이번에는 Transformer model 에 대해서 알아보자.
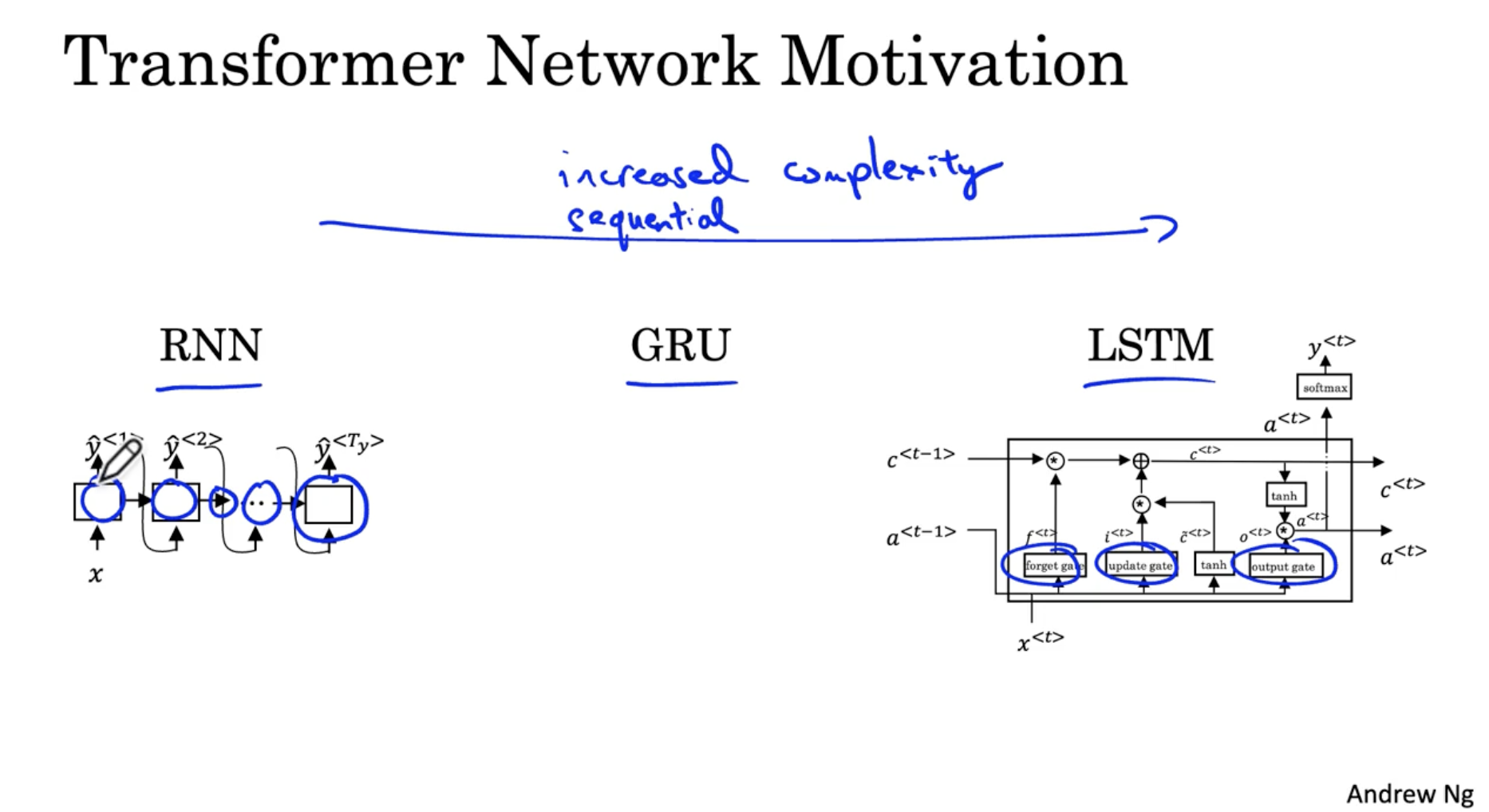
- Transformer Network 는 다음과 같은 동기로 발전하였다.
- 기존의 RNN -> GRU -> LSTM 모델은 Vanishing gradient 문제를 해결하기 위해서, 모델이 점점 복잡해지는 단점이 존재한다.
- 이에 따라 마지막 activation 을 계산하기 위해서는 이전의 시퀀스 데이터들의 activation 이 먼저 처리될 때까지 기다려야 한다. 이러한 bottleneck ( 병목현상 ) 을 줄이기 위해서 병렬 처리를 할 수 있는 Transformer Network 가 발전하게 되었다.
Transformer Network 의 개략적인 설명은 아래와 같다.
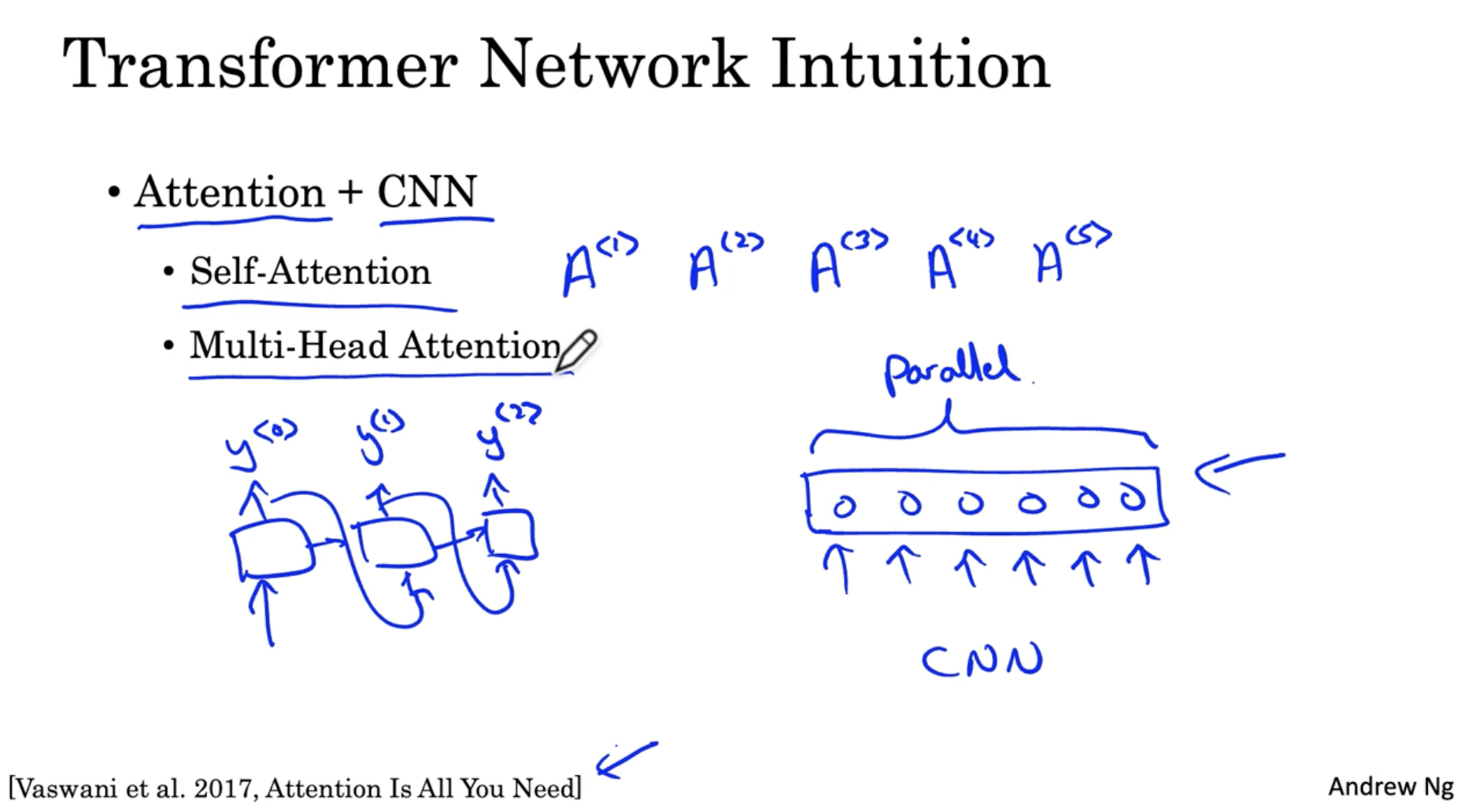
- Attention + CNN 이다.
- RNN 기반 Attention 모델에 병렬 처리 기반의 CNN 모델을 합치는 방법이다.
- Self-Attention 은 입력 시퀀스 (예: 크기가 5인 시퀀스) 를 병렬 처리하여 attention 을 구한다.
- Multi-Head Attention 은 Self-Attention loop 를 의미한다.
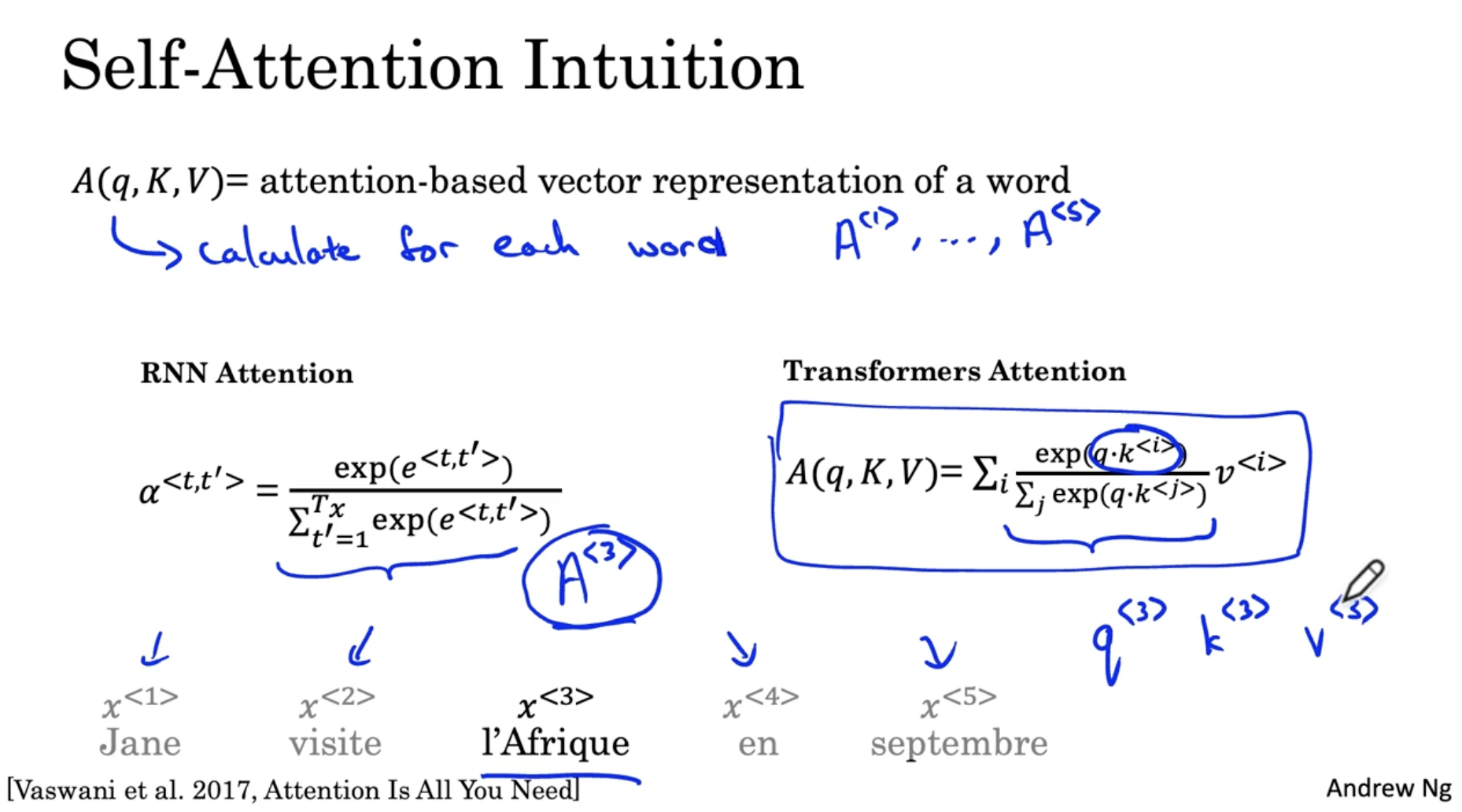
먼저 Self-Attention 메커니즘을 알아보자.
- 이전의 Attention 대신, 를 사용한다.
- 는 아래 예시에서 입력 시퀀스의 각 단어 를 병렬로 처리하여 벡터 형태로 표현된다.
- 의 의미는 다음과 같다. 예를 들어 I'Afrique 이라는 단어에서 해당 단어의 word embedding 값을 본다. 그리고 이는 문맥에 따라 휴양지를 의미할 수도 있고, 큰 대륙을 의미할 수도 있고, 역사적 장소일 수도 있다. 따라서 문맥에 따라 I'Afrique 이라는 단어를 어떻게 해석할지를 결정하는 게 이다.
- 그리고 의 방정식은 다음과 같다.
- q : 해당 단어의 query, k : 해당 단어의 key, v : 해당 단어의 value
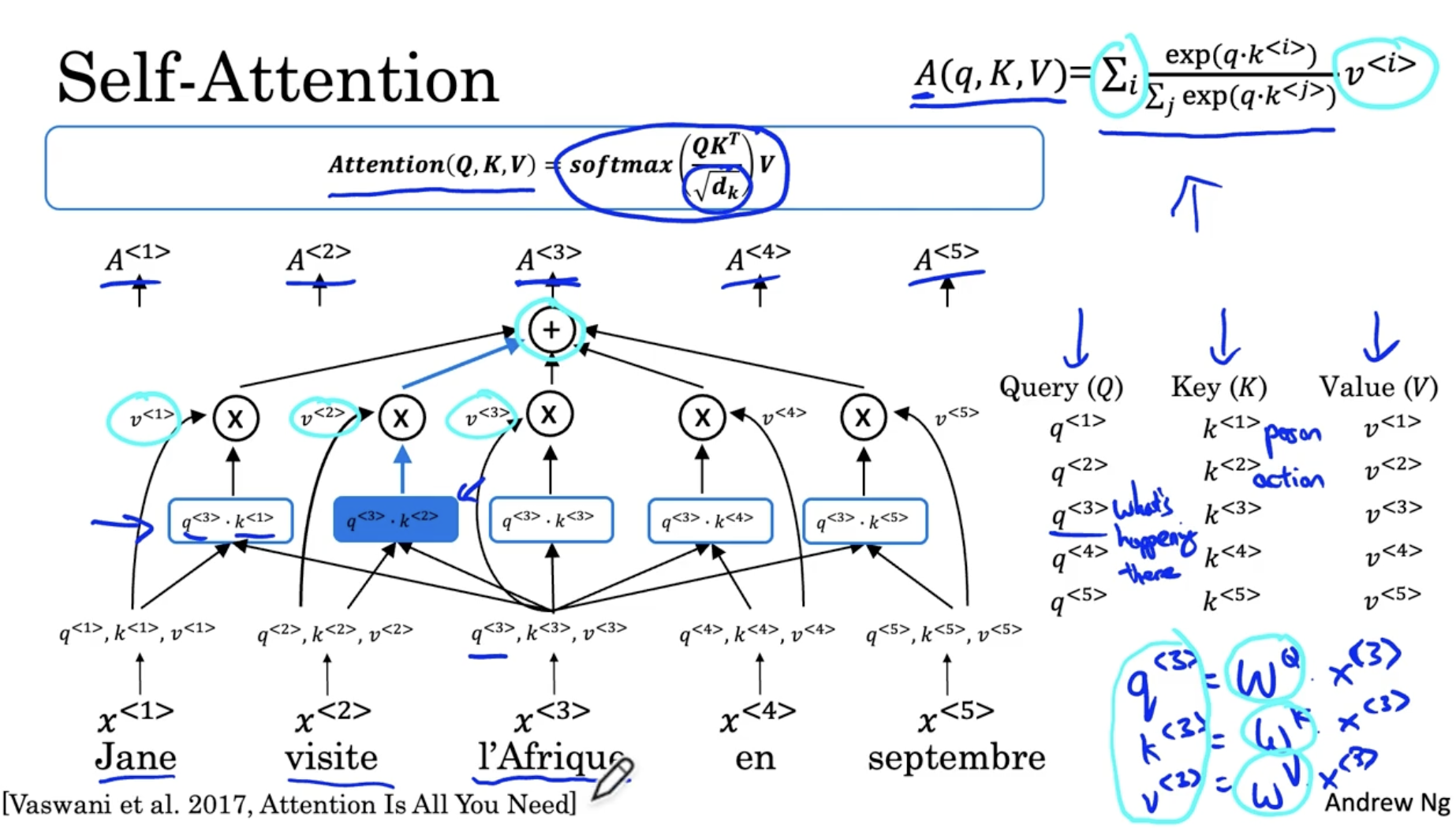
Self-Attention 의 메커니즘을 다음과 같다.
- I'Afrique 를 예시로 든다.
- 은 I'Afrique 의 word embedding vector 라고 하자.
- 그리고 I'Afrique 에 대해서 다음과 같은 query 를 한다. "what happening there"
- 그리고 이 쿼리 에 대해서 모든 단어들 과의 유사성을 dot product 로 계산한 후 softmax 함수를 적용한다. 이 경우 vistite 라는 단어가 해당 쿼리와의 유사성이 가장 높은 단어로 적용될 것이다.
- 그러고 나서 모든 단어에서 적용한 쿼리 에 대한 dot product 값의 softmax에 해당 단어의 value 를 곱한다.
- 그리고 위 값들을 모두 더하면 을 구하게 된다.
- 그리고 이 과정을 모든 단어에 대해서 병렬로 처리하는 형태로 표현하면 다음과 같다.
( 는 내적의 크기를 조정하여 exploding 을 방지하는 값이다. like hyper-parameter?)- 그리고 Self-Attention 모델이 강력한 이유는 q, k, v 의 값들을 학습할 수 있어서 이를 통해 단어의 word embedding vector 값이 고정되어 있지 않다는 점이다. 예를 들어, 모델을 학습하면서 I'Afrique 가 방문지 라는 것을 점점 깨닫게 해준다.
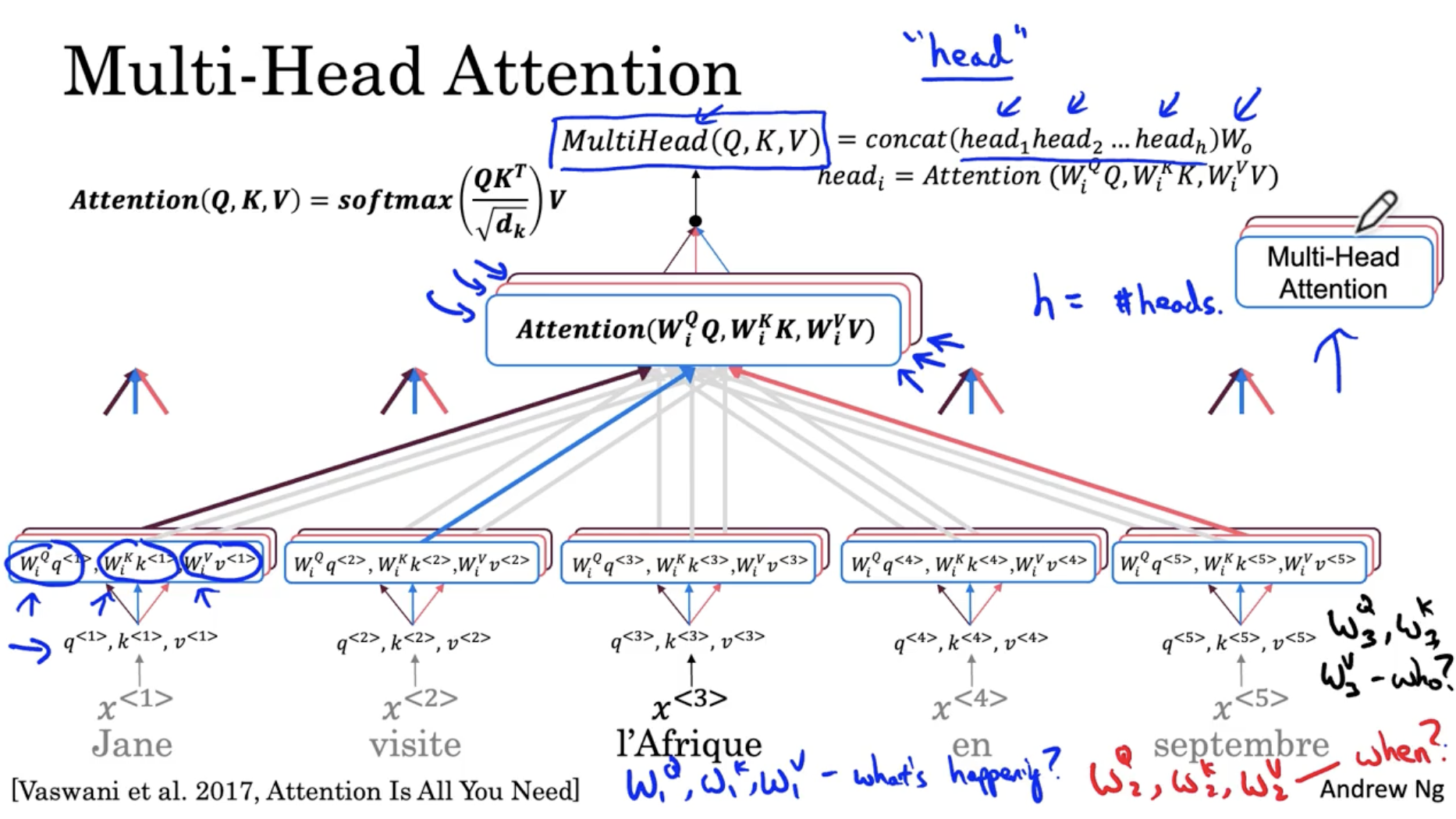
다음은 multi-head attention 에 대한 내용이다.
- 이전에 본 1개의 attetion head 를 multi 로, 즉 병렬로 처리한다는 의미이다.
- 예를 들어, 이전 attetion 이 " what's happening? " () 쿼리에 대한 attention head 였다면, 다른 attention head 는 " when? " () , " who? " () 에 대한 attention head 이다.
- 이와 같은 attetion head 들이 총 8개로 구성되어 있으며, 이 각각의 쿼리에 대한 연산은 서로 영향을 받지 않기 때문에 개별적으로 병렬로 처리할 수가 있다.
- 그리고 의 파라미터 는 같은 attetion head 에서는 동일하게 적용된다.
- 그리하여 모든 attetion head 를 구한 후, concatenate 하여 를 구한다.
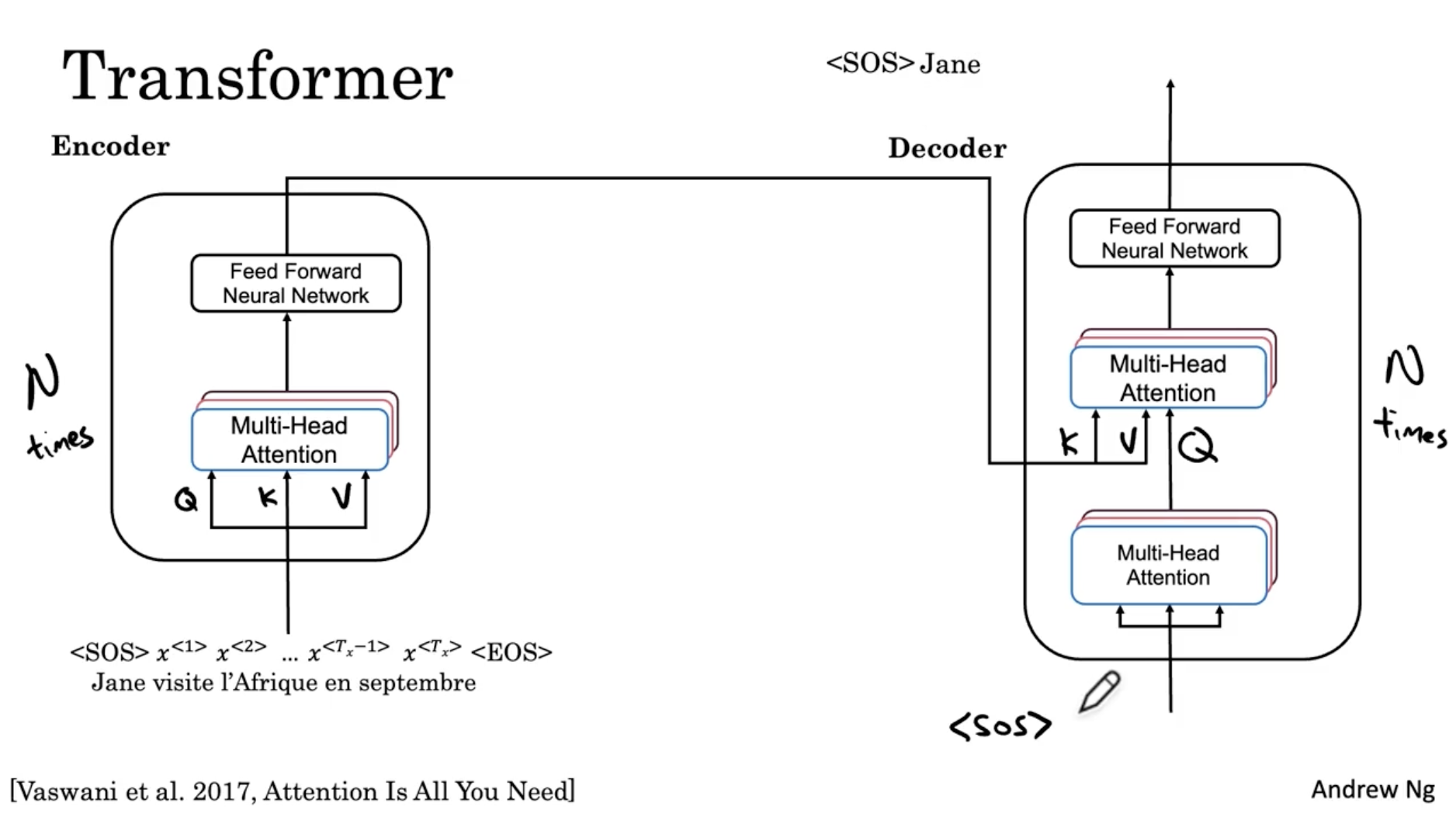
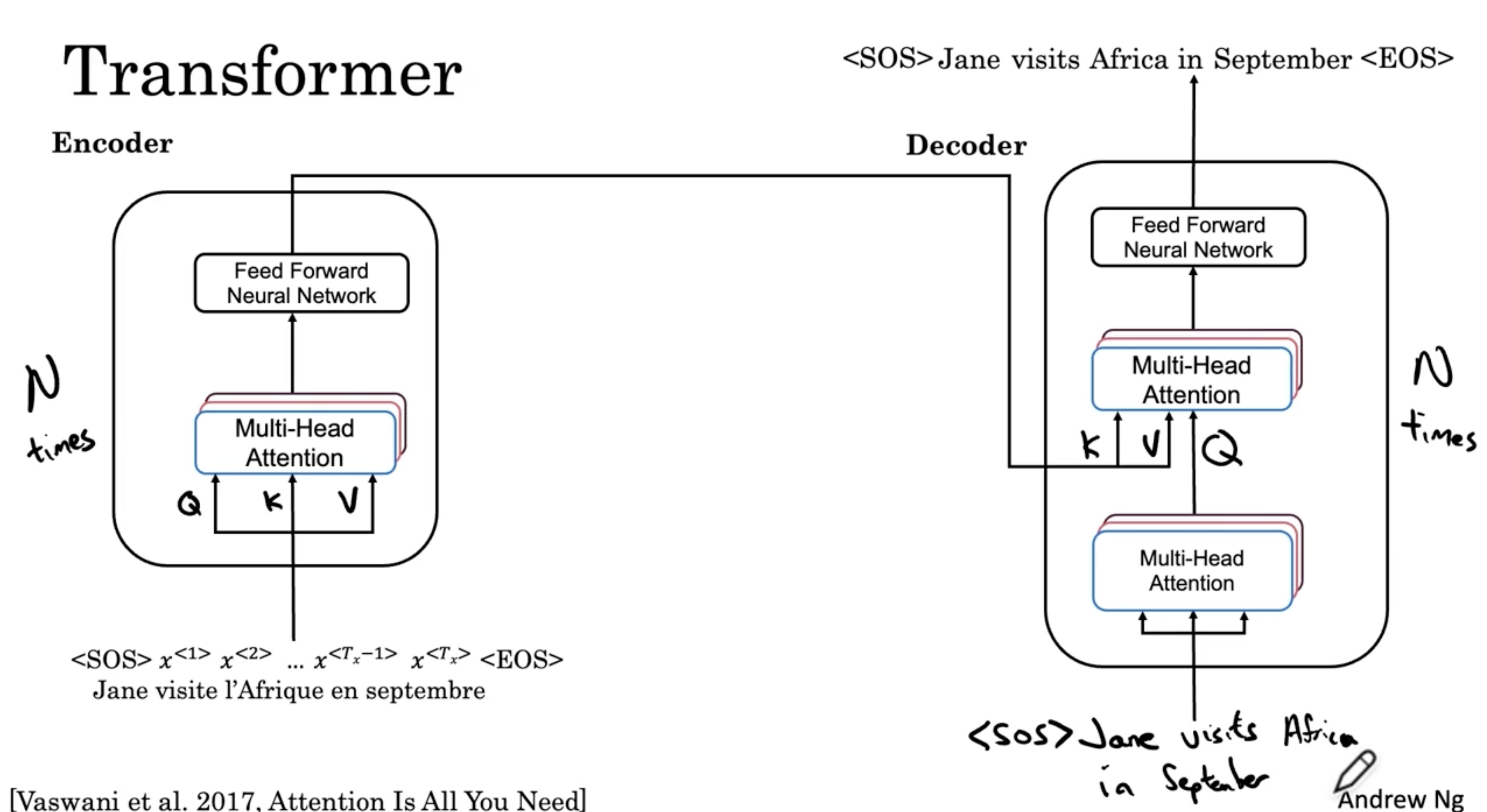
다음은 Transformer 모델에 대한 내용이다.
- 아래와 같이 인코더 - 디코더 모델의 구조를 이루며, 그 안에 위에서 배운 multi-head attention 블록과 feed forward NN (forward + backward) 블록으로 구성되어 있다.
- 그리고 인코더의 K, V 를 디코더의 2번째 multi-head attention 블록으로 준다.
- 그리고 디코더에서는 예를 들어 다음과 "<SOS>" 라는 토큰이 주어질 때? 라는 query 를 주고, 이 쿼리로 인코더의 K, V에 적용하여 FNN 을 거쳐 Jane 이라는 출력을 한다.
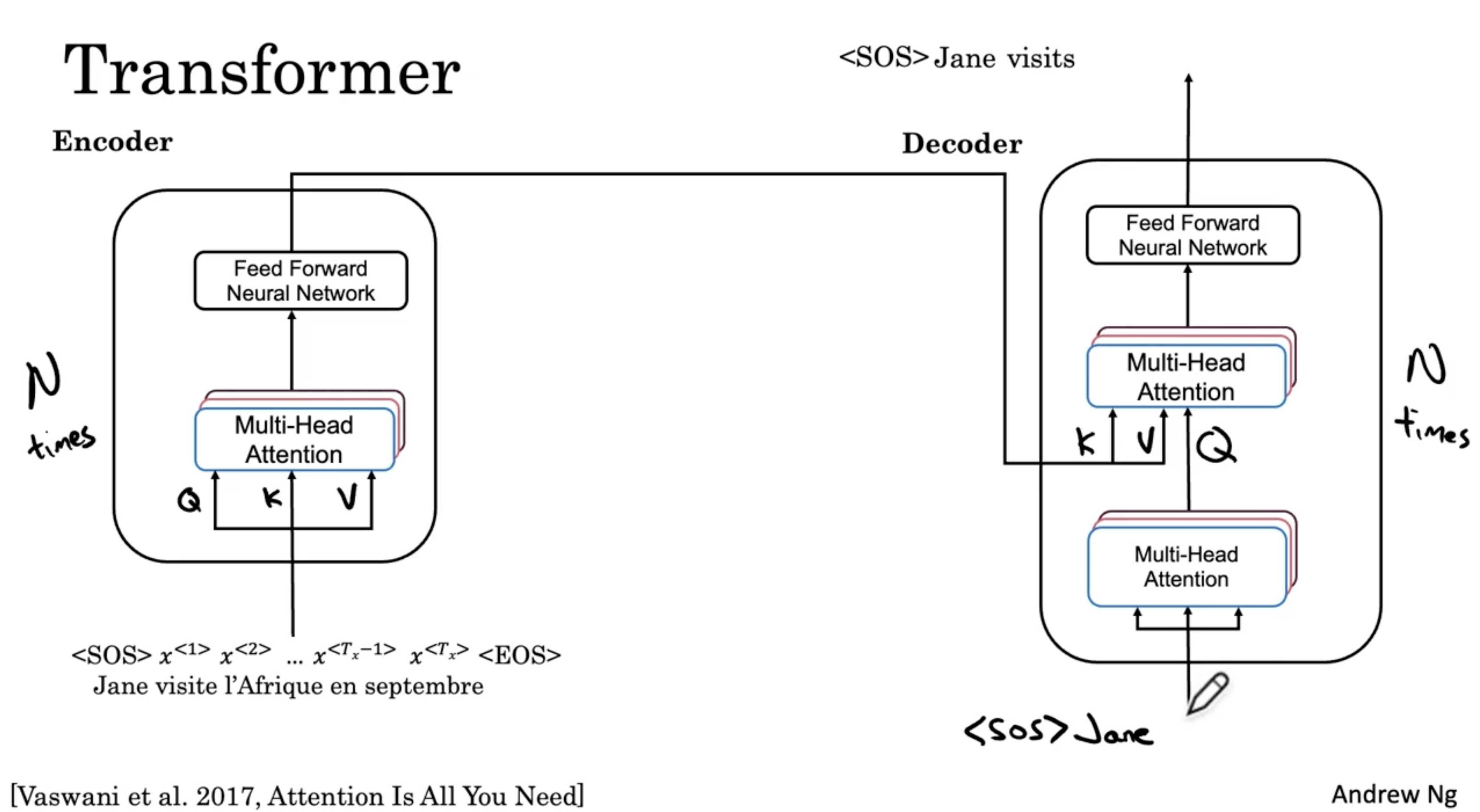
- 다음으로 앞서 출력된 <SOS> Jane 입력값을 주고, <SOS> Jane visits 를 출력한다.
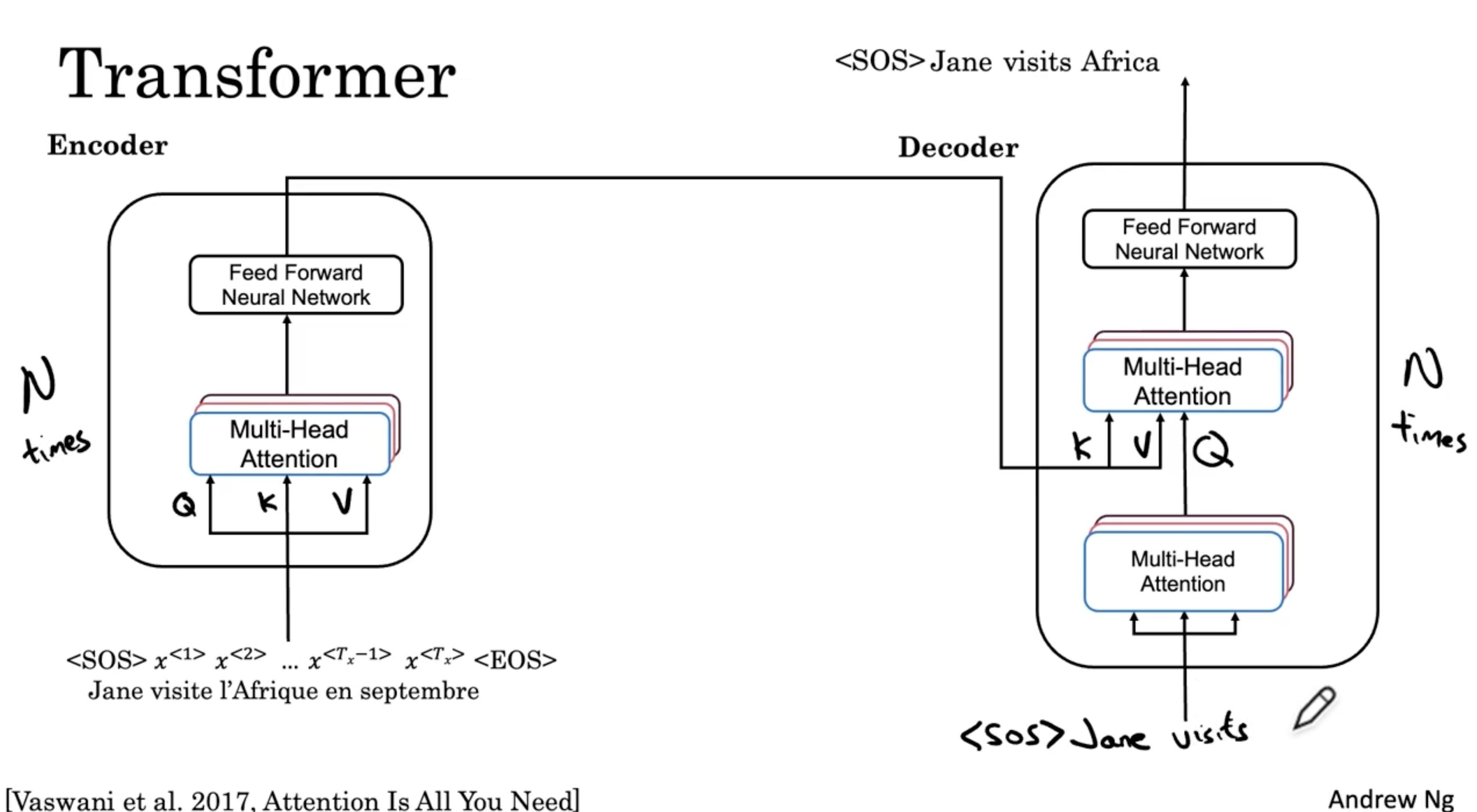
- 다음은 <SOS> Jane visits 를 입력하여, <SOS> Jane visits Africa 를 출력한다.
- 이런 식으로 다음과 같이 전체 문장이 완성될 때까지 N번 반복할 것이다. (이 경우 N=6)
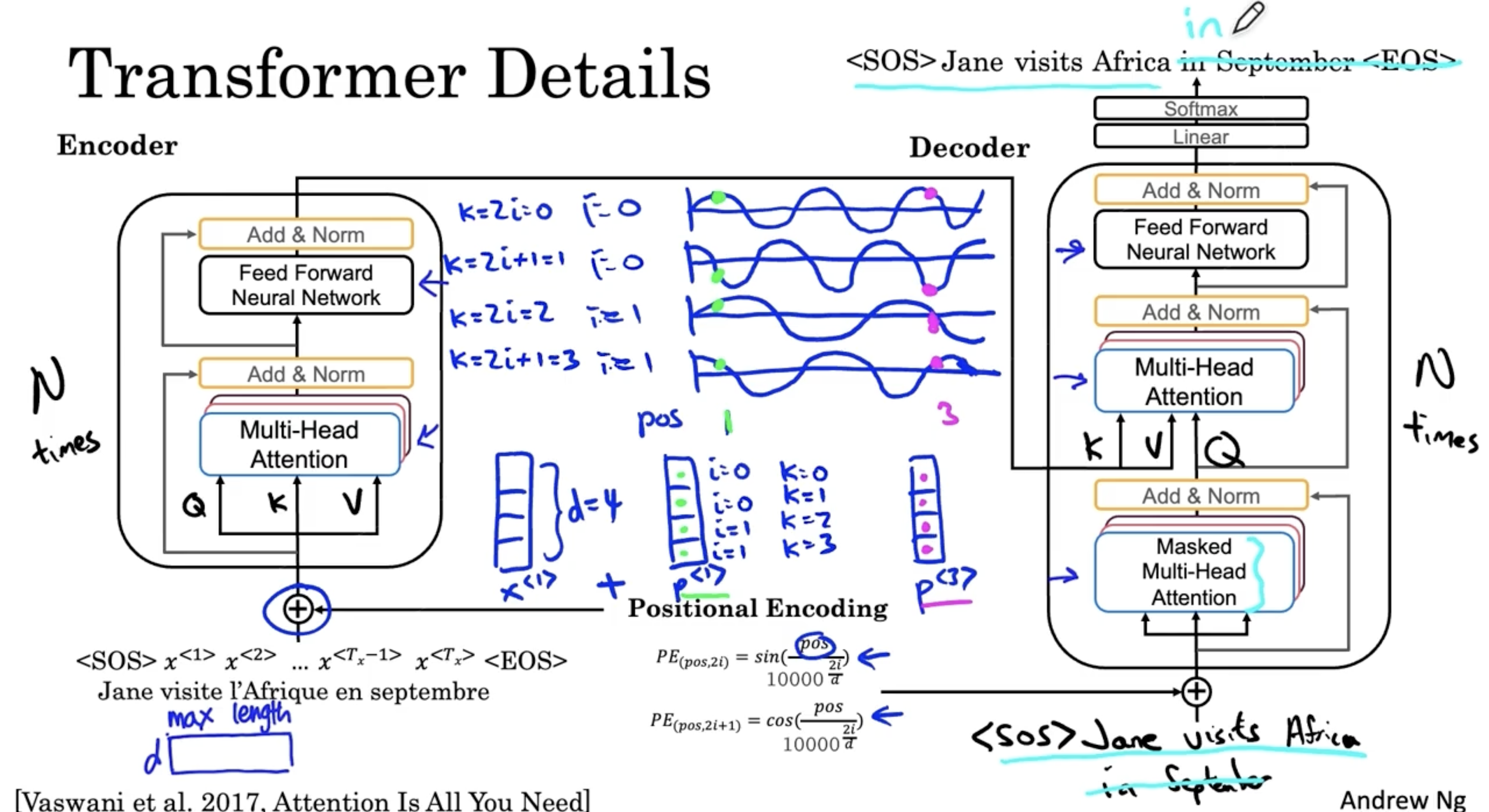
다음은 Transformer 모델의 디테일한 부분을 다룬 내용인데, 솔직하게 무슨 내용인지 잘 이해가 가지 않았다. 이해한 내용만 적자면 다음과 같다.
- 각 단어의 word embedding 과 같은 차원의 positional embedding vector 를 추가한다. 이 값은 아래와 같은 sin, cos 값으로 결정된다.
- 그리고 positional embedding vector 를 보며 해당 단어의 위치 정보를 알 수가 있다. 아래와 같이 그래프를 봤을 때, 의 는 의 과 비슷한 값을 갖는 것을 알 수가 있다.
- 그리고 각 블록 이후에 Add & Norm 블록이 있는데, 이는 쉽게 생각해서 Batch-Norm. 이라고 생각하면 된다.

천천히, 그리고 꾸준히.