[SK shieldus Rookies 19기][Python] 4일차 (많다 많아!)
파일 생성 및 사용 기초
파이썬에서 파일을 다루는 기본적인 방법에 대해 알아보겠습니다. 파일을 생성, 쓰기, 읽기, 추가하기 등의 작업을 할 수 있으며, 이를 통해 데이터를 영구적으로 저장하고 필요할 때마다 불러와 사용할 수 있습니다.
파일 생성하기
# 파일을 쓰기 모드로 열어 새 파일 생성
f = open("새파일.txt", 'w')
f.close()- open 함수는 파일을 열 때 사용하며, 파일 이름과 파일 열기 모드를 인자로 받는다.
- 파일 열기 모드에는 주로 사용되는 것으로 'r'(읽기), 'w'(쓰기), 'a'(추가)가 있다.
- 'w' 모드로 파일을 열면, 해당 파일이 이미 존재한다면 내용이 모두 사라지고, 존재하지 않는다면 새로운 파일이 생성된다.
- close 함수는 열린 파일 객체를 닫아주며, 이는 필수적인 작업은 아니지만 좋은 습관이다.
파일에 내용 쓰기
f = open("새파일.txt", 'w')
for i in range(1, 11):
data = "%d번째 줄입니다.\n" % i
f.write(data)
f.close()- 파일 객체의 write 함수를 사용하여 파일에 데이터를 쓸 수 있다.
- 이 예제에서는 1부터 10까지의 숫자를 파일에 쓰고 있다.
파일 읽기
파일에서 데이터를 읽는 방법은 여러 가지가 있다:
readline() 함수 사용: 한 번에 한 줄씩 읽는다.
f = open("새파일.txt", 'r')
line = f.readline()
print(line)
f.close()readlines() 함수 사용: 파일의 모든 줄을 읽어 각 줄을 요소로 갖는 리스트로 반환한다.
f = open("새파일.txt", 'r')
lines = f.readlines()
for line in lines:
print(line.strip()) # strip() 함수로 줄바꿈 문자 제거
f.close()read() 함수 사용: 파일 내용 전체를 문자열로 반환한다.
python
Copy code
f = open("새파일.txt", 'r')
data = f.read()
print(data)
f.close()파일 객체를 이용한 반복문 사용: 파일 내용을 줄 단위로 읽어 처리할 수 있다.
f = open("새파일.txt", 'r')
for line in f:
print(line.strip())
f.close()파일에 내용 추가하기
f = open("새파일.txt", 'a')
for i in range(11, 20):
data = "%d번째 줄입니다.\n" % i
f.write(data)
f.close()'a' 모드로 파일을 열면, 파일의 끝에 새로운 내용을 추가할 수 있다.
with 문과 함께 파일 사용하기
with open("foo.txt", "w") as f:
f.write("Life is too short, you need python")with 문을 사용하면, 파일을 사용한 작업이 끝난 후 자동으로 파일을 닫아준다. 이는 파일을 닫는 것을 잊을 걱정 없이 코드를 더 깔끔하게 작성할 수 있게 해준다.
실습. 성적 데이터 파일을 읽어서 이름, 과목별 점수, 합계, 평균 정보를 출력
C:\python\score_data.txt 파일 생성
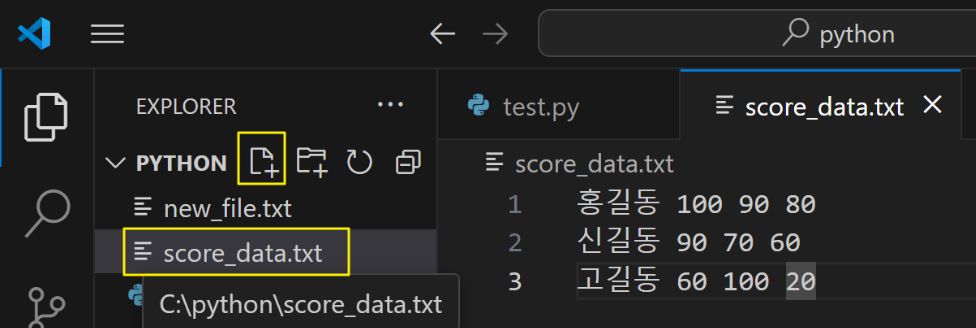
출력 예)
이 름 국어 영어 수학 합계 평균
====== ==== ==== ==== ==== ====
홍길동 100 90 80 270 90
신길동 90 70 60 220 73 ⇐ 평균은 반올림
고길동 60 100 20 180 60
프로그램 로직을 주석으로 기술
# 점수 데이터 파일을 오픈
with open('score_data.txt', 'r', encoding='utf-8') as file:
# 타이틀을 출력
# 파일을 행 단위로 읽어서 처리
for line in file:
# 개행문자를 제거
# 공백문자를 기준으로 분리
# 이름을 추출
# 점수를 추출
# 합계를 계산
# 평균을 계산
# 이름, 점수, 합계, 평균을 출력주석에 맞는 로직을 구현
# 점수 데이터 파일을 오픈
with open('score_data.txt', 'r', encoding='utf-8') as file:
# 타이틀을 출력
print('====== ==== ==== ==== ==== ====')
print('이 름 국어 영어 수학 합계 평균')
print('====== ==== ==== ==== ==== ====')
# 파일을 행 단위로 읽어서 처리
for line in file:
# 개행문자를 제거
line = line.strip()
# 공백문자를 기준으로 분리
datas = line.split()
# 이름을 추출
name = datas[0]
# 점수를 추출
scores = datas[1:]
# 합계를 계산
sum = 0
for score in scores:
sum += int(score)
# 평균을 계산
average = int(sum / len(scores))
# 이름, 점수, 합계, 평균을 출력
print(f"{name:3}", end=" ")
for score in scores:
print(f"{int(score):4}", end=" ")
print(f"{sum:4}", end=" ")
print(f"{average:4}")코드를 단순화하기 위해 함수로 대체
# 리스트에 들어 있는 모든 정수의 합을 계산해서 반환하는 함수
def calurate_sum(scores):
sum = 0
for score in scores:
sum += int(score)
return sum
# 리스트에 들어 있는 모든 정수의 평균을 계산해서 반환하는 함수
def calurate_average(scores):
return int(calurate_sum(scores) / len(scores))
def print_title():
print('====== ==== ==== ==== ==== ====')
print('이 름 국어 영어 수학 합계 평균')
print('====== ==== ==== ==== ==== ====')
def print_data(name, scores, sum, average):
print(f"{name:3}", end=" ")
for score in scores:
print(f"{int(score):4}", end=" ")
print(f"{sum:4}", end=" ")
print(f"{average:4}")
# 점수 데이터 파일을 오픈
with open('score_data.txt', 'r', encoding='utf-8') as file:
# 타이틀을 출력 ==> 함수로 대체
# print('====== ==== ==== ==== ==== ====')
# print('이 름 국어 영어 수학 합계 평균')
# print('====== ==== ==== ==== ==== ====')
print_title()
# 파일을 행 단위로 읽어서 처리
for line in file:
# 개행문자를 제거
line = line.strip()
# 공백문자를 기준으로 분리
datas = line.split()
# 이름을 추출
name = datas[0]
# 점수를 추출
scores = datas[1:]
# 합계를 계산 ==> 함수로 대체
# sum = 0
# for score in scores:
# sum += int(score)
sum = calurate_sum(scores)
# 평균을 계산 ==> 함수로 대체
#average = int(sum / len(scores))
average = calurate_average(scores)
# 이름, 점수, 합계, 평균을 출력 ==> 함수로 대체
# print(f"{name:3}", end=" ")
# for score in scores:
# print(f"{int(score):4}", end=" ")
# print(f"{sum:4}", end=" ")
# print(f"{average:4}")
print_data(name, scores, sum, average)주석을 제거 (가독성 향상 여부를 확인하기 위해)
def calurate_sum(scores):
sum = 0
for score in scores:
sum += int(score)
return sum
def calurate_average(scores):
return int(calurate_sum(scores) / len(scores))
def print_title():
print('====== ==== ==== ==== ==== ====')
print('이 름 국어 영어 수학 합계 평균')
print('====== ==== ==== ==== ==== ====')
def print_data(name, scores, sum, average):
print(f"{name:3}", end=" ")
for score in scores:
print(f"{int(score):4}", end=" ")
print(f"{sum:4}", end=" ")
print(f"{average:4}")
with open('score_data.txt', 'r', encoding='utf-8') as file:
print_title()
for line in file:
line = line.strip()
datas = line.split()
name = datas[0]
scores = datas[1:]
sum = calurate_sum(scores)
average = calurate_average(scores)
print_data(name, scores, sum, average)print_title() 함수 개선 및 print_tail() 함수 추가
def calurate_sum(scores):
sum = 0
for score in scores:
sum += int(score)
return sum
def calurate_average(scores):
return int(calurate_sum(scores) / len(scores))
def print_title():
# print('====== ==== ==== ==== ==== ====')
# print('이 름 국어 영어 수학 합계 평균')
# print('====== ==== ==== ==== ==== ====')
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
print('이 름 국어 영어 수학 합계 평균')
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
def print_tail():
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
def print_data(name, scores, sum, average):
print(f"{name:3}", end=" ")
for score in scores:
print(f"{int(score):4}", end=" ")
print(f"{sum:4}", end=" ")
print(f"{average:4}")
with open('score_data.txt', 'r', encoding='utf-8') as file:
print_title()
for line in file:
line = line.strip()
datas = line.split()
name = datas[0]
scores = datas[1:]
sum = calurate_sum(scores)
average = calurate_average(scores)
print_data(name, scores, sum, average)
print_tail()최종 결과
====== ==== ==== ==== ==== ====
이 름 국어 영어 수학 합계 평균
====== ==== ==== ==== ==== ====
홍길동 100 90 80 270 90
신길동 90 70 60 220 73
고길동 60 100 20 180 60
====== ==== ==== ==== ==== ====
파일 생성 및 데이터 처리
파일 생성하기
- 파이썬에서 파일을 생성하려면 open 함수를 사용한다. 이 함수는 파일명과 함께 파일을 어떻게 사용할지 결정하는 모드를 인자로 받는다.
# 파일 생성하기
f = open("새파일.txt", 'w')
f.close()파일 열기 모드
'r': 읽기 모드
'w': 쓰기 모드
'a': 추가 모드
'w' 모드로 파일을 열 경우, 해당 파일이 이미 존재하면 내용이 모두 사라지고, 존재하지 않으면 새 파일이 생성된다.
파일에 내용 쓰기
파일을 쓰기 모드로 열고, write 메소드를 사용해 파일에 데이터를 쓸 수 있다.
f = open("새파일.txt", 'w')
for i in range(1, 11):
data = f"{i}번째 줄입니다.\n"
f.write(data)
f.close()파일 읽기
파일에서 데이터를 읽는 방법은 여러 가지가 있다.
readline() 함수: 파일의 첫 번째 줄을 읽어 출력
readlines() 함수: 파일의 모든 줄을 읽어 각 줄을 요소로 하는 리스트로 반환
read() 함수: 파일 내용 전체를 문자열로 반환
파일 객체를 이용: 파일 객체를 for 문과 함께 사용하여 파일의 내용을 줄 단위로 읽음
# readline() 예시
f = open("새파일.txt", 'r')
line = f.readline()
print(line)
f.close()# readlines() 예시
f = open("새파일.txt", 'r')
lines = f.readlines()
for line in lines:
print(line.strip()) # 줄바꿈 문자 제거
f.close()# read() 예시
f = open("새파일.txt", 'r')
data = f.read()
print(data)
f.close()파일에 내용 추가하기
파일의 내용을 유지하면서 새로운 내용을 추가하려면 파일을 추가 모드('a')로 연다.
f = open("새파일.txt", 'a')
for i in range(11, 20):
data = f"{i}번째 줄입니다.\n"
f.write(data)
f.close()with 문과 함께 사용하기
with 문을 사용하면 파일을 자동으로 닫아주기 때문에 close() 메소드를 명시적으로 호출할 필요가 없다. 이 방법은 파일 작업을 더 안전하게 만들어 준다.
with open("새파일.txt", "w") as f:
f.write("Life is too short, you need python")실습. 프로그램 실행시 전달받은 문장에 포함된 글자(문자)의 사용 회수를 계산해서 출력
실행 예)
python test.py "This is sample program"
입력 ⇒ This is sample program
T => 1
h => 1
i => 2
s => 3
:
import sys
sentence = sys.argv[1]
print(f"입력 => {sentence}")
# 글자(키)와 글자의 사용 회수(값)를 가지는 딕셔너리
char_count = dict()
# 입력받은 문장에서 한 글자씩을 추출해서 딕셔너리에 추가
for char in sentence:
# 딕셔너리에 해당 글자가 존재하는 경우, 사용 회수를 증가
if char in char_count:
char_count[char] = char_count[char] + 1
# 딕셔너리에 해당 글자가 존재하지 않는 경우, 사용 회수로 1을 설정해서 추가
else:
char_count[char] = 1
# 딕셔너리를 순회하면서 출력
for char in char_count:
print(f"{char} => {char_count[char]}")PS C:\python> python test.py "This is sample program"
입력 => This is sample program
T => 1
h => 1
i => 2
s => 3
=> 3
a => 2
m => 2
p => 2
l => 1
e => 1
r => 2
o => 1
g => 1
위의 프로그램을 출련한 (대소문자를 구분하지 않은) 알파벳과 그 회수로 제한하고 알파벳 순으로 정렬해서 출력하도록 수정해 보세요. (공백, 특수문자는 대상에서 제외)
PS C:\python> python test.py "T & t is sampe char."
입력 => T & t is sampe char.
a => 2
c => 1
:
i => 1
s => 1
t => 2
import sys
sentence = sys.argv[1]
print(f"입력 => {sentence}")
char_count = dict()
for char in sentence:
# 알파벳을 소문자로 변경
char = char.lower()
# 알파벳이 아닌 경우 다음 글자를 처리
if char < 'a' or char > 'z':
continue
if char in char_count: char_count[char] = char_count[char] + 1
else: char_count[char] = 1
# 알파벳(키)를 기준으로 정렬한 결과를 출력
for key in sorted(char_count.keys()):
print(f"{key} => {char_count[key]}")PS C:\python> python test.py "T & t is sampe char."
입력 => T & t is sampe char.
a => 2
c => 1
e => 1
h => 1
i => 1
m => 1
p => 1
r => 1
s => 2
t => 2
import sys
# 문자열 예시
sentence = "T & t is same alphabet."
print(f"입력 => {sentence}")
char_count = {}
# 문자열을 순회하며 알파벳의 빈도를 계산
for char in sentence:
char = char.lower()
if char.isalpha():
if char in char_count:
char_count[char] += 1
else:
char_count[char] = 1
# 빈도수별로 알파벳을 분류
frequency = {}
for char, count in char_count.items():
if count in frequency:
frequency[count].append(char)
else:
frequency[count] = [char]
# 빈도수를 기준으로 내림차순 정렬
sorted_freq = sorted(frequency.items(), key=lambda x: x[0], reverse=True)
# 결과 출력
for count, chars in sorted_freq:
print(f"{count} => {sorted(chars)}")실습. 위의 프로그램을 가장 많이 나온 알파벳 순으로 출력하도록 수정
PS C:\python> python test.py "T & t is same alphabet."
입력 => T & t is same alphabet.
3 => [ 'a', 't' ]
2 => [ 'e', 's' ]
1 => [ 'b', 'h', 'i', 'l', 'm' ]
import sys
sentence = sys.argv[1]
print(f"입력 => {sentence}")
char_count = dict()
for char in sentence:
char = char.lower()
if char < 'a' or char > 'z':
continue
if char in char_count: char_count[char] = char_count[char] + 1
else: char_count[char] = 1
# 회수(숫자)를 키로 가지고, 문자 리스트를 값으로 가지는 딕셔너리를 정의
# { 3: ['a', 'b', 'c'], 2: ['x', 'y'] }
count_char = {}
for char in sorted(char_count.keys()):
count = char_count[char]
if count in count_char: count_char[count].append(char)
else: count_char[count] = [char]
# 회수(키) 내림차순으로 정렬해서 출력
for key in sorted(count_char.keys(), reverse=True):
print(f"{key} => {count_char[key]}")
프로그램 통합
c:\python\hangman.py
import re
import random
#words = input('여러 단어로 구성된 문장을 입력하세요. ')
words = "Visit BBC for trusted reporting on the latest world and US news, sports, business, climate, innovation, culture and much more."
print(f"입력 : {words}")
# 문장부호를 제거 ! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ ] ^ _ ` { | } ~ \
words = re.sub(r'[!"#$%&\'()*+,-./:;<=>?@\[\]^_\`{|}~\\\\]', '', words)
# 공백문자를 기준으로 단어를 분리
words = words.split()
# 임의의 단어를 추출
rand_word = list(words[random.randrange(len(words))])
# 화면에 출력할 내용
disp_word = list('_' * len(rand_word))
print(f'힌트 >>> {''.join(disp_word)}')
try_count = 0
while True:
try_count += 1
alpha = input(f'{try_count} 시도 >>> 영어 단어를 구성하는 알파벳을 입력하세요. ')
for i, a in enumerate(rand_word):
if alpha == a:
disp_word[i] = alpha
print(f'힌트 >>> {''.join(disp_word)}')
if disp_word.count('_') == 0:
print(f'정답 "{''.join(rand_word)}"를 {try_count}번 만에 맞췄습니다.')
break
elif try_count >= 10:
print(f'10번에 기회가 모두 끝났습니다. 정답은 "{''.join(rand_word)}" 입니다.')
breakc:\python\score.py
def calurate_sum(scores):
sum = 0
for score in scores:
sum += int(score)
return sum
def calurate_average(scores):
return int(calurate_sum(scores) / len(scores))
def print_title():
# print('====== ==== ==== ==== ==== ====')
# print('이 름 국어 영어 수학 합계 평균')
# print('====== ==== ==== ==== ==== ====')
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
print('이 름 국어 영어 수학 합계 평균')
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
def print_tail():
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
def print_data(name, scores, sum, average):
print(f"{name:3}", end=" ")
for score in scores:
print(f"{int(score):4}", end=" ")
print(f"{sum:4}", end=" ")
print(f"{average:4}")
with open('score_data.txt', 'r', encoding='utf-8') as file:
print_title()
for line in file:
line = line.strip()
datas = line.split()
name = datas[0]
scores = datas[1:]
sum = calurate_sum(scores)
average = calurate_average(scores)
print_data(name, scores, sum, average)
print_tail()c:\python\counter.py
import sys
sentence = sys.argv[1]
print(f"입력 => {sentence}")
char_count = dict()
for char in sentence:
char = char.lower()
if char < 'a' or char > 'z':
continue
if char in char_count: char_count[char] = char_count[char] + 1
else: char_count[char] = 1
# 회수(숫자)를 키로 가지고, 문자 리스트를 값으로 가지는 딕셔너리를 정의
# { 3: ['a', 'b', 'c'], 2: ['x', 'y'] }
count_char = {}
for char in sorted(char_count.keys()):
count = char_count[char]
if count in count_char: count_char[count].append(char)
else: count_char[count] = [char]
# 회수(키) 내림차순으로 정렬해서 출력
for key in sorted(count_char.keys(), reverse=True):
print(f"{key} => {count_char[key]}")c:\python\main.py
=================
1. 행맨
2. 점수계산
3. 알파벳 카운터
Q. 종료
실행할 프로그램의 번호를 입력하세요. : 1
메뉴를 출력하고 메뉴 번호를 입력 받아서 동작하는 것을 확인
def show_menu():
print("""
=================
1. 행맨
2. 점수계산
3. 알파벳 카운터
Q. 종료
=================
""")
while True:
show_menu()
menu = input("실행할 프로그램의 번호를 입력하세요. : ")
if menu == 'Q':
print("프로그램을 종료합니다.")
break
menu = int(menu)
if menu == 1:
print("행맨 실행")
elif menu == 2:
print("점수 계산 실행")
elif menu == 3:
print("알파벳 카운트 실행")
else:
print("잘못된 입력입니다. 다시 시도해 주세요.")행맨 소스 코드를 모듈화
import re
import random
def main(): #main() 함수를 호출해야 실행되도록 수정
#words = input('여러 단어로 구성된 문장을 입력하세요. ')
words = "Visit BBC for trusted reporting on the latest world and US news, sports, business, climate, innovation, culture and much more."
print(f"입력 : {words}")
# 문장부호를 제거 ! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ ] ^ _ ` { | } ~ \
words = re.sub(r'[!"#$%&\'()*+,-./:;<=>?@\[\]^_\`{|}~\\\\]', '', words)
# 공백문자를 기준으로 단어를 분리
words = words.split()
# 임의의 단어를 추출
rand_word = list(words[random.randrange(len(words))])
# 화면에 출력할 내용
disp_word = list('_' * len(rand_word))
print(f'힌트 >>> {''.join(disp_word)}')
try_count = 0
while True:
try_count += 1
alpha = input(f'{try_count} 시도 >>> 영어 단어를 구성하는 알파벳을 입력하세요. ')
for i, a in enumerate(rand_word):
if alpha == a:
disp_word[i] = alpha
print(f'힌트 >>> {''.join(disp_word)}')
if disp_word.count('_') == 0:
print(f'정답 "{''.join(rand_word)}"를 {try_count}번 만에 맞췄습니다.')
break
elif try_count >= 10:
print(f'10번에 기회가 모두 끝났습니다. 정답은 "{''.join(rand_word)}" 입니다.')
break
if __name__ == '__main__': #모듈 import 시에는 실행되지 않도록 제한
main() #모듈을 직접 실행했을 때만 실행main 모듈에서 행맨 모듈을 추가하고 메뉴 선택 시 모듈의 실행 함수를 호출
import hangman #행맨 모듈을 (사용하기 위해서) 추가
def show_menu():
print("""
=================
1. 행맨
2. 점수계산
3. 알파벳 카운터
Q. 종료
=================
""")
while True:
show_menu()
menu = input("실행할 프로그램의 번호를 입력하세요. : ")
if menu == 'Q':
print("프로그램을 종료합니다.")
break
menu = int(menu)
if menu == 1:
print("행맨 실행")
hangman.main() #행맨 모듈의 실행 함수를 호출
elif menu == 2:
print("점수 계산 실행")
elif menu == 3:
print("알파벳 카운트 실행")
else:
print("잘못된 입력입니다. 다시 시도해 주세요.")점수 계산 코드를 모듈화
def calurate_sum(scores):
sum = 0
for score in scores:
sum += int(score)
return sum
def calurate_average(scores):
return int(calurate_sum(scores) / len(scores))
def print_title():
# print('====== ==== ==== ==== ==== ====')
# print('이 름 국어 영어 수학 합계 평균')
# print('====== ==== ==== ==== ==== ====')
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
print('이 름 국어 영어 수학 합계 평균')
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
def print_tail():
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
def print_data(name, scores, sum, average):
print(f"{name:3}", end=" ")
for score in scores:
print(f"{int(score):4}", end=" ")
print(f"{sum:4}", end=" ")
print(f"{average:4}")
def main():
with open('score_data.txt', 'r', encoding='utf-8') as file:
print_title()
for line in file:
line = line.strip()
datas = line.split()
name = datas[0]
scores = datas[1:]
sum = calurate_sum(scores)
average = calurate_average(scores)
print_data(name, scores, sum, average)
print_tail()
if __name__ == '__main__':
main()알파벳 카운트 코드를 모듈화
import sys
def main():
# sentence = sys.argv[1]
sentence = input("문장을 입력하세요. ")
print(f"입력 => {sentence}")
char_count = dict()
for char in sentence:
char = char.lower()
if char < 'a' or char > 'z':
continue
if char in char_count: char_count[char] = char_count[char] + 1
else: char_count[char] = 1
count_char = {}
for char in sorted(char_count.keys()):
count = char_count[char]
if count in count_char: count_char[count].append(char)
else: count_char[count] = [char]
for key in sorted(count_char.keys(), reverse=True):
print(f"{key} => {count_char[key]}")
if __name__ == '__main__':
main()main 모듈에 점수 계산 모듈과 알파벳 카운트 모듈을 추가
import hangman
import score
import counter
def show_menu():
print("""
=================
1. 행맨
2. 점수계산
3. 알파벳 카운터
Q. 종료
=================
""")
while True:
show_menu()
menu = input("실행할 프로그램의 번호를 입력하세요. : ")
if menu == 'Q':
print("프로그램을 종료합니다.")
break
menu = int(menu)
if menu == 1:
print("행맨 실행 ...")
hangman.main()
elif menu == 2:
print("점수 계산 실행 ...")
score.main()
elif menu == 3:
print("알파벳 카운트 실행 ...")
counter.main()
else:
print("잘못된 입력입니다. 다시 시도해 주세요.")클래스(Class)란?
클래스는 객체를 생성하기 위한 템플릿이다. 클래스에는 객체의 기본적인 구조와 동작을 정의한다. 예를 들어, Calculator 클래스는 계산기 객체의 구조와 계산기가 수행할 수 있는 연산들을 정의한다.
기본 구조
class Calculator:
def __init__(self): # 생성자
self.result = 0 # 인스턴스 변수 초기화
def add(self, num): # 메서드
self.result += num
return self.result
def sub(self, num):
self.result -= num
return self.result - init 메서드는 클래스의 생성자로, 객체가 생성될 때 자동으로 호출된다. 인스턴스 변수를 초기화한다.
- self 키워드는 인스턴스 자신을 가리킨다. 클래스 내에서 메서드를 호출하거나 인스턴스 변수에 접근할 때 사용한다.
- add와 sub 메서드는 계산기의 덧셈과 뺄셈 기능을 구현한다.
객체 생성 및 사용
cal1 = Calculator() # 객체 생성
print(cal1.add(3)) # 객체의 메서드 호출
print(cal1.sub(1)) # 다른 메서드 호출Calculator()는 Calculator 클래스의 인스턴스(객체)를 생성한다.
생성된 객체를 통해 정의된 메서드를 호출할 수 있다.
사칙연산 기능 추가
class Calculator:
def __init__(self, first, second): # 생성자에 파라미터 추가
self.first = first
self.second = second
def add(self):
return self.first + self.second
def sub(self):
return self.first - self.second
# mul, div 메서드 추가사칙 연산을 수행하는 메서드를 추가하여 클래스를 확장할 수 있다.
생성자와 메서드
객체가 생성될 때 자동으로 호출되는 특별한 메서드인 생성자를 통해 인스턴스 변수를 초기화할 수 있다.
생성자는 객체의 초기 상태를 설정하는 데 사용된다.
클래스의 목적
클래스는 데이터와 이를 조작하는 메서드를 함께 묶어 관리한다. 이는 코드의 재사용성을 높이고, 관리를 용이하게 한다.
오류 처리
def div(self):
if self.second == 0:
return 0 # 0으로 나누는 경우의 처리
return self.first / self.second메서드 내에서 오류 상황(예: 0으로 나누기)을 처리하여 프로그램의 안정성을 높일 수 있다.
클래스와 객체 지향 프로그래밍
- 클래스와 객체는 객체 지향 프로그래밍(OOP)의 핵심 요소이다.
- OOP는 코드의 재사용성, 확장성, 관리의 편리함을 제공한다.
시계 클래스를 구현
시계 클래스를 구현
import time
class Clock:
def __init__(self) -> None:
self.hour = 0
self.miniute = 0
self.second = 0
def print(self):
print(f"{self.hour}:{self.miniute}:{self.second}")
def add_one_hour(self):
self.hour += 1
if self.hour >= 24:
self.hour = 0
def add_one_minute(self):
self.miniute += 1
if self.miniute >= 60:
self.miniute = 0
self.add_one_hour()
def add_one_second(self):
self.second += 1
if self.second >= 60:
self.second = 0
self.add_one_minute()
c = Clock()
while True:
c.add_one_second()
c.print()
# time.sleep(1)