1. Introduction
- 대규모 언어 모델의 한계: 산술 연산이나 최신 정보에 대한 접근과 같은 부분에서는 기본적이고 작은 모델들에 비해 부족함을 겪고 있다.
- Toolformer model : 언어 모델이 외부 도구(예: 계산기, 질문 답변 시스템, 검색 엔진, 번역 시스템 및 캘린더)를 사용하는 방법을 스스로 가르칠 수 있는 모델
- 이 모델은 간단한 API를 통해 외부 도구를 호출하여, 언제 어떤 도구를 호출할지, 어떤 인수를 전달할지, 그리고 획득한 결과를 어떻게 향후 토큰 예측에 통합할지 결정하는 방법을 자가 학습한다.
- 이 과정은 몇 가지 시연만을 필요로 하는 in-context learning으로 진행되며, 언어 모델의 핵심 언어 모델링 능력은 감소하지 않으면서 다양한 하류 과제에서 상당한 개선을 이루어냄을 확인함.
2. Approach
- 우리의 목표: 언어 모델 M이 API 호출을 통해 다양한 tool을 사용할 수 있도록 하는 것
이를 위해 각각의 API의 input과 output이 텍스트 sequence로 나타내질 수 있어야 한다. 즉, 특별한 tagging(start/end 표시)를 통해 어느 text에라도 API를 넣을 수 있어야 한다.
API call :
( : the name of API, : the corresponding input)
", , " special tokens
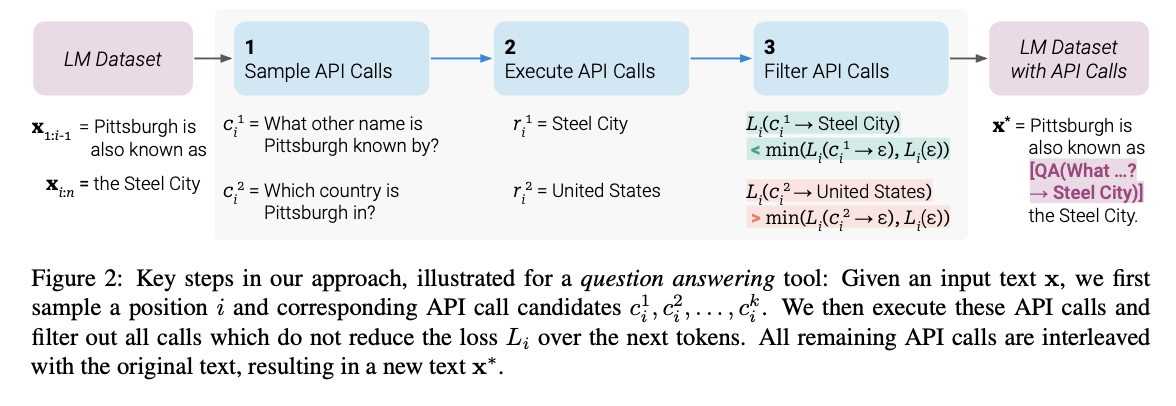
-
API 호출 샘플링: Toolformer는 주어진 텍스트에 대해 어떤 API를 호출할지, 그리고 어떤 인자를 넘겨줄지 스스로 결정. 이를 위해, 인간이 작성한 몇 가지 예시를 바탕으로 언어 모델이 대규모 언어 모델링 데이터셋에 API 호출을 주석으로 달아 생성
-
API 실행: 샘플링된 API 호출이 실행되어 결과를 획득. 이 결과는 후속 토큰 예측에 유용한 정보를 제공할 수 있음.
-
API 호출 필터링: 모든 API 호출이 유용한 것은 아니므로, 실행된 API 호출의 결과가 모델의 예측 성능에 실제로 도움이 되는지를 평가하는 자가 감독 손실 함수를 사용하여 필터링. 이는 미래의 토큰을 예측하는 데 있어 손실을 줄이는 API 호출만을 선택하는 과정.

-
모델 파인튜닝: 유용한 것으로 판단된 API 호출을 데이터셋에 추가한 후, 이 데이터셋을 사용하여 언어 모델을 파인튜닝. 이렇게 함으로써 모델은 언제, 어떻게 외부 도구를 사용할지 스스로 결정하는 능력을 개발.
이러한 접근 방법을 통해 Toolformer는 API 호출을 생성, 실행, 통합하는 전체 프로세스를 내재화하며, 이를 통해 언어 모델의 기능을 크게 확장한다.
중요한 점은, 이 과정 전체가 사람의 개입 없이 자가 학습 방식으로 이루어진다는 점이다. 따라서 Toolformer는 특정한 인간의 지시 없이도 다양한 외부 도구를 활용하여 문제를 해결할 수 있는 능력을 갖추게 된다.
3. Tools
- Toolformer가 사용하는 다양한 외부 도구들과 각 도구가 언어 모델의 어떤 한계를 극복하는 데 도움을 주는지
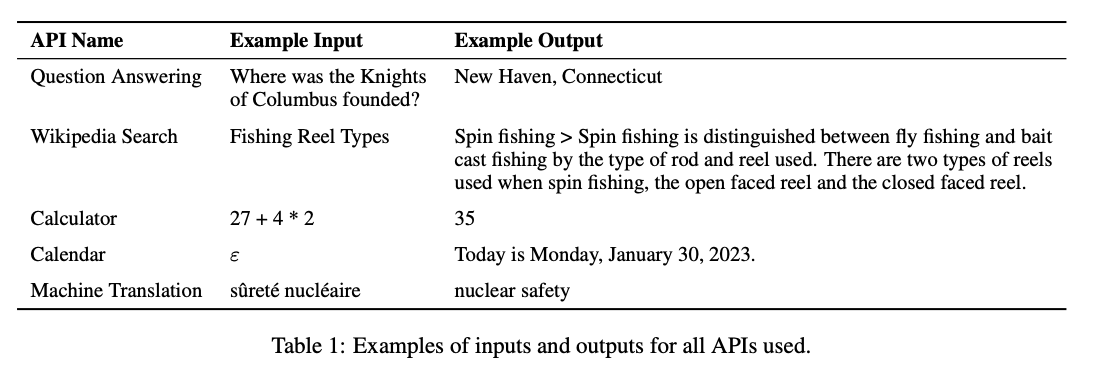
- 질문 답변 시스템(Question Answering): 이 도구는 간단한 사실에 관한 질문에 답할 수 있으며, Atlas와 같은 검색 기반 언어 모델을 사용. 이는 언어 모델이 최신 정보에 접근하거나 확실하지 않은 정보를 검증할 수 있게 함.
- 계산기(Calculator): 기본 산술 연산을 수행할 수 있는 도구로, 언어 모델이 정확한 수치 계산을 할 수 있게 한다. 결과는 항상 소수점 두 자리까지 반올림된다.
- 위키피디아 검색(Wikipedia Search): 주어진 검색어에 대한 위키피디아의 짧은 텍스트 스니펫을 반환하는 검색 엔진. 이 도구는 모델이 보다 포괄적인 정보에 접근할 수 있게 하지만, 관련 정보를 스스로 추출해야 함.
- 기계 번역 시스템(Machine Translation System): 특정 언어에서 영어로 문장을 번역할 수 있는 도구이다. 200개 이상의 언어를 지원하며, 낮은 자원 언어에 대한 이해를 향상시킨다.
- 캘린더(Calendar): 현재 날짜를 반환하는 API로, 언어 모델이 시간에 민감한 문제를 해결할 때 시간적 맥락을 제공한다.
4. Experiments
4.1 Experimental Setup
- Dataset Generation
a subset of CCNet as our language modeling dataset and GPT-J as our language model
앞서 언급된 방법들을 통해서 에서 을 얻음 - Model Finetuning
batch size 128
learning rate - Baseline Models
GPT-J : baseline
GPT-J + CC : GPT-J fintuned on , our subset of CCNet without any API calls
Toolformer : GPT-J finetuned on , our subset of CCNet augmented with API calls
Toolformer (disabled) : The same model as Toolformer, but API calls are disabled during decoding
4.2 Downstream Task
- consider a prompted zero-shot setup (자연어로 처리해야 할 task를 받지만, in-context로 예시를 건네 받지 못함)
- standard greedy decoding 사용
4.2.1 LAMA
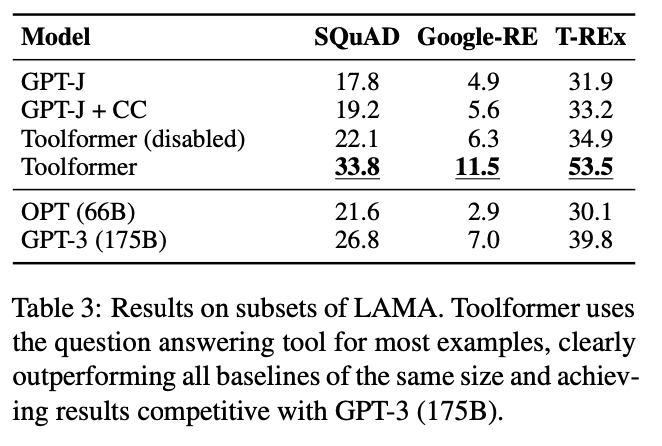
- 지식 기반 벤치마크(LAMA): Toolformer는 사실 기반 질문에 답하기 위해 질문 답변 시스템을 사용. 이를 통해 기존 GPT-J 모델과 대규모 모델인 GPT-3와 비교했을 때, 상당히 높은 성능 향상을 보여주었음
4.2.2 Math Datasets
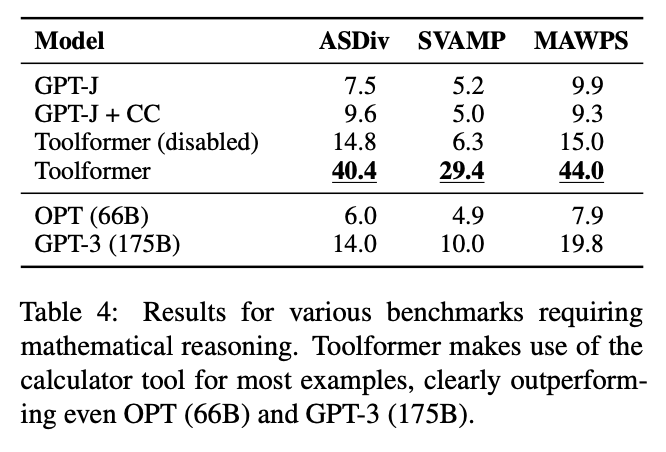
- 수학 문제 해결(Math Datasets): ASDiv, SVAMP, 그리고 MAWPS 같은 수학 문제 해결 벤치마크에서 Toolformer는 계산기 도구를 활용하여 향상된 결과를 달성. 이는 Toolformer가 기존 모델과 비교하여 더 정확한 수치 계산을 수행할 수 있음을 보여줌.
4.2.3 Question Answering
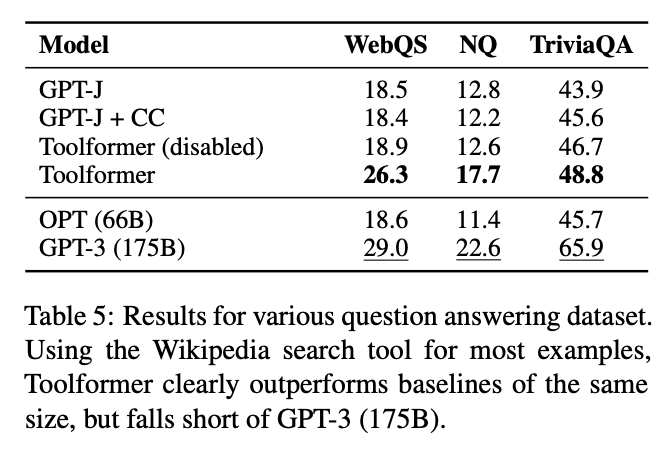
- 질문 답변(Question Answering): Web Questions, Natural Questions, 그리고 TriviaQA 등의 질문 답변 데이터셋에서 Toolformer는 위키피디아 검색 도구를 사용하여 정보를 검색하고, 답변에 필요한 정보를 획득한다. 이를 통해 기존 언어 모델과 비교하여 성능이 향상됨을 확인할 수 있음
4.2.4 Multilingual Question Answering
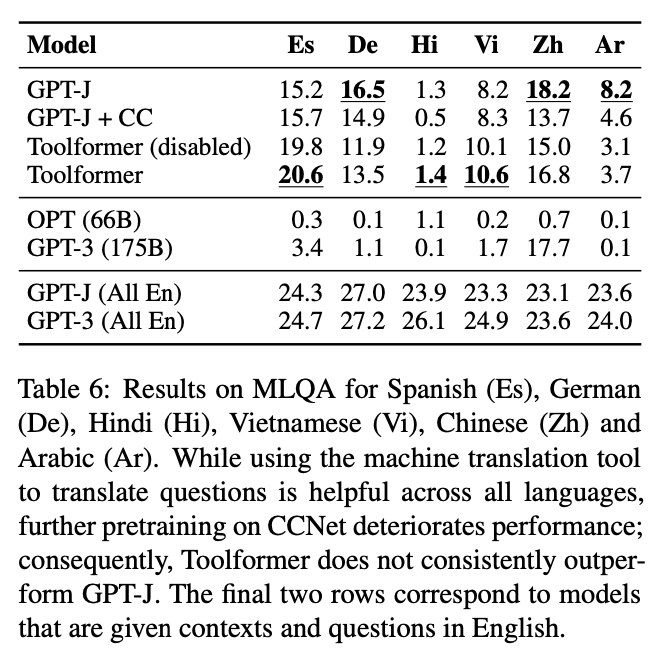
- 다국어 질문 답변(Multilingual Question Answering): MLQA 벤치마크를 통해 Toolformer는 기계 번역 시스템을 활용하여 다양한 언어로 제시된 질문을 영어로 번역하고, 이를 바탕으로 질문에 답한다. 이 실험은 Toolformer가 다국어 이해 능력을 향상시킬 수 있음을 보여준다.
4.2.5 Temporal Datasets
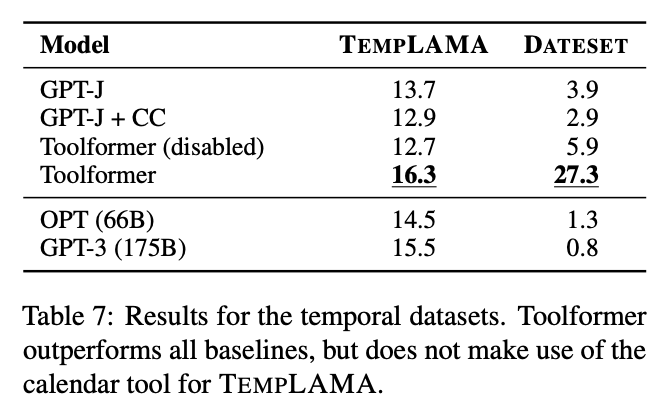
- 시간에 민감한 데이터셋(Temporal Datasets): TEMPLAMA와 DATESET 같은 시간에 민감한 데이터셋에서 Toolformer는 캘린더 도구를 사용하여 현재 날짜를 인식하고, 이를 바탕으로 질문에 답하는 능력을 보여준다.
4.3 Language Modeling

WikiText와 CCNet 데이터셋에서의 언어 모델링 성능을 평가하여, Toolformer가 도구를 사용하는 능력을 통합하면서도 기본적인 언어 모델링 능력을 유지하거나 향상시킬 수 있음을 보여준다.
4.4 Scaling Laws
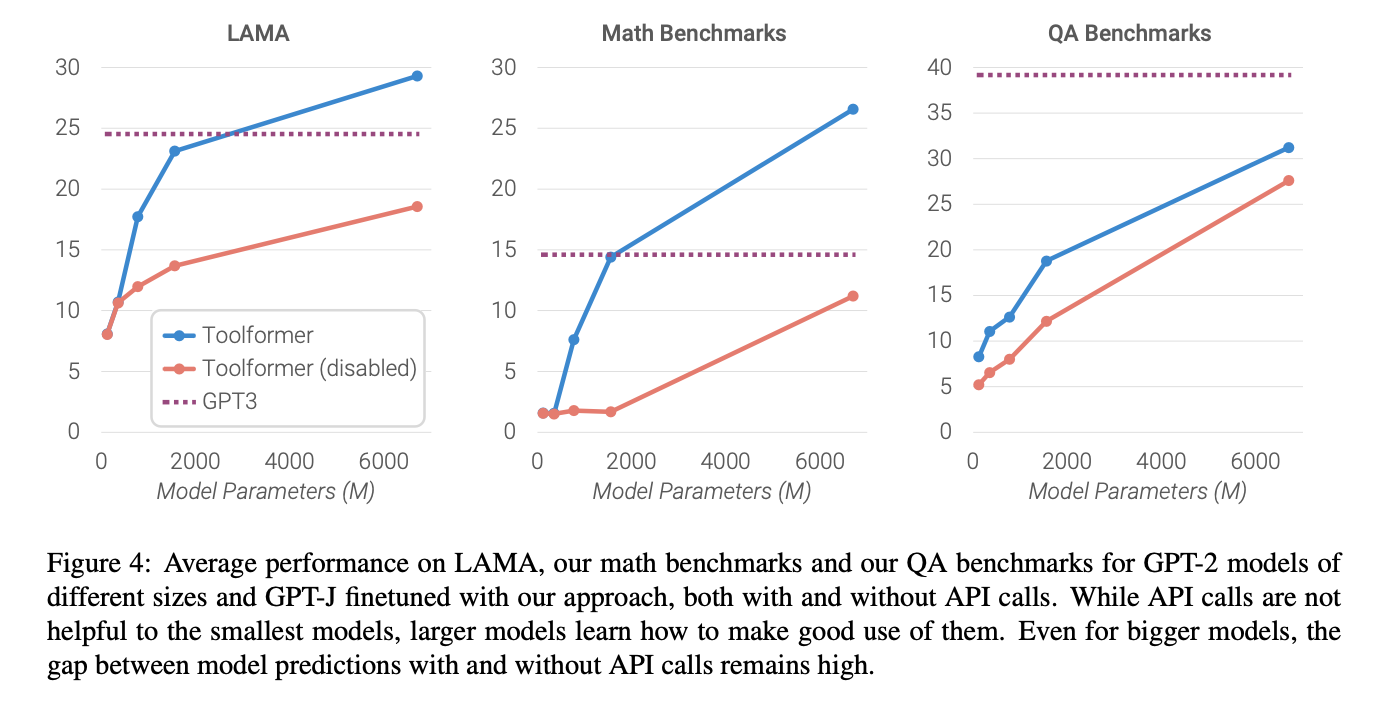
GPT-J 뿐만 아니라 더 작은 GPT-2에도 적용해보았음. 앞선 예시 중에 QA, calculator, Wiki 과제만 수행하도록 함.
5. Analysis
- 모델이 외부 도구를 어떻게 활용하는지, 다양한 설정이 모델의 도구 사용 능력과 성능에 어떻게 영향을 미치는지
- 디코딩 전략(Decoding Strategy): Toolformer가 API 호출을 결정하는 과정에서, "k"의 값을 조정하여 언제 토큰을 생성할지를 조절한다. "k" 값이 클수록 모델이 API를 호출할 가능성이 높아진다. 실험을 통해, 적절한 "k" 값을 설정하는 것이 중요함을 발견하며, 이는 Toolformer가 도구를 사용하여 성능을 향상시킬 가능성을 증가시킨다.
- 데이터 품질(Data Quality): Toolformer가 생성한 API 호출의 품질을 분석한다. 유용한 API 호출은 모델의 예측 성능을 향상시키는 반면, 불필요한 API 호출은 성능에 부정적인 영향을 미칠 수 있다. 따라서, 유용한 API 호출만을 선별하는 필터링 과정의 중요성을 강조한다.
6. Related Works
- Language Model Pretraining
- Tool Use
- Bootstrapping
7. Limitations
- 모델이 도구 사용을 체인 형태로 연결하거나 상호작용하는 방식으로 질문을 제기하는 것은 현재의 구현에서 지원되지 않는다.
- Toolformer는 입력된 문장의 정확한 표현에 민감하게 반응할 수 있으며, 모든 도구 호출이 항상 유용한 것은 아니다.
8. Conclusion
Toolformer는 언어 모델이 외부 도구를 활용하여 기존에는 해결하기 어려웠던 문제들을 해결할 수 있도록 확장하는 새로운 접근법을 제시한다. 실험을 통해 Toolformer가 다양한 종류의 외부 도구를 효과적으로 사용하여 정보 검색, 수치 계산, 다국어 번역 등의 과제에서 기존 모델들을 뛰어넘는 성능을 달성할 수 있음을 입증했다. 이는 언어 모델의 기능을 크게 확장하는 데 중요한 발전이며, 이를 통해 더 복잡하고 다양한 문제를 해결할 수 있는 가능성을 열었다. 그럼에도 불구하고, 모델의 한계를 극복하고 Toolformer의 개념을 더 발전시키기 위한 추가적인 연구가 필요하다.
