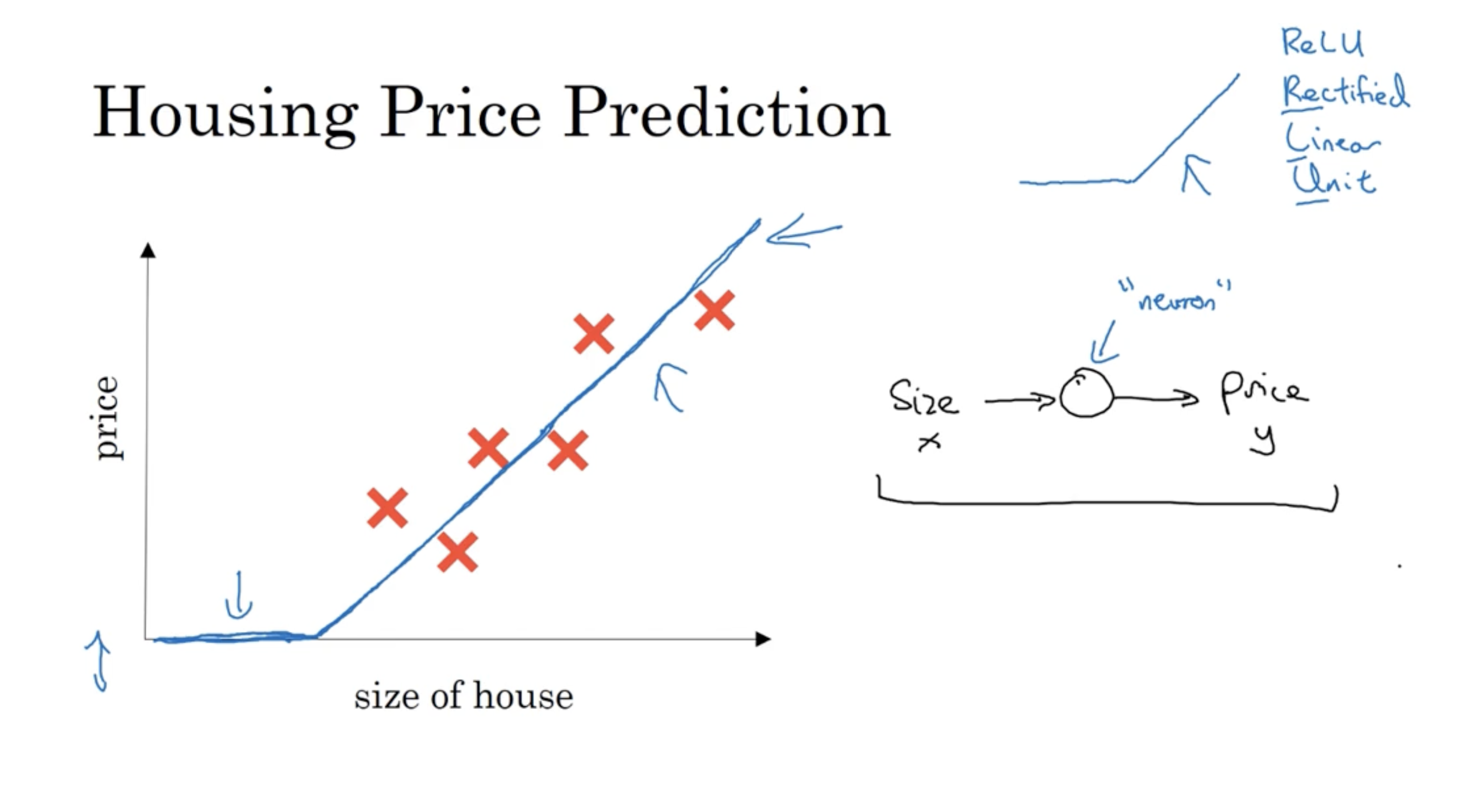
딥러닝을 배우기 전에 neural networks에 대해서 알아본다. 아래와 같이 (집 크기, 가격) 데이터를 가지고 집 크기에 따른 가격을 예측하는 뉴럴넷을 만들어보자. 이 경우 그래프에 있는 함수처럼 예측 함수가 만들어질 것이다. (이러한 모양의 함수를 ReLU 함수라고 한다.)
우측 그림과 같이 size -> (neuron) -> price 의 구조를 띤다.
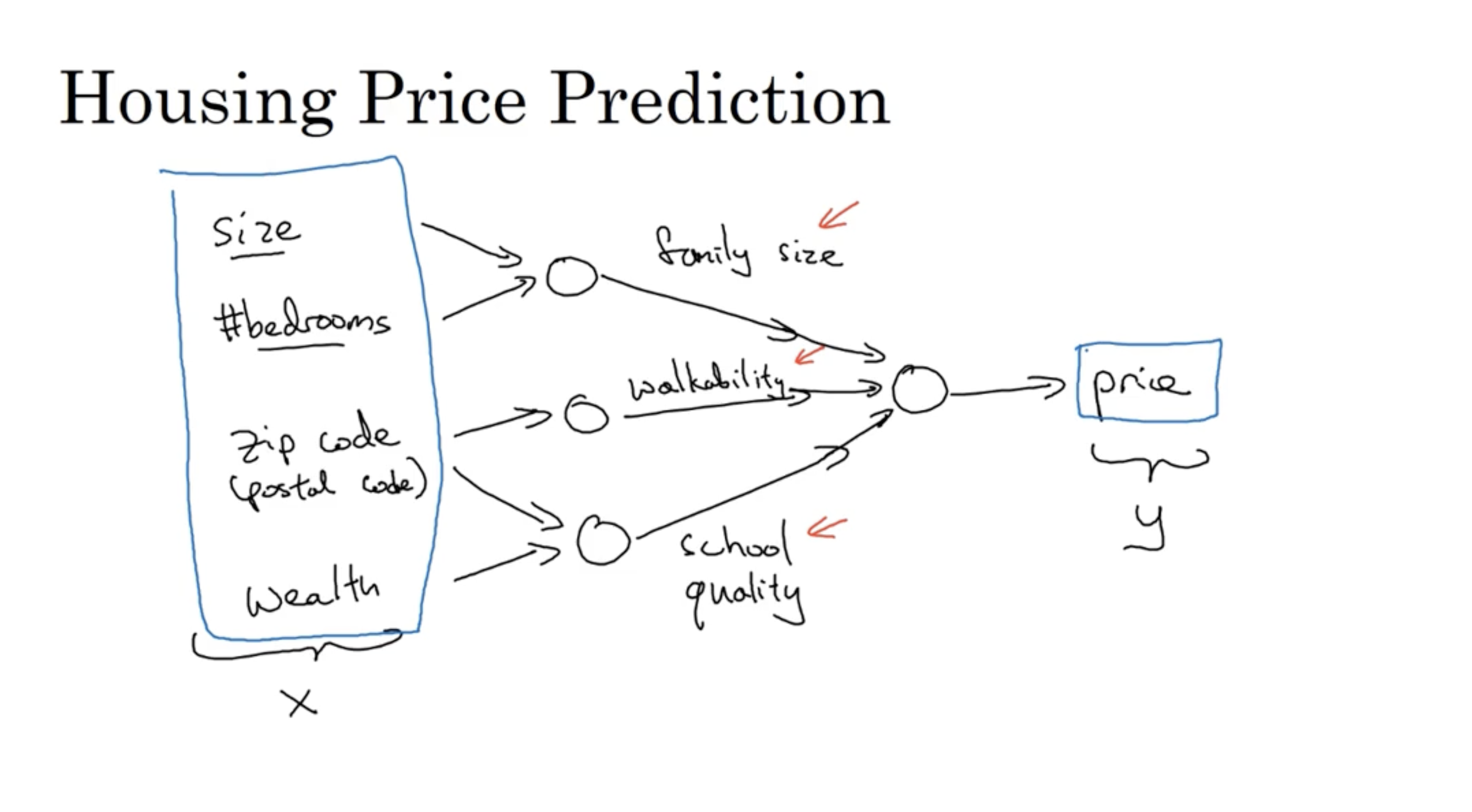
뉴럴넷의 구조를 더 구체적으로 살펴보면 다음과 같다. (size, #bedrooms, zip code, wealth)의 features를 갖는 데이터 를 입력으로 넣으면 이 feature들은 뉴런을 거쳐 최종 output인 price를 출력한다. (그리고 그림과 같이 (size, #bedrooms)->familiy size를 의미하고, (zip code)는 walkability를 의미하는 등 해당 값들을 이용하여 최종 결과 price를 예측할 수 있을 것이다.)
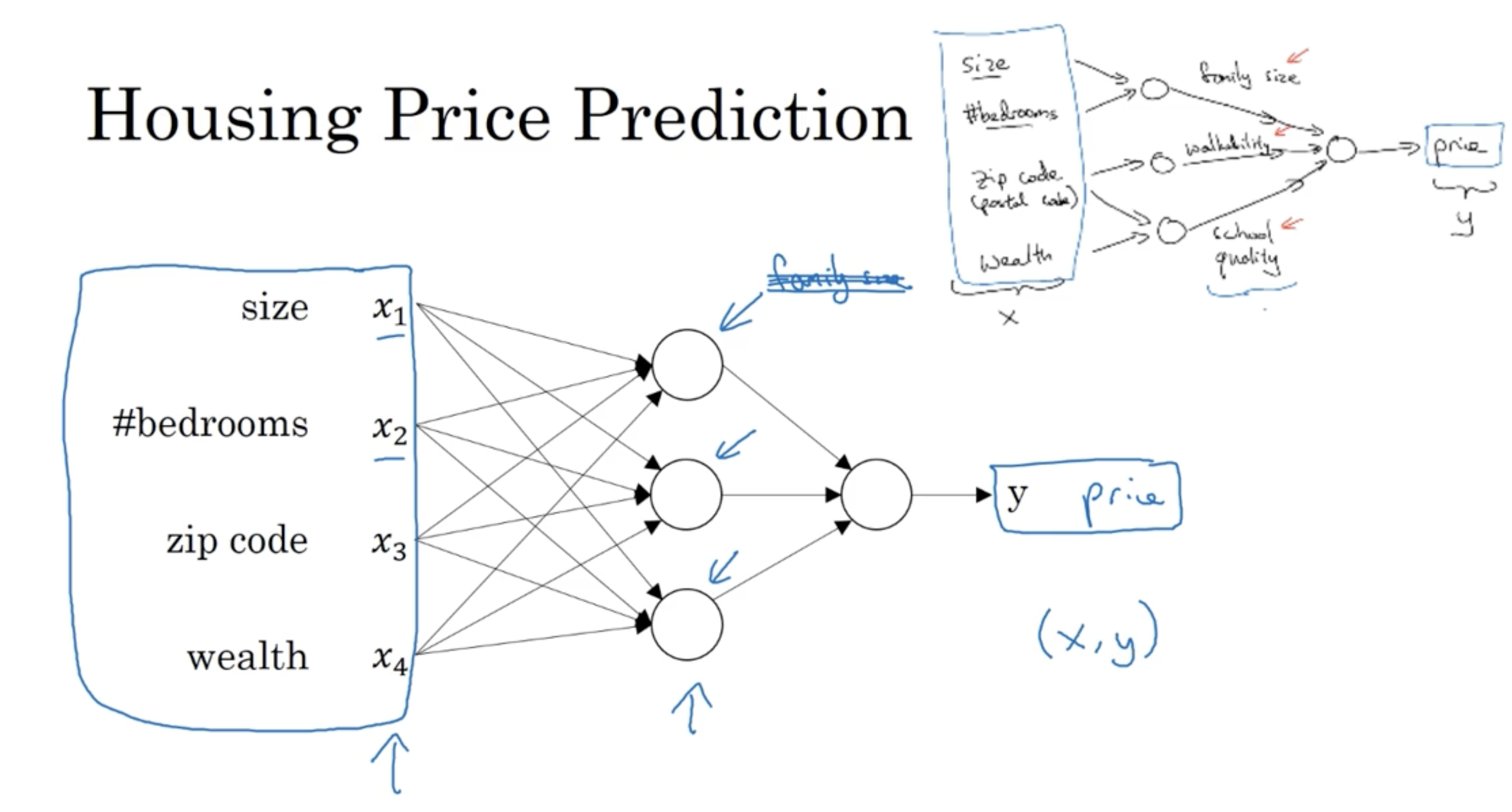
다만 실제 neural networks의 hidden unit들은 특정한 feature들의 조합만 가져오지는 않고, 전체 feature들을 다 고려하며, 이를 통해 hidden unit 값을 구한다.
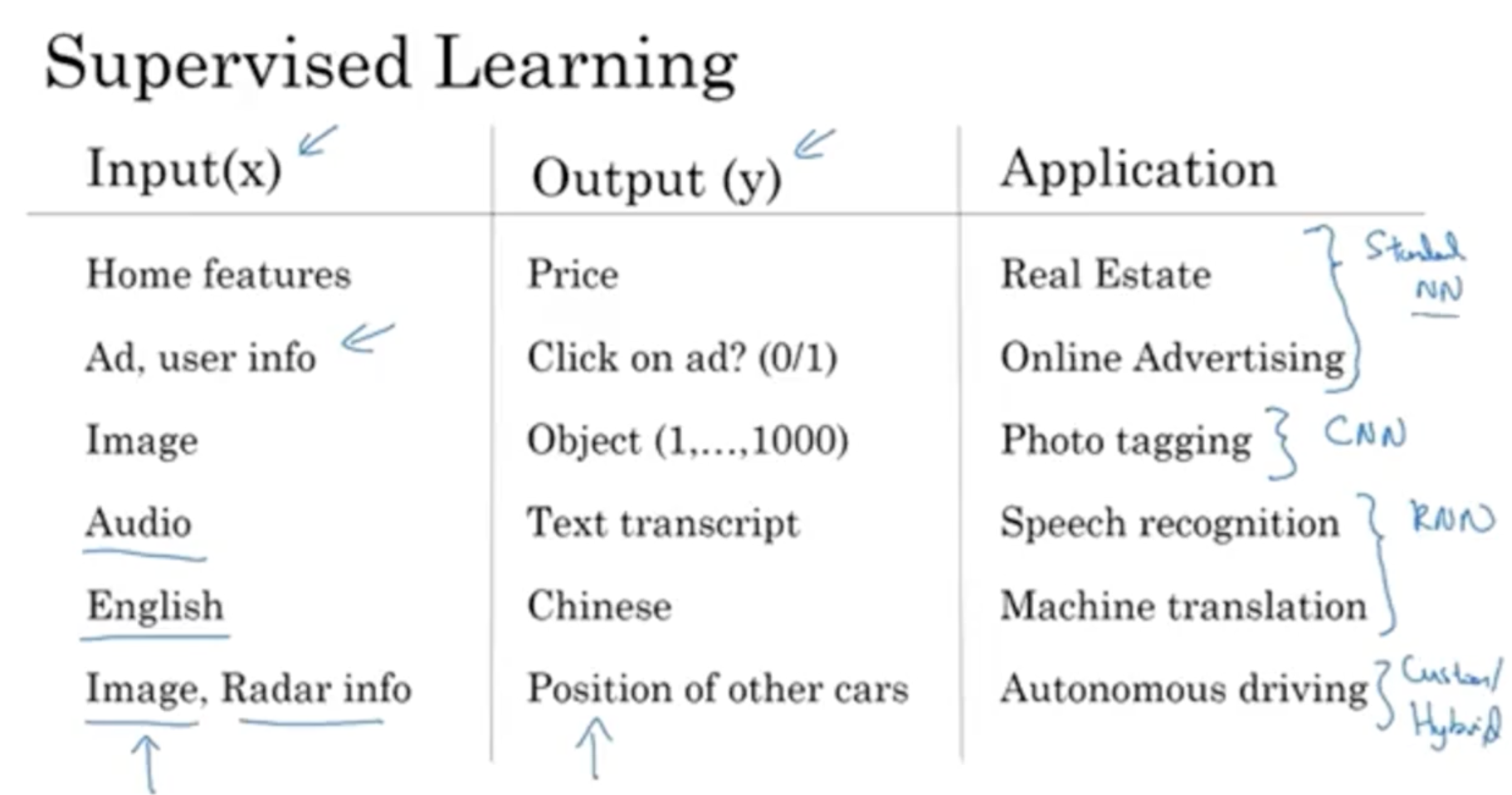
Supervised learning은 입력 데이터와 출력 데이터가 주어진 상태에서 학습하는 것을 의미하며, 예시는 아래와 같다.
- home features (input ) -> price (output )
- 그리고 다음과 같은 다양한 응용 사례가 존재한다.
- 부동산 가격, 온라인 광고, 사진 태깅, 음성 인식, 번역, 자율주행
- 그리고 다음과 같이 neuranl net을 분류할 수 있다.
- Standard NN : 보편적인 뉴럴넷 (ex. 부동산 예측, 광고 효과 예측)
- CNN : 이미지 관련 뉴럴넷 (ex. 사진 분류)
- RNN : 1-D 데이터 관련 뉴럴넷 (ex. 음성 데이터 -> 텍스트 추출, 언어 번역)
- Hybrid : 여러 기법이 섞인 뉴럴넷 (ex. 레이다 정보 -> 이미지 -> 차량 위치 분석)
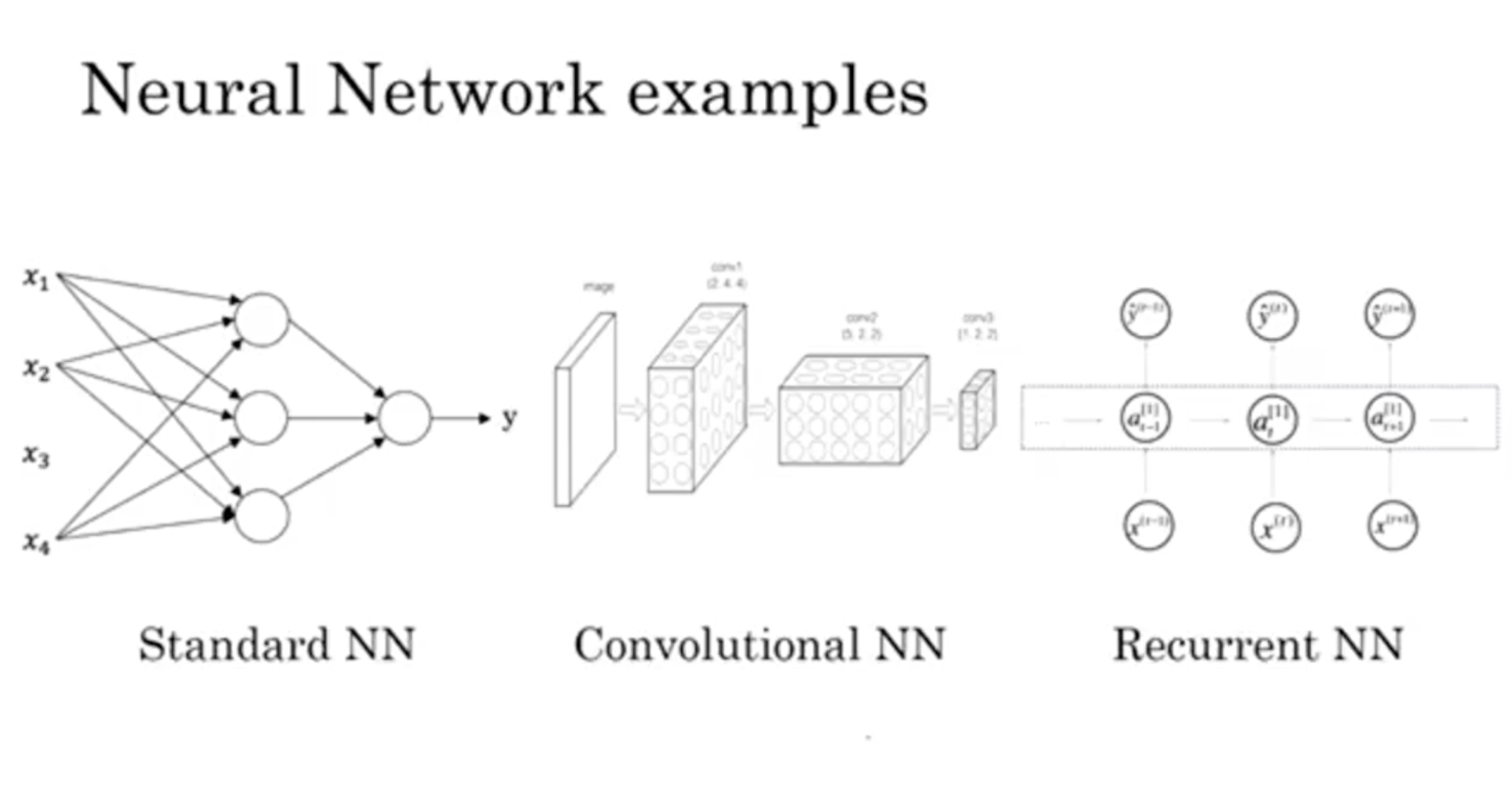
그리고 각 Neural Networks의 구조를 간단히 살펴보면 아래와 같다.
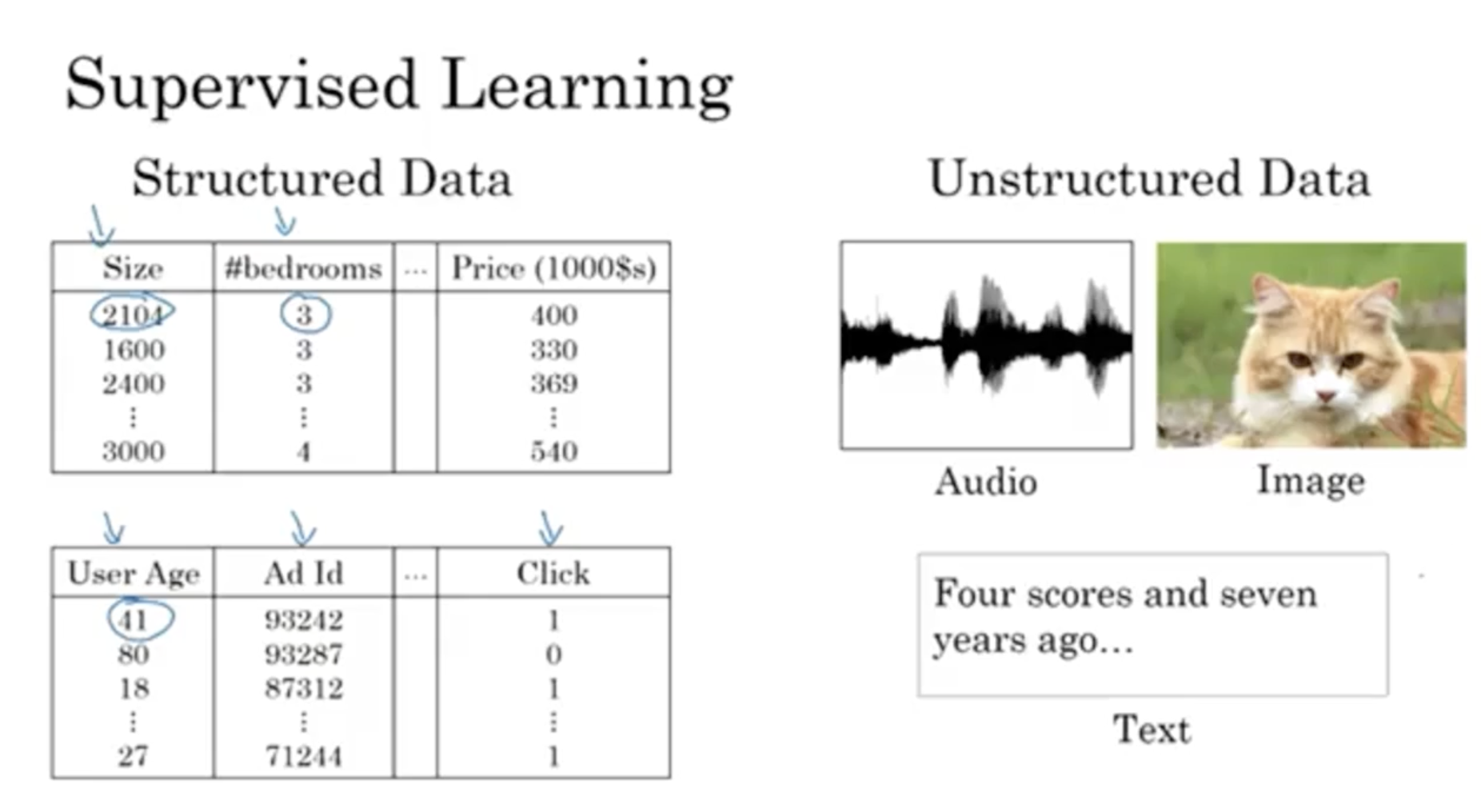
그리고 Supervised learning에서는 데이터의 종류가 크게 두 종류로 구분이 된다.
- Structured Data
- 일반적으로 생각하는 데이터베이스 스키마와 같다.
- Unstructured Data
- 오디오, 이미지, 텍스트 등이 해당한다.
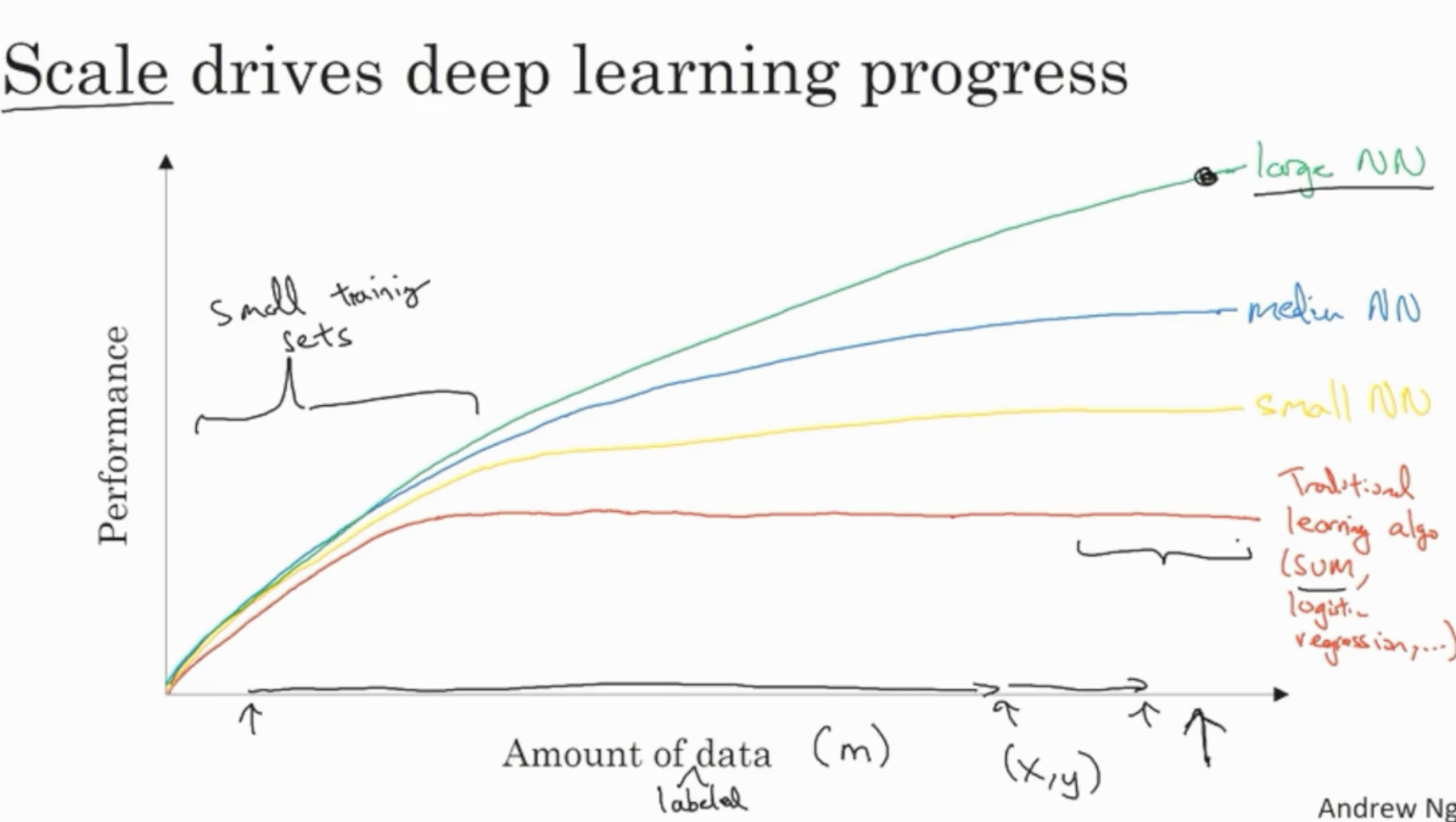
그렇다면 왜 딥러닝이 급부상하게 되었을까? 아래 그림을 보자.
- 과거와 달리 데이터가 커지면서 (=데이터셋의 크기 이 커지면서) Large Neural Network는 일반적인 ML Alg.(ex. SVM, Logistic regression)의 성능을 크게 능가하는 모습을 보여 준다.
(이때 사용되는 데이터는 labeled 데이터를 의미한다.)
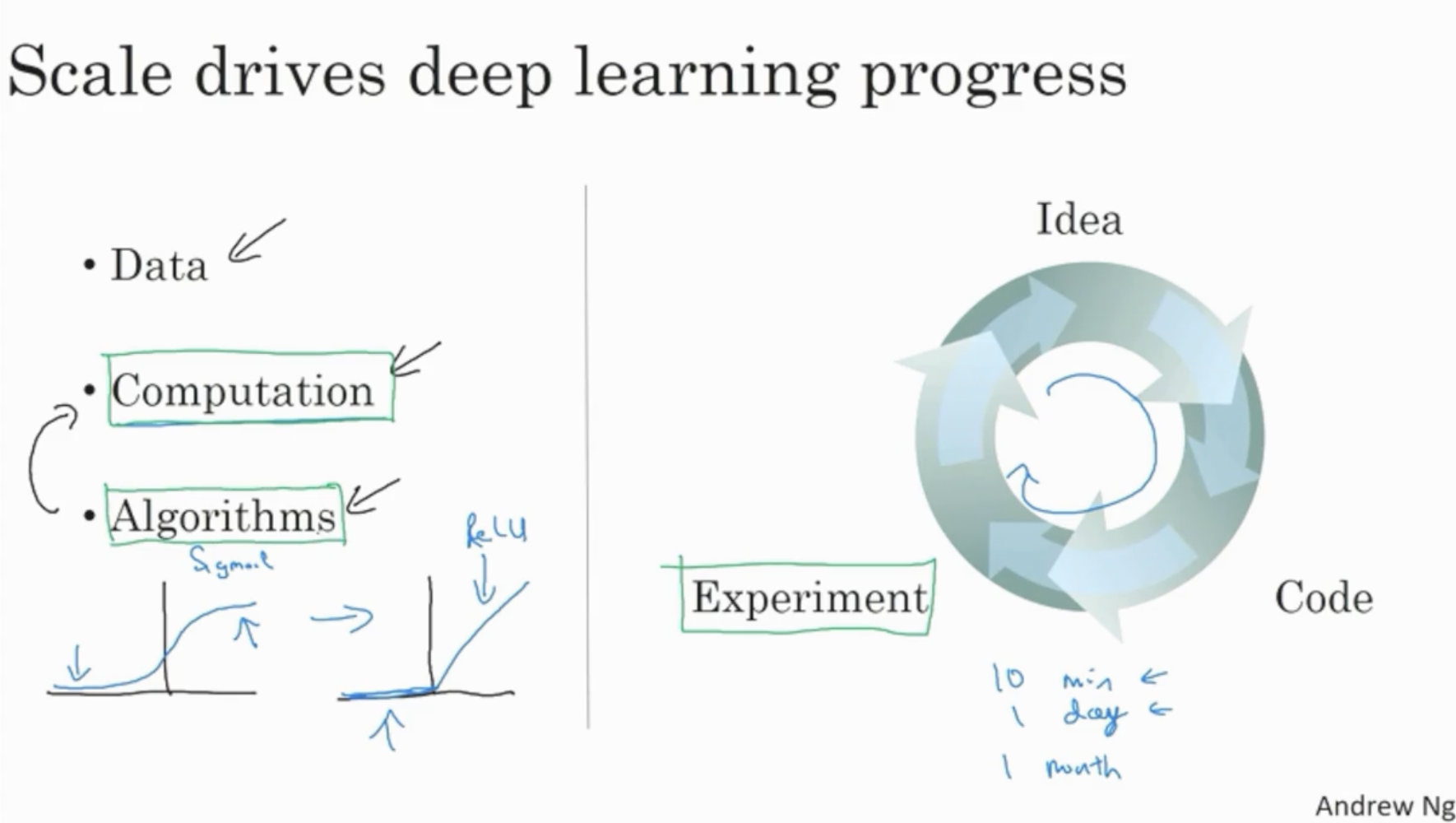
또한, 과거와 달리 데이터가 쌓이고 새로운 알고리즘 등이 개발되며, 연산 속도가 빠르게 향상되는 과정에서 딥러닝의 발전 속도에 가속도가 붙었다.
- 예를 들어, 과거에는 activation function으로 sigmoid function을 적용하여 gradient descent 속도가 매우 느리다는 단점이 존재했다. (왜냐하면 sigmoid는 [0, 1]의 범위를 갖기 때문에 값이 커질 경우엔 큰 의미가 없다.)
- 하지만 현재 activation function으로 ReLU function을 적용함으로써, gradient descent 속도를 빠르게 향상시켰으며, 이로 인해 (학습)연산 속도가 크게 향상되었다. (ReLu는 0 이하의 값은 0으로, 그 이상의 값은 값을 갖는다. 따라서 값의 범위에 제약이 없다.)