개요
화재 발생 예측 RandomForest 모델 개발
- MICE 기법을 활용하여 결측치를 처리하였다.
- 범주형 변수를 모델 학습에 사용하기 위해 One-Hot Encoding을 통해 연속형으로 변환하였다.
- 상관관계 분석을 통해 모델 학습의 목적과 관계있는 변수를 선별하였다.
팀 프로젝트 (데이터분석 동아리 Flex)
COMPAS 김해시 화재발생 예측모델 개발 경진대회 [Site]
기간
2019.11
배경 및 목적
김해지역은 화재가 계절 및 장소 등에 관계 없이 잇따라 발생하고 있어 시민의 인명과 재산의 피해를 줄이기 위한 다양한 대책이 요구되고 있다. 김해시에서는 소방 및 건물관련 정보를 융합하여 지역 내 화재 위험도에 대해 분석 및 예측하고 이를 이용하여 화재에 대한 집중적이고 적극적인 예방활동을 수행함으로써 행정력의 효율적인 배분에 기여하고자 한다. 따라서 김해시가 수집한 소방 및 건물 관련 데이터를 활용하여 건축물의 화재 위험도 분석 및 예측 모델을 개발한다.
역할
- 데이터 전처리
- MICE를 활용한 결측치 처리
- 상관관계 분석을 통한 변수 선택
데이터 전처리
전체 데이터 중에 약 40%가 결측치로 이루어져 있었다.
원활한 모델 학습을 위해 MICE 기법을 활용하여 결측치를 대체하였다.
데이터에 화재발생여부, 건물유형 등 범주형 변수들이 존재했다.
범주형 변수들을 모델 학습에 사용하기 위해 One-Hot Encoding을 통해 연속형으로 변환하였다.
모델 학습의 목적과 관계있는 변수를 찾기 위해 변수들끼리의 상관계수를 구하였다.
상관관계 분석을 통해 사용할 변수들과 사용하지 않을 변수들을 선별하였다.
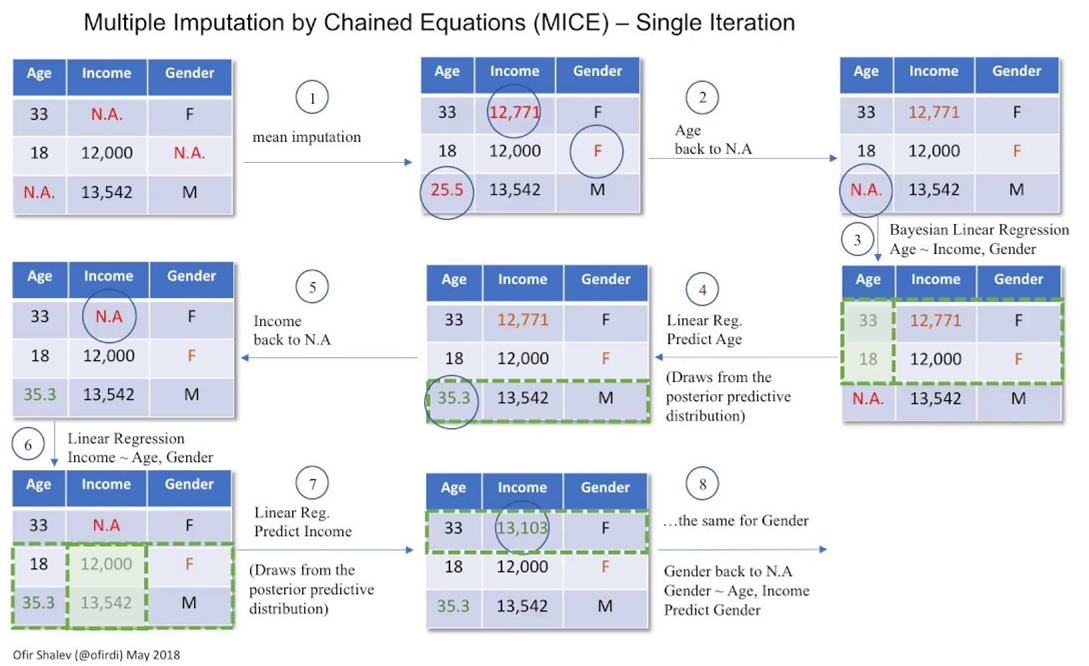
MICE를 활용한 결측치 처리
단일대체법(Single Imputation) : 평균, 중앙값, 최빈값 등 하나의 값으로 결측치 대체
다중대체법(Multiple Imputation) : 여러 추정값을 종합하여 결측치 대체
MICE(Multivariate Imputation by Chained Equations) : 연쇄방정식에 의한 다중대체법
- 결측치를 단일대체법을 이용하여 1차로 채워넣은 후에, 여러개의 데이터 셋을 생성하여 다중 회귀 방법으로 더 유의미한 대체값 도출
성과 및 배운점
26위 / 133팀

학과에서 데이터분석 동아리를 결성하고 첫 머신러닝 프로젝트를 경험하였다.
머신러닝 모델에 대한 이해도가 부족해서 나는 R 언어를 활용한 데이터 전처리 부분을 맡았다.
데이터에 결측치가 많아서 어려움을 겪었지만 여러 기법들을 활용하여 괜찮은 결과를 이끌어낼 수 있어서 뿌듯했다.
파이썬을 활용해서 SVM 모델 학습을 시도해보았지만, 파이썬에 익숙하지 못했고 모델 이해도가 부족하여 실패했다.
R 대신에 머신러닝 모델을 학습시키기 좋은 파이썬을 배워야겠다고 느꼈다.
다음 대회에는 SVM 모델을 학습시켜서 결과를 내고 싶다.
Reference
https://rchemistblog.com/blog/posts/mice_imputation/
https://velog.io/@drudger/%EA%B2%B0%EC%B8%A1%EC%B9%98%EC%B2%98%EB%A6%AC#233-%EB%8B%A4%EC%A4%91%EB%8C%80%EC%B2%B4%EB%B2%95multiple-imputation
