테이블 랜덤 액세스
- 아무리 데이터가 많아도 인덱스를 사용하면 금방 조회
- 대량 데이터를 조회할 때 인덱스를 사용하면 테이블 전체를 스캔할 때보다 훨씬 느림
인덱스 ROWID는 물리적 주소? 논리적 주소?
- 인덱스를 스캔하는 이유는 검색 조건을 만족하는 소량의 데이터를 인덱스에서 빨리 찾고 거기서 테이블 레코드를 찾아가기 위한 주소값(ROWID)을 얻기 위해서이다.
- ROWID는 물리적 주소보다 논리적 주소에 가깝다.
- ROWID는 물리적으로 직접 연결되지 않고 테이블 레코드를 찾아가기 위한 논리적 주소 정보를 담고 있음.
- 인덱스 ROWID는 논리적 주소 - 디스크 상에서 테이블 레코드를 찾아가기 위한 위치 정보를 담는다!
메인 메모리 DB와 비교
- 메인 메모리 DB는 데이터를 모두 메모리에 로드해 놓고 메모리를 통해서만 I/O를 수행하는 DB
- 즉, 빠르다!
- 일반 DBMS에서 인덱스 ROWID를 이용한 테이블 액세스가 생각만큼 빠르지 않다!
I/O 매커니즘 복습
- DBA(데이터파일번호 + 블록번호)는 디스크 상에서 블록을 찾기 위한 주소
I/O 성능을 높이려면 버퍼캐시를 활용
블록을 읽을 때는 디스크로 가기 전에 버퍼캐시부터 찾아봄
읽고자 하는 DBA를 해시 함수에 입력해서 해시 체인을 찾고 거기서 버퍼 헤더를 찾는다
캐시에 적재할 때와 읽을 때 같은 해시 함수를 사용하므로 버퍼 헤더는 항상 같은 해시 체인에 연결됨
반면, 실제 데이터가 담긴 버퍼 블록은 매번 다른 위치에 캐싱되는데
그 메모리 주소값을 버퍼 헤더가 가지고 있음 - 해싱 알고리즘으로 버퍼 헤더를 찾고 거기서 얻은 포인터로 버퍼 블록을 찾아감.
- 인덱스로 테이블 블록을 액세스할 때는 리프 블록에서 읽은 ROWID를 분해해서 DBA 정보를 얻고
테이블을 Full Scan 할 때는 익스텐트 맵(각 익스텐트의 첫 번째 블록 주소 값을 갖음)을 통해 읽은 블록들의 DBA 정보를 얻는다. - ROWID가 가리키는 테이블 블록을 버퍼캐시에 먼저 찾아보고, 못 찾을 때만 디스크에서 블록을 읽음.(버퍼캐시에 적재한 후에 읽음)
인덱스 ROWID는 우편 주소
우편주소 : 서울시 중구 무교동 123번지 타워 10층
ROWID : 7번 데이터 파일 123번 블록에 저장된 10번째 레코드
인덱스 클러스터링 팩터
- 클러스터링 팩터는 틀정 컬럼을 기준으로 같은 값을 갖는 데이터가 서로 모여있는 정도를 의미
- 클러스터링 팩터가 좋은 컬럼에 생성한 인덱스는 검색 효율이 매우 좋음
- 테이블 액세스량에 비해 블록 I/O가 적게 발생함을 의미
- 위와 반대로 좋지 않은 컬럼에 생성한 인덱스는 검색 효율이 매우 나쁨
인덱스 손익분기점
- 인덱스 ROWID를 이용한 테이블 액세스는 생각보다 고비용!
- 일겅야 할 데이터가 일정량을 넘는 순간, 테이블 전체를 스캔하는 것보다 오리혀 느리다.
- Index Range Scan에 의한 테이블 액세스가 Table Full Scan보다 느려지는 지점 = 인덱스 손익분기점
- Table Full Scan의 성능이 일정함.
- 추출 건수가 많을수록 느려짐 (테이블 랜덤 액세스 때문)
| Table Full Scan | 인덱스 ROWID를 이용한 테이블 액세스 |
|---|---|
| 시퀄셜 액세스 | 랜덤 액세스 방식 |
| Multiblock I/O | Single Block I/O |
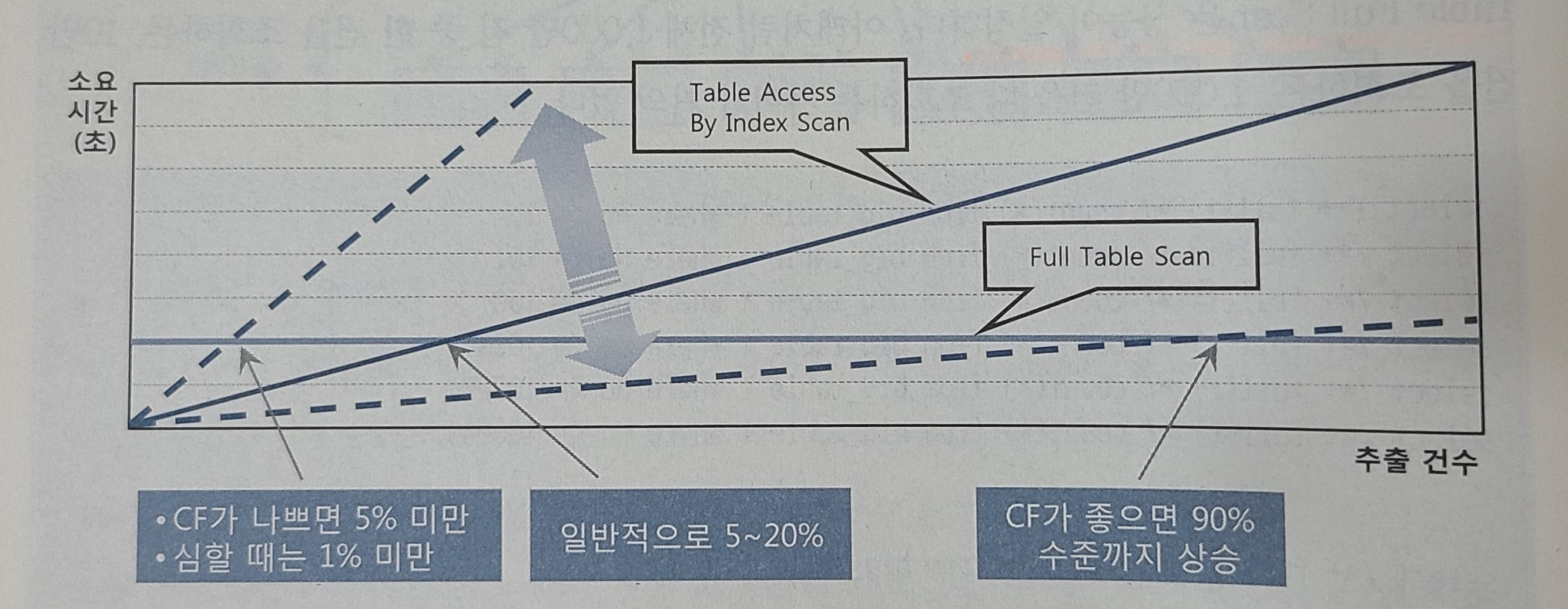
- 클러스터링 팩터가 나쁘면 손익분기점은 5%로 미만
- 클러스터링 팩터가 좋으면 손익분기점은 90% 수준까지 올라감.
- 테이블 스캔이 항상 나쁜것은 아니며, 인덱스 스캔이 항상 좋은 것도 아님!
온라인 프로그램 튜닝 vs 배치 프로그램 튜닝
- 온라인 프로그램
- 보통 소량의 데이터를 읽고 갱신하므로 인덱스를 효과적으로 활용하는 것이 중요
- 조인도 대부분 NL(Nested Loops) 방식을 사용
- 배치 프로그램
- 항상 전체범위 처리 기준으로 튜닝함
- 전체를 빠르게 처리하는 것을 목표로 삼아야 함
- 파티션 활용 전략이 매우 중요한 튜닝 요소이다.(왜? 대량은 Full Scan이 효과적이지만 초대용량은 상당히 오래 기다려야 하고 시스템에 주는 부담도 적지 않음)
- 병렬 처리까지 더할 수 있다면 엄청 좋음!!
인덱스 컬럼 추가
- 가장 일반적으로 사용하는 튜닝 기법은 인덱스에 컬럼을 추가
- 클러스터링 팩터가 좋은 인덱스를 사용하면테이블 액세스량에 비해 블록 I/O가 훨씬 적게 발생
인덱스만 읽고 처리
- 랜덤 엑세스가 아무리 많아도 필터 조건에 의해 버려지는 레코드가 거의 없다면 거기에는 비효율이 없다
- 인덱스 스캔 과정에서 얻은 데이터가 많다면 그만큼 테이블 랜덤 액세스가 많이 발생하므로 성능이 느림
- 성능의 개선하기 위해서는 쿼리에 사용된 컬럼을 모두 인덱스에 추가해서 테이블 액세스가 아예 발생하지 않게 하는 것!
- 인덱스만 읽어서 처리하는 쿼리를 Covered 쿼리라 한다.
- 그 쿼리에 사용한 인덱스를 Covered 인덱스라고 부름
Include 인덱스
- 인덱스 키 외에 미리 지정한 컬럼을 리프 레벨에 함께 저장하는 기능
- 순전히 테이블 랜덤 액세스를 줄이는 용도로 개발됨
- 인덱스를 생성할 때 include 옵션을 지정하면 됨
create index example on account (name) include (age)인덱스 구조 테이블
- 랜덤 액세스가 아예 발생하지 않아도 테이블을 인덱스 구조로 생성 -> IOT(Index Organized Table)
- 테이블을 찾아가기 위한 ROWID를 갖는 인덱스와 달리 IOT는 그 자리에 테이블 데이터를 갖는다.
- 인덱스 리프 블록이 곧 데이터 블록
- 테이블을 인덱스 구조로 만드는 구문
create table ...;
origanization index;- 인덱스 구조 테이블이므로 정렬 상태를 유지하며 데이터를 입력함.
- 일반 테이블은 힙 구조 테이블이라 부름
create table ...;
origanization heap; // 테이블을 생성할 때 생략됨.- 데이터를 입력할 때 랜덤 방식을 사용
- Freelist로 부터 할당 받은 블록에 정해진 순서 없이 데이터를 입력
클러스터 테이블
인덱스 클러스터 테이블
- 클러스터 키 값이 같은 레코드를 한 블록에 모아서 저장하는 구조
- 여러 테이블 레코드를 같은 블록에 저장(다중 테이블 클러스터)
- 일반 테이블은 하나의 데이터 블록을 여러 테이블이 공유할 수 없음
- 클러스터형 인덱스는 IOT에 가까움
- 클러스터를 생성한 후 클러스터 인덱스를 정의 후 테이블을 생성
- 클러스터 인덱스는 데이터 검색 용도로 사용할 뿐만 아니라 데이터가 저장될 위치를 찾을 때도 사용함
- 일반 테이블에 생성한 인덱스 레코드는 테이블 레코드와 1:1 대응 관계를 갖음
- 클러스터 인덱스는 테이블 레코드와 1:M 관계를 갖음
- 클러스터 인덱스의 키는 항상 Unique하다.
해시 클러스터 테이블
- 인덱스를 사용하지 않고 해시 알고리즘을 사용해 클러스터를 찾아간다는 점만 다르다.
- 클러스터를 생성 -> 클러스터 테이블 생성

Hi