[Paper Review] Rethinking Multiple Instance Learning for Whole Slide Image Classification: A Good Instance Classifier is All You Need
Paper Review
Rethinking Multiple Instance Learning for Whole Slide Image Classification: A Good Instance Classifier is All You Need
contrastive learning 과 prototype learning, joint training strategy 를 사용하여 기존 MIL 의 문제점을 완화한 연구가 공개되었다. 최근에는 attention pooling 을 활용한 aggregation 기법들이 많이 사용되었는데, attention score 가 굉장히 일부 instance에 대해서만 높아 gradient가 제한적으로 흐르기 때문에 좀 더 괜찮은 instance classifier 를 만들어 mean pooling 하는 전략을 사용하였다.
Introduction
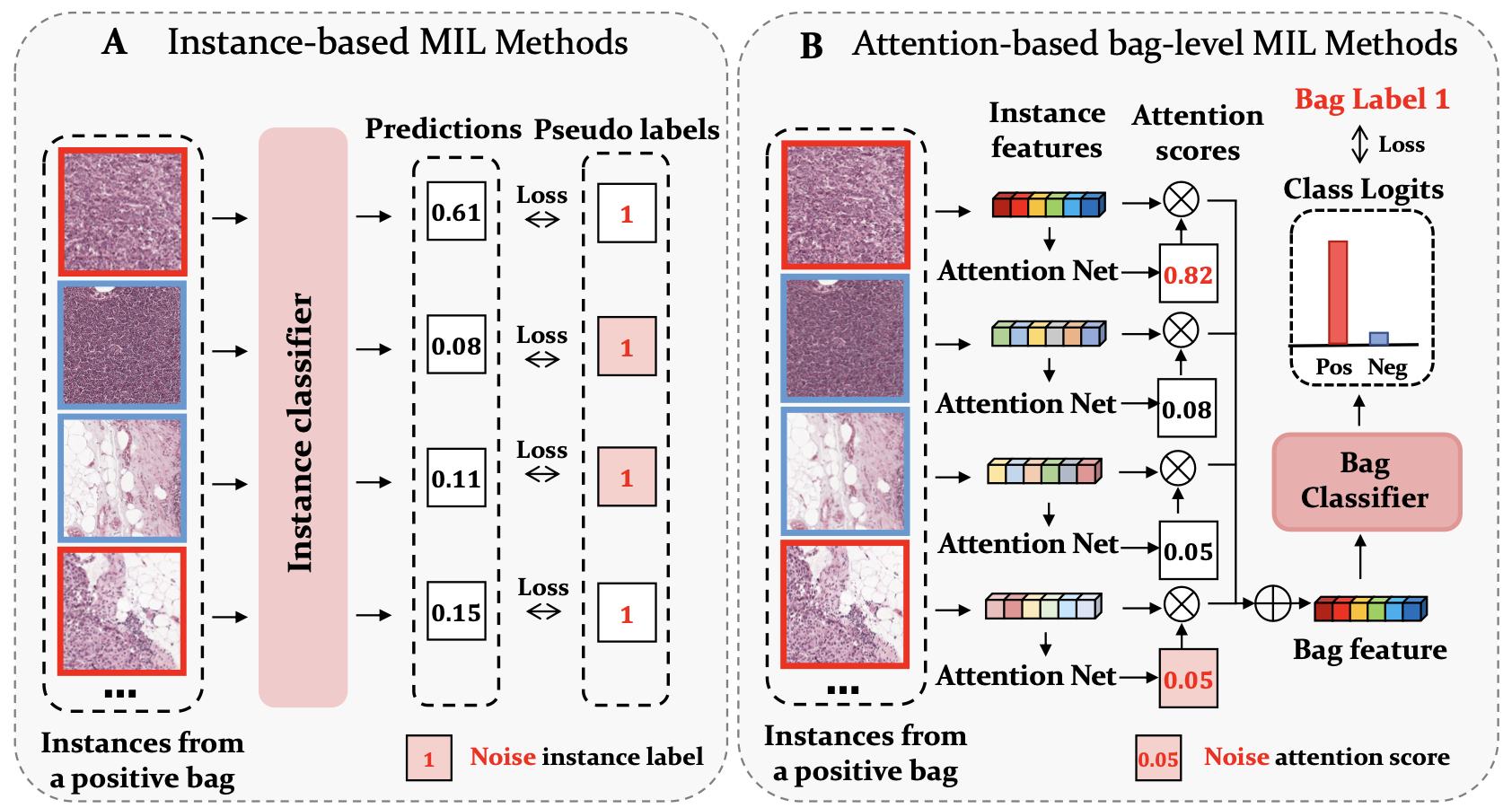
1) Low performance in instance-level classificaion
: only the most easily identifiable positive instances are found while other more difficult ones are missed
: instance pseudo labels contain a lot of noise
2) Bag-level classification performance is not robust
: A typical example is the bias that occurs in classifying bags with a large number of difficult positive instances while very few easy positive instances
The main contributions of this paper are as follows:
- We propose INS, an instance-based MIL framework that combines contrastive learning and prototype learning. This framework serves as an efficient instance classifier, capable of effectively addressing instance-level and bag-level classifi- cation tasks at the finest-grained instance level.
- We propose instance-level weakly supervised contrastive learning (IWSCL) for the first time in the MIL setting to learn good feature representations for each instance. We also propose the Prototype-based Pseudo Label Generation (PPLG) strategy, which generates high-quality pseudo labels for each instance through prototype learning. We further propose a joint training strategy for IWSCL, PPLG, and the instance classifier.
- We comprehensively evaluated the performance of INS on six tasks of four datasets. Extensive experiments and visualization results demonstrate that INS achieves the best performance of instance and bag classification.
Related work
Instance-based MIL Methods
- 주로 각 instance 에 pseudo label 을 붙이고 instance classifier 를 학습하고, bag 내부의 모든 instance prediction 을 aggregate하여 bag classification 을 수행한다.
- 하지만 positive bag 의 상당 수의 negative instance 가 positive label 관련 noise 를 받게 된다.
Bag-based MIL Methods
- instance feature 를 추출하고 aggregate 하여 bag feature 로 bag classification 을 수행한다. 특히 attention-based method 가 main stream 이고, 독립된 scoring network 의 learnable attention weight 를 사용하여 각 instance feature 점수를 매긴다.
- 하지만 쉬운 instance 에는 attention score 가 잘 반영되는데, difficult instance 에는 그렇지 않다.
Prototype Learning for WSI classification
- derived from Nearest Mean Classifier, concise representation for instance
- (내게는) 친숙하지 않은 개념이라 레퍼된 논문을 좀 살펴봤다.
TPMIL (TPMIL: Trainable Prototype Enhanced Multiple Instance Learning for Whole Slide Image Classification)
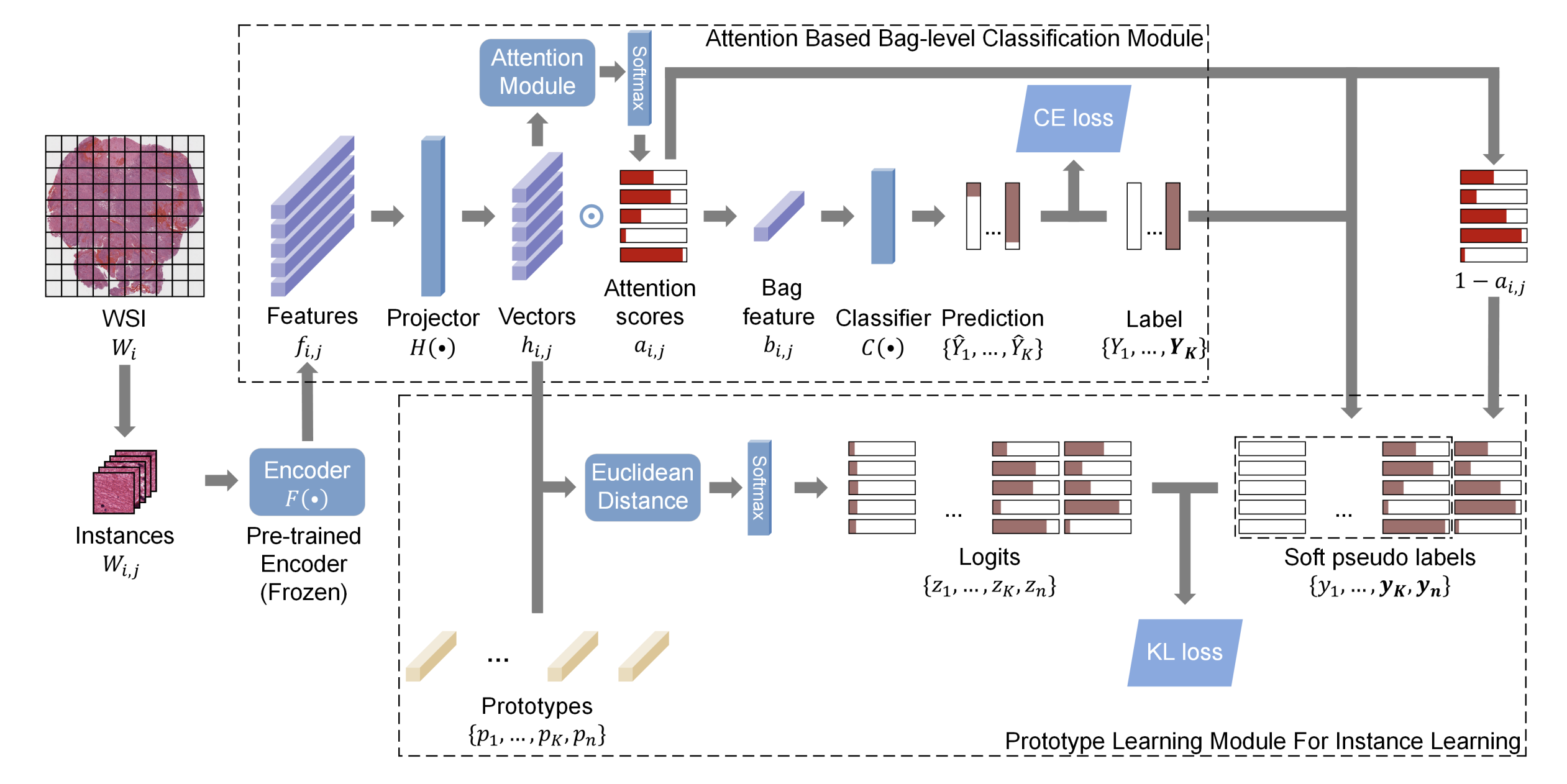
create learnable prototype vectors 후, attention score 로부터 얻은 soft pseudo label 과 KL divergence 를 계산하여 update 하는 프레임워크 이다.
- 하지만 attention score 는 challenging positive instance 를 식별하지 못하는 문제점이 있다.
- 이를 개선하기 위해, PPLG (prototype-based pseudo label generation) strategy 를 취해, high-quality pseudo-label 을 생성하고, instance contrastive representation learning, prototype learning, instance classifier 간의 joint training 을 수행한다.
- 특히 negative bags 에서 sampling 한 instance 는 true negative instance 인 점을 활용하여 instance classifier 로부터 prototype learing 에 가이드를 준다.
Methods
Problem Formulation

binary setting 이다. 이 setting 에서는 negative bags 의 모든 instance 는 negative instance 이다.
Framework Overview
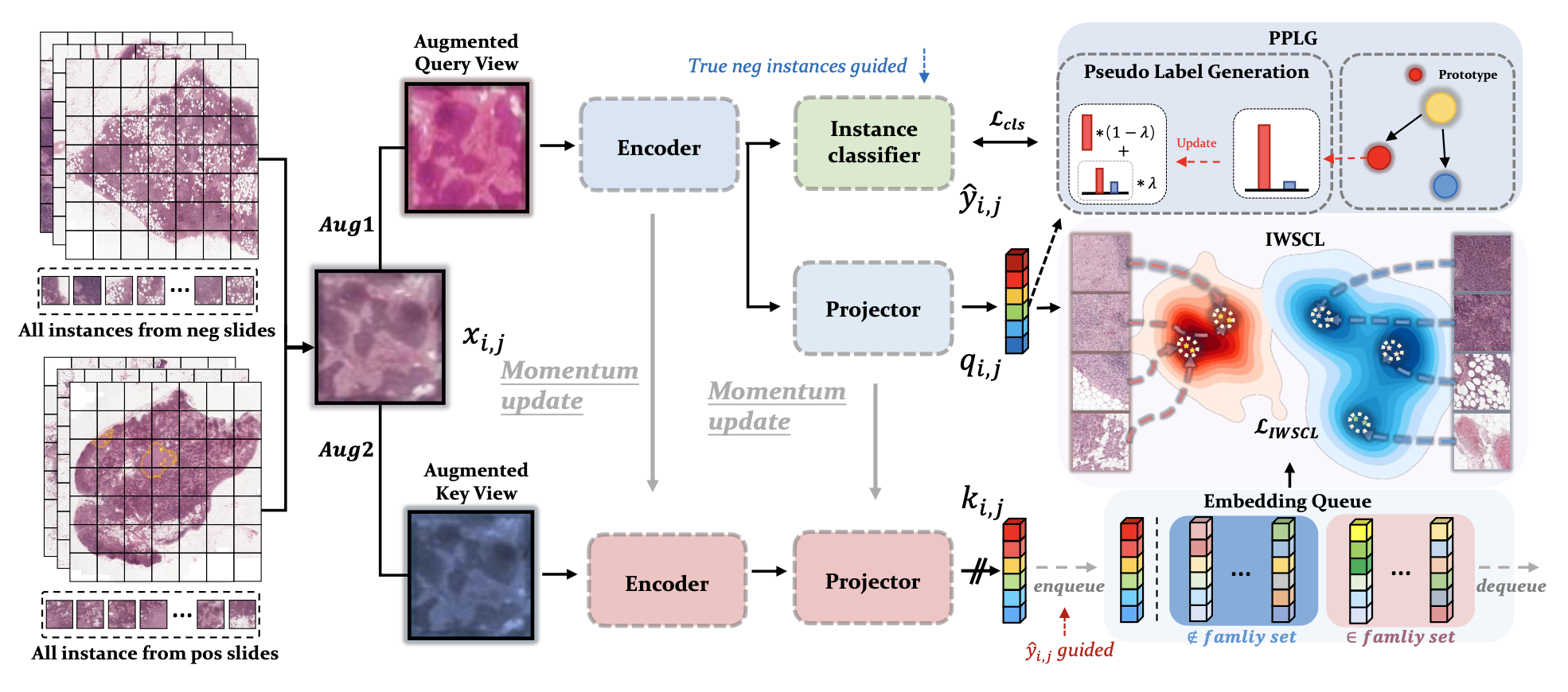
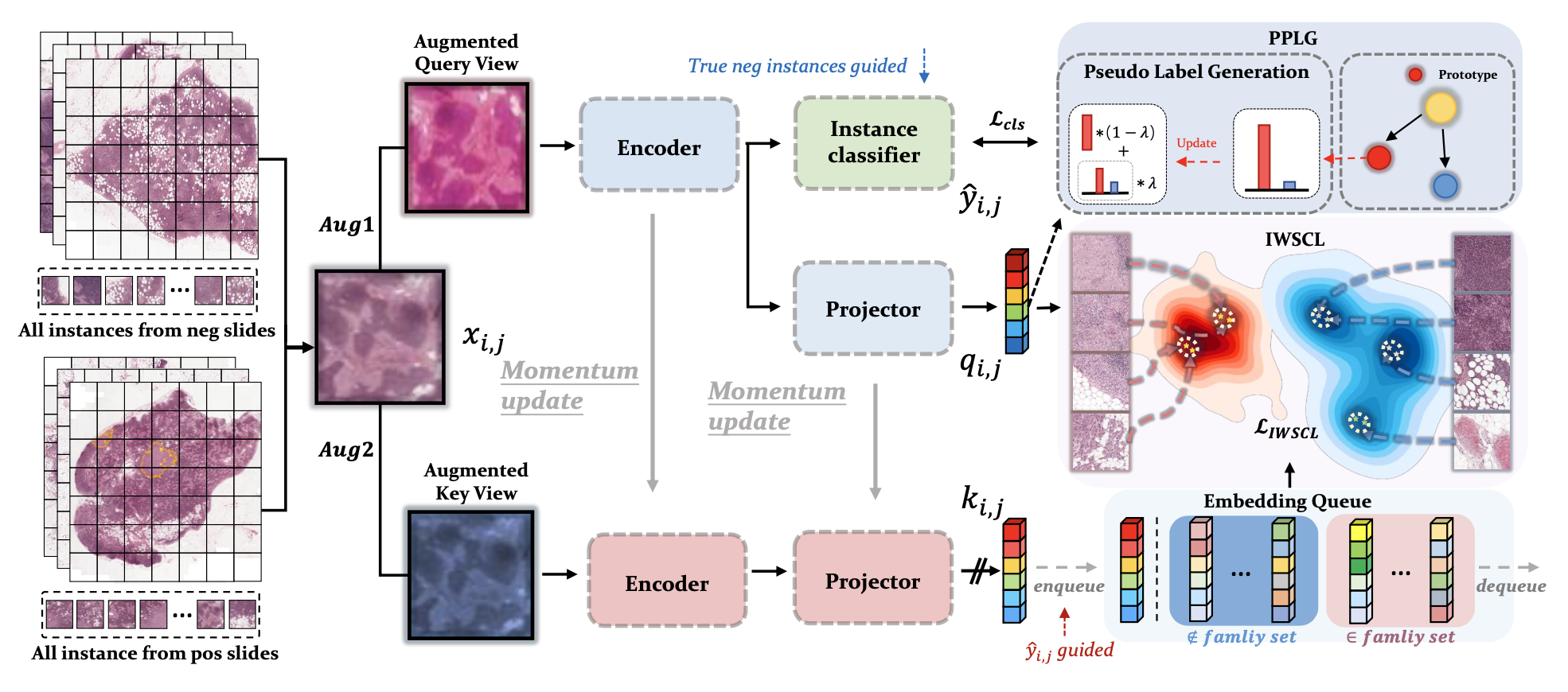
bag 으로부터 instance 를 sampling 하고 query view 와 key view 를 two augmentation 으로부터 얻는다. query view branch 에서 encoder 를 거친 feature 를 instane classifier 와 projector (MLP-based) 에 넣고, 각각으로부터 predicted class , feature embedding 를 얻는다. key view branch 에는 gradient 가 흐르지 않는 대신, query branch 로부터 momentum update 방식으로 모델이 업데이트 된다. 그림처럼 encoder 와 projector 를 거쳐 를 얻는다. 여기서 조금 복잡한데, 위 query branch 로부터 얻었던 predicted class 와 함께 넣어주는 것이 포인트이다. 이를 embedding queue 에 enqueue 한 후, 내부에서 contrastive learning loss 를 계산한다. 이 부분은 아래 다른 섹션에서 더 설명하도록 하겠다. 마지막으로, 다시 query branch 로부터 나온 와, prototype vector와 loss 를 계산한다. PPLG module 내에서는 two representative feature vector 를 positive, negative class training 과정에서 계속해서 업데이트 한다. 이 또한 아래 섹션에서 더 설명하도록 하겠다.
Instance-level Weakly Supervised Contrastive Learning
목적: 좋은 feature representation 을 얻는 것.
논문에서도 언급하지만, 사실 contrastive learning 에서 가장 중요한 것은, 식이 어떻고를 떠나서 어떻게 negative, positive sample set 을 construction 하느냐가 핵심이다. 기존 self-supervised learning setting 에서는 본인과 본인을 제외한 나머지로 보통 셋을 구성했지만, MIL setting 에서는 negative bag in the training set 으로부터 뽑은 all instance 는 true negative label 을 갖고 같은 셋에 속하도록 할 수 있다. 이러한 트릭을 다른 어느 논문에서도 사용하지 않았다고 한다. 이 weak label 정보는 instance-level contrastive learning 을 효율적으로 guide할 수 있었다고 한다.
특히 large Embedding Queue 에서 feature embedding 와 그것들의 class 를 함께 저장했고, 이 때, true negative instance 같은 경우에는, predicted class 를 저장하지 않고, 바로 directly assign them a definite negative class 로 하였다. 이 부분을 계속 강조하는 이유는,, 나중에 framework 를 좀 더 자세히 봤을 때, '임의로 만든 것' 과 '임의로 만든 것' 간의 거리를 비교하고 또 '임의로' 만드는 과정이 들어가는데, 그것의 base... 기반이 되어주는 true basic label 으로써 굉장히 중요한 역할을 수행한다.
- Family and Non-family sample selection
large embedding queue 에서 family set 와 non family set 를 구성하고, 에 기반하여 contrastive loss 를 계산한다. 이 때, 는 q, k 와 embedding queue whose class label equals 로부터 구성되고, 그 나머지는 모두 가 된다. 이것이 전부이다.

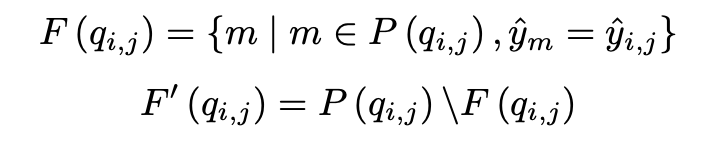
B 는 minibatch 를 뜻한다. Q는 embedding queue 이다.
위 family set 과 non-family set 을 이용해 다음과 같은 loss 를 계산한다.
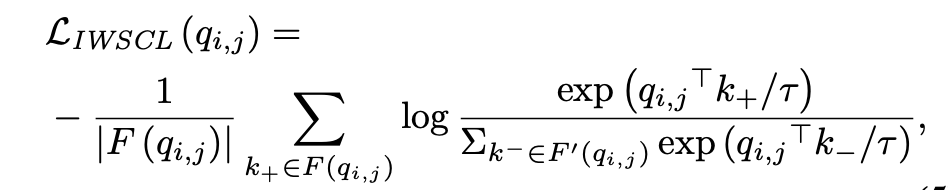
- Embedding Queue Updating
iteration 끝마다, current instance's momentum embedding 와 predicted label 또는 true negative label 은 embedding queue Q 에 들어가고 오래된 건 dequeue 된다.
Prototype-based Pseudo Label Generation
목적: assign more accurate pseudo labels to instances by prototype learning
아직 설명 전이지만, 이 과정을 통해, maintain two representative feature vector 를 얻는다. , . 사실 pseudo label 의 생성과 prototype 의 updating process 역시 (아까 말했듯) true negative instance 와 instance classifier (predicted label을 만들어 주기 때문) 에 의해 guide 된다.
만약 가 positive bag 으로 부터 왔다면, embedding 과 prototype vectors 로 pseudo label 를 생성한다.
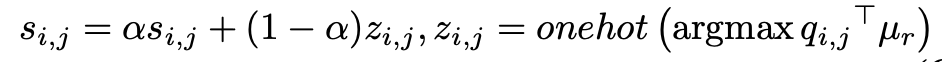
동시에, prototype vector of the corresponding class 를 predicted label 과 embedding q 로 update 한다.
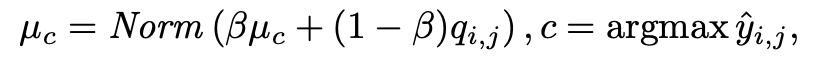
만약 negative bag 으로부터 왔다면, directly assign negative label 후, embedding q 를 활용하여 negative prototype vector 를 update 한다.
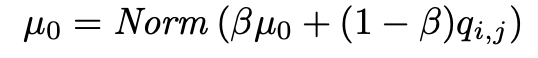
마지막으로, generated pseudo label 을 실제 encoder 로부터 나온 smoothed predicted value 간의 cross-entropy loss 를 계산하여 iteration 을 마치게 된다.
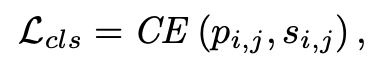
Bag Constraint and Total Loss
정말 마지막 단계로, bag label 을 조금 더 활용하기 위해 embedding vector 를 mean pooling 해서 bag label 과 cross entropy loss 를 계산해서 total loss 에 더해준다.

요즘 트렌드인 attention weight 를 전혀 사용하지 않은 부분이 상당히 인상적이다.
Experimental Settings
Dataset
- Simulated CIFAR-MIL Dataset
: 32x32 이미지 합쳐서 WSI 처럼 합성, 하나의 category label 을 positive 로 정의. - Camelyon16 Public Dataset
: 512x512 image patches under 10x mag, total 186604 instances. - TCGA LUNG Cancer Dataset
: 1054 WSIs, 5.2 million patches at 20x mag. - Cervical Cancer Dataset
: 374 WSIs, 5x mag, 224x224 patches
Evaluation Metrics and Comparision Methods
in both instance and bag classification, AUC & acc are used.
compared out INS to 11 competitors:
MILRNN, Chi-MIL, DGMIL (instance)
ABMIL, Loss-ABMIL, CLAM, DSMIL, TransMIL, DTFD-MIL, TPMIL, WENO (bag)
Results
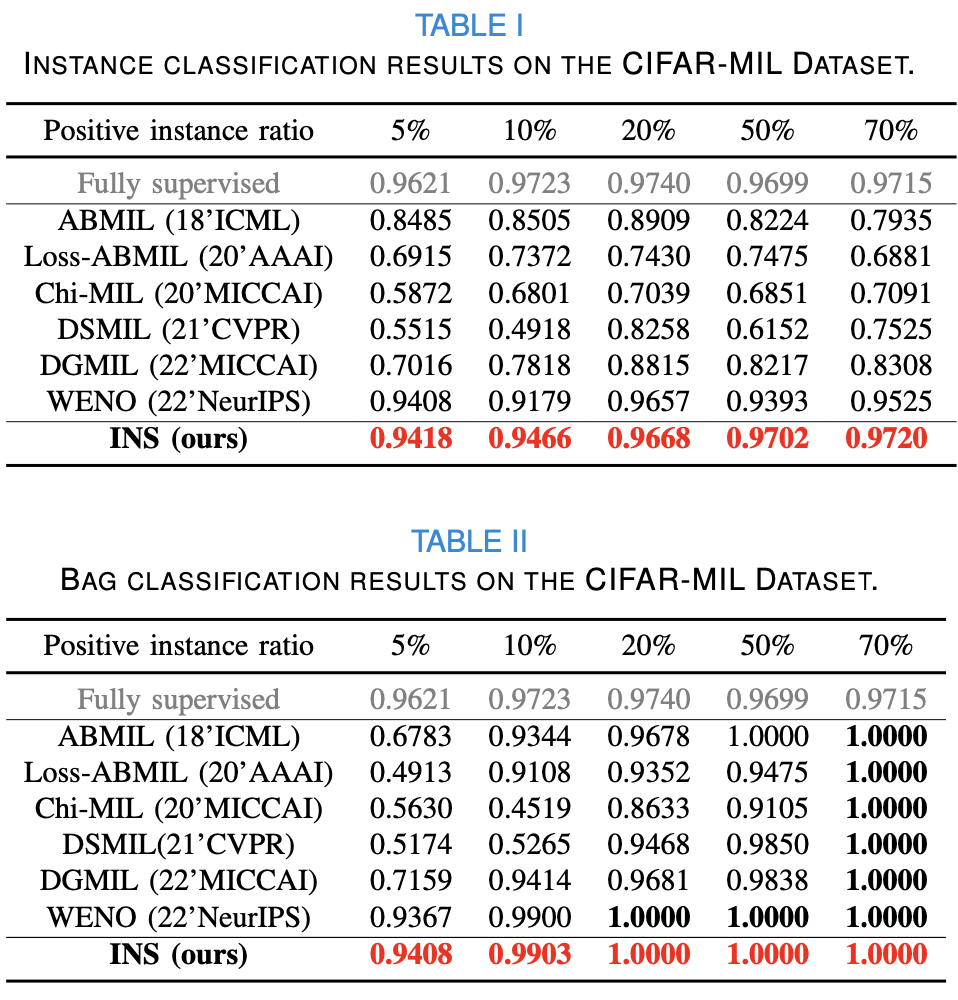
Synthetic Dataset CIFAR-MIL
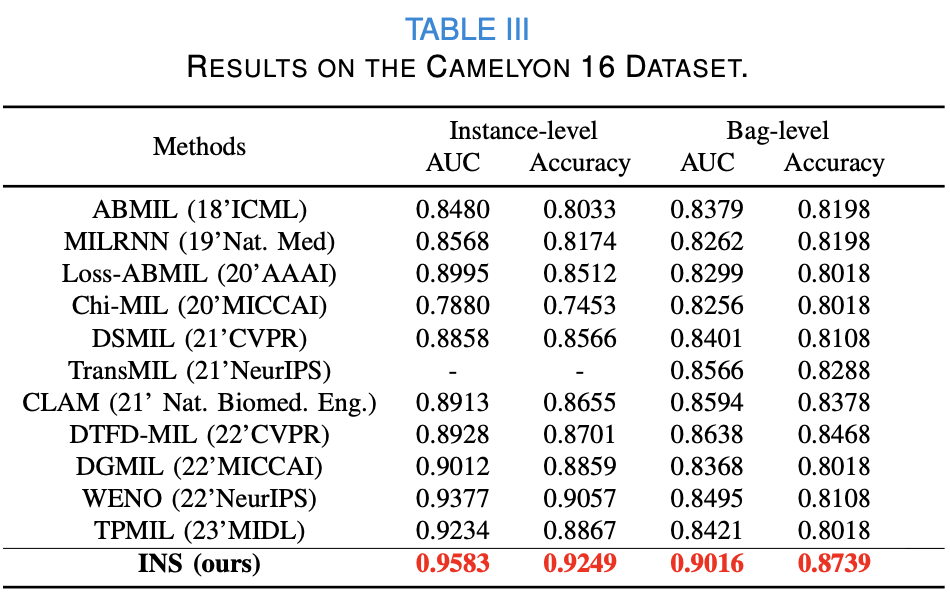
Camelyon 16 Dataset

TCGA-LUNG cancer Dataset

Cervical Cancer Dataset

Interpretability Study of the Lymph Node Metastasis
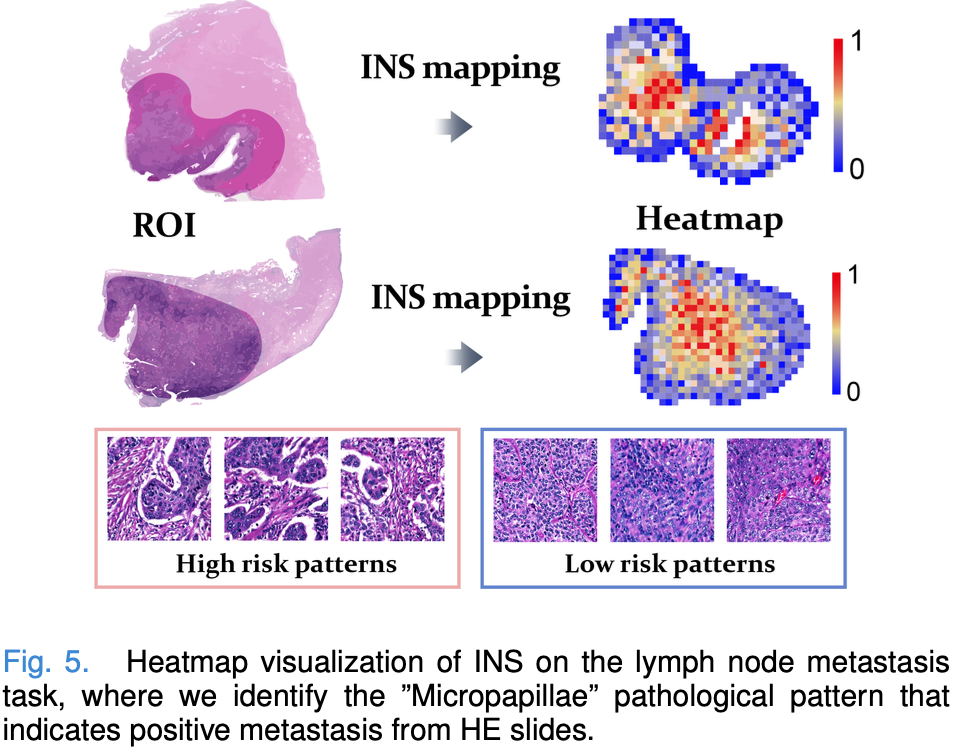
INS to predict the probability of each instance being positive within the positive bags and visuazualied the top 0.1% instances with the highest and lowest probilities separately.
- lymph node metastasis "micropapillae" are more prevalent
- 특히, small clusters of infiltrating cancer cells forming hollow or mulberry-like nests without a central fibrovascular axis, surrounded by blank lacunae or lacunae between interstitial components
- negative lymph node more commonly exhibits a sheet-like pattern
나머지가 조금 있긴 한데 추후에 업데이트 하겠다.

재밌는 논문이네요 혹시 더 업데이트해주실수 있으신가요?