1x1 Convolution에 대해 알아보기 전에 1x1 Convolution이 왜 사용되기 시작했는지 이해하기 위해 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)라는 Challenge와 대회에서 수상을 했던 5개 Network 들의 주요 아이디어와 구조에 대해 알아보려고 한다.
Network List
-
AlexNet
- 최초로 Deep Learning을 이용하여 ILSVRC에서 수상
- ReLU를 활성화 함수로 사용함. ReLU는 0보다 큰 x값에 대해서는 gradient를 1로 보존되기 때문에 Vanishing Gradient Problem을 해소해주었다.
-
VGGNet
-
3x3 Convolution을 이용하여 Receptive field는 유지하면서 더 깊은 네트워크를 구성
-
Why 3x3 Convolution?
- 5x5 필터를 한 번 적용하는 것보다 2번의 3x3 필터를 적용하는 것이 파라미터 수가 더 적다.

-
-
GoogLeNet
- Inception Block
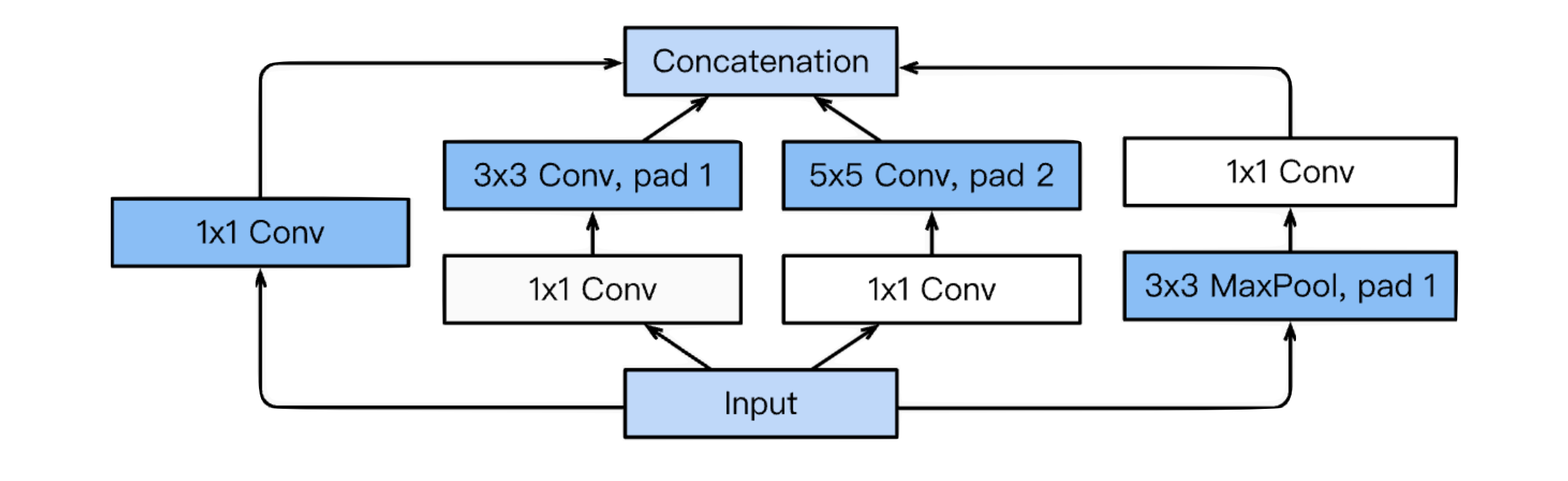
- WHY inception block?
-
1x1 convolution을 통과시켜서 파라미터 수를 줄여준다.
-
HOW?
- Channel-wise dimension reduction이라고 한다. 1x1 Convolution을 하면 채널의 수를 줄일 수 있다.
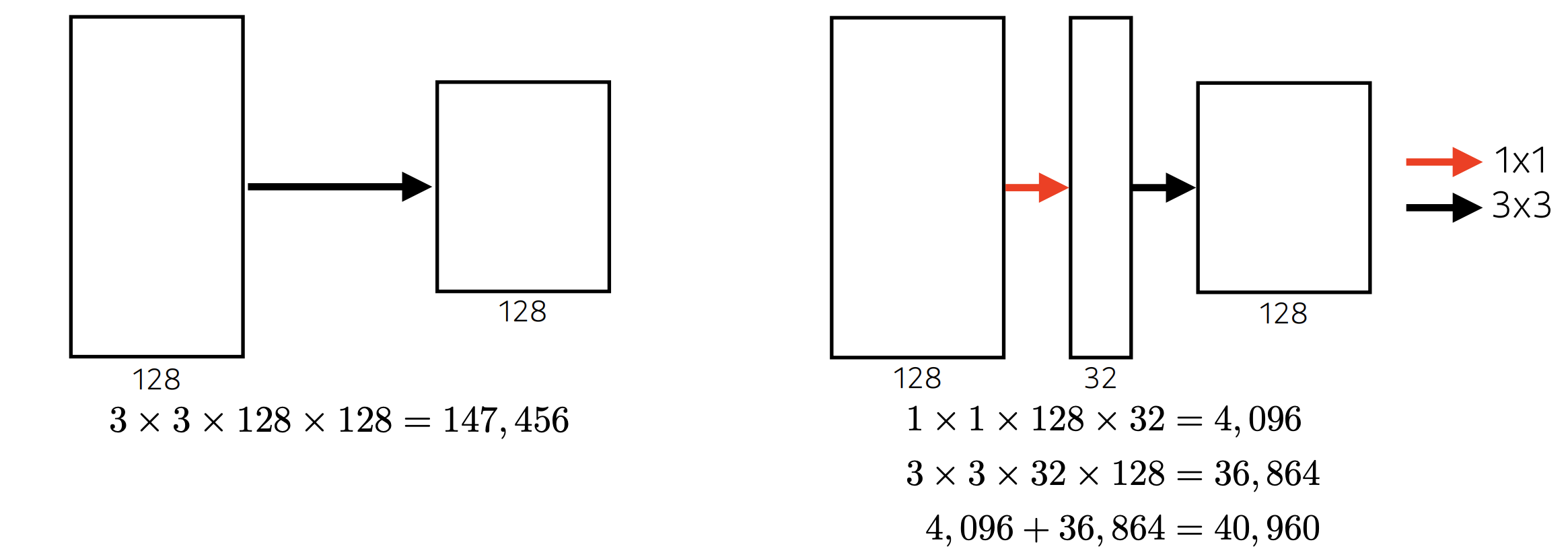
-
- 여기까지 3개의 네트워크의 레이어 수와 파라미터 수를 비교해보면
- AlexNet (8 layers, 60m)
- VGGNet (19 layers, 110m)
- GoogLeNet (22 layers, 4m) # 구글넷이 가장 레이어 수가 많은데 파라미터 수는 제일 적은 것을 알 수 있다. 이것이 1x1 Convolution의 효과이다.
-
ResNet
- Residual connection(Skip connection)이라는 구조를 제안
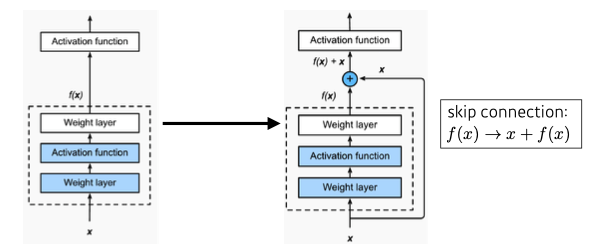
- 레이어가 깊어지면 오버피팅과 같은 현상이 종종 발생했는데 ResNet에서 어느 정도 해소함
- Performance 가 증가한 반면 Parameter size는 감소함
- Residual connection(Skip connection)이라는 구조를 제안
-
DenseNet
- ResNet과 비슷한 아이디어지만 Addition이 아닌 Concatenation을 적용한 CNN
