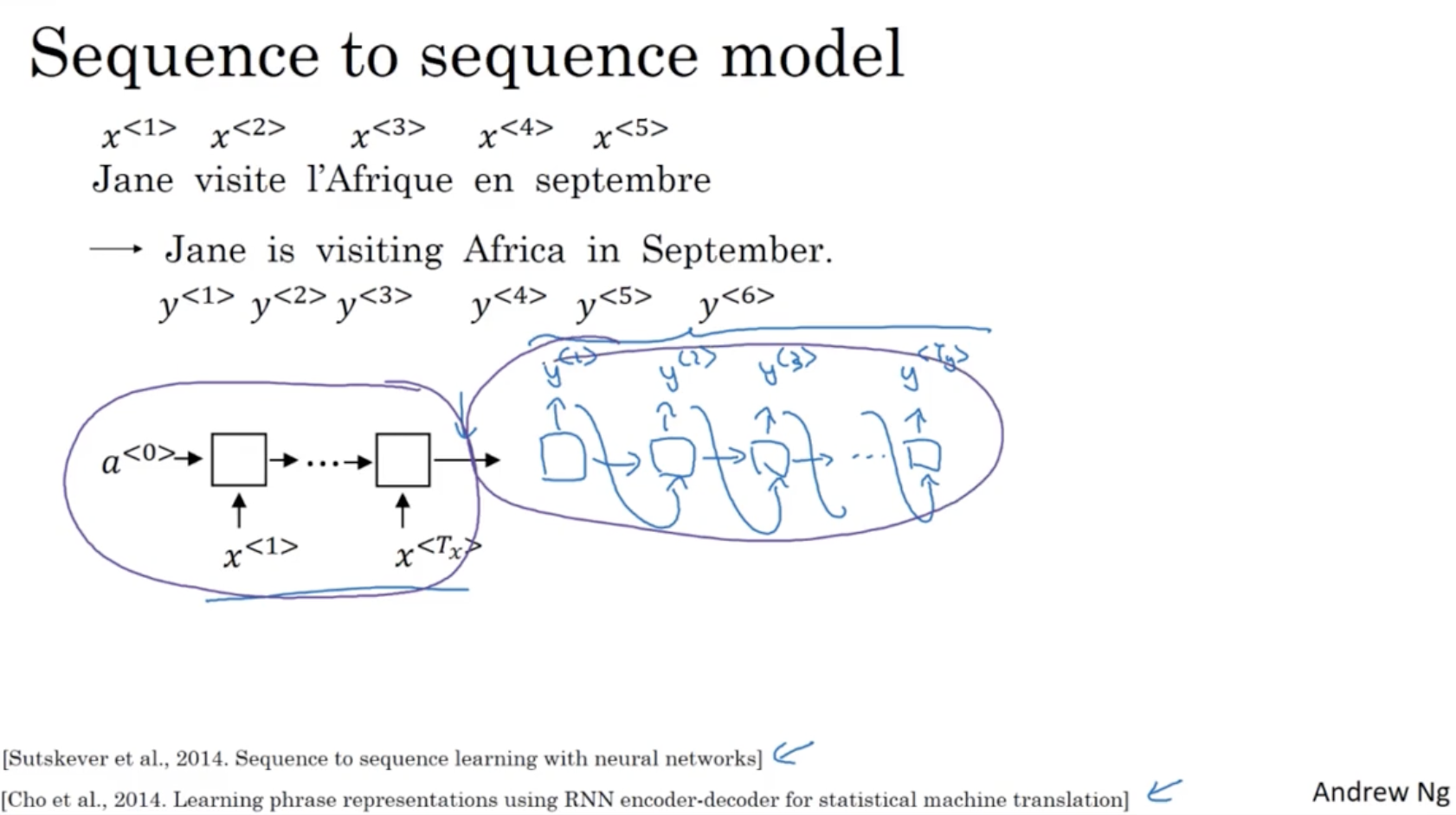
다음으로 sequence to sequence 모델에 대해서 알아보자.
- 아래와 같이 프랑스어를 영어로 번역할 때 사용되는 모델이다.
- 입력 시퀀스 를 먼저 학습하고 ( encoder ) 출력 시퀀스 를 출력한다. (decoder)
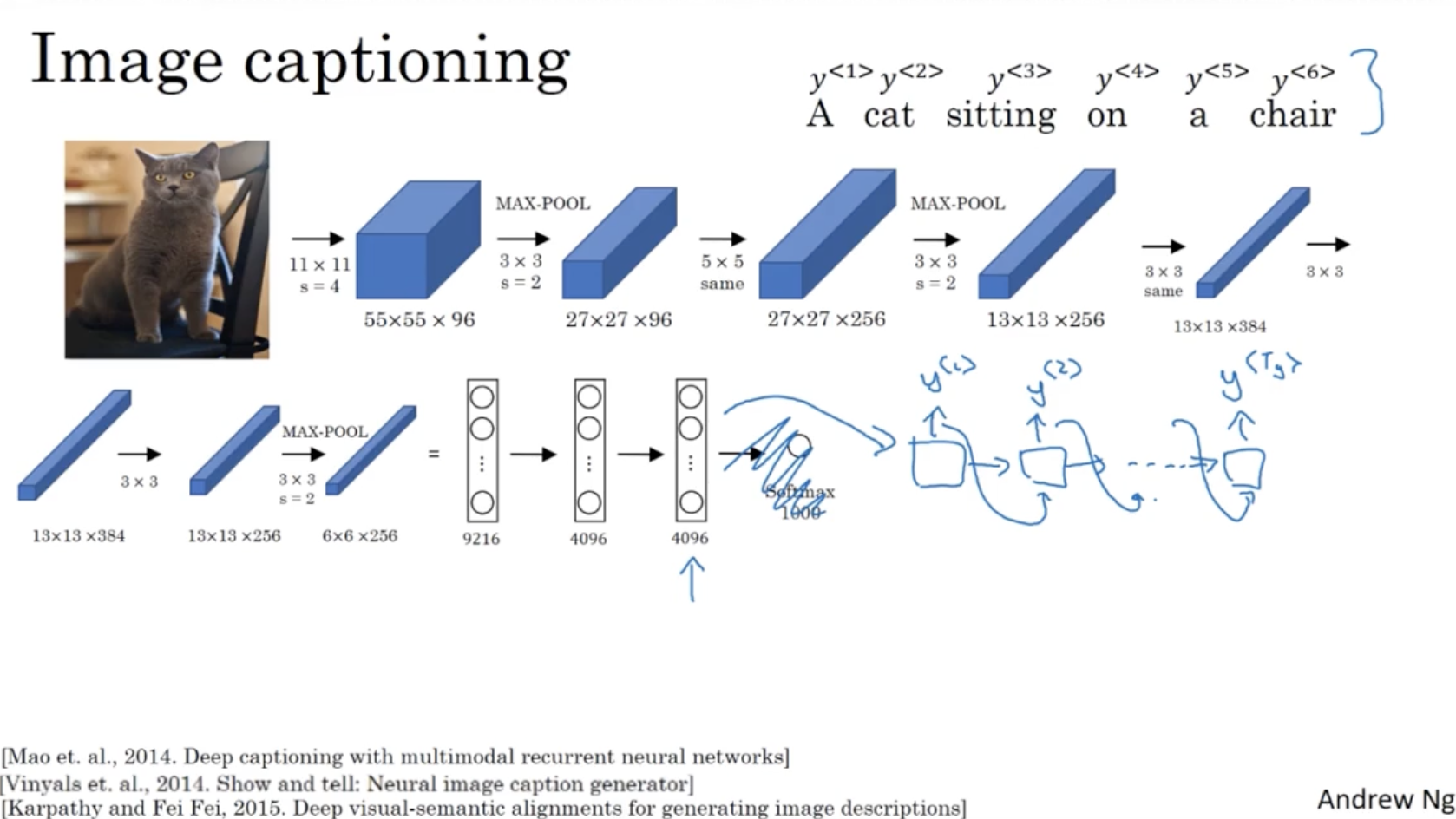
또한 다음과 같이 Image captioning 도 sequence to sequence 모델의 한 예시이다.
- AlexNet. 과 같은 CNN 모델을 encoder 로 두고, 이 4096 차원의 벡터를 RNN 의 입력값으로 넣어서 출력 시퀀스를 출력하는 decoder 로 둘 수 있다.
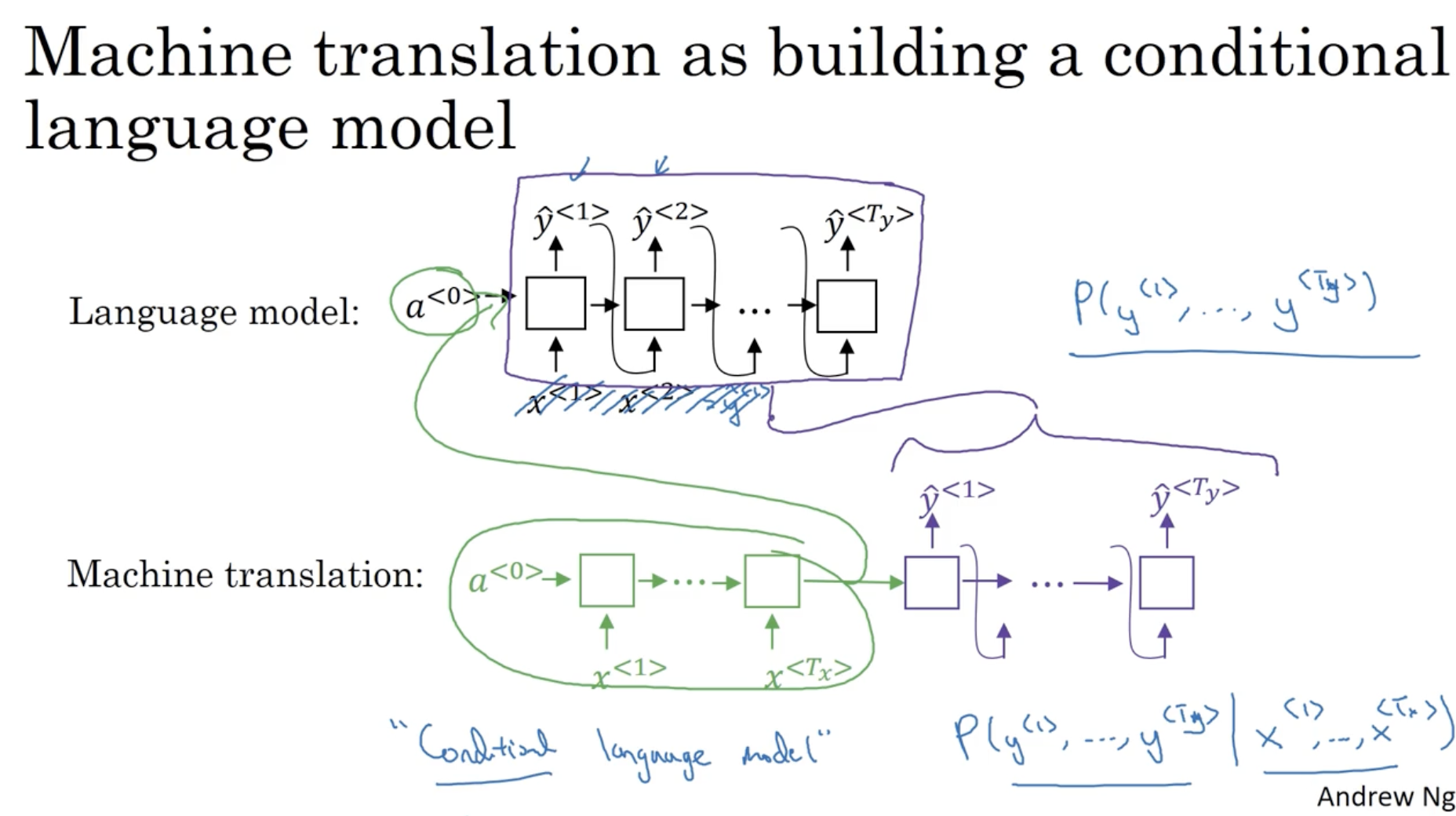
language model 과 machine translation 은 유사한 점이 있다.
- 쉽게 생각해서 machine translation 의 encoder 결과를 language 모델의 입력 activation 로 주고, 이 language 모델을 decoder 로서 적용하는 것과 같다.
하지만 아래와 같이 다양한 번역문이 존재할 수 있는데, 이때 가장 확률이 높은 번역문을 선택해야 한다.
- 이를 위해 Beam Search 방법 등이 있다.

왜 greedy 한 방식이 안 되는지는 다음과 같다.
- 예를 들어, Jane is visiting ... 과 Jane is going ... 라는 문장에서 일반적으로 영어에서는 going 이 좀더 범용적으로 적용되어 확률이 높게 나올 것이다. 따라서 이 경우 Jane is going ... 처럼 번역이 될 수 있다. 이러한 문제점이 존재하기에 greedy 방식은 안 된다.

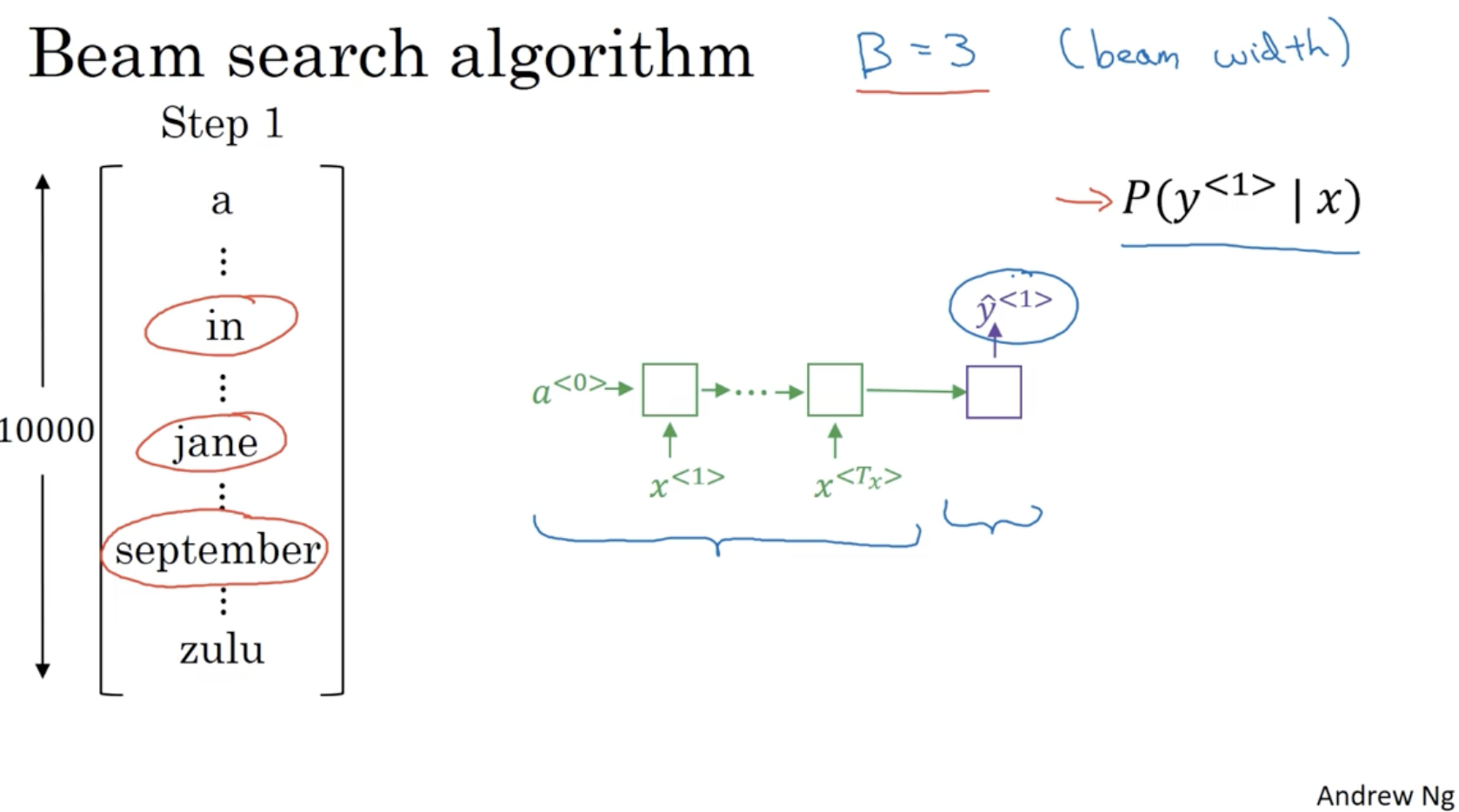
Beam Search algorithm 은 다음과 같다.
- Beam width 로 설정한다.
- 이 경우 각 사전에 대한 단어 중 가장 확률이 높은 단어 3개를 저장해놓는다.
- in, jane, september
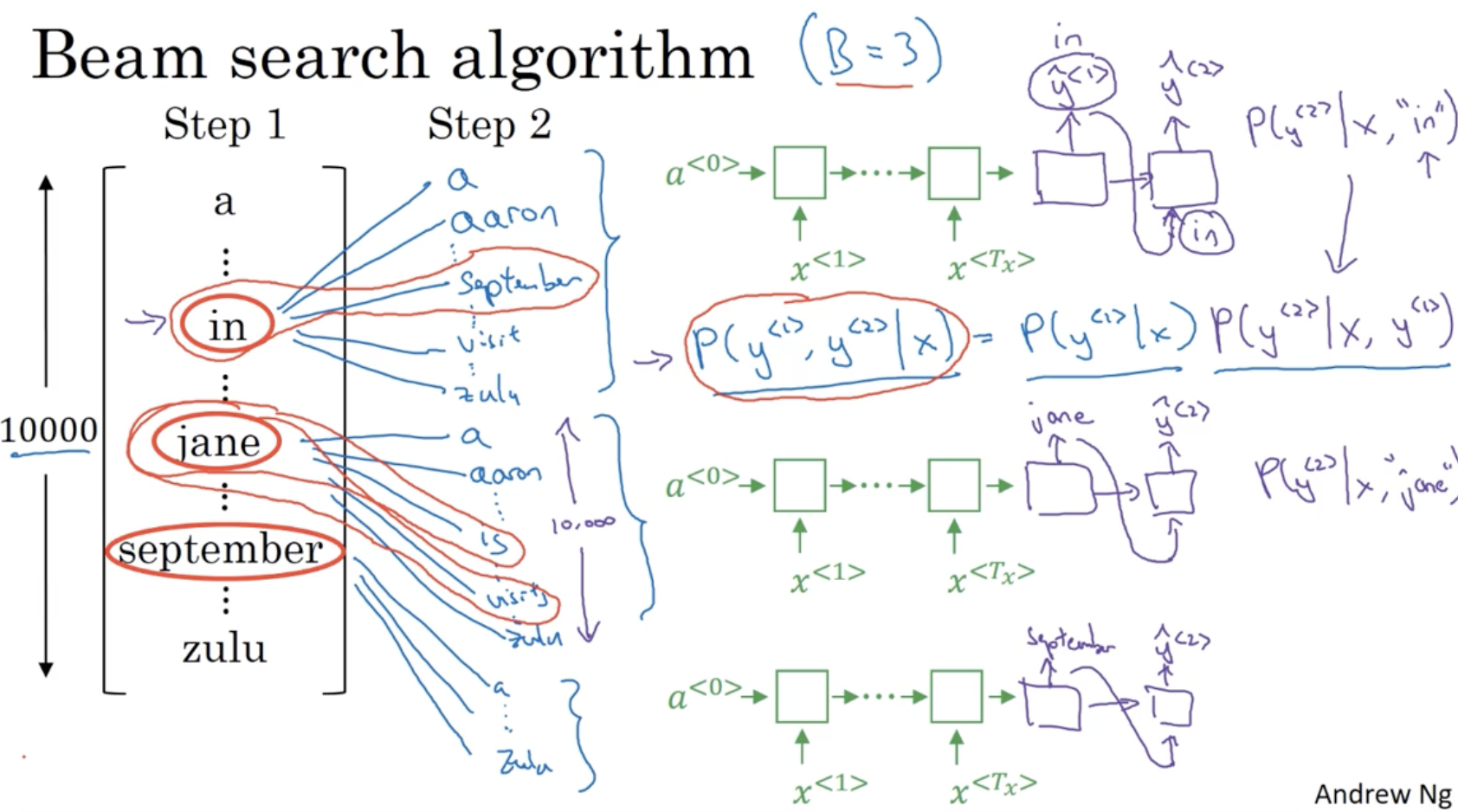
다음으로 이전에 뽑은 가장 확률이 높은 3개의 단어를 각각의 으로 두고 을 계산하여 다시 가장 확률이 높은 3개의 단어 를 뽑는다.
- 이 경우 3만 개의 단어 조합 중, in september, jane is, jane visits 이 가장 확률이 높은 3개로 뽑혔다.
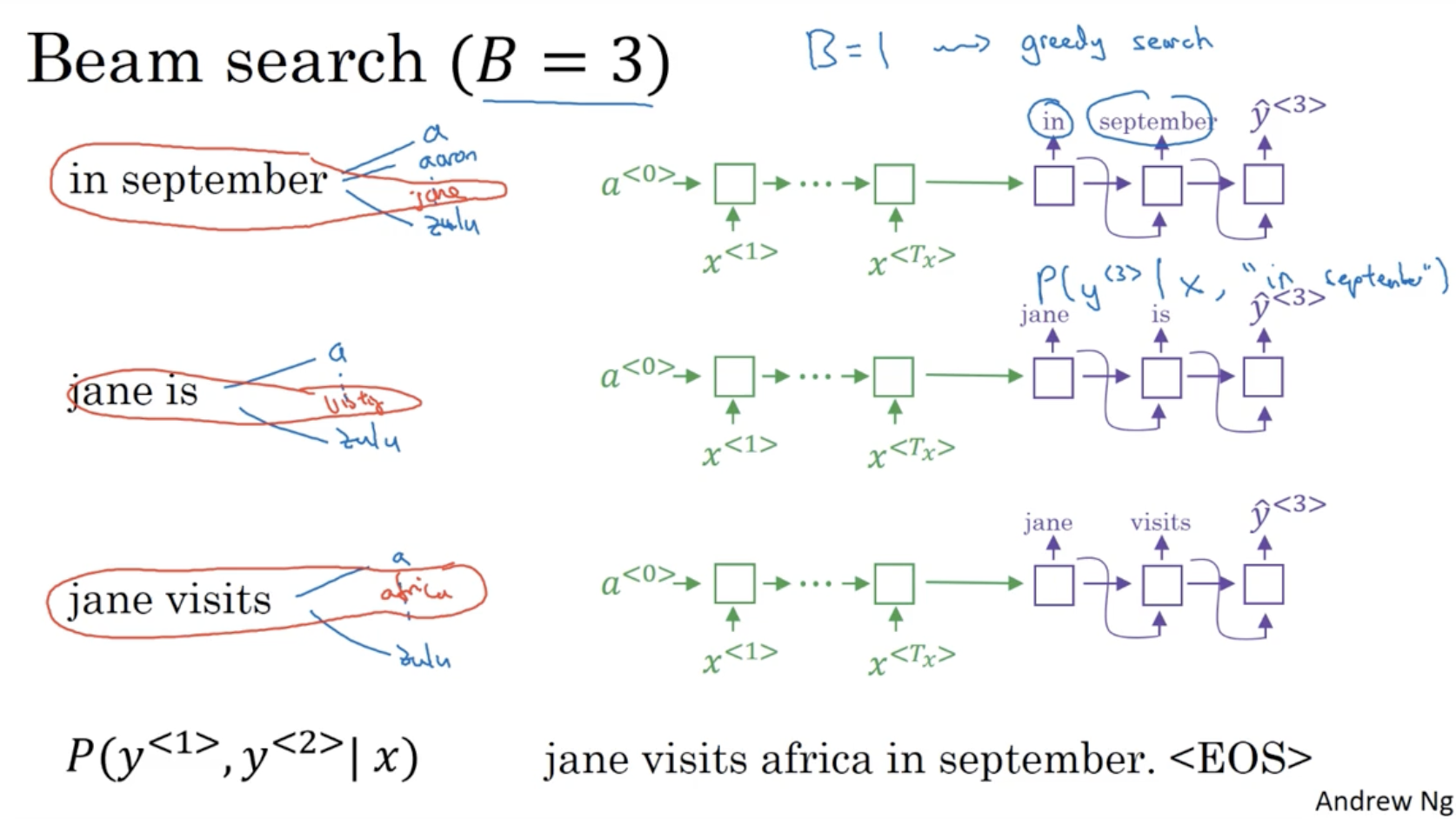
마찬가지로 이전에 뽑힌 in september, jane is, jane visits 다음으로 이뤄질 단어 중 가장 확률이 높은 3개를 뽑는다.
- 이런 식으로 반복하다보면 결국 가장 확률이 높은 "jane visits africa in september. <EOS>" 가 남을 것이다.
- 그리고 만약 Beam width 이라면 이는 이전에 봤던 greedy search 와 같을 것이다.
Beam search alg. 의 일부 식을 바꾸면 다음과 같다.
- 기존의 경우인 와 같은 수식을 보자. 확률은 0.xxxx 값을 갖기 때문에 이 값이 누적되어 곱해지다보면 컴퓨터에서 underflow 문제가 발생할 수 있다.
- 따라서 여기에 를 적용하여 이 문제를 해결할 수 있다.
- 그리고 와 같이 적용하여 lenght normalization 을 얼마나 적용할지를 선택할 수 있다. 예를 들어 문장 길이가 짧을 경우 underflow 문제는 발생할 확률이 낮으니 이 경우에는 normalization 을 덜 적용해도 괜찮을 거다.
- 는 휴리스틱한 방법으로 정확도가 항상 높게 나온다는 증명은 안 되어 있지만, 사람들은 보통 일 때 정확도가 높게 나온다고 한다.

그렇다면 Beam width 는 어떻게 세팅해야 할까?
- 가 크다면, 정확도는 올라가지만 그 만큼 속도가 느려질 것이다.
- 가 작다면, 정확도는 내려가지만 그 만큼 속도는 빨라질 것이다.
- 이처럼 값을 설정하는 것은 적용되는 도메인마다 다르기 때문에 1->3->10 처럼 grid 한 방식으로 비교하는 것을 추천한다.

다음으로 Beam Search 의 정확도를 분석하는 법을 알아본다.
- 아래와 같이 인간이 번역한 값 와, beam search alg. 이 번역한 값 가 있다고 해보자.
- 그리고 이 두 값을 RNN ( encoder-decoder ) 에 적용하여 와 중 어느 것이 확률이 더 높게 나오는지를 확인한다.
- 이를 활용하면 beam search 의 에러를 확인할 수 있을 것이다.

다음과 같이 구체적으로 살펴보자.
- 만약 일 경우, Beam search alg. 은 잘못되었다고 판단할 수 있으며,
- 만약 일 경우, RNN 모델이 잘못되었다고 판단할 수 있다.

따라서 다음과 같이 각 문장에 대한 를 비교하면서 RNN 모델의 에러와 beam search alg. 의 에러 비율을 확인할 수 있을 것이다.

다음으로 Attention model 에 대해서 배워본다.
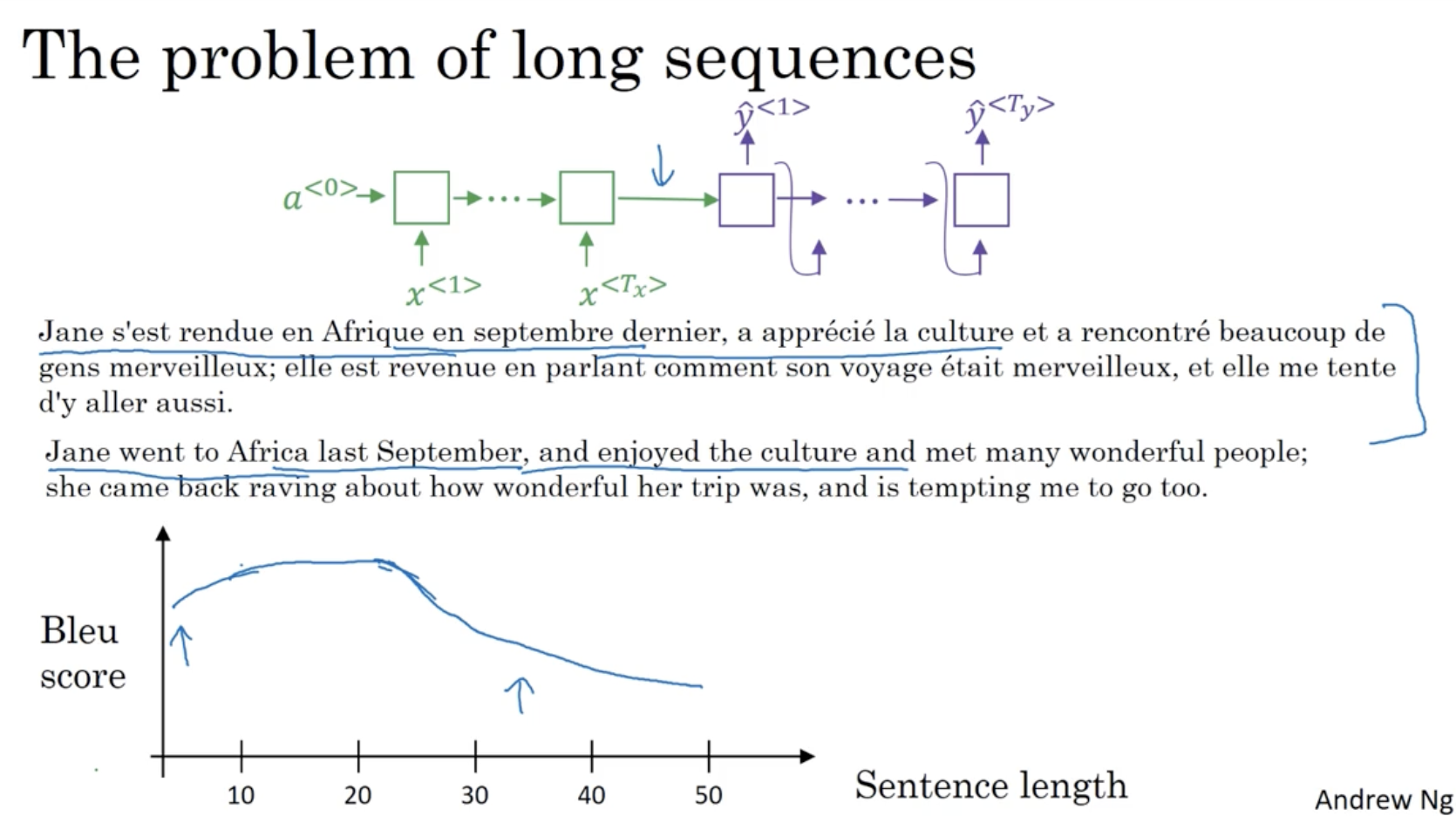
- 우선 아래와 같이 긴 문장을 번역한다고 해보자.
- 사람의 경우 조금씩 읽으면서 번역을 수행한다.
- 하지만 이전에 배운 Beam Search alg. 과 같은 방법은 전체 문장을 한번에 읽고 한번에 번역을 진행한다.
- 따라서 아래 그래프와 같이 문장 길이가 길어질수록 Bleu score (번역문의 정확도를 측정하는 지표) 값이 떨어지는 것을 확인할 수 있을 것이다.
- 따라서 사람이 번역하는 것처럼 앞문장을 조금씩 읽으면서 번역하는 방법을 위해 Attention model 이 적용된다.
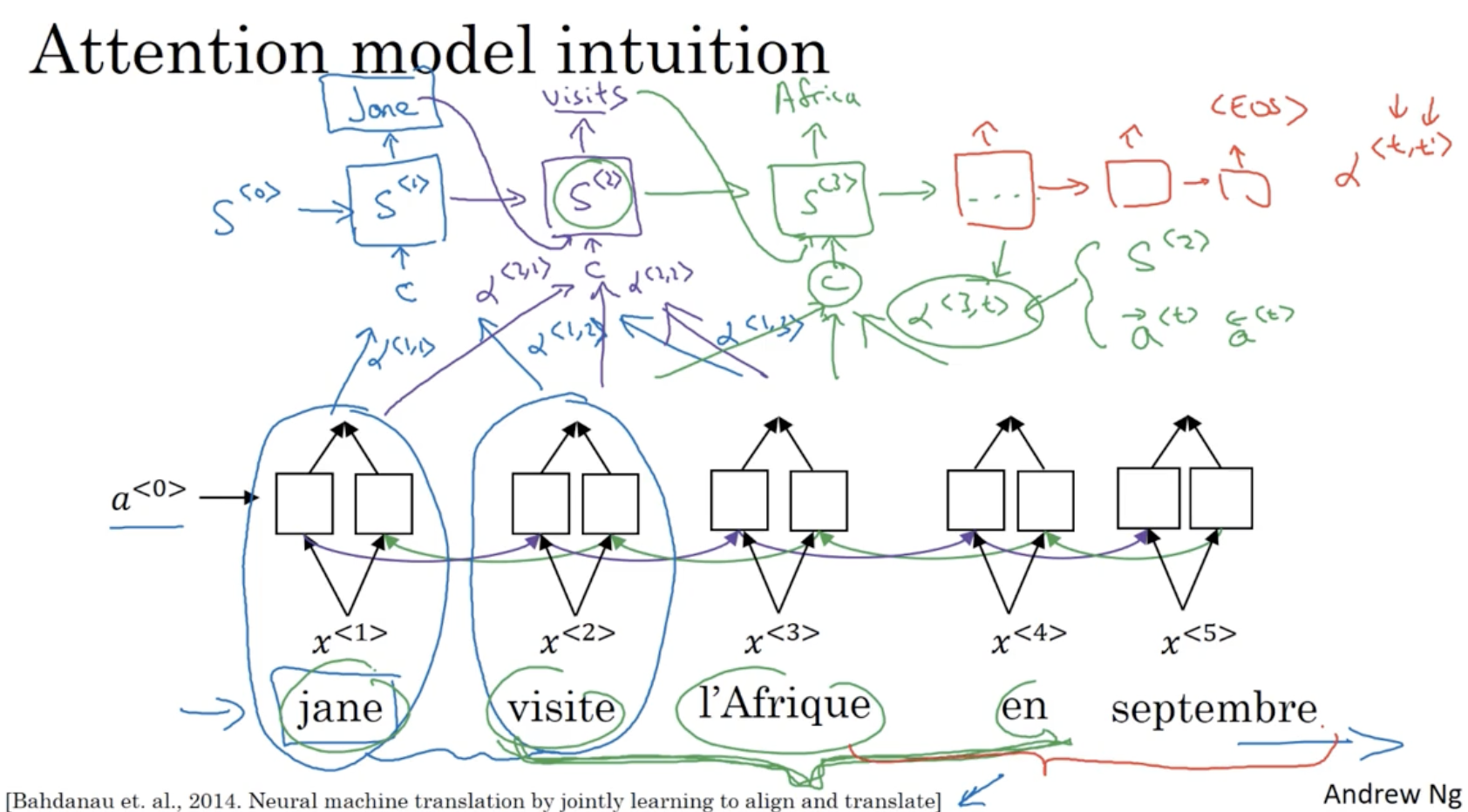
Attention model 의 개략적인 구조는 아래와 같다.
- 입력 시퀀스 를 BRNN 모델에 적용하여 각각의 activations 를 구한다.
- 그리고 이 activations 를 가지고 값을 구한다. (해당 단어의 기여도 같은 의미)
- : 번째 hidden states 의 예측을 위한 윈도우 내 존재하는 시퀀스 데이터들의 가중치(기여도) 값.
- 그리고 hidden states 에 context 와 윈도우 내 존재하는 을 입력하여 출력 시퀀스 를 구한다.
- 그리고 은 의 입력으로 들어간다.
- 이런 식으로 진행하여 <EOS> 가 나올 때까지 수행한다.
Attention model 의 구체적인 구조는 아래와 같다.
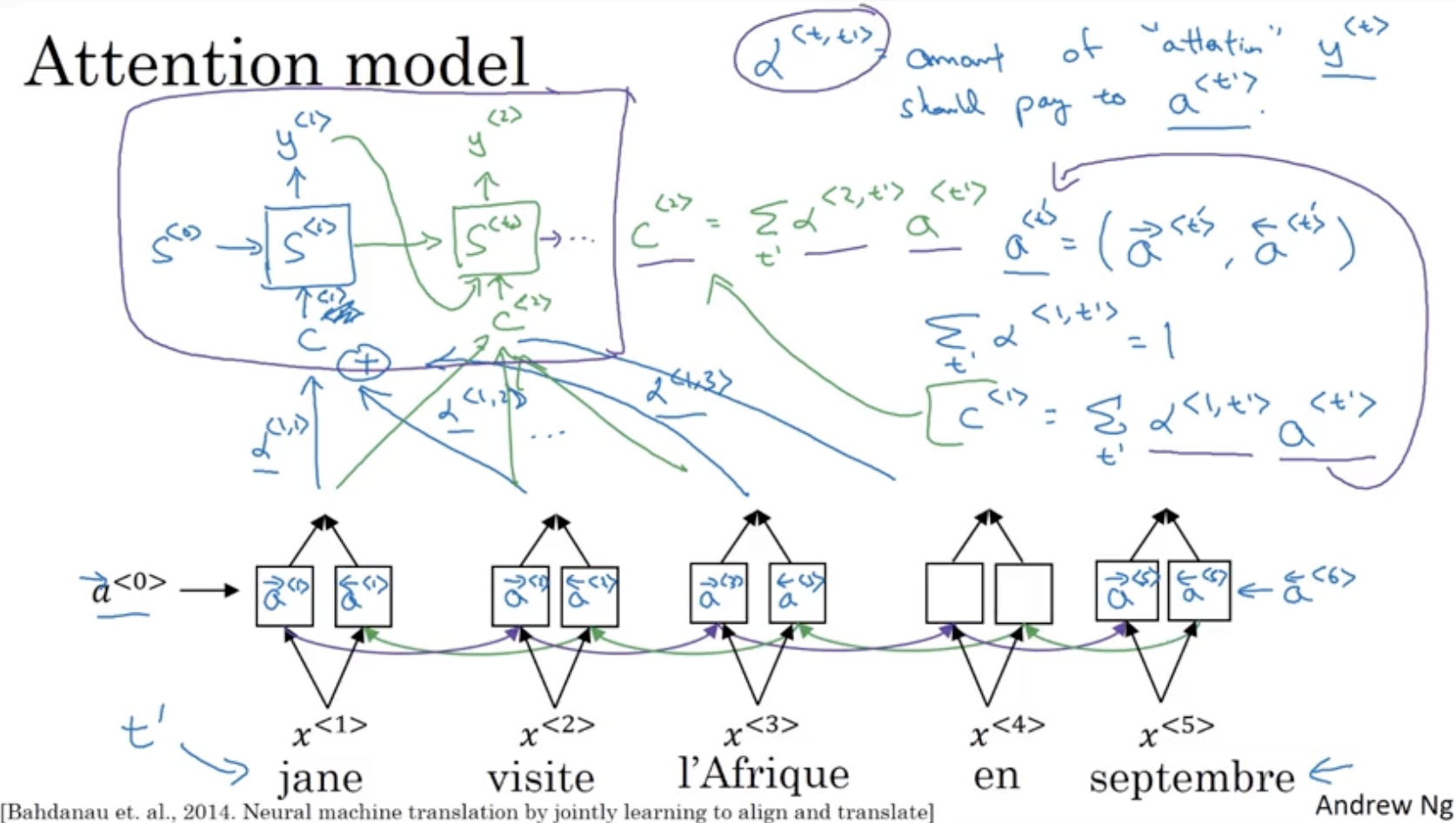
- : 번째 입력 데이터 시퀀스
- : 번째 입력 시퀀스의 에 대한 가중치. 해당 가중치를 통해서 를 출력할 때 해당 입력 시퀀스를 얼마나 가중할지 결정.
- : 번째 Hidden State 의 입력값.
- 입력 시퀀스 에 대한 가중치와 그 activation 값들의 곱의 합.
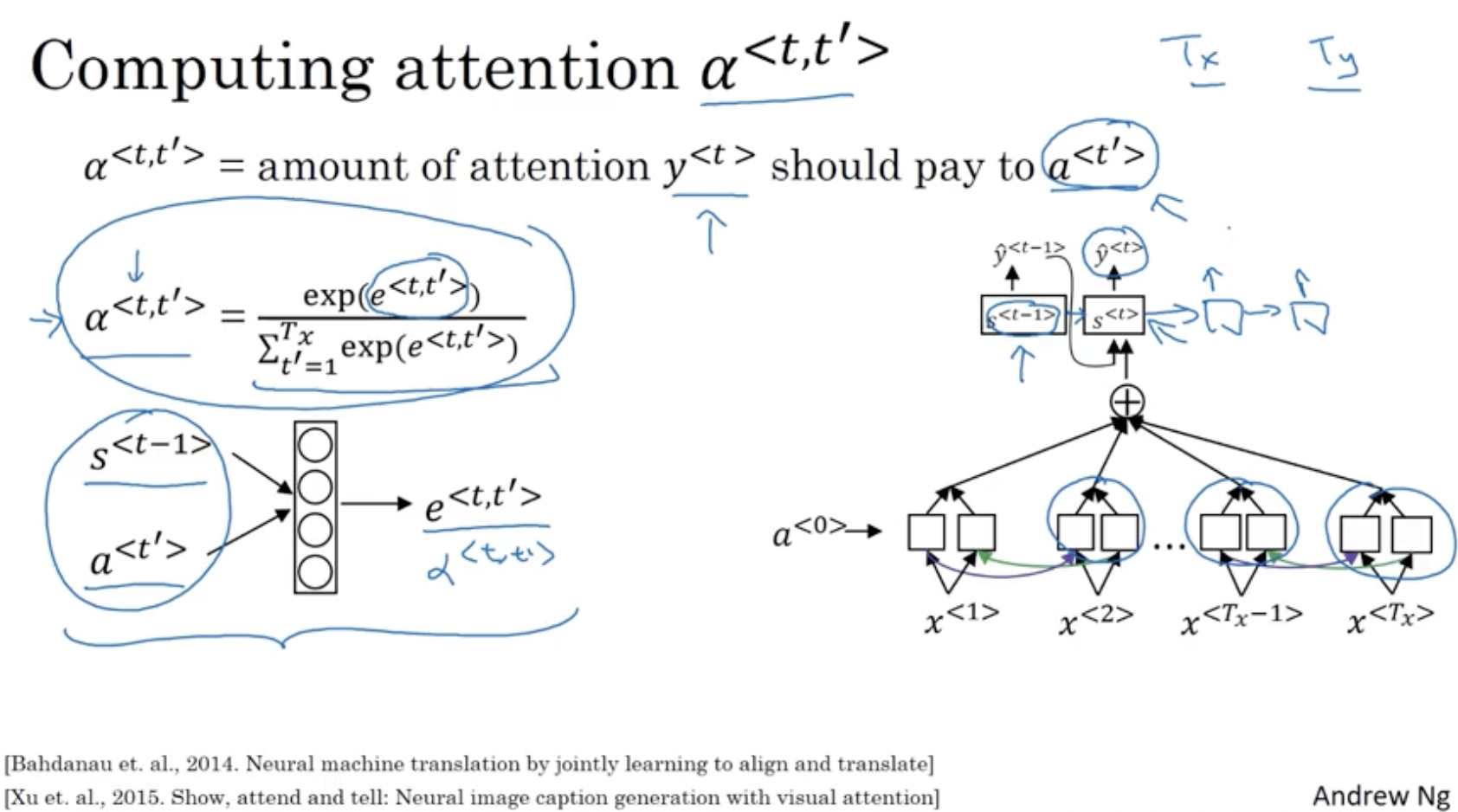
다음은 attention 값인 를 구하는 방법이다.
- : 번째 입력 시퀀스의 feature 가 에 얼마나 가중치를 부여할 지를 의미한다.
- : softmax 함수처럼 구할 수 있다.
- Neural Network
- 다만 attention 모델의 경우 계산 비용이 이라는 단점이 있다. 왜냐하면 만큼의 연산이 필요하기 때문이다.
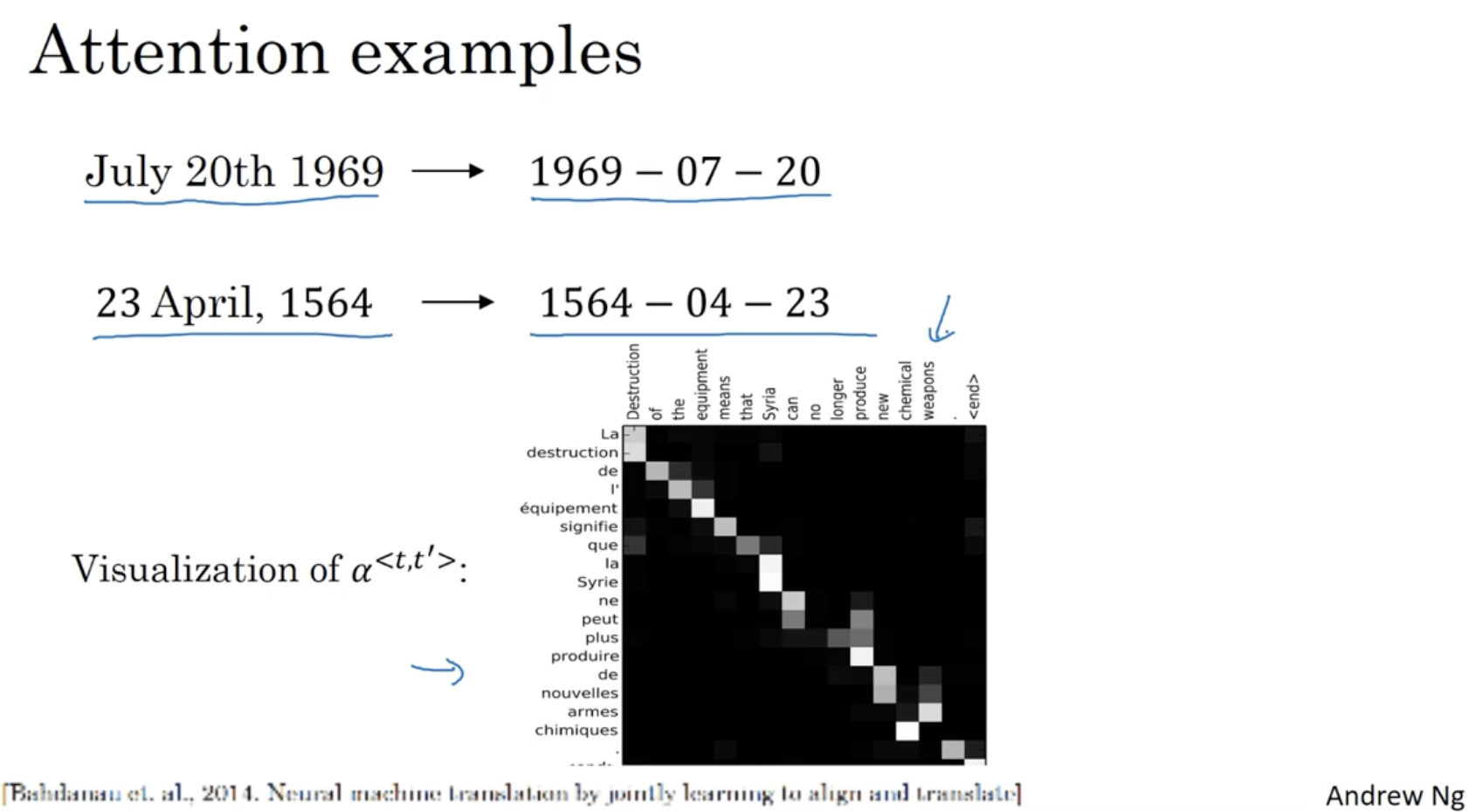
다음은 Attention Model 의 예시와 Attention 이 실제로 어떻게 나오는지를 시각화한 예시이다.
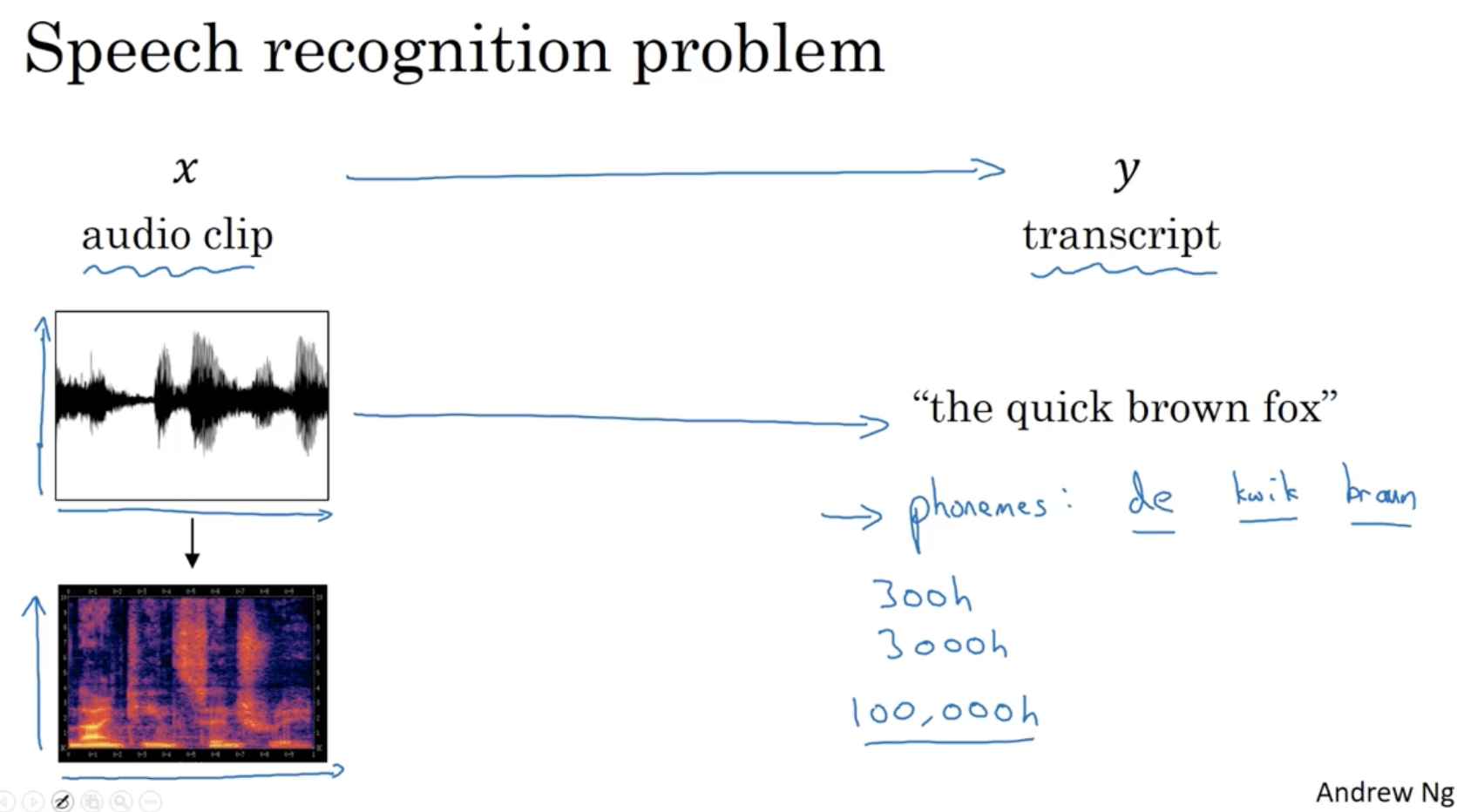
다음으로 Speech Regcognition model 에 대해서 알아보자.
- 아래와 같이 음성 클립을 가지고 문장으로 출력한다.
- 300시간의 오디오 클립, 3000시간, 100000시간 오디오 등을 가지고 학습하는 경우도 있다.
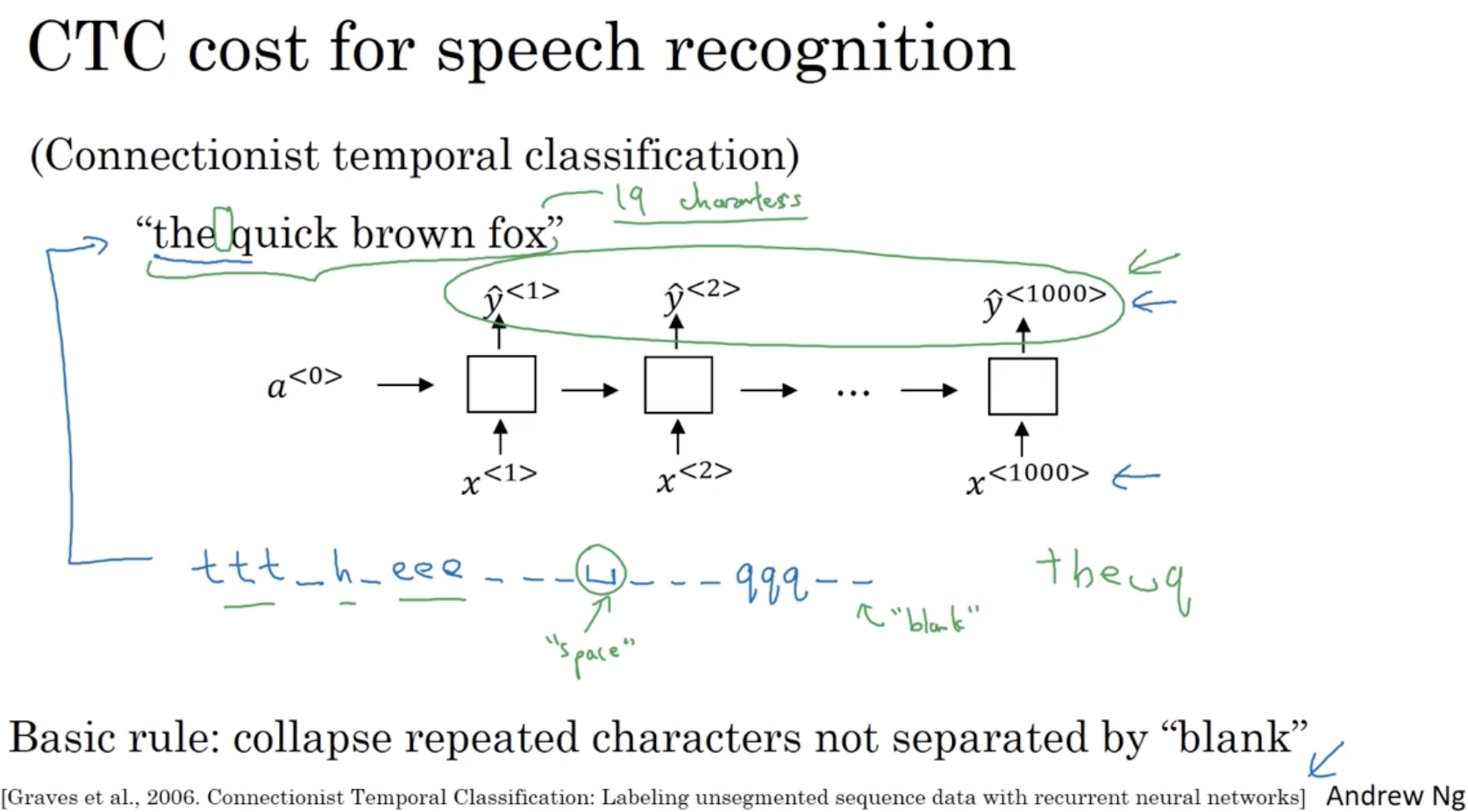
주요 모델 중 하나는 CTC (Connectionist temporal classification) 모델이다.
- 아래와 같이 the quick brown fox 라는 10초 짜리 오디오 클립이 입력으로 주어진다고 가정해보자.
- (이 경우 가 같아 보이지만, 실제로는 거의 다르다.)
- 그리고 이 10초 짜리 오디오 클립을 아래와 같이 1000 개의 시퀀스로 분리할 수 있다.
- 시퀀스의 각 데이터는 t, t, t, _, h, _, e, e, e, ... 처럼 이루어진다.
- 따라서 이러한 시퀀스 입력 데이터를 가지고 오디오에 대한 문장을 출력한다.
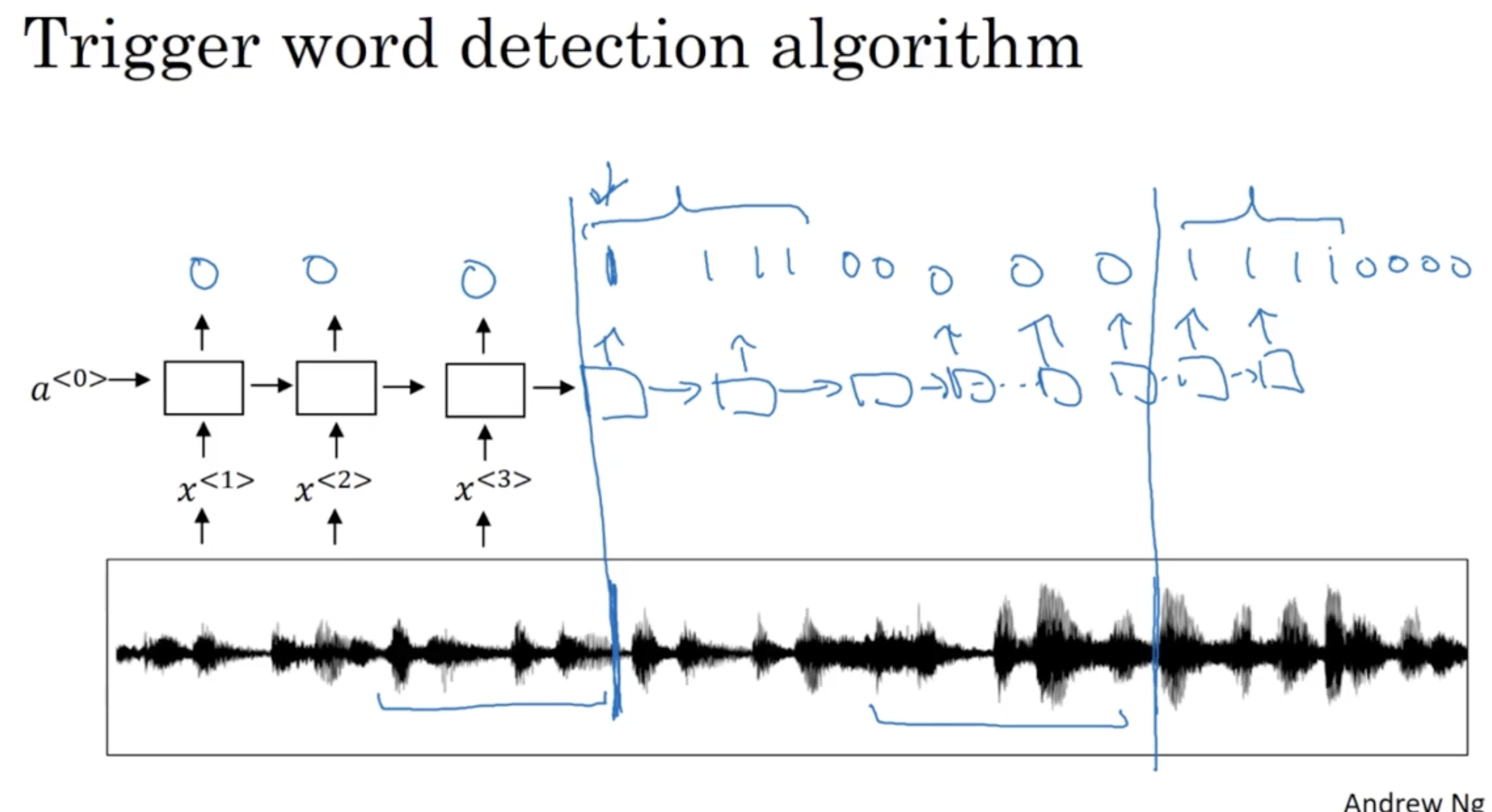
다음으로 trigger word detection 에 대해서 알아보자.
- 쉽게 생각해서 "시리야"와 같은 특정 키워드를 인식하는 것이다.

다음은 Trigger word detection 의 입력 데이터와 정답 데이터의 예시이다.
- 음성 클립에서 특정 키워드가 나온 부분에 대해서는 1 로 예측하고, 그 외에는 0 으로 예측한다.