이다. 실험은 7자유도 Franka Research 3 암, 6자유도 Inspire hand, 그리고 시각 관측을 위한 두 대의 RealSense L515 카메라를 사용하여 수행한다.
공간 인식 및 추론의 다양한 측면을 테스트하기 위해 세 가지 조작 작업을 설계한다: (1) Put-Three-Obj – 세 개의 과일을 서랍에 순차적으로 넣으며, 여러 객체를 로컬라이제이션하고 조작하는 능력을 평가한다. (2) Wipe-Board – 천을 사용하여 화이트보드의 모든 펜 자국을 지우며, 불규칙한 모양의 대상 영역에 대한 유연한 공간 추론을 요구한다. (3) Water-Plant – 물뿌리개를 집어 식물에 물을 주며, 정밀한 공간 로컬라이제이션과 세밀한 3차원 동작 제어를 요구한다. 각 작업은 세부적인 실행 성능을 측정하기 위해 여러 하위 작업(sub-tasks)으로 분해된다. 또한 일반화 능력을 평가하기 위해 각 작업에 대해 학습 시 보지 못한 환경(unseen environment) 설정을 설계한다.
- Put-Three-Obj: 로봇이 서랍을 열고, 테이블 위의 세 가지 과일(사과, 바나나, 자두)을 순차적으로 집어 서랍에 넣은 후 서랍을 닫아야 한다. 하위 작업은 서랍 열기, 사과 집어서 놓기, 바나나 집어서 놓기, 자두 집어서 놓기, 서랍 닫기의 다섯 가지로 정의된다. 보지 못한 환경을 위해 테이블 표면을 본 적 없는 색상의 식탁보로 덮어 수정한다.
- Wipe-Board: 로봇이 천을 집어 화이트보드의 펜 자국을 닦아내야 한다. 하위 작업은 천 집기, 펜 자국 닦기, 전체 화이트보드 청소의 세 가지다. 보지 못한 환경을 위해 펜 자국을 그리는 마커의 색상을 변경한다.
- Water-Plant: 로봇이 물뿌리개를 집고 식물의 위치를 파악하여 분사 핸들을 눌러 물을 주어야 한다. 하위 작업은 물뿌리개 집기, 식물 위치 파악, 분사 핸들 누르기의 세 가지로 정의된다.
작업에 대한 설명은 Figure 5에 나타나 있다. 각 작업에 대해 사후 학습을 위한 50개의 원격 조작(teleoperated) 궤적을 수집하고, 작업 성공률 측정을 위해 10회의 평가 시도를 수행한다. 평가 중에는 매 시도마다 테이블 위의 객체 배치와 화이트보드의 펜 자국 분포를 무작위화한다. 이 설정은 학습된 정책이 고정된 구성을 암기하는 대신 일반화 능력을 갖추었는지 테스트한다. 전체 작업 성공률 외에도 모든 시도에서 완료된 하위 작업의 비율로 계산된 평균 하위 작업 성공률을 보고한다.
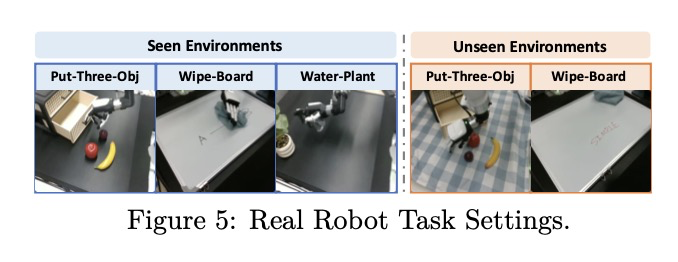
Table 5에서 보듯, VIPA-VLA는 모든 실제 조작 작업에서 최고의 종합 성능을 달성하며, 사전 학습 중에 습득한 공간 이해가 실제 로봇 조작을 효과적으로 도와 실제 환경에서 더 견고하고 일반화된 행동을 이끌어냄을 보여준다. 절제 실험(ablation) 베이스라인인 InternVL3.5와 비교했을 때, 본 모델은 모든 작업에서 상당한 개선을 이루어 제안된 공간 인식 사전 학습과 이중 인코더 아키텍처가 공간 접지 및 일반화 향상에 효과적임을 확인시켜 준다. VIPA-VLA가 Put-Three-Obj에서 전체 작업 성공률은 더 낮을지라도 하위 작업 성공률은 더 높게 나타나는데, 이는 베이스라인 모델들이 시퀀스 초기에 실패하여 첫 단계조차 완료하지 못하는 경우가 많아 공간 추론 및 제어가 덜 안정적임을 나타내기 때문이다. 대조적으로 VIPA-VLA는 작업 단계 전반에 걸쳐 더 일관된 진행을 보이며 실제 실행에서의 더 강한 견고함을 반영한다.

보지 못한 환경에서의 평가 결과인 Table 6을 보면, VIPA-VLA는 시각적으로 새로운 환경에서도 강력한 성능을 유지하며 모든 베이스라인을 크게 능가한다. 다른 모델들은 성능이 급격히 저하되는 반면, 본 모델은 높은 하위 작업 및 전체 성공률을 유지하여 향상된 견고함과 일반화 능력을 입증한다. 이는 2차원 시각 관측을 3차원 물리적 표현으로 접지함으로써 새로운 장면에 더 안정적으로 일반화할 수 있기 때문이다. Figure 6의 정성적 사례들은 모델이 객체를 정확히 로컬라이제이션하고 다양한 배치에 적응하며 일관된 궤적으로 다단계 조작을 완료함을 보여준다. Figure 7의 실패 사례 분석 결과, VIPA-VLA의 실패는 주로 작은 물체를 잡을 때의 미세한 정렬 오류와 같은 세밀한 조작 단계에서 발생하며 전체적인 공간 로컬라이제이션 및 행동 계획은 여전히 올바르다. 반면 베이스라인 모델은 부정확한 공간 접지로 인해 잘못된 영역에 손을 뻗거나 객체 위치를 오판하는 등 근본적인 공간 이해 부족으로 인해 조작 시작 전에 멈춰버리는 경우가 빈번하다.

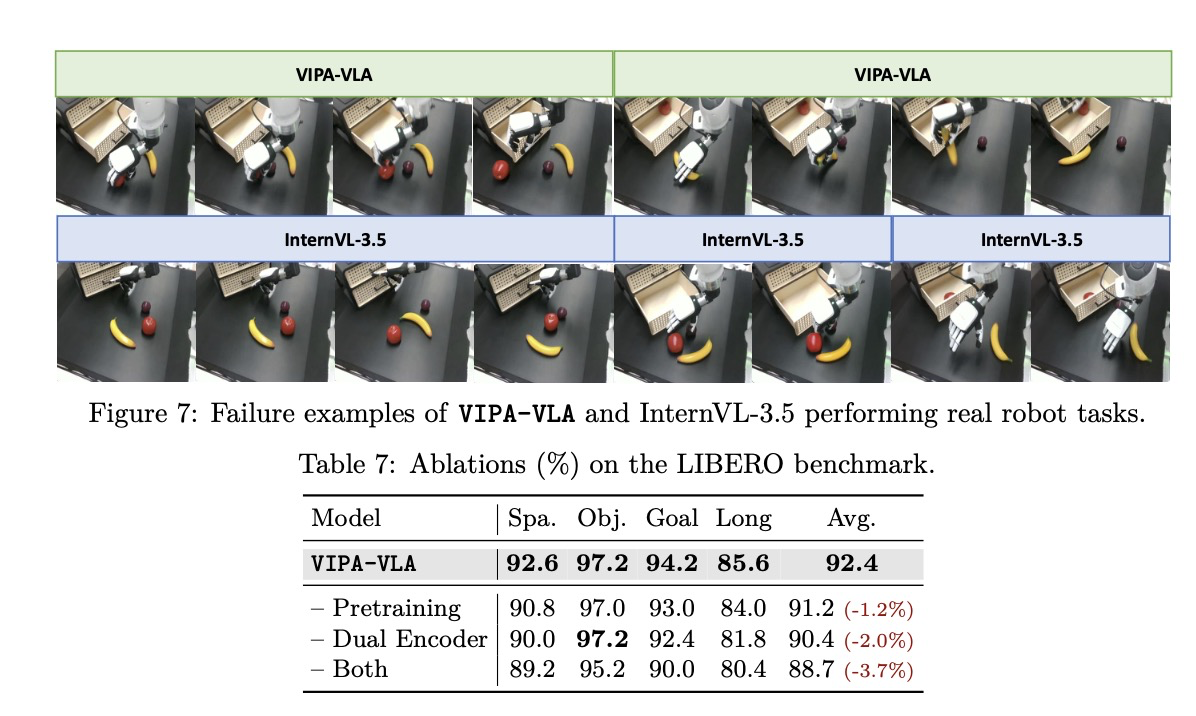
4.4 Ablation Studies
Architecture and the Spatial-Aware VLA Pretraining. 모델 아키텍처와 제안된 공간 인식 VLA 사전 학습의 효과를 평가하기 위해 LIBERO 벤치마크에서 절제 실험을 수행한다. 이 분석은 이중 인코더 설계와 시각-물리적 정렬을 통한 사전 학습 전략의 개별 기여도를 분리하여 평가한다.
Table 7에서 보듯이, 인간 영상에 대한 공간 인식 사전 학습과 제안된 이중 인코더 아키텍처는 모두 전체 성능 향상에 기여한다. 두 구성 요소 중 하나라도 제거하면 모든 작업 세트에서 일관된 성능 저하가 발생한다. 사전 학습은 모델에 인간 시연으로부터 학습된 풍부한 3차원 동작 및 인식 사전 지식(priors)을 제공하며, 이중 인코더는 3차원 시각 표현의 더욱 효과적인 융합을 가능하게 한다. 이 두 가지 설계가 결합되었을 때 모델의 공간 추론과 일반화 능력이 더욱 강화되어 가장 강력한 성능을 나타낸다.
Effect of Spatial-Aware VLA Pretraining. 먼저 3차원 시각 주석에 대한 1단계 사전 학습이 공간 이해 능력을 향상시키는 데 미치는 효과를 평가한다. 구체적으로 모델이 시각적 장면에서 공간적 관계와 3차원 기하학을 얼마나 잘 추론할 수 있는지 평가한다. 이를 위해 훈련 말뭉치에 포함되지 않은 보지 못한 영상의 2,000개 VQA 쌍으로 구성된 Hand3D-test에 대한 결과를 보고한다. 평가는 거리 정확도와 방향 정확도라는 두 가지 측면에 초점을 맞춘다. 방향 정확도는 세 개의 주축을 따른 예측의 정확성을 평가하여 측정하며, 거리 정확도는 미터 단위의 평균 예측 오차로 수치화한다.
VIPA-VLA-PT를 두 가지 절제 모델과 비교한다: (1) InternVL3.5: 추가 사전 학습이 없는 백본 VLM, (2) InternVL3.5 + Hand3D: 제안된 이중 인코더 아키텍처 없이 Hand3D로 사전 학습된 백본 모델이다. 이 설정을 통해 Hand3D 사전 학습 자체의 기여도와 VIPA-VLA 아키텍처의 기여도를 구분할 수 있다.
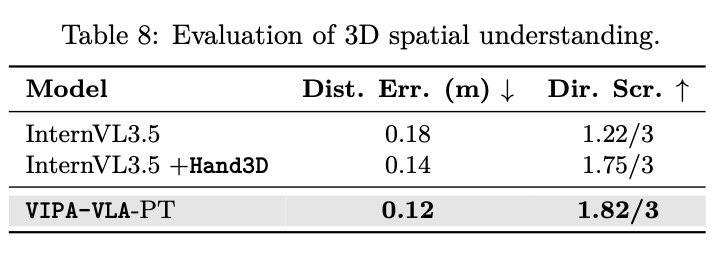
Table 8의 결과에 따르면, 백본 InternVL3.5는 공간 추론 작업에서 저조한 성능을 보이며 공간 관계에 대한 이해가 제한적임을 나타낸다. Hand3D에 대한 사전 학습은 성능을 눈에 띄게 향상시키며, 이는 3차원 시각 주석이 시각-물리적 정렬을 통해 모델의 공간 접지 능력을 효과적으로 강화함을 확인시켜 준다. 제안된 VIPA-VLA는 추가적인 성능 이득을 달성하며, 이는 3차원 시각 인코더와 융합 메커니즘을 도입하는 것이 데이터 수준의 감독 이상의 추가적인 이점을 제공함을 입증한다. 특히 이 단계에서는 융합 레이어만 훈련되는데, 이는 의미론적 및 공간적 시각 특징을 정렬하는 것만으로도 상당한 이득을 얻을 수 있음을 보여준다.
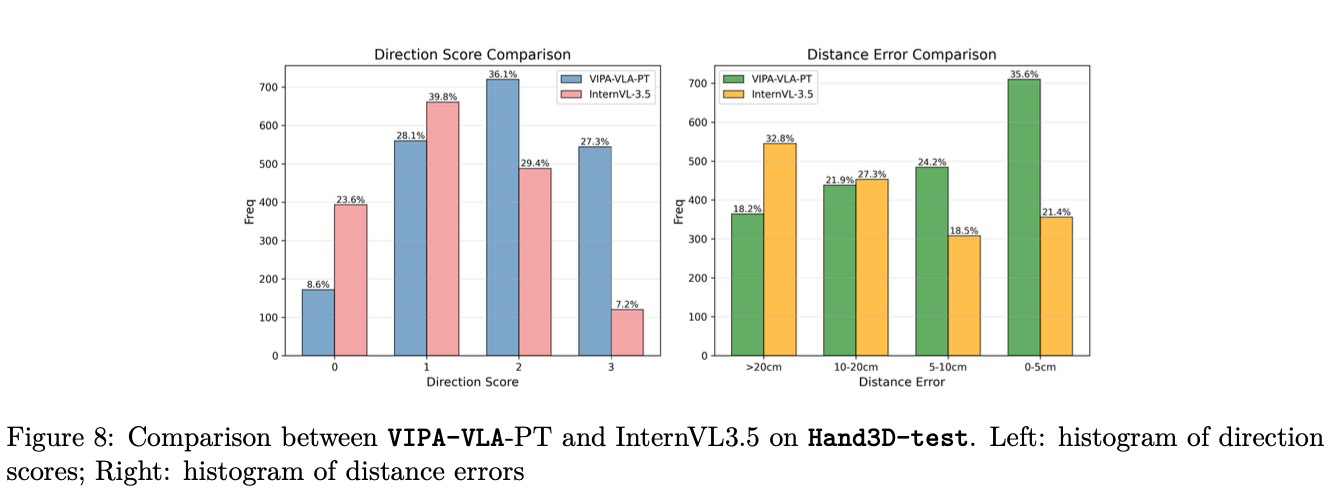
Figure 8에서는 VIPA-VLA-PT와 InternVL3.5 간의 상세한 비교를 제시한다. 3차원 시각 주석에 대한 공간 인식 사전 학습 후, 본 모델은 심각한 오류를 실질적으로 줄이고 사례의 약 30%에서 매우 정확한 예측을 달성하며, 이는 이 단계에서 획득한 정밀하고 신뢰할 수 있는 3차원 공간 접지 능력을 반영한다.

이어서 3차원 행동 주석에 대한 2단계 사전 학습의 정성적 결과를 Figure 9에 나타낸다. 예측된 궤적은 지침(instructions)과 밀접하게 일치하며, 이는 모델이 시각적 관측과 물리적 공간 사이의 매핑을 효과적으로 이해하고 있음을 보여준다. 인간의 자연스러운 가변성으로 인해 종종 노이즈가 있고 중복된 동작을 보이는 정답(ground-truth) 궤적과 비교할 때, 본 모델은 더 매끄럽고 목표 지향적인 궤적을 생성한다. 또한 예측 결과에는 학습된 어포던스(affordance) 지식이 반영되어 있다. 예를 들어, 나무 숟가락을 조작할 때 모델은 손잡이 끝부분 근처를 잡는다.
5. Conclusion
본 연구에서는 대규모 인간 영상을 활용한 공간 인식 VLA 사전 학습(Spatial-Aware VLA Pretraining)을 통해 시각-언어-행동(VLA) 모델의 결정적인 2D-3D 간극 문제를 해결한다. 인간의 조작 활동에서 도출된 3D 시각 및 행동 주석을 제공하는 데이터셋인 Hand3D를 소개하며, 시각-물리적 정렬을 위해 설계된 이중 인코더 아키텍처인 VIPA-VLA를 제안한다.
제안된 패러다임은 2D 인식과 3D 물리적 이해를 효과적으로 정렬하여 공간 추론 및 하위 로봇 조작 분야에서 강력한 성능 향상을 이끌어낸다. 본 연구의 결과는 인간 시연을 통한 공간 인식 사전 학습의 유효성을 입증한다. 향후 이 사전 학습 패러다임은 로봇 데이터 사전 학습과 결합되어 더욱 포괄적이고 효과적인 전체 사전 학습 전략을 달성할 수 있을 것이다.
