1. Introduction
- LLM finetuning - 원하는 동작은 넣거나 빼는 효과적인 방법
but, 큰 모델일수록 finetuning에 대한 비용이 비싸다. - 최근의 quantization 방법들은 LLM의 memory footprint를 줄일 수 있지만 이 방법들은 training 도중에만 가능하다.
- QLoRA: uses a novel high-precision techinque to quantize a pretrained model to 4-bit, then adds a small set of learnable Low-rank Adapter weights that are tuned by backpropagation gradients through the quantized weights
- 65B parameter 크기의 모델 finetuning에 필요한 메모리 양: >780GB → <48GB
(모델의 성능, 속도의 저하 없이) - Guanaco family of models
ChatGPT 성능의 97.8% 달성, 12시간의 training
ChatGPT 성능의 99.3% 달성, 24시간의 training
5GB의 메모리만을 필요로 하는 모델 개발 - memory 문제로 인해 학습을 시키지 못했던 복잡한 모델을 finetuning할 수 있음
- trends in the trained models
- data quality가 data size보다 중요함
- strong Massive Multitask Language Understanding benchmark performance (MMLU) ⇏ (⇍) strong Vicuna chatbot benchmark performance
- Extensive analysis of chatbot performance: both human raters and GPT-4
- 모델 사이에 좋은 response를 내는 것을 토너먼트 형식으로 결정함
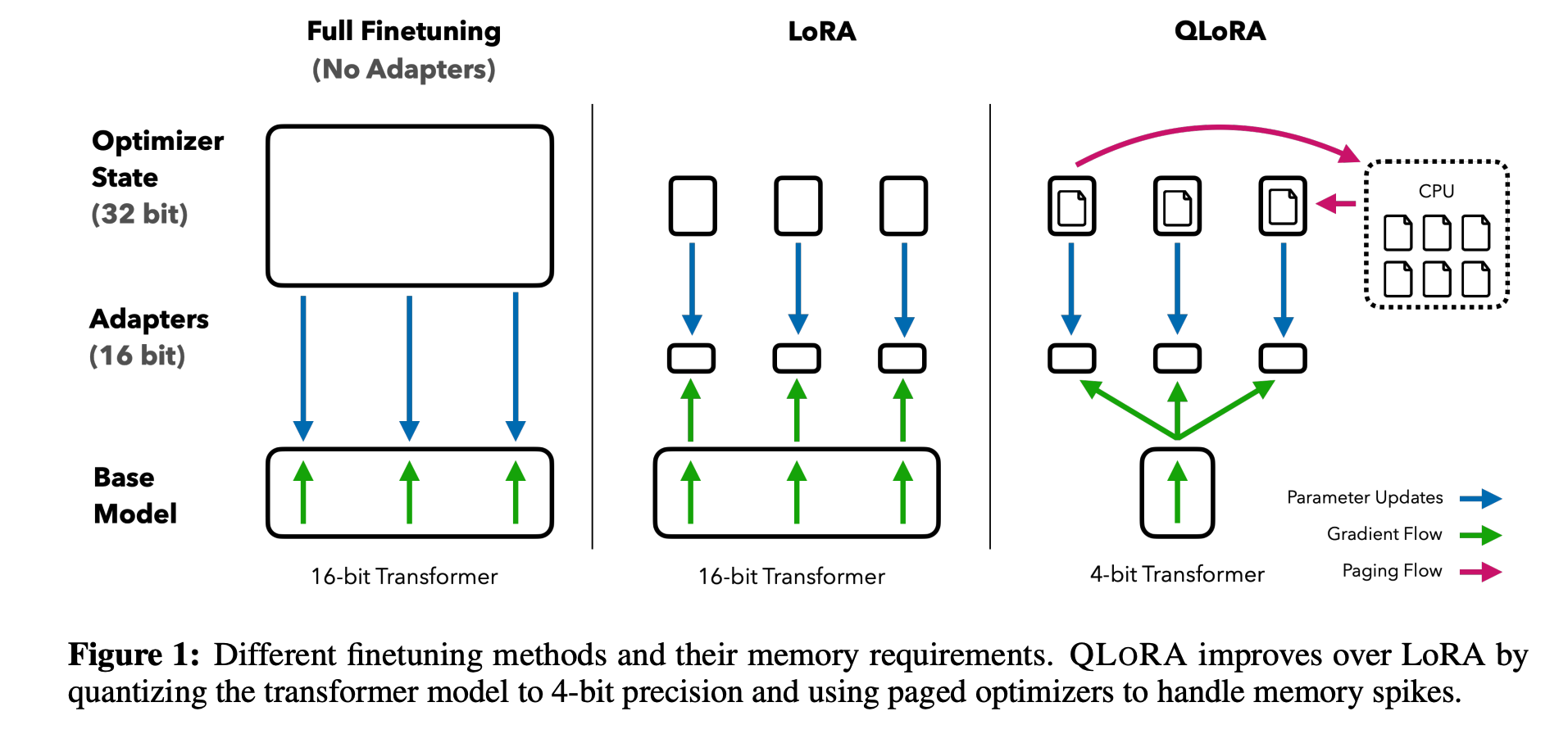
2. Background
Block-wise k-bit Quantization
- Quantization(양자화) : 입력 데이터를 보다 정보량이 적은 표현으로 변환하는 방법, 보통 더 많은 비트를 사용하는 데이터 타입을 적은 비트를 사용하는 데이터 타입으로 전환함
- 입력 데이터 타입을 대상 데이터 타입 범위로 정규화하여 전체 범위를 사용하도록 함. 절대 최대값을 사용
ex) 32-bit Floating Point(32FP) tensor → Int 8 tnesor [-127, 127]
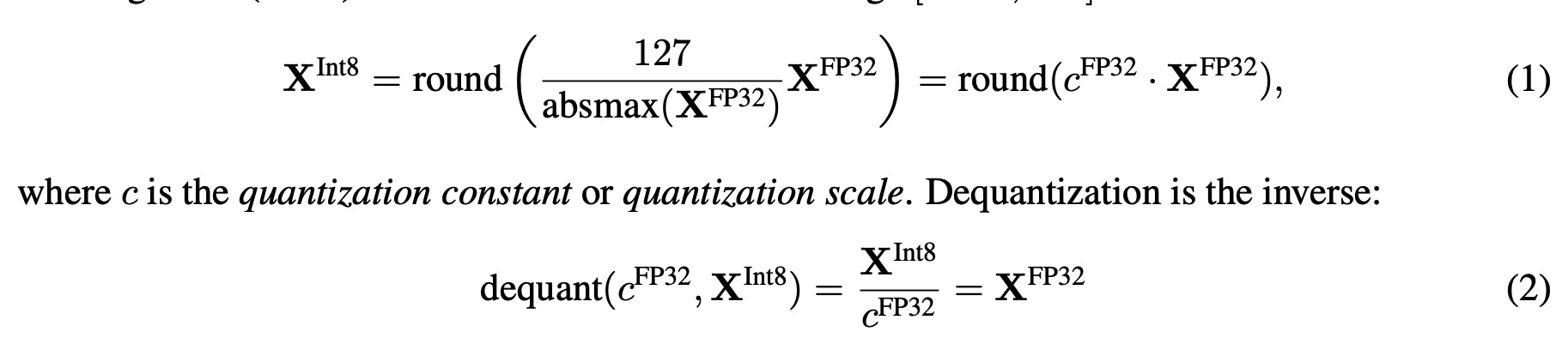
- 입력 텐서에 매우 큰 값(이상치)이 존재하는 경우, 양자화된 텐서에서 일부 이진 조합이 제대로 사용되지 않는 문제가 발생할 수 있음. 이를 해결하기 위해 일반적으로 입력 텐서를 독립적으로 양자화하는 블록으로 나누고, 각 블록에 대해 독립적인 양자화 상수를 채택. (각 블록이 그 자체로 양자화되어 이상치의 영향을 최소화할 수 있다)
Low-rank Adapters
- LoRA finetuning : LLM의 finetuning 시 메모리 요구량을 줄이면서 성능은 유지할 수 있도록 설계된 파라미터 효율적 finetuning qkdqjq.
- 전체 모델 파라미터를 업데이트 하지 않고 작은 크기의 학습 가능한 파라미터의 집합 (adapter)를 사용한다. 훈련 중에는 미리 학습된 모델 가중치를 고정하고, 이 가중치를 통해 gradient를 전파하여 손실 함수를 최적화하도록 어댑터를 업데이트한다.
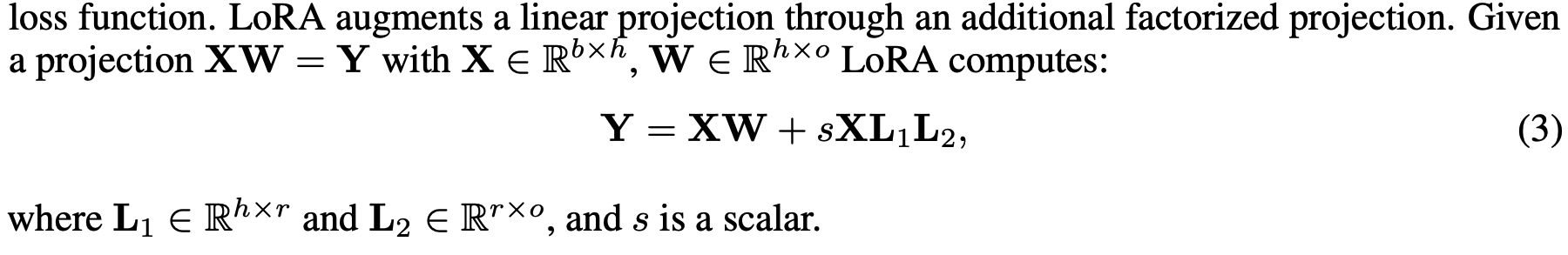
Memory Requirement of Parameter-Efficient Finetuning
- 메모리 요구사항은 activation gradient와 관련됨.
- LoRA를 사용할 때, LoRA 어댑터의 입력 그래디언트는 상당한 메모리를 차지하지만, LoRA 파라미터 자체는 매우 적은 메모리를 사용한다.
- LoRA는 많은 adapter를 사용하여 성능을 향상시킬 수 있지만, 전체 훈련 메모리 사용량을 크게 증가시키지는 않는다. gradient checkpoint를 사용하여 입력 그래디언트의 메모리 사용량을 줄이면서도, 더 많은 어댑터를 사용하기 때문이다.
- LoRA를 사용하는 PEFT 방법: 모델의 메모리 요구량을 최소하하면서도 모델의 성능을 유지하거나 개선할 수 있는 효율적인 방법
3. QLoRA Finetuning
4-bit NormalFloat Quantization
-
정보 이론적 최적화: NF4는 입력 텐서의 값을 균등하게 분포시키는 양자화 방법이다. 이는 각 양자화 bin에 입력 텐서 값들이 고르게 할당되도록 함으로써, 정보 손실을 최소화하는 것을 목표로 한다.
-
양자화 프로세스
- 입력 텐서 X가 주어졌을 때, 입력 값들의 표준 정규 분포를 가정. (평균 0, 표준편차 일정한 정규분포)
- 입력 텐서의 표준편차를 조정하여, 데이터 타입 범위 [-1, 1]에 맞도록 스케일링
- 스케일링된 텐서를 사용하여 4-bit 데이터 타입으로 양자화를 진행한다. 각 값은 가장 가까운 양자화 레벨로 매핑된다.
- 실제 구현
- 양자화 된 값들은 사전에 계산된 양자화 레벨을 사용하여 정회된다. 이 레벨들은 입력 텐서의 분포를 기반으로 계산되어, 양자화 과정에서 정보 손실을 최소화하도록 설계된다.
- 각 양자화 레벨은 입력 텐서의 분포에서 나타나는 각 값의 cumulative distribution function(CDF)를 사용하여 결정된다.

- 성능 평가
- NF4 양자화를 표준 4-bit 정수 또는 부동소수점 양자화 방법과 비교하여 성능을 평가
- 양자화 오류가 발생할 수 있는 이상치에 대한 내성이 높음. 더 낮은 비트에서도 높은 성능을 유지할 수 있게 설계됨.
Double Quantization
- 메모리 요구 사항을 더 줄이기 위해 설계됨
- 양자화 상수의 추가 양자화
첫 번째 양자화 단계에서 사용된 양자화 상수들을 다시 양자화한다. - 양자화 프로세스
원래 양자화 상수 를 두 번째 양자화 단계의 입력으로 사용한다.
이 상수들은 8-bit 부동소수점 수로 더 양자화하여, 최종적으로 더 적은 메모리를 사용하는 를 생성한다. - 메모리 절약 효과
큰 블록 크기를 사용하는 경우, 양자화 상수의 메모리 요구량을 기존의 절반 이상 줄일 수 있다.
Paged Optimizers
- NVIDIA의 통합 메모리 기능을 활용하여, 대규모 모델을 finetuning할 때 발생할 수 있는 메모리 스파이크를 관리하는 기술
- page-to-page transfer : CPU와 GPU 간에 자동적으로 수행. GPU 메모리가 일시적으로 부족할 때 발생할 수 있는 오류를 방지
- 메모리 할당 : 필요할 때 GPU 메모리로 다시 paging 가능하도록 CPU RAM에 일시적으로 저장됨
- 메모리 요구 사항 관리 : 긴 시퀀스 길이를 가진 미니배치를 처리할 때 발생하는 메모리 스파이크를 효과적으로 관리. 특히 단일 GPU에서 대규모 언어 모델으 효율적으로 훈련할 수 있게 해주는 중요한 기능
QLoRA
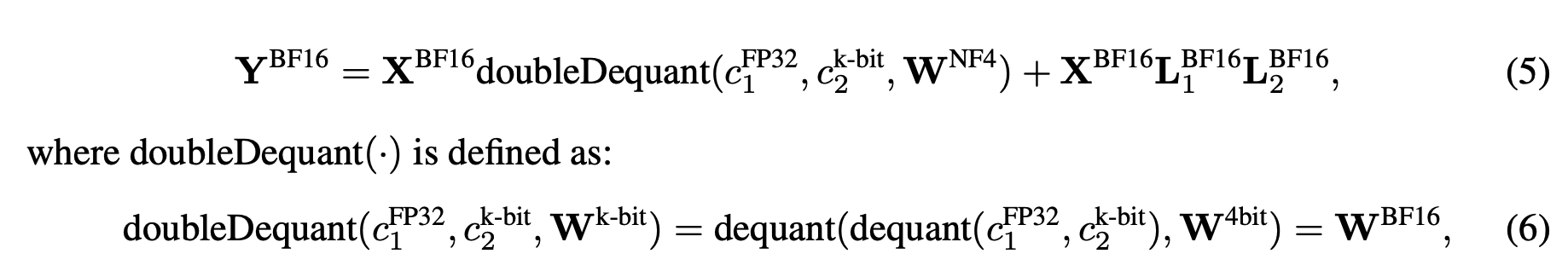
- 저장 데이터 타입: 4-bit의 저정밀도 저장 데이터 타입 사용
- 계산 데이터 타입: 16-bit (BFloat16) 사용
- Adapter 가중치: Low-rank Adapters를 사용하여 모델의 성능 유지
- 양자화 및 역양자화: 모델의 가중치는 저정밀도 데이터 타입으로 양자화되어 저장되며, 계산 시에는 역양자화를 거쳐 BFloat16으로 변환된다. 이렇게 함으로써, 계산 중에는 높은 정밀도를 유지할 수 있다.
- 파라미터 업데이트: LoRA Adapter의 가중치에 대한 그래디언트만 계산. 이는 전체 모델 가중치가 아닌, 어댑터 파라미터만 업데이터되므로 메모리 효율성이 크게 향상됨
- 미세조정 성능 유지: 저비트 양자화 + 파라미터 효율적 미세조정 → 메모리 사용을 크게 줄이면서도 기존 미세조정과 동등한 성능을 유지함
4. QLoRA vs. Standard Finetuning
Experimental setup
- 언어 모델링과 제로샷 작업: 다양한 모델 크기와 데이터 타입에 대해 언어 모델링 및 제로샷 성능을 평가함.
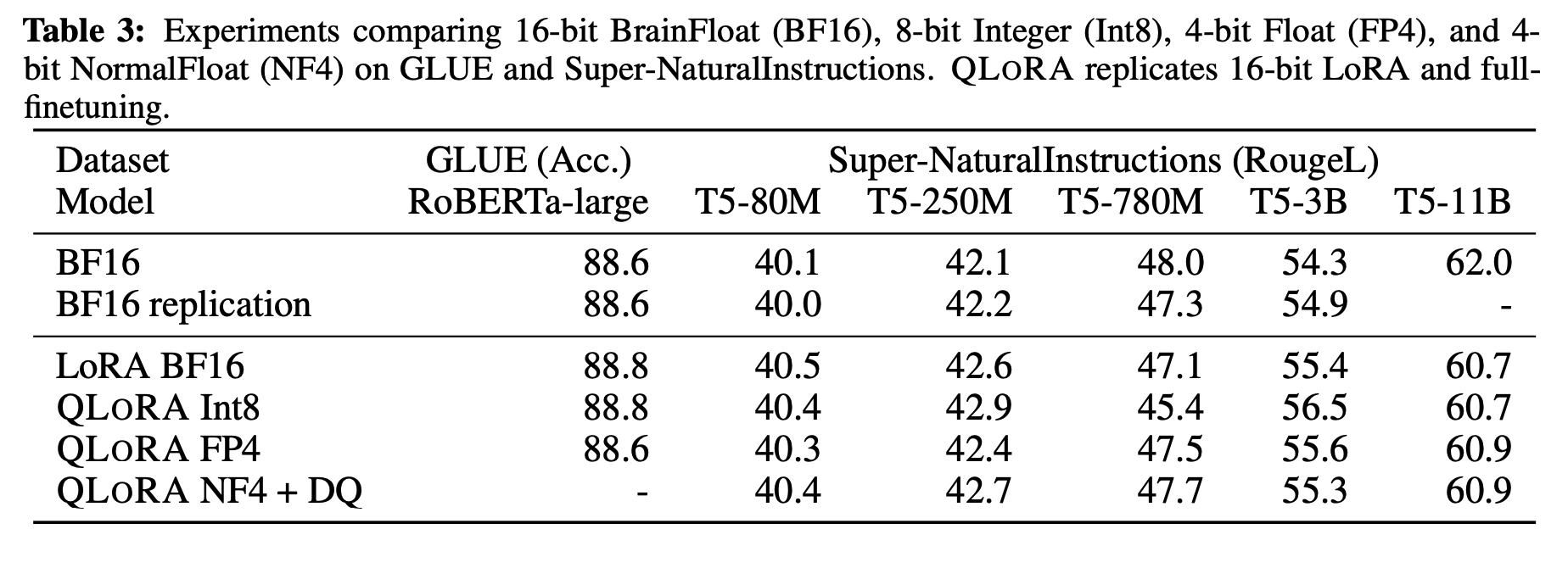
- GLUE benchmark & Super-NaturalInstructions dataset : QLoRA의 일반화 및 instruction following 성능을 평가한다.
Default LoRA hyperparameters do not match 16-bit performance

4-bit NormalFloat yields better performance than 4-bit Floating Point
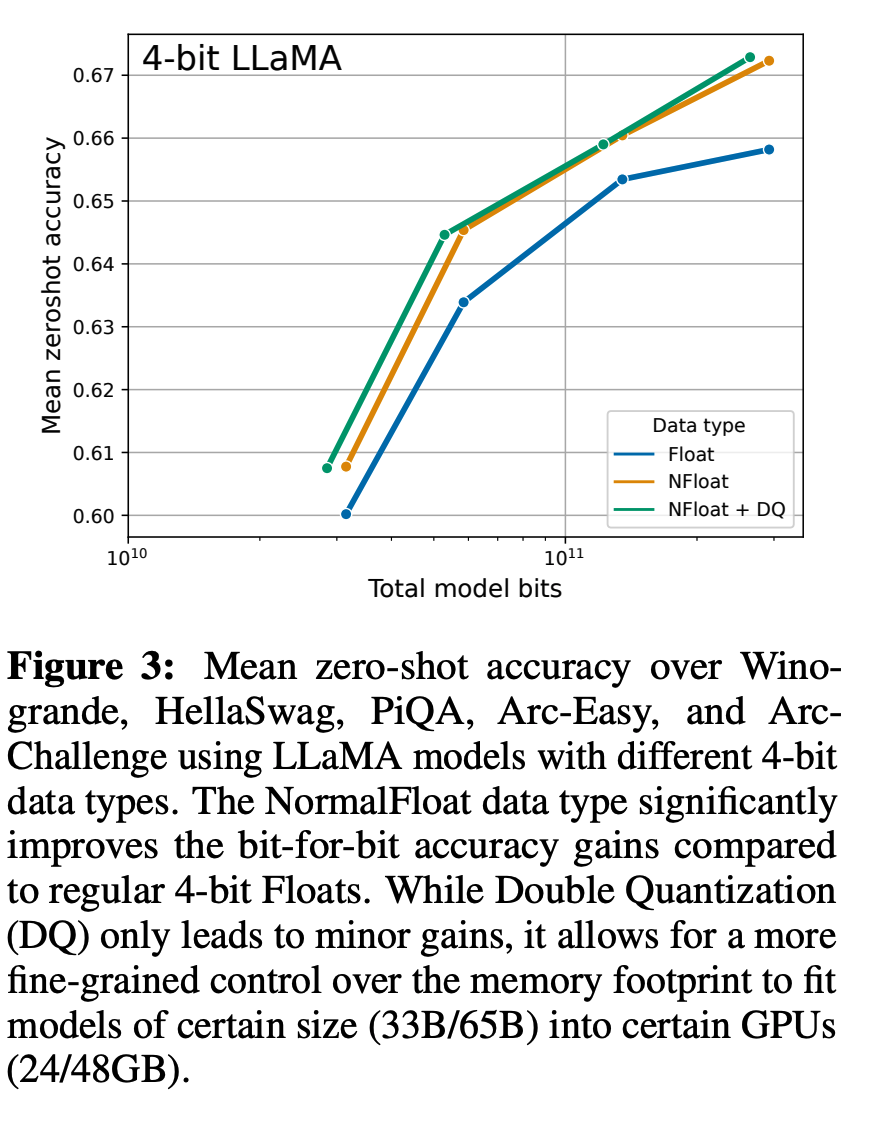

k-bit QLoRA matches 16-bit full finetuning and 16-bit LoRA performance
Summary
- 메모리 사용 감소
- 성능 유지
5. Pushing the Chatbot State-of-the-art with QLoRA
5.1 Experimental setup
- Data: 다양한 instruction을 따르는 최신 데이터셋을 사용하여 모델을 훈련. 다양한 언어, 크기 및 라이선스를 포함하는 광범위한 데이터
- 훈련 방식: 강화 학습 없는 지도 학습을 사용. 데이터셋에 명확한 지시어와 응답이 있는 경우, 응답 부분만을 미세조정에 사용
5.2 Evaluation
- 자연어 이해 벤치마크: MMLU 벤치마크를 사용하여 모델의 언어 이해 능력을 평가.
- 실제 챗봇 성능 평가: 실제 챗봇 응답의 질을 평가하기 위해 자동화된 평가와 인간 평가를 변행한다. GPT-4를 사용하여 다른 시스템의 출력과 비교하여 점수를 매긴다.
5.3 Guanaco: QLoRA trained on OASST1 is a State-of-the-art Chatbot
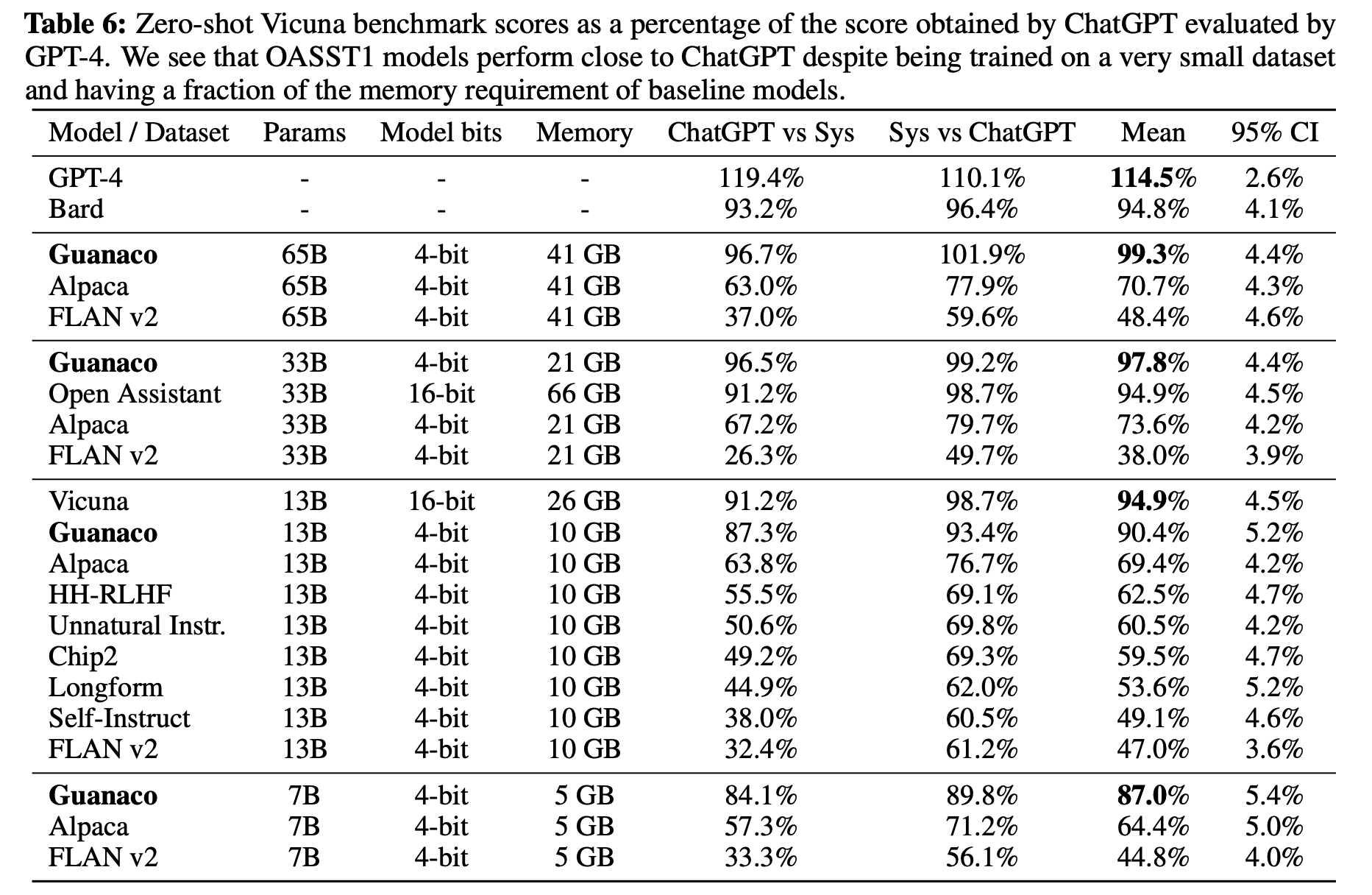
- QLoRA를 사용하여 미세조정된 'Guanaco' 모델이 새로운 최첨단 성능을 달성. 이 모델은 Vicuna 벤치마크와 같은 자연어 처리 벤치마크와 같은 자연어 처리 벤치마크에서 뛰어난 결과를 보임
- 효율성: QLoRA는 훨씬 적은 메모리를 사용하면서도, 경쟁 모델과 비교할 때 우수한 성능을 유지한다. 이는 메모리가 제한된 장치에서도 고성능 모델을 미세조정할 수 있게 한다.
6. Qualitative Analysis
6.1 Qualitative Analysis of Example Generations
특정 부분에 대한 예시를 "cherries"와 "lemons"를 구분하여 제시
- Factual Recall
- Suggestibility
- Refusal
- Secret Keeping
- Math
- Theory of Mind
6.2 Considerations
- Guanaco와 같은 모델들은 특정 벤치마크에 맞춰 최적화될 수 있으나, 이러한 벤치마크가 실제 세계의 다양한 요구사항을 충분히 반영하지 못할 수 있음. 따라서 벤치마크의 설계와 선택이 모델 평가에 미치는 영향에 대해서도 고려해야 함.
7. Related Work
Quantization of Large Language Models
- 기존의 양자화는 주로 추론 시간의 최적화를 목표로 하였으나, QLoRA는 양자화된 가중치를 통한 미세조정에 초점을 맞춘다.
Finetuning with Adapters
- 다양한 PEFT 방법, QLoRA는 이 중 LoRA adapter를 사용하여 효과적으로 성능을 유지하고 메모리 요구사항을 최소화한다.
Instruction Finetuning
- 지시어를 따르도록 학습된 언어모델들의 발전으로 검토한다.
Chatbots
- 대화 중심 모델들에 대한 설명
8. Limitations and Discussion
- 규모의 한계: 33B와 65B 크기의 모델에 대한 QLoRA의 효과를 완전히 입증하지 못하였음.
- 벤치마크의 일반성:일부 주요 벤치마크에서는 평가되지 않았음.
- 양자화의 밀도: 4-bit 이하의 더 낮은 비트 수준에서도 QLoRA가 효과적인지에 대한 연구가 부족하다.
9. Broader Impacts
- 기술 접근성의 증진: 낮은 메모리 요구사항
- 모바일 및 저전력 장치에서의 가능성
- 윤리적 및 사회적 고려사항
