Using LLMs for Market Research James Brand Ayelet Israeli Donald Ngwe July 29, 2024, published at ssrn
초록 (Abstract)
대규모 언어 모델(LLMs)은 프로그래밍, 글쓰기, 그리고 빠른 텍스트 생성을 통해 이익을 얻는 많은 다른 과정들에서 노동을 보조하는 도구로 빠르게 인기를 얻었다. 본 논문에서 우리는 소비자 선호를 이해하려는 연구자와 실무자를 위해 LLM의 활용과 이점을 탐구한다. 우리는 LLM 응답의 분포적 특성에 초점을 맞추며, Generative Pre-trained Transformer 3.5 Turbo(GPT-3.5 Turbo) 모델을 사용해 각 설문 질문에 대해 수십 개의 응답을 생성한다. 우리의 접근 방식을 설명하고 평가하기 위해 두 가지 결과를 제시한다. 첫째, GPT 응답에서 도출된 제품 및 기능에 대한 지불의사 추정치가 현실적이며 인간 연구 결과와 비교 가능하다는 것을 보여준다. 둘째, 우리는 시장 조사자가 이전의 유사 맥락의 설문 데이터를 파인튜닝을 통해 GPT 응답에 통합하여 GPT의 응답을 개선하는 실용적 방법을 제시한다. 이 방법은 기존 제품 기능뿐만 아니라 새로운 제품 기능에 대해서도 GPT 응답과 인간 응답 간의 정합성을 향상시킨다. 그러나 새로운 제품 범주나 고객 세그먼트 간의 차이에 대해서는 유사한 개선을 발견하지 못했다.
1 서론
LLM은 코드 작성 보조 도구(예: Github Copilot), 검색 도구(예: Bing, Gemini)와 같은 여러 잘 알려진 AI 보강 솔루션을 구동하며, 일부 연구에서는 투표(Argyle et al., 2022)와 경제 실험(Horton, 2023) 등 제한적인 실제 행동을 복제할 수 있음.
본 논문에서는 LLM(우리의 경우 주로 GPT-3.5 Turbo 모델, 이하 “GPT”)을 시장 조사 도구로 어떻게 활용할 수 있는지를 탐구함. GPT 학습 데이터에는 제품 리뷰와 소비자들이 구매한 제품에 대해 논의하는 다양한 온라인 포럼의 기여도 포함될 수 있음. 우리는 GPT가 시장 조사 설문에 제공하는 응답이 부분적으로는 학습 데이터 속 소비자들이 동일한 질문에 했을 법한 응답을 반영할 것이라고 가설을 세움.
기존의 시장 조사 도구인 컨조인트 분석(conjoint studies), 포커스 그룹, 독점적 데이터 세트는 비용이 많이 듬. LLM 사용하면 빠르고 저렴하게 할 수 있음.
GPT의 응답으로부터 전형적인 소비자 설문 질문에 대해 무엇을 배울 수 있을지 명확하지 않음. 예를 들어, GPT의 학습 데이터에 포함되었을 가능성이 있는 제품 리뷰는 고객이 제품에 대해 표명한 선호에 대한 정보를 드러낼 수 있지만, 가격이나 의사결정자(예: 소득이나 인구통계학적 특성)의 다른 핵심 속성을 항상 언급하지는 않을 수 있음. GPT가 각각의 개별 질문에 대해 합리적인 응답을 생성할 수 있다고 하더라도, 그 응답들이 서로 다른 질문들 간에서 소비자들이 그러하듯 내부적으로 일관성을 가질 수 있을지 초점을 맞춤.
GPT의 학습 데이터셋이 이 맥락에서 유용한 응답을 생성할 수 있을지도 불분명함. 문헌에서는 재화 묶음에 대한 진술적 선호를 이끌어내는 고객 설문조사와, 실제 선택을 통해 고객 선호가 드러나는 실제 수요 데이터 사이의 차이를 문서화함(예: Kroes and Sheldon, 1988; Johnston et al., 2017). GPT의 학습 데이터셋은 이 두 가지 측면을 모두 포함함. 이러한 학습 데이터의 특성과, LLM이 프롬프트에 어떻게 응답하는지가 불투명하다는 점이 결합되어, LLM이 시장 조사에 얼마나 유용한지를 탐구하도록 동기를 부여함.
GPT의 효과성을 정량화하기 위해, 우리의 실증 분석은 시장 조사자가 실제로 직면할 수 있는 문제들을 근사하려함. 시장 조사는 고객의 선호에 대해 무언가를 배우는 데 사용되며, 이는 기존 제품 및 기능, 기존 제품의 새로운 기능, 혹은 완전히 새로운 제품 범주일 수 있음. 또한 마케터들은 일반적인 시장 고객의 선호뿐만 아니라 자신들이 목표로 하는 시장 세그먼트의 선호에도 관심을 가짐. 이러한 사용 사례를 염두에 두고, 우리는 가상의 시장 조사자가 가질 수 있는 정보 집합을 분리하고 각 경우에 GPT의 성능을 탐구할 수 있도록 다섯 가지 인간 참여자 설문을 설계함. 우리는 먼저 연구자가 제품 범주에 대한 사전 정보가 전혀 없는 상황에서 GPT가 소비자 선호를 시뮬레이션하는 능력을 연구하고, 이후 인간 설문에서 얻은 제품과 고객에 대한 다양한 수준과 형태의 정보를 추가함. 이러한 연구들은 시장 조사자가 동일하거나 유사한 제품 시장과 고객 세그먼트에 대한 이전 연구를 이용해 GPT를 보완하는 단계를 시뮬레이션함.
도출된 지불의사(WTP) 추정치는 규모와 분포 모두에서 현실적임. 특히, 우리는 선호 추정을 위한 컨조인트 유사 접근 방식이 Fong et al.(2023)이 수행한 실제 소비자 조사 및 우리가 실시한 추가적인 인간 설문조사 결과와 유사한 결과를 산출한다는 것을 보여줌. 더욱이, 인간 설문 데이터를 GPT에 보강하는 것이 GPT가 해당 설문과 일관되게 응답할 수 있는 능력을 향상시킬 뿐만 아니라, 새로운 제품 기능에 대한 별도의 인간 설문조사와도 일치하게 만든다는 것을 발견함. 다만 이 접근 방식을 다른 제품 범주에 적용하는 것에는 실패함. 우리는 마케터들이 인간을 대체하기 위해 GPT를 사용할 것을 제안하지는 않지만, 특히 마케터들이 관심 있는 집단의 설문을 이미 가지고 있는 경우, GPT는 새로운 기능 아이디어를 인간에게 시험하기 전에 탐색하고 좁혀 나가는 데 도움을 줄 수 있음.
그러나 우리의 조사에서는 GPT가 인구통계학적 그룹 간 이질적 선호를 의미 있게 반영하지 못함. 현재의 최첨단 GPT 모델은 평균 인구의 WTP를 더 잘 반영함.
온라인 부록 A에서 우리는 접근 방식의 한계와 연구를 수행하는 동안 직면한 문제들에 대한 몇 가지 지침을 제공함.
1.1 기존 문헌 (Existing Literature)
우리 연구와 가장 관련 깊은 것은 Horton(2023)으로, 다양한 LLM이 고전적인 행동경제학 실험에 직관과 경험에 부합하는 방식으로 응답함을 보여줌. Horton은 진술적 선호(stated preferences)와 드러난 선호(revealed preferences)를 구분하며, LLM이 학습된 말뭉치가 드러난 선호와 더 유사할 가능성이 크다고 결론지음. 그는 GPT를 난수 생성기와 비교하는데, 우리는 LLM 응답의 분포에 초점을 둠. 이후 다양한 분야의 후속 연구들(e.g., Bisbee et al., 2024; Dominguez-Olmedo et al., 2023; Goli & Singh, 2024)은 합성 설문 응답자로 LLM을 사용하는 데 있어 한계점을 검토하며, 응답의 질과 신뢰성에서의 문제를 강조하고 이를 완화하기 위한 해결책을 제안함. 우리는 LLM이 고객 선호를 추출하는 능력을 평가함으로써 이 문헌에 기여함.
개념적으로 우리 연구와 가장 가까운 논문은 Netzer et al.(2012)로, 이들은 텍스트에서 고객 선호를 추출함. Timoshenko와 Hauser(2019), 그리고 Burnap et al.(2023)은 마케팅 관리자가 ML/AI 접근법을 이용해 집약적이고 수작업적이며 비용이 많이 드는 과정을 효율적으로 개선할 수 있음을 보여줌. 생성형 AI 맥락에서, Li et al.(2024)는 LLM에 브랜드 유사성에 대해 질문하여 지각 맵(perceptual maps)을 구축하는 방법을 보여주며, 그 응답이 인간의 것과 유사함을 입증함. 우리는 광범위하게 이용 가능한 생성형 AI 도구들이 소비자 선호를 추출할 수 있음을 추가로 보여줌으로써 이 문헌에 기여함.
2 연구 설계 (Research Design)
GPT를 인간 응답을 시뮬레이션하는 도구로 시장 조사에 사용하는 방법에 초점을 맞춰 우리의 연구 설계를 개괄함.
2.1 GPT
GPT는 OpenAI에 의해 개발되어 2020년에 공개되었으며, OpenAI는 일반적인 프로그래밍 언어에서 빠르게 다수의 프롬프트를 제출하고 각 프롬프트에 대해 여러 응답을 동시에 받을 수 있도록 하는 공개 API를 유지하고 있음. 우리는 LLM 응답의 분포적 특성에 초점을 맞춤.
우리는 두 가지 이유로 GPT-3.5 Turbo(정식 명칭은 OpenAI의 “gpt-3.5-turbo-0125” 모델)를 주요 연구 모델로 사용함. 첫째, 이는 OpenAI가 파인튜닝을 위해 권장한 최신 모델이었으며, 우리는 이 기능을 탐구하는 데 관심이 있었고, 모든 결과가 동일한 모델에 기반하도록 하고자 함. 둘째, GPT-3.5 Turbo는 OpenAI의 가장 비용 효율적인 고급 모델임. 우리의 방법론이 GPT 모델 선택에 얼마나 강건한지를 검토하기 위해, 우리는 3.1.3절에서 OpenAI, Meta, Anthropic의 다양한 모델을 사용해 우리의 연구 중 하나를 복제함.
2.2 인간 응답 시뮬레이터로서의 GPT
GPT 응답에 대한 우리의 가설은 GPT(또는 다른 LLM)에게 모의 시장 조사 연구에서 제품 간 선택을 하도록 유도하면, 그 응답은 학습 데이터에 포함된 소비자들로부터 학습된 응답 분포를 반영한다는 것임. GPT가 인간이 어떻게 반응하는지를 정확하게 예측할 수 있는 모델이라면, 그 모델은 자신이 대표하려는 인간의 일부 선호 역시 드러낼 수밖에 없다는 가정에 의거함. GPT를 설문조사에 대한 실제 소비자 응답을 예측하는 도구로 취급하는 것임.
최근 연구들 역시 GPT를 인간 응답 시뮬레이션 도구로 사용하는 데 있어 초기 성공을 보여줌. Horton(2023)은 GPT-3를 사용해 경제 실험을 수행했고, Argyle et al.(2022)은 정치적 선호 샘플을 시뮬레이션했으며, Aher et al.(2022)은 잘 알려진 밀그램 전기 충격 실험을 포함한 심리학 연구들을 시뮬레이션함. 시장 조사는 고객이 자신의 선호에 대해 말하는 것뿐만 아니라, 경제학적 모델을 이용해 데이터로 추정했을 때 그들의 선택이 드러내는 근본적인 선호까지도 다룸. 후자의 분석은 다양한 맥락의 여러 질문을 인간에게 제시하고, 인간이 대체로 내부적으로 일관되게 행동할 것을 요구함. 따라서 우리는 GPT가 마케팅 질문에 대해 인간과 질적으로 유사한 응답을 하리라 기대하지만, GPT의 시장 조사 설문 응답이 실제적이고 인간 데이터와 일관된 선호 추정을 제공할 수 있을지에 대한 핵심 질문은 여전히 남아 있음.
2.3 시장 조사를 위한 GPT 질의
우리의 연구 설계는 관심 있는 고객이나 제품을 직접 다루는 새로운 인간 설문조사를 수행할 수는 없지만 과거 설문에서 관련 데이터를 가진 시장 조사자가 소비자 선호를 추정해야 하는 문제를 고려함. 우리는 이 맥락에서 GPT가 연구자를 도울 수 있는 두 가지 방법을 상정함. 첫째, 연구자는 GPT를 직접 조사하고, 그 데이터를 다른 인간 연구를 보완하는 휴리스틱한 자료로 사용할 수 있음. 둘째, 연구자는 이용 가능한 데이터를 통해 GPT의 지식을 보강하고 원하는 목표 집단에 GPT의 응답을 집중시킬 수 있음.
우리는 제품 속성에 대한 지불의사(WTP) 추정을 특정 문제로 삼음. 우리가 연구하는 속성에 대한 WTP를 계산하기 위해, 우리는 컨조인트 분석 패러다임을 이용해 속성과 가격에 대한 선호를 도출함. 우리가 제품 단위가 아닌 속성 단위의 WTP에 집중하는 또 다른 이유는, 제품 단위의 WTP와 달리 속성 단위의 WTP는 제품 페이지나 리뷰에 직접적으로 진술될 가능성이 훨씬 낮아 GPT의 말뭉치에 포함될 가능성이 낮기 때문임.
우리는 선호를 조사하기 위해 여러 접근 방식을 시험함. 제품 속성의 WTP 수치를 정량화하는 것은 인간에게 어려움. 우리는 GPT를 인간 응답 시뮬레이터로 사용하고 있으며, 따라서 인간에게 적용되는 간접 추출 방법이 GPT에서도 가장 성공적일 것으로 예상함. 그럼에도 불구하고 컨조인트 분석에 집중하기 전에, 우리는 GPT가 속성 WTP를 직접 제공하거나 온라인 부록 C에 설명된 비교적 단순한 간접 방법을 통해 제공할 수 있는지를 테스트함. 우리는 이러한 접근 방식이 GPT로부터 선호를 이끌어내는 데 있어 컨조인트보다 열등하다는 결론에 도달했으며, 따라서 본 논문의 나머지 부분에서는 컨조인트 분석을 사용함.
GPT가 의미 있고 현실적인 WTP를 제공할 수 있는 능력을 평가하기 위해, 우리는 GPT와 인간 모두에게 (거의) 동일한 질문을 제시하여 응답을 수집함. 그런 다음 이러한 응답을 서로 비교하고, GPT가 소비자 이질성을 반영할 수 있는 능력을 검토함. 마지막으로, 기존 인간 설문을 GPT에 보강하는 것이 그 출력물을 개선할 수 있는지, 그렇다면 언제 그러한 효과가 나타나는지를 평가함.
2.3.1 기준선 인간 연구 (Baseline Human Studies)
GPT의 시장 조사 응용 능력을 시험하기 위해서는 GPT 출력과 비교할 수 있는 합리적인 기준선 응답이 필요함. 우리는 인간 설문을 마케터에게 가장 관련성이 크고 최선의 벤치마크로 활용함. 우리는 “진실” 대신 고객 선호에 대한 두 가지 기준선을 사용함. 첫째, 예비 연구로서 우리는 Fong et al.(2023)의 기존 연구를 사용함. 이들은 2020년 말 실제 컨조인트를 수행해 가정용 소비재에 대한 WTP를 추정했으며, 그 추정치가 시장 결과와 일치함을 확인함. 우리는 이 연구를 비교 기준으로 삼아 2023년 3월 당시 최신 GPT 모델(text-davinci-003)을 사용해 GPT 연구를 수행함. 중요한 점은, 그 모델의 학습 말뭉치는 학습 종료 시점 때문에 Fong et al.(2023)의 연구 결과를 포함할 수 없었다는 것임.
둘째, 예비 연구에서 고무적인 결과가 도출된 이후, 우리는 조사를 확장하기 위해 새로운 인간 컨조인트 설문을 수집함. 고객 하위 집단의 선호를 추정하고, 새로운 제품 기능을 연구하며, GPT를 파인튜닝하기 위함임. 이를 위해 우리는 치약, 노트북, 태블릿 세 가지 소비재 범주를 다루는 다섯 가지 새로운 인간 연구를 실시함. 세 가지 연구(1A, 2A, 2C)는 이미 존재하는 제품 기능을 포함했으며, 이는 GPT의 학습 말뭉치에 포함되었을 가능성이 큼. 두 가지 연구(1B, 2B)는 새로운 가상의 제품 기능을 포함함. 우리는 모든 연구를 GPT의 기준선 응답 평가에 사용했지만, 후자의 연구는 새로운 기능에 대해 GPT의 성능을 인간 벤치마크와 비교하기 위해, 파인튜닝을 적용했을 때와 적용하지 않았을 때 모두에서 사용함.
우리의 모든 연구는 표 1에 요약되어 있으며, 사용된 구체적인 속성 수준(attribute levels)은 표 2에 정리되어 있음. 각 연구에서 우리는 미국에 거주하는 만 18세 이상의 참여자 300명을 Prolific을 통해 모집함. 참여자들은 12개의 선택 과제에 응답했는데, 먼저 두 가지 제품 구성 중 선호하는 옵션을 선택하도록 요청받았고, 이어서 선택한 제품을 구매하고 싶은지 혹은 이번에는 아무것도 구매하지 않기를 원하는지를 표시하도록 요청받음. 연구 자료는 온라인 부록 D에서 확인할 수 있음.
2.3.2 GPT 기준선 선호 (Baseline GPT Preferences)
경험적 마케팅 및 산업조직 문헌의 많은 부분에서처럼, 우리는 상품 속성의 변화가 선택 확률과 시장 점유율에 미치는 영향을 연구하고자 함. 이는 보통 무작위로 추출된 많은 고객이나 시장으로부터 데이터를 필요로 함. GPT 응답의 분포를 생성하기 위해 우리는 모든 연구에서 GPT의 “temperature”를 기본값(1.0)으로 설정해 응답 간 변이를 극대화함.
각 연구에서 우리는 GPT에게 관심 있는 카테고리에서 무작위로 설문에 참여하도록 선택된 고객인 것처럼 설문 응답을 작성하도록 프롬프트를 제공함. 고객 속성(예: 연소득)을 명시하기도 함. 우리는 이 고객에게 구매를 고려할 두 가지 제품을 제시하고, 언제든 구매하지 않을 수도 있음을 상기시킴. 우리는 각 자유형식 텍스트 응답을 기록하고 파싱함. 이러한 프롬프트를 GPT에 수십 번 제출하고 응답을 집계해 관심 지표를 구축함. GPT 프롬프트에 대한 주요 학습 내용은 온라인 부록 A에서 논의하며, 프롬프트 엔지니어링과 최적화는 미래 연구로 남겨둠.
일반적인 컨조인트 연구에서는 구성 간 직교성을 확보하고 속성을 균형 있게 분배한 선택 세트를 생성해야 함. 연구 참가자들은 전체 구성 집합에서 2~3개의 제품을 비교하는 10~15개의 시나리오에 제시됨. GPT는 시간이나 복잡한 비교 수행 능력에 제한을 받지 않으므로, 우리는 각 속성 집합에 대해 전체 옵션을 생성하고 각 컨조인트 연구를 전수 설계(full-factorial design)로 만듦. 이 접근 방식을 사용해 우리는 치약, 노트북, 태블릿에 대해 GPT 기반 컨조인트 연구를 수행하여 인간 연구와 대응시킴(세부 사항은 표 1과 표 2 참조). 모든 연구에서 사용한 정확한 프롬프트와 기타 설계 세부 사항은 온라인 부록 E에 제공됨. 샘플 프롬프트는 부록 B에, 샘플 응답은 온라인 부록 F에 있음.
우리는 GPT 연구를 인간 연구와 최대한 유사하게 설계함. 예비 연구에서는 GPT 응답과 비교할 개별 수준의 인간 데이터가 없었기 때문에, 우리는 프롬프트에 고객 소득을 명시함(미국 인구조사의 중위 소득을 사용했으며, 이는 Fong et al.(2023) 샘플과 유사함). 단순화를 위해 우리는 브랜드, 가격, 불소 함량만 변형하고, 모든 프롬프트에서 “미백(whitening)”은 고정시키고, 두 개의 서로 다른 브랜드 중 선택하도록 함.
이후 GPT 기준선 연구에서는 GPT 프롬프트에서 고객 소득을 제거하여 더 일반적으로 만들었고, 브랜드 속성을 포함해 GPT에서 전수 요인 컨조인트를 실행함. 질의 횟수와 관련해서, 예비 연구에서는 각 세트에 대해 300개의 응답을 수집했지만, 본 연구에서는 150개만 수집했으며, 이후에는 GPT 응답이 더 작은 샘플 크기에서도 일관됨을 확인했기 때문에 50개만 수집함(세부 사항은 온라인 부록 G 참조).
2.3.3 선호의 이질성 탐구
고객 이질성에 관심 있는 시장 조사자들은 종종 인구통계, 행동 또는 기타 특성에 기반해 서로 다른 하위 집단의 설문 응답을 분석함. 우리는 인간 컨조인트 설문 끝에서 인구통계학적 특성을 수집함. 이 데이터를 사용해 서로 다른 고객 세그먼트를 구성하고, 이 그룹 간 WTP를 비교함. 그 후 GPT 프롬프트에 소득, 성별, 인종과 같은 관련 인구통계 특성을 포함시켜, 대응되는 하위 표본 고객 응답을 GPT로 시뮬레이션함. 우리는 특정 인간 세그먼트 응답이 암시하는 선호를 해당 GPT 세그먼트의 응답과 비교함.
각 인간 연구에서 우리는 성별, 연령, 인종/민족, 정치 성향, 가구 소득, 교육 수준에 대한 자기보고 정보를 수집함. 우리의 참여자 풀은 성별과 인종 면에서 미국 인구와 유사했지만, 일반 인구보다 더 젊고, 더 교육 수준이 높으며, 민주당 성향이 강하고, 소득은 더 낮은 편이었음. 세부 사항은 온라인 부록의 표 D.1에 제시되어 있음.
2.3.4 관련 맥락을 통한 파인튜닝
새로운 제품, 기능 또는 고객 세그먼트에 대한 시장 조사를 수행하는 실무자는 유사하거나 인접한 제품, 기능, 고객 세그먼트에 대한 과거 연구에 접근할 수 있음. 우리는 이러한 과거 설문을 GPT 파인튜닝에 통합함으로써 GPT의 가중치를 수정함. 우리의 파인튜닝 접근법은 이전 인간 설문 응답을 GPT 프롬프트와 동일한 형식의 새로운 프롬프트-응답 쌍으로 변환하는 것임(2.3.2절에서 설명한 형식). 이 구성 과정의 예시는 그림 1에 제시되어 있음. 이 형식을 따라, 우리는 기존 인간 연구 전체를 사용해 GPT를 파인튜닝함. 예를 들어, 참가자 300명과 각자 12개의 질문이 있는 연구의 경우, 우리는 3,600개의 응답을 사용해 GPT를 파인튜닝힘.
파인튜닝 연구에서 우리는 인간 연구 1A(기존 치약) 응답으로 GPT를 파인튜닝하고, 그 결과를 연구 1B(새롭고 특이한 맛의 치약)에서 평가함. 유사하게, 연구 2A(노트북) 응답으로 GPT를 파인튜닝하고, 연구 2B(노트북의 새로운 기능)와 2C(노트북과 동일한 속성의 다른 수준을 가진 태블릿) 응답을 평가함.

3 결과 (Results)
GPT 기반 컨조인트 연구가 시장 조사 도구로서 얼마나 유용한지를 평가하기 위해 설계된 연구 결과를 제시함.
3.1 컨조인트를 통한 GPT 기준선 선호 회복
첫 번째 결과 집합에서는, 간단한 설문 프롬프트에 포함된 정보 외에 추가 맥락 정보 없이 GPT가 제품 속성에 대한 소비자의 WTP를 반영하는 응답을 생성할 수 있는 능력을 평가함. 우리의 목표는, 과거 설문이 없는 상황에서 마케터가 고객의 WTP 순위와 규모에 대한 기준선을 생성하는 도구로서 GPT를 평가하는 것임. 이를 위해 세 가지 실험 결과를 제시함. 첫째, 치약과 데오도란트의 기본 속성에 대한 GPT의 암시적 선호를 보고하고, 이를 Fong et al.(2023)의 인간 연구 결과와 비교함. 둘째, 치약, 노트북, 태블릿 속성에 대한 GPT의 WTP를 우리의 인간 연구와 비교하며, 이는 GPT 출시 이전에 존재했던 속성에 초점을 맞춤. 마지막으로, 새로운 기능으로 관심을 돌려, 노트북 내장 프로젝터와 새롭고 특이한 치약 맛에 대한 GPT와 인간의 선호를 비교함.
3.1.1 예비 연구 (Pilot Studies)
GPT의 치약과 데오도란트에 대한 선호를 조사한 첫 번째 결과 집합은 표 3에 제시되어 있음. 이 컨조인트 연구에서 우리는 각 브랜드에 대해 전체 옵션 세트를 만들었으며, 각 속성 옵션에 세 가지 가격 수준을 두어 총 36가지 구성을 도출함. 컨조인트 설계는 Fong et al.(2023)의 선택지를 참고했으며, 각 제품 카테고리에서 상위 두 브랜드를 사용하고, 각 제품에 세 가지 가격 수준을 두었으며, 불소와 알루미늄 함량 속성은 두 가지 수준(있음/없음)을 포함함.
2023년 3월 OpenAI의 GPT API를 통해 text-davinci-003 모델을 사용해 수행한 두 연구에서 추정된 효용 파라미터를 제시함. 다항 로짓 선택 모델을 사용해 추정한 치약의 불소와 데오도란트의 알루미늄에 대한 암시적 WTP(지불의사)도 포함함. 우리는 LLM을 추정하는 데 사용된 데이터나 모델 구조를 알 수 없기 때문에, LLM에서 발생하는 표본 불확실성을 정확히 규정할 방법이 없음.
LLM은 표본 분산을 특성화하는 데 독특한 어려움을 제기하지만, 우리는 표 3에서 데이터를 무작위로 추출한 소비자 표본에서 생성된 것처럼 표준 오차를 계산함. 암시적 WTP 값을 제시할 때는 표준 오차를 생략함.
우리는 소비자들이 치약에 불소를 추가하기 위해 평균 3.40달러를 지불할 의향이 있고, 데오도란트에서 알루미늄을 제거하기 위해 평균 0.91달러를 지불할 의향이 있음을 추정함. Fong et al.(2023)의 결과와 비슷함. Fong et al.(2023)은 소비자들이 불소에 대해 평균 3.27달러, 알루미늄에 대해 평균 -1.97달러의 WTP를 보였다고 보고함. 즉, 두 경우 모두에서 우리의 추정치가 그들의 결과의 50% 이내에 있다는 뜻임.
3.1.2 주요 연구 (Main Studies)
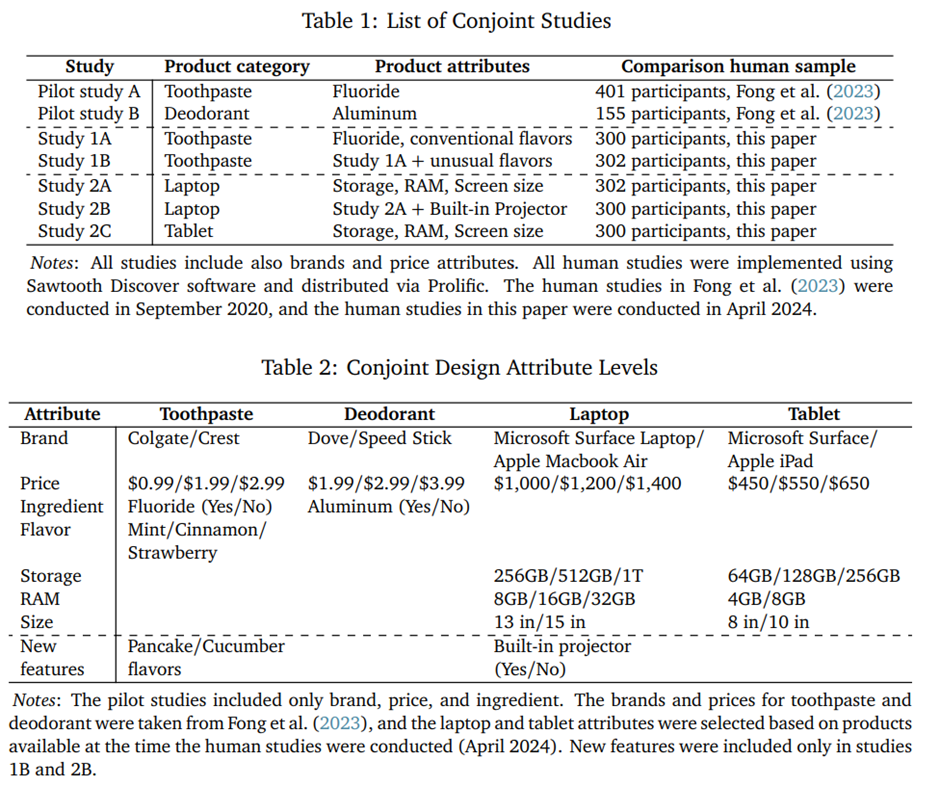
두 번째 결과 집합으로 넘어가, GPT를 우리가 새롭게 수행한 인간 연구와 비교함. 주요 연구에서는 GPT-3.5 Turbo를 사용함. 전반적으로, GPT는 일부 맥락에서는 인간 선호를 잘 근사했으나, 다른 맥락에서는 어려움을 보임. 먼저, 치약 연구(연구 1A와 1B)를 살펴본다. 각 속성에 대한 WTP 추정치는 그림 2에 제시되어 있음. 그림에는 인간 연구에서 추정된 WTP의 95% 신뢰구간(CI)이 포함되어 있으나, LLM에 대해서는 포함하지 않았음.
연구 1A에서 GPT의 결과는 거의 모든 속성을 올바르게 순위화함. Colgate에 비해 Crest 브랜드의 가치는 다른 속성들에 비해 작게 나타났지만, GPT의 WTP는 인간과 부호가 다르게 나타남(인간의 신뢰구간은 0을 포함). 계피와 딸기 맛 치약(민트 기준선 대비)에 대한 GPT의 WTP는 부호가 올바르고, 규모도 인간 설문과 유사함. 다만 GPT의 딸기 맛에 대한 WTP는 인간보다 더 부정적이었음.
인간과 GPT 간의 주요 차이는 GPT가 불소에 대해 더 높은 WTP를 보였다는 점임. 연구 1B 결과도 유사했으며, GPT는 불소에 더 높은 가치를 부여했고 비민트 맛에 대해 더 큰 거부감을 보임. 동시에, 인간 연구에서의 불소 WTP 추정치는 Fong et al.(2023)의 결과와 유사함(연구 1A와 1B에서 인간의 불소 WTP는 각각 2.60달러, 2.90달러). 그러나 GPT의 불소 WTP(연구 1A는 8.20달러, 연구 1B는 9.30달러)는 GPT-3.5 Turbo로 예비 연구를 재현했을 때 나온 값(4.42~4.95달러)보다 거의 두 배 컸음.
다음으로, 연구 1B에서 새로운 맛을 평가할 때 GPT는 새로운 치약 맛(오이, 팬케이크)에 대해 WTP 부호가 인간 데이터와 달랐음. GPT 응답에 따르면, 이러한 차이는 GPT가 새로운 제품을 시도하는 데 선호를 보이기 때문일 수 있음. 실제로 GPT는 새로운 맛이 제공되지 않았을 때(연구 1A 대비) 구매를 더 자주 거부하는 경향을 보임(이에 대한 예시는 온라인 부록 F 참조).
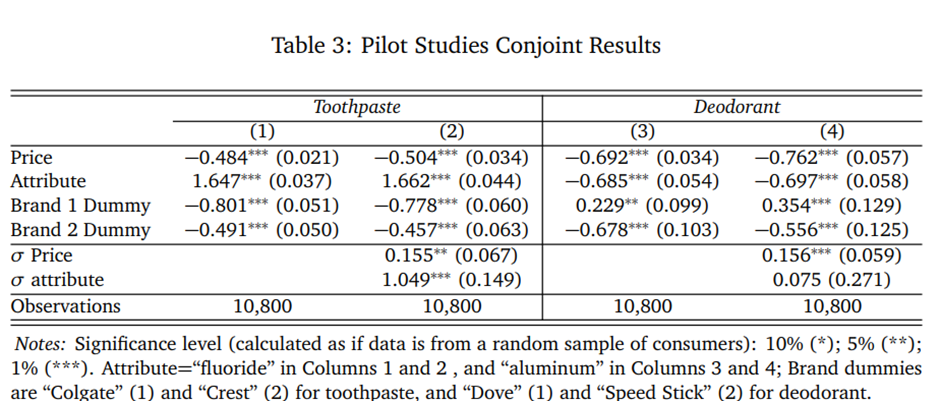
소비자 전자제품 연구 결과는 그림 3에 제시되어 있음. 연구 2A에서 GPT는 저장 용량과 RAM에 대한 WTP 순위를 인간 데이터와 일치시켰으며, 인간 표본의 추정 WTP의 64%~90% 범위 내에 있는 값을 산출함. 연구 2B(새로운 인간 표본 조사)에서도 마찬가지였음. 그러나 두 연구 모두에서 GPT 응답은 Macbook 브랜드에 대해 음(-)의 WTP를 암시했으며, 반대로 인간은 두 연구 모두에서 브랜드 선호가 유의하게 더 높았음. 연구 2C(태블릿)에서도 유사한 비교가 나타났는데, GPT는 iPad에 대한 선호가 상대적으로 낮았음. 이 경우 GPT의 부호는 인간과 일치했지만, 인간 추정치와는 50달러(67%) 차이가 남. 그러나 저장 용량, RAM, 크기와 같은 다른 속성에 대한 GPT의 WTP 추정치는 인간의 WTP보다 훨씬 큼(70%~312% 더 크며, 95% 신뢰구간을 벗어남). 새로운 기능인 “내장 프로젝터”를 탐색한 연구 2B에서는, GPT의 WTP가 인간보다 거의 3배 더 크게 나타남.
노트북 화면 크기와 관련해서는, 인간은 더 큰 화면을 선호한 반면, GPT는 연구 2A와 2B 모두에서 음(-)의 WTP를 보임. 추가 탐색 결과, 이는 설계상의 선택 때문임을 알 수 있었음. GPT는 13인치 화면을 선호했는데, 우리의 옵션에는 13인치와 15인치만 있었기 때문에 해당 속성에서 음의 WTP가 나타난 것임.
종합적으로, 많은 속성에서 GPT-3.5 Turbo는 인간 표본과 규모 및 부호 면에서 유사한 수준의 WTP 추정치를 산출했지만, 일부 속성에서는 상당한 차이가 있음. GPT는 새로운 기능에 대해 잘못된 결론을 초래할 수 있다(예: GPT 결과는 인간이 “팬케이크” 치약 맛을 좋아할 것이라고 시사).
3.1.3 LLM 선택에 대한 강건성 (Robustness to the Choice of LLM)
시장 조사에서 LLM의 신뢰성이 LLM의 선택에 따라 달라지는지, 그리고 어느 정도 달라지는지를 살펴봄. 이는 단일 LLM의 결과가 시간에 따라 얼마나 안정적인지와 밀접하게 관련되어 있다고 봄. 우리는 연구 2A를 GPT-4o, Claude 3 Haiku, Claude 3.5 Sonnet, 그리고 LLaMA-3(8B와 70B)를 사용해 분석을 복제함으로써 이 질문을 다룸. 이러한 모델들 간 비교(그림 3a)는 몇 가지 주목할 만한 차이를 강조함. 일반적으로 GPT-3.5 Turbo와 GPT-4o의 응답이 Claude와 LLaMA-8B보다 인간 표본의 응답을 훨씬 더 잘 근사하는 것으로 보임. LLaMA-8B는 인간의 선호를 크게 과소평가하는 경향을 보였는데(아마도 가장 작은 모델이기 때문일 수 있음). Claude는 이 문제에서 상대적으로 덜하지만, Macbook에 대한 선호가 인간과 다른 모델보다 훨씬 높게 나타났으며, 화면 크기에 대한 선호는 모든 모델 중 인간과 가장 동떨어져 있었음.
실제로, 연구자들은 시장 조사를 위한 LLM 보강이 가능하다면 기존 데이터에 기반하기를 원할 것이며, 이용 가능한 데이터를 넘어선 외삽이 필요할 때만 LLM으로 이를 보완하기를 원할 것임. 충분한 맥락 데이터(파인튜닝의 형태)가 주어진다면, LLM 간 차이의 일부는 줄어들 것이라는 것이 우리의 가설임. 이러한 파인튜닝 접근법이 GPT 설문에서 얻는 통찰에 어떤 영향을 미치는지는 3.3절에서 맥락 내(in-context)와 맥락 외(out-of-context) 모두에 대해 논의함.
3.2 WTP의 이질성 검토 (Examining Heterogeneity in WTP)
설문 설계의 중요한 요소 중 하나는 목표 모집단을 정의하는 것임. 우리는 GPT가 서로 다른 모집단의 선호를 반영할 수 있는 능력을 이해하고자 함. 이를 위해, 우리는 미국에 거주하며 만 18세 이상인 Prolific 참여자들로 이루어진 인간 연구의 모집단에 의존함. 우리는 인간 참여자들로부터 인구통계 데이터를 수집했고(세부 사항은 온라인 부록 D 참조), 각 인구통계 그룹별로 WTP를 별도로 추정한 뒤, 각 그룹에 해당하는 질의를 GPT에 제출함. 특히, 우리는 프롬프트를 수정해 고객의 소득, 성별, 인종을 명시함(세부 사항은 온라인 부록 E 참조).
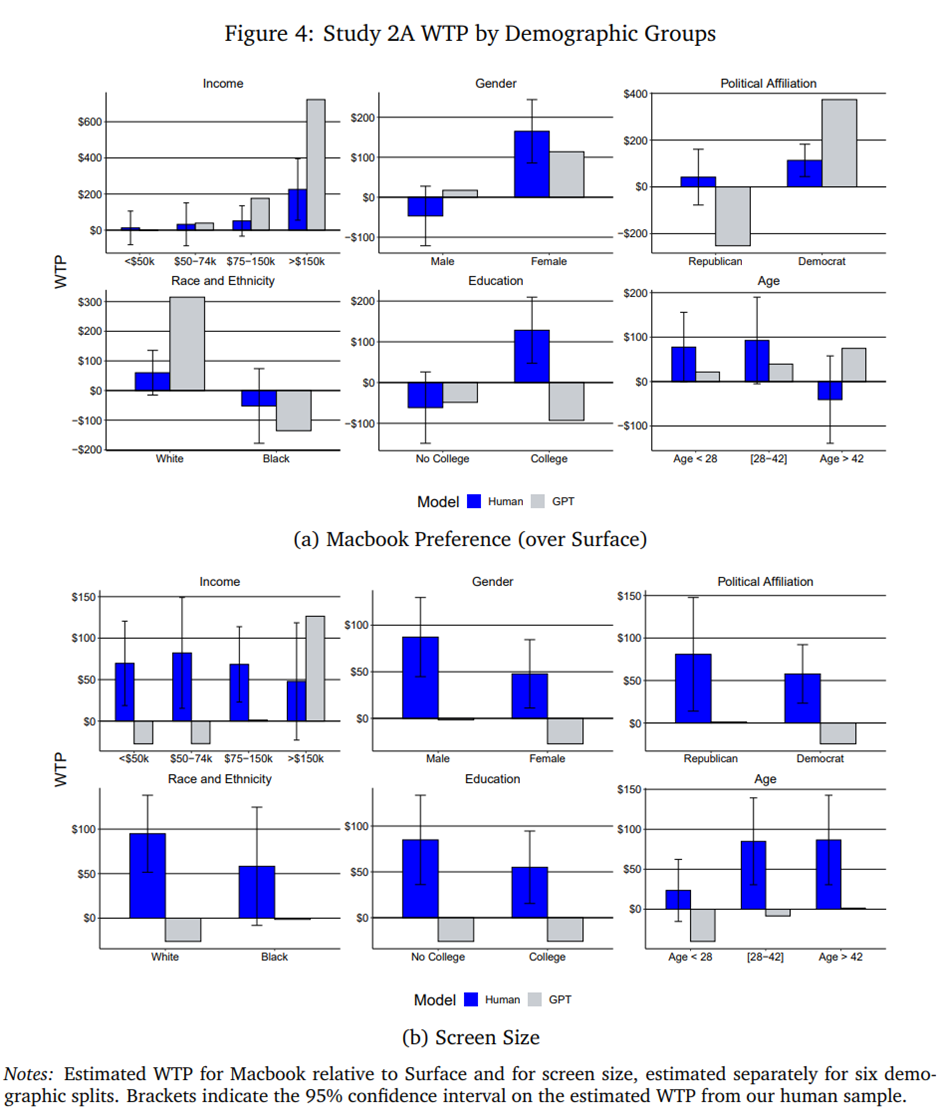
우리는 고객 이질성 조사를 위해 연구 2A를 사용함. 인간 연구에서 우리는 특정 인구통계 구분(예: 소득) 내에서 RAM이나 저장공간에 대한 WTP, 혹은 구매를 포기하는 비율(대부분 그룹에서 약 50%, 다만 흑인 참여자의 경우 37%)이 상대적으로 적게 변동한다는 것을 발견함. 반면 GPT는 이러한 지표에서 인구통계 그룹 간 큰 변동을 반영함. 예를 들어, 소득 5만 달러 이하 그룹과 15만 달러 이상 그룹의 경우, 인간의 RAM에 대한 WTP는 각각 17.80달러와 19.40달러였던 반면, GPT 기반 추정치는 각각 -4.40달러와 99.60달러였다. 또한 GPT의 구매 포기율(opt-out rate)은 저소득 그룹에서 95%, 고소득 그룹에서 34%였는데, 인간의 대응 값은 각각 49%와 47%였음. 그룹별 인간과 GPT가 암시하는 WTP 비교는 온라인 부록 G에서 확인할 수 있음.
인간 설문에서는 화면 크기와 Macbook 제품(Surface와 비교)의 WTP가 다른 속성에 비해 그룹 간 더 크게 달라짐을 발견함.
그림 4는 서로 다른 집단에 대해 인간과 GPT를 기반으로 추정한 WTP를 비교한 것임. 소득, 성별, 정치 성향, 인종 및 민족(그러나 교육이나 연령은 아님)에 따른 집단 간 비교에서, 화면 크기가 아닌 Macbook WTP의 경우 흥미로운 패턴이 나타남. GPT의 추정치는 인간의 것과 크기와 부호에서 차이가 있지만, 집단 간 순서 관계는 일관되게 반영하는 것으로 보임.
예를 들어, 인간 표본에서는 소득 구간이 증가함에 따라 Macbook에 대한 WTP가 12.50달러에서 225.60달러로 증가했으며, GPT의 WTP는 -2.60달러에서 722.52달러로 증가함. 그러나 GPT는 이러한 순서를 모든 속성(즉, 저장공간과 RAM)에도 일반화하는데, 이는 인간 데이터에서 관찰되는 것과는 다름. 성별에 초점을 맞추면, 인간 표본에서 가장 큰 구분(응답자의 44%가 남성, 54%가 여성)과 가장 작은 신뢰구간을 보이는 경우인데, GPT의 Macbook WTP 추정치는 신뢰구간 안에 포함됨. 하지만 화면 크기나 다른 속성들에서는 그렇지 않음.
종합적으로, GPT는 인간 표본에서 발견되는 고객 그룹 간의 일부 차이는 반영하지만, 다른 부분은 반영하지 못함. 특히, 어떤 특정 집단의 선호를 잘 반영하지 못함.
3.3 GPT-3.5 Turbo에 파인튜닝 보강하기
우리는 목표 모집단의 관련 설문으로 GPT를 파인튜닝했을 때 GPT가 어떻게 반응하는지를 탐구함. 우리는 두 가지 질문에 초점을 맞춤.
(1) 파인튜닝은 GPT와 인간 간의 정렬(alignment)을, 파인튜닝 데이터에 포함된 제품과 기능에서 더 좋게 만들어주는가?
(2) GPT는 관련은 있지만 다른 제품 카테고리나 새로운 제품 기능과 같은 표본 외(out-of-sample) 질문에서 어떻게 수행하는가?
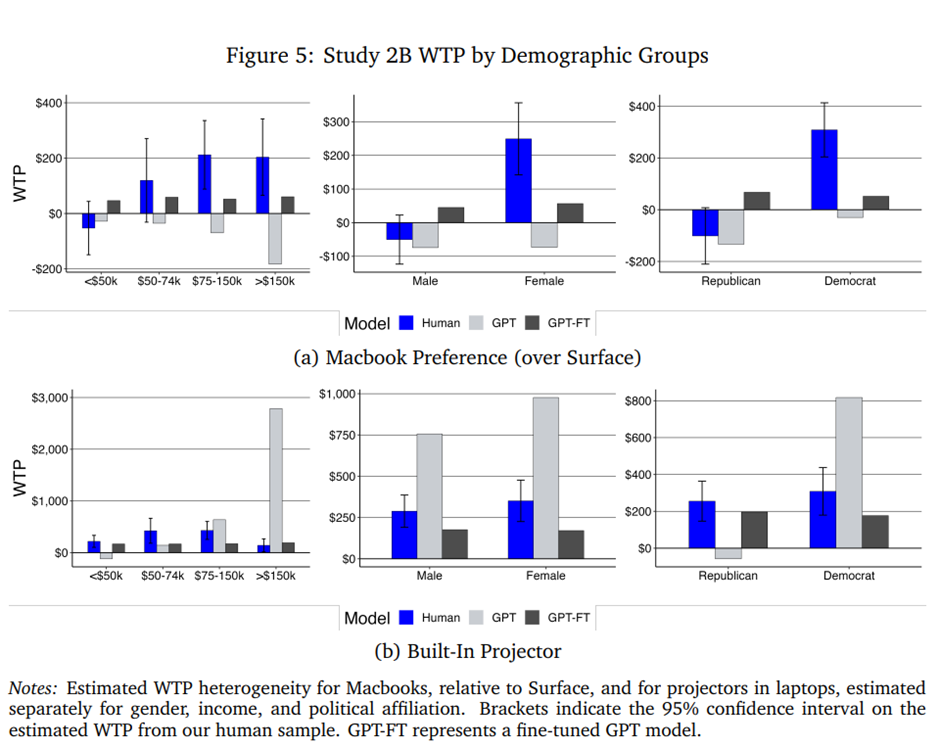
이 두 질문을 연구하기 위해, 우리는 하나의 연구에서 인간 설문 데이터를 사용해 GPT를 파인튜닝하고, 그 후 다른 연구의 질문으로 GPT를 질의함. 첫 번째 질문부터 살펴보면, 우리는 기존 제품(치약 또는 노트북)에 대한 연구로 GPT를 파인튜닝한 뒤, 새로운 기능(새로운 맛 또는 내장 프로젝터가 있는 제품)에 대해 질의함. 먼저, 연구 1B 결과를 살펴보는데, 이때 GPT는 연구 1A를 사용해 파인튜닝됨(그림 2b 참조). 그리고 연구 2B에서는 연구 2A 데이터를 사용해 GPT-3.5를 파인튜닝함(그림 3b 참조). 두 경우 모두, 파인튜닝 데이터에 포함된 일부 속성에서 개선이 나타남. 기준선 GPT와 비교했을 때, 불소에 대한 WTP는 파인튜닝 후 인간과 유사한 수준으로 감소함. 특히, 연구 1A를 사용해 GPT를 파인튜닝한 경우, 계피와 딸기 맛에 대한 GPT의 WTP 정확도가 연구 1A와 1B 두 표본의 결과 모두에서 향상됨. 한 인간 집단의 설문 결과를 GPT에 제공했을 때, 다른 집단의 유사한 질문에 대한 응답을 예측하는 데 도움이 되었음을 시사함. 유사하게, 연구 2B에서는 파인튜닝 후 Macbook에 대한 선호 부호가 반전되었고, 저장공간에 대한 우리의 WTP 추정치도 개선됨.
파인튜닝이 GPT의 WTP에 거의 영향을 미치지 못한 사례도 발견함. 가장 좋은 예는 노트북 크기인데, 기본 GPT-3.5(및 다른 LLM들)는 인간과 달리 이를 부정적으로 인식했다. 연구 2A의 인간 응답으로 GPT를 파인튜닝해도 정렬은 개선되지 않음. 이 문제에 대한 가능한 설명은 GPT의 학습 데이터가 15인치 화면 크기를 노트북의 부정적 특징으로 강하게 신호화했기 때문일 수 있음.
두 번째 질문을 다루기 위해, 우리는 GPT가 파인튜닝에 사용된 데이터로부터 외삽(extrapolation)할 수 있는 능력을 연구함. 먼저, 별개의 그러나 관련 있는 제품 카테고리로의 외삽을 살펴봄. 연구 2C에서 우리는 노트북에 대한 설문 데이터를 사용해 GPT를 파인튜닝했지만, 태블릿에 대해 질의함. 결과적으로 파인튜닝은 브랜드, 저장공간, RAM에 대한 인간과 GPT WTP 추정치 간의 거리를 오히려 늘림. 크기에 대한 WTP 절대 차이는 줄었지만, 인간과 비교해 선호의 부호가 뒤집힘. 종합적으로, 우리는 파인튜닝 후 GPT가 다른 제품 카테고리(속성이 동일할지라도)로 외삽하는 능력에 대한 증거를 찾지 못함. 우리가 생각하는 이유 두 가지는 (i) 태블릿의 속성 값은 노트북의 최저 수준과 같거나 더 낮음(예: RAM 16GB는 태블릿에서 가능한 최대이지만 노트북에서는 최저 수준), 이는 GPT가 이러한 수준을 학습하는 능력에 영향을 줄 수 있음. (ii) 파인튜닝 전부터 GPT의 태블릿 추정치는 인간 표본과 가장 큰 차이를 보임.
카테고리 내 외삽은 성공적임. 우리는 GPT를 파인튜닝할 때 세 가지 속성 정보를 제외했다: 치약의 오이 맛과 팬케이크 맛, 그리고 노트북의 내장 프로젝터. 먼저 연구 1B를 보면, 연구 1A 데이터를 사용해 GPT를 파인튜닝한 결과, 두 가지 새로운 맛에 대한 WTP 부호가 양수에서 음수로 바뀌어 인간 표본과 일치함. 파인튜닝 후 오이 맛에 대한 WTP 추정치는 인간 추정치와 30% 이내였으나, 여전히 해당 신뢰구간 밖에 있었음. 계피 맛 치약에 대한 우리의 WTP 추정치는 연구 1A에서 인간 추정치의 신뢰구간 내에 있었고, 연구 1A로 연구 1B를 파인튜닝한 결과, 연구 1B에서도 GPT의 계피 WTP가 신뢰구간 안으로 들어옴. 팬케이크 맛 치약(민트 대비)의 경우 유사성이 낮았는데, GPT는 -2.40달러의 WTP를 보였고, 인간 표본은 약 -7.00달러였음. 그럼에도 불구하고, 이 경우 파인튜닝된 GPT는 인간과 GPT 추정치 간의 거리가 극적으로 줄어들었기 때문에 시장 조사자가 두 새로운 맛이 대상 소비자에게 인기가 없을 것임을 올바르게 판단하는 데 도움을 줄 수 있음.
연구 2B 외삽도 성공적임. 이는 새로운 프로젝터 기능이 있는 노트북에 관한 설문으로, 우리는 연구 2A(프로젝터 없는 노트북) 데이터로 GPT를 파인튜닝함. 이 연구의 기준선 버전에서 GPT는 프로젝터에 대한 고객의 WTP를 3배 이상 과대평가함. 그러나 파인튜닝 후에는 두 추정치가 매우 근접하게 정렬됨. 이 연구에서 파인튜닝은 합리적인 추정치를 개발하는 데 필수적이었으며, 목표 고객층의 WTP에 대해 올바른 부호뿐만 아니라 올바른 규모까지 산출해냄. 마지막으로, 우리는 GPT-4o에서 파인튜닝 없이 연구를 복제했는데, 이 경우 인간과 파인튜닝된 GPT 모두와 매우 유사한 WTP가 도출됨. 비록 단 하나의 사례에 불과하지만, 이는 파인튜닝이 LLM 간 추정치의 이질성을 줄이는 데 도움을 줄 수 있다는 우리의 가설을 뒷받침함.
마지막으로, 우리는 파인튜닝이 고객 이질성 결과를 개선할 수 있는지 여부도 검토함. 이를 위해 우리는 다시 연구 2A 응답으로 GPT를 파인튜닝했지만, 프롬프트를 수정해 설문 응답을 기반으로 고객의 소득 구간과 성별을 포함시킴. 이후 우리는 연구 2B의 질문으로 이 파인튜닝된 GPT를 질의했으며, 여기서는 서로 다른 소득 수준, 성별, 정치 성향의 고객을 별도로 조사함. 종합적으로, 인구통계 정보를 사용해 GPT를 파인튜닝한 결과, 인간 연구의 평균 추정치와 더 유사한 WTP를 산출했고, 또한 소득 분포 전반에 걸쳐 Macbook 선호의 부호를 올바르게 바꿈(소득 5만~7.5만 달러 고객 대비).
그러나 GPT는 연구 2A에 존재했던 속성과 새로운 속성 모두에서, 서로 다른 인구통계 집단 간 차이를 의미 있게 복원하지 못함. 그 차이가 통계적으로 유의할 때조차도 그러함(예: 최저와 최고 소득 구간, 성별, 정치적 차이; 그림 5a 참조). 예를 들어, 인간 남성의 Macbook 평균 WTP는 -50달러였고 여성은 249달러였지만, 파인튜닝된 모델은 각각 45달러와 57달러를 제시함. 프로젝터의 경우, 파인튜닝된 모델은 170~196달러의 WTP를 제시했는데, 이는 대부분 인간 하위 표본의 신뢰구간 밖이었음. 그림 5는 Macbook과 프로젝터에 대한 WTP 결과를 제시하며, 온라인 부록 G.2는 절차에 대한 추가 세부 사항과 모든 속성에 대한 WTP 추정치를 제시함.
3.4 우리의 파인튜닝 접근 방식의 확장 가능성 (Potential for Scalability of Our Fine-Tuning Approach)
앞서 제시한 결과는 이러한 접근 방식이 실제로 어떻게 확장될 수 있을지에 대한 질문을 남김. 우리는 데이터셋 내의 어떤 관계는 LLM이나 그 어떤 머신러닝 모델이라도 본질적으로 다른 관계보다 더 쉽게 “학습”할 수 있으리라 직관적으로 생각함. 특히 소규모 표본에서는, LLM이 WTP를 추정하는 것보다 시장 점유율과 같은 단순한 통계량(moment)을 더 쉽게 학습할 수 있을 것임. WTP는 데이터에 크게 의존하는 복잡한 함수이기 때문임.
더 많은 파인튜닝 데이터가 주어질수록 GPT가 데이터 내의 더 복잡한 관계를 학습하는 데 도움이 될 것임.
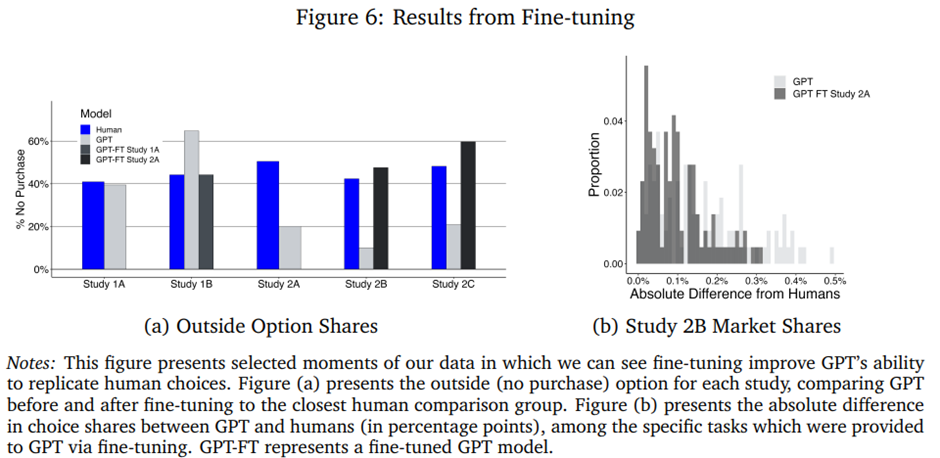
그림 6에서는 GPT가 데이터 속 관계를 학습한다는 점을 직관적으로 보여주기 위해 두 가지 모델 비의존적 결과를 제시함. 그림 6a에서는 모든 연구에서, 관련이 있는 경우 파인튜닝 전후를 포함해, 인간과 GPT의 비구매 선택 비율을 나타냄. 여기서 우리는 GPT를 파인튜닝한 세 가지 연구 각각에서, 파인튜닝이 GPT가 인간 참여자와 더 유사한 비율로 비구매 옵션을 선택하게 했음을 확인할 수 있음. 이는 새로운 기능을 포함해 새로운 연구의 선택 세트가 파인튜닝 데이터와 다르게 구성된 연구 1B와 2B에서도 마찬가지였는데, 이는 일정 수준의 성공적인 외삽을 보여줌. 그림 6b에서는 연구 2B에서 생성된 GPT 데이터를 GPT 파인튜닝에 사용된 정확히 동일한 질문 집합(즉, 인간 설문조사 버전인 Sawtooth의 연구 2A에 포함된 질문들)으로 제한하고, 파인튜닝 전후의 GPT와 인간 간 선택 점유율의 유사성을 비교함. 여기서도 파인튜닝이 인간 벤치마크에 비해 이러한 경험적 통계량의 정확도를 직관적으로 개선했음을 확인할 수 있음. 이러한 비교는 우리의 접근 방식이 시간이 지남에 따라 연구 회사들에 의해 확장될 수 있음을 시사함.
4 결론 (Conclusion)
이 논문은 GPT와 다른 LLM들이 시장 조사자들에게 얼마나 유용할 수 있는지를 연구함. 우리는 새로운 환경에서 고객 선호에 대해 무언가를 배우고 싶지만, 인간 대상의 새로운 연구를 진행할 시간이나 예산이 없는 시장 조사자의 실제 문제에 초점을 맞춤. 이러한 상황을 염두에 두고, 우리는 시장 조사자가 가진 기존 데이터 자원을 모방하고 GPT가 연구 맥락에 대해 가지는 정보의 양과 유형을 통제할 수 있는 맞춤형 연구들을 설계함. 이후 GPT의 설문 응답을 인간의 응답과 비교함.
우리는 많은 경우 GPT가 파인튜닝 없이도 시장 조사 질문에 인간과 유사하게 응답한다는 것을 발견함. GPT를 파인튜닝을 통해 보강했을 때, GPT는 새로운 제품 기능에 대해서도 인간 응답과 더 잘 정렬되는 모습을 보임. 그러나 파인튜닝 데이터 밖의 제품 범주로 외삽하는 데는 어려움을 겪었고, 이 맥락에서는 오히려 GPT의 성능이 악화됨. 고객 이질성을 재현하는 데에도 실패함. 우리는 마케터들이 우리의 접근 방식을, LLM으로 인간 연구 대상을 대체하는 것이 아니라, 새로운 기능 아이디어를 인간을 대상으로 시험하기 전에 탐색하고 좁히는 데 활용할 것이라고 봄.
우리의 연구는 시장 조사에 LLM을 사용할 때의 몇 가지 한계를 드러냄. LLM이 어떤 시장 조사 목적에 가장 적합하고, 어떤 목적에는 기존 방법의 대체재로 부적합한지를 평가하기 위해 더 많은 연구가 필요함. 고객 이질성을 반영하는 능력이 제한적임. 또한 우리의 연구는 프롬프트 문구에 따라 GPT의 민감도가 달라짐. 더 나아가, 빠른 개발 주기와 새로운 LLM의 잦은 도입은 각 LLM 릴리스에서 기준선 응답을 평가할 필요성을 제기함.
우리는 LLM이 앞으로 시장 조사에서 더욱 유용해질 것이라고 예상함. 이는 이러한 모델들의 정교함이 빠르게 향상되는 것과 병행함. LLM의 정확성이 개선되고(GPT-4o 출시에서 널리 보고됨), 더 많은 데이터에 접근할 수 있게 되면서(대중적 검색 엔진에서의 활용이 이를 보여줌), 소비자 행동의 풍부한 측면을 흡수하고 추론하는 능력도 마찬가지로 향상될 것이라고 낙관함. GPT를 진실의 원천으로서 얼마나 유용한지 설명하기 위해 기존의 시장 조사 패러다임에 기대고 있지만, LLM은 인간 대상 연구의 한계를 넘어서는 새로운 시장 조사 패러다임을 만들어낼 수도 있음.
