개요
태양광 발전량 예측 SVM 모델 개발
- 확보할 수 있는 데이터를 최대한 활용하고, 파생변수를 생성하여 모델의 성능을 향상시켰다.
- 미래의 일사량 데이터를 확보할 수 없어서 일사량 예측 모델을 제작하고 활용하였다.
- Grid Search를 활용하여 SVM 모델을 튜닝함으로써 성능을 향상시켰다.
- 밤에는 발전량을 0으로 고정하고 학습에서 제외시키는 Rule-based 기법도 활용하여 학습의 노이즈를 줄이고, 성능을 향상시켰다.
팀 프로젝트 (데이터분석 동아리 Flex)
POSTECH OIBC 태양광 발전량 예측 경진대회
발표자료 & 코드 [GitHub]
기간
2020.07
배경 및 목적
- 과거 발전량 복원
- 2019년 7월 1일부터 2020년 6월 30일까지의 태양광 발전량 데이터를 활용하여 기록되지 않은 2020년 1월 31일, 2020년 3월 31일, 2020년 5월 31일의 시간대별 태양광 발전량 복원
- 미래 발전량 예측
- 2019년 7월 1일부터 2020년 7월 30일까지의 태양광 발전량 데이터를 활용하여 2020년 7월 31일의 시간대별 태양광 발전량 예측
역할
- 데이터 수집 및 전처리
- 파생변수 생성
- SVM 모델링
데이터 수집 및 전처리
태양광 발전량 데이터
1차로 2019년 7월 1일부터 2020년 6월 30일까지의 진천군 태양광 발전량 데이터가 제공되었고, 이를 활용하여 과거 태양광 발전량을 복원하였다.
2차로 2020년 7월 1일부터 2020년 7월 30일까지의 진천군 태양광 발전량 데이터가 제공되었고, 1차 데이터와 2차 데이터를 활용하여 미래 태양광 발전량을 예측하였다.
태양광 발전량은 15분 단위로 제공되었기 때문에 누적합을 이용하여 1시간 단위로 변경하였다.
일사량 데이터
참고 논문을 통해 태양광 발전량은 일사량에 큰 영향을 받는다는 사실을 확인하였다.
기상자료개방포털에서 일사량 데이터를 수집하였다.
최신 자료는 csv 형태로 제공되지 않기 때문에 7월의 일사량 데이터는 기상청 Open-API를 통해 수집하였다.
날씨 데이터
기온, 풍속, 풍향, 습도, 하늘상태, 강수확률 데이터를 활용하였다.
기상자료개방포털에서 매일 20시에 발표하는 단기 예보 데이터를 수집하였다.
최신 자료는 csv 형태로 제공되지 않기 때문에 7월 31일의 예보 데이터는 기상청 Open-API를 통해 수집하였다.
단기 예보는 3시간 단위로 발표되기 때문에 비어있는 시간에 해당하는 결측치는 선형보간을 활용하여 처리하였다.
예외적으로 하늘상태 변수는 범주형이므로 앞 시간의 데이터로 대체하였다.
태양 고도 데이터
참고 논문을 통해 태양 고도가 일사량과 관련이 있어 태양광 발전량 예측에 효과적이라는 사실을 확인하였다.
태양 고도 데이터를 한국천문연구원 웹페이지에서 크롤링을 통해 수집하였다.
밤시간 제외
밤에는 태양광 발전량과 일사량이 없지만 날씨는 계속 변한다.
밤시간의 데이터는 모델 학습에 방해된다고 판단하였다.
실제로 밤시간의 데이터를 제외한 결과가 더 높은 정확도를 보였다.
밤의 기준은 태양 고도 -10으로 설정하였고, 태양 고도가 -10보다 작은 시간의 데이터는 학습에서 제외하였다.
모델의 예측값 또한 태양 고도가 -10보다 작은 경우에는 0으로 대체하였다.
파생변수 생성
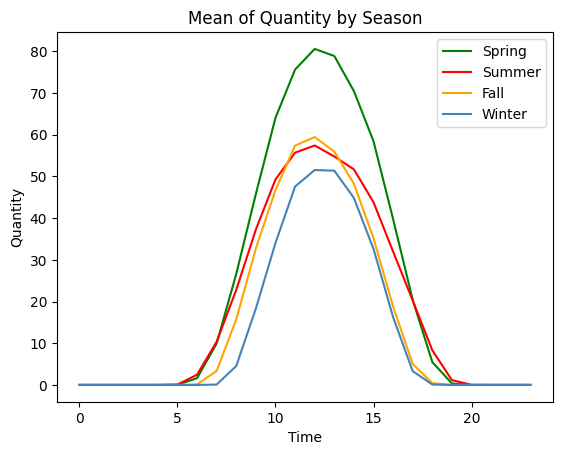
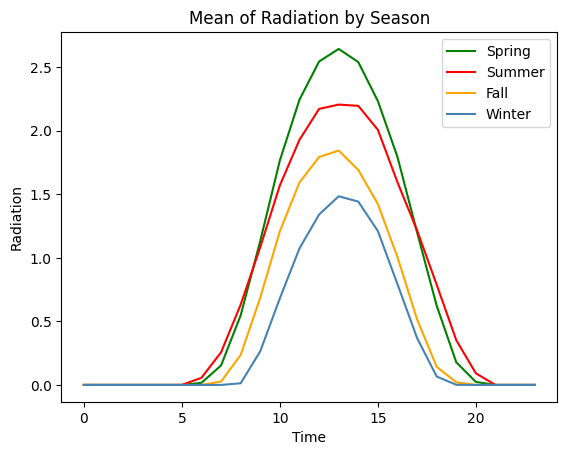
계절별 평균/사분위수
EDA를 통해 태양광 발전량과 일사량이 계절에 따라 구분된다는 사실을 확인하였다.
계절별 특성을 모델에 학습시키기 위해 동시간대의 계절별 태양광 발전량과 일사량의 평균과 사분위수를 파생변수로 활용하였다.
 |  |
|---|
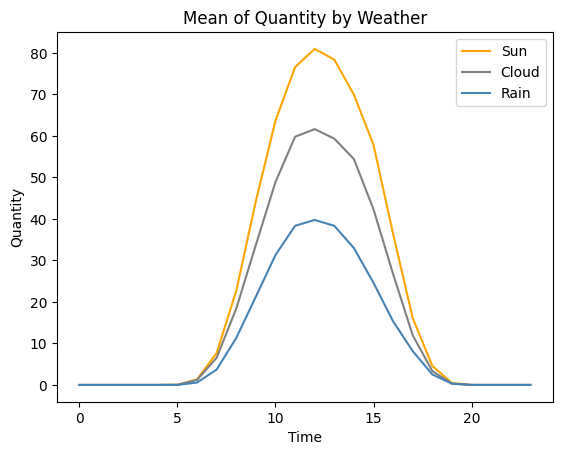
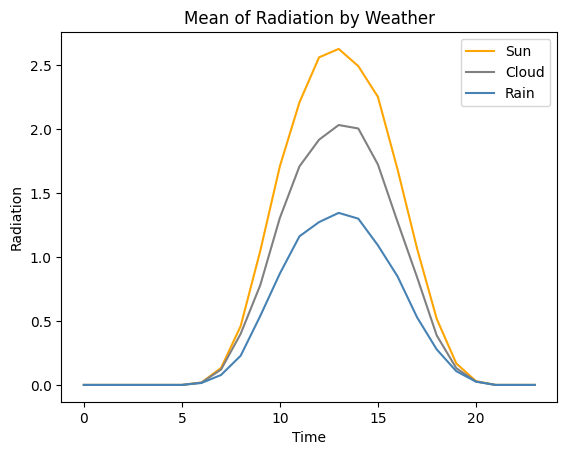
날씨별 평균/사분위수
EDA 결과를 통해 태양광 발전량과 일사량이 하늘 상태에 따라 구분된다는 사실을 확인하였다.
날씨별 특성을 모델에 학습시키기 위해 동시간대의 날씨별 태양광 발전량과 일사량의 평균과 사분위수를 파생변수로 활용하였다.
 |  |
|---|
자기회귀
가까운 과거의 태양광 발전량과 일사량을 결정하는 요인들은 예측하고자 하는 현재의 요인들과 유사할 것으로 판단하였다.
따라서 7일 동안의 동시간대 태양광 발전량과 일사량의 자기회귀 변수를 파생변수로 활용하였다.
파생변수의 상관관계
태양광 발전량과 일사량에 대한 변수들의 상관관계를 확인하였다.
대부분의 파생변수들은 태양광 발전량과 일사량에 대해 0.75 이상의 매우 높은 상관관계를 가지고 있었다.
이를 통해, 파생변수가 태양광 발전량 예측에 효과적일 것으로 예상할 수 있었다.
SVM 모델링
모델링
태양광 발전량을 예측하는 모델로 SVM(Support Vector Machine)을 활용하였다.
변수들은 MinMaxScaler를 통해 0과 1 사이의 값으로 정규화하였다.
모델을 평가하기 위해 Cross Validation을 활용하였다.
SVM 모델에서 최적의 파라미터를 찾기 위해 Grid Search를 활용하였다.
각 달의 마지막날을 Test로, 나머지는 Train으로 설정하여 모델을 평가하였다.
과거 발전량 복원
태양광 발전량을 y로 설정하였고, 일사량, 날씨, 태양 고도, 계절별 태양광 발전량과 일사량, 날씨별 태양광 발전량과 일사량, 태양광 발전량의 자기회귀를 변수로 선정하여 SVM 모델을 학습시켰다.
Cross Validation을 통해 도출된 정확도는 0.872이고, Grid Search를 활용하여 0.913으로 정확도를 향상시켰다.
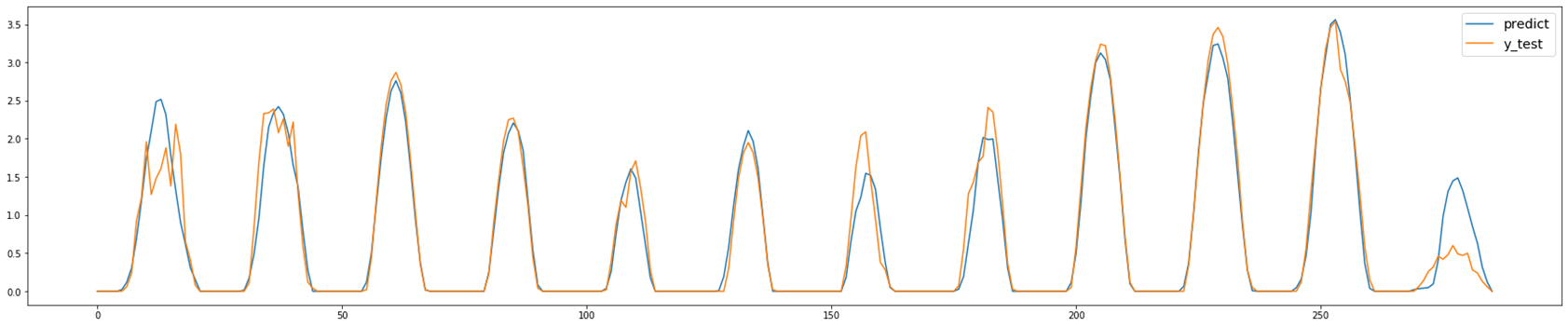
일사량 예측
우리는 7월 30일에 7월 31일의 태양광 발전량을 예측해야했다.
날씨 데이터는 예보를 활용하기 때문에 확보할 수 있었지만 태양광 발전량 예측에 가장 중요한 변수인 일사량을 확보할 수 없었기 때문에 일사량 예측 모델을 만들었다.
7월 28일까지의 일사량만 확보할 수 있었기 때문에 자기회귀 1, 2는 학습에서 제외하였다.
일사량을 y로 설정하였고, 날씨, 태양 고도, 계절별 일사량, 날씨별 일사량, 일사량의 자기회귀를 변수로 선정하여 SVM 모델을 학습시켰다.
Cross Validation을 통해 도출된 정확도는 0.817이고, Grid Search를 활용하여 0.819로 정확도를 향상시켰다.
미래 발전량 예측
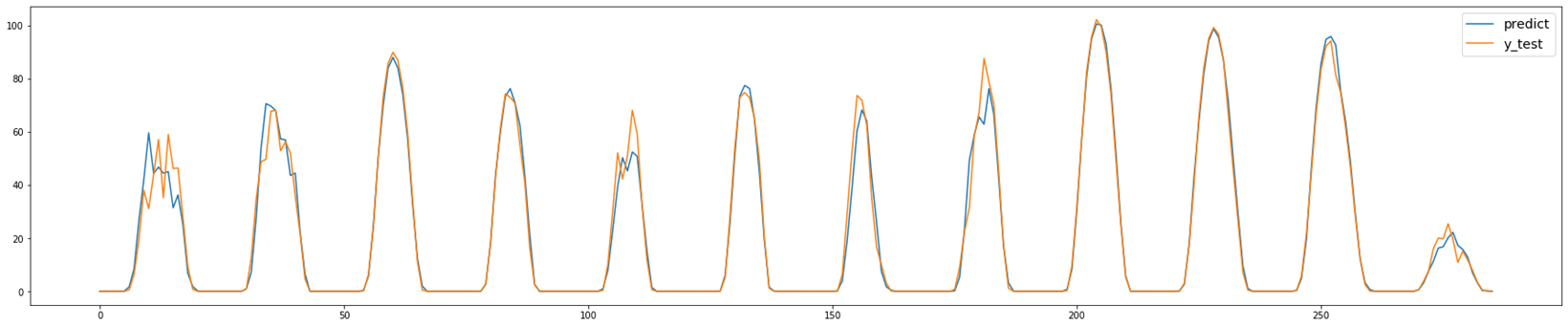
2020년 7월의 날씨 데이터는 예측하는 당일인 7월 31일의 예보 데이터만 확보할 수 있었기 때문에 7월의 데이터를 학습에서 제외하였다.
7월의 태양광 발전량과 일사량은 확보할 수 있었기 때문에 7월 31일의 자기회귀에 사용하였다.
7월 29일까지의 태양광 발전량만 확보할 수 있었기 때문에 자기회귀 1은 학습에서 제외하였다.
7월 31일의 예상 일사량은 일사량 예측 모델을 통해 도출하였다.
태양광 발전량을 y로 설정하였고, 일사량, 날씨, 태양 고도, 계절별 태양광 발전량과 일사량, 날씨별 태양광 발전량과 일사량, 태양광 발전량의 자기회귀를 변수로 선정하여 SVM 모델을 학습시켰다.
Cross Validation을 통해 도출된 정확도는 0.875이고, Grid Search를 활용하여 0.914로 정확도를 향상시켰다.
성과 및 배운점
우수상 (2위 / 61팀)
데이터 관련 문제 해결
변수 선정 시 실제상황에서 구할 수 있는 데이터인지를 가장 먼저 고려하였다.
예측 가능한 태양 고도 데이터와 기상청 Open-API를 통해 예측 전날에 받을 수 있는 예보 데이터를 활용하였다.
가장 중요한 변수인 일사량은 예보가 제공되지 않으므로 과거 일사량과 예보 데이터를 활용하여 일사량을 예측하였다.
따라서 구하기 쉬운 데이터를 사용하고, 이를 활용하여 파생변수 생성과 일사량 예측을 통해 태양광 발전량을 예측하는 이 모델이 실제 상황에 적합하다고 판단하였다.
기상청 Open-API에서는 보안상의 문제로 1일 전에 발표된 예보 데이터만을 조회할 수 있었다.
태양광 발전량을 예측하는 데에는 문제가 없었지만 예보 데이터가 존재하지 않아 7월 데이터를 학습에 활용할 수 없었던 것이 아쉬웠다.
1년간의 태양광 발전량을 사용할 수 있었는데, 더 긴 기간의 데이터가 확보된다면 더욱 정확한 모델 구현이 가능할 것이다.
느낀점
머신러닝을 제대로 경험한 첫 프로젝트였고, 밤새 코딩도 해보면서 AI와 코딩의 즐거움을 느꼈다.
수업을 통해 얻는 것보다 프로젝트를 통해 직접 부딪혀보니 얻는 것도 많았고, 실력이 많이 늘었다.
노력한만큼 좋은 성과도 얻을 수 있었고, 파생변수 생성과 그리드 서치가 핵심적인 역할을 하였다.
머신러닝에서는 데이터가 가장 중요하고, 파생변수를 활용하여 의미있는 변수를 만들어내는 것이 정말 효과적이라는 것을 느꼈다.
어떤 모델을 쓸지도 중요하지만 모델을 데이터에 알맞게 튜닝하는 것도 중요하다는 것을 느꼈다.
Reference
서포트 벡터 회귀를 이용한 24시간 앞의 태양광 발전량 예측 [Paper]
기상 예보를 이용한 머신러닝 알고리즘 기반 태양광 발전량 예측 기법 [Paper]
예측 일사량과 기상변수를 이용한 인공신경망 기반 태양광 발전량 예측 [Paper]
