jpa
1.jpa 프록시
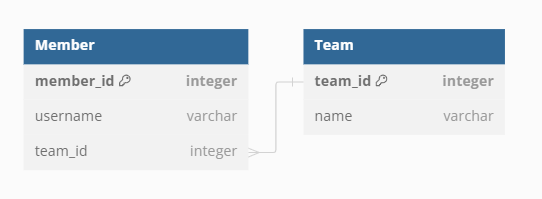
JPA 를 사용해서 연관관계를 매핑할 때 CASCADE, fetch(지연 로딩, 즉시 로딩) 등 다양한 용어가 나온다. 이들을 온전히 이해하지 못하면 데이터베이스에서 데이터를 가져올 때 날리는 쿼리문이 왜 이렇게 많이 날라가는지, 혹은 왜 쿼리문이 날라가지 않는지 등
2.스프링 jpa fetch join
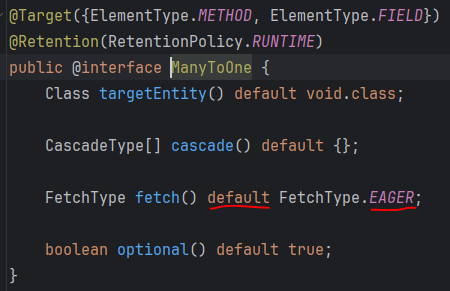
스프링에서 jpa 를 활용하여 @Entity 계층을 만들 때, XtoOne 에는 다들 지연로딩을 적용 할 것이다. 그 이유는 사용하지도 않는 데이터를 굳이 쿼리 날리면서 가져올 필요 없기 때문이다. (참고로 XtoOne의 default가 즉시 로딩(EAGER) 이라서
3.스프링 jpa fetch join 페이징 문제 해결

XtoOne (ManyToOne, OneToOne) 관계에 있어서 fetch join 을 사용하면 n + 1 문제가 해결 되는 것을 경험했다. 그런데 fetch join 의 치명적인 단점은 페이징을 못한다는 것이다. 정확하게 말하면 fetch join 을 사용하는 동시
4.영속성 컨텍스트 & EntityManger
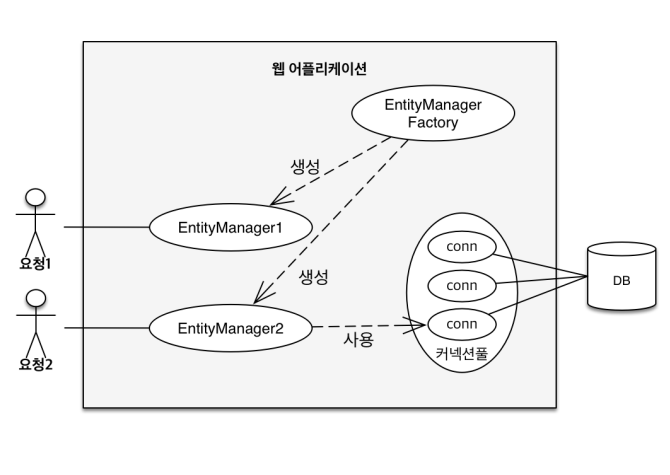
was 는 하나의 EntityManagerFactory 를 가지고 여러개의 EntityManager 를 만든다.영속성 컨텍스트는 데이터베이스 커넥션을 포함하고 있다.참고로 jpa 에서 데이터베이스와 관련된 모든 작업은 Transaction 단위 내에서 수행한다.Enti
5.JPA 상속관계 매핑
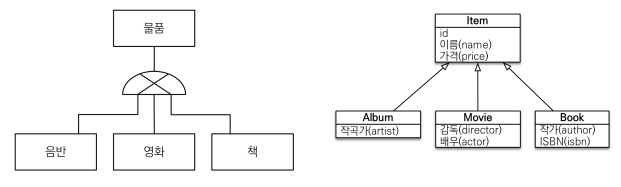
객체 세상에서는 상속관계가 있다. 그리고 이와 유사하게 데이터베이스에서는 슈퍼타입과 서브 타입의 개념이 있다. jpa는 이러한 상황속에서 객체와 디비와 연결해주기 위해서 편리한 애노테이션을 제공한다. 바로 @Inheritance(strategy=InheritanceTy
6.JPA 공통 매핑정보 @MappedSuperclass
jpa 를 사용해서 엔티티를 만들때 공통적으로 사용하는 기능이 있다면 BaseEntity를 활용하는 것이 좋다. 코드를 보면 바로 이해가 될 것이다.@MappedSuperclass 어노테이션을 적용하면 쉽게 공통적인 필드를 적용할 수 있다.공통적인 필드를 적용하고 싶은
7.jpa cascade
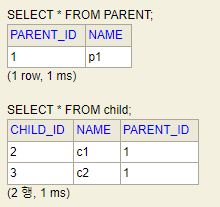
나는 jpa 에서 @OneToMany(cascade = CascadeType.ALL) 처럼 cascade의 옵션을 무심코 쓴 경험이 있다. 알지도 못하고 사용한 나 자신에 대해서 반성하게 되며, cascade의 옵션에 대해서 이해한 내용을 정리해보겠다cascade 는
8.JPA 임베디드 타입
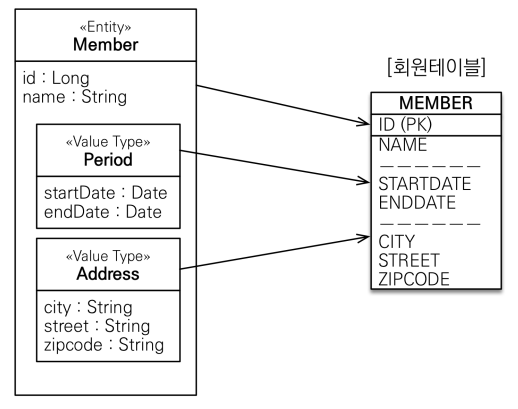
@MappedSuperclass는 공통된 필드를 모아주는 역할을 한다. 이와 유사하게 임베디드 타입은 공통된 필드를 제공하면서 재사용성을 가능하게 해준다. 그러면 이 둘과의 차이점이 뭘까? 가장 큰 차이점은 바로 상속과 위임의 차이다. @MappedSuperclass는
9.Jpa 메모장
위 코드는 하나의 트랜잭션상에 있기 때문에 findMember와 member 가 같다.테스트 코드에서 @Transactional 를 적용한다면 (Jpa 사용시) 영속성 컨텍스트에 플러시를 날리지 않는다. 즉, DB에 데이터를 반영하지 않는다는 것이다. 만약에 테스트 코
10.Jpa 벌크 연산 주의점
벌크 연산이란 한번에 대량의 데이터를 수정하는 것을 뜻한다. Jpa는 영속성 컨텍스트라는 개념이 존재하기 때문에 벌크 연산 시 주의점이 있다. 아래 예제를 통해서 주의점을 살펴보자.spring data jpa의 코드로 특정 나이보다 많다면 모든 Member 에 대해서
11.JPA 조인 테이블 전략 삭제
필자는 프로젝트 진행중에서 조인 테이블 전략을 사용했을 때 연관관계를 부모 테이블, 자식 테이블 중 어느 테이블에 매핑 시켜야 하지 라는 의문이 있었다. 결론부터 말하면 부모 테이블에 다른 테이블과의 연관관계를 매핑시켜야 한다. ex) board 라는 부모 테이블에 c