미리 보는 인덱스 튜닝
데이터를 찾는 두가지 방법
- 테이블을 전체 스캔
- 인덱스를 이용
- 소량의 데이터를 검색할 때 사용
인덱스 튜닝의 두가지 핵심 요소
- 인덱스 스캔 효율화 튜닝
- 인덱스 스캔 과정에서 발생하는 비효율을 줄이는 것
- 랜덤 액세스 최소화 튜닝
- 테이블 액세스 횟수를 줄이는 것
- 인덱스 스캔 효율화 튜닝보다 성능에 미치는 영향이 더 크다.
SQL 튜닝은 랜덤 I/O와의 전쟁
- 데이터베이스 성능이 느린 이유는 디스크 I/O 때문이다.
인덱스 구조
인덱스는 대용량 테이블에서 필요한 데이터만 빠르게 효율적으로 액세스하기 위해 사용하는 오브젝트다.
(색인과 같은 역할)
- DBMS는 일반적으로 BTree 인덱스를 사용
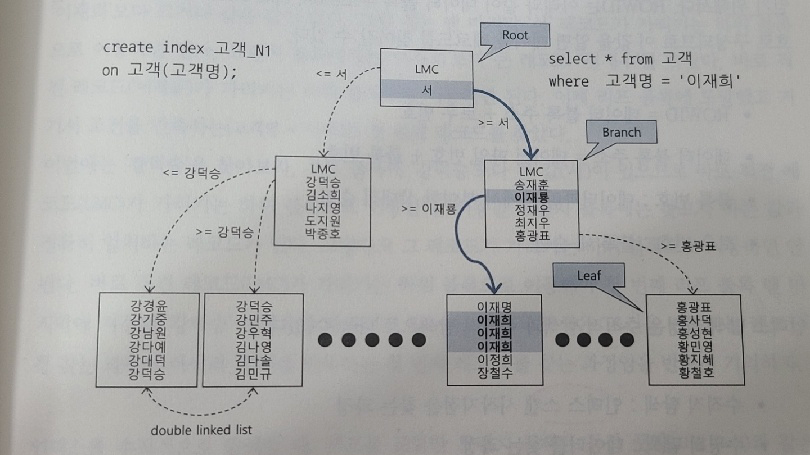
- 루트와 브랜치에 있는 각 레코드는 하위 블록에 대한 주소값을 갖는다.
- LMC(Leftmost Child) : 자식 노드 중 가장 왼쪽 끝에 위치한 블록을 가리킴
- 리프블록에 저장된 각 레코드는 키값 순으로 정렬되어 있고 테이블 레코드를 가리키는 주소값(ROWID)를 갖는다.
| ROWID | 데이터 블록 주소 + 로우 번호 |
| 데이터 블록 주소 | 데이터 파일 번호 + 블록 번호 |
| 블록 번호 | 데이터 파일 내에서 부여한 상대적 순번 |
| 로우 번호 | 블록 내 순번 |
- 수직정 탐색 : 인덱스 스캔 시작지점을 찾는 과정
- 수평적 탐색 : 데이터를 찾는 과정
인덱스 수직적 탐색
- 인덱스 스캔 시작지점을 찾는 과정
- 예로 책의 목차 또는 색인이라고 생각하자
- 인덱스 수직적 탐색은 루트 블록에서부터 시작
- 루트를 포함해 브랜치 블록에 저장된 각 인덱스 레코드는 하위 블록에 대한 주소값을 갖는다.
인덱스 수평적 탐색
- 수직적 탐색을 통해 더이상 찾고자 하는 데이터가 안 나타날 때 수평적 탐색을 함
- 데이터를 찾는 과정!
- 인덱스 리프 블록끼리는 서로 앞뒤 블록에 대한 주소값을 갖고 있기 때문에 수평적 탐색이 가능
- 수평적 탐색을 하는 이유
1. 조건절을 만족하는 데이터를 모두 찾기 위해서- ROWID를 얻기 위해서(일반적으로 인덱스를 스캔하고서 테이블도 액세스함. 이때 ROWID가 필요함.)
결합 인덱스 구조와 탐색
- 인덱스를 두개 이상으로 구성된 것
- 선택도가 낮은 컬럼은 앞으로 두고 결합 인덱스를 생성해야 성능에 유리하다.
- 예를 들어 이름으로 검색할 때 인덱스가 [성별 + 이름]일 때 성별을 먼저 필터링하고 이름을 필터링을 한다. 인덱스가 [이름 + 성별]일 때 이름만 필터링 한다. 즉 비교연산 횟수를 줄일 수 있다.
Balanced의 의미
- BTree 인덱스의 B는 Balanced의 약어
- 어떤 값으로 탐색하더라도 인덱스 루트에서 리프 블록에 도달하기까지 읽는 블록 수가 같음을 의미
- 즉, 리프 블록까지의 높이는 항상 같다.

Hi