SQL
1.인덱스 구조 및 탐색

인덱스 구조 및 탐색 수직적 탐색 수평적 탐색 미리 보는 인덱스 튜닝 데이터를 찾는 두가지 방법 테이블을 전체 스캔 인덱스를 이용 소량의 데이터를 검색할 때 사용 인덱스 튜닝의 두가지 핵심 요소 인덱스 스캔 효율화 튜닝 인덱스 스캔 과정에서 발생하는 비효율을 줄이
2.인덱스 기본 사용법
인덱스 기본 사용법은 인덱스를 Range Scan 하는 방법을 의미인덱스를 정상적으로 사용한다 라는 표현은 리프 블록에서 스캔 시작점을 찾아 거기서부터 스캔하다가 중간에 멈추는 것을 의미즉, 리프블록 일부만 스캔하는 Index Range Scan을 의미인덱스 컬럼을 가
3.인덱스 확장기능 사용법
BTree 인덱스의 가장 일반적이고 정상적인 형태의 액세스 방식!인덱스 루트에서 리프 블록까지 수직적으로 탐색한 후에 필요한 범위만 스캔성능은 인덱스 스캔 범위, 테이블 액세스 횟수를 얼마나 줄일 수 있느냐로 결정됨.수직적 탐색 없이 인덱스 리프 블록을 처음부터 끝까지
4.테이블 액세스 최소화
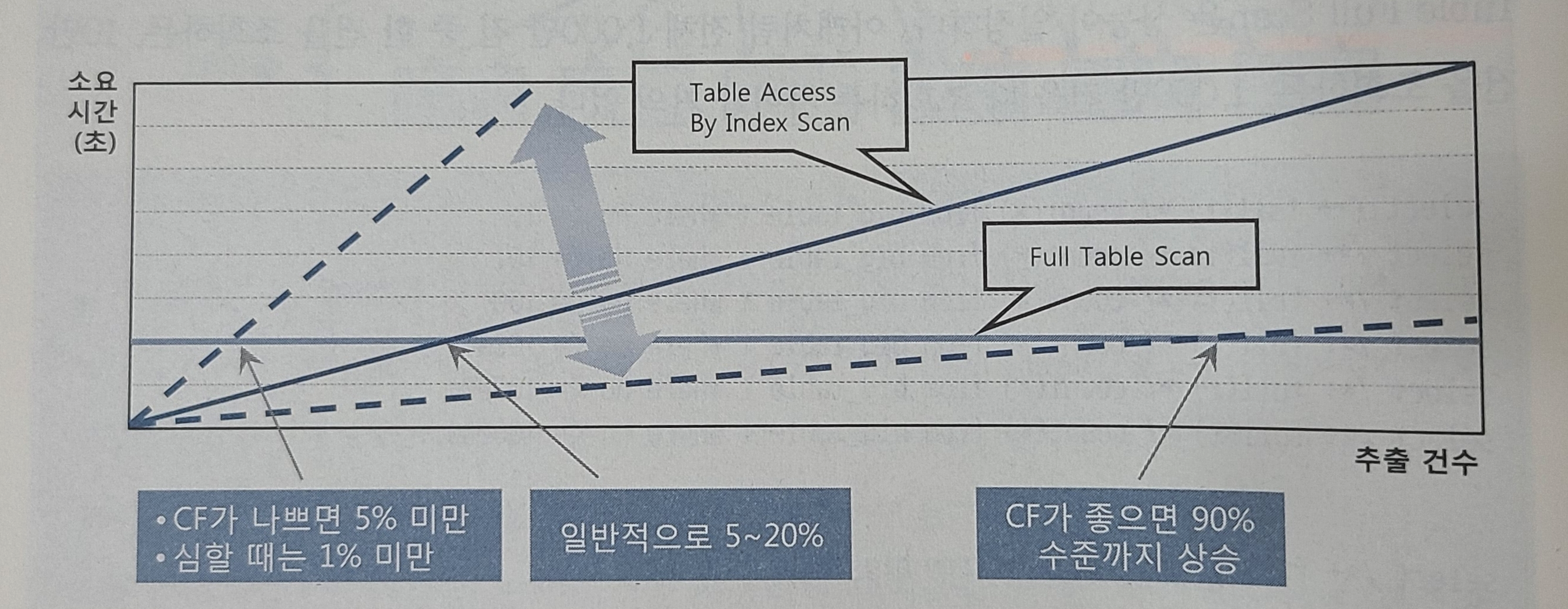
아무리 데이터가 많아도 인덱스를 사용하면 금방 조회대량 데이터를 조회할 때 인덱스를 사용하면 테이블 전체를 스캔할 때보다 훨씬 느림인덱스를 스캔하는 이유는 검색 조건을 만족하는 소량의 데이터를 인덱스에서 빨리 찾고 거기서 테이블 레코드를 찾아가기 위한 주소값(ROWID
5.부분범위 처리 활용
전체 쿼리 결과집합을 쉼 없이 연속적으로 전송하지 않고 사용자로 부터 Fetch Call이 있을 때마다 일정량씩 나누어 전송하는 것을 '부분범위 처리'라 한다.최초 rs.next() 호출 시 Fetch Call을 통해 DB 서버로 부터 전송받은 데이터 10건을 클라이언
6.인덱스 스캔 효율
수직적 탐색, 수평적 탐색인덱스 선행 컬럼이 조건절에 없거나 '=' 조건이 아니면 인덱스 스캔 과정에서 비효율 발생액세스 조건인덱스 스캔 범위를 결정하는 조건절인덱스 수직적 탐색을 통해 시작점을 결정하는데 영향을 미침인덱스 리프 블록을 스캔하다가 어디서 멈출지를 결정하
7.인덱스 설계
DML 성능 저하(-> TPS 저하)데이터베이스 사이즈 증가 (-> 디스크 공간 낭비)데이터베이스 관리 및 운영 비용 상승조건절에 항상 사용하거나, 자주 사용하는 컬럼을 선정'=' 조건으로 자주 조회하는 컬럼을 앞쪽에 둔다.수행 빈도(가장 중요한 하나)업무상 중요도클러
8.NL 조인
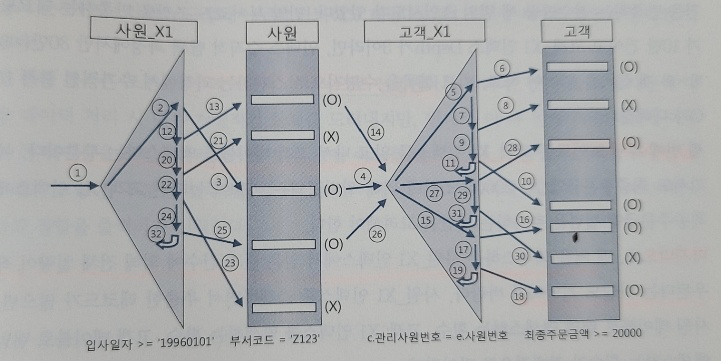
인덱스를 이용한 조인 방식Outer와 Inner 양쪽 테이블 모두 인덱스를 이용Outer쪽 테이블은 사이즈가 크지 않으면 인덱스를 이용하지 않을 수 있다.Inner 쪽 테이블은 인덱스를 사용해야 한다.ordered 힌트 : From 절에 기술한 순서대로 조인하라고 옵티
9.소트 머지 조인
조인 컬럼에 인덱스가 없을 때, 대량의 데이터 조인이어서 인덱스가 효과적이지 않을 때, 옵티마이저는 NL조인 대신 소트 머지 조인이나 해시 조인을 선택한다.SGA공유 메모리 영역인 SGA에 캐시된 데이터는 여러 프로세스가 공유할 수 있다.여러 프로세스가 공유할 수 있지
10.해시 조인
트 머지 조인은 항상 양쪽 테이블을 정렬하는 부담이 있는데, 해시 조인은 그런 부담도 없다.Build 단계 \- 작은 쪽 테이블을 읽어 해시 테이블을 생성한다.아래 조건에 해당하는 사원 데이터를 읽어 해시 테이블을 생성한다.사원번호를 해시 함수에 입력해서 반환된
11.서브쿼리 조인
\-하나의 SQL문 안에 괄호로 묶은 별도의 쿼리 블록을 말한다.인라인 뷰From 절에 사용한 서브쿼리중첩된 서브쿼리WHERE 절에 사용한 서브쿼리서브쿼리가 메인쿼리 컬럼을 참조하는 형태를 '상관관계 있는 서브쿼리'라 함스칼라 서브쿼리한 레코드당 정확히 하나의 값을 반