서론
스프링에서 jpa 를 활용하여 @Entity 계층을 만들 때, XtoOne 에는 다들 지연로딩을 적용 할 것이다. 그 이유는 사용하지도 않는 데이터를 굳이 쿼리 날리면서 가져올 필요 없기 때문이다. (참고로 XtoOne의 default가 즉시 로딩(EAGER) 이라서 fetch를 LAZY 로 설정하는 것이다.)
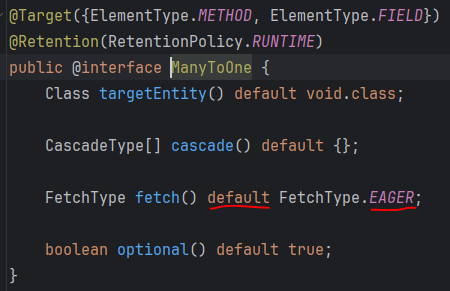
그런데 이러한 지연 로딩이 항상 좋은 것은 아니다. 왜냐하면 지연로딩으로 걸린 엔티티 데이터를 함께 가져오고 싶은 경우에는 쿼리가 여러번 나가는 성능 이슈가 있기 때문이다. 예를 들어보자.
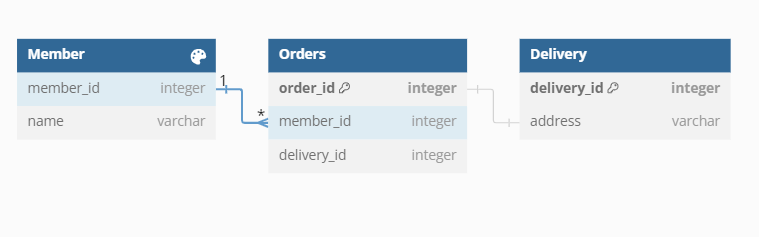
- 위의 엔티티들에 대해서 간단하게 상황 살명을 하자면, 회원(member)는 여러개의 주문(order) 를 할 수 있고, 주문(order) 에는 배송지(Delivery) 정보가 있다. 2개의 주문에 대한 더미 데이터가 있고, 3개의 엔티티에 대해서는 모두 지연로딩으로 설정해줬다고 가정하자.
@GetMapping("/api/v2/simple-orders")
public List<SimpleOrderDto> ordersV2() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
List<SimpleOrderDto> result = orders.stream()
.map(o -> new SimpleOrderDto(o))
.collect(toList());
return result;
}
//dto
static class SimpleOrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public SimpleOrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
address = order.getDelivery().getAddress();
}
} //orderRepository 내부 구현 함수
public List<Order> findAll() {
return em.createQuery("select o from Order o", Order.class)
.getResultList();
}
- 위의 코드를 실행하면 2개의 더미 데이터에 대해서 5개의 쿼리가 나간다.
- 5번의 쿼리가 나간 이유는 바로 지연로딩 때문이다.
- 먼저 order에 대해서 2개의 데이터가 있다고 앞서 얘기했다. 따라서
orderRepository.findAllByString(new OrderSearch())를 이용하면 order 데이터 2개를 가져오는 하나의 쿼리문이 실행된다. - 그리고 첫번째 order 데이터에 대해서 회원의 이름을 가져오는
order.getMember().getName()을 실행하면 하나의 쿼리문이 나간다. - 마지막으로 배송정보를 가져오는
order.getDelivery().getAddress()을 실행하면 하나의 쿼리가 나간다. - 즉, 하나의 주문 정보당 2개의 쿼리가 추가로 나가게 되어서 1(order) + 2(member name) + 2 (delivery address) 의 쿼리가 나가게 된 것이다.
- 지연로딩이기 때문에 한번에 쿼리가 나간 것이 아니라 실제로 사용할때 쿼리가 나가는 것이다.
지금은 2개의 주문만 있기 때문에 (1 + 2 + 2)개의 쿼리문이 나간 것이지 만약에 주문이 10개 있다고 생각해보자. 그러면 위처럼 최악의 경우에 (1 + 10 + 10)개의 쿼리문이 나갈 것이다. 그렇다고 지연로딩을 즉시로딩으로 바꾸기에는 성능 개선의 여지가 줄어들기에 좋은 선택지는 아니다. 이런 상황을 해결해주는 것이 바로 fetch join 이다.
그래서 fetch join이 뭔데?
fetch join은 jpql에서 성능 최적화를 위해 제공하는 기능으로 연관된 엔티티나 컬렉션을 sql 한번에 함께 조회하는 기능을 수행한다. 바로 예제 코드로 살펴보자.
@GetMapping("/api/v3/simple-orders")
public List<SimpleOrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllWithMemberDelivery();
List<SimpleOrderDto> result = orders.stream()
.map(o -> new SimpleOrderDto(o))
.collect(toList());
return result;
}
//orderRepository 내부
public List<Order> findAllWithMemberDelivery() {
return em.createQuery(
"select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d", Order.class
).getResultList();
}- fetch join은 jpql에
join fetch o.member m처럼 작성하면 된다. - 위처럼 코드를 작성하면 쿼리문은 한번만 나간다.
- 그 이유는 fetch join을 사용해서 order, member, delivery를 모두 한번에 조회하기 때문에 지연로딩이 적용되지 않기 때문이다.

인사이트를 얻고 정리하는 공간입니다