2024년 8월 8일, Stanford PACS 워킹페이퍼
Abstract
To evaluate whether large language models (LLMs) can be leveraged to predict the results of social science experiments, we built an archive of 70 pre-registered, nationally representative, survey experiments conducted in the United States, involving 476 experimental treatment effects and 105,165 participants. We prompted an advanced, publicly-available LLM (GPT-4) to simulate how representative samples of Americans would respond to the stimuli from these experiments. Predictions derived from simulated responses correlate strikingly with actual treatment effects (r = 0.85), equaling or surpassing the predictive accuracy of human forecasters. Accuracy remained high for unpublished studies that could not appear in the model’s training data (r = 0.90). We further assessed predictive accuracy across demographic subgroups, various disciplines, and in nine recent megastudies featuring an additional 346 treatment effects. Together, our results suggest LLMs can augment experimental methods in science and practice, but also highlight important limitations and risks of misuse.
Introduction
이 논문은 LLM이 행동 실험의 결과를 정확하게 예측할 수 있는지 탐구했다. 공개적으로 사용할 수 있는 LLM인 GPT-4가 실험 효과를 예측하는 데 사용할 수 있는지 실험했다. GPT-4가 인구통계학적으로 다양한 미국인 표본의 응답을 simulate 할 수 있도록 프롬프트를 작성했으며, LLM이 예측한 실험 효과 크기 응답 평균을 실제 실험과 비교했다.
사회과학 실험 결과를 높은 정확도로 예측할 수 있는 능력은 기초, 응용 사회과학에 상당한 영향을 끼칠 수 있다. 실제 사람이 진행하는 예측 및 연구는 높은 비용이 들고 시간이 오래 걸리지만, LLM 도구는 예측을 낮은 비용으로 가능하게 한다.
기존 연구는 설문 응답 시뮬레이션에 그쳤지만, 이 논문은 실험 효과를 예측하는 데 집중했다. 이는 인간 응답을 시뮬레이션하는 것뿐 아니라 각 응답들이 미묘하게 다른 환경에서 어떻게 나타나는지를 시뮬레이션해야 하기 때문에 더 어렵다.
LLM 예측에는 한계점이 있다. 모델의 훈련 데이터에서 적게 나타난 그룹에 대해서는 실험 효과 크기 예측에서 낮은 정확도를 보였고, 유해한 정보를 잘 식별하여 악용할 가능성이 있다.
Study Overview
연구팀은 2016년부터 2022년까지 TESS에서 진행된 50개의 설문 실험과 복제 프로젝트 20개를 수집하고, 각 실험에 대해 일관된 방식으로 재분석했다.
이 테스트 아카이브는 4가지의 강점을 가진다.
-
실험은 모두 높은 퀄리티이다: 모두 통계적으로 정확하며, 사전등록 되었으며, 동료 리뷰를 거쳤으며, 오픈 소스들을 사용했다.
-
아카이브는 범위가 넓고 다양하다.
-
다른 분석에 의존하지 않고, 일관된 분석 접근을 통해 실험 처치 효과를 예측했다.
-
GPT-4가 훈련하지 않은 데이터를 포함했다.
한계점은 다음과 같다.
-
아카이브는 미국 인구에만 대표성을 띈다.
-
학문 분야를 모두 포함하지는 않으며, 텍스트 기반 실험만 포함하고 행동 기반, 이미지나 비디오 자극은 제외되었다.
이를 보완하기 위해 보조 데이터셋(mega-study)을 분석했다.
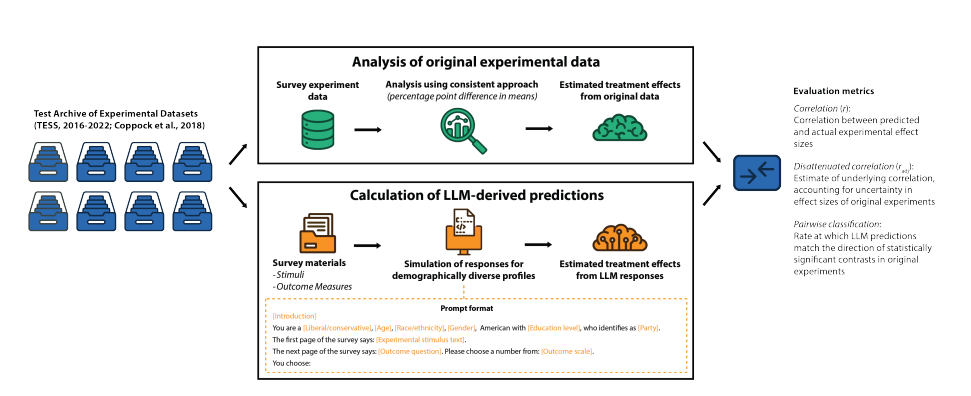
LLM을 프롬프트할 때 (a)안내 메시지, (b)특정 인구 프로필을 모방하도록 하고, (c)텍스트 형태의 실험 자극을 제공하고, (d)결과 변수 문항을 제공했다. 앙상블 method를 통해 다양한 프롬프트 형식의 특이점을 줄였다.
연구 당 하나의 조건과 종속변수를 무작위로 선택했고, 실제 효과 크기와 상관계수를 16번 반복 측정했다. 주돤 정확도 측정 방법은 r 이며, 보정 상관계수도 함께 측정했다.
Results
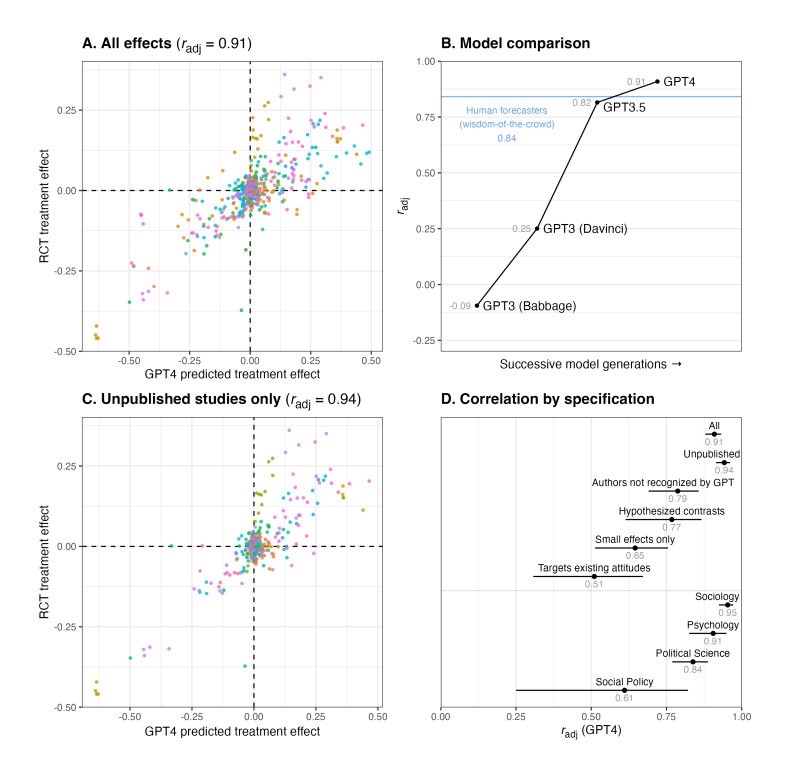
GPT-4가 예측한 실험 효과 크기와 실제 결과는 매우 높은 상관관계(r = 0.85, radj = 0.91)를 보였다. 실제로 유의미했던 실험 비교 중 90%는 방향도 일치했다. GPT-3 보다 GPT-4 에서 LLM의 정확도가 향상되었고, 많은 프롬프트를 이용할 때 정확도가 증가했다. 훈련 데이터 이후에 발표된 실험의 예측 정확도(r = 0.90)가 오히려 발표된 실험(r = 0.74)보다 높았으며, 저자를 예측하지 못한 실험에서도 높은 상관을 보였다. 2,659명의 일반 미국인을 대상으로 동일한 예측을 실시했을 때, GPT-4는 인간 예측자보다 높은 정확도를 보였다.
회귀분석 결과, 인간 예측과 GPT-4 예측은 서로 독립적인 정보를 제공하고 있으며, 둘을 평균내면 정확도(r = 0.88)가 더 높아진다. 따라서 인간과 LLM의 협업이 효과적일 수 있다.
GPT-4는 실제보다 더 크게 예측하는 경향이 있어, RMSE가 10.9pp로 인간 예측자(8.4pp)보다 높았다. 이를 조정하기 위해 예측값에 0.56을 곱해야 한다.
Assessing the scope of LLM-derived predictions of experimental effects
-
Assessing biases in LLM-derived predictions
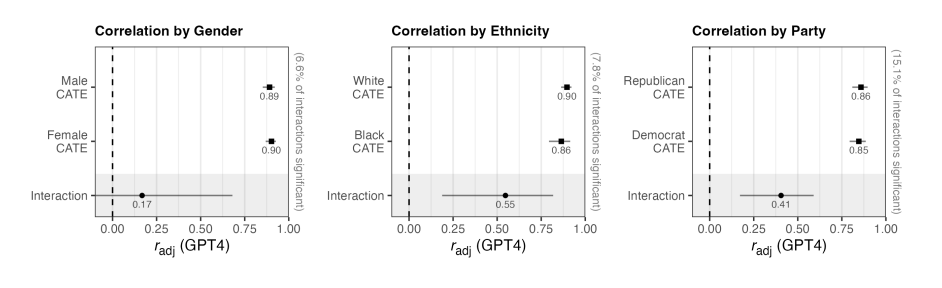
본 연구는 인구통계 프로필별로 LLM을 프롬프트하여, 실제 해당 하위집단의 실험 결과와 LLM 예측값을 비교함으로써 예측편향이 있는지 검증했다.GPT-4는 여성(r = 0.80), 남성(r = 0.72), 흑인(r = 0.62), 백인(r = 0.85), 민주당원(r = 0.69), 공화당원(r = 0.74) 등에 대해 전반적으로 높은 예측 정확도를 보였다. 집단 간 예측 정확도 차이가 거의 없는 이유는 원래 실험 효과 자체가 집단 간에 크게 다르지 않았기 때문이다. LLM은 개별 특성과 실험 간 interaction effect 를 예측할 때는 정확도가 낮았다.
-
Assessing predictions for survey and field intervention studies
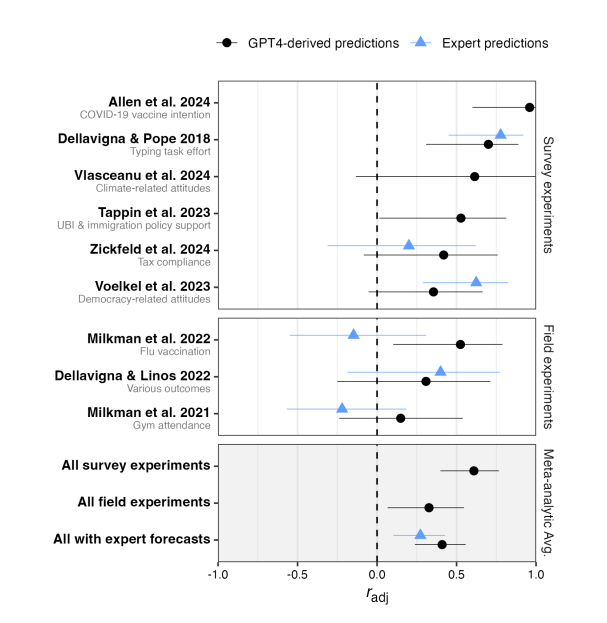
정책 결정자들은 종종 전문 예측 도구에 의존한다. 이러한 실험을 LLM을 활용해 저비용, 고속의 예측 도구로 활용한다면 유용할 수 있다.9개의 mega-study를 추가로 분석했다. 총 346개의 실험 효과, 180만 명 이상의 참여자가 포함되어 있다. 이러한 메가스터디는 같은 방향의 효과를 유도하고, 차이가 작아 예측이 어렵다. 게다가, 텍스트가 아닌 자극을 사용하여 LLM에 프롬프트하기 어려웠다.
GPT-4는 설문 기반 실험에서 중간 정도의 상관(r = 0.47, radj = 0.61)을 보였으며, 현장 실험에서는 낮은 정확도(r = 0.27, radj = 0.33)를 보였다. 또한, 텍스트 기반 자극 실험에서 더 정확했고, 비텍스트 기반 실험에서는 예측 정확도가 낮았다. 6개의 mega-study는 전문가 예측도 함께 수집되었는데, LLM은 69% 방향이 일치했으며, 전문가 예측은 66%였다.
-
Assessing risks of harmful use
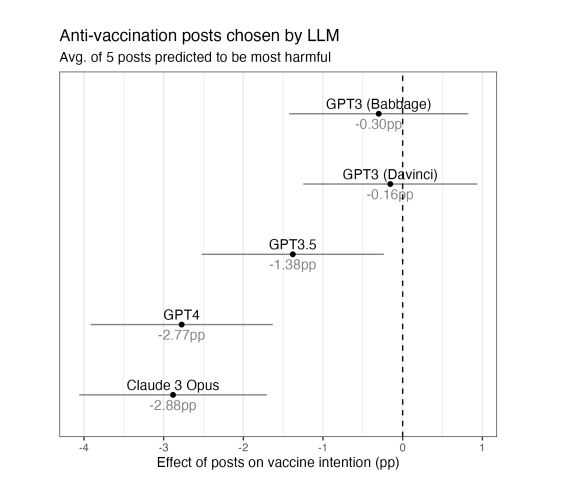
LLM은 유해한 콘텐츠를 악용할 가능성이 있다. first-order 가드레일은 이를 막기에 불충분하다.코로나 19와 관련해 예측값과 실제 효과 간 의미 있는 상관관계(r = 0.49, radj = 0.96)를 보였다. GPT-4가 유해하다고 판단한 5개의 게시글은 백신 의도를 2.77%p 낮추는 효과가 있었다. 기업은 second-order 가드레일 예외를 부여받아야 한다.
