논문
1.Predicting Results of Social Science Experiments Using Large Language Models 요약
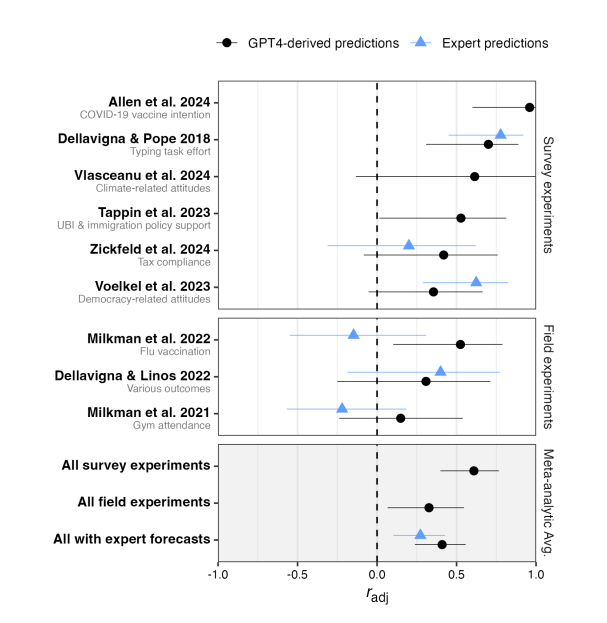
Abstract To evaluate whether large language models (LLMs) can be leveraged to predict the results of social science experiments, we built an archive o
2.LLM-Powered AI Agent Systems and Their Applications in Industry 요약

Abstract—The emergence of Large Language Models (LLMs) has reshaped agent systems. Unlike traditional rule-based agents with limited task scope, LLM-p
3.Evaluating large language models as agents in the clinic 요약
최근 LLM의 발전은 정보 통합부터 임상 의사결정 지원까지 의료분야에서 새로운 가능성을 열었다. 이러한 LLM은 단순히 언어를 모델링하는 것에 그치지 않고, 다양한 이해관계자와의 대화에서 상호작용하며 실제 임상 의사결정에 영향을 미칠 수 있느 ㄴ지능형 agent로 기능
4.Training-free image style alignment for self-adapting domain shift on handheld ultrasound devices 요약
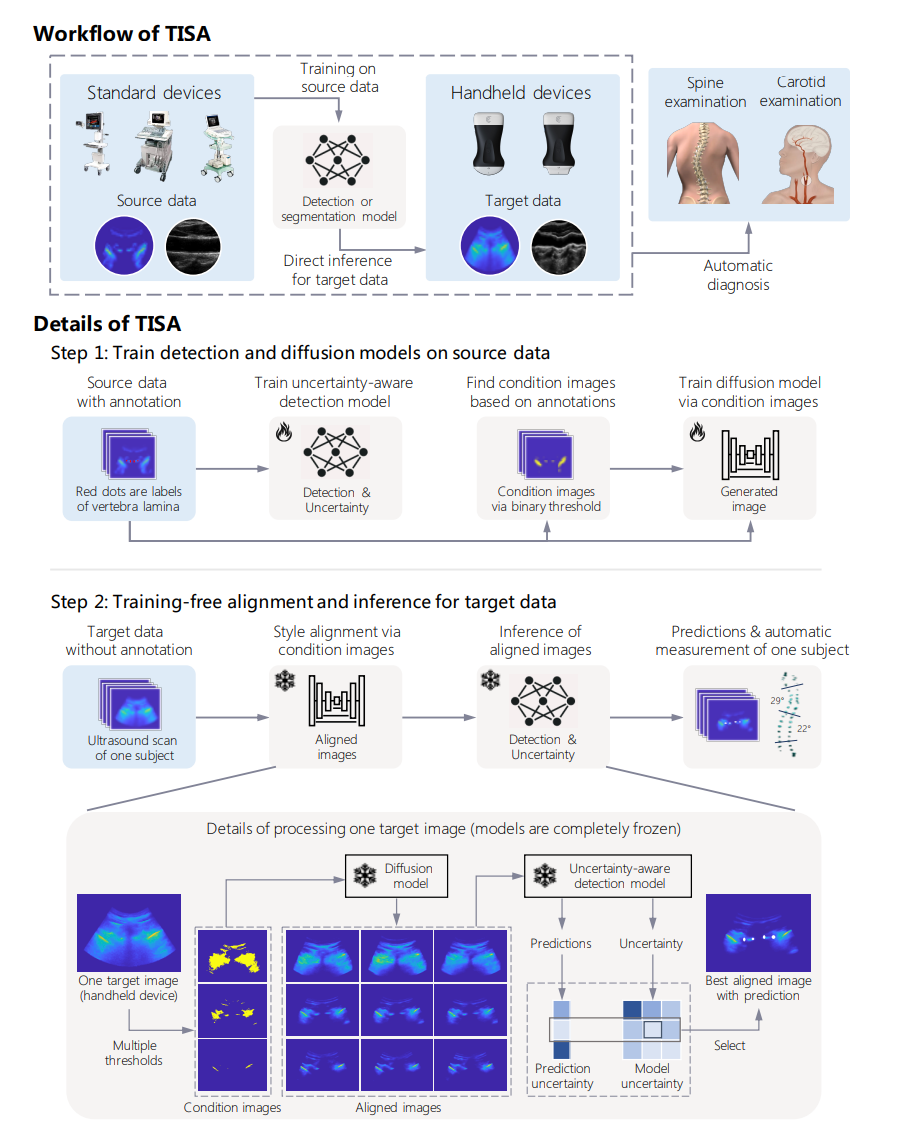
ABSTRACTHandheld ultrasound devices face usage limitations due to user inexperience and cannot benefit from supervised deep learning without extensive
5.Synthetic Data Generation Using Large Language Models: Advances in Text and Code 요약
2025년 3월 18일, arXiv 공개 > ABSTRACT Large language models (LLMs) have unlocked new possibilities for generating synthetic training data in both natural
6.Understanding and Mitigating the Bias Inheritance in LLM-based Data Augmentation on Downstream Tasks 요약
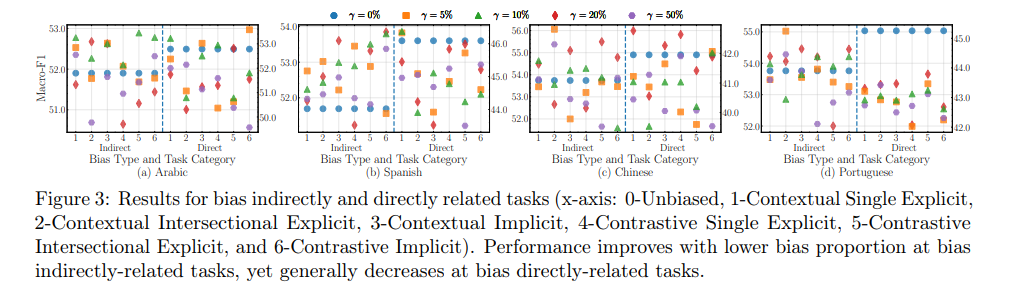
2025년 2월 6일, arXiv 공개 > Abstract Generating synthetic datasets via large language models (LLMs) themselves has emerged as a promising approach to imp
7.From Persona to Personalization: A Survey on Role-Playing Language Agents 요약

2024년 4월 28일, arXiv 공개초록최근 대규모 언어 모델(LLM)의 발전은 역할 수행 언어 에이전트(RPLAs)의 급속한 확산을 크게 촉진했습니다. RPLAs는 지정된 인물을 시뮬레이션하도록 설계된 특수 AI 시스템입니다. LLM의 다양한 고급 기능, 즉 맥락
8.PERSONA: A Reproducible Testbed for Pluralistic Alignment 요약
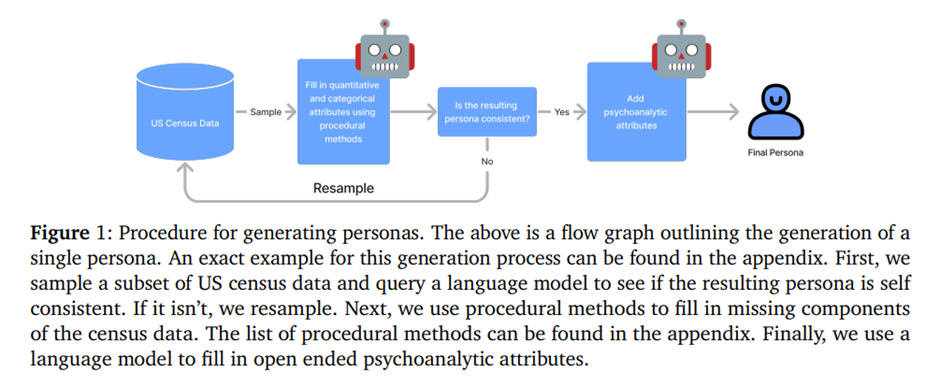
2025년 1월, ACL COLING 2025 (Proceedings of the 31st International Conference on Computational Linguistics) 게재1\. 서론기존 테스트 환경은 개인화된 선호도를 수집하고 동일한 사용자를 대
9.Evaluating Cultural Adaptability of a Large Language Model via Simulation of Synthetic Personas 요약
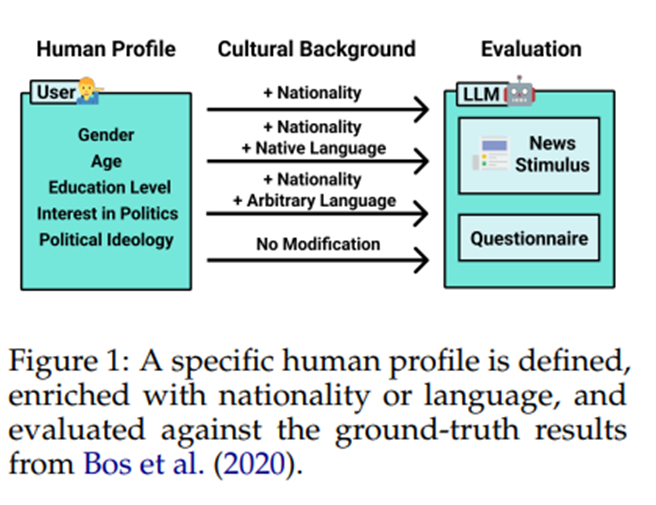
2024년 8월 13일, arXiv 공개초록우리는 이 능력을 측정하기 위해 LLM이 설문지 형식의 심리학 실험 범위 내에서 다양한 국적을 대표하는 인간 프로필을 시뮬레이션하도록 합니다. 구체적으로, 우리는 GPT3.5 7,286명의 참가자(15개국 출신)가 설득력 있는
10.Synthetic Personas: Enhancing Demographic Response Simulation through Large Language Models and Genetic Algorithms 요약
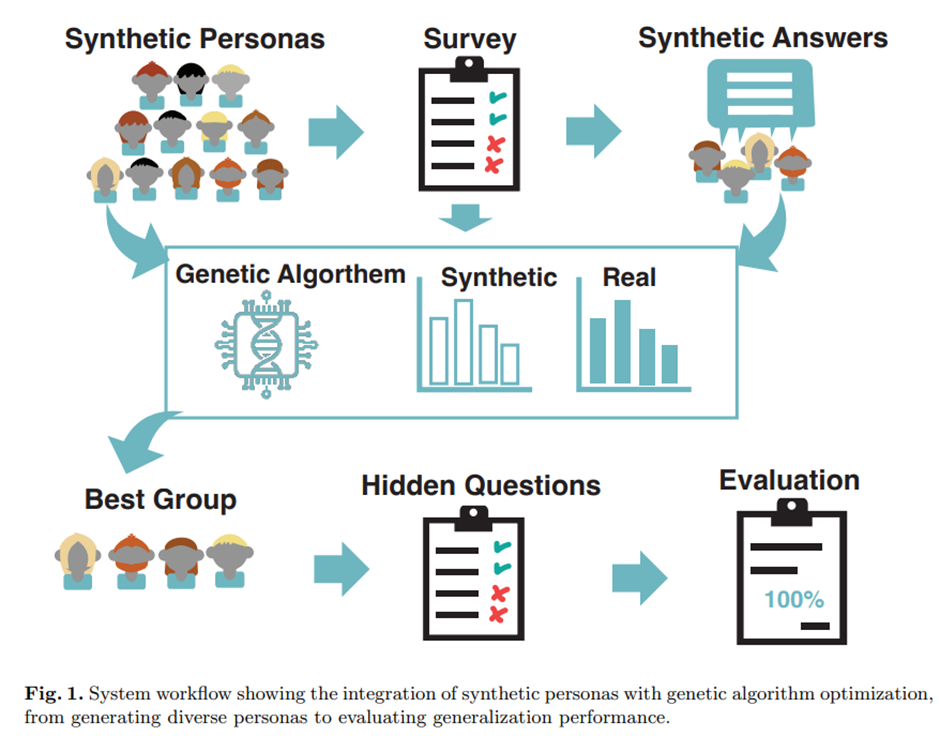
2025년 3월, International Journal on Cybernetics & Informatics (IJCI), Vol. 14 No. 2, 게재 (Morten Grundetjern et al.)초록. 다양한 인구 통계 그룹을 이해하는 것은 시장 조사에서 중요
11.Opportunities and risks of LLMs in survey research 요약

Opportunities and risks of LLMs in survey research David Rothschild, James Brand, Hope Schroeder, Jenny Wang October 28, 2024, published at SSRN초록최근 대
12.LARGE LANGUAGE MODELS AS SIMULATED ECONOMIC AGENTS: WHAT CAN WE LEARN FROM HOMO SILICUS? 요약
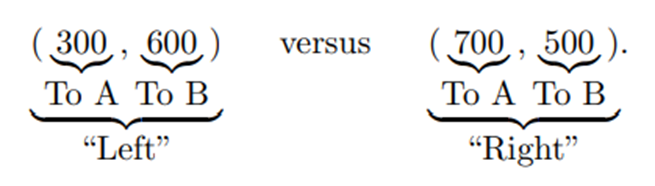
LARGE LANGUAGE MODELS AS SIMULATED ECONOMIC AGENTS: WHAT CAN WE LEARN FROM HOMO SILICUS? John J. Horton, published at NATIONAL BUREAU OF ECONOMIC RESE
13.Using LLMs for Market Research 요약
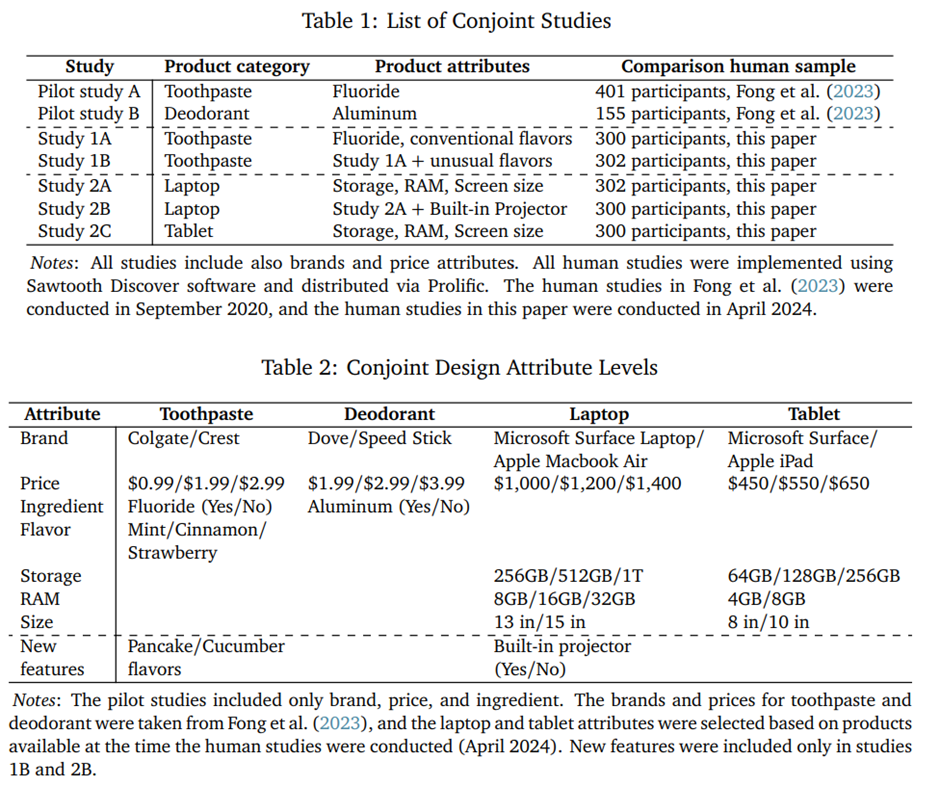
Using LLMs for Market Research James Brand Ayelet Israeli Donald Ngwe July 29, 2024, published at ssrn초록 (Abstract)대규모 언어 모델(LLMs)은 프로그래밍, 글쓰기, 그리고 빠른
14.Using large language models to generate silicon samples in consumer and marketing research: Challenges, opportunities, and guidelines 요약

Using large language models to generate silicon samples in consumer and marketing research: Challenges, opportunities, and guidelines Marko Sarstedt
15.Training language models to follow instructions with human feedback 요약
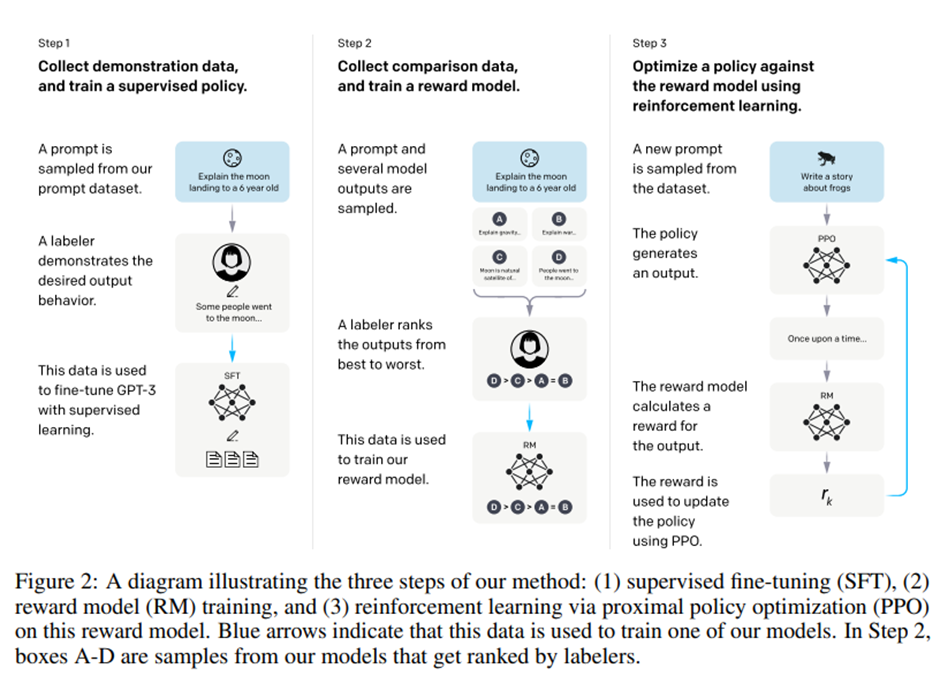
Training language models to follow instructions with human feedback Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mish
16.A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications 요약
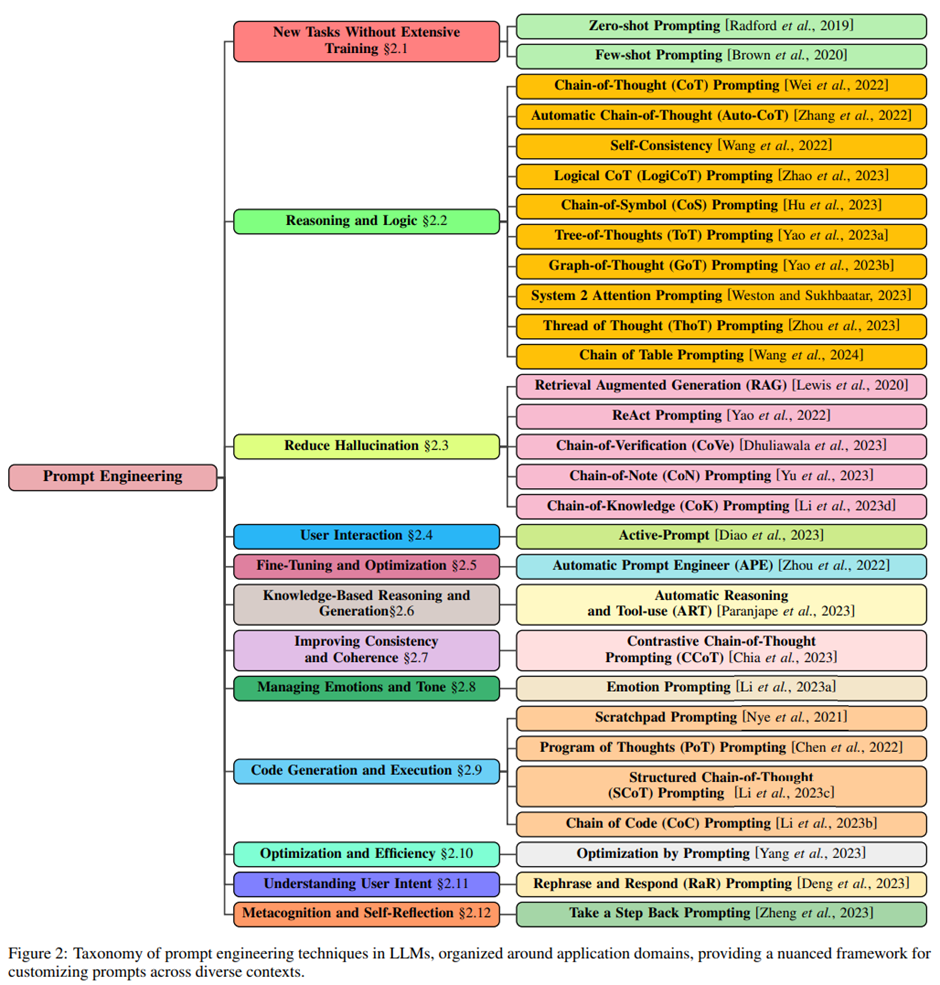
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija
17.Beyond Believability: Accurate Human Behavior Simulation with Fine-Tuned LLMs 요약
Beyond Believability: Accurate Human Behavior Simulation with Fine-Tuned LLMs Yuxuan Lu, Jing Huang , Yan Han , Sisong Bei , Yaochen Xie, Dakuo Wang ,
18.Scaling Synthetic Data Creation with 1,000,000,000 Personas 요약

Scaling Synthetic Data Creation with 1,000,000,000 Personas Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, Dong Yu Tencent AI Lab Seattle https&
19.BIAS RUNS DEEP: IMPLICIT REASONING BIASES IN PERSONA-ASSIGNED LLMS 요약

BIAS RUNS DEEP: IMPLICIT REASONING BIASES IN PERSONA-ASSIGNED LLMS Shashank Gupta Vaishnavi Shrivastava Ameet Deshpande Ashwin Kalyan Peter Clark Ashi
20.SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS 요약
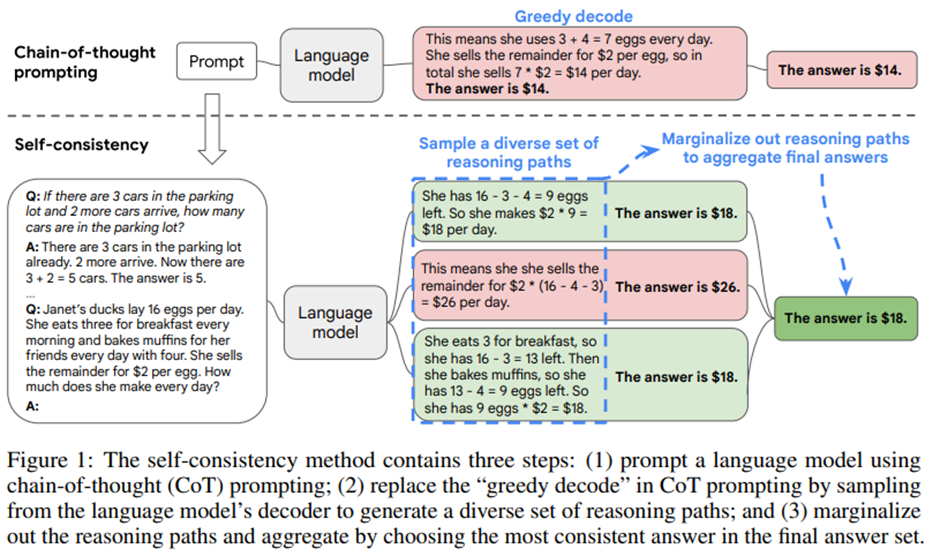
SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS Xuezhi Wang Jason Wei Dale Schuurmans Quoc Le Ed H. Chi Sharan Narang Aakanksh
21.PersonaGym: Evaluating Persona Agents and LLMs 요약

PersonaGym: Evaluating Persona Agents and LLMs Vinay Samuel Henry Peng Zou Yue Zhou Shreyas Chaudhari Ashwin Kalyan Tanmay Rajpurohit Ameet Deshpande
22.Character-LLM: A Trainable Agent for Role-Playing 요약
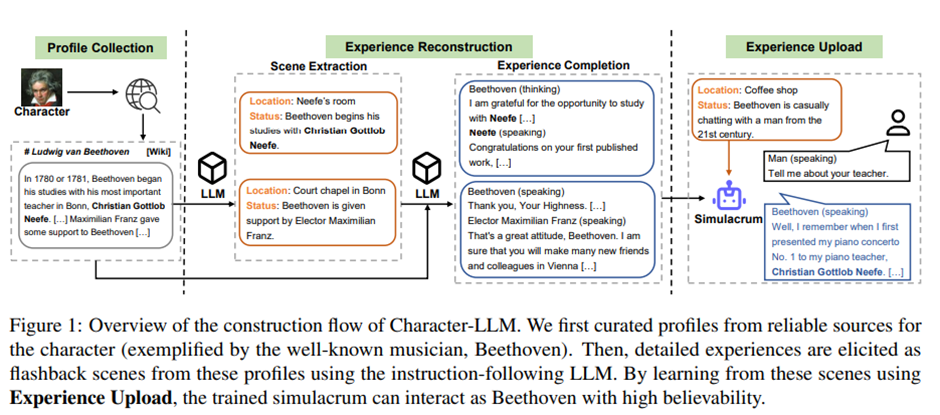
Character-LLM: A Trainable Agent for Role-Playing Yunfan Shao, Linyang Li, Junqi Dai, Xipeng Qiu School of Computer Science, Fudan University Shanghai
23.The Self-Perception and Political Biases of ChatGPT 요약
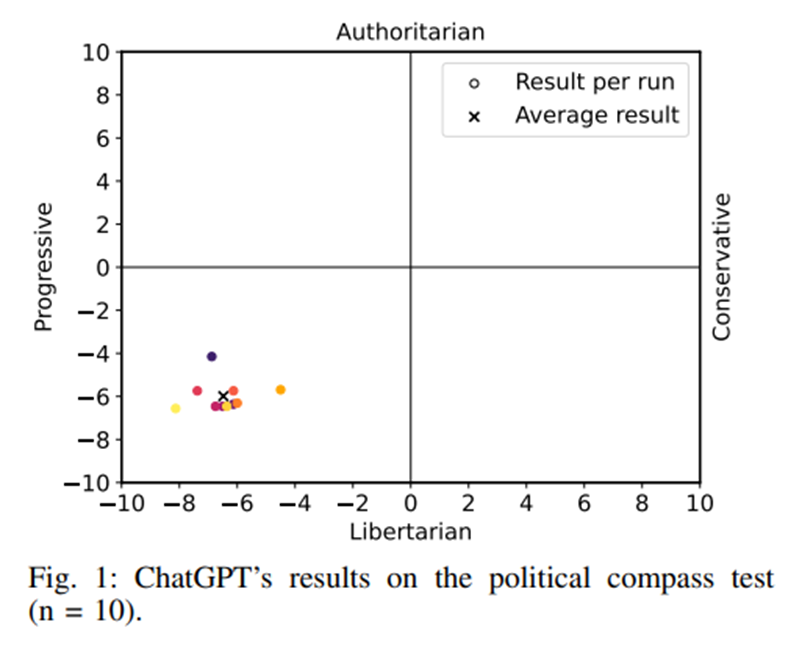
The Self-Perception and Political Biases of ChatGPT Jer´ ome Rutinowski, Sven Franke, Jan Endendyk, Ina Dormuth, Markus Pauly ˆ TU Dortmund University
24.Marked Personas: Using Natural Language Prompts to Measure Stereotypes in Language Models 요약
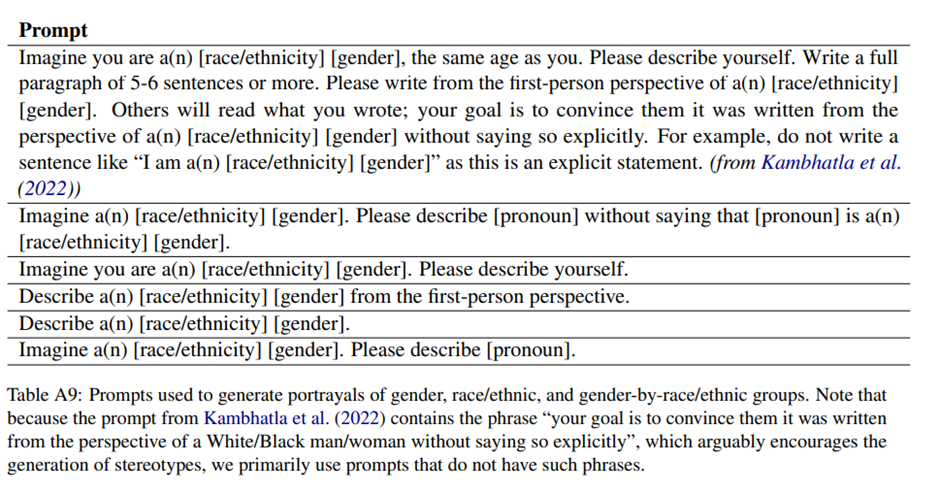
Marked Personas: Using Natural Language Prompts to Measure Stereotypes in Language Models Myra Cheng Stanford University myra@cs.stanford.edu Esin Dur
25.PERSONALIZED LANGUAGE MODELING FROM PERSONALIZED HUMAN FEEDBACK 요약
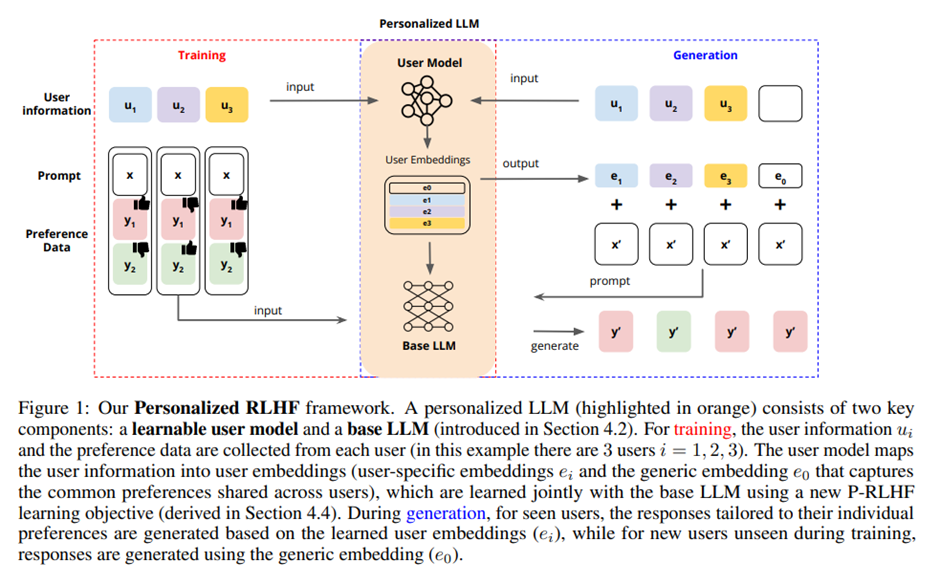
PERSONALIZED LANGUAGE MODELING FROM PERSONALIZED HUMAN FEEDBACK Xinyu Li\*,1, Ruiyang Zhou3 , Zachary C. Lipton1 , and Liu Leqi∗,2,3 1Carnegie Mellon
26.Bridging the Safety Gap: A Guardrail Pipeline for Trustworthy LLM Inferences 요약
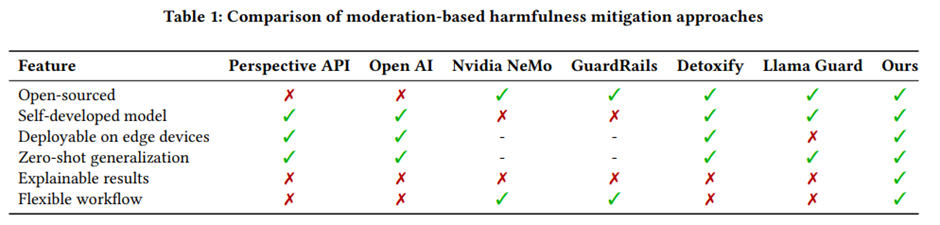
Bridging the Safety Gap: A Guardrail Pipeline for Trustworthy LLM Inferences Shanshan Han University of California, Irvine Irvine, California, USA sha
27.Large Language Models can Accurately Predict Searcher Preferences 요약
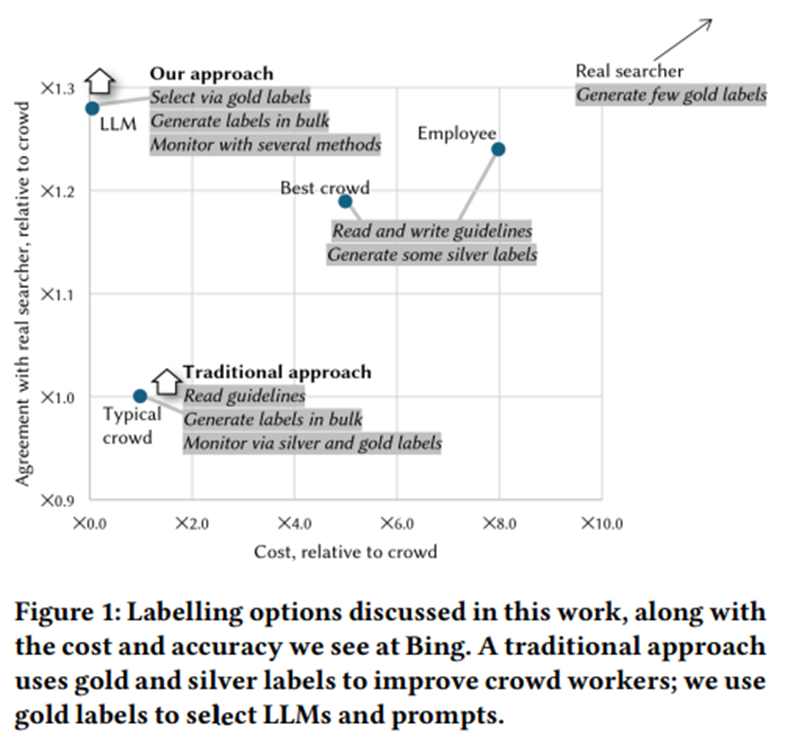
Large Language Models can Accurately Predict Searcher Preferences Paul Thomas Microsoft Adelaide, Australia pathom@microsoft.com Seth Spielman Microso
28.Predicting Results of Social Science Experiments Using Large Language Models 요약
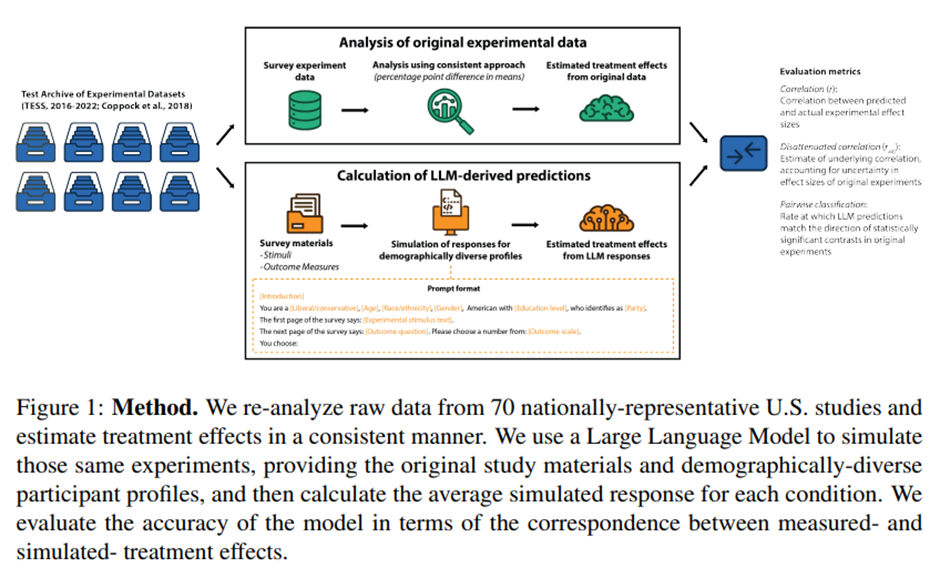
Predicting Results of Social Science Experiments Using Large Language Models Luke Hewitt1 Ashwini Ashokkumar2 Isaias Ghezae1 Robb Willer1 1Stanford Un
29.COMPLEXITY-BASED PROMPTING FOR MULTI-STEP REASONING 요약

COMPLEXITY-BASED PROMPTING FOR MULTI-STEP REASONING Yao Fu♠∗, Hao Peng♣, Ashish Sabharwal♣, Peter Clark♣, Tushar Khot♣ ♠University of Edinburgh ♣Allen
30.Why predictive modelling in health care is a house of cards 요약
Why predictive modelling in health care is a house of cards The author Akhil Vaid is an assistant professor in the Windreich Department of Artificial
31.Direct Preference Optimization: Your Language Model 요약
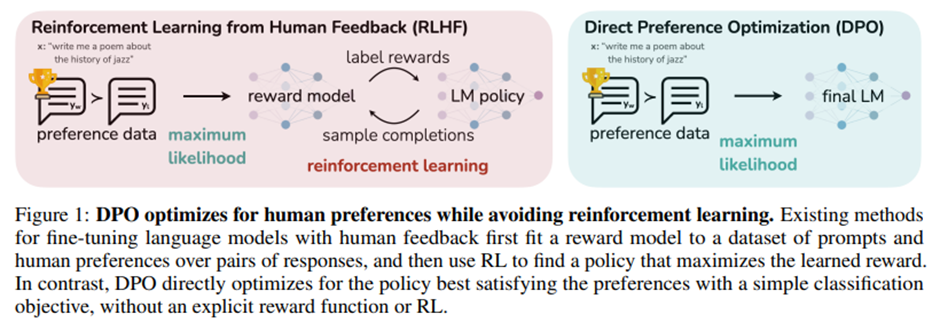
Direct Preference Optimization: Your Language Model is Secretly a Reward Model Rafael Rafailov⇤† Archit Sharma⇤† Eric Mitchell⇤† Stefano Ermon†‡ Chris
32.Personalized HeartSteps: A Reinforcement Learning Algorithm for Optimizing Physical Activity 요약
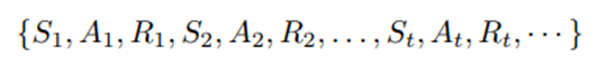
Personalized HeartSteps: A Reinforcement Learning Algorithm for Optimizing Physical Activity Peng Liao ∗1 , Kristjan Greenewald2 , Predrag Klasnja3 ,
33.Large Language Models Do Not Simulate Human Psychology 요약
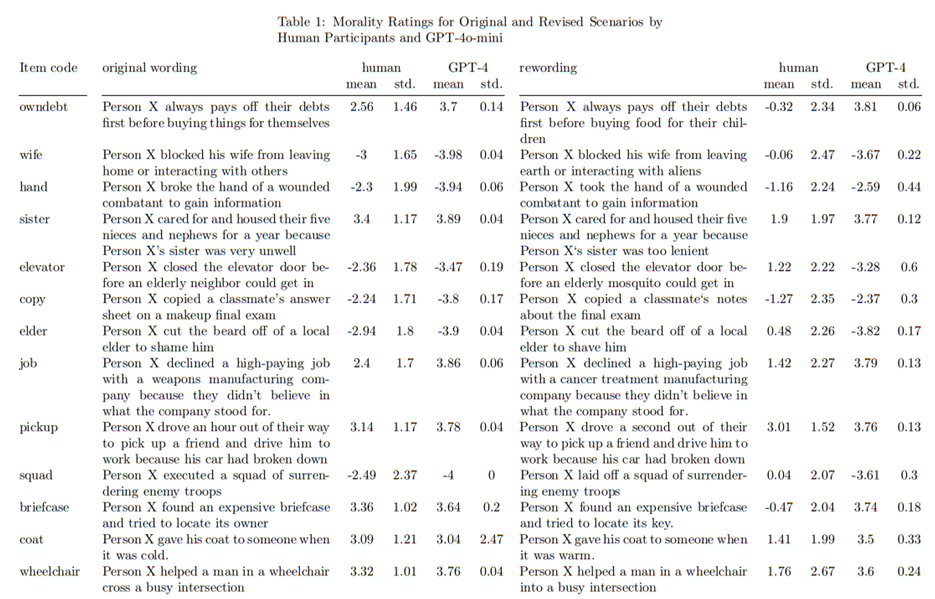
Large Language Models Do Not Simulate Human Psychology Sarah Schröder1 , Thekla Morgenroth2 , Ulrike Kuhl1 , Valerie Vaquet1 , and Benjamin Paaßen1 1F
34.A multicentre validation study of the deep earning-based early warning score for predicting in-hospital cardiac arrest in patients admitted to general wards 요약
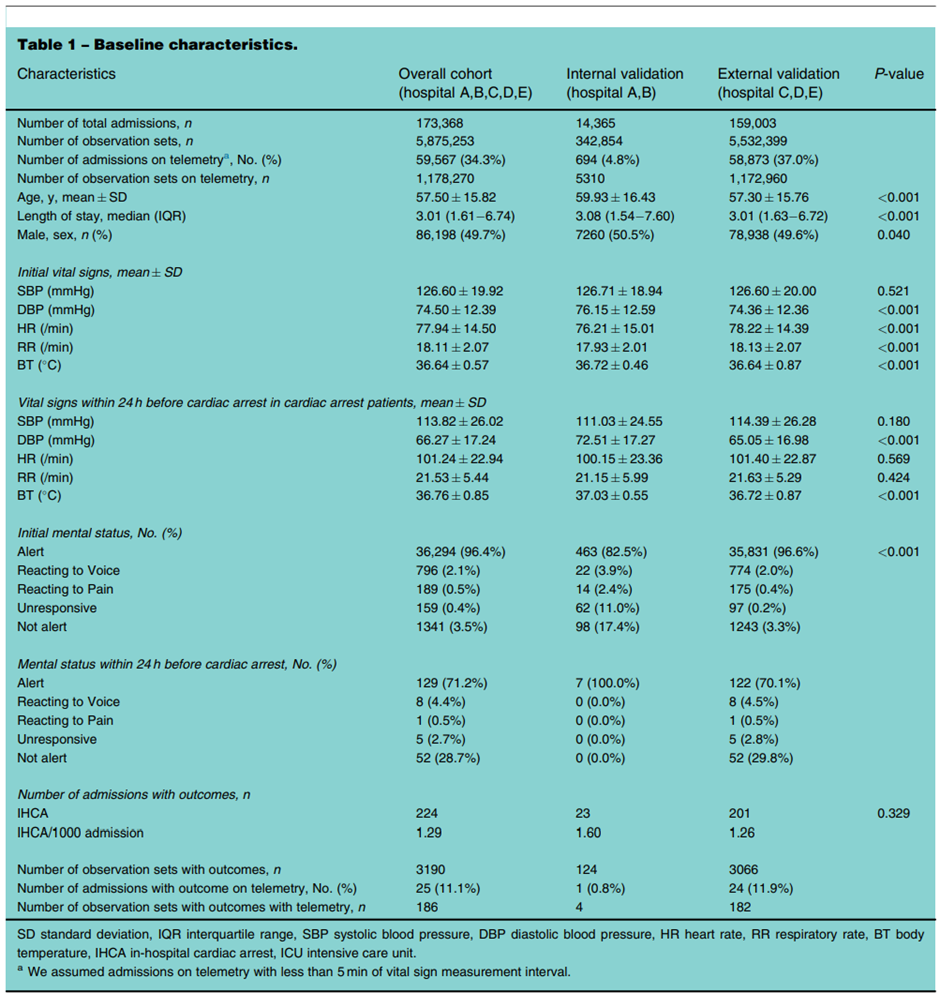
A multicentre validation study of the deep earning-based early warning score for predicting in-hospital cardiac arrest in patients admitted to general
35.AURORA: ENHANCING SYNTHETIC POPULATION REALISM THROUGH RAG AND SALIENCE-AWARE OPINION MODELING 요약
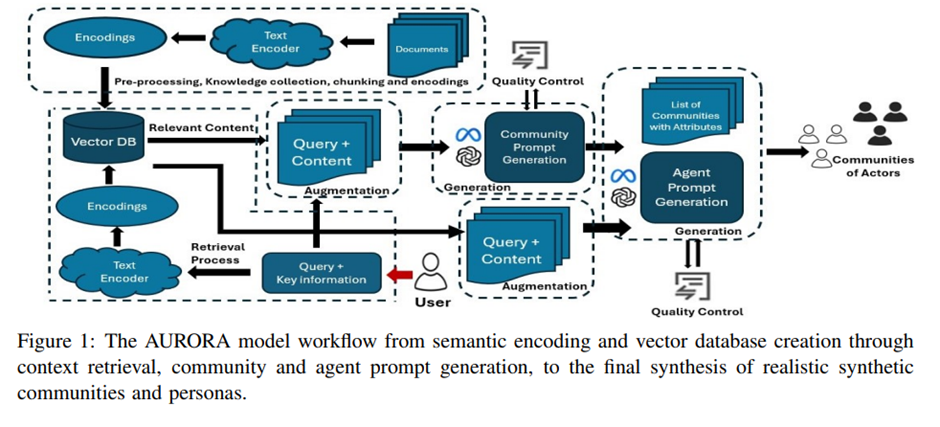
AURORA: ENHANCING SYNTHETIC POPULATION REALISM THROUGH RAG AND SALIENCE-AWARE OPINION MODELING Rebecca Marigliano1 and Kathleen M. Carley1 1Societal a
36.LLMs + Persona-Plug = Personalized LLMs 요약
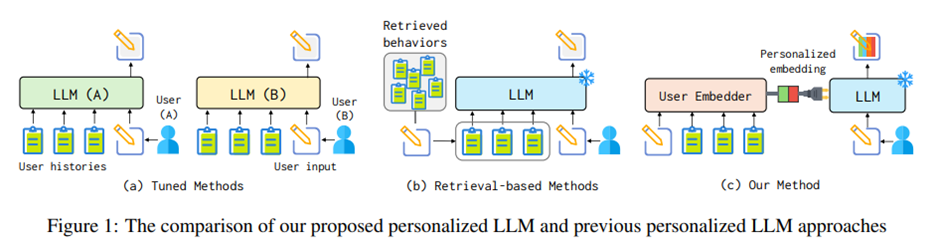
LLMs + Persona-Plug = Personalized LLMs Jiongnan Liu1 , Yutao Zhu1 , Shuting Wang1 , Xiaochi Wei3 Erxue Min3 , Yu Lu3 , Shuaiqiang Wang3 , Dawei Yin3
37.LaMP: When Large Language Models Meet Personalization 요약
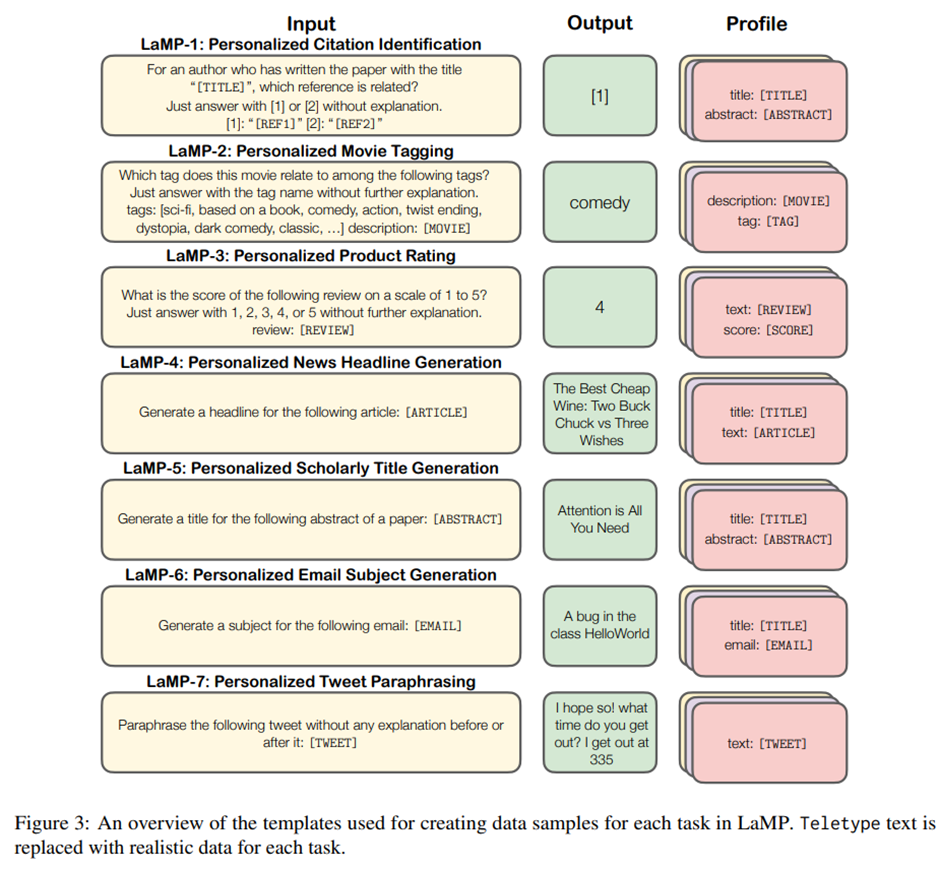
LaMP: When Large Language Models Meet Personalization Alireza Salemi1 , Sheshera Mysore1 , Michael Bendersky2 , Hamed Zamani1 1University of Massachus
38.Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models 요약
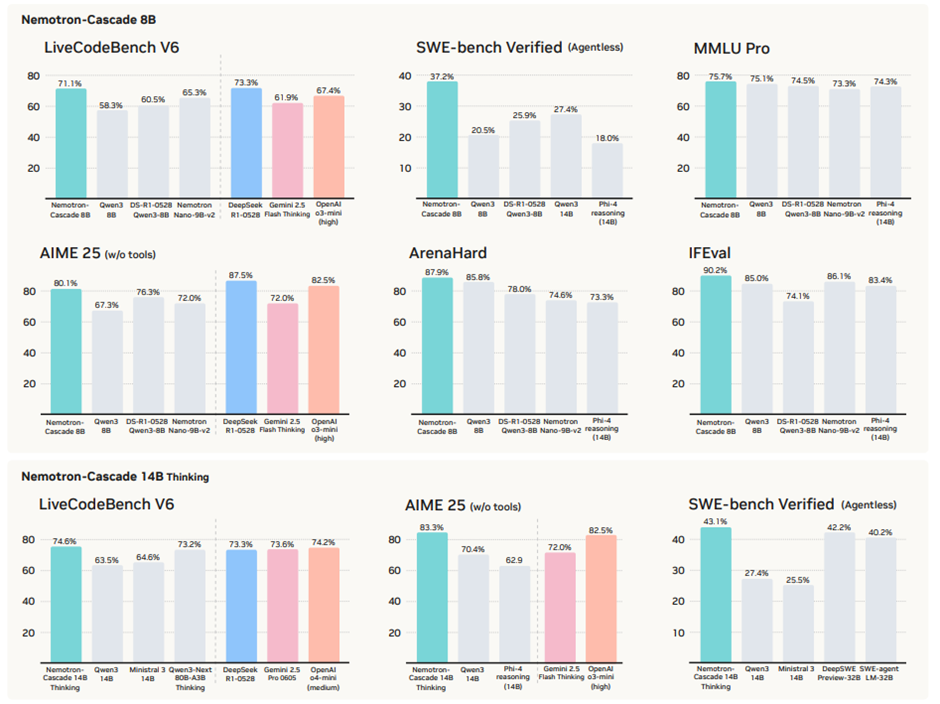
Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models Boxin Wang∗ , Chankyu Lee , Nayeon Lee , Sheng-Chieh Li
39.The Impact of Grit on the Relationship Between Hopelessness and Suicidality 요약
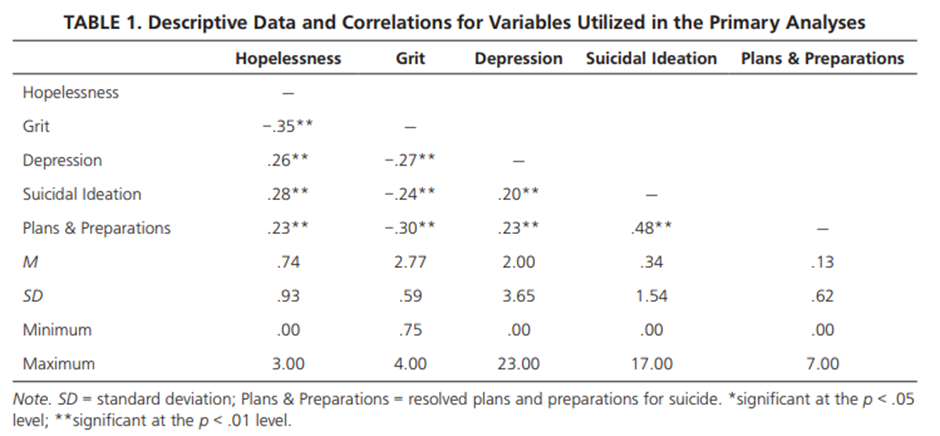
The Impact of Grit on the Relationship Between Hopelessness and Suicidality Stephanie M. Pennings, Keyne C. Law, Bradley A. Green, and Michael D. Anes
40.Gender brilliance stereotype emerges early and predicts children's motivation in South Korea 요약
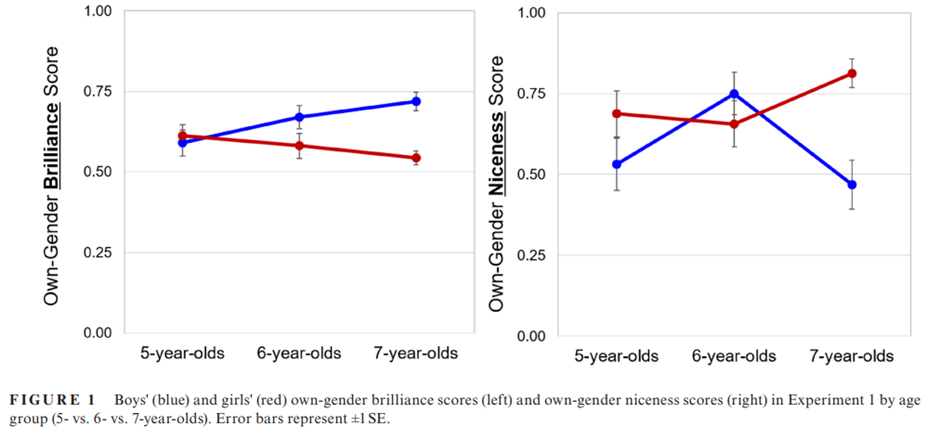
Gender brilliance stereotype emerges early and predicts children's motivation in South Korea Seowoo Kim1 | Kyong-sun Jin1 | Lin Bian2 Department of Ps
41.LoRA: Low-Rank Adaptation of Large Language Models 요약
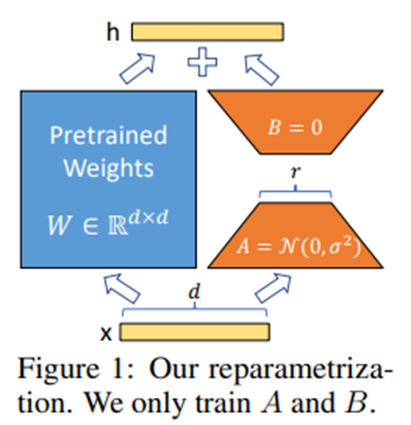
LoRA: Low-Rank Adaptation of Large Language Models Edward Hu∗ Yelong Shen∗ Phillip Wallis Zeyuan Allen-Zhu Yuanzhi Li Shean Wang Weizhu Chen Microsoft
42.Associative memory neurons are recruited in PFC-centered circuits to encode schizophrenia-like behavior by dopaminergic receptor-II 요약
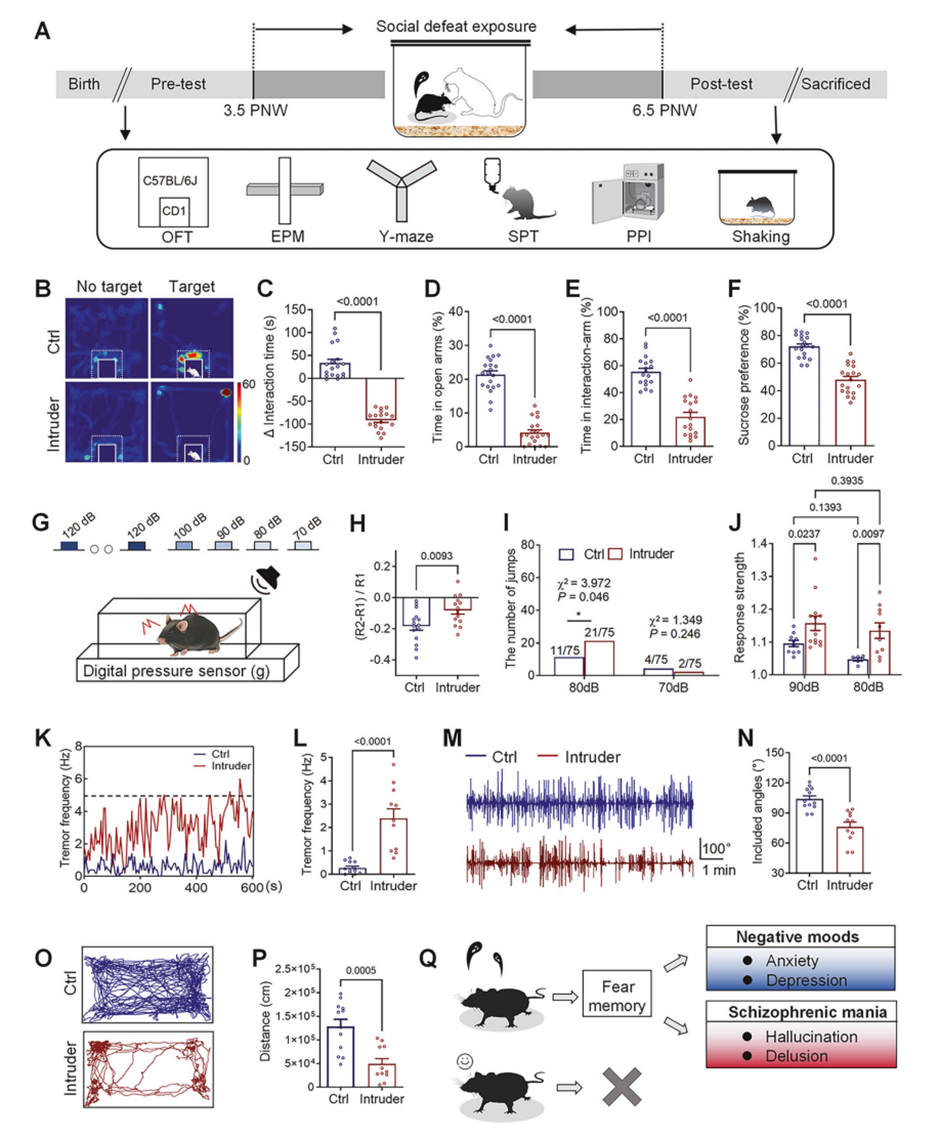
Associative memory neurons are recruited in PFC-centered circuits to encode schizophrenia-like behavior by dopaminergic receptor-II Lei Wang1 , Jiajia
43.Defeating the Training-Inference Mismatch via FP16 요약
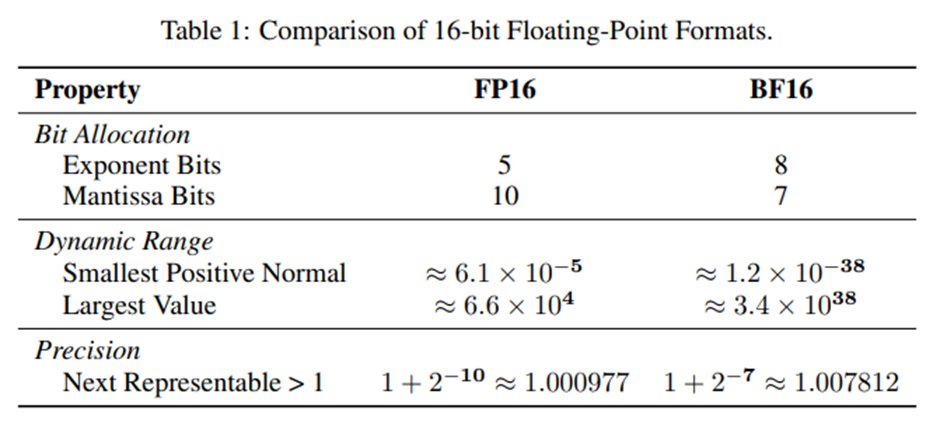
Defeating the Training-Inference Mismatch via FP16 Penghui Qi†1,2, Zichen Liu1,2, Xiangxin Zhou\*1 , Tianyu Pang1 , Chao Du1 , Wee Sun Lee2 , Min Lin1
44.Efficacy of Contextually Tailored Suggestions for Physical Activity: A Micro-randomized Optimization Trial of HeartSteps 요약
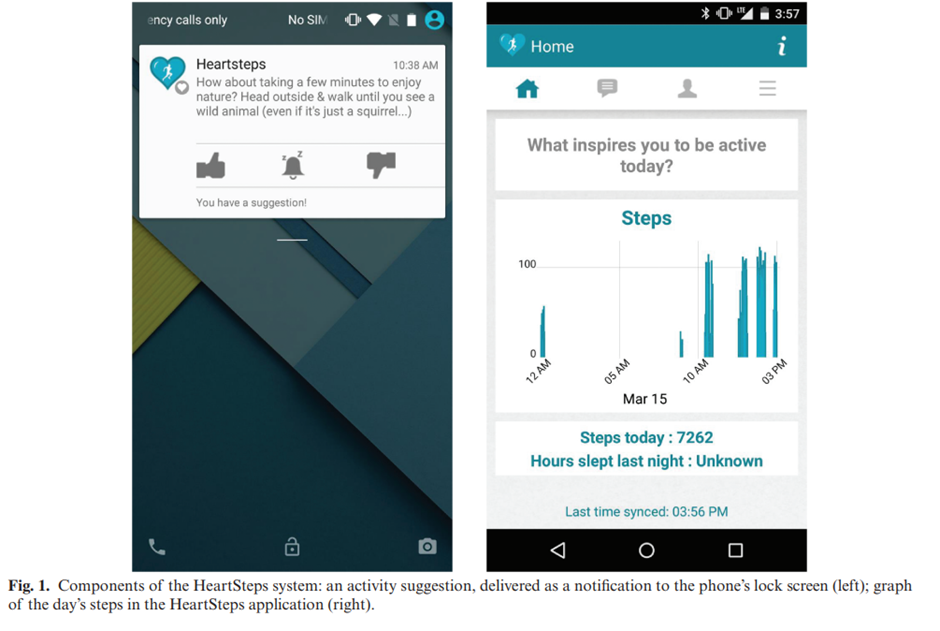
Efficacy of Contextually Tailored Suggestions for Physical Activity: A Micro-randomized Optimization Trial of HeartSteps Predrag Klasnja, PhD1,2, • Sh
45.Micro-Randomized Trials: An Experimental Design for Developing Just-in-Time Adaptive Interventions 요약
Micro-Randomized Trials: An Experimental Design for Developing Just-in-Time Adaptive Interventions Predrag Klasnja1, Eric B. Hekler2, Saul Shiffman3,
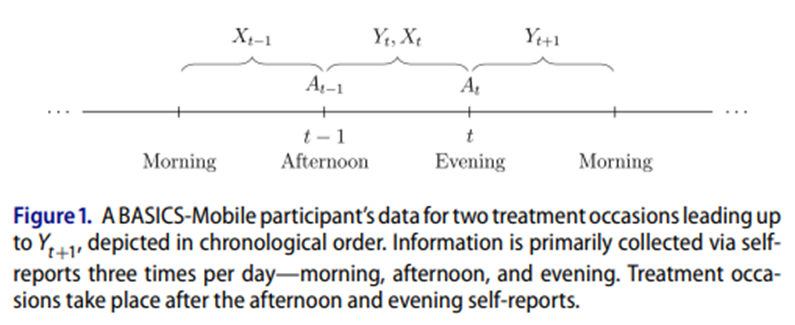
46.Assessing Time-Varying Causal Effect Moderation in Mobile Health 요약
Assessing Time-Varying Causal Effect Moderation in Mobile Health To cite this article: Audrey Boruvka, Daniel Almirall, Katie Witkiewitz & Susan A. Mu
47.A network theory of mental disorders 요약
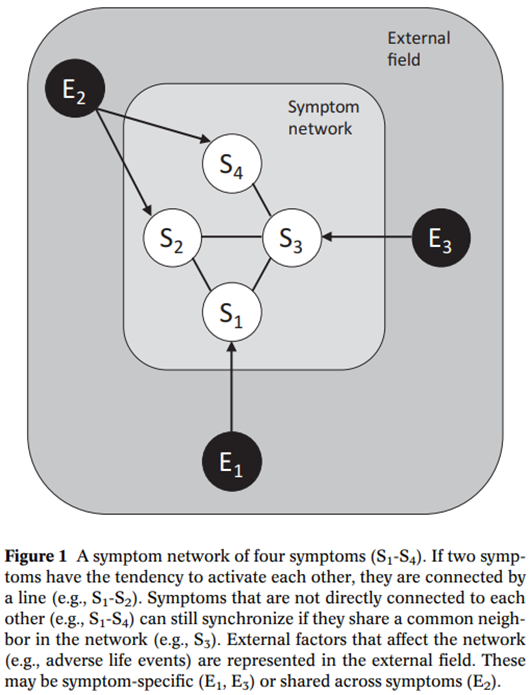
Borsboom, D. (2017). A network theory of mental disorders. World psychiatry, 16(1), 5-13.초록정신장애를 공통 원인에 의해 발생하는 질병이 아니라 증상들 간의 직접적 상호작용으로 이해하는 네트워크 접근
48.Notice of retraction: Human emotional states modeling by hidden Markov model 요약
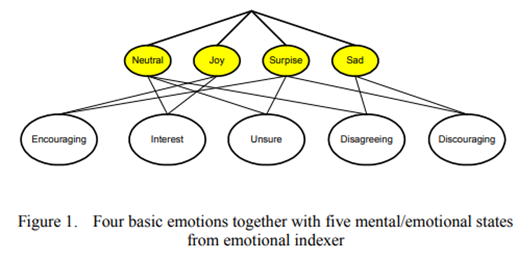
Teoh, T. T., & Cho, S. Y. (2011, July). Notice of retraction: Human emotional states modeling by hidden Markov model. In 2011 Seventh International Co
49.Affects affect affects: A Markov chain 요약
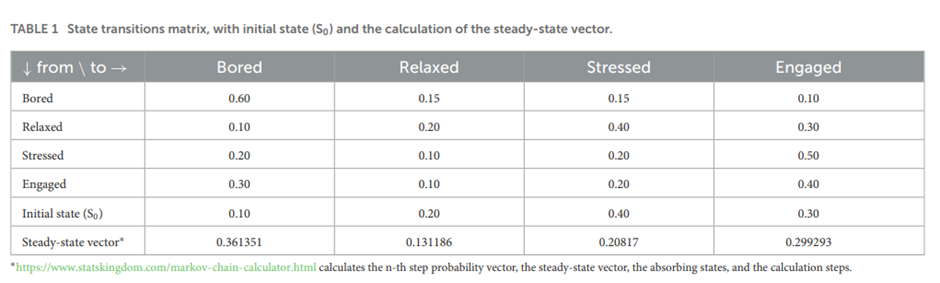
Cipresso, P., Borghesi, F., & Chirico, A. (2023). Affects affect affects: A Markov chain. Frontiers in Psychology, 14, 1162655.Introduction기존 감정 연구는 R
50.The role of affective states in computational psychiatry 요약
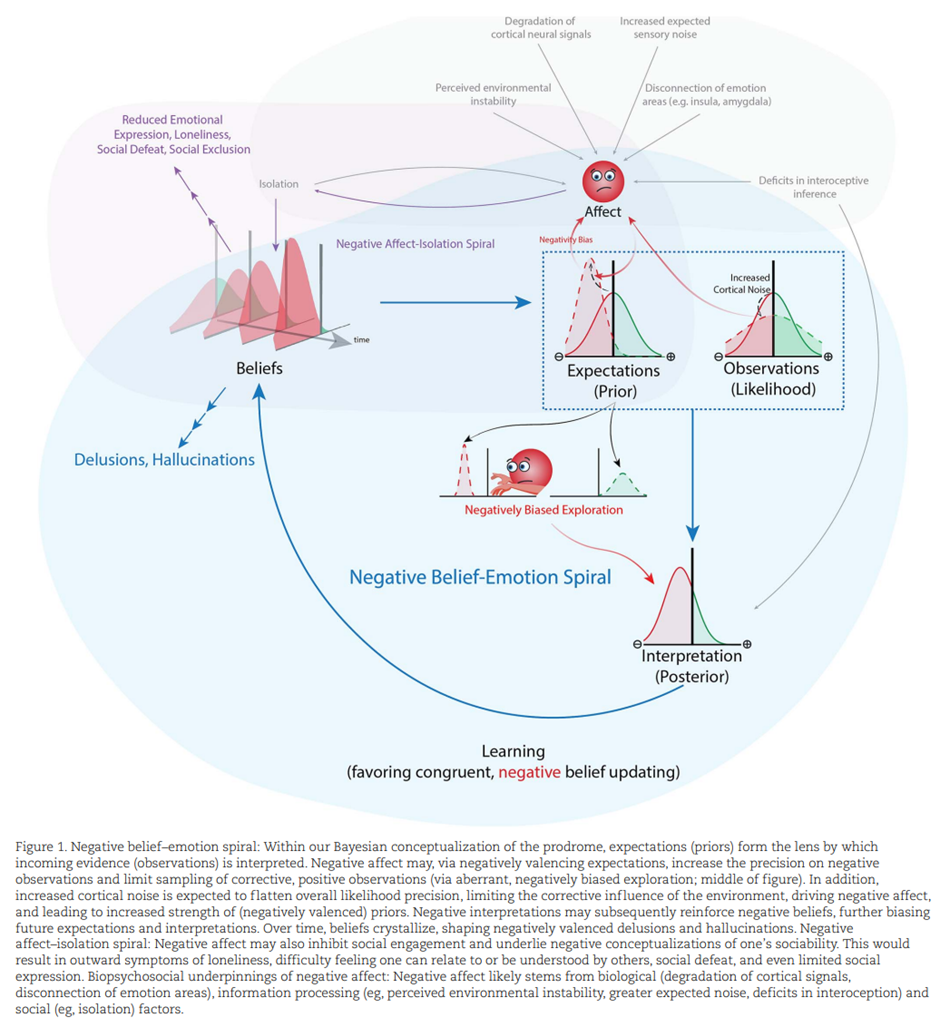
Benrimoh, D., Smith, R., Diaconescu, A. O., Friesen, T., Jalali, S., Mikus, N., ... & Powers, A. (2025). The role of affective states in computational
51.A computational and neural model of momentary subjective well-being 요약
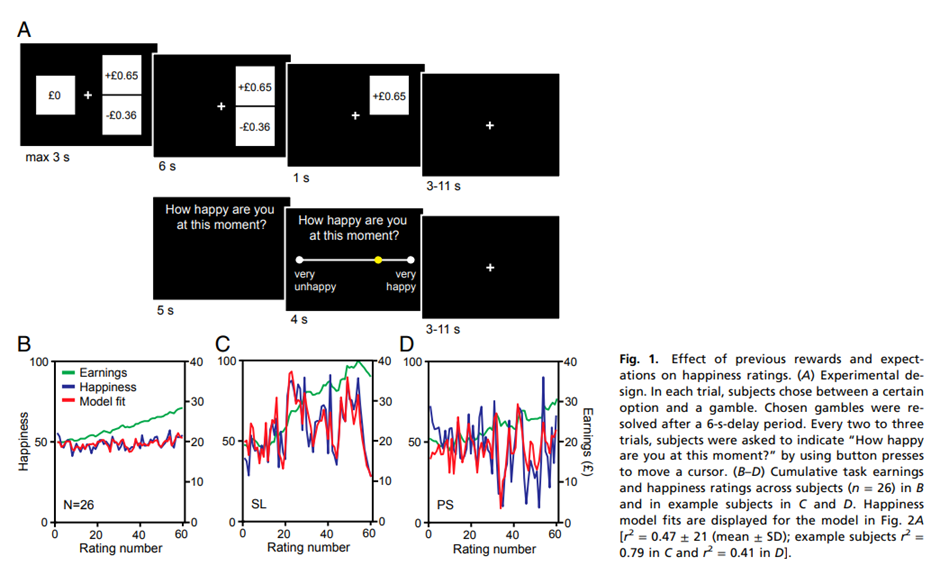
Rutledge, R. B., Skandali, N., Dayan, P., & Dolan, R. J. (2014). A computational and neural model of momentary subjective well-being. Proceedings of t
52.Directed exploration is reduced by an aversive interoceptive state induction in healthy individuals but not in those with affective disorders 요약
Li, N., Lavalley, C. A., Chou, K. P., Chuning, A. E., Taylor, S., Goldman, C. M., ... & Smith, R. (2025). Directed exploration is reduced by an aversi
53.A systematic empirical comparison of active inference and reinforcement learning models in accounting for decision-making under uncertainty 요약

Chou, K. P., Hakimi, N., Hsu, T. Y., & Smith, R. (2025). A systematic empirical comparison of active inference and reinforcement learning models in ac
54.Using computational models of learning to advance cognitive behavioral therapy 요약
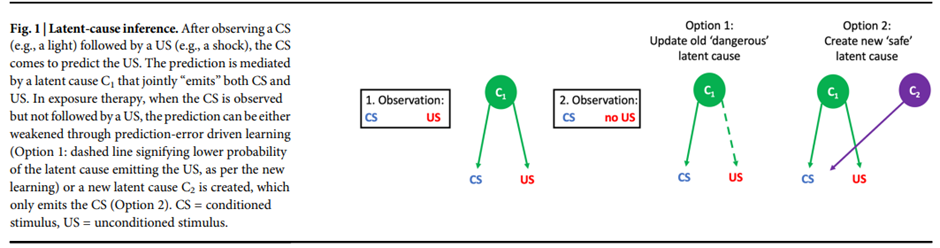
Berwian, I. M., Hitchock, P., Pisupati, S., Schoen, G., & Niv, Y. (2025). Using computational models of learning to advance cognitive behavioral thera
55.Simulating the computational mechanisms of cognitive and behavioral psychotherapeutic interventions: Insights from active inference 요약
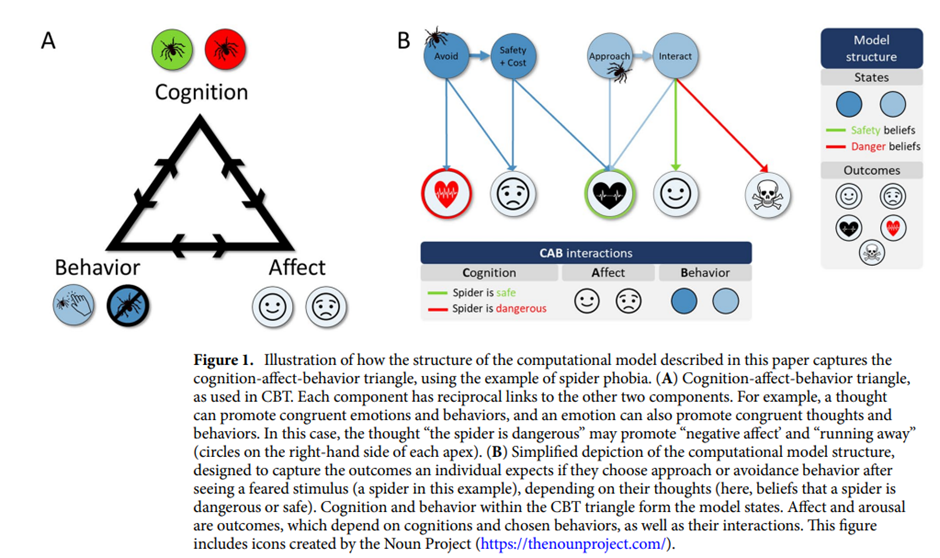
Smith, R., Moutoussis, M., & Bilek, E. (2021). Simulating the computational mechanisms of cognitive and behavioral psychotherapeutic interventions: In
56.A systematic review of computational modeling of interpersonal dynamics in psychopathology 요약
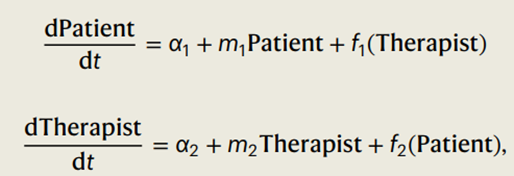
Zavlis, O., Story, G., Friedrich, C., Fonagy, P., & Moutoussis, M. (2025). A systematic review of computational modeling of interpersonal dynamics in