요약.
- 빅데이터 처리를 위해 하둡이라는 오픈소스가 등장함.
- 분산 파일 시스템(HDFS)과 분산 컴퓨팅 시스템(맵리듀스->YARN)으로 구성됨.
- 맵리듀스 프로그래밍의 제약성으로 인해 SQL이 재등장.- Spark은 대세 대용량 데이터 분산 컴퓨팅 기술.
- Pandas + Scikit Learn의 스테로이드 버전.
- SQL과 스트림 데이터와 그래프 처리도 제공.
1. 빅데이터란
정의 1.
- 서버 한 대로 처리할 수 없는 규모의 데이터.
- 즉, 분산 환경이 필요한 규모의 데이터.
- 예) 판다스로 처리하기에 데이터가 너무 커서 Spark을 활용해야하는 경우.
정의 2.
- 기존의 소프트웨어로 처리할 수 없는 규모의 데이터.
- 예) 기존의 서비스인 오라클, MySQL과 같은 RDB로는 처리할 수 없는 규모의 데이터.
- 서버 한 대로 구성되는 대신, Scale-up 방식으로 메모리, CPU, DISK 등을 업그레이드.
정의 3.
- 4V (Volume, Velocity, Variety, Veracity).
- Volume: 데이터의 크기가 대용량인지.
- Velocity: 데이터의 처리 속도가 얼마나 중요한지.
- Variety: 데이터의 특성, 구조화/비구조화 데이터인지?
- Veracity: 데이터의 품질이 좋은지.
빅데이터 예 - 디바이스 데이터.
- 모바일 디바이스: 위치 정보.
- 스마트 TV.
- IoT 센서.
- 네트워킹 디바이스.
빅데이터 예 - 웹.
- 수 많은 웹 페이지가 존재 -> 온갖 지식의 바다.
- 웹 검색 엔진 개발은 대용량 데이터 처리로 볼 수 있음.
- 웹 페이지 크롤링 -> 인덱싱 -> 서빙.- 사용자 검색어와 클릭 정보 자체도 대용량 데이터. 이를 마이닝하여 개인화 가능.
- 요즘은 웹 자체가 NLP 거대 모델 개발의 훈련 데이터로 사용되고 있음.
2. 빅데이터 처리의 문제점 및 해결 방안.
문제.
1. 큰 데이터를 손실 없이 보관할 방법이 필요함. 즉, 스토리지가 있는가.
2. 빅데이터를 직렬로 처리하면 시간이 오래 걸림. 즉, 병렬 처리 방식이 필요함.
3. 비구조화된 데이터를 어떻게 처리할 것인가. SQL만으로는 부족함. 예) 웹 로그 파일.
해결 방안.
1. 빅 데이터를 저장할 수 있는 분산 파일 시스템.
2. 병렬 처리가 가능한 분산 컴퓨팅 시스템.
3. 비구조화 데이터 처리 방법.
- 즉, 다수의 컴퓨터로 구성된 프레임웤이 필요함.
대용량 분산 시스템이란,
- 분산 환경 기반 (다수의 서버로 구성됨.)
- 컴포넌트: 분산 파일 시스템, 분산 컴퓨팅 시스템.- Fault Tolerance: 일부 서버가 고장나도 동작해야함.
- 확장이 용이해야함: Scale Out(서버 추가)이 가능해야함.
3. 하둡의 등장과 소개.
Hadoop.
- 구글에서 발표한 논문에 기반하여 만든 오픈소스 프로젝트.
- 처음 시작은 Nutch라는 오픈소스 검색 엔진의 하부 프로젝트였으나, 2006년에 아파치 톱레벨 프로젝트로 나옴.
Hadoop이란,
- 저렴한 컴퓨터로 구성된 다수의 서버로 분산 파일 시스템(HDFS) 및 분산 컴퓨팅 시스템(맵리듀스->YARN)이 가능한 서비스.
- 다수의 노드로 구성된 클러스터 시스템.
- 마치 하나의 거대한 컴퓨터처럼 동작.
- 다수의 컴퓨터들이 복잡한 소프트웨어로 통제됨.
하둡의 발전.
- 하둡 1.0은 HDFS 위에서 MapReduce라는 분산 컴퓨팅 시스템이 도는 구조.
- 하둡 1.0의 MapReduce가 생산성이 떨어져서 하둡 2.0에서 아키텍처가 크게 변경됨.
- 하둡 2.0의 YARN은 분산 처리 시스템 위에서 동작하는 앱이 됨.
- 하둡 2.0의 Spark은 YARN 위에서 앱 레이어로 실행됨.
HDFS - 분산 파일 시스템.
- 데이터를 블록 단위로 나눠 저장.
- 한 블록의 디폴트 크기: 128MB.- 블록 복제 방식 적용 (소수의 서버가 고장날 경우에 대비).
- 각 블록은 세 군 데에 중복 저장됨.
- Falut Tolerance 보장.
- 하둡 2.0 내임 노드 이중화 지원.
- 내임 노드: 메타 정보를 갖는 디렉토리.
- 내임 노드가 동작하지 않으면 블록 내 데이터 노드는 무쓸모임. 따라서, 내임노드의 이중화가 필요.
- Secondary 내임 노드를 통해 메인 내임 노드를 만들어 냄. -> 불편함.
- 보완책: Active 내임 노드와 Standby 내임 노드로 존재함.
MapReduce - 분산 컴퓨팅 시스템.
- 하둡 1.0.
- 다수의 테스크 트래커(slave)와 하나의 잡 트레커(master)로 구성됨.
- MapReduce만 지원함 -> 제너럴한 시스템이 아님. -> 하둡 2.0의 YARN으로 진화.
YARN - 분산 컴퓨팅 시스템.
- 하둡 2.0.
- 세부 리소스 관리가 가능한 범용 컴퓨팅 프레임웤.
- 커스텀으로 분산 컴퓨팅 방식을 만들 수 있음.
- 리소스 매니저(master).
- 노드 매니저(slave).
- 컨테이너(앱 마스터, 테스크).
- Spark은 이 위에서 구현됨.
YARN의 동작.
1. 클라이언트 -> 리소스 매니저: 실행 코드와 환경 설정 정보 등을 리소스 매니저에게 제출.
2. 리소스 매니저 -> 노드 매니저: 노드 매니저를 통해 앱 마스터(컨테이너 내부에서 실행)를 실행.
3. 앱 마스터 -> 리소스 매니저: 리소스 매니저에게 코드 실행에 필요한 리소스(자원)을 요청함.
4. 앱 마스터 -> 노드 매니저: 노드 매니저를 통해 컨테이너들을 받아 코드(테스크)를 실행함.
5. 테스크 -> 앱 마스터: 테스크들은 자신의 상황을 주기적으로 앱 마스터에게 보고함.
Hadoop 3.0.
- YARN 2.0을 사용.
- YARN 프로그램들을 플로우(그룹)으로 나눠서 자원 관리가 가능.
- 비슷한 목적을 갖는 앱끼리 정보를 공유하여 리소스를 아낄 수가 있음.
- YARN에서 발생하는 다양한 이벤트들을 저장하는 타임라인 서버에서 HBase를 기본 스토리지로 사용.
- 파일 시스템.
- 다수의 스탠바이 내임 노드를 지원.
- HDFS, S3, Azure Storage뿐만 아니라, Azure Data Lake Storage 등을 지원.
4. 맵리듀스 프로그래밍
특징.
- 데이터셋은 key, value의 집합이라는 전제 조건 필요.
- 데이터 조작은 map과 reduce 두 개의 오퍼레이션으로만 가능함.
- 두 오퍼레이션은 항상 하나의 쌍으로 연속으로 실행됨.
- 오퍼레이션의 코드는 개발자가 커스텀으로 채워야 함.
- Map 코드의 결과를 Reduce 코드에서 모아 줌.
- 이 단계를 셔플링이라 부르며 네트워크를 통해 데이터 이동이 생김.- Map의 입력은 (시스템이 정해줌) HDFS 파일에서 지정된 값으로 넘어 옴. (key, value) -> (key', value')
- Reduce의 입력은 시스템에 의해 주어짐. (key, [value1, value2, value3, ...]) -> (key'', value'')
Shuffling and Sorting.
- Shuffling: Mapper의 출력을 Reducer로 보내 주는 프로세스. 전송되는 데이터의 크기가 너무 크면 병목 현상이 발생함.
- Sorting: 모든 Mapper의 출력을 받아 키별로 정렬.
Data Skew.
- 각 테스크가 처리하는 데이터 크기에 불균형이 존재한다면?
- 병렬 처리가 의미가 없음.
- Reducer로 오는 나눠진 데이터의 크기가 큰 차이가 있을 수 있음.
- 빅데이터 시스템에서 자주 발생하는 문제 중 하나.
MapReduce 프로그래밍의 문제점.
- 낮은 생산성.
- 두 개의 오퍼레이션만 존재.
- (key, value)라는 하나의 데이터 포맷만 적용 가능.
- 배치 작업만 가능.
- 빠른 속도로 데이터를 처리하지 못함.
MapReduce의 대안책.
- 범용적인 프레임웤의 등장: YARN, Spark.
- SQL의 재등장: Hive, Presto.
5. 하둡 설치 및 맵리듀스 실습
https://phoenixnap.com/kb/install-hadoop-ubuntu
- 우분투 서버에서 자바가 설치되어 있는지 확인.
java -version apt install openjdk-8-jre-headless로 자바8 설치.- 하둡 클러스터가 동작할 전용 계정 생성.
sudo adduser hdoop su - hdoop으로 계정 로그인.- 하둡에 패스워드 입력 없이 로그인하기 위해, ssh 키 페어.
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsacat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys- key file을 read only로 변경.
chmod 0600 ~/.ssh/authorized_keys ssh localhost를 통해 패스워드 없이 로그인.wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz을 통해 hadoop 설치. (버전은 때마다 다르니 https://downloads.apache.org/hadoop/common/ 에서 확인.)tar xzf hadoop-3.2.1.tar.gz으로 압축 해제.vi .bashrc를 통해 문서의 맨 뒤로 가서,
#Hadoop Related Options
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"내용 추가.
source .bashrc로 배쉬 실행. (에러 발생 시 - https://sparkbyexamples.com/hadoop/hadoop-unable-to-load-native-hadoop-library-for-your-platform-warning/ 참고)vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh에서 export JAVA_HOME의 커멘트 아웃을 하고, 자바 홈 경로 설정.export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64vi $HADOOP_HOME/etc/hadoop/core-site.xml에서 내임 노드 관련 정보 설정. configuration 태그 사이에 내용 추가.
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdoop/tmpdata</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>vi nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml에도 HFDS와 관련된 데이터 블럭 정보를 설정.
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>vi $HADOOP_HOME/etc/hadoop/mapred-site.xml에서 맵리듀스와 관련된 정보 설정. YARN 위에서 돌아가도록 설정.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>vi $HADOOP_HOME/etc/hadoop/yarn-site.xml에서 노드 매니저와 리소스 매니저 관련 설정.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>hdfs namenode -format으로 포맷.cd hadoop-3.3.6/sbin/으로 관계된 스크립트 디렉토리로 이동../start-dfs.sh을 통해 hdfs와 관련된 네임 노드와 데이터 노드 데몬 실행../start-yarn.sh으로 YARN 실행 (리소스 매니저와 노드 매니저 실행).jps라고 하면 커맨드가 없다고 나옴.exit으로 우분투(root)로 이동.sudo apt install openjdk-8-jdk-headless로 jdk 설치.su - hdoop및jps실행.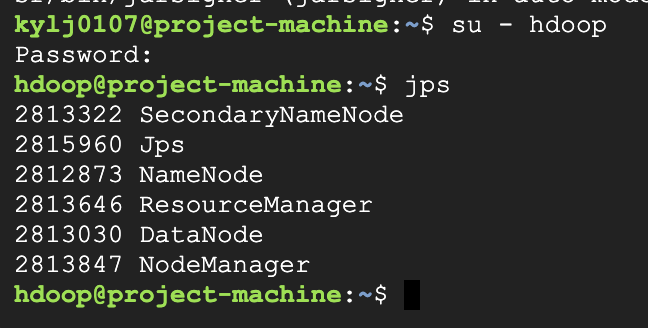
하둡 웹 UI - HDFS.
- name node : port:9870.
- data node : port:9864.
WordCount 프로그램 실습
bin/hdfs dfs -mkdir /user,bin/hdfs dfs -mkdir /user/hdoop,bin/hdfs dfs -mkdir input으로 input dir 생성.bin/hdfs dfs -ls로 생성되었는지 확인.vi words.txt로 입력이 될 랜덤한 단어들 입력 및 저장.the brave yellow lion the lion ate the cow now the lion is happybin/hdfs dfs -put words.txt input로 입력 파일을 input dir로 저장.bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount input output로 WordCount 실행. input과 output은 hdfs의 홈 디렉토리를 기준으로 함.bin/hdfs dfs -ls output로 결과 확인.bin/hdfs dfs -cat output/part-r-00000로 결과 확인.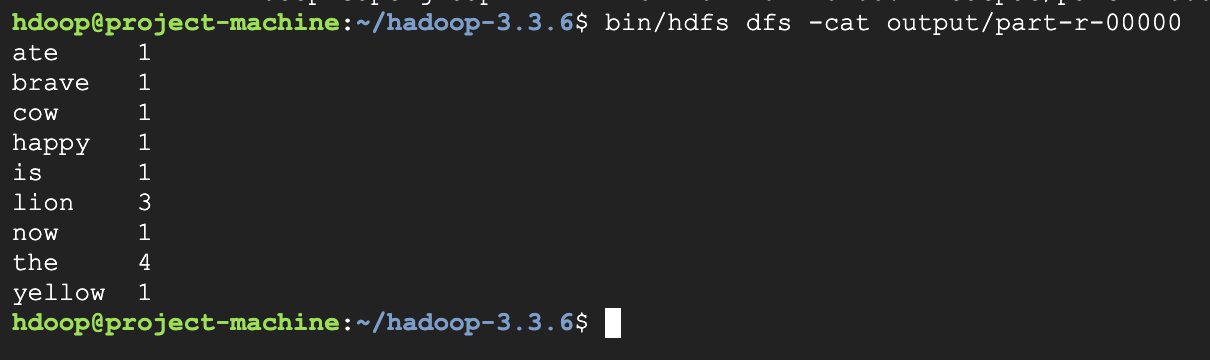
MapReduce의 문제점.
- 데이터 모델과 오퍼레이션에 제약이 많아 생산성이 떨어짐.
- 모든 입출력이 디스크를 통해 이뤄짐. 큰 데이터 배치 프로세싱에 적합함.
- 셔플링 이후 Data Skew가 발생하기 쉬움. Reduce 테스크 수를 개발자가 지정해야 함.
6. Spark
Spark의 등장.
- 아파치 오픈소스 프로젝트로 2013년에 시작됨.
- 하둡의 뒤를 잇는 2세대 빅데이터 기술.
- YARN, Kubernetes 등의 다양한 분산환경 적용 가능.
- Scala로 만들어 짐.
- 빅데이터 처리 관련 다양한 기능 제공.
Spark 3.0의 구성.
- Spark Core
- Spark SQL
- Spark ML
Spark vs. MapReduce.
- Spark은 기본적으로 메모리 기반. 디스크 기반인 맵리듀스보다 따라서 속도가 더 빠름.
- 맵리듀스는 하둡(YARN) 위에서만 동작. Spark은 하둡 외에도 K8s 등 다양한 분산 컴퓨팅 환경 지원.
- 맵리듀스는 키, 밸류 기반의 데이터만 지원. 스팤은 판다스 데이터프레임과 같은 데이터 구조 지원.
- 스팤은 다양한 방식의 컴퓨팅 지원. 배치, 스트림 데이터 처리, SQL, ML, Graph 분석 등.
Spark 프로그래밍 API.
1. RDD: 로우 레벨 프로그래밍 API로 세밀한 제어 가능. 하지만 코딩 복잡도가 높아 거의 사용 X.
2. DataFrame: 판다스의 데이터프레임과 거의 동일. 하이 레벨 프로그래밍이 가능. Python.
3. Dataset: 판다스의 데이터프레임과 거의 동일. 하이 레벨 프로그래밍이 가능. Scala, Java.
- DataFrame/Dataset이 꼭 필요한 경우 : ML 피쳐 엔지니어링 혹은 Spark ML을 쓰는 경우, SQL 만으로는 할 수 없을 경우.
Spark SQL.
- 구조화된 데이터를 처리하는 방법.
- 데이터 프레임을 SQL로 처리 가능. 데이터프레임을 테이블처럼 sql로 처리 가능.
Spark ML.
- ML 관련 알고리즘 지원.
- Classification, Regression, Clustering, ...
- RDD 기반의 MLlib와 DataFrame기반의 ML 존재.
Spark ML의 장점.
- 원스톱 ML 프레임워크. 전처리, 모델 빌딩 자동화, 모델 서빙 등 모든 과정을 작업 가능.
- 대용량 데이터도 처리 가능.
Spark 데이터 시스템 사용 예.
- 대용량 데이터 배치 처리, 스트림 처리, 모델 빌딩.
- 대용량 비구조화된 데이터 처리. (ETL, ELT)
- ML 모델의 대용량 피쳐 처리. (배치/스트림)
- Spark ML을 이용한 대용량 훈련 데이터 모델 학습.
Spark 실행 환경.
- 개발/테스트/학습 환경
- 노트북(주피터)
- Spark Shell
- 프로덕션 환경
- spark-submit(가장 많이 사용)
- 데이터브릭스 노트북
- REST API
Spark 프로그램 구조.
- Driver: 실행하는 코드의 마스터 역할 수행. (YARN의 App Master)
- Executor: 실제 테스크를 실행하는 역할 수행. (YARN의 컨테이너)
Driver.
- 실행하는 코드의 총 지휘하는 마스터 역할.
- 실행 모드(클라이언트(YARN 클러스터 외부에서 실행), 클러스터(YARN 클러스터 내부에서 실행))에 따라 실행되는 곳이 다름.
- 코드에 필요한 리소스 지정 관련 다양한 config. 지정 가능.
--num-executor, --executor-cores, --executor-memory- 보통 SparkContext를 만들어 Spark cluster와 통신 수행.
- Cluster Manager (YARN의 리소스 매니저)
- Executor (YARN의 컨테이너)
- 사용자 코드를 실제 Spark task로 변환하여 Spark cluster에서 실행.
Executor.
- 실제 테스크를 실행해 주는 역할 수행(JVM): Transformations, Actions.
- YARN의 컨테이너.
Spark 클러스터 매니저 옵션
- local[n] : n개의 cpu 사용.
- YARN
- K8s
- Mesos
- Standalone
local[n].
- 개발/테스트용.
- Spark shell or IDE or 노트북에서 실행.
- n은 코어의 수: executor의 수가 됨.
- local[*]: 컴퓨터의 모든 코어 사용.
YARN.
- 두 개의 실행 모드가 존재: Client vs. Cluster.
- Client mode: Driver가 Spark 클러스터 밖에서 동작.
- 개발/테스트 등을 할 때 사용.- Cluster mode: Driver가 Spark 클러스터 안에서 동작.
- 하나의 executor 사용.
- 실제 프로덕션에서 사용.
"클러스터 매니저 | 실행 모드 | 프로그램 실행 방식" 으로 구분하여 실행 모델 요약 가능.
