https://www.youtube.com/watch?v=_SbZYGeVcVM&list=PLiPvV5TNogxIS4bHQVW4pMkj4CHA8COdX&index=2
우선 supervised learing에 대해서 다시 상기해보자.
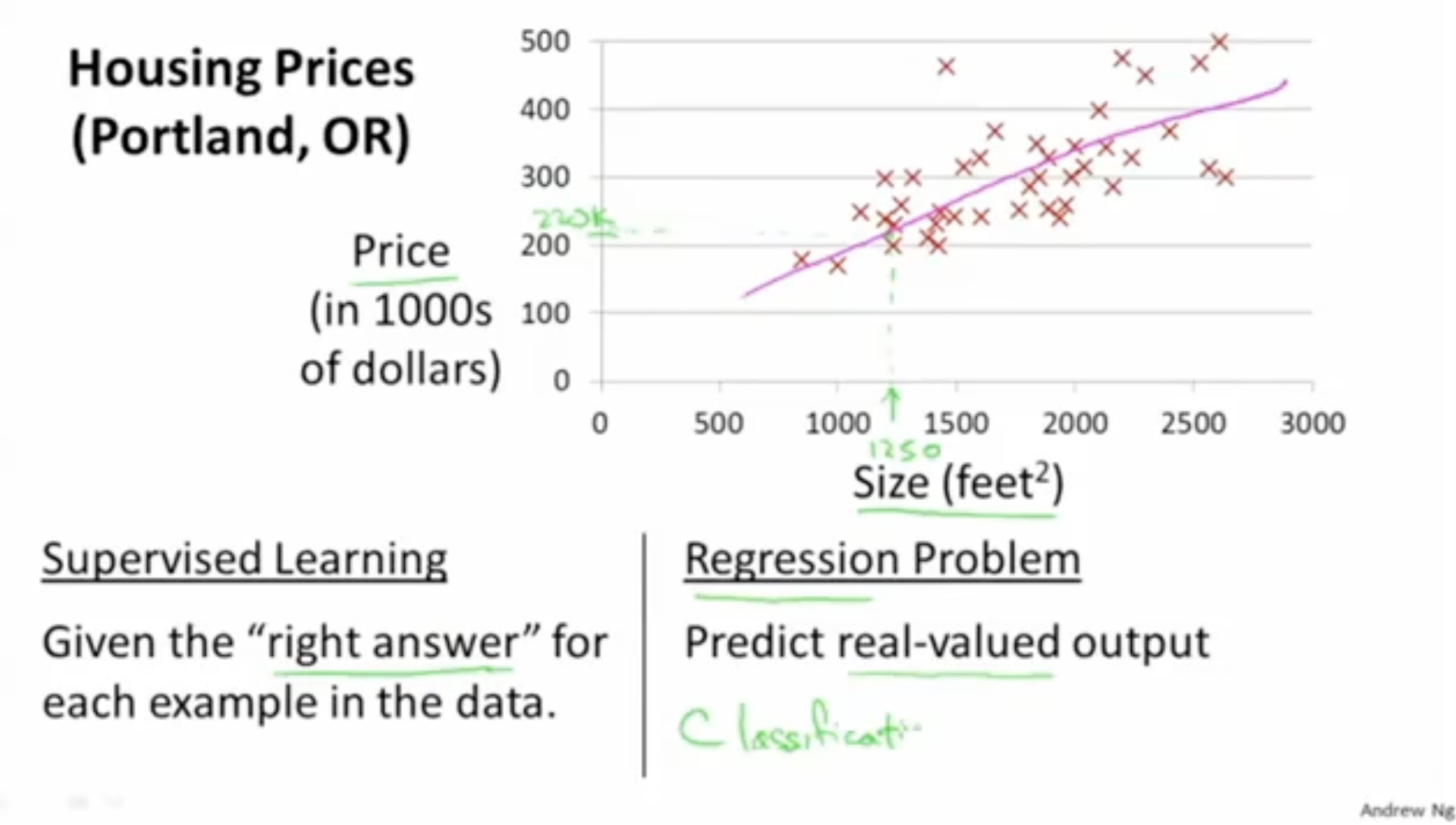
아래 그림을 예시로 들어, size에 따른 집 price 데이터가 주어졌다고 가정해보자. 이 경우, 우리는 1250이라는 size가 입력됐을 때, 해당 집 price가 몇일지 예측하고 싶어한다. 그리고 이전 데이터들을 통해서 linear한 함수를 만들어 놨기 때문에 이 함수에 1250을 입력함으로써 우리는 집 price가 220이라는 것을 예측할 수 있다.
따라서, 이 경우 x에 대한 y 값이 주어졌기 때문에 (정답값이 주어졌기 때문에) supervised learning이며, 특히 (linear) regression(회귀) 문제에 해당함을 알 수 있다.
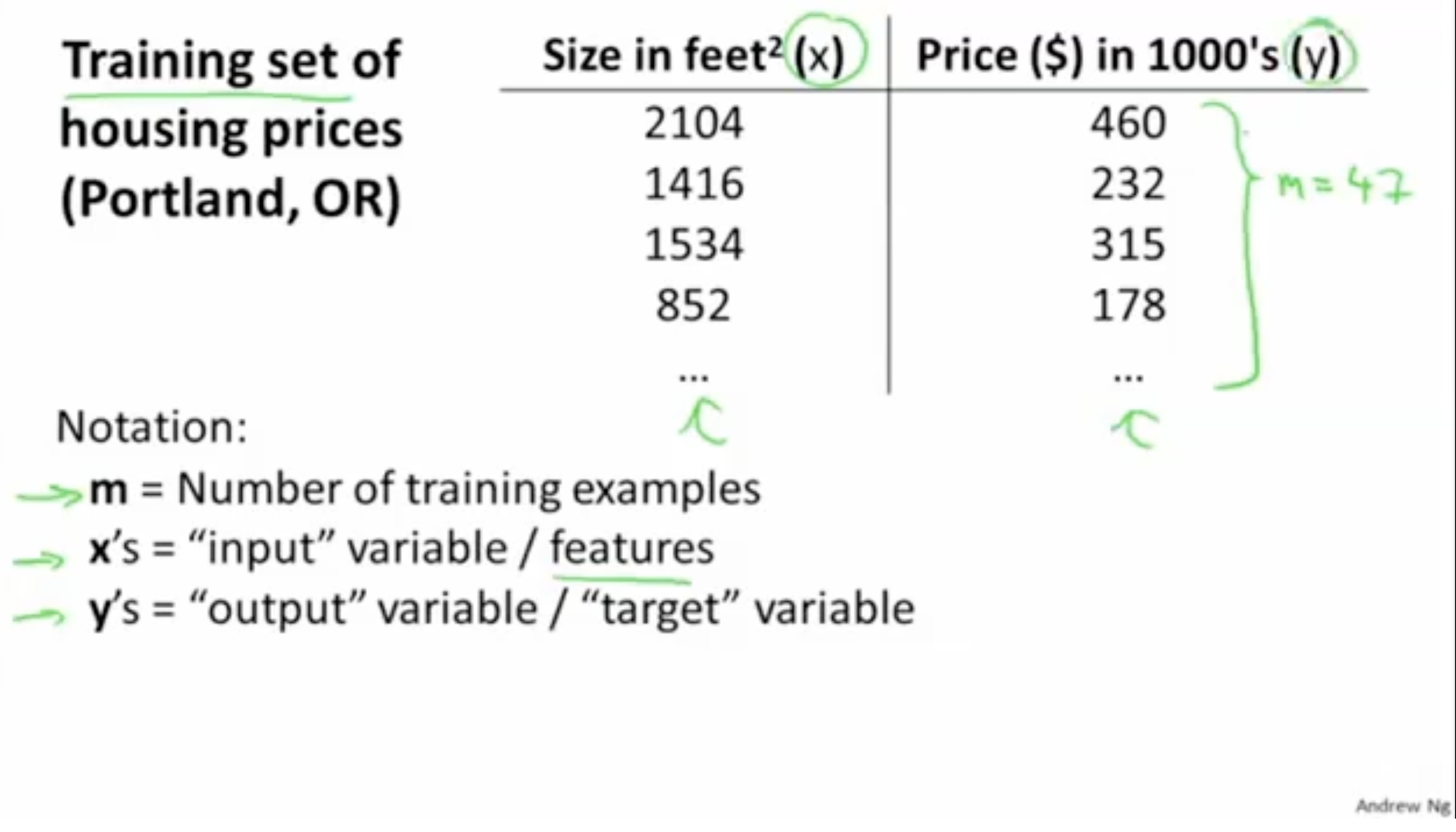
다음은 데이터에 대한 정의이다.
- m : 트레이닝 데이터셋의 수.
- x: 입력값(feature)
- y: 결과값(target)
- : 번째 학습 데이터셋

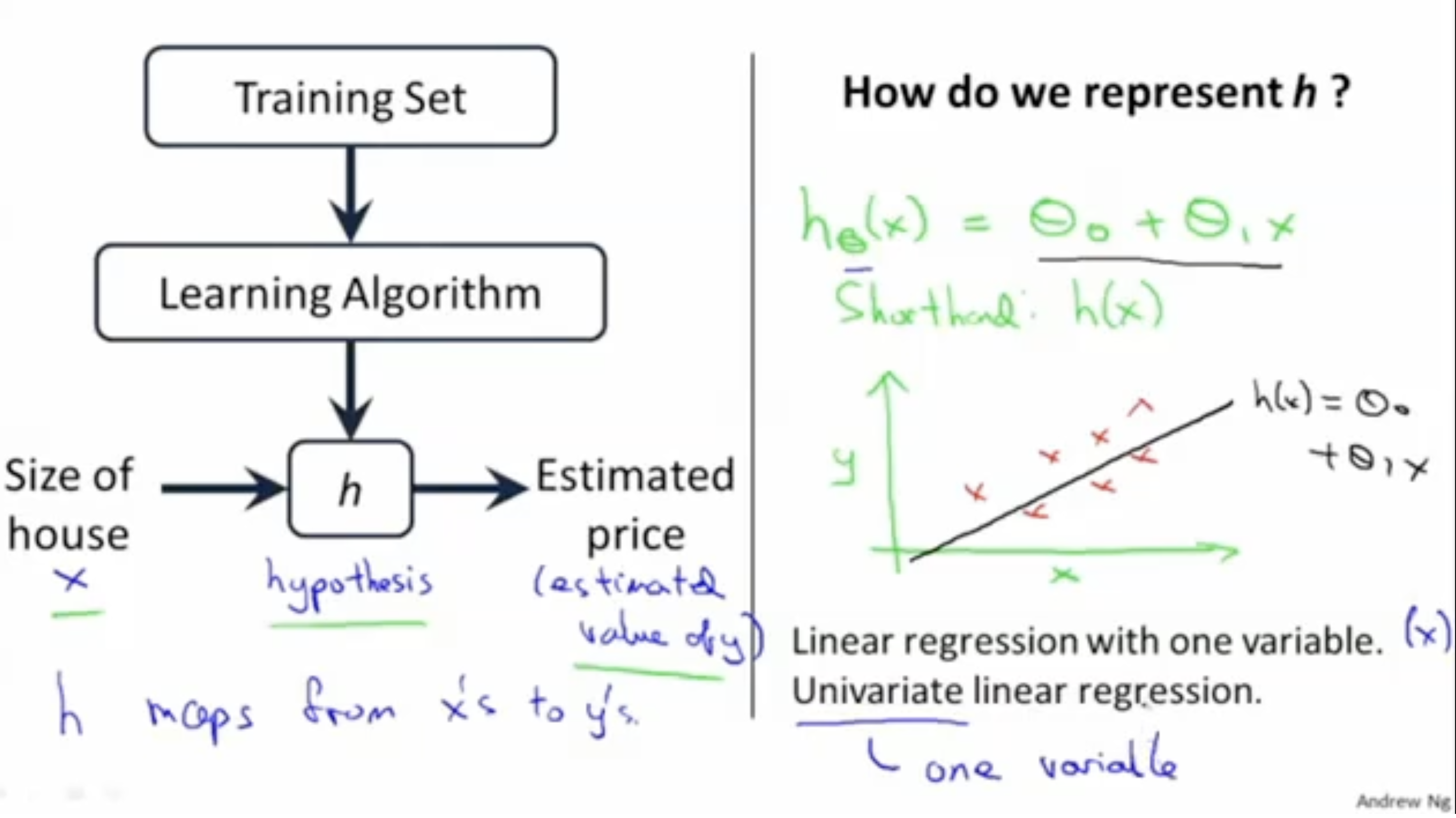
linear regression의 과정은 아래 그림과 같다. 아래의 경우는 단일 변수 linear regression이다.
1. 학습 데이터를 가지고 learning alg.에 적용. (모델 학습)
2. 학습을 마친 후 hypothesis 생성.
3. input(입력) -> h -> output(예측)
그리고 를 통해 값을 구하는 과정은 다음과 같다.
- 로 함수를 정의한다. (간단히 라 하자.)
- 그리고 선형 함수 를 통해서 입력값 에 대한 결과값을 예측한다.
하지만 아래 그림과 같이, 의 값에 따라서 함수의 모양은 다양하게 나올 수 있다.
따라서 학습데이터를 가지고 잘 fit하는 를 찾아야 한다.

어떻게 최적의 를 찾을 수 있을까? 방법은 다음과 같다.
" "
- 위 함수의 의미는 모든 학습 데이터셋에 대해서 의 값이 최소가 되도록 하는 즉, 예측값과 실제값 간의 차이가 최소가 되도록하는 를 찾으라는 의미이다.
- 위에서 을 나눠준 이유는 총 데이터셋이 개이기 때문에 평균값을 기준으로 삼기위해서이다.
또한, (예측값 - 실제값)에 제곱을 해주었는데, 이 경우 이는 "Squared Error Function"에 해당한다.- 그리고 위 수식을 간단하게 로 나타낼 수 있으며,
이를 "Cost Function"이라고 부른다.- 따라서 최적의 를 찾는 수식은 다음과 같이 정의할 수 있다.
" "

그렇다면, 실제 값을 대입하면서 예시를 살펴보자.
아래 그림은 을 가정하고, 에 대해서만 cost function을 구하는 예시이다.
일 때, cost function인 는 다음과 같다.
그리고 이 값을 그래프에 표시하면 우측 그림과 같다.
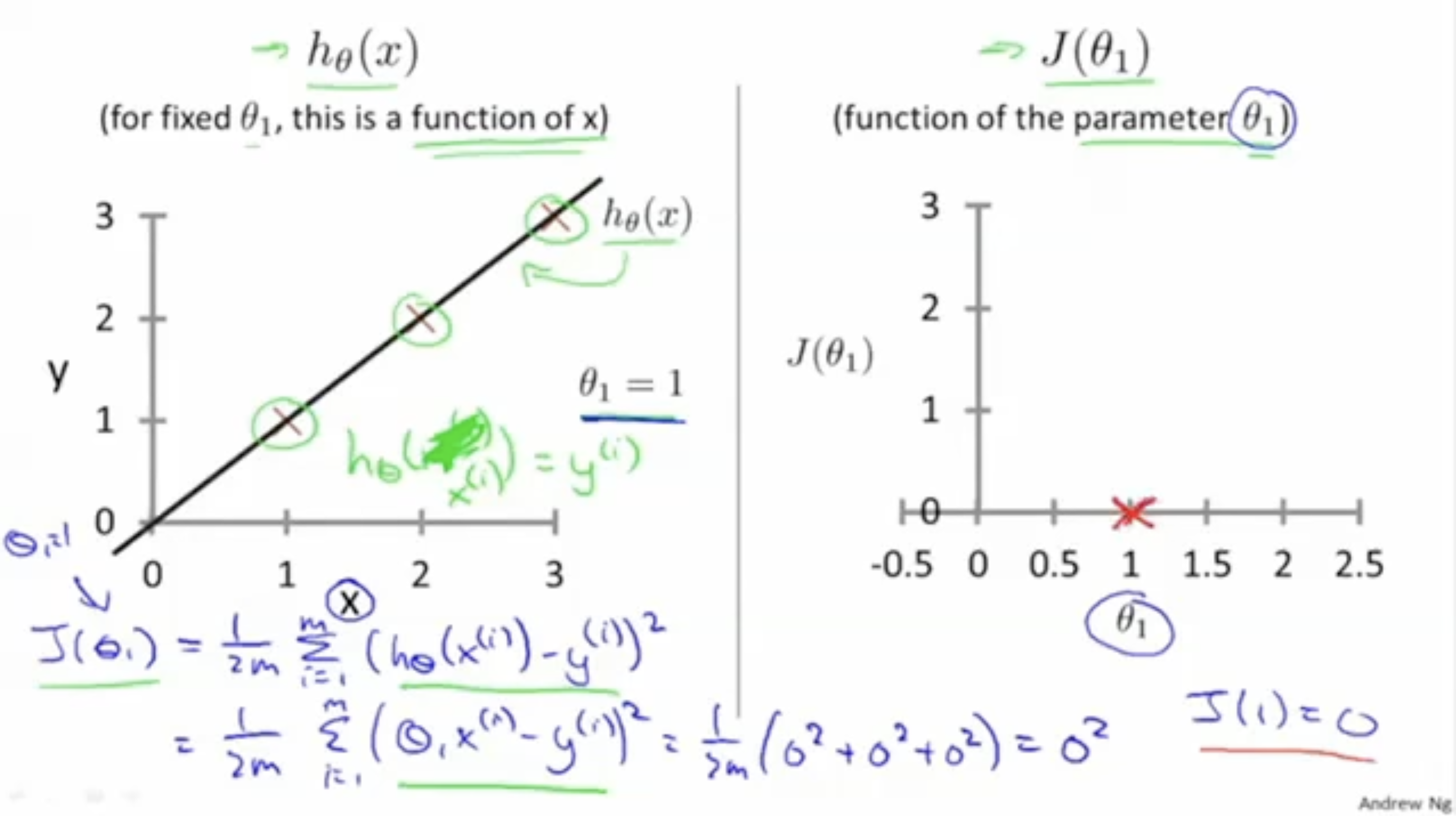
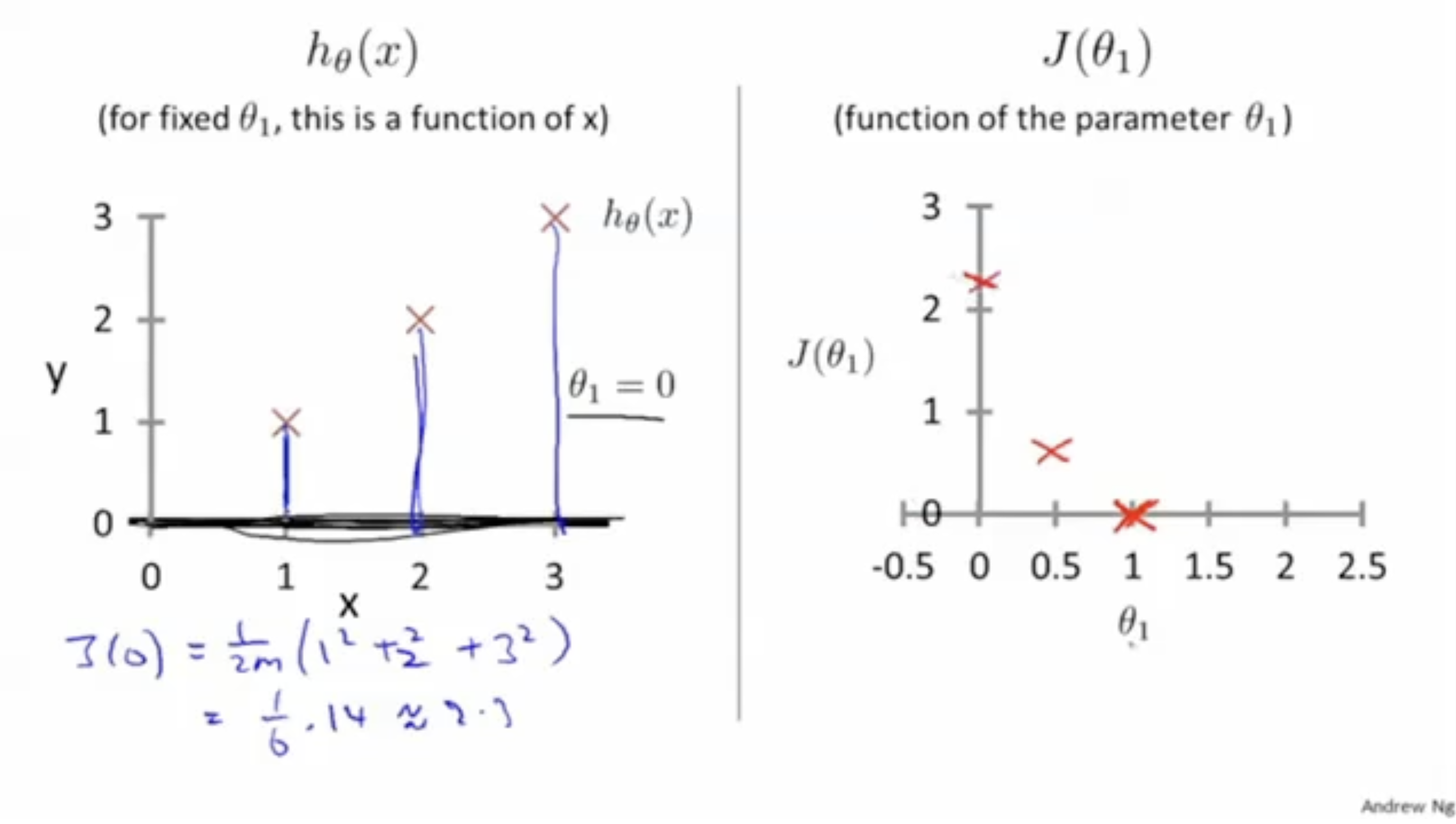
그렇다면 만약 이면 어떨까?
이 경우, 예측값과 실제값은 좀더 멀어지게 되며,
cost function 값은 이 나오고, 표시하면 우측 그림과 같을 것이다.
기존의 보다 cost function 값이 더 커진 것을 확인할 수 있다.
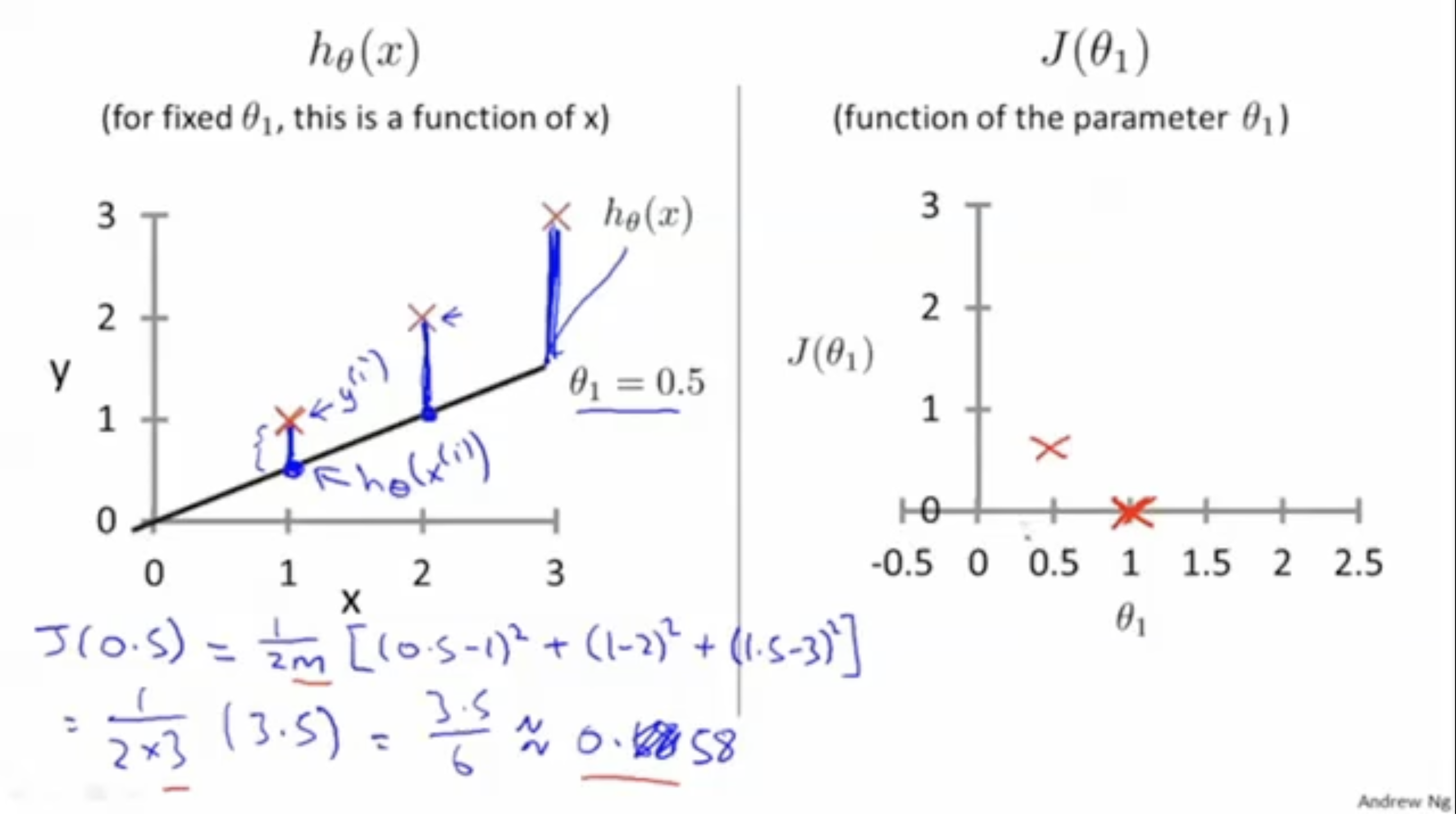
다음은 에 대한 그림이다. 마찬가지로 이전보다 cost function값이 더 커졌다.
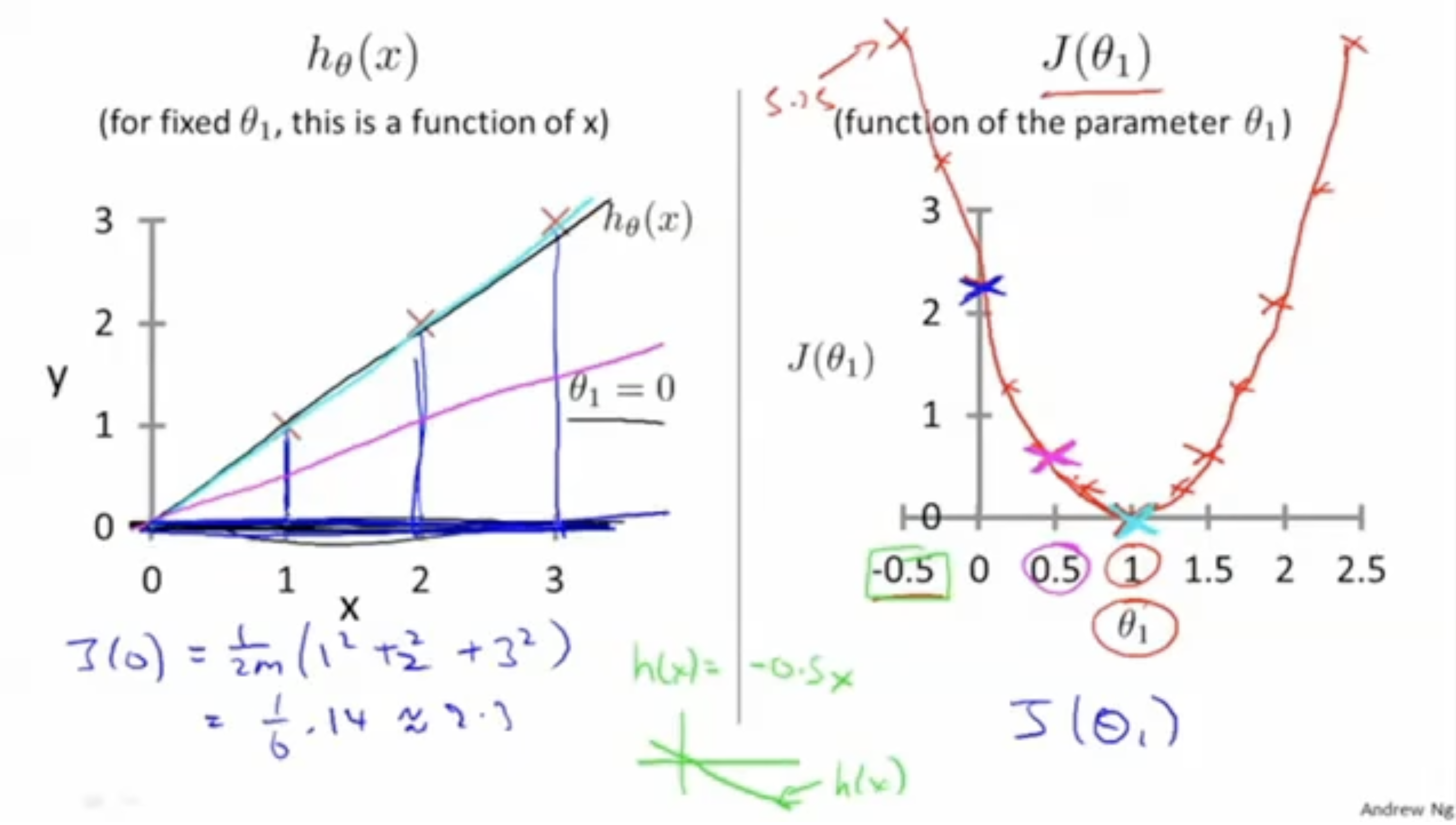
에 대해서 cost function 의 값을 그래프로 표현하면 아래 그림과 같이 나올 것이다.
즉, 가 최적의 의 값()에 가까워질수록 cost function 의 값은 에 가까워질 것이다.
위와 마찬가지로, 뿐만 아니라 도 고려했을 때, 최적의 와 에 대한 cost function 에 대한 그래프는 아래와 같이 나올 것이다.
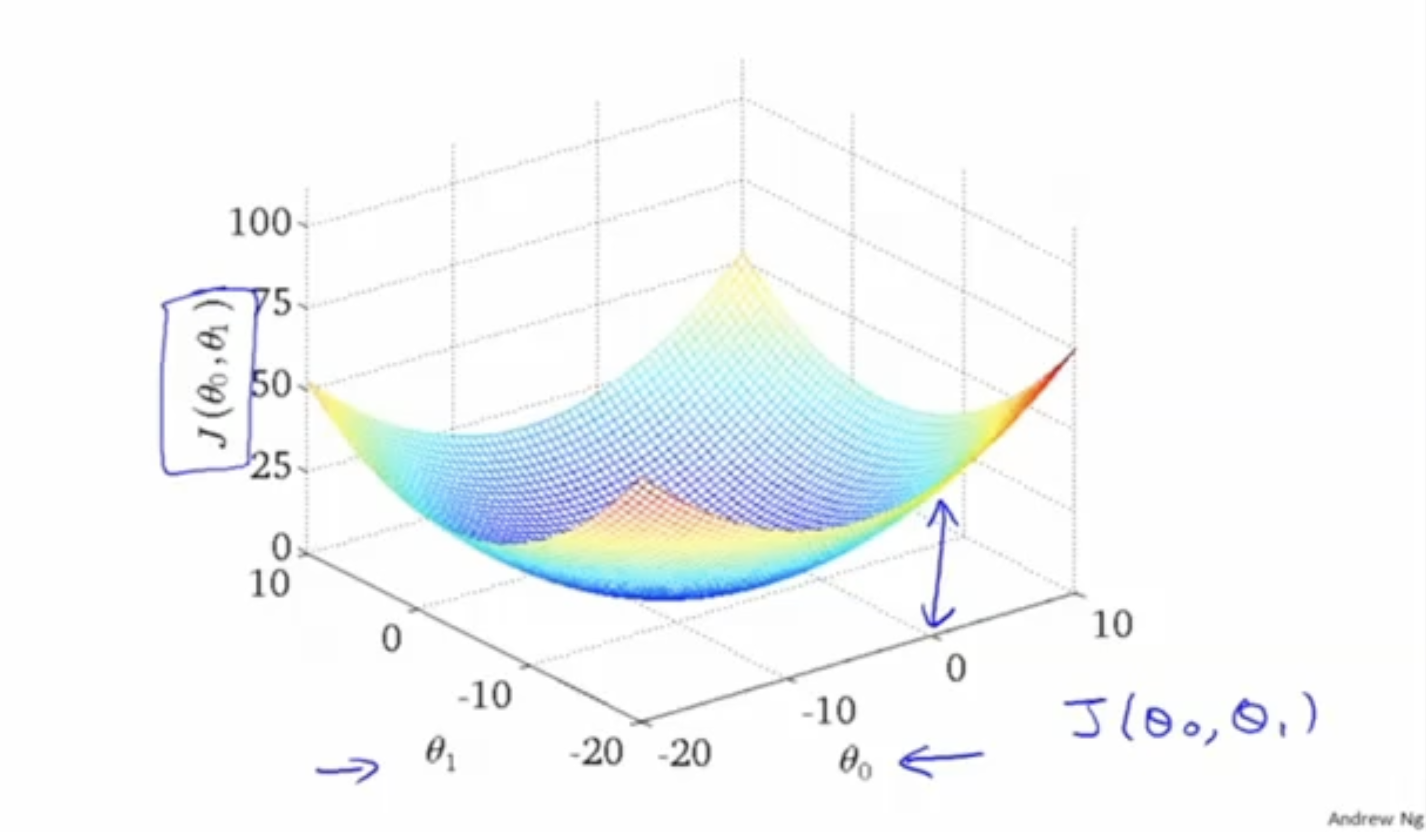
이를 2차원 그래프로 표현해보면, 아래 그림과 같다.
아래 그림에서 의 값은 거의 최소에 가깝고,
따라서 는 실제값과 예측값의 차이가 최적의 함수라고 판단할 수 있다.
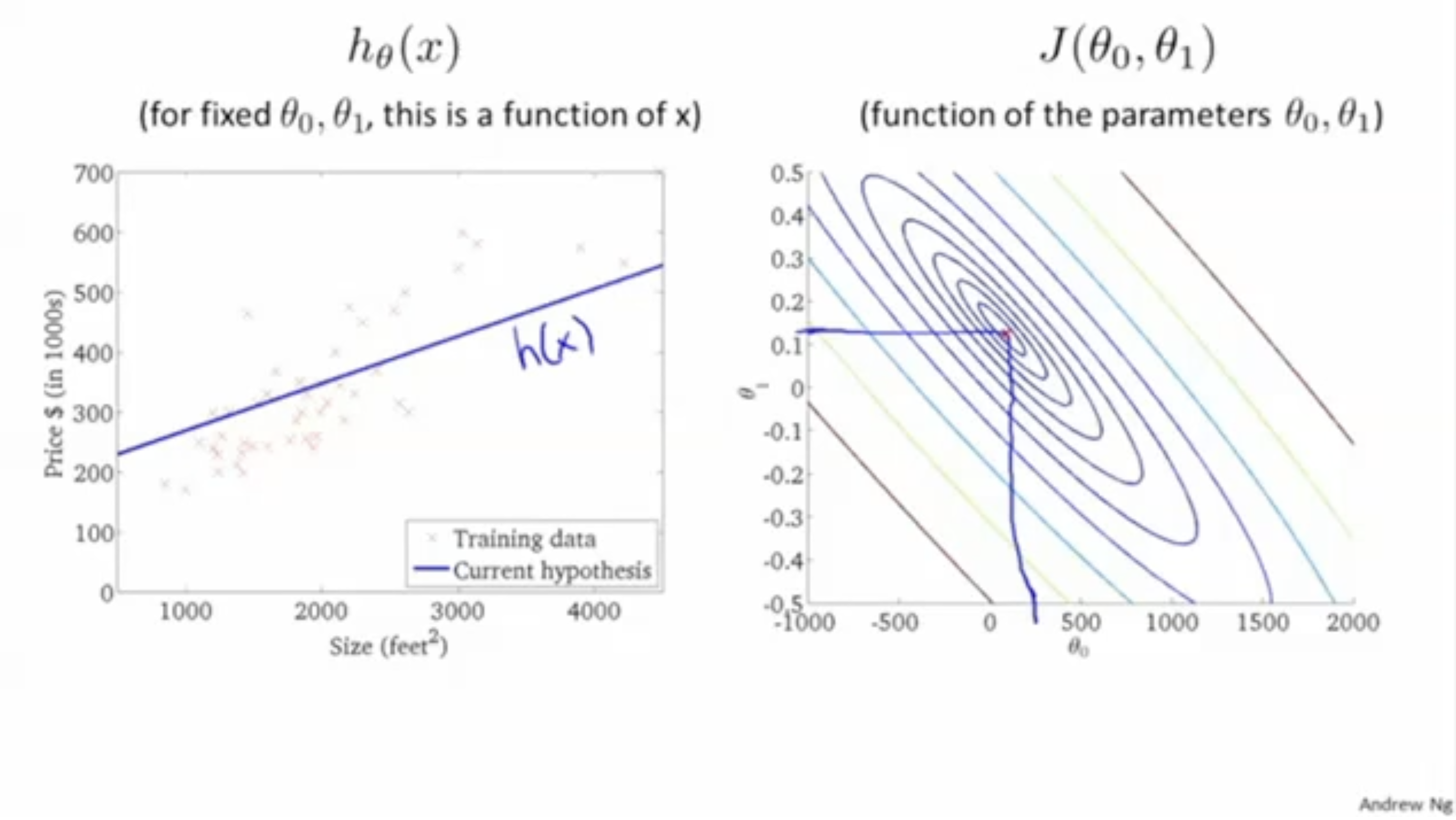
cost function 최솟값을 찾는 과정(최적의 와 을 찾는 과정)은 아래 그림과 같다.
처음 빨간색 부분에서 시작한다고 했을 때, 점점 cost function이 값이 작아지도록 내려간다.
그렇게 내려가다보면 local optima에 도착한다.
마찬가지로 다른 local optima에 도착할 수도 있다.
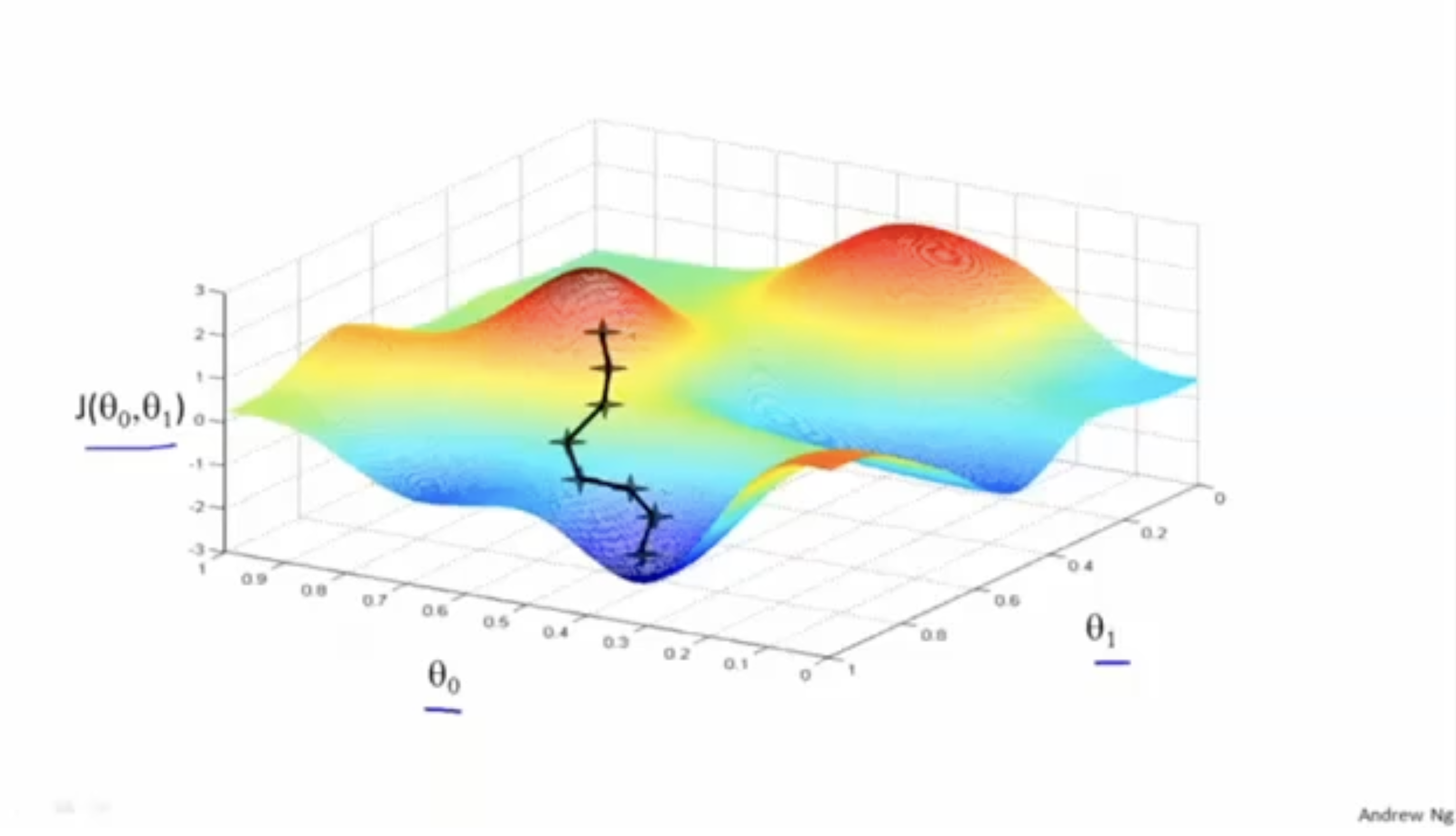
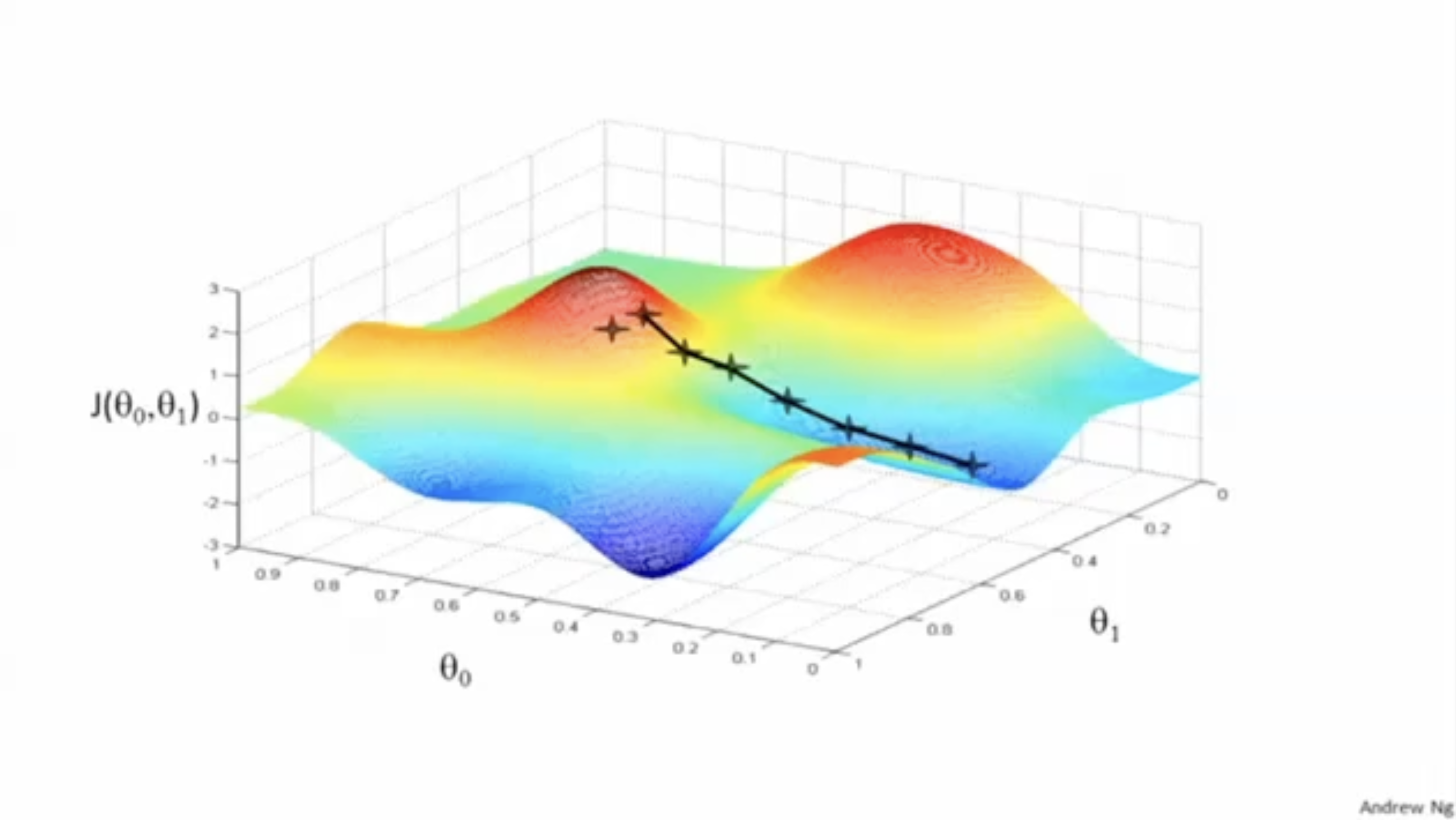
이처럼 local optima를 향해 내려가는 방법을 "Gradient Descent Algorithm"이라고 한다.
그리고 Gradient Descent Alg.의 개요는 아래 그림과 같다.
(for and )
- : learning rate.
- 위 과정을 local optima에 수렴할 때까지 계속 반복한다.
- 대신 주의할 점이 있는데, 이때 각 의 값은 동시에(simultaneous하게) 갱신되어야 한다.
- 결론적으로, 위 수식을 반복하다보면 local optima에 도달할 수 있다.

그렇다면 Gradient Descent Alg.의 수식이 왜 와 같이 나오는지 이유를 설명해보자.
이에 대한 설명은 아래 그림과 같다.
우선, 으로 가정하고 에 대해서만 생각해보자. 수식은 다음과 같다.
- 만약 위 그래프처럼 그래프의 기울기 가 양의 값을 갖는다면, 은 왼쪽으로 가야 한다. 따라서, 처럼 값을 감소시켜야 한다.
- 반대로 아래 그래프처럼 그래프의 기울기 가 음의 값을 갖는다면, 은 오른쪽으로 가야 한다. 따라서, 이 되어, 은 값이 증가하는 형태가 된다.
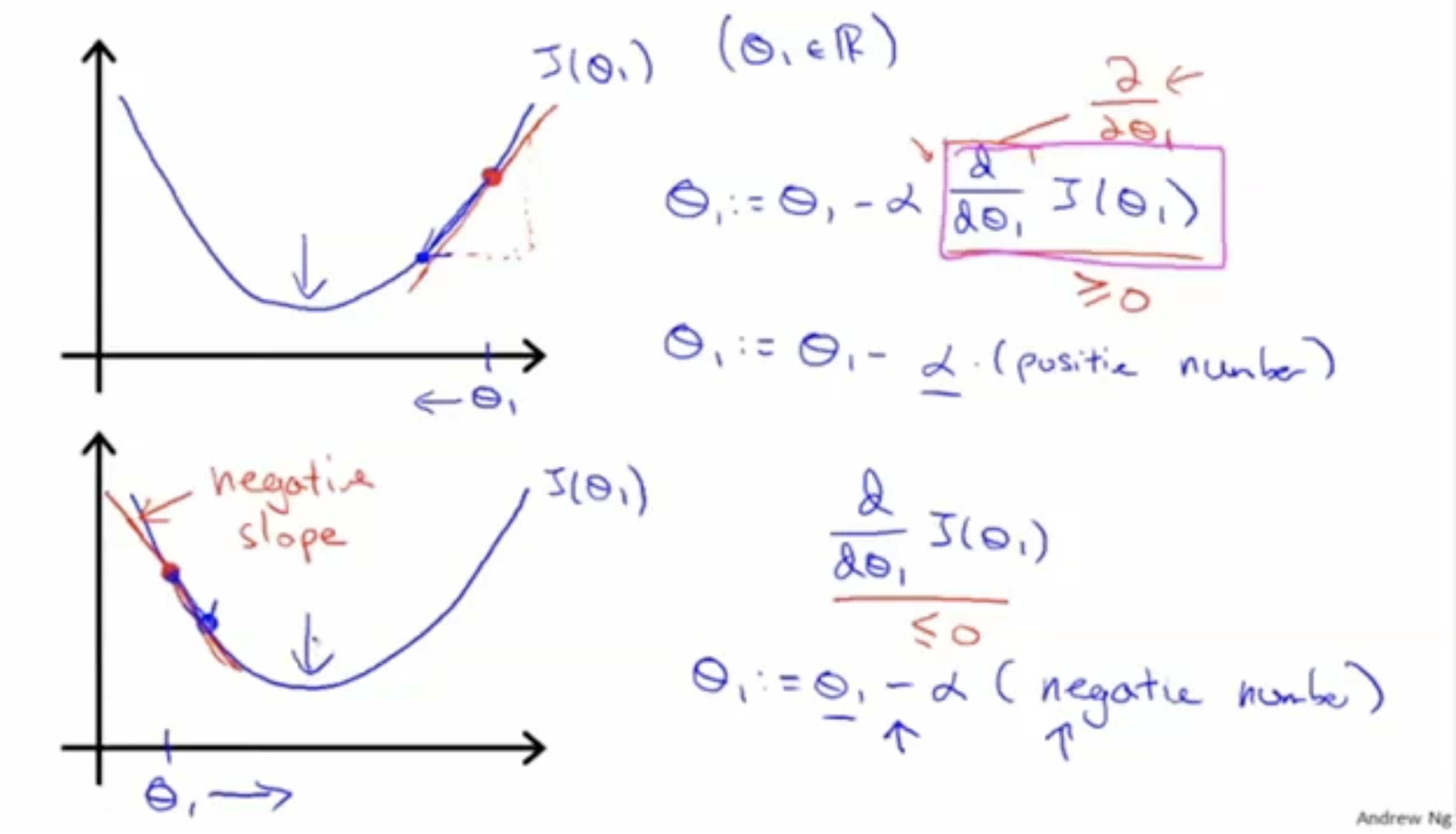
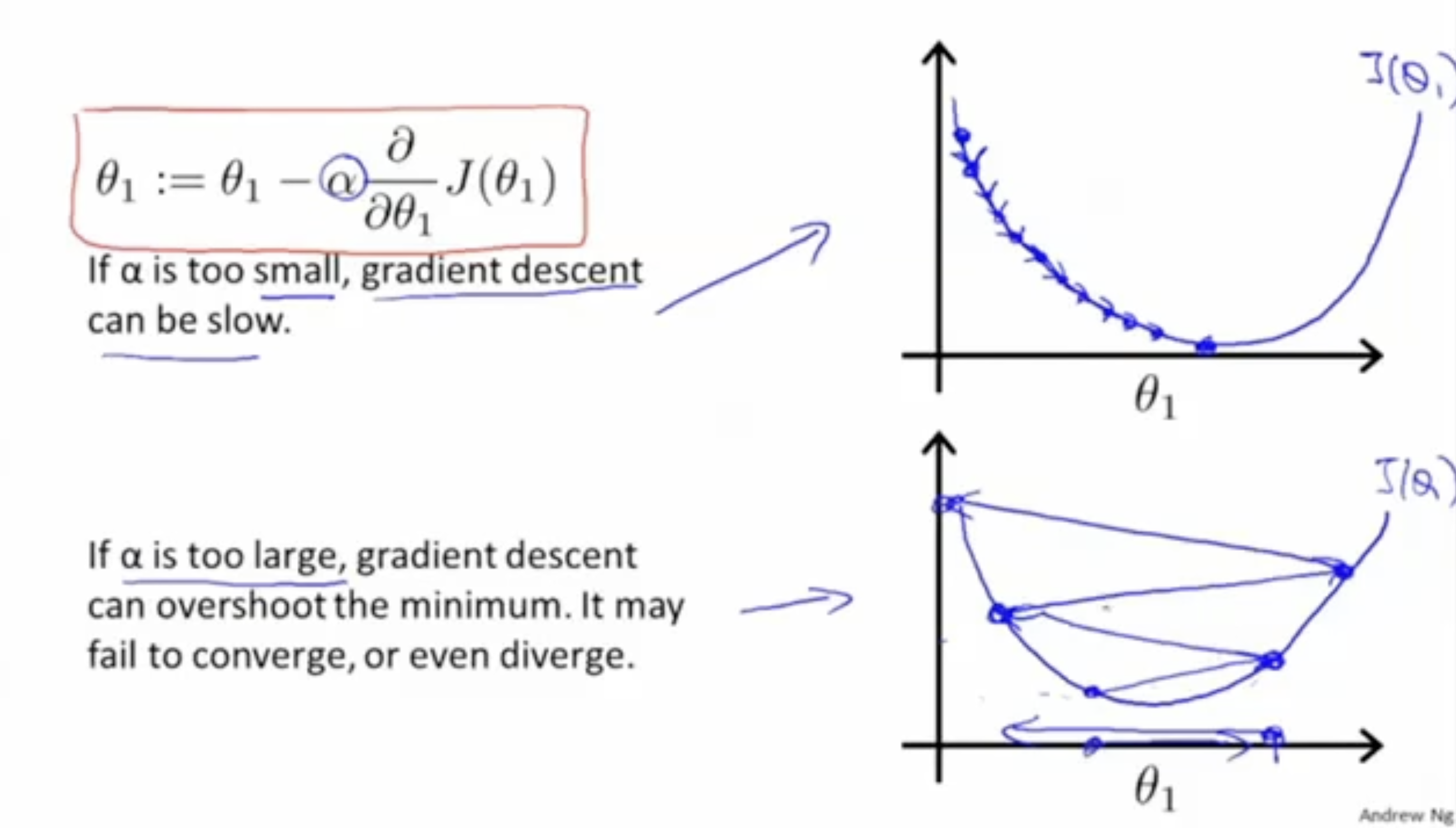
그리고 (learning rate)을 통해 값을 얼마나 증가/감소 시킬지 결정한다.
- 만약 learning rate가 너무 작다면, local optima까지 도달하는 데 시간이 매우 오래 걸릴 것이고,
- 반대로 learning rate가 너무 크다면, local optima에 도달하지 못하고 값이 분산될 것이다.
- 따라서 적절한 learning rate 값을 부여하는 것이 중요하다.
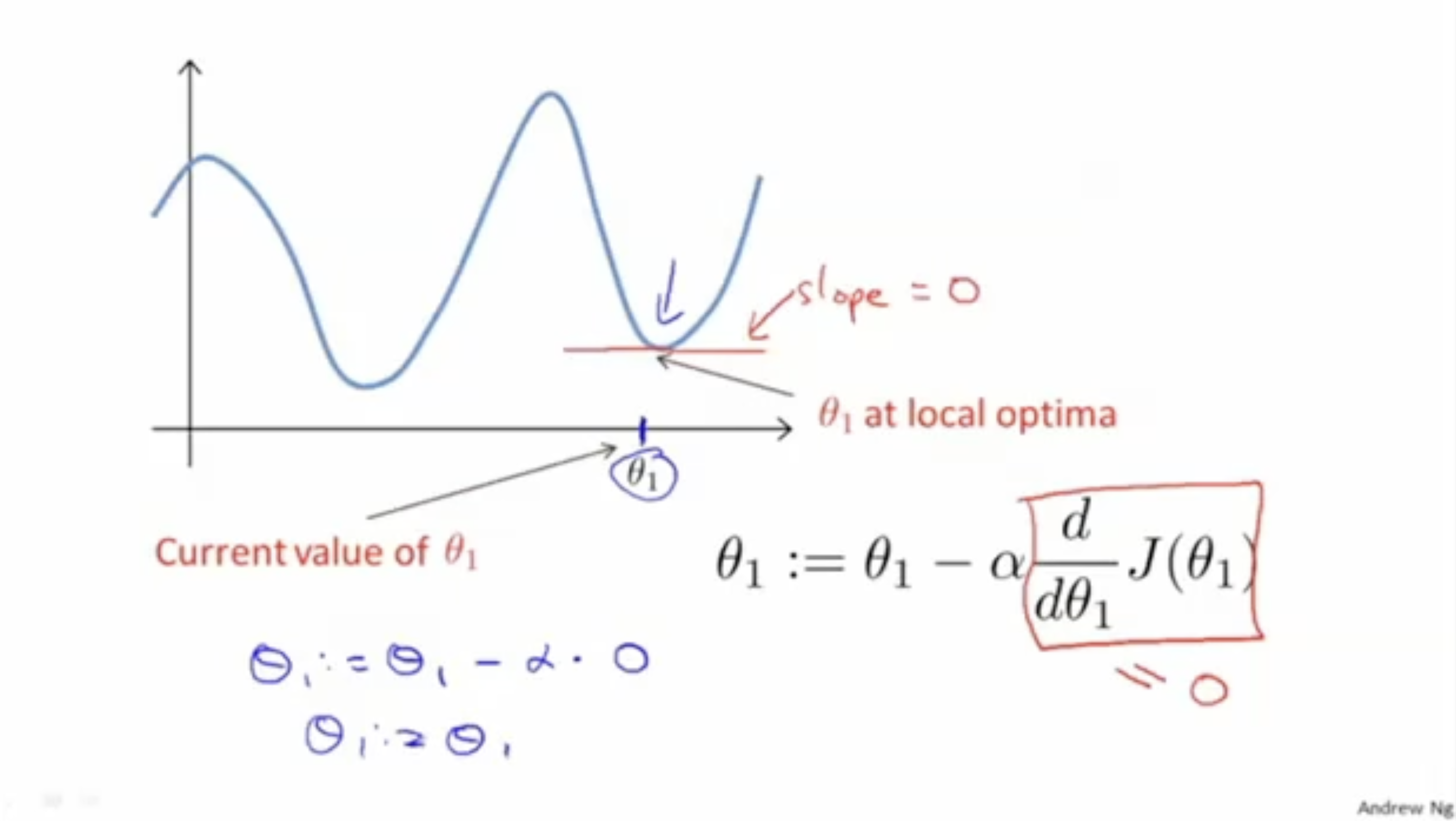
그렇다면, 어떻게 local optima에 도착했다는 것을 알 수 있을까?
답은 아래 그림과 같다.
- local optima에서 그래프의 기울기는 0일 것이다. 따라서, 다음 스텝으로 이동하지 않을 것이다.
- 이렇게 되면 의 값에는 변화가 없을 것이고, 따라서 local optima에 도달했음을 알 수 있다.
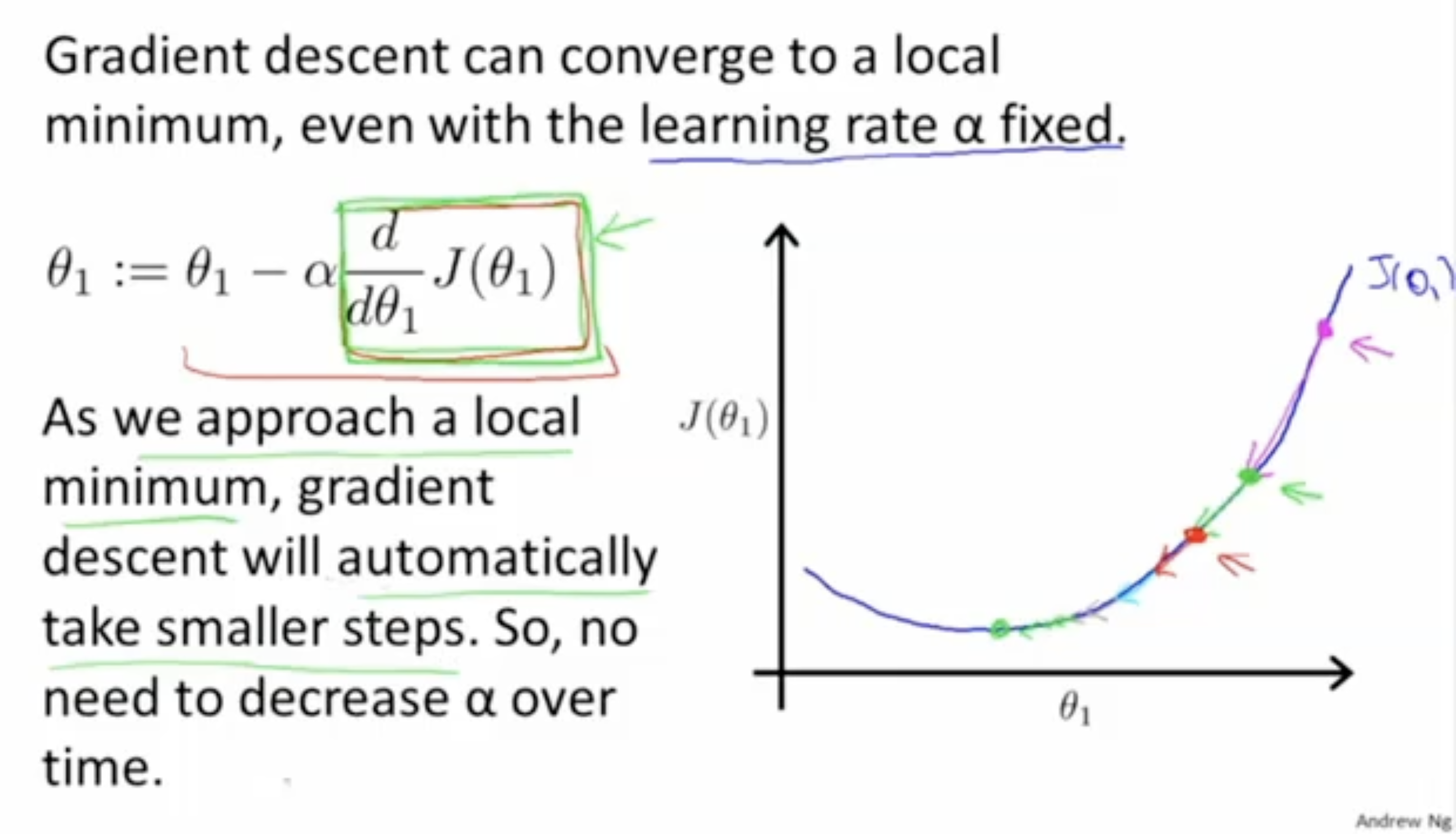
다음으로, learning rate 는 왜 고정값으로 적용해도 문제가 없는지에 대한 설명은 아래와 같다.
- local optima에 가까워질수록 그래프의 기울기 값이 점점 0에 수렴한다.
- 따라서, 자동적으로 값의 변화는 줄어들 것이다.
그렇다면 그래프의 기울기는 어떻게 구할 수 있을까?
이 경우, 아래 그림처럼 편미분 공식을 통해 구하면 된다.
- 우선 은 과 같다.
- 그리고 은 로 풀어서 작성할 수 있다.
- 그러면 이제 에 대해서 편미분만 하면 된다.
- 먼저, 에 대해 편미분을 하면, 이 되고,
이는 과 같다.- 다음으로 에 대해 편미분을 하면, 가 되고,
이는 와 같다.
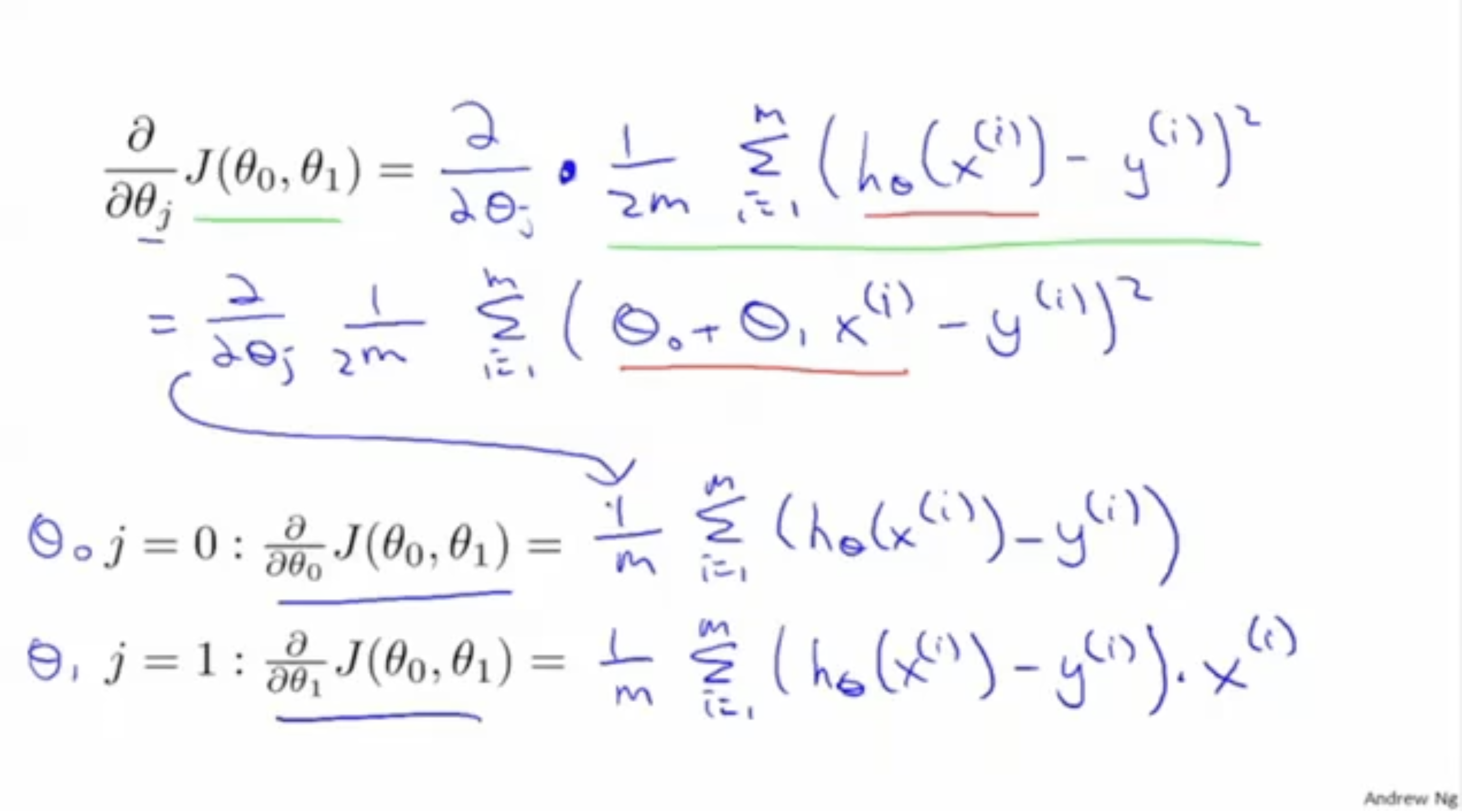
따라서 위에서 구한 편미분 식으로 각 의 값을 구하면 된다.

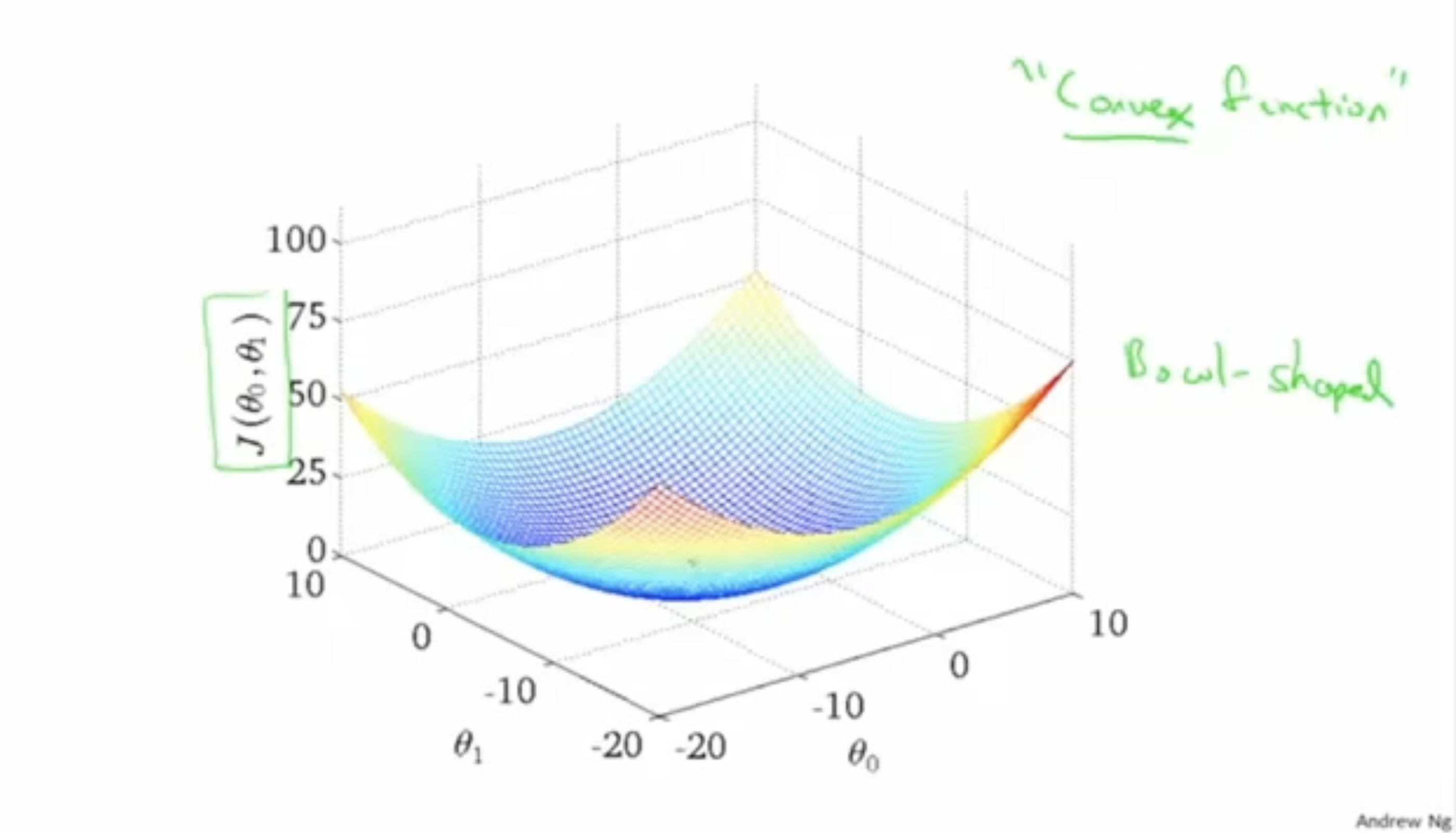
아래 그림처럼 local optima는 여러 개가 존재하기 보다는,
global optima로서 하나의 optima가 존재할 것이다.
이러한 경우를 "Convex function" 혹은 "Bowl-shpaed function"이라고 부른다.
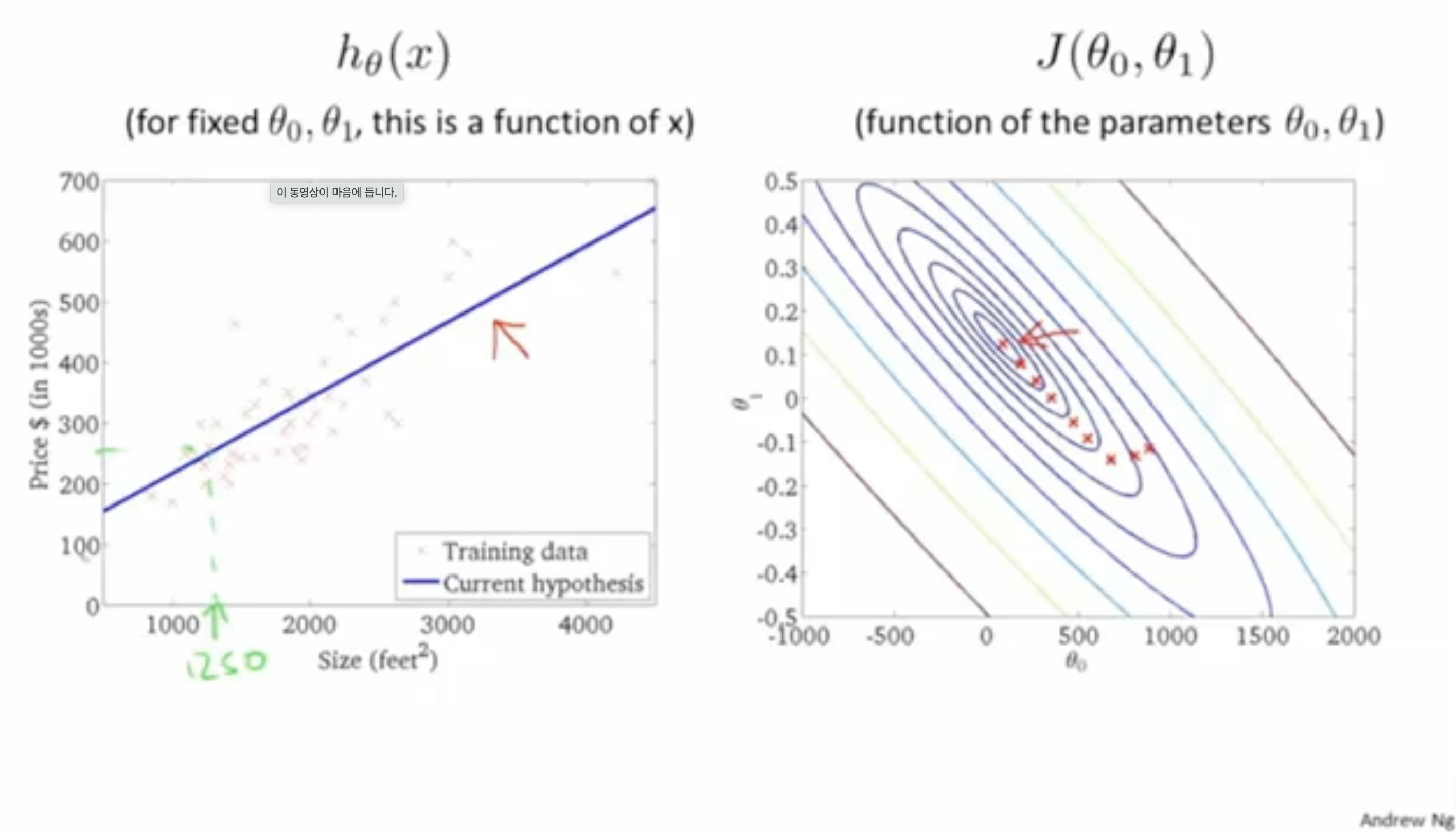
따라서, 아래 그림의 경우처럼 최적의 parameter 와 을 구했다면(local optima를 찾았다면), 이에 대한 최적의 를 얻을 수 있다.
- 따라서 최적의 에 1250을 입력값으로 주면, 대충 250이라는 예측값을 구할 수 있다.
사실 위 과정들은 정확히 말하면 "Batch" Gradient Descent에 해당된다.
Batch의 의미는 gradient descent를 할 때 전체 학습데이터셋을 사용한다는 의미이다.

그렇다면 만약 변수가 하나가 아니라 여러 개면 어떻게 구할 수 있을까? 또, gradient descent와 같은 반복 과정을 거치지 않고 어떻게 최적의 파라미터를 찾을 수 있을까?
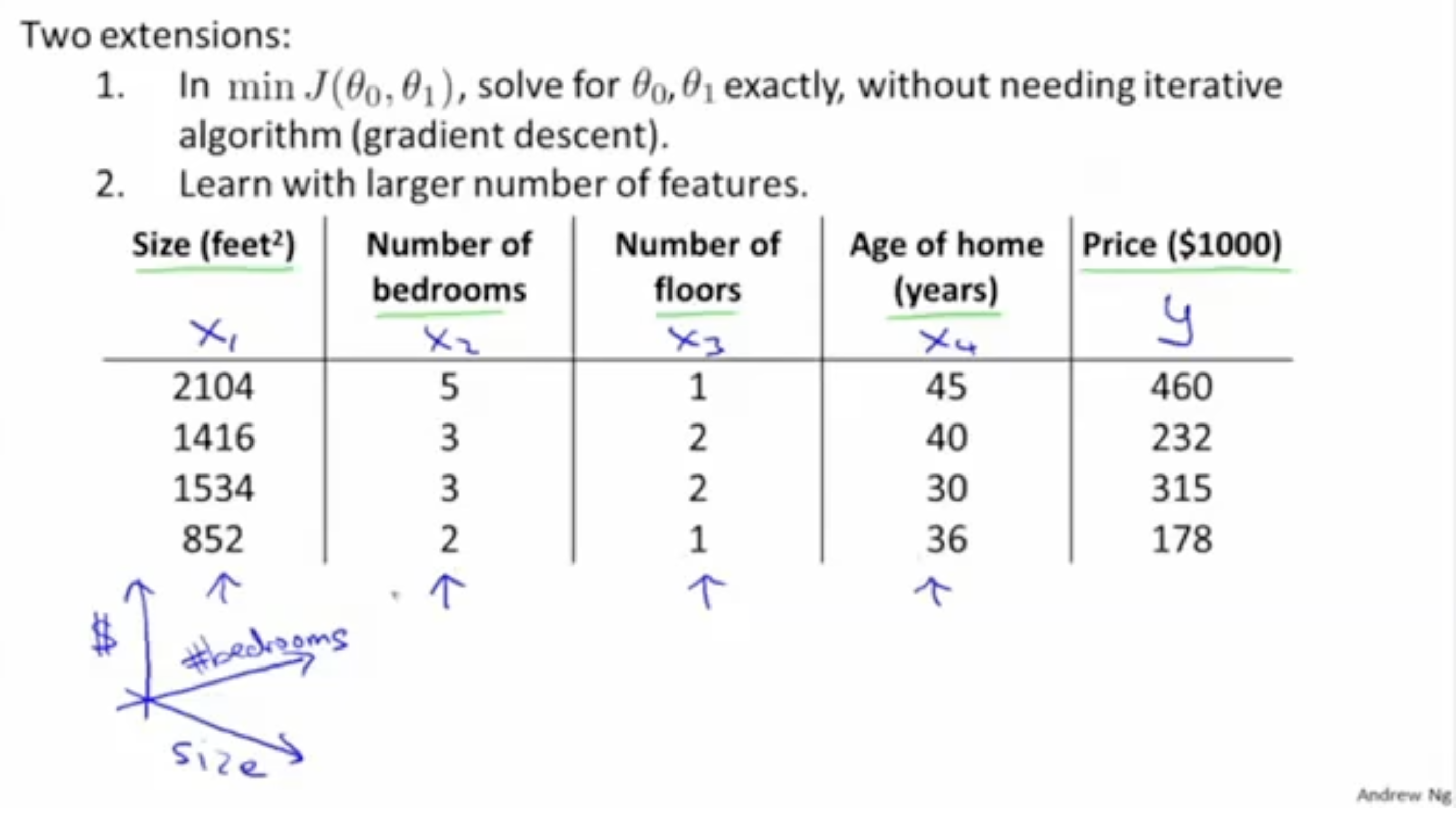
이를 위해 필요한 게 "선형 대수" 개념이다. 선형대수를 통해서 행렬과 벡터를 표현할 수 있기 때문에 고차원에 대해서 처리가 가능해진다.

다음 강의에서는 선형 대수에 대해서 다룰 예정이다.
- 행렬과 벡터가 무엇인지
- 행렬과 벡터에 대한 연산은 어떻게 이뤄지는지
- 역행렬과 전치행렬이 무엇인지

