1. 프로젝트 개요
https://apiportal.koreainvestment.com/apiservice/apiservice-domestic-stock-quotations#L_07802512-4f49-4486-91b4-1050b6f5dc9d 의 주식 정보 데이터에 대해서, 데이터 파이프라인을 구축하는 프로젝트.
사용 기술 : docker, airflow, GCP Compute Engine, Snowflake, AWS S3
2. GCP Compute Engine 설정
-
GCP에서 Compute Engine -> VM 인스턴스 를 선택한다.
-
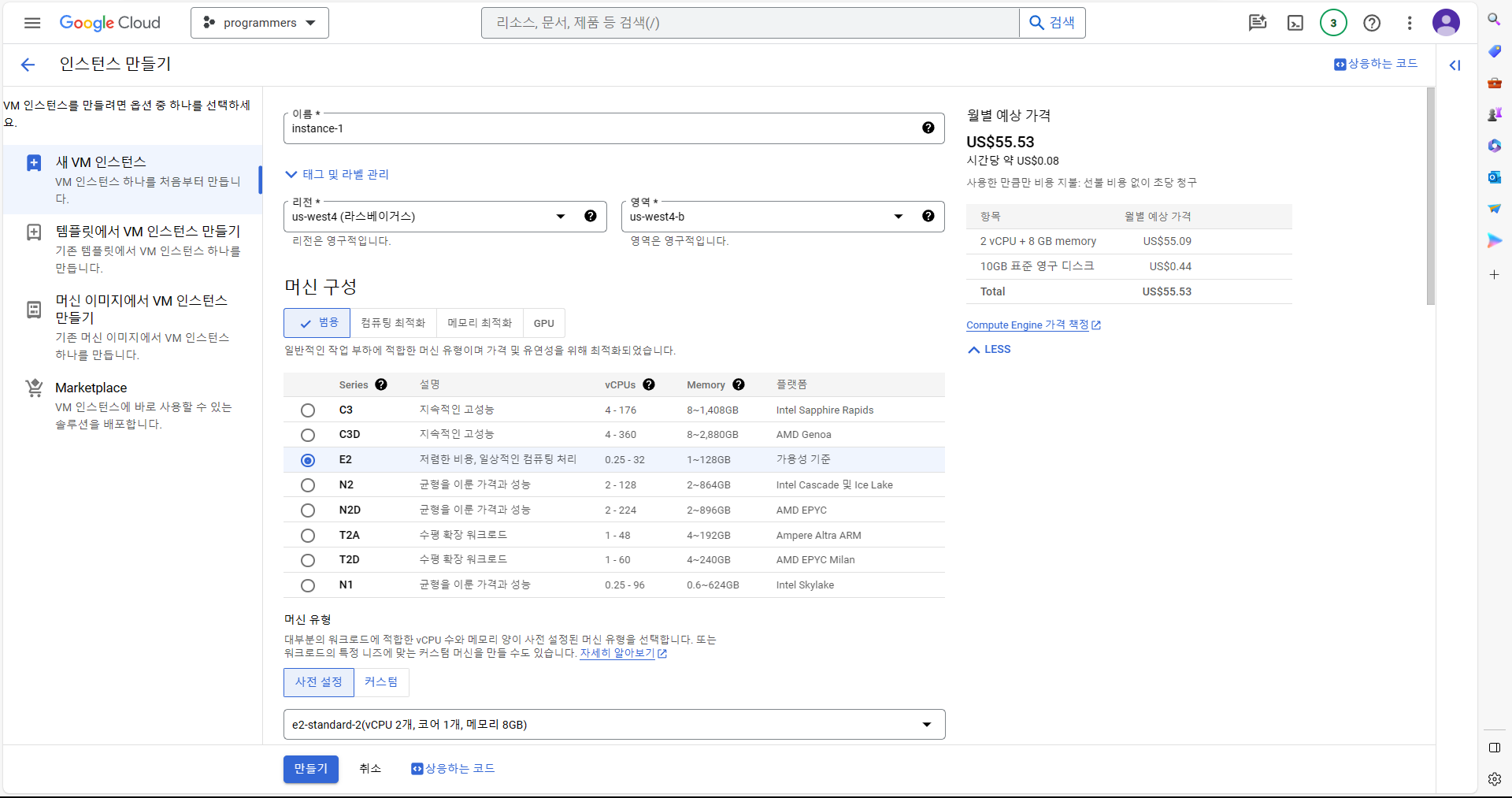
인스턴스 생성 -> 머신 구성에서 E2 선택 -> 머신 유형에서 e2-standard-2 선택 -> 부팅 디스크에서 변경 선택 후, 운영 체제 Ubuntu 선택, 버전은 그대로, 크기는 100GB로 설정. -> 부팅 디스크 설정 후 아래의 액세스 범위에서 "모든 Cloud API에 대한 전체 액세스 허용" 선택 -> 방화벽에서 "HTTP(S) 트래픽 허용" 체크 -> 만들기.
3. 외부에서 ssh로 GCP Compute Engine 연결.
3-1. Windows
-
PuTTY KEY Generator에서 generate 선택.
-
창 위에서 마우스 계속 움직여서 키 생성.
-
키 생성 후, Key Comment에 키에 대한 이름 입력.
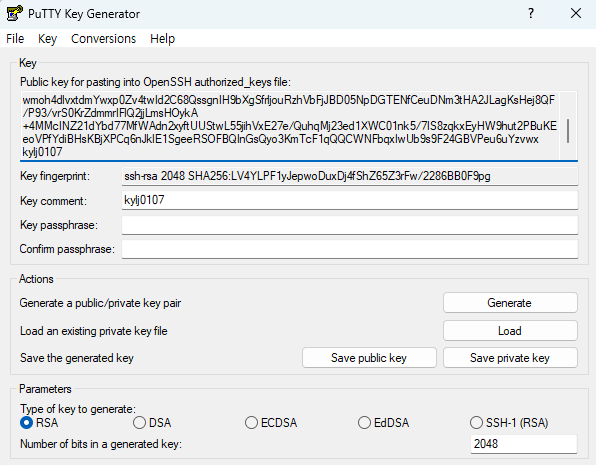
-
상단의 Key 내용 복사.
-
Save public key 및 Save private key 선택하여 ppk 파일 저장.
-
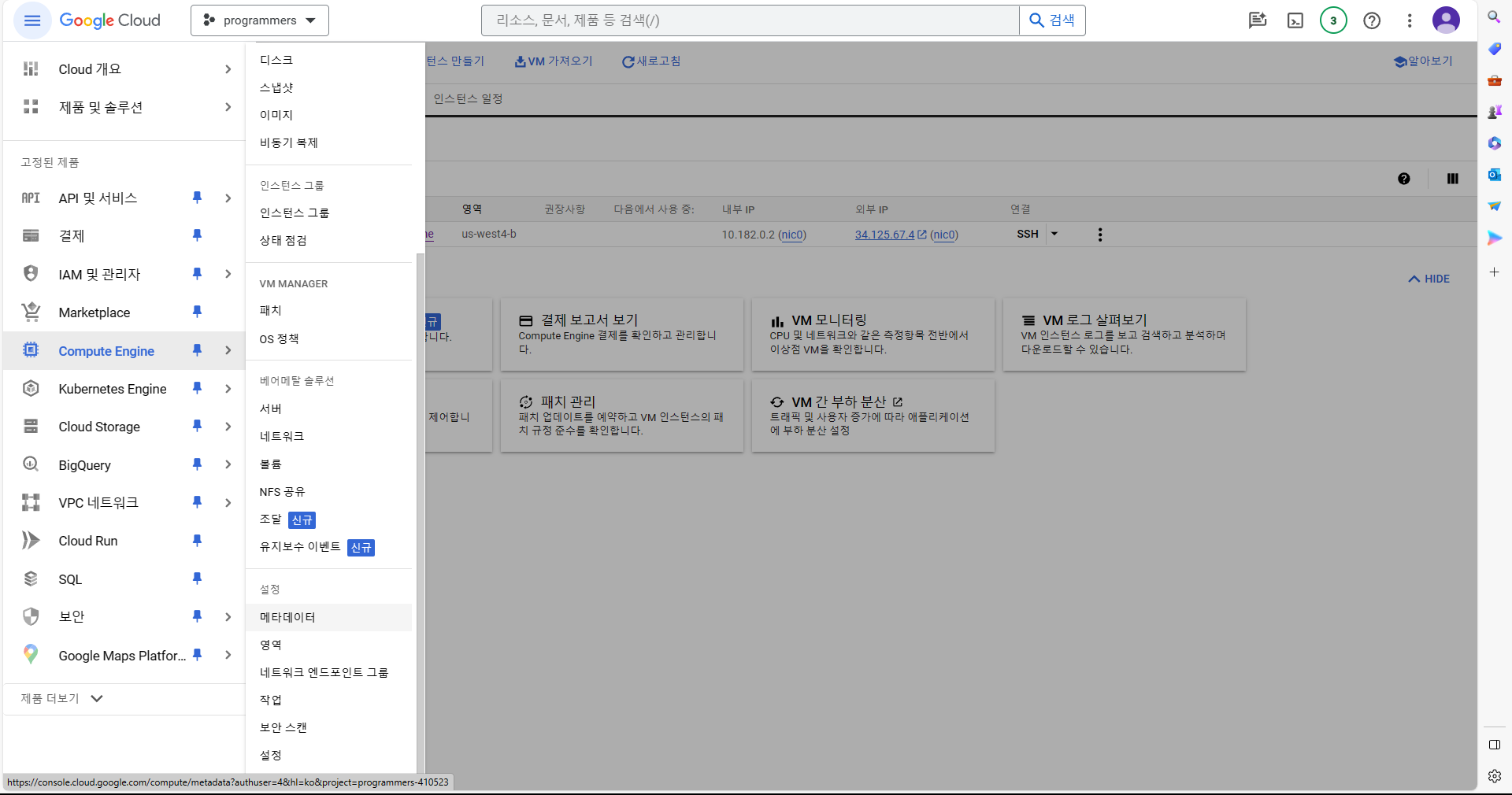
GCP에서 Compute Engine -> 설정 -> 메타데이터 선택.
-
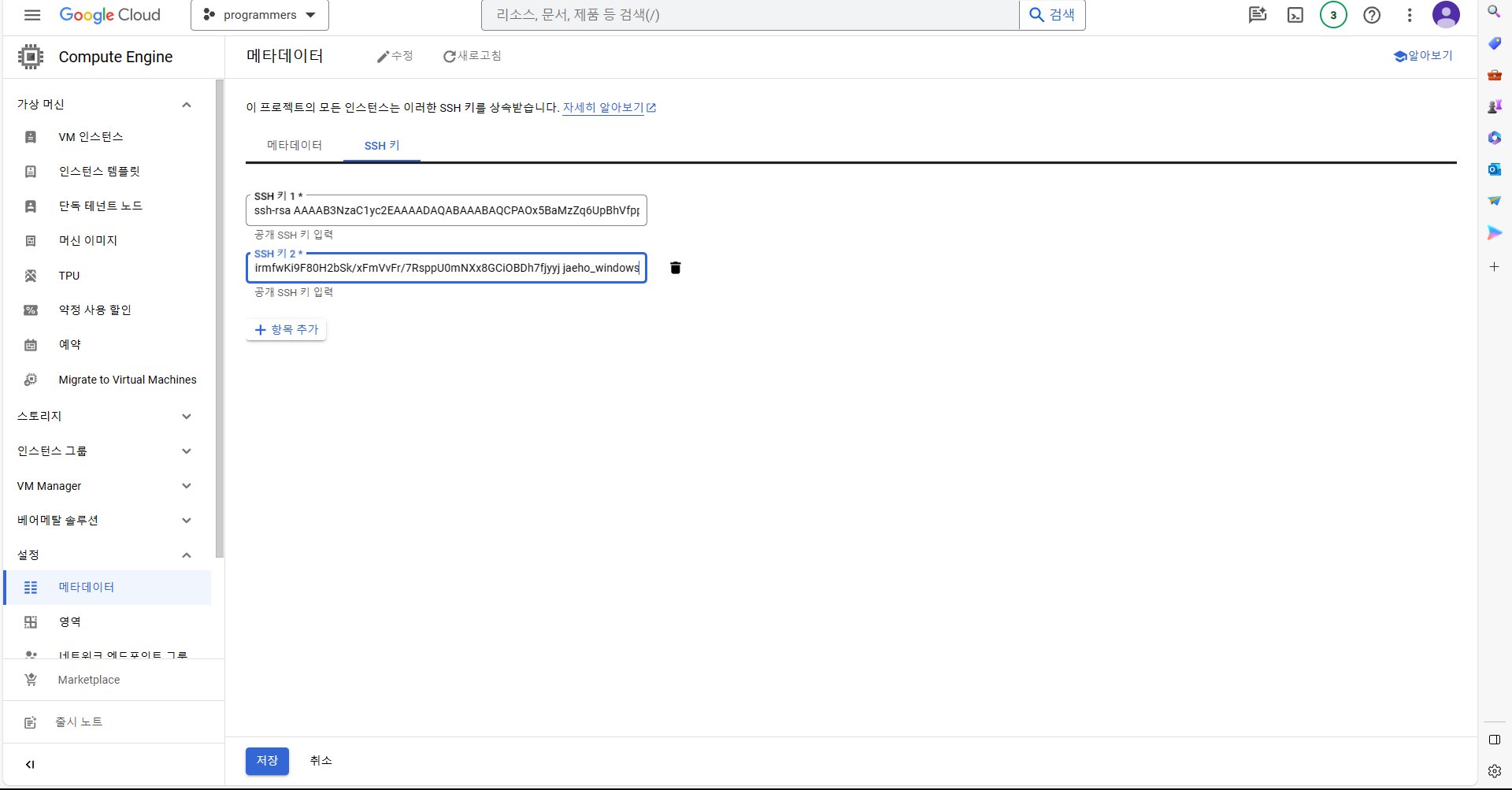
메타데이터 생성 선택 -> SSH 키 -> 항목 추가 선택 후, 복사했던 Key 내용 입력 -> 저장
-
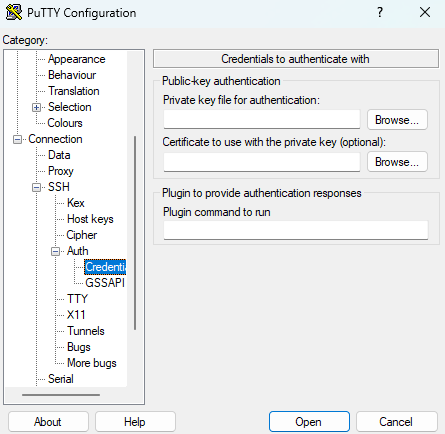
putty에서 Connection -> SSH -> Auth -> Credentials 선택 후, private key ppk file 업로드.
-
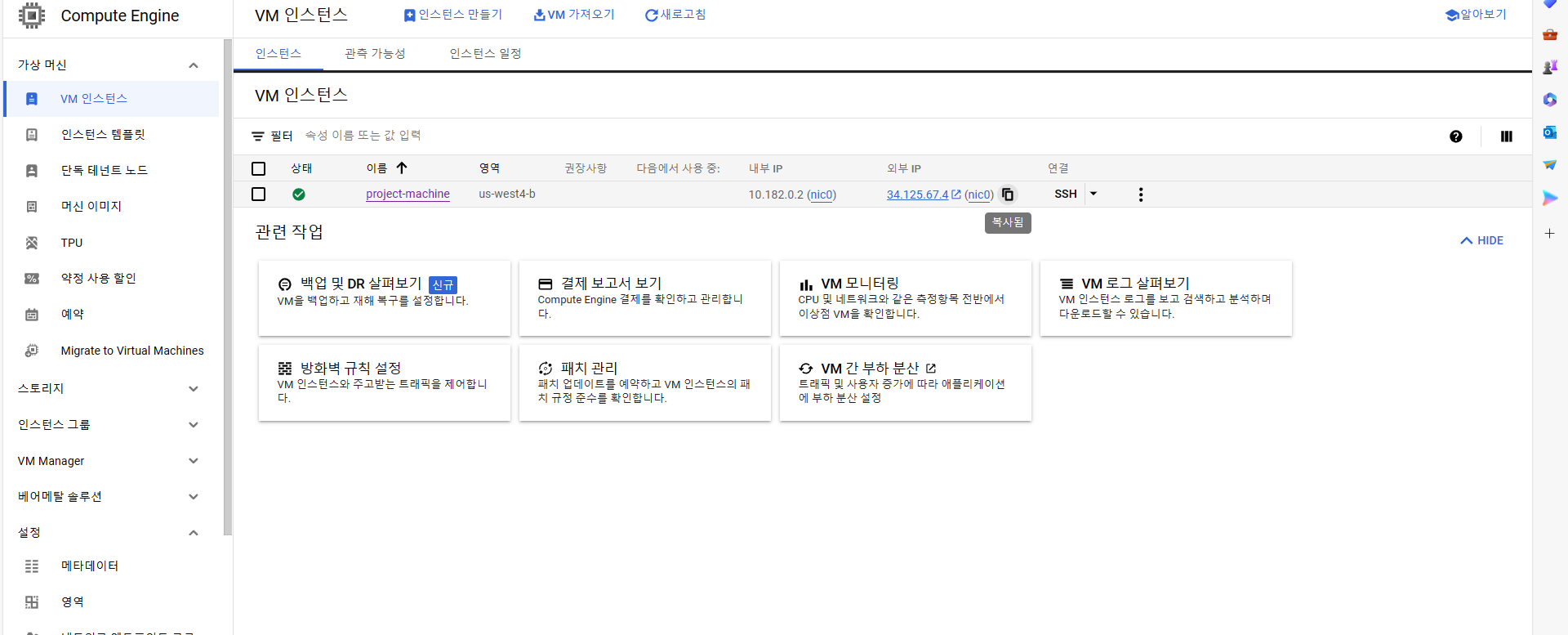
Session에서 Host Name에 {username}@{GCP 외부 IP 주소} 입력 후, 오픈.
3-2. Mac
4. Snowflake S3 연동
--S3 버킷에서 데이터 가져오기
COPY INTO dev.raw_data.test_data
from 's3://버킷주소/파일이름'
credentials=(AWS_KEY_ID='ABC...HIJ' AWS_SECRET_KEY='123ABC...789XYZ')
FILE_FORMAT = (type = 'CSV' skip_header=1);