LoRA: Low-Rank Adaptation of Large Language Models Edward Hu∗ Yelong Shen∗ Phillip Wallis Zeyuan Allen-Zhu Yuanzhi Li Shean Wang Weizhu Chen Microsoft Corporation {edwardhu, yeshe, phwallis, zeyuana, yuanzhil swang, wzchen}@microsoft.com [Submitted on 17 Jun 2021 (v1), last revised 16 Oct 2021 (this version, v2)]
1 Introduction
파인튜닝의 가장 큰 단점: 원래 모델과 동일한 수의 파라미터를 저장해야 함.
완화를 위해: 1) 일부 파라미터만 튜닝, 2) 새로운 작업을 위한 외부 모듈 학습. -> 배포 효율은 향상되지만 추론 지연 발생, 입력 시퀀스 길이 감소, 파인튜닝 기준 성능에 도달 못하는 문제 발생.
과매개변수화 모델이 실제로는 낮은 내재 차원 위에 존재한다는 기존 연구[1, 20] -> 가설: 언어 모델 적응에서의 업데이트 행렬 역시 낮은 “내재 랭크(intrinsic rank)”를 가짐. -> 제안: LoRA
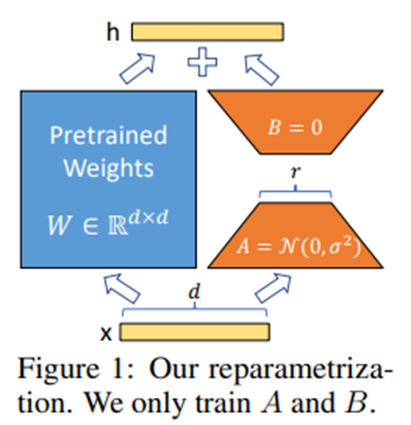
원래의 행렬은 고정한 채, 밀집 레이어의 업데이트에 대한 랭크 분해 행렬을 주입하고 이를 최적화함으로써 신경망의 모든 밀집 레이어를 간접적으로 학습할 수 있도록 함.
LoRA의 장점: 저장 요구량과 작업 전환 오버헤드 줄임, 학습 효율 높아지고 하드웨어 진입 장벽 3배 낮아짐, 추론 지연 추가 없음, prefix 튜닝 같은 방법과 결합 가능(예시는 부록 D).
D Combining LoRA with Prefix Tuning
WikiSQL과 MNLI 데이터셋에서 LoRA와 프리픽스 튜닝 변형들을 결합한 두 가지 방법.
LoRA+PrefixEmbed (LoRA+PE): LoRA와 프리픽스-임베딩 튜닝을 결합한 방식. 총 l_p+ l_i개의 특수 토큰을 삽입하고 이 토큰들의 임베딩을 학습 가능한 파라미터로 취급.
LoRA+PrefixLayer (LoRA+PL): LoRA와 프리픽스-레이어 튜닝을 결합한 방식. l_p+ l_i개의 특수 토큰을 삽입하지만, 이 토큰들의 은닉 표현이 자연스럽게 변하도록 두는 대신, 매 Transformer 블록 이후에 이를 입력과 무관한 벡터로 대체. -> 임베딩뿐 아니라 이후 Transformer 블록에서의 활성값들까지 모두 학습 가능한 파라미터로 취급.
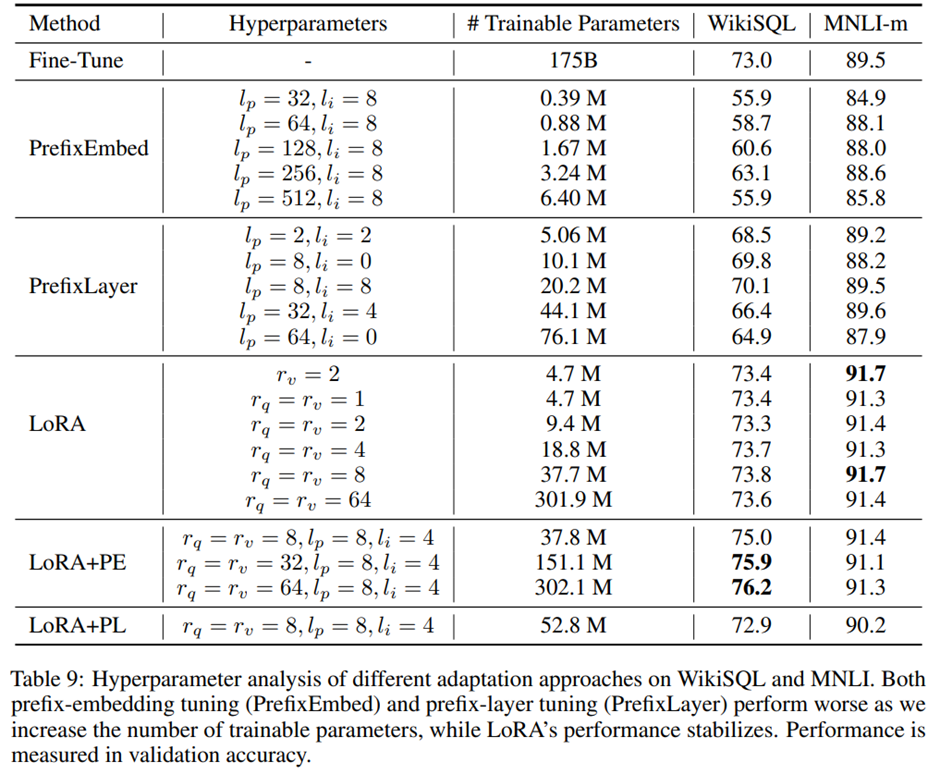
WikiSQL과 MultiNLI에서 LoRA+PE와 LoRA+PL의 평가 결과. LoRA+PE는 WikiSQL에서 LoRA 단독이나 프리픽스-임베딩 튜닝보다 유의미하게 더 나은 성능 -> oRA가 프리픽스-임베딩 튜닝과 어느 정도 직교적인 성질을 가진다는 것 시사. MultiNLI에서는 LoRA+PE가 LoRA 단독보다 더 나은 성능을 보이지 않음. -> LoRA만으로도 이미 인간 기준선에 준하는 성능을 달성했기 때문일 가능성.
LoRA+PL은 더 많은 학습 가능한 파라미터를 사용함에도 불구하고 LoRA 단독보다 약간 낮은 성능. -> 프리픽스-레이어 튜닝이 학습률 선택에 매우 민감하기 때문에, LoRA+PL 설정에서는 LoRA 가중치의 최적화가 더 어려워지기 때문이라고 해석.
2 Problem Statement
사전학습 자기회귀 언어모델: p_phi (y│x)
다운스트림 데이터셋: Z={(xi,y_i )}(i=1)^N
기존 파인튜닝 목적함수:
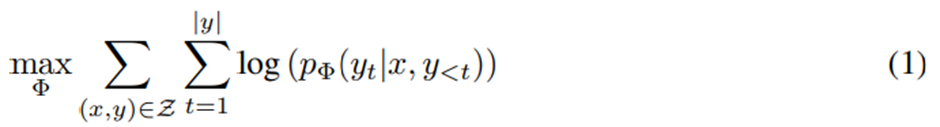
이 과정에서 모델은 사전학습된 파라미터 ϕ_0로 초기화되고, 조건부 언어 모델링 목적함수를 최대화하기 위해 반복적으로 그래디언트를 따라 ϕ_0+ Δϕ로 업데이트됨.
파인튜닝의 핵심 문제: 작업마다 서로 다른 Δϕ 학습. |Δϕ|=|ϕ_0 | -> 대규모 모델(GPT-3)의 경우 많은 독립적인 파인튜닝 모델을 저장하고 배포하는 것은 사실상 불가능.
파라미터 효율적 재정식화:
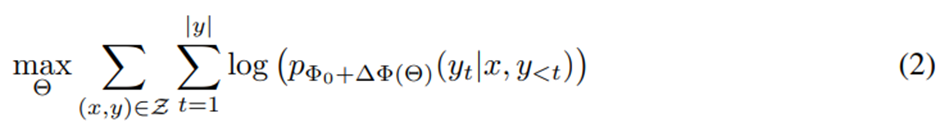
파라미터 효율적 접근법 채택 -> 작업 특화 파라미터 증가량 Δϕ= Δϕ(Θ)를 |Θ|≪|ϕ_0 |를 만족하는 훨씬 작은 크기의 파라미터 집합 Θ으로 추가적으로 인코딩 -> Δϕ를 찾는 문제는 Θ에 대한 최적화 문제로 바뀜.
제안: Δϕ를 계산적, 메모리 측면에서 모두 효율적인 저랭크 표현으로 인코딩하는 방법.
3 Our Method
Low-Rank Constraint on Update Matrices
사전학습 가중치: W_0∈R^(d×k)
LoRA 업데이트 방식: W_0+ΔW=W_0+BA where B∈R^((d×r) ),A∈R^(r×k),r≪min(d,k)
학습 설정: W_0 고정, A, B 학습.
순전파:
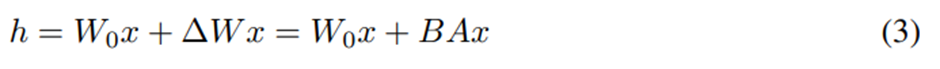
A: 무작위 가우시안 초기화, B: 0으로 초기화 -> 학습 시 ΔW=BA가 0이 되도록 함. 이후 학습 과정에서 ΔWx를 1/r로 스케일링해서, 학습이 끝난 뒤에도 ΔWx의 각 좌표가 r에 대해 대략 Θ(1)크기를 유지하도록 함.
Weight Decay to Pre-trained Weights
A, B에 weight decay 적용. -> 사전학습된 가중치로 되돌아가려는 정규화, catastrophic forgetting 완화 가능성. 예) r=d_model=1024인 LoRA가 GPT-2 Medium에서 full 파인튜닝보다 더 나은 성능.
No Additional Inference Latency
배포 시 W=W_0+BA를 명시적으로 계산. 작업 전환 시에는 BA 제거 후 B’A’ 추가. -> 최대 메모리 사용량 소폭 증가, 모델 전환 시 단일 순전파를 넘지 않는 수준의 지연 추가. 추론 과정 자체에는 추가 지연 발생 x.
3.1 Applying LoRA to Transformer
원칙적으로 LoRA는 신경망 내의 어떤 가중치 행렬 부분집합에도 적용하여 학습 가능한 파라미터 수 줄일 수 있음.
Transformer 아키텍처에는 self-attention 모듈에 네 개의 가중치 행렬(W_q,W_k,W_v,W_o)이 있고, MLP 모듈에는 두 개의 가중치 행렬. 출력 차원이 여러 어텐션 헤드로 분할되어도 W_q(또는 W_k,W_v)를 d_model×d_model 차원의 단일 행렬로 취급. 동일한 랭크 r을 사용할 경우 MLP 모듈에 LoRA를 적용하면 학습 가능한 파라미터 수가 4배로 증가 -> 다운스트림 작업에서는 어텐션 가중치만 변경, MLP 모듈은 고정해서 학습 x.
Practical Benefits and Limitations
메모리/저장 이점: r≪d_model일 때 VRAM 사용량 최대 2/3 감소, 체크포인트 크기를 대략 d_model/2γr 배만큼 줄일 수 있음. γ: LoRA를 적용하는 가중치 행렬의 비율. 예) GPT-3에서 VRAM 사용량 1.2TB -> 350GB, r=4, γ=1/6일 때 체크포인트 크기 350GB -> 35MB(10,000배 감소). -> 훨씬 적은 수의 GPU로 학습 가능, I/O 병목 피함.
배포 효율: 전체 가중치 대신 수 MB 단위의 LoRA 가중치만 교체해서 저비용, 빠른 작업 전환.
학습 효율: 대부분 파라미터 그래디언트 계산 불필요 -> 학습 속도 약 25% 향상
한계: 추론 지연 제거를 위해 A, B를 W에 흡수 -> 서로 다른 LoRA를 쓰는 다중 작업을 단일 순전파 배치 처리하기 어려움.
4 Related Works
Transformer Language Models
Transformer 기반 언어모델이 NLP 지배.
GPT-3: 175B 파라미터.
Prompt Engineering and Fine-Tuning
GPT-3는 프롬프트에 민감함.
파인튜닝은 성능 우수하지만 비용 과도.
Parameter-Efficient Adaptation
[15, 34]는 Adapter layers 삽입하는 방법 제안. LoRA는 이와 유사하게 저랭크 병목 구조를 사용하지만, 학습된 가중치를 메인 가중치와 병합 가능해 추론 지연이 없음.
파인튜닝 대신 입력 단어 임베딩 최적화하는 방식 -> 프롬프트에 더 많은 특수 토큰을 사용하는 방식으로만 확장 가능, 위치 임베딩이 학습된 경우 작업 토큰에 사용할 수 있는 시퀀스 길이 잠식.
Low-Rank Structures in Deep Learning
많은 ML/DL 문제는 본질적으로 저랭크. 기존 연구는 update의 저랭크성은 고려하지 않음.
5 Empirical Experiments
실험 모델: GPT-2, GPT-3.
데이터셋: GPT-3: WikiSQL(자연어에서 SQL 쿼리로의 변환), MultiNLI(자연어 추론), SAMSum(대화 요약), GPT-2: 언어 생성 과제인 Table-to-Text E2E NLG Challenge. 자세한 내용은 부록 B.
B Dataset Details
MultiNLI: 자연어 추론 데이터셋. 392,702개의 학습 예제와 9,815개의 검증 예제로 구성. 전처리 과정에서는 문맥을 x = {[premise]: premise, [hypothesis]: hypothesis} 형태로 인코딩하고, 타깃 y는 {entailment, neutral, contradiction} 중 하나로 설정.
WikiSQL: 56,355개의 학습 예제와 8,421개의 검증 예제를 포함. 과제의 목표는 자연어 질문과 테이블 스키마로부터 SQL 쿼리를 생성하는 것. 본 논문에서는 문맥을 x = {table schema, query}로, 타깃을 y = {SQL}로 인코딩.
E2E NLG Challenge: end-to-end 데이터 기반 자연어 생성 시스템을 학습하기 위한 데이터셋. Data-to-text 평가에 사용됨. 음식점 도메인에서 수집된 42K개의 학습 예제, 4.6K개의 검증 예제, 4.6K개의 테스트 예제로 구성. 입력으로 사용되는 각 소스 테이블은 여러 개의 참조 문장을 가질 수 있음. 각 샘플 입력 (x, y)는 슬롯-값 쌍들의 시퀀스와 이에 대응하는 자연어 참조 텍스트로 이루어져 있음.
DART: 오픈 도메인 Data-to-text 데이터셋. DART의 입력은 ENTITY | RELATION | ENTITY 형태의 트리플 시퀀스. 총 82K개의 예제 포함.
WebNLG: Data-to-text 평가에 사용됨. 총 22K개의 예제로 구성. 14개의 서로 다른 범주를 포함, 9개는 학습 단계에 사용. 5개는 테스트 세트에만 포함. 평가는 일반적으로 “seen”(S) 범주, “unseen”(U) 범주, 그리고 “all”(A)로 나누어 수행. 각 입력 예제는 SUBJECT | PROPERTY | OBJECT 트리플들의 시퀀스로 표현.
하드웨어: NVIDIA Tesla V100 GPU. GPT-3 fine-tuning: 96 GPUs, GPT-3 LoRA: 24 GPUs, GPT-2: 1 GPU
5.1 Baselines
Fine-Tuning: 마지막 두 개 레이어만 튜닝하는 방법(FT-Top2) 사용.
Bias only: 다운스트림 작업에 적응할 때 바이어스 벡터만 학습.
Prefix-embedding tuning: 입력 토큰과 함께 특수 토큰 주입하는 방식. 학습 가능한 파라미터 수: |Θ|=d_model×(l_p+l_i)
Prefix-layer tuning: prefix-embedding 튜닝의 확장. 일부 특수 토큰에 대해 단어 임베딩(또는 임베딩 레이어 이후의 활성값)만 학습하는 대신, 모든 레이어 이후의 활성값 학습. 학습 가능한 파라미터 수: |Θ|=L×d_model×(l_p+l_i), L: 레이어 수.
Adapter tuning: self-attention 모듈(및 MLP 모듈)과 그 다음 잔차 연결 사이에 어댑터 레이어 삽입. 하나의 어댑터 레이어에는 비선형성으로 연결된 두 개의 가중치 행렬 존재. 어댑터 레이어의 은닉 차원 크기 n이 전체 학습 파라미터 수 결정, 학습 가능한 파라미터 수: |Θ|=4×L×d_model×n
LoRA: 기존 가중치 행렬에 랭크 분해 행렬 쌍을 추가해서 학습. W_q,W_v에만 LoRA 적용. 학습 가능한 파라미터 수는 랭크 r과 원래 가중치의 형태에 의해 결정, 학습 가능한 파라미터 수: |Θ|=2×L×d_model×r
5.2 Performance on GPT-3
Hyperparameters
모든 GPT-3 실험에서 AdamW를 사용해 2 에포크, 배치 크기 10만 토큰, 시퀀스 길이는 768, 가중치 감쇠 계수 0.1. 자세한 내용은 C.1절.
C Hyperparameters Used in Experiments
C.1 GPT-3 Experiments
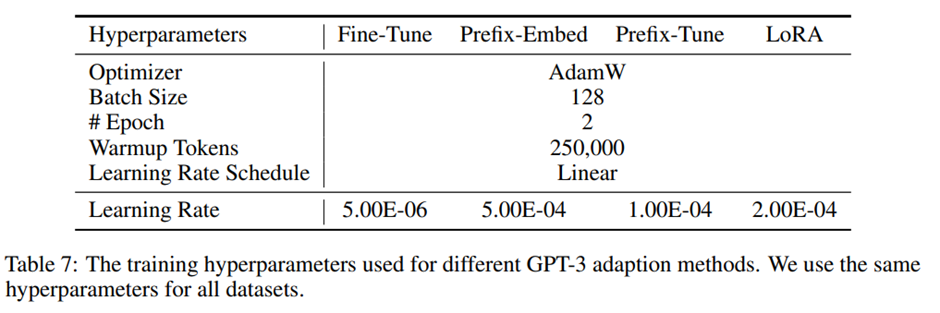
GPT-3 실험에서 사용된 학습 하이퍼파라미터.
Prefix-embedding 튜닝에서 최적의 l_p,l_i는 각각 256, 8. 총 학습 가능한 파라미터 수 320만개. PrefixLayer에서는 전체 성능을 가장 잘 얻기 위해 l_p,l_i 8, 학습 가능한 파라미터 수 2020만개. LoRA에 대해서는 1) r_q=r_v=4 (18.8M), 2) r_q=r_v=8 (37.7M)
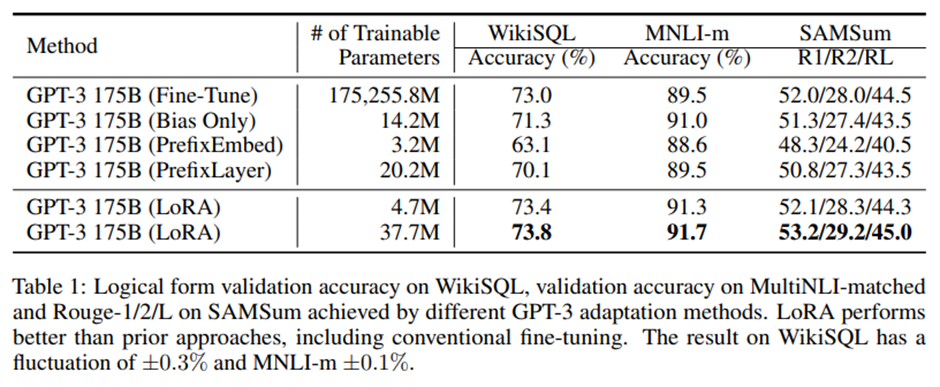
세 개의 데이터셋 모두에서 LoRA는 파인튜닝 기준선 능가. Prefix-embedding 튜닝은 다른 방법들보다 훨씬 적은 수의 파라미터를 사용하기 때문에 더 많은 학습 가능한 파라미터를 가질 경우 성능이 향상될 것처럼 보일 수도 있음.
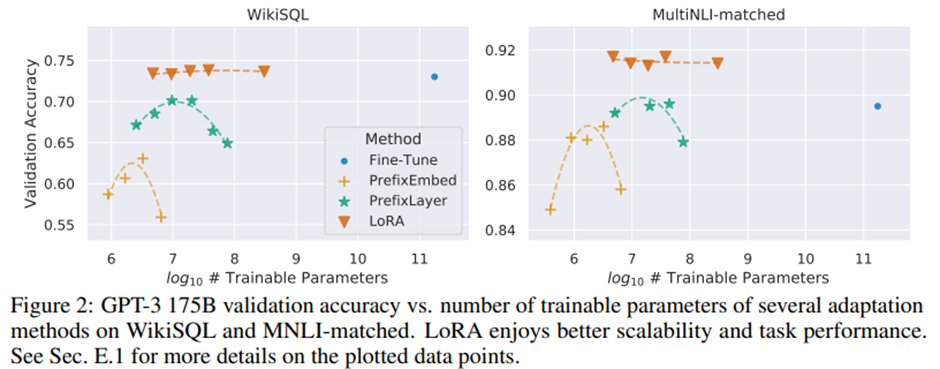
실제로는 그렇지 않음. Prefix-embedding 튜닝에서 256개를 초과하는 특수 토큰을 사용하거나, prefix-layer 튜닝에서 32개를 초과하는 특수 토큰을 사용할 경우 성능이 크게 저하. -> 특수 토큰의 수가 증가할수록 입력 분포가 사전 학습 데이터 분포에서 더 멀어지게 되어 모델 성능이 저하되는 것으로 추정.
저데이터 환경에서의 적응 방법 성능은 E.3절.
E Additional Task-Based Experiments
E.3 Low-Data Regime
저데이터 환경에서 서로 다른 적응 방법들의 성능을 평가하기 위해 MNLI 전체 학습 세트에서 무작위로 100개, 1,000개, 10,000개의 학습 예제를 샘플링하여 MNLI-n 저데이터 과제 구성.
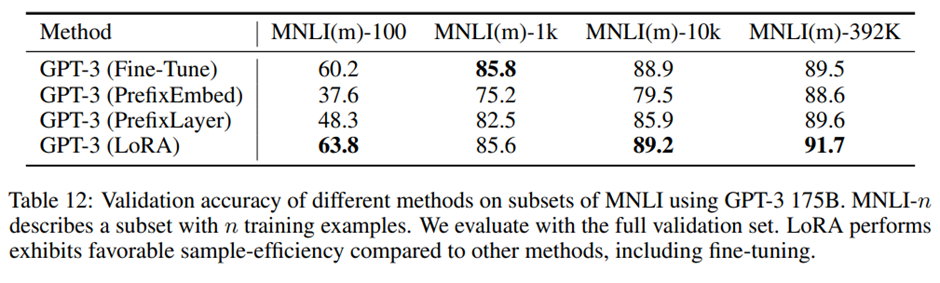
MNLI-n 과제에서 다양한 적응 방법들의 성능. PrefixEmbed와 PrefixLayer는 MNLI-100 데이터셋에서 매우 저조한 성능. PrefixEmbed는 무작위 추측보다 약간 나은 수준의 성능, (37.6% 대 33.3%) PrefixLayer는 PrefixEmbed보다는 더 나은 성능이지만 MNLI-100에서는 여전히 파인튜닝이나 LoRA에 비해 유의미하게 뒤쳐짐.
학습 예제 수가 증가함에 따라 프리픽스 기반 접근법들과 LoRA 또는 파인튜닝 간의 성능 격차는 점차 줄어들음 -> 프리픽스 기반 방법들이 GPT-3에서 저데이터 과제에는 적합하지 않을 수 있음.
LoRA는 MNLI-100과 MNLI-Full 모두에서 파인튜닝보다 더 나은 성능, MNLI-1k와 MNLI-10k에서는 파인튜닝과 비교해 유사한 성능.
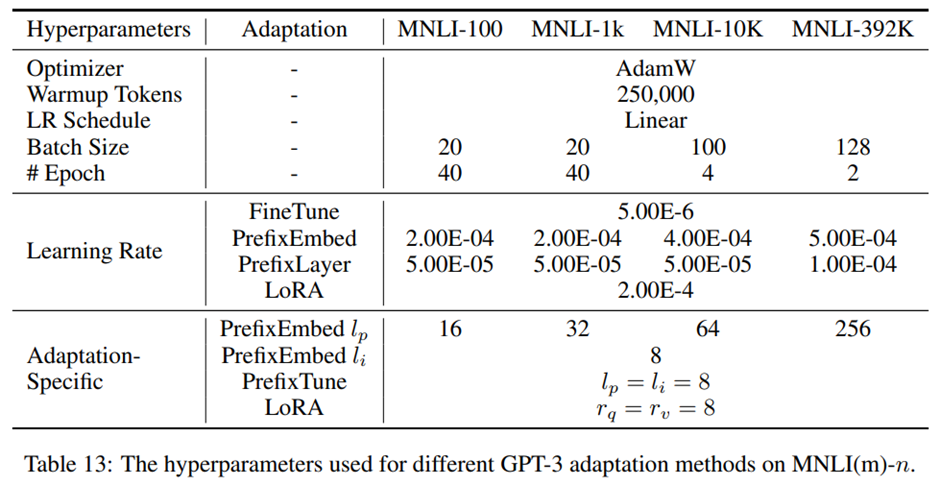
MNLI-n에서 서로 다른 적응 방법들에 사용된 학습 하이퍼파라미터. MNLI-100 설정에서는 더 큰 학습률을 사용할 경우 학습 손실이 감소하지 않았기 때문에 PrefixLayer에는 더 작은 학습률 사용.
5.3 Performance on GPT-2
GPT-3에서 LoRA가 경쟁력 있는 방법임을 확인. -> LoRA가 GPT-2 medium이나 large[32]와 같이 과도하게 파라미터화되지 않은 모델에서도 효과적으로 작동하는지 확인.
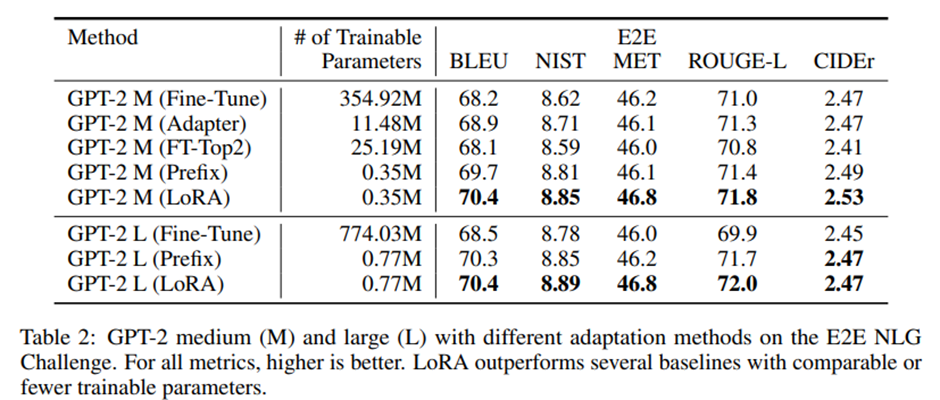
E2E NLG Challenge에서의 결과.
더 많은 데이터셋에 대한 결과는 E.2절.
E Additional Task-Based Experiments
E.2 Additional Experiments on GPT-2
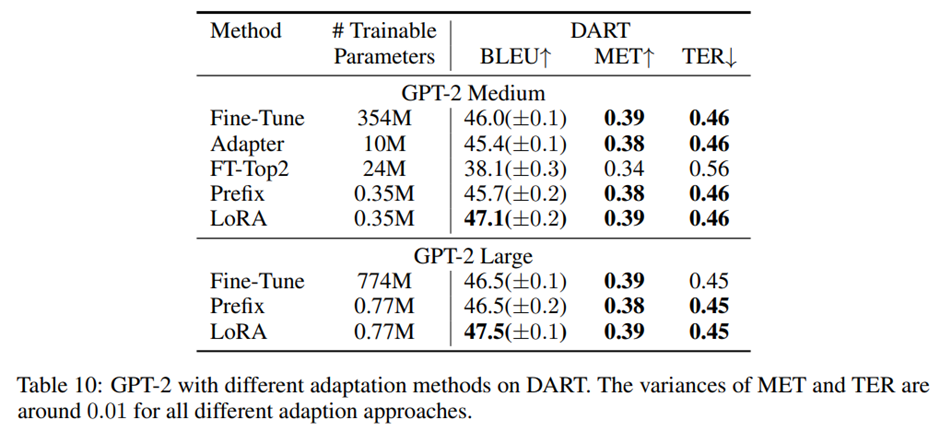
[21]의 설정을 따라 DART[27]와 WebNLG[10]에서 실험 반복한 결과. E2E NLG Challenge 결과와 유사하게, 동일한 수의 학습 가능한 파라미터가 주어졌을 때 LoRA는 프리픽스 기반 접근법들과 비교해 더 나은 성능을 보이거나 최소한 동등한 성능.
Hyperparameters
모든 GPT-2 모델은 AdamW[26]와 선형 학습률 스케줄을 사용하여 5 에포크. 배치 크기, 학습률, 빔 서치의 빔 크기: [21]에 기술된 설정. LoRA에 대해서도 동일한 하이퍼파라미터들 튜닝.
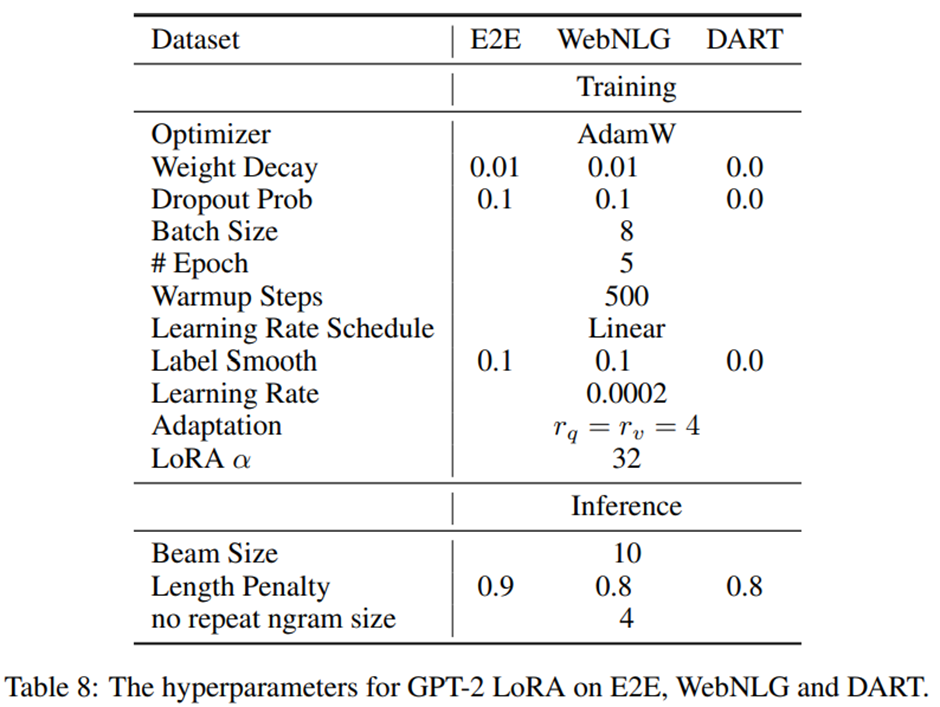
하이퍼파라미터 목록.
6 Understanding the Low-Rank Updates
LoRA의 실증적 우위 확인. -> 다운스트림 작업에서 학습된 저랭크 적응이 어떤 특성을 가지는지 더 깊이 설명. 저랭크 구조는 여러 실험을 병렬로 수행할 수 있게 해 하드웨어 진입 장벽을 낮추고, 업데이트 가중치가 사전 학습된 가중치와 어떻게 상관되어 있는지를 더 잘 해석할 수 있게 해줌.
분석 질문: 1) 파라미터 예산이 제한된 상황에서, 다운스트림 성능을 극대화하기 위해 사전 학습된 Transformer의 어떤 가중치 행렬 부분집합을 적응시켜야 하는가? 2) “최적의” 적응 행렬 ΔW는 실제로 랭크 결손(rank-deficient)인가? 그렇다면 실무에서 사용하기에 적절한 랭크는 얼마인가? 3) ΔW와 W 사이에는 어떤 관계가 있는가? ΔW는 W와 높은 상관관계를 가지는가? ΔW의 크기는 W에 비해 얼마나 큰가?
6.1 Which Weight Matrices in Transformer Should We Apply LoRA to?
self-attention 모듈에 포함된 가중치 행렬만 고려. GPT-3에서 약 1800만 개(약 35MB)에 해당하는 파라미터 예산을 설정. -> 96개 모든 레이어에 대해 하나의 가중치 유형만 적응시키는 경우 r = 8, 두 가지 유형을 적응시키는 경우 r = 4.
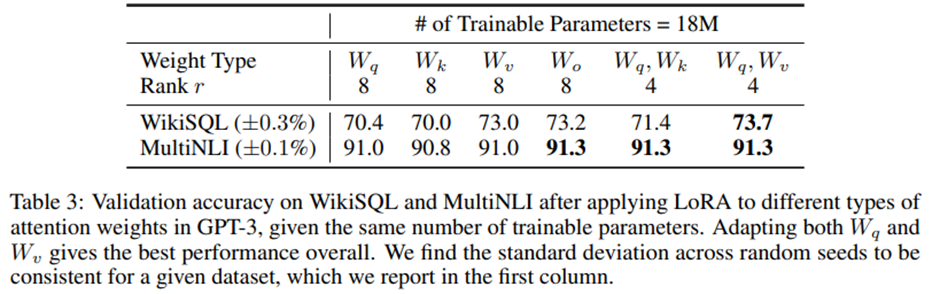
모든 파라미터를 ΔW_q 또는 ΔW_k에만 할당하면 성능이 유의미하게 낮아지고, W_q,W_v를 모두 적응하는 경우 가장 좋은 결과. -> 랭크가 4에 불과해도 ΔW에 충분한 정보 담을 수 있고, 더 큰 랭크로 단일 유형의 가중치만 적응시키는 것보다 여러 가중치 행렬을 함께 적응시키는 편이 더 바람직함.
6.2 What is the Optimal Rank r for LoRA?
랭크 r이 모델 성능에 미치는 영향. 이전 실험에서 가장 좋은 성능 보인 W_q,W_v 모드 적응하는 설정, 비교를 위해 W_q만 적응하는 경우도 고려.
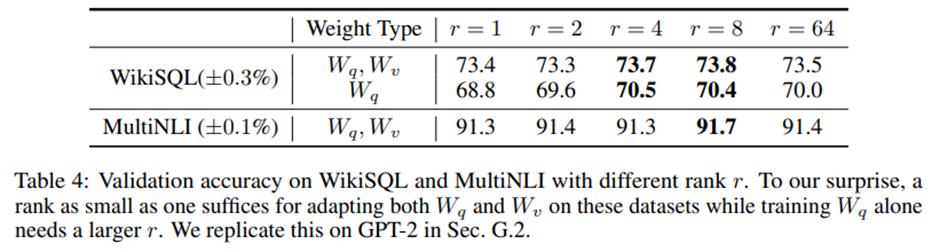
매우 작은 r에서도 LoRA가 이미 경쟁력 있는 성능 보임(W_(q+v) 가 W_q 단독보다 좋음). -> 업데이트 행렬 ΔW가 매우 작은 “내재 랭크(intrinsic rank)”를 가질 수 있음. -> 추가 뒷받침 위해 서로 다른 r 선택과 서로 다른 무작위 시드로 학습된 부분공간(subspace)들 사이의 겹침 정도 확인. r을 증가시켜도 의미 있는 새로운 부분공간을 더 포괄하지는 않음. -> 저랭크 적응 행렬만으로도 충분.
Subspace similarity between different r
동일한 사전 학습 모델을 사용해 랭크 r = 8과 r = 64로 학습된 적응 행렬 A(r=8),A(r=64). 특이값 분해를 수행해서 right-singular unitary 행렬 U(A(r=8) ),U(A(r=64) ) 얻음. U(A(r=8) )에서 상위 i개의 특이 벡터가 span하는 부분공간 (1≤ I ≤8) 중 얼마나 많은 부분이 U(A(r=64) )에서 상위 j개의 특이 벡터가 span하는 부분공간 (1 ≤ j ≤ 64) 에 포함되는가? -> Grassmann 거리 기반의 정규화된 부분공간 유사도 측정. 형식적인 논의는 부록 F.
F Measuring Similarity Between Subspaces
두 개의 열 정규직교(column-orthonormal) 행렬 U_A^i∈ R^(d×i)와 U_B^j∈R^(d×j) 사이의 부분공간 유사도를 측정하기 위해 ϕ(A,B,i,j)=ψ(U_A^i,U_B^j )=(|(|U_A^(i⊺) U_B^j |)|_F^2)/(min{i,j}) 라는 척도 사용. U_A^i,U_B^j 는 각각 행렬 A, B의 left singular matrix에서 열들을 취해 얻은 것. -> 이 유사도가 부분공간 간 거리를 측정하는 표준적인 Projection Metric의 단순한 역(reverse) 형태임.
U_A^(i⊺) 〖,U〗_B^j의 특이값을 σ_1,σ_2,…,σ_p. P = min{I, j}.
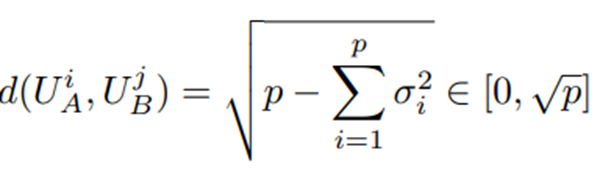
잘 알려진 Projection Metric의 정의.
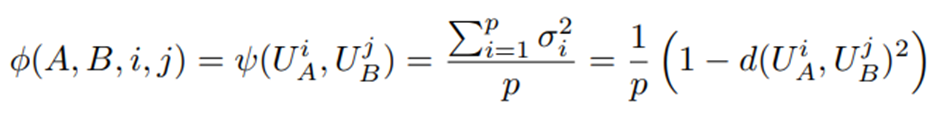
본 논문에서 사용하는 유사도 정의. 이 유사도는 만약 U_A^i와 U_B^j가 동일한 column span을 공유한다면 ϕ(A,B,i,j)=1. 만약 두 부분공간이 완전히 직교한다면 ϕ(A,B,i,j)=0. 그 외에는 0과 1 사이의 값.
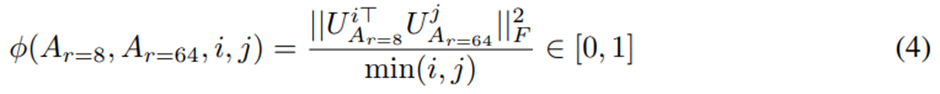
U(A(r=8))^i는 U(A(r=8) )의 상위 i개 특이 벡터에 해당하는 열. ϕ(⋅)의 범위는 [0, 1], 1은 부분공간이 완전히 겹침, 0은 완전히 분리됨.
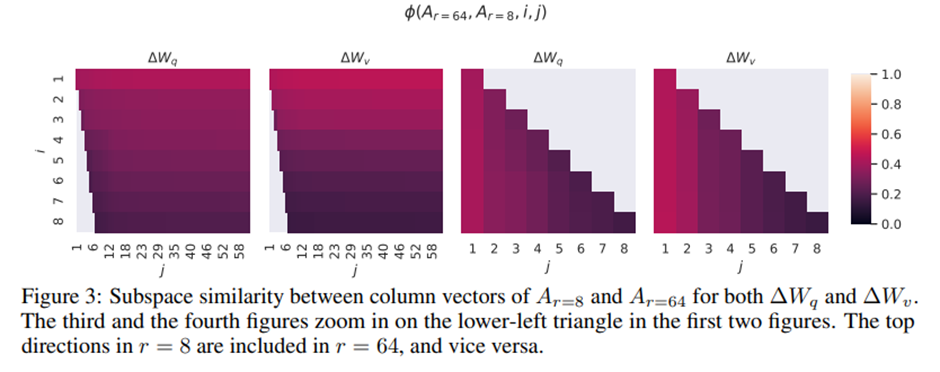
I와 j를 변화시킬 때 ϕ가 어떻게 변하는지. 96개 레이어 중 48번째 레이어만 살핌. G.1절: 다른 레이어들에서도 동일한 결론.
G Additional Experiments on Low-Rank Matrices
G.1 Correlation between LoRA Modules
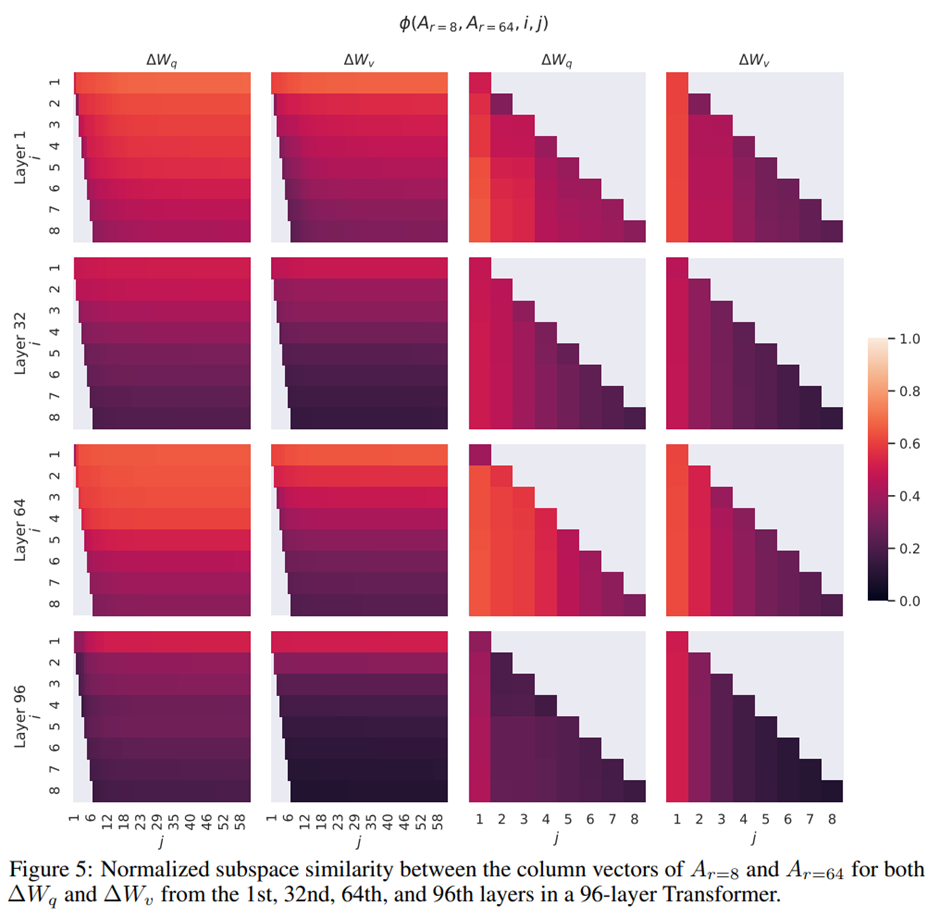
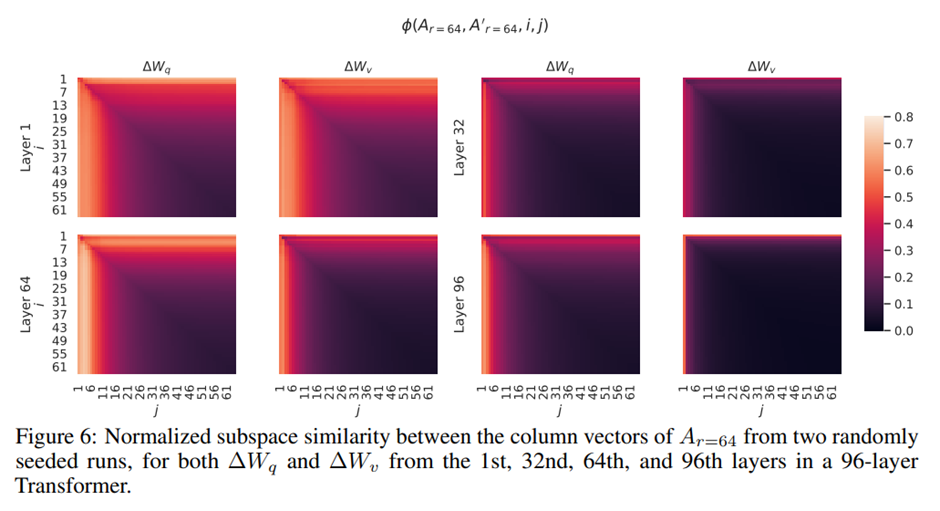
그림 3과 그림 4에서 제시된 결과가 다른 레이어들로 어떻게 일반화되는지는 그림 5와 그림 6 참고.
A(r=8),A(r=64)사이에서 최상위 특이 벡터에 해당하는 방향들은 상당히 많이 겹치지만 나머지는 그렇지 않음. -> A(r=8)의 ΔW_v (resp.ΔW_q)와 A(r=64)의 ΔW_v (resp.ΔW_q)는 정규화된 유사도가 0.5를 초과하는 1차원 부분공간 공유 -> GPT-3의 다운스트림 작업에서 r = 1이 상당히 잘 작동하는 이유.
최상위 특이 벡터는 가장 유용, 나머지는 학습 과정에서 누적된 대부분 무작위적인 잡음을 포함하고 있을 가능성 -> 적응 행렬은 실제로 매우 낮은 랭크를 가질 수 있음.
Subspace similarity between different random seeds
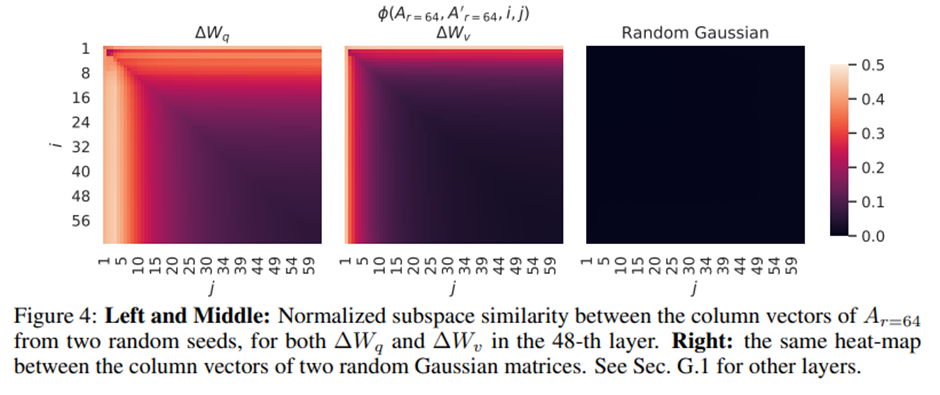
r = 64로 학습된 두 개의 서로 다른 무작위 시드 실행 결과 사이의 정규화된 부분공간 유사도. ΔW_q는 ΔW_v보다 보다 더 높은 intrinsic rank -> 두 실행 모두에서 ΔW_q에 대해 더 많은 공통적인 특이값 방향이 학습되었기 때문. 표 4에서의 실증적 관찰과도 일치.
두 개의 무작위 가우시안 행렬 사이의 부분공간 유사도 -> 두 행렬은 서로 어떤 공통된 특이값 방향도 공유하지 않음.
6.3 How Does the Adaptation Matrix ∆W Compare to W?
ΔW와 W 사이의 관계를 추가로 조사. ΔW는 W와 높은 상관관계를 가지는가? 수학적으로, ΔW는 대부분 W의 상위 특이 방향들 안에 포함되어 있는가? ΔW는 W의 해당 방향들과 비교했을 때 얼마나 큰가? -> 사전 학습된 언어 모델을 적응시키는 근본적인 메커니즘을 이해하는 데 도움.
ΔW의 좌우 특이 벡터 행렬을 각각 U와 V라고 할 때 U⊺WV⊺ 계산함으로써 W를 ΔW의 r차원 부분공간으로 projection. -> ||U⊺W_q V⊺||_F와 |(|W|)|_F 사이 프로베니우스 노름 비교. 비교 대상으로 U와 V를 W의 상위 r개 특이 벡터 또는 무작위 행렬의 특이 벡터로 대체했을 때의 ||U⊺W_q V⊺||_F도 함께 계산.
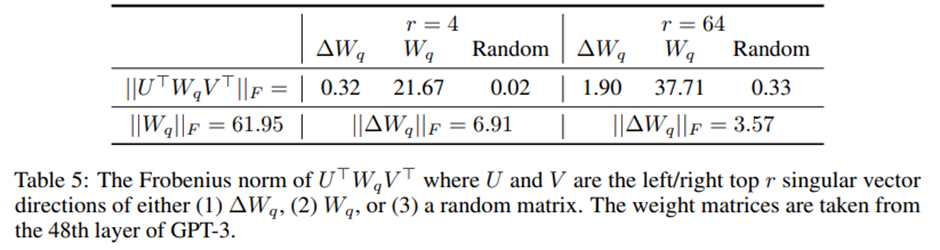
1) ΔW는 무작위 행렬에 비해 W와 더 강한 상관관계 -> ΔW가 W에 이미 존재하는 일부 특징들을 증폭시킴. 2) ΔW는 W의 상위 특이 방향들을 그대로 반복하는 것이 아니라, W에서는 강조되지 않았던 방향들만을 증폭. 3) 이러한 증폭 계수는 상당히 크며, r = 4일 때 21.5 ≈ 6.91/0.32에 해당. r = 64에서 증폭 계수가 더 작은 이유에 대해서는 G.4절.
G Additional Experiments on Low-Rank Matrices
G.4 Amplification Factor
Feature amplification factor는 |(|ΔW|)|_F/(||U⊺WV⊺||_F ) 의 비율로 정의할 수 있음. U, V는 ΔW의 SVD에서 얻어진 좌우 특이행렬.
ΔW가 주로 작업 특화적인 방향들을 담고 있을 때 이 값은 그러한 방향들이 ΔW\Delta WΔW에 의해 얼마나 크게 증폭되는지 측정. r=4인 경우 이 증폭 계수는 최대 20. -> 각 레이어마다 사전 학습된 모델 WWW가 가지는 전체 특징 공간 중에서 (일반적으로) 네 개 정도의 특징 방향이 다운스트림 작업에서 보고된 성능을 달성하기 위해 약 20배라는 매우 큰 계수로 증폭될 필요가 있음. 서로 다른 다운스트림 작업마다 증폭되어야 하는 특징 방향의 집합은 매우 다를 것으로 예상.
반면 r = 64인 경우에는 이 증폭 계수가 약 2 정도에 불과함. -> r = 64에서 학습된 ΔW의 대부분의 방향들이 크게 증폭되지 않음. 모델 적응을 위해 필요한 task-specific directions을 표현하는 데 요구되는 내재 랭크가 낮다는 점을 다시 한 번 뒷받침. R = 4에 해당하는 ΔW\Delta WΔW의 방향들은 훨씬 더 큰 계수인 20으로 증폭됨.
W_q 에서 더 많은 상위 특이 방향들을 포함시킬수록 상관관계가 어떻게 변화하는지를 G.3절에서 시각화로. -> 저랭크 적응 행렬이 일반적인 사전 학습 모델에서는 학습되었지만 강조되지는 않았던, 특정 다운스트림 작업에 중요한 특징들을 증폭시킬 가능성.
G Additional Experiments on Low-Rank Matrices
G.3 Correlation between W and ∆W

r을 변화시켰을 때 W와 ΔW 사이의 정규화된 부분공간 유사도. ΔW는 W의 상위 특이 방향들을 포함하고 있지 않음 -> ΔW의 상위 4개 방향과 W의 상위 10% 방향들 사이의 유사도가 0.2를 거의 넘지 않기 때문. ΔW가 W에서는 강조되지 않았던 task-specific 방향들을 담고 있다는 증거.
7 Conclusion and Future Work
LoRA 장점: 추론 지연 없음, 시퀀스 길이 감소 없음, 빠른 작업 전환 가능, 제안된 원칙들은 밀집 레이어를 가진 모든 신경망에 일반적으로 적용 가능.
향후 연구: 일부 레이어만을 튜닝하거나 적대적 학습을 추가하는 방향, ΔW의 랭크 결손 특성은 W 역시 랭크 결손일 수 있음.
