
자료구조는 데이터를 보다 효율적으록 관리하고 저장하기 위한 하나의 방법과 이론을 뜻한다.
이는 데이터의 저장, 검색, 수정, 삭제 등의 작업에 있어서 보다 효율적으로 처리가 가능하도록 해주는 이점이 있기에 백엔드 개발에 있어서 중요한 부분이라고 생각을 한다.
자료구조의 필요성
필자의 경험으로 예전에는 어떠한 가게나 회사의 전화번호를 알고싶을 때 114에 전화를 걸어서 확인하는 방법과 전화번호부 책자에서 찾아서 확인하는 방법이 있었다. 여기서 후자의 방법을 보면 내가 찾고자하는 회사나 가게 등 분류를 거치고 가나다 순서로 정렬이 되어있어 생각보다 빠르게 찾을 수 있다는 장점이 있다.
이렇게 전화번호부를 메모리, 하나의 요소를 데이터로 비유하여 일상에서 예를 찾아볼 수 있다.
이 처럼 자료구조를 이용한다면 데이터의 접근 속도와 처리 속도가 크게 향상이 되어 성능에 최적화가 되며, 보다 효율적으로 메모리를 관리할 수 있다는 점이 있다.
알고리즘에서 자료구조
자료구조는 알고리즘에 있어서 성능과 효율을 결정짓는 중요한 요소라고 생각을 한다. 자료구조는 데이터가 저장되고 조직되는 방식이기 때문에, 특정한 작업을 수행하는데 있어서 필요한 시간과 공간의 효율성에 직접적인 영향을 끼친다고 본다.
만약에 알고리즘에 있어서 잘못된 자료구조를 사용한다면 문제에 있어서 해결은 가능하겠지만 다소 비효율적인 결과를 얻을 수 있다.
간단한 예를 들어보겠다.
수천 개의 전화번호가 저장된 시스템에서 특정 전화번호를 검색하는 코드를 만들어라
이러한 문제를 해결해야 할 때 어떤 방법으로 해결을 할까?
뭐 진짜 간단하게 반복문을 사용해도 해결은 가능할 것이다. 다만 수천 개의 번호에서 진짜 셀 수 없을 정도로 많은 번호가 있는 시스템에서 한다면... 아마 결과를 받기에는 지칠 수 있겠다는 생각이 든다.
그래서 단순한 반복문 대신에 자료구조를 이용해서 해결해보자
-
정렬된 배열 사용
- 이진 검색 알고리즘을 이용할 수 있다. 해당 알고리즘을 사용하면 시간 복잡도는 이다. 그러면 기존의 방법보다 훨씬 빠른 검색이 가능해진다.
-
해시 테이블 사용
- 평균적으로 의 시간 복잡도로 매우 빠르게 처리가 가능하다.
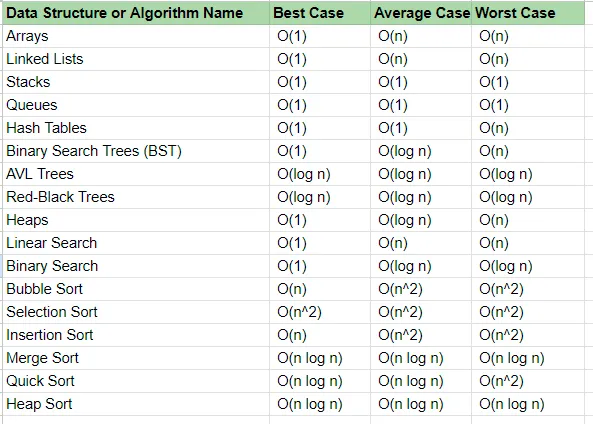
Time Complexity, Space Complexity
-
시간 복잡도(Time Complexity)
알고리즘이 실행되는 데 소모되는 시간을 나타낸다. 데이터의 크기에 따라 시간이 얼마나 소모되는지 분석한다. -
공간 복잡도(Space Complexity)
알고리즘이 사용하는 메모리의 양을 나타낸다. 데이터의 크기에 따라 얼마나 많은 메모리를 사용하는지 분석한다.
결과적으로 자료구조는 알고리즘의 성능과 효율성을 결정하는 핵심적인 요소가 된다. 알고리즘을 설계할 때, 문제의 특성과 요구사항을 이해하고, 이에 적절한 자료구조를 선택하는 것이 중요하다.
올바른 자료구조를 사용한다면 보다 좋은 성능으로 해결할 수 있다.
자료구조 분류
이제는 어떻게 자료구조를 분류하는지와 어떠한 자료구조들이 있는지 확인해보자
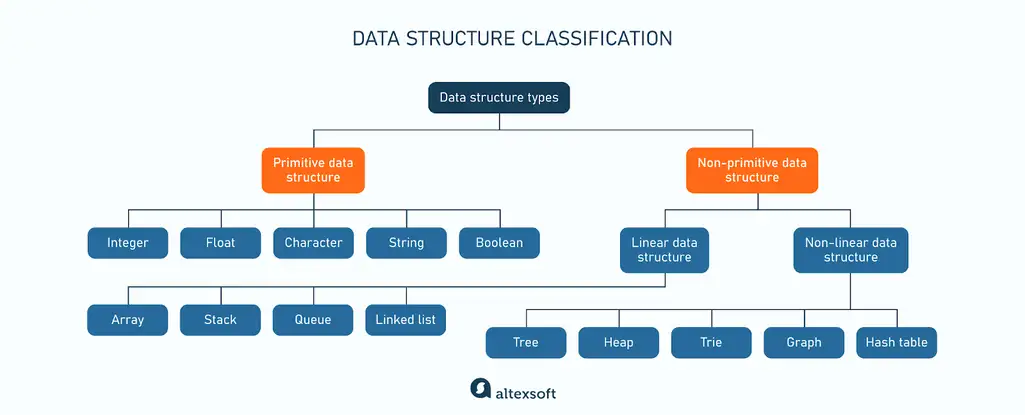
위 이미지에서 자료형을 저장방식을 기준으로 선형 자료구조와 비선형 자료구조로 구분해서 분류를 했다.
그렇다면 선형과 비선형은 어떠한 차이점이 있을까??
-
선형 구조
쉽게 생각하면 데이터가 순차적으로 나열되는 구조이다. 이는 각 요소는 하나의 줄로 연결되어 있으며, 해당 자료구조에서는 순서가 중요하다.- 특징
데이터를 순차적으로 접근할 수 있다. 그리고 구조가 비교적으로 간단하다는 특징이 있다.
- 특징
-
비선형 구조
데이터가 계층적이거나 망상 구조로 나열되어 있는 구조이다. 각 요소는 여러 경로로 연결될 수 있으며, 선형 구조와는 달리 순서가 그닥 중요하지 않다.- 특징
데이터 간의 계층적 관계나 네트워크 관계를 표현할 수 있고, 구조가 복잡하여 더 복잡한 문제를 해결할 수 있다는 특징이 있다.
- 특징
Array
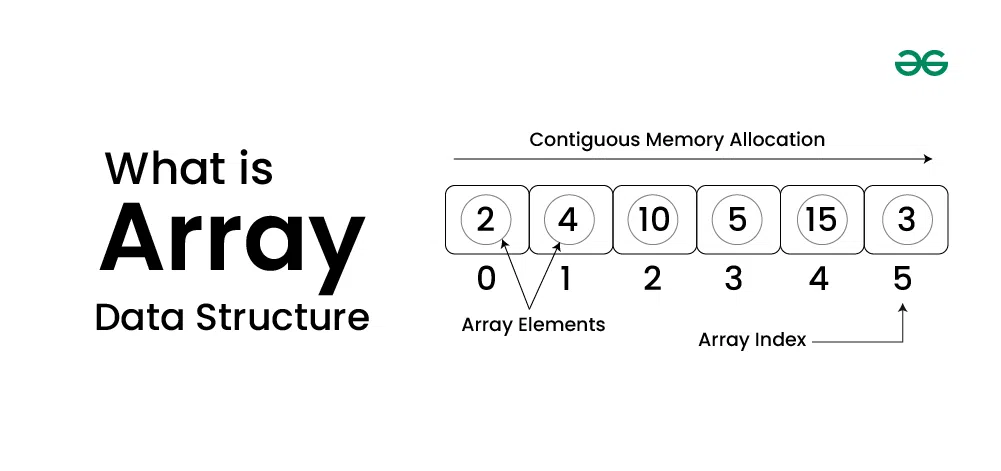
배열의 형태는 동일한 타입의 요소들이 연속적인 메모리 공간에 할당되어 저장이 된다. 그리고 해당 자료구조는 데이터가 정해진 크기로 주어질 때, 빠른 인덱스 접근이 필요할 때 사용한다.
-
특징
- 고정된 크기
- 인덱스를 이용한 의 접근 속도
- 삽입과, 삭제가 다소 비효울적이다.
-
알고리즘
이진 탐색(Binary Search), 정렬 알고리즘(Quick Sort, Merge Sort)
Linked List
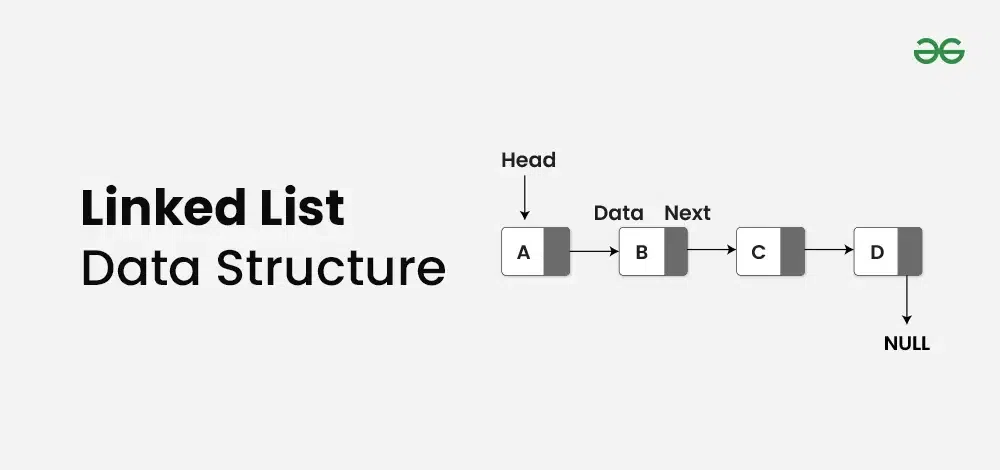
각 요소가 데이터와 다음 요소를 가리키는 포인터를 포함한다. 사진을 보면 잘 이해할 수 있다.
이러한 형태를 갖는 Linked List 자료구조는 빈번한 삽입과 삭제가 필요한 경우와 메모리 낭비를 피해야 할 때 주로 사용이 된다.
-
특징
- 동적 크기 조절
- 순차 접근 $O(n)
- 삽입과 삭제가 효율적
-
알고리즘
리스트 기반의 큐, 스택 구현, 깊이 우선 탐색(DFS)에서 경로 저장
Stack
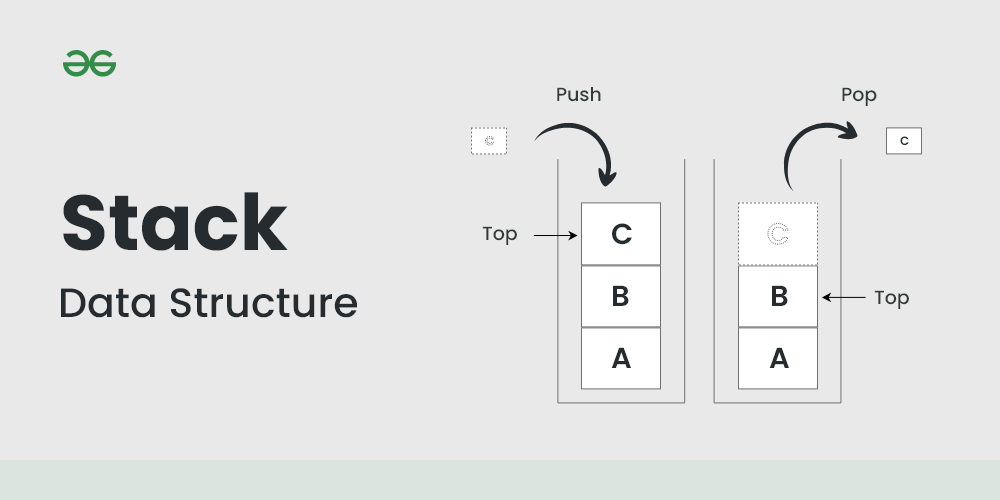
Stack은 순서가 보장되는 선형 구조의 자료구조이다. 그리고 LIFO의 구조를 갖기 때문에 마지막 요소부터 접근이 가능하다. (간단하게 후입선출의 성향)
함수 호출 관리(재귀), 수식 계산(후위 표기법)에 사용이 된다.
-
특징
- 삽입과 삭제의 시간은 을 갖는다.
- 최상위 요소만 접근이 허용된다.
-
알고리즘
깊이 우선 탐색(DFS), 백트래킹 알고리즘
Queue
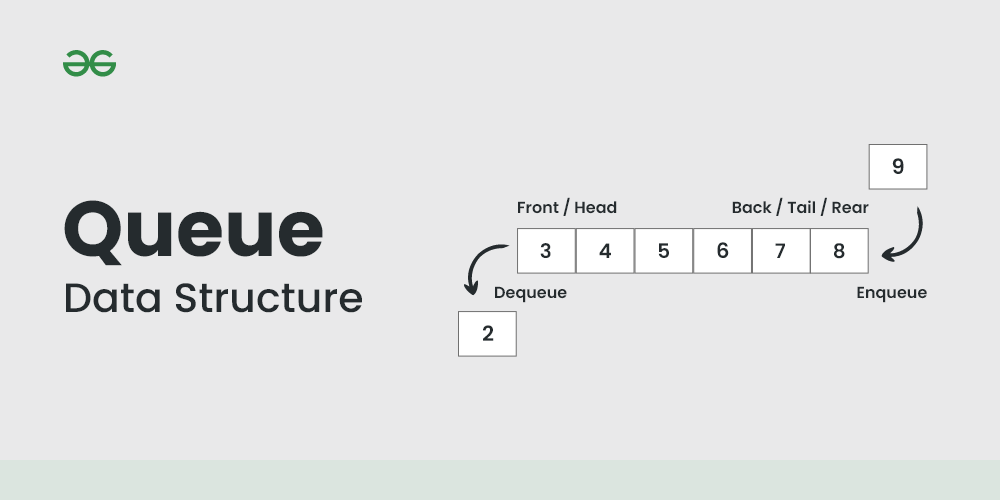
Queue은 FIFO의 구조를 갖는다.(선입선출)
작업 스케줄링, 데이터 버퍼(네트워크 패킷 관리)에 사용된다.
-
특징
- 삽입과 삭제의 시간은 을 갖는다.
- 첫 번째와 마지막 요소만이 접근이 허용된다.
-
알고리즘
너비 우선 탐색(BFS), 시뮬레이션 알고리즘
Hash table
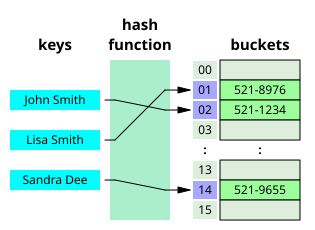
위 이미지 처럼 K-V 쌍의 형태로 저장을 한다. 해시 함수를 통하여 인덱스를 계산하는 형태를 갖는다. 보통 해당 자료구조는 데이터베이스 인덱스, 캐시 구현에 주로 사용이 된다.
-
특징
- 평균적으로 O(1) 접근 속도를 갖는다.
- 해시 충돌 관리 필요 (체이닝, 개방 주소법)
-
알고리즘
해시 기반 검색, 데이터 중복 검사
Graph
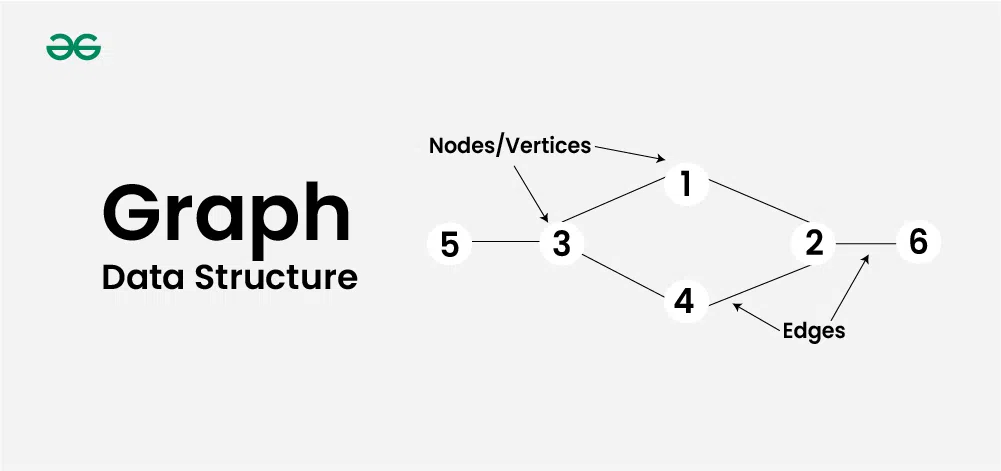
정점(Vertex)와 정점을 연결하는 간선(Edge)으로 구성되어 있다. 해당 자료 구조는 네트워크 라우팅, 소셜 네트워크 분석, GPS를 통한 위치 및 이동경로를 나타내는데 사용이 된다.
-
특징
해당 그래프의 특징은 어떠한 그래프냐에 따라 각기 다른 특징을 갖고 있다. 그래서 따로 정리하지는 않겠다. -
알고리즘
너비 우선 탐색(BFS), 깊이 우선 탐색(DFS), 최단 경로 알고리즘(Dijkstra, Floyd-Warshall)
Tree
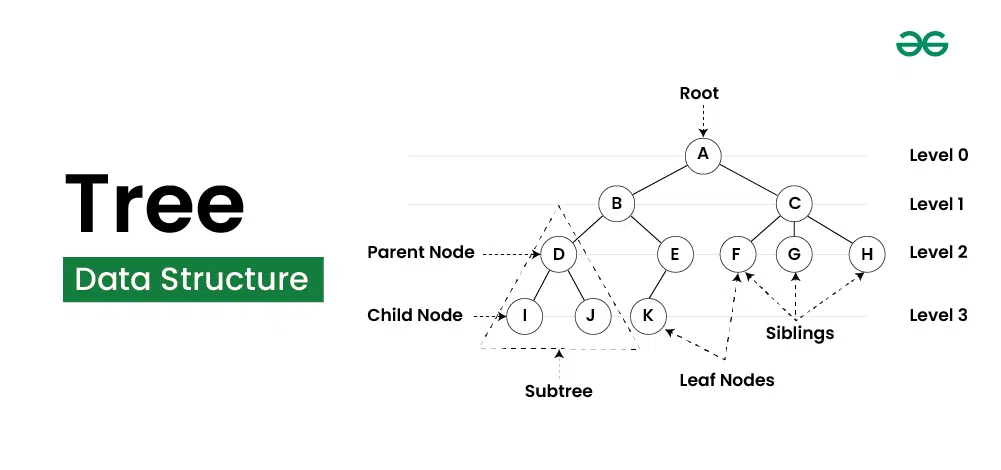
계층적 구조, 루트 노드와 자식 노드로 구성되어 있다. 해당 자료구조 사용의 예로는 데이터베이스 인덱스와 파일 시스템 구조가 있다.
-
특징
- 무방향, 사이클 없음
- 이진트리, AVL트리, B 트리 등등...
-
알고리즘
이진 탐색, 트리 순회(In-order, Pre-order, Post-order), 균형 유지 알고리즘(AVL 트리, Red-Black 트리)
