Defeating the Training-Inference Mismatch via FP16 Penghui Qi†1,2, Zichen Liu1,2, Xiangxin Zhou*1 , Tianyu Pang1 , Chao Du1 , Wee Sun Lee2 , Min Lin1 1Sea AI Lab 2National University of Singapore https://github.com/sail-sg/Precision-RL [Submitted on 30 Oct 2025]
1 Introduction
RL 파인튜닝은 LLM의 추론 성능을 크게 향상시키지만, 학습 붕괴와 극심한 불안정성 문제가 반복적으로 발생. 현대 RL 프레임워크는 효율성을 위해 학습과 추론에 서로 다른 계산 엔진을 사용하고, 이로 인해 수학적으로 동일해야 할 정책 π와 µ 사이에 수치적 차이 발생. -> training–inference mismatch는 편향된 그래디언트와 배포 격차라는 두 가지 핵심 문제 만듦.
기존 해결책들은 중요도 샘플링 기반 알고리즘 보정에 의존하지만 계산 비용이 크고, 수렴이 느리며, 배포 격차를 근본적으로 해결하지 못함.
제안: 근원이 BF16 정밀도 자체에 있음, FP16 전환하자.
2 Background
RL 파인튜닝에서는 추론 정책 µ로 샘플링하고 학습 정책 π로 그래디언트를 계산하기 때문에 정책 불일치가 발생. -> 이 불일치는 REINFORCE 기반 정책 그래디언트를 편향되게 만듦.
학습은 π 기준으로 이루어지지만 실제 배포와 평가는 µ를 사용하므로, 파라미터 최적점 자체가 달라지는 deployment gap 발생.
2.1 Correcting Biased Gradient via Importance Sampling
중요도 샘플링은 정책 불일치로 인한 편향을 이론적으로 제거할 수 있는 정석적인 방법이지만 시퀀스 길이가 긴 LLM 환경에서는 확률 비율의 분산이 매우 커짐.
-> TIS와 MIS 같은 클리핑 기반 기법들이 제안되었으나, 이는 편향–분산 트레이드오프를 초래함.
2.1.1 Existing Implementations
실제 프레임워크들은 순수한 중요도 샘플링 정책 그래디언트 대신 GRPO 기반 패치 사용. -> 추가 forward pass를 요구하여 약 25%의 계산 오버헤드 발생. 그래디언트 편향은 줄일 수 있어도 배포 격차는 해결하지 못함.
2.2 Engineering Attempts to Reduce the Mismatch
FP32 헤드 사용, 학습, 추론 구현 수동 정렬, 추론 결정성 강제 등의 엔지니어링 시도가 있었으나 일반화가 어렵고 비용이 큼.
병렬화 방식, autoregressive 생성, MoE의 top-k 선택 등 구조적 차이로 인해 불일치는 여전히 남음.
3 Revisiting FP16 Precision
복잡한 알고리즘 수정 대신 수치 정밀도 자체를 재검토. BF16 대신 FP16을 사용하면 정책 불일치가 크게 줄어들고 RL 전반의 성능과 안정성이 향상됨.
3.1 FP16 vs. BF16
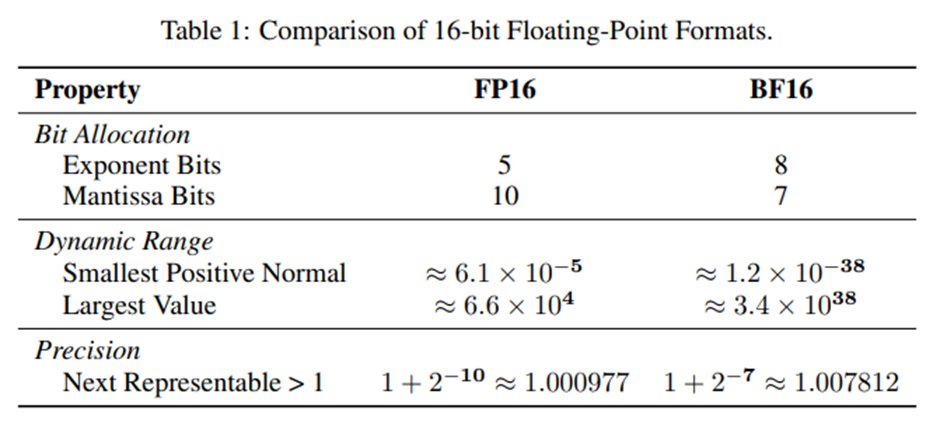
FP16은 가수 비트가 많아 정밀도가 높지만 동적 범위가 좁음. BF16은 FP32 수준의 범위를 가지지만 정밀도가 낮음.
BF16은 사전학습에는 적합하지만 RL 파인튜닝에는 오히려 문제 유발.
3.2 Stabilizing FP16 Training with Loss Scaling
FP16의 언더플로우 문제는 손실 스케일링으로 해결 가능.
동적 손실 스케일링은 이미 주요 프레임워크에 표준으로 구현되어 있음.
3.3 The Rise of BF16 in Modern LLM Training
BF16은 손실 스케일링 없이 안정적인 학습이 가능해 혼합 정밀도 표준이 됨. -> 주로 사전학습 관점에서의 장점.
3.4 Why FP16 is the Key for RL Fine-Tuning
BF16에서는 학습과 추론 엔진 간 미세한 구현 차이가 반올림 오차로 증폭됨.
FP16은 mantissa 비트가 많아 이러한 오차 누적을 흡수함.
RL 파인튜닝 단계에서는 동적 범위보다 정밀도가 더 중요.
3.5 Offline Analysis Results
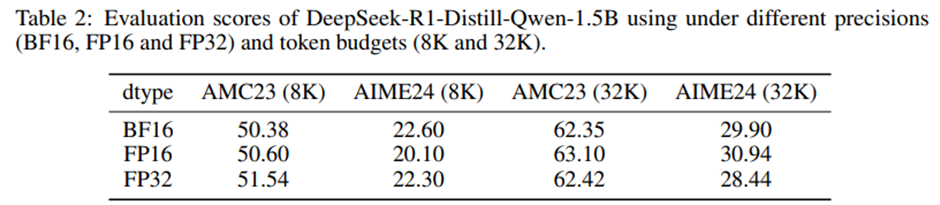
BF16과 FP16은 단순 추론 성능 자체에서는 큰 차이가 없음.
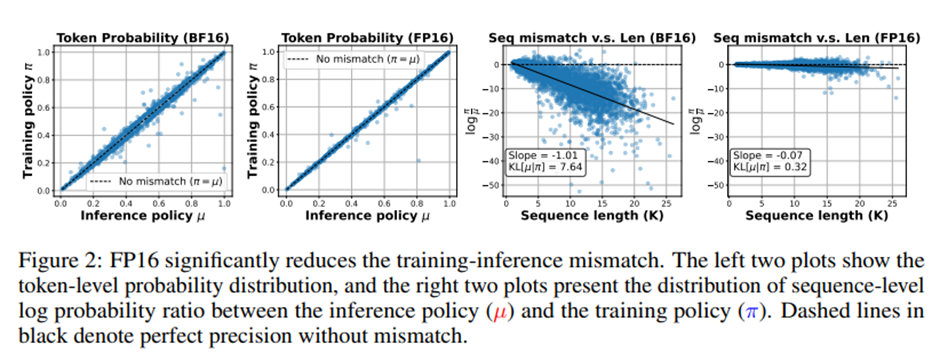
오른쪽 두 플롯은 서로 다른 생성 길이에 걸쳐 시퀀스 수준 로그 확률 비율의 분포. 문제는 추론 정확도가 아니라 학습-추론 일관성임.
4 A Sanity Test for RL Algorithms
알고리즘의 신뢰성을 검증하기 위해 “완전 개선 가능(perfectible)” 데이터셋 설계. 이 데이터셋에서는 이상적인 RL 알고리즘이라면 거의 100% 학습 정확도를 달성해야 함.
4.1 Experimental Setup
여러 RL 알고리즘을 동일 조건에서 비교하며, mismatch 보정 알고리즘들을 집중 평가.
4.2 Comparison with Existing Algorithmic Corrections
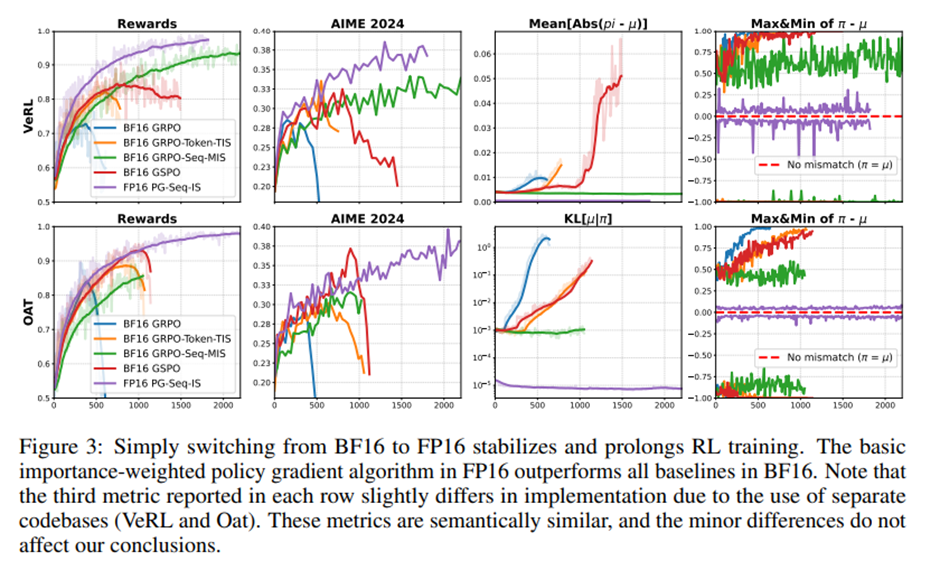
BF16에서는 대부분의 알고리즘이 결국 학습 붕괴를 겪음. 시퀀스 수준 MIS만 안정성을 유지하지만 수렴이 느리고 성능 상한 낮음. FP16에서는 단순한 정책 그래디언트가 모든 BF16 기반 방법 능가.
4.3 Reviewing RL Algorithms under FP16
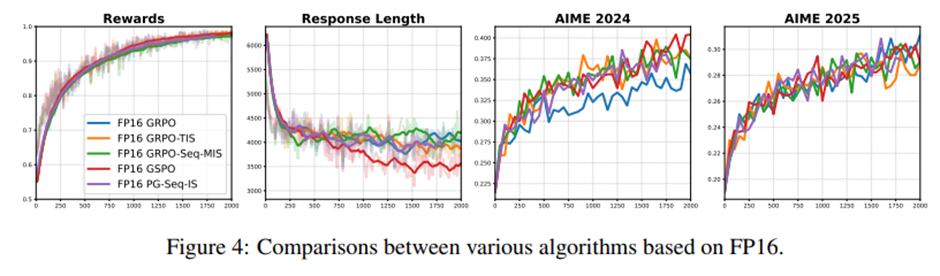
FP16 환경에서는 알고리즘 간 성능 차이가 거의 사라짐. -> 학습이 사실상 on-policy에 가까워졌기 때문.
4.4 Ablation on the Precision
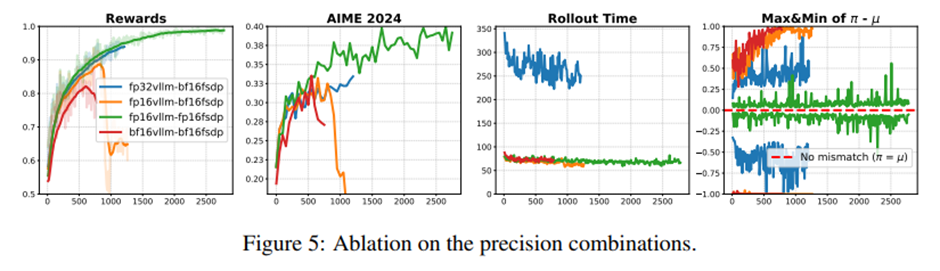
학습과 추론 모두 FP16을 사용할 때 가장 안정적이고 효율적. FP32 추론은 안정적이지만 속도가 너무 느려 실용적이지 않음.
5 Generalization Across Models, Data, and Training Regimes
FP16 효과는 sanity test를 넘어 다양한 설정에서 일관되게 나타남.
5.1 MoE RL
MoE 환경에서도 FP16은 안정성과 성능을 동시에 향상시킴. 구체적인 실험 설정은 부록 A.1.
5.2 LoRA RL
BF16 LoRA 학습은 붕괴하지만 FP16은 안정적으로 유지됨.
5.3 RL on Large Dense Models
대규모 모델에서도 FP16은 더 빠른 보상 증가와 더 높은 성능을 보임.
5.4 RL on Other Model Families
Qwen 외 모델에서도 동일한 현상이 재현됨.
6 논의
RL 파인튜닝에서는 BF16 중심의 정밀도 선택을 재고해야 함.
FP16은 편향과 분산을 동시에 줄여 알고리즘 설계 부담을 크게 낮춤.
7 결론
RL 파인튜닝의 핵심 불안정성은 알고리즘 문제가 아니라 정밀도 문제임.
FP16 전환이라는 단순한 선택만으로 더 안정적이고 효율적인 RL 학습 가능.
