음악 추천 서비스 Au-Dionysos에 사용된 GraphSAGE 구현 코드 리뷰
추천 파이프라인
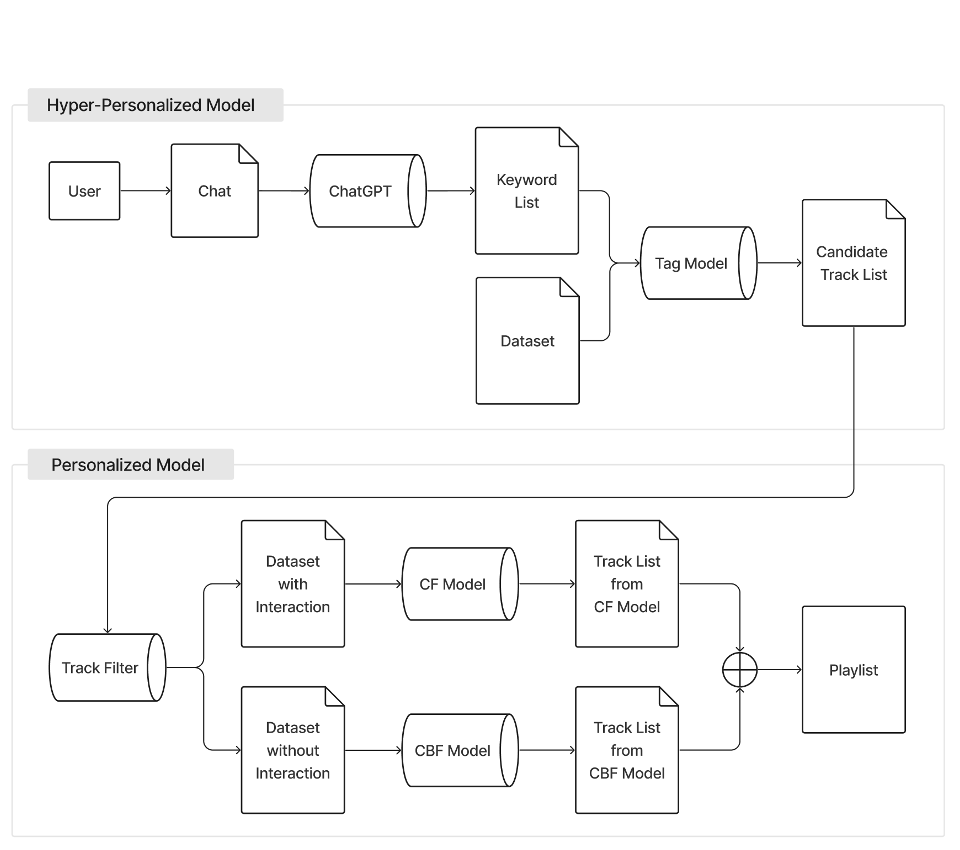
-
ChatGPT : 사용자가 입력한 텍스트에서 Keyword(Tag)를 추출한다. 기존 Track들이 가진 고유의 Tag들을 바탕으로 텍스트와 감정, 상황, 맥락적으로 가장 적합한 태그 5개를 추출한 뒤 반환한다.
-
Tag Model : Track과 Tag의 관계를 GraphSAGE 구조로 학습한다. 입력된 Tag와 관련된 Track을 추천한다.
-
Track Filter : User-Track interaction의 유무로 데이터를 나눈다. LastFM 데이터에는 Interaction 정보가 존재하지만, Spotify 데이터에는 Interaction 정보가 존재하지 않기 때문에 두 가지 모델로 나누어 학습한다.
-
CF Model : User의 청취 기록을 바탕으로 User 임베딩을 생성한다. User와 Track의 관계를 GraphSAGE 구조로 학습하고, Track과 Genre Tag의 관계를 보조적으로 활용한다. 입력된 User가 좋아할만한 Track을 추천한다.
-
CBF Model : Track과 Genre Tag의 관계를 GraphSAGE 구조로 학습한다. 입력된 Track과 유사한 Track을 추천한다.
-
Shuffle : CBF Model의 결과와 CF Model의 결과를 하나씩 번갈아 출력하는 방식으로 Shuffle한다.
폴더 구조
📦models
┣ 📂EDA
┣ 📂graphsage_cbf
┃ ┣ 📜args_cbf.py
┃ ┣ 📜args_tag.py
┃ ┣ 📜data_preprocessing.py
┃ ┣ 📜model.py
┃ ┣ 📜trainer.py
┃ ┗ 📜utils.py
┣ 📂graphsage_cf
┃ ┣ 📜args.py
┃ ┣ 📜data_preprocessing.py
┃ ┣ 📜model.py
┃ ┣ 📜trainer.py
┃ ┗ 📜utils.py
┣ 📜content_based_model.py
┣ 📜filtering.py
┣ 📜inference.py
┣ 📜inference_cbf_model.py
┣ 📜inference_cf_model.py
┣ 📜inference_tag_model.py
┣ 📜make_data.py
┣ 📜tag_embedding.py
┣ 📜train_cbf_model.py
┣ 📜train_cf_model.py
┣ 📜train_graphsage.sh
┗ 📜train_tag_model.py
GraphSAGE - CF Model
train_cf_model.py
1. 모듈 불러오기
import torch
import warnings
from torch.nn import TripletMarginLoss
from torch_geometric import EdgeIndex
from torch_geometric.loader import LinkNeighborLoader
from graphsage_cf.args import parse_args
from graphsage_cf.data_preprocessing import data_preprocessing
from graphsage_cf.model import Model
from graphsage_cf.trainer import train, test, feature
from graphsage_cf.utils import set_seed, makedirs, get_logger- PyTorch
- Warning 메시지 무시
- Triplet Loss 함수
- 그래프 생성
- graphsage_cf 폴더의 모듈
2. 설정
def main():
args = parse_args()
set_seed(args.seed)
makedirs(args.log_dir)
makedirs(args.model_dir)
logger = get_logger(filename=f'{args.log_dir}{args.model_name}.log')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
warnings.filterwarnings('ignore')- argument 불러오기
- Seed 설정
- 파일 경로/이름 지정
- GPU 설정
- Warning 메시지 무시
3. 데이터 전처리
# 데이터 전처리
train_data, valid_data, test_data, train_edge_index, valid_edge_index, test_edge_index = data_preprocessing(args)4. Edge
# Edge 저장
sparse_size = (train_data['user'].num_nodes, train_data['track'].num_nodes)
train_edge_index = EdgeIndex(
train_edge_index.to(device),
sparse_size=sparse_size,
).sort_by('row')[0]
valid_edge_index = EdgeIndex(
valid_edge_index.to(device),
sparse_size=sparse_size,
).sort_by('row')[0]
test_edge_index = EdgeIndex(
test_edge_index.to(device),
sparse_size=sparse_size,
).sort_by('row')[0]5. DataLoader
# DataLoader
train_loader = LinkNeighborLoader(
train_data,
num_neighbors = {('user', 'listen', 'track'): [args.neighbors_sampling] * args.n_layers, # [node 당 sample 개수] * layer 개수
('tag', 'tagged', 'track'): [args.neighbors_sampling] * args.n_layers,
('track', 'rev_listen', 'user'): [args.neighbors_sampling] * args.n_layers,
('track', 'rev_tagged', 'tag'): [args.neighbors_sampling] * args.n_layers},
edge_label_index = (('user', 'listen', 'track'), train_data['user', 'listen', 'track'].edge_index),
batch_size = args.batch_size,
shuffle = True,
filter_per_worker=True,
)6. 모델 정의
# 모델 정의
model = Model(data=train_data, x_dim=args.x_dim, embedding_dim=args.embedding_dim, hidden_dim=args.hidden_dim, n_layers=args.n_layers).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=args.learning_rate)
loss = TripletMarginLoss(margin=args.margin).to(device)7. Train / Validation
counter = 0
best_interaction_dict = {'epoch':0, 'train_loss':0, 'train_ndcg':0, 'train_recall':0, 'valid_ndcg':0, 'valid_recall':0}
for epoch in range(1, args.epochs+1):
print(f'Epoch: {epoch:02d}')
# train
train_ndcg, train_recall, train_loss = train(args, model=model, optimizer=optimizer, loss=loss,
dataloader=train_loader, data=train_data, train_edge_index=train_edge_index,
k=args.topk, device=device)
logger.info(f'Epoch: {epoch:02d} Loss: {train_loss:.4f}')
logger.info(f'Train Interaction NDCG@{args.topk}: {train_ndcg:.4f} Train Interaction Recall@{args.topk}: {train_recall:.4f}')
# validation
valid_ndcg, valid_recall = test(model=model, data=valid_data, k=args.topk, device=device,
train_edge_index=train_edge_index, test_edge_index=valid_edge_index)
logger.info(f'Valid Interaction NDCG@{args.topk}: {valid_ndcg:.4f} Valid Interaction Recall@{args.topk}: {valid_recall:.4f}')
# Best Interaction 모델 저장
if valid_ndcg > best_interaction_dict['valid_ndcg']:
logger.info(f'Best Interaction NDCG@{args.topk} is Updated')
best_interaction_dict = {'epoch': epoch, 'train_loss': train_loss, 'train_ndcg': train_ndcg, 'train_recall': train_recall, 'valid_ndcg': valid_ndcg, 'valid_recall': valid_recall}
torch.save(model.state_dict(), f'{args.model_dir}{args.model_name}.pt') # interaction 모델 저장
counter = 0
else:
counter += 1
# early stopping (최소 epoch 이상이면서 지정된 횟수의 epoch 동안 성능 향상 없을 때)
if (epoch > args.min_epochs) and (counter >= args.early_stopping):
logger.info(f'Early Stopping at Epoch {epoch:02d}')
break8. Feature 모델 평가
# Feature 모델 결과 출력
feature_ndcg_dict, feature_recall_dict = feature(data=test_data, k=args.topk, device=device,
train_edge_index=train_edge_index, valid_edge_index=valid_edge_index, test_edge_index=test_edge_index)
logger.info('Feature Model')
logger.info(f'Train Feature NDCG@{args.topk}: {feature_ndcg_dict["train"]:.4f} Train Feature Recall@{args.topk}: {feature_recall_dict["train"]:.4f}')
logger.info(f'Valid Feature NDCG@{args.topk}: {feature_ndcg_dict["valid"]:.4f} Valid Feature Recall@{args.topk}: {feature_recall_dict["valid"]:.4f}')
logger.info(f'Test Feature NDCG@{args.topk}: {feature_ndcg_dict["test"]:.4f} Test Feature Recall@{args.topk}: {feature_recall_dict["test"]:.4f}')
# Best 모델 결과 출력
logger.info('Best Interaction Model')
logger.info(f'Epoch: {best_interaction_dict["epoch"]:02d} Loss: {best_interaction_dict["train_loss"]:.4f}')
logger.info(f'Train Interaction NDCG@{args.topk}: {best_interaction_dict["train_ndcg"]:.4f} Train Interaction Recall@{args.topk}: {best_interaction_dict["train_recall"]:.4f}')
logger.info(f'Valid Interaction NDCG@{args.topk}: {best_interaction_dict["valid_ndcg"]:.4f} Valid Interaction Recall@{args.topk}: {best_interaction_dict["valid_recall"]:.4f}')9. Test
# test
model = Model(data=train_data, x_dim=args.x_dim, embedding_dim=args.embedding_dim, hidden_dim=args.hidden_dim, n_layers=args.n_layers).to(device)
model.load_state_dict(torch.load(f'{args.model_dir}{args.model_name}.pt')) # Best 모델 로드
test_ndcg, test_recall = test(model=model, data=test_data, k=args.topk, device=device,
train_edge_index=train_edge_index, test_edge_index=test_edge_index)
logger.info(f'Test Interaction NDCG@{args.topk}: {test_ndcg:.4f} Test Interaction Recall@{args.topk}: {test_recall:.4f}')
if __name__ == '__main__':
main()