https://www.youtube.com/watch?v=gb262LDH1So&list=PLiPvV5TNogxIS4bHQVW4pMkj4CHA8COdX
Andrew Ng 교수님의 머신러닝 강좌를 통해 공부를 시작했다.
머신러닝의 예시에는 어떤 것들이 있는가.
- 데이터 마이닝
- 자율주행
- 필적 확인
- 자연어 처리
- 컴퓨터 비전
- 상품 추천

머신러닝은 어떤 태스크 T와 측정값 P에 따라 경험 E를 학습하는 것이다.
만약 이메일 프로그램이 당신이 각 메일을 스팸으로 처리하는지 아니면 처리하지 않는지를 보며, 스팸 필터링 기능을 향상시키는 쪽으로 학습한다고 가정해보자. 이 경우, 아래 보기 중 태스크 T는 무엇일까?

정답은 1번이다. 각 보기의 의미는 다음과 같다.
1. 이메일을 분류하는 것. 즉, 작업(태스크)을 의미.
2. 이메일이 스팸인지 아닌지 레이블을 확인하는 것. 즉, 경험(관찰)을 의미
3. 올바르게 분류된 이메일의 수. 즉, 측정값을 의미.

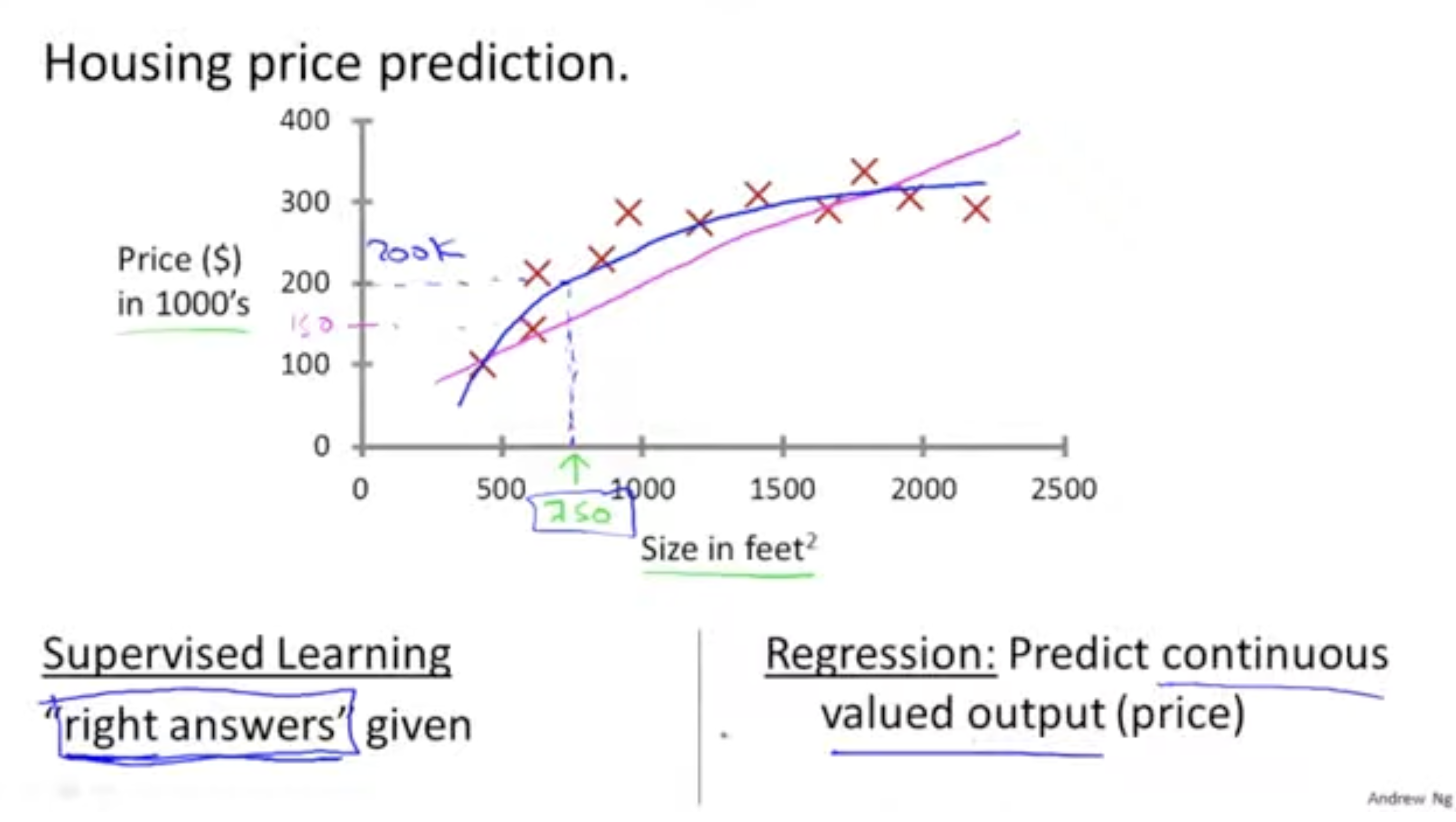
- 다음과 같은 주택 가격 그래프를 보자.
- 각 점은 그래프에서 (집 크기, 가격)에 대한 데이터를 나타내고 있다.
- 이 경우, 이러한 데이터들을 가지고 그림과 같이 직선 및 곡선 함수를 만들 수 있을 것이다.
- 따라서, 만약 750이라는 집 크기가 주어진다면, 이 데이터의 가격은 150(직선의 경우) 아니면 200(곡선의 경우)라고 예측할 수 있을 것이다.
- 이처럼 기존의 정답 데이터들을 가지고 학습하는 것을 "Supervised Learning"이라고 한다.
- 그리고 가격 정보처럼 연속된 값을 예측하는 것을 "Regression"이라고 한다.
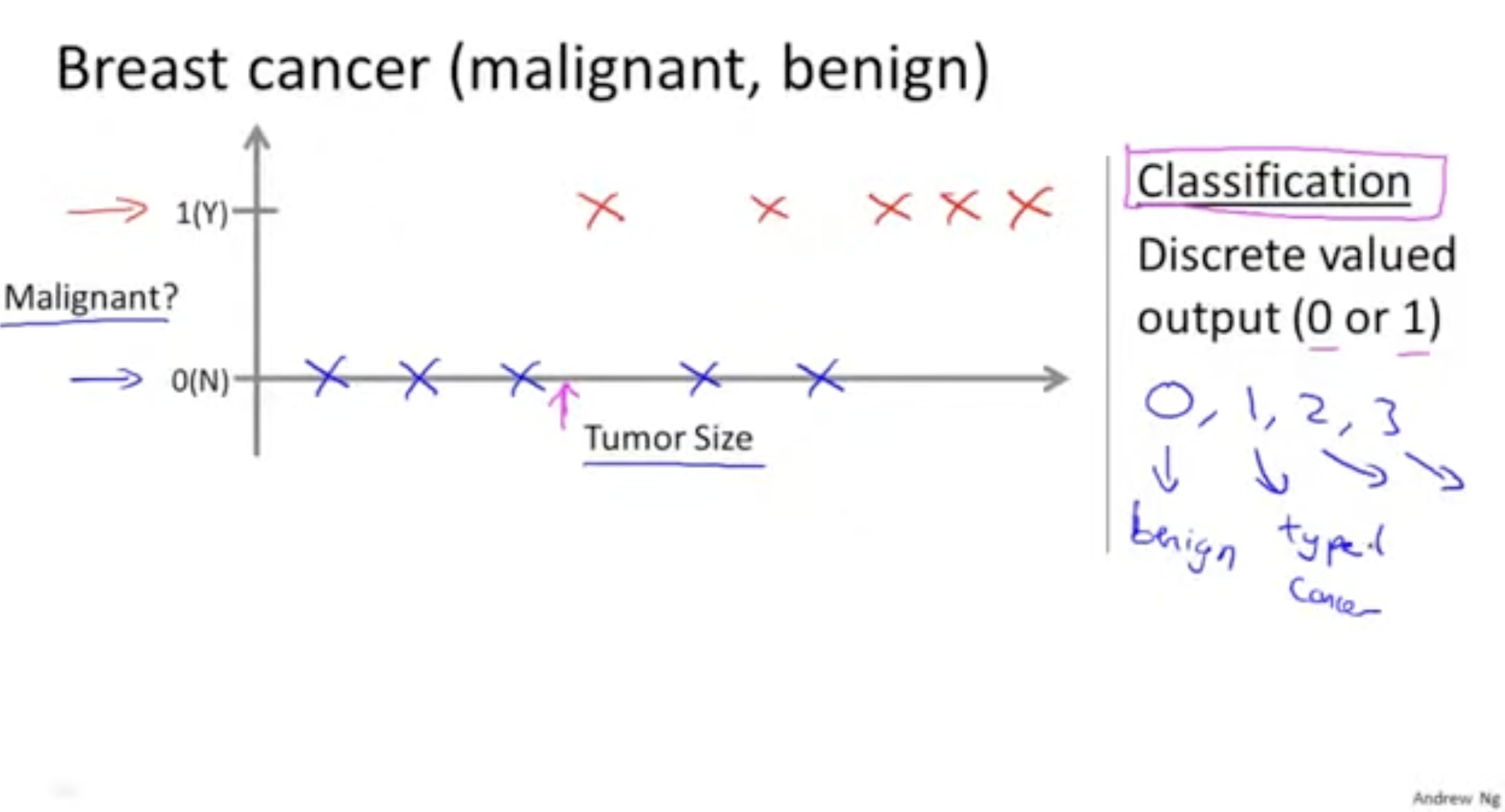
- 다음은 종양에 따른 유방암 유무를 나타내는 데이터다.
- 악성 종양인지 양성 종양인지 판별한다.
- 파란색은 양성, 빨간색은 악성이다.
- 그림과 같이 양성(파란색)은 0, 악성(빨간색)은 1로 분류하였다.
- 이와 같이 데이터의 클래스를 분류하는 것을 "Classification"이라고 한다.
- 그림과 달리 클래스의 개수는 여러 개일 수 있다. (0: 남자, 1: 여자, 2: 성인, 3: 어린이, ...)
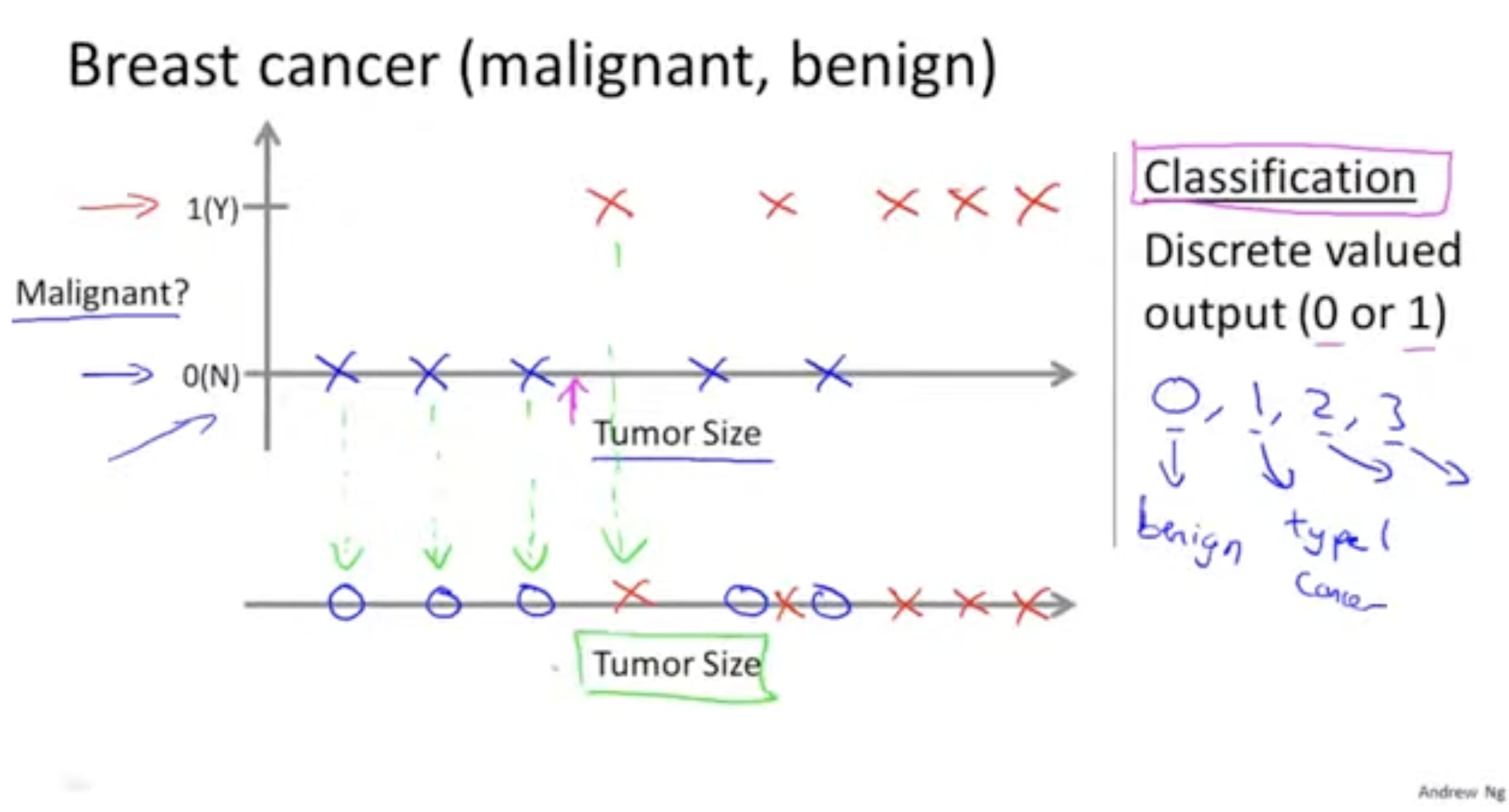
그렇다면 위의 그래프를 아래 그래프처럼 1차원 그래프로 표시해보자. 이 경우 feature의 차원은 1이다 (Tumor Size만 존재)
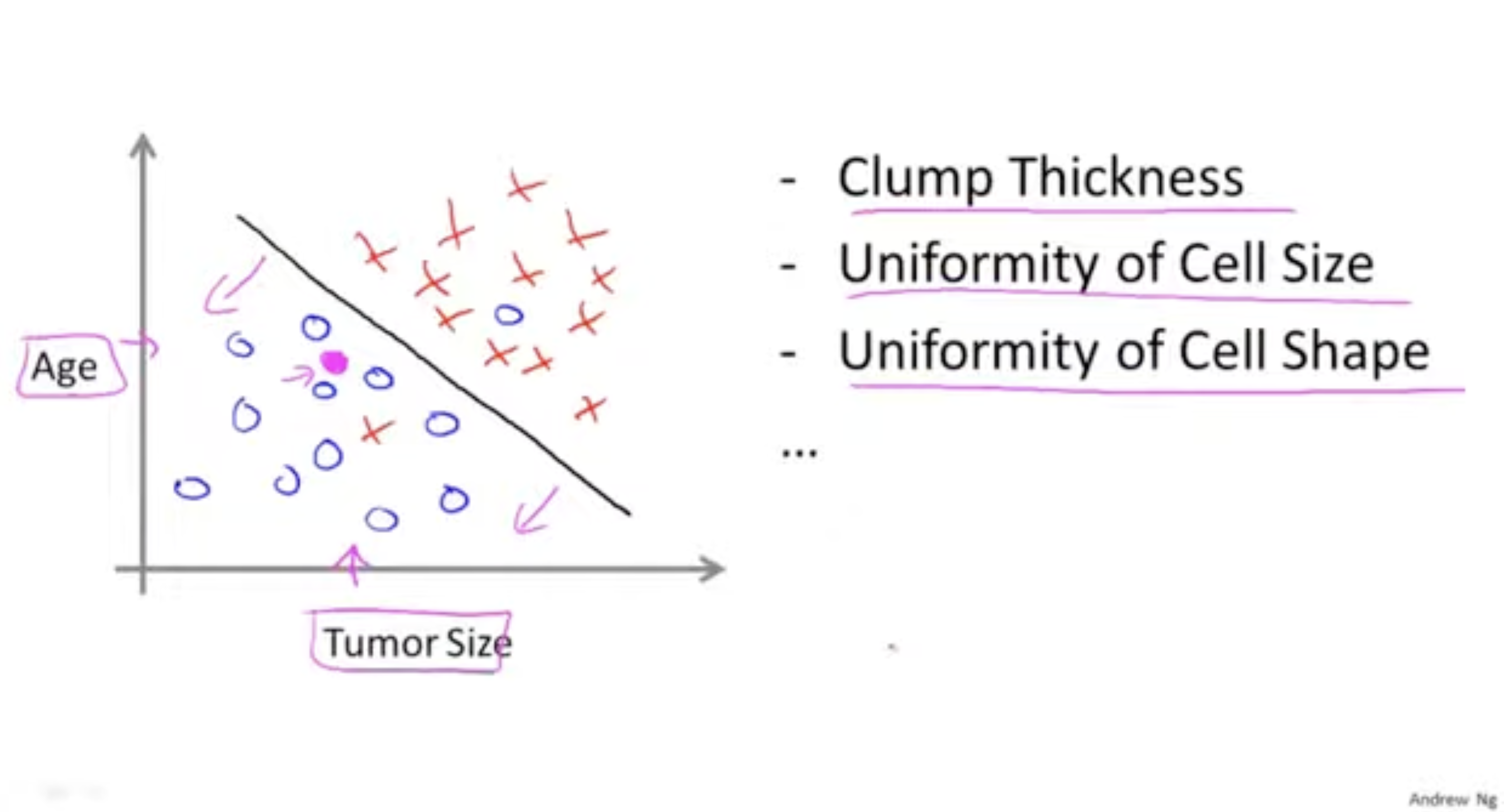
그렇다면 차원이 더 늘어난다면 어떨까?
- 아래 그림은 2차원 feature (Tumor Size, Age)에 대한 그래프이다.
- 이 경우 양성(파란색), 악성(빨간색)을 어떻게 구분할 수 있을까?
- 그림과 같이 경계선을 기준으로 분류가 가능할 것이다.
- 그리고 feature의 차원이 계속 늘어난다고 해도 어떤 경계를 기준으로 분류가 계속 이뤄질 것이다.
문제1: 동일한 물건의 재고가 많이 있다고 하자. 다음 3개월 동안 물건이 얼마나 팔릴까?
문제2: 각 customer의 계정에 대해서 해킹/손상 되었는지 어떻게 알 수 있을까?
이 문제들에 대해서 각각 classfication인지, regression인지 맞혀보자.

정답은 3번이다.
문제1의 경우 수치값, 즉 연속적인 값을 예측해야하는 문제로 regression에 해당한다. 그리고 문제2는 hacked or not hacked를 묻는 문제로 classification에 해당한다.

이때까지 정답값이 주어진 데이터를 학습하는 Supervised Learning을 배웠다. 아래 그림처럼 데이터들의 분류값(정답값)이 주어진 상태다.

반면에, "Unsupervised Learning"은 데이터들 간의 구별이 되지 않는다. 즉, 데이터의 분류값(정답값)이 존재하지 않는 상태로 학습을 하는 것을 의미한다.
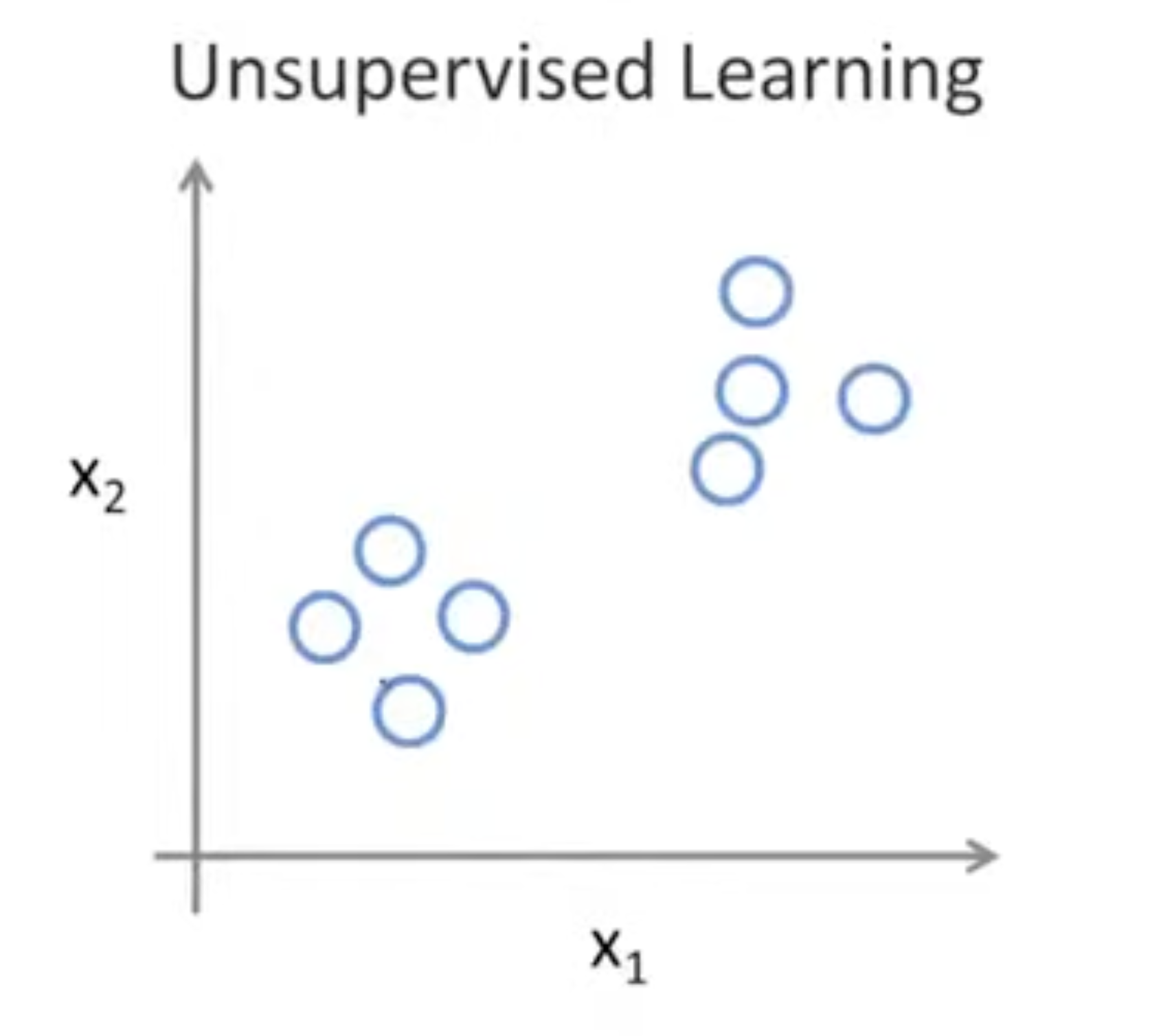
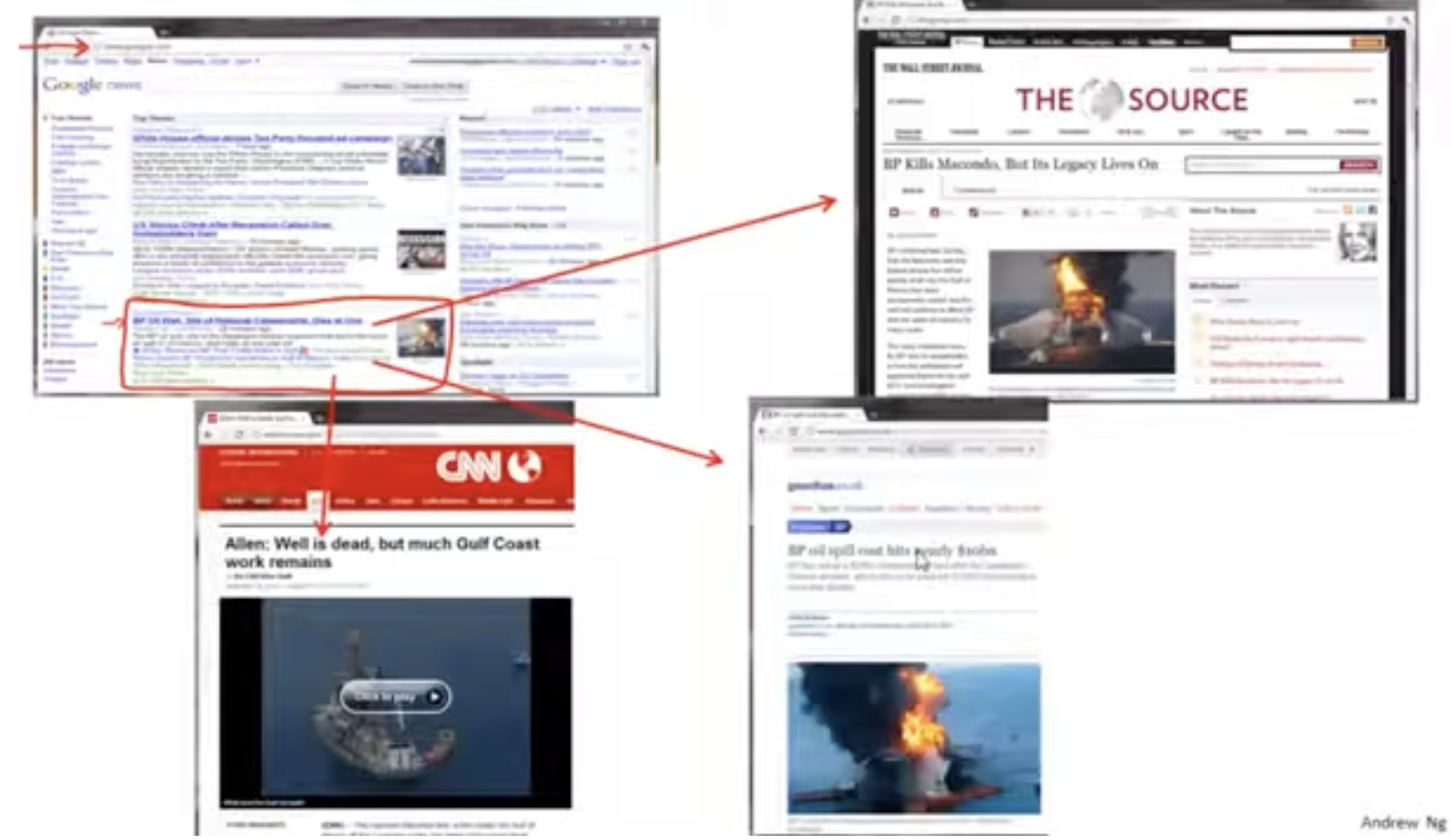
만약 구글에 어떤 뉴스를 검색했을 때, 관련 뉴스들을 어떻게 묶을 수 있을까?
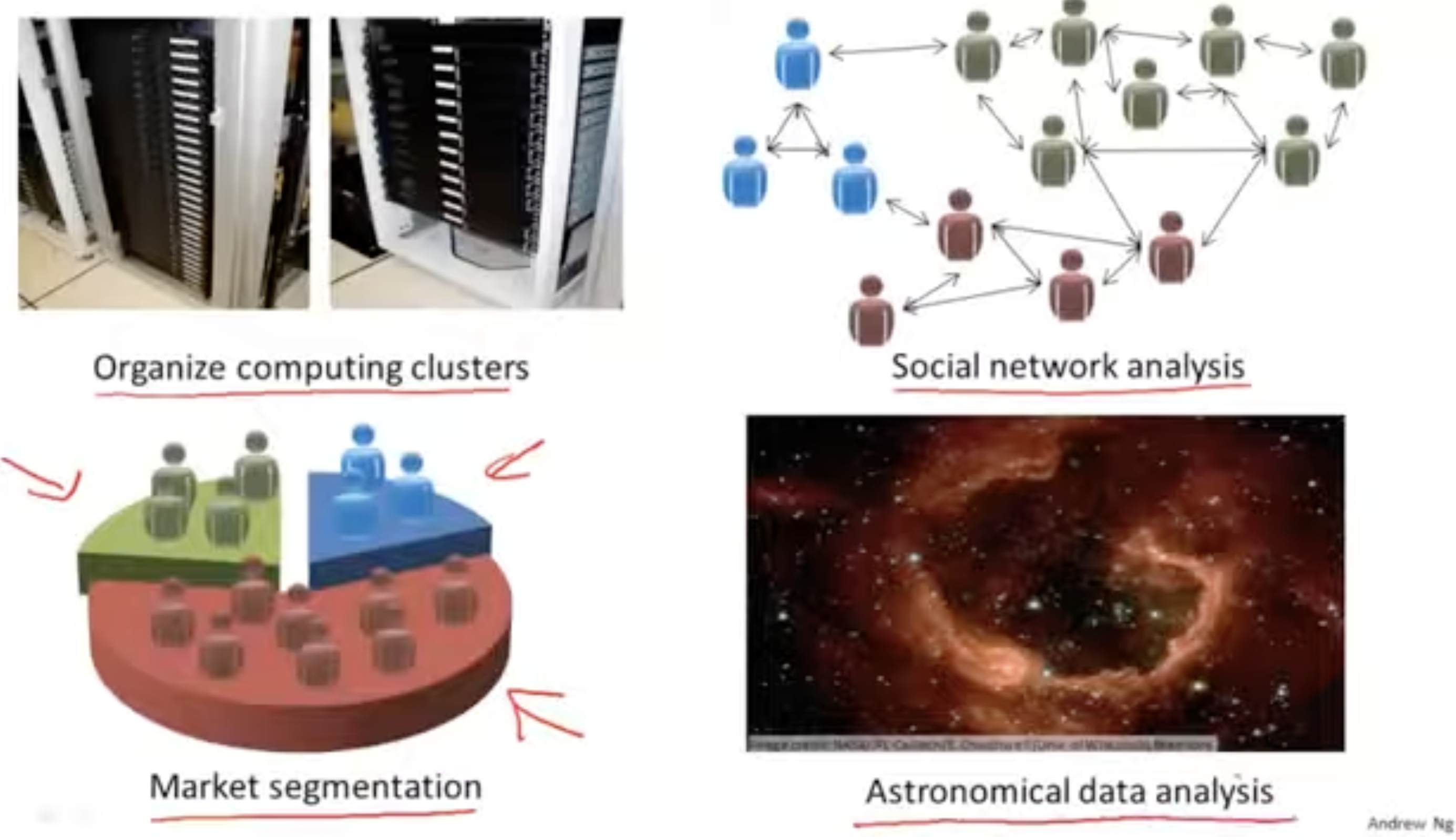
다음은 unsupervised learning에 대한 예시들이다.
- 컴퓨터 서버(클러스터)를 그룹핑(클러스터링).
- 소비 패턴에 따른 고객 분류.
- 유사한 관심사를 갖는 사람들끼리 그룹핑.
- 별과 은하의 스펙트럼 데이터를 기반으로 유형 분류.
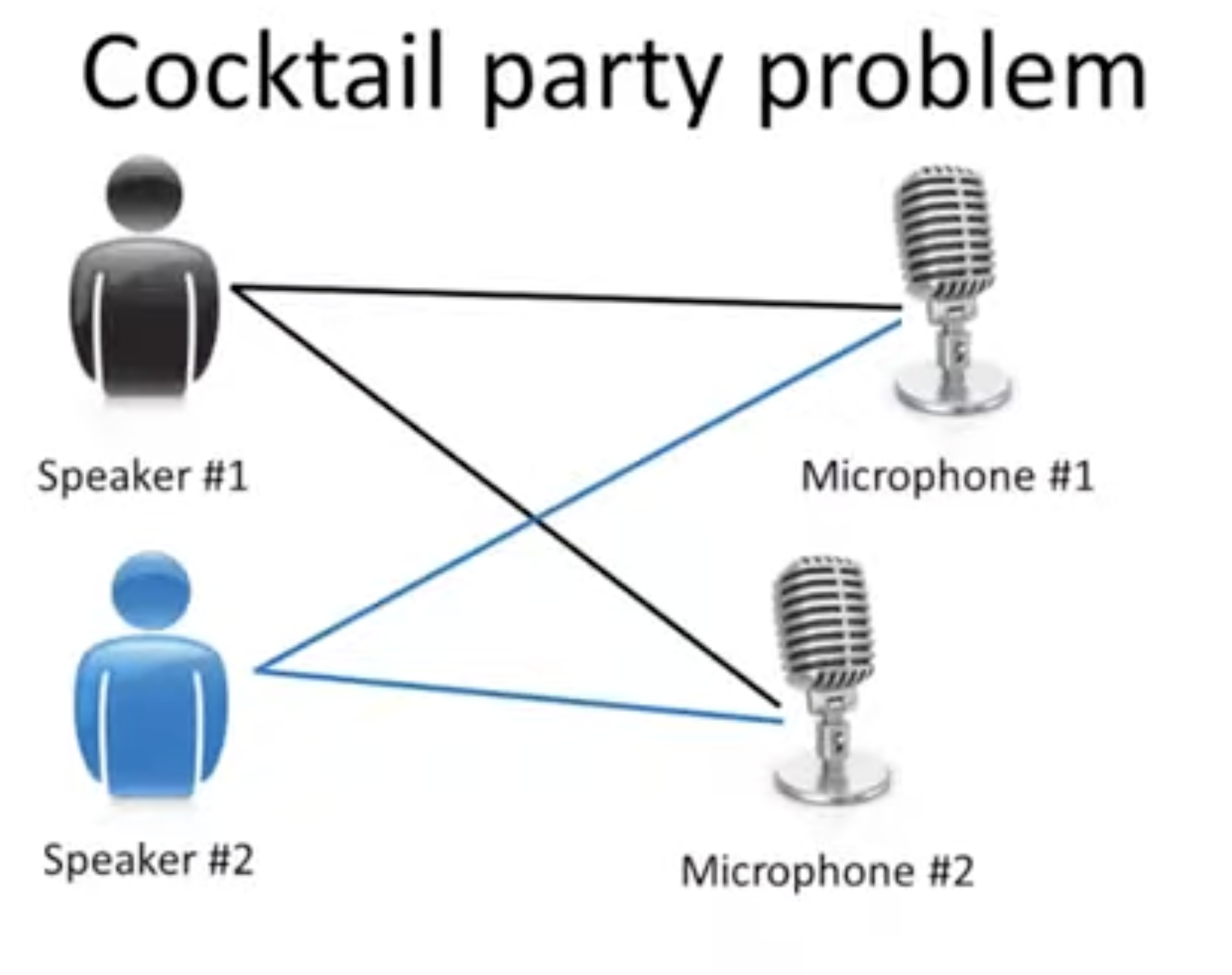
- 칵테일 파티에서 두 명이 동시에 말하고 있다고 상상해보자.
- 이때 각 마이크에는 화자의 음성이 거리에 따라서 크거나 작게, 그리고 동시에 녹음이 되고 있을 것이다.
- 그렇다면 이때 수집된 음성 데이터에서 각 화자의 음성만을 어떻게 분류할 수 있을까?
- 보통 이 경우, 화자1의 음성만 따로 녹음한 음성데이터를 학습하여 위 음성데이터에서 화자1의 음성만 추출할 수 있다.
- input(화자1_음성데이터, 복합_음성데이터) -> 추출(분류)모델 -> output(복합_화자1_음성데이터)
- 이와 같은 모델은 전형적인 "Unsupervised Learning" 모델에 해당한다.
다음 예시 중 unsupervised learning alg.은 어떤 것들이 해당할까?

정답은 2번과 3번이다.
- 1번은 레이블된(스팸인지 아닌지) 데이터를 가지고 학습하기 때문에, supervised learning에 해당한다.
- 2번은 뉴스 기사에서 유사한 내용을 갖는 뉴스들끼리 그룹화를 하는 것이기 때문에 unsupervised learning에 해당한다.
- 3번은 고객 데이터를 가지고 그룹핑하는 것이기 때문에 unsupervised learning에 해당한다.
- 4번은 환자들의 당뇨 유무라는 정답값을 갖는 데이터로 학습하기 때문에 supervised learning에 해당한다.

