개요
태양광 발전량 예측 머신러닝 모델 개발 및 성능 비교
- EDA를 통해 데이터의 특징을 파악하고 모델링에 적용하였다.
- XGBoost, ExtraTrees, GradientBoosting, LGBM, RandomForest, SVM의 성능을 비교하여 데이터에 적합한 모델을 탐색하였다.
- 파생변수의 사용 여부와 최적의 모델 선택을 위한 실험을 진행하였다.
팀 프로젝트
Dacon 태양광 발전량 예측 AI 경진대회 [Site]
코드 & 실험 기록 [GitHub]
기간
2020.12 ~ 2021.01
배경 및 목적
태양광 발전은 매일의 기상 상황과 계절에 따른 일사량의 영향을 받는다. 이에 대한 예측이 가능하다면 보다 원활하게 전력 수급 계획을 세울 수 있다. 따라서 신재생에너지의 생산 효율성을 극대화하고, 사용자들에게 저렴한 전력을 공급할 수 있도록 인공지능 기반 태양광 발전량 예측 모델을 개발할 필요가 있다.
모델은 7일 동안의 데이터를 인풋으로 활용하여, 향후 2일 동안의 30분 간격의 발전량을 예측해야 한다.
역할
- EDA
- 데이터 전처리 및 파생변수 생성
- 머신러닝 모델 성능 비교
- XGBoost, ExtraTrees 모델링
EDA
사용 변수
TARGET : 태양광 발전량
DHI : 산란일사량
DNI : 직달일사량
GHI : 전일사량 (DHI+DNI)
WS : 풍속
RH : 상대습도
T : 기온
추세 그래프
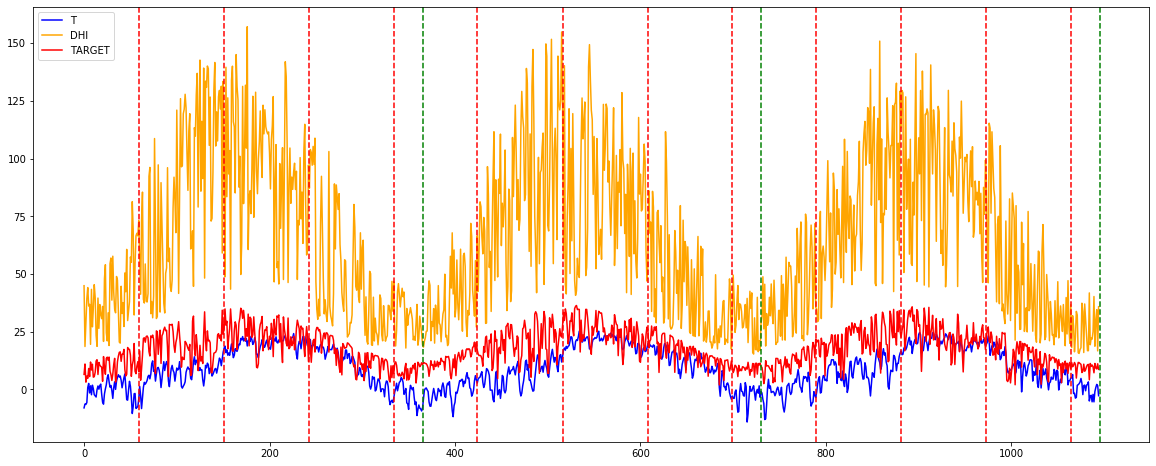
이 그래프는 데이터로 사용한 3년간의 발전량, 산란일사량, 기온을 표현한 것이다. 빨간색은 발전량, 주황색은 산란일사량, 파란색은 기온을 나타내고, 빨간색 세로점선은 계절의 경계선, 초록색 세로점선은 1년의 경계선을 나타낸다. 이 그래프를 통해 3가지 변수 모두 계절성이 있다는 것을 확인할 수 있다.
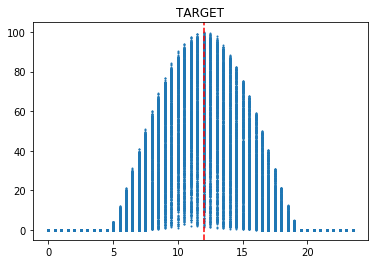
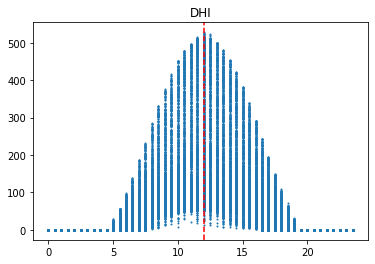
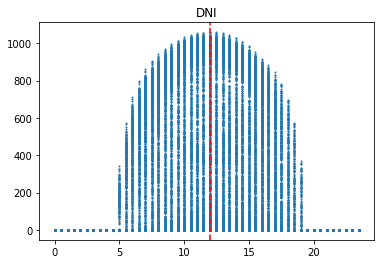
시간에 따른 변화
 |  |  |
|---|---|---|
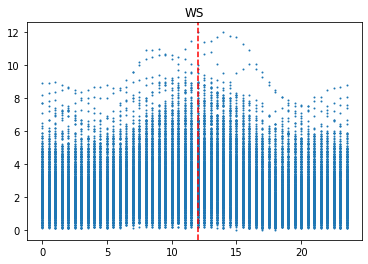 | 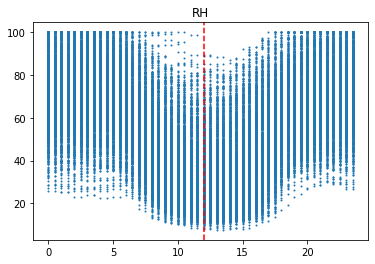 | 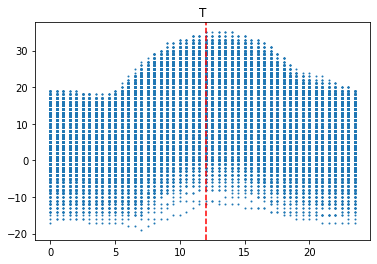 |
이 그래프는 발전량, 산란일사량(DHI), 직달일사량(DHI), 풍속(WS), 상대습도(RH), 기온(T)을 시간별로 표현한 것이다. 발전량, 일사량, 풍속은 12시를 기준으로 위로 볼록한 형태이고, 기온은 14시를 기준으로 위로 볼록한 형태이다. 반면에 상대습도는 14시를 기준으로 아래로 볼록한 형태이다. 이를 통해, 시간에 따른 특징이 명확하다는 사실을 확인할 수 있다.
그리고 발전량은 산란일사량과 그래프 형태가 유사하다. 이를 통해, 발전량은 산란일사량의 영향을 많이 받는다고 해석할 수 있다.
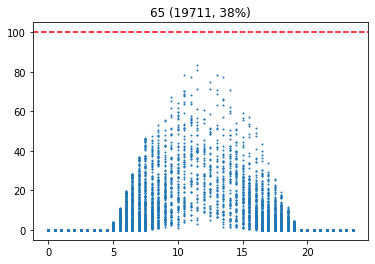
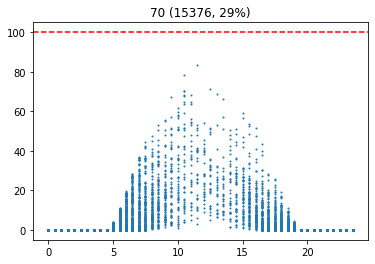
기준 습도별 발전량
 |  |  |
|---|---|---|
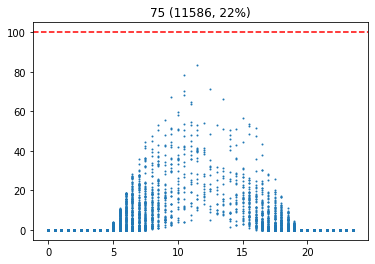 | 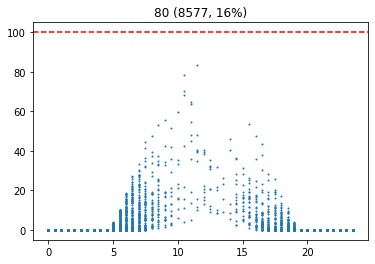 | 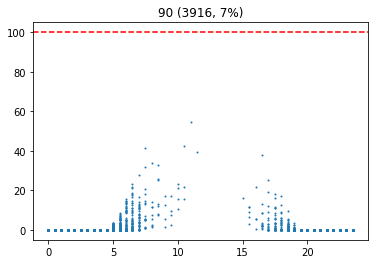 |
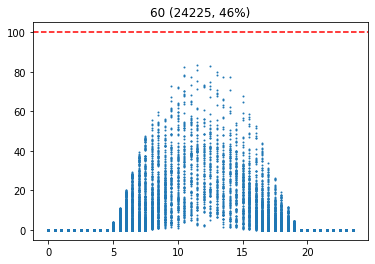
이 그래프는 습도에 대한 시간별 발전량을 표현한다. 이를 통해, 습도가 높을 수록 발전량이 적다는 사실을 확인할 수 있다.
습도가 높다는 것은 날씨가 흐리다는 것을 의미할 가능성이 높다. 따라서 습도를 통해 날씨에 대한 흐린 정도를 나타낼 수 있다. 습도가 70 이상인 경우를 흐림으로 설정하였다.
발전량
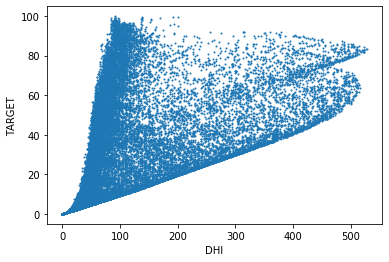 |  |  |
|---|---|---|
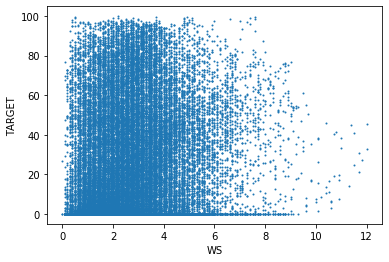 | 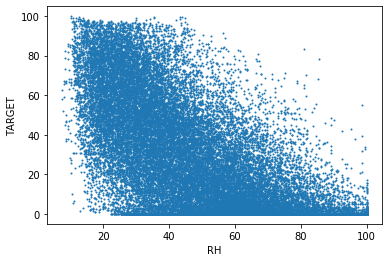 | 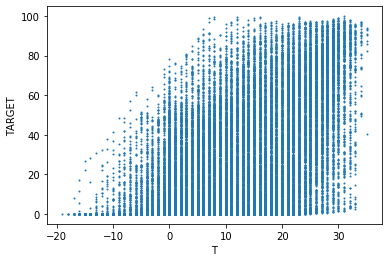 |
이 그래프는 발전량과 다른 변수들의 관계를 표현한다. 발전량과 일사량(DHI, DNI, GHI)은 강한 비례 관계를 보인다. 또한, 습도(RH)는 발전량과 반비례 관계이고, 기온(T)은 발전량과 비례 관계임을 알 수 있다.
풍속(WS)이 작을 때에는 발전량이 골고루 나타나지만 풍속이 클 때에는 발전량이 적다. 이는 보통 흐리거나 태풍이 오는 경우에 풍속이 크기 때문으로 추측할 수 있다. 추가로 일사량 그래프에는 직선의 형태도 보이는데, 이는 결측치를 처리한 흔적으로 추정한다.
일사량
 |  |
|---|
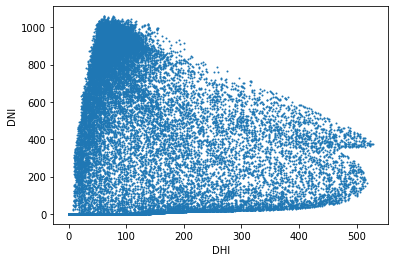
이 그래프는 산란일사량(DHI)에 대한 직달일사량(GHI), 전일사량(GHI)의 관계를 표현한다.
산란일사량과 직달일사량의 그래프를 보면, 산란일사량이 적으면서 직달 일사량이 많은 경우가 많다. 이를 통해, 산란일사량과 직달일사량은 약한 반비례 관계라고 할 수 있다.
산란일사량과 전일사량은 대체로 비례하지만, 산란일사량이 적을 때 전일사량이 높은 경우가 많다. 이는 산란일사량이 적고 직달일사량이 많을 때에 전일사량이 높은 경우가 많다는 의미라고 해석할 수 있다.
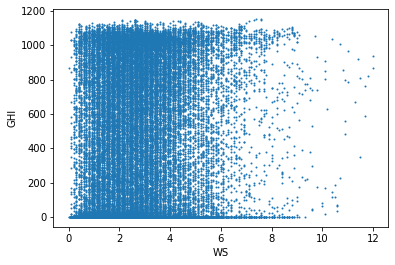
풍속과 일사량
 |  |  |
|---|
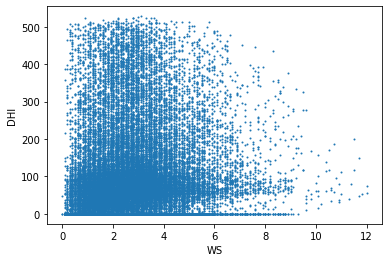
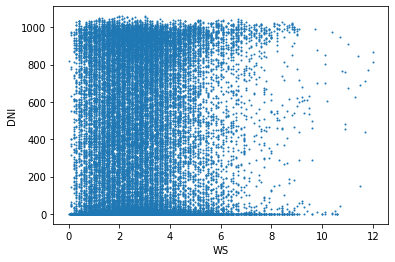
이 그래프는 풍속(WS)에 대한 산란일사량(DHI), 직달일사량(DNI), 전일사량(GHI)의 관계를 표현한다. 풍속이 작을 때 산란일사량이 적은 경우가 많고, 풍속이 작을 때 직달일사량이 많은 경우가 많다. 풍속과 산란일사량은 약한 비례관계이고, 풍속과 직달일사량은 약한 반비례관계이다.
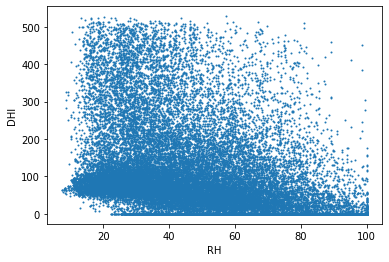
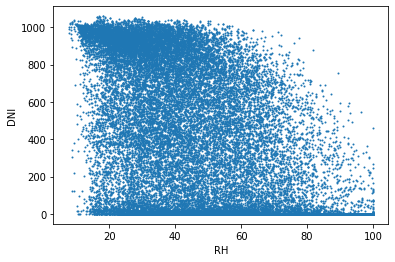
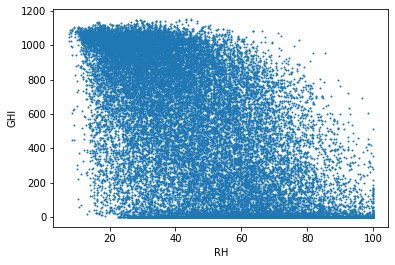
습도와 일사량
 |  |  |
|---|
이 그래프는 습도(RH)에 대한 산란일사량(DHI), 직달일사량(DNI), 전일사량(GHI)의 관계를 표현한다. 습도가 낮을 때 산란일사량이 적은 경우가 많고, 습도가 낮을 때 직달일사량이 많은 경우가 많다. 습도와 산란일사량은 약한 비례관계이고, 습도과 직달일사량은 약한 반비례관계이다.
파생변수 생성
태양광 발전량 예측을 해봤던 경험을 바탕으로 파생변수를 생성하였다. 사용한 파생변수는 다음과 같다.
- 태양광 발전량의 4일간 평균
- 계절별 태양광 발전량의 평균/사분위수
- 시간별 태양광 발전량의 평균/사분위수
- 태양광 발전량의 4일 자기회귀
- 일사량의 4일간 평균
- 계절별 일사량의 평균/사분위수
- 시간별 일사량의 평균/사분위수
머신러닝 모델 성능 비교
성능이 좋다고 알려진 모델인 XGBoost를 활용하여 태양광 발전량 예측을 수행하였다. 하지만 생각했던 것 만큼 XGBoost의 예측 성능이 만족스럽지 않아서 다른 모델로 변경하고자 하였다. 데이터에 적합한 머신러닝 모델을 선택하기 위해 다양한 모델들의 성능을 Cross Validation을 활용하여 비교하였다.
RandomForest
당일 발전량 예측 : 0.799
다음날 발전량 예측 : 0.790
SVM
당일 발전량 예측 : 0.787
다음날 발전량 예측 : 0.775
GradientBoosting
당일 발전량 예측 : 0.805
다음날 발전량 예측 : 0.792
LGBM
당일 발전량 예측 : 0.799
다음날 발전량 예측 : 0.788
XGBoost
당일 발전량 예측 : 0.778
다음날 발전량 예측 : 0.768
GradientBoosting > RandomForest = LGBM > SVM > XGBoost
이 실험을 통해 트리 계열의 모델도 시도해보는 것이 좋겠다는 생각이 들었다. 따라서 RandomForest보다 랜덤성이 더 가미된 ExtraTrees 모델을 활용하여 태양광 발전량 예측을 수행하였다.
LGBM : 1.864
GradientBoosting : 1.915
ExtraTrees : 1.934
RandomForest : 1.966
대회에서는 평가 지표로 퀀타일 예측값들을 종합한 Pinball Loss를 사용하였다. ExtraTrees 모델은 RandomForest보다 좋은 성능을 보였지만, GradientBoosting 계열의 모델들의 성능이 더 우수하였다.
배운점
처음에는 XGBoost 모델의 성능이 가장 좋을 것이라고 예측했지만 생각보다 만족스럽지 못해서 다양한 모델들을 비교해보았다. 확실히 데이터마다 성능이 좋은 모델이 다 다른 것 같다. 그렇기 때문에 본격적인 모델링 전에 실험을 통해 적절한 모델을 선택하는 것이 중요한 것 같다.
그리고 이번에는 데이터의 특징을 제대로 파악하고 싶어서 EDA를 디테일하게 해보았다. 이렇게 EDA를 하면서 데이터에 대한 이해도가 올라가고, 주제에 대한 방향성이 잡히는 느낌이 들었다. 모델링 전에 데이터 분석을 소홀이 하면 안된다는 것을 다시 한번 느꼈다.
