https://www.youtube.com/watch?v=ViTUqw8kXPQ&list=PLiPvV5TNogxIS4bHQVW4pMkj4CHA8COdX&index=4
이전에는 single variable에 대한 linear regression에 대해서만 알아보았다. 그렇다면 muti-variable에 대해서는 어떻게 적용할 수 있을까.
아래 그림과 같이 총 4개의 feature 종류와 하나의 y값을 갖는 데이터셋을 생각해보자.
- : 데이터셋의 총 개수. (위 예시에서는 47개)
- : feature의 종류. (위 예시에서는 4개)
- : 번째 feature 벡터.
- : 번째 feature 벡터 중 번째 feature.

위 예시에서는 feature가 4개이므로 가설 함수 역시 그에 맞춰서 작성해야 한다.
즉, 처럼 표시해야 한다.
- parameter의 종류 수를 feature의 종류 수와 맞춰 주었다.
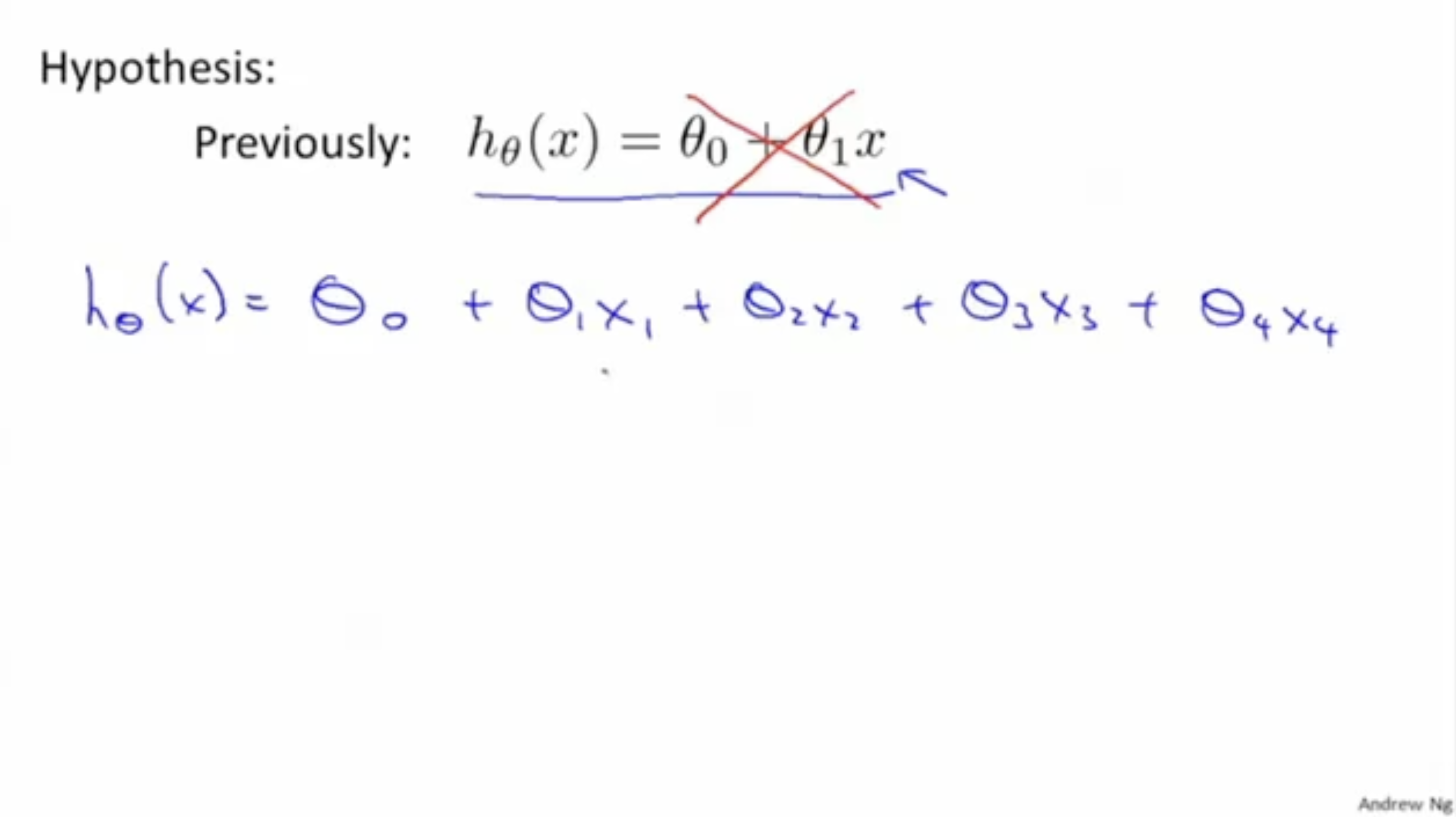
그리고 에 대해서는 왜 feature를 부여하지 않는지에 의문점이 들 수 있는데,
편의를 위해서 이라고 정의하기 때문이다.
아래 그림처럼 feature 벡터 와 parameter 벡터 를 정의하여 multi-variable에 대한 linear regression을 진행할 수 있다.
- feature 벡터 : (벡터 는 차원)
여기서 차원이 인 이유는 feature들의 개수 에 에 대한 처리로 +1이 된 것이다.- parameter 벡터 : (벡터 는 차원)
- 그리고 에 대해서 벡터로 간단하게 표시하여,
처럼 나타낼 수 있다.
여기서 에 대해 Transpose를 적용하여야 수식을 행렬로 표현할 수가 있다.

그렇다면 multipe-features의 cost function에 대한 gradient descent는 어떻게 할 수 있을까?
다음 그림을 살펴보자.
- 이전에 봤던 single-feature cost function과 크게 다를 게 없다. 차이가 있다면 벡터로 표현이 된다는 점이다.
- 마찬가지로 cost function을 보다는 편하게 로 작성한다.
- 그리고 모든 parameter 에 대해 동시에 gradient descent를 적용한다.

구체적으로 살펴보면 아래 그림과 같다.
- 좌측 그림은 이전에 했던 single-feature에 대한 gradient descent 예시이다.
- 우측 그림은 multiple-features에 대한 gradient descent 예시이다.
- 크게 차이점은 없다. 다만, multiple-features에서는 의 종류가 많다는 차이만 존재한다.
- 그림의 우측 아래 부분은 번째 학습 데이터셋에서, 모든 parameter 에 대해 gradient descent를 적용하는 과정을 하나씩 나열한 것이다.

그렇다면 feature 종류 간에 값의 범위 차가 매우 크다면 어떨까? 아마 모델이 제대로 학습을 하지 못할 것이다. 왜냐하면 값이 큰 feature의 영향만 크게 받을 것이기 때문이다.
따라서, feature 데이터들의 범위를 정해주어야 한다. 이를 feature scailing이라 한다.
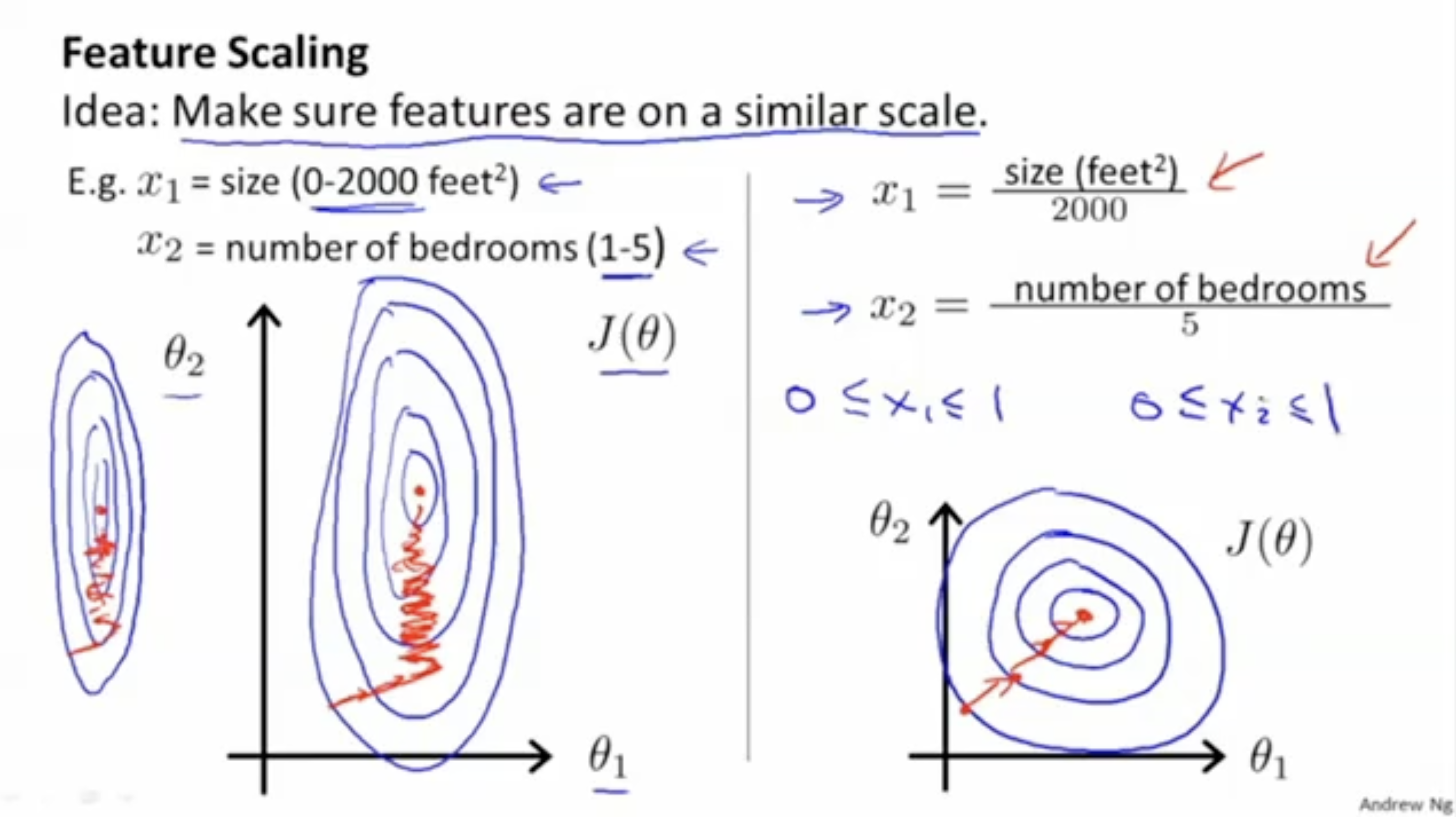
아래 그림은 feature scaling을 나타내는 그림이다.
- feature 은 값의 범위가 0~2000 이다. 반면에, feature 는 값의 범위가 1~5 이다.
- 따라서 만약 그대로 cost function 를 적용한다면 왼쪽 그림과 같이 과 의 균형이 맞지 않을 것이다.
- 이를 위해 값의 범위를 0~1로 지정해주자.
- 오른쪽 그림처럼, 모든 feature 데이터에 대해서 식을 적용한다.
이렇게 함으로써 모든 feature 데이터의 값의 범위는 0~1로 지정될 것이다.- 따라서 feature scailing을 적용하여 local optima를 찾는 를 그래프로 그리면 오른쪽 그림처럼 균형 잡힌 모습을 볼 수 있을 것이다.
그리고 feature scaling은 무조건 0~1의 범위가 갖도록 할 필요가 없다.
아래 그림처럼 "-1 ~ 1", "0 ~ 3", "-2 ~ 0.5" 등으로 해도 문제는 없다.
- 하지만, 값의 범위가 너무 크거나 너무 작지 않도록 주의해야 한다. 이 경우는 문제가 된다.

feature scaling의 대표적인 방법 중 "mean normalization(평균 정규화)" 방법이 있다.
아래 그림처럼 데이터들의 평균이 0이 되도록 만드는 방법이다.
수식은 아래와 같다.
- : 평균값
- : 또는 (Standard Deviation, 표준 편차)

다음으로 Gradient Descent를 구하는 실질적인 방법을 알아보자.
먼저, 아래 그림과 같이 gradient descent 식을 볼 수 있다.
다만 어떻게 grdient descent가 올바르게 작동하는지, 그리고 learning rate 를 어떻게 잘 선택하는지 방법을 모른다. 따라서 이런 내용을 알아본다.

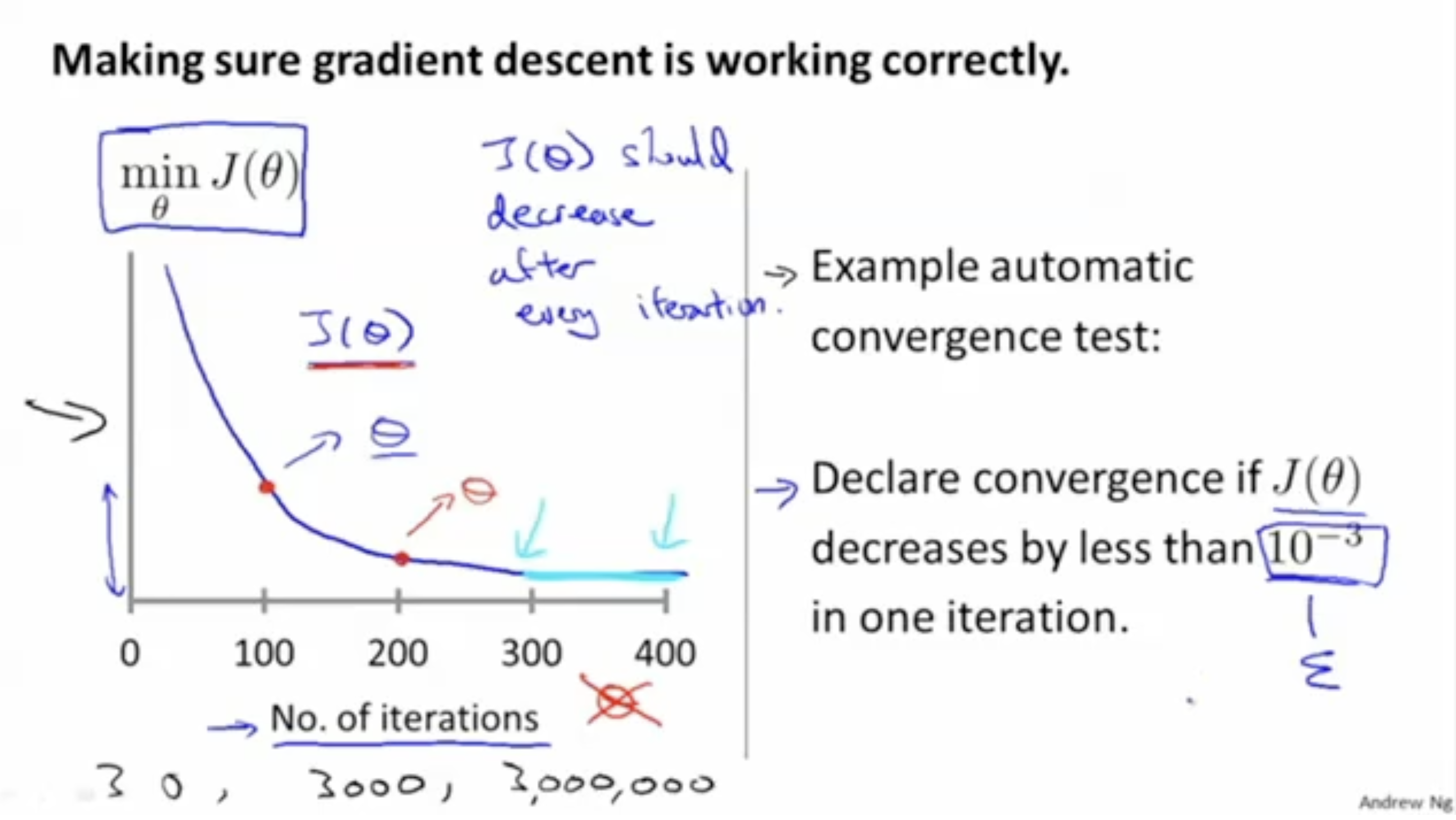
먼저 gradient descent가 잘 동작하는 예시는 아래 그림과 같다.
cost function 가 gradient descent 과정이 반복될 수록 값이 0에 가까워지는 것을 볼 수 있다.
그리고 의 값이 보다 작아지면, 즉, 을 만족하면 local optima를 찾았다고 정의하여 gradient descent 과정을 그만둔다.
이처럼 과 같이 기준이 되는 값을 (입실론)이라고 한다.
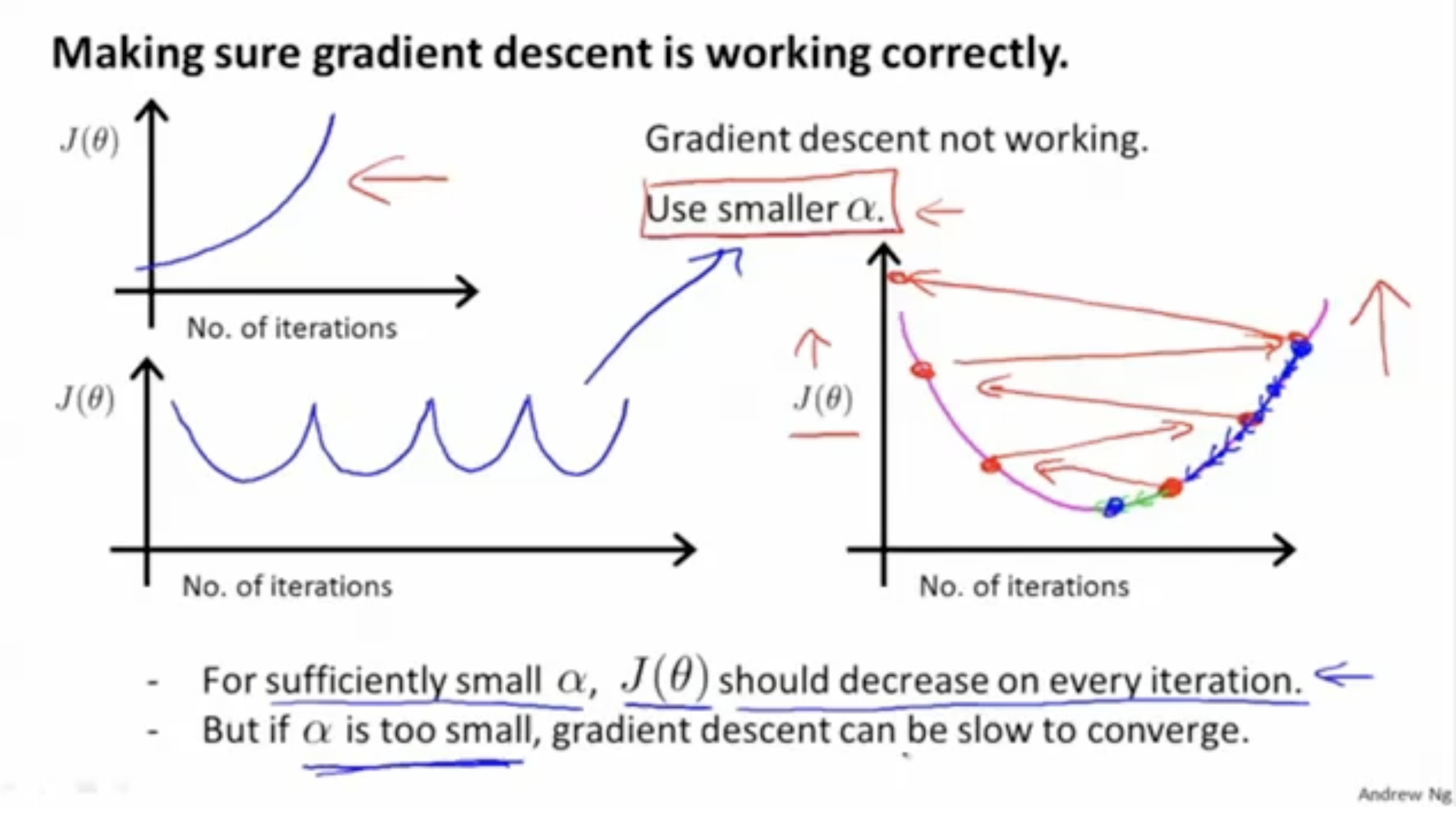
반면에, 아래 그림은 gradient descent가 잘 동작하지 않는 예시이다.
- 반복 횟수가 증가할수록 cost function 의 값이 증가하거나,
- 반복 횟수가 증가할수록 cost function 의 값이 수렴하지 못하고 왔다 갔다 하거나,
- cost function 의 값이 local optima에서 점점 멀어지는 경우가 있다.
그리고 이러한 문제를 해결하기 위해서, learning rate인 의 값을 낮춰줘야 한다.
하지만 값을 너무 낮추면 local optima를 찾는 데 매우 많은 시간이 소요되므로 주의할 필요가 있다.
요약하자면 다음과 같다.
- 만약 learning rate 가 너무 작다면 local optima로 수렴하는 데 시간이 매우 많이 걸리는 단점이 있고,
- 만약 learning rate 가 너무 크면 cost function 의 값은 반복할 수록 local optima에서 멀어진다는 단점이 있다.
따라서 강의에서 Andrew Ng 교수님은 값을 과 같이 작은 값으로 시작해서 조금씩 조정하는 것을 추천하셨다.

다음은 linear가 아닌 non-linear에 대한 예시이다.
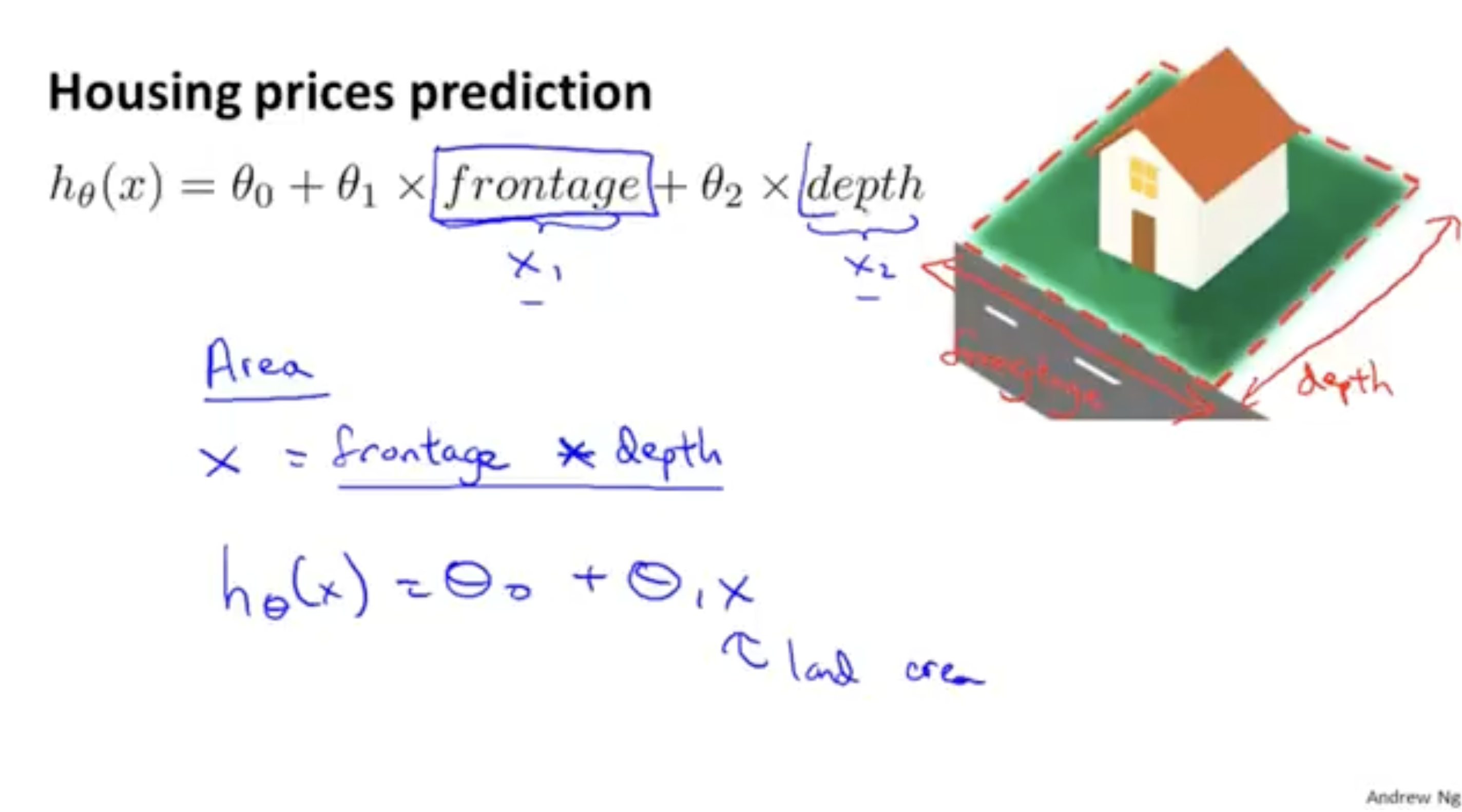
아래 그림과 같이 는 집 가격을 예측하는 함수이다.
하지만 과 를 하나로 합쳐서 라는 새로운 feature로 정의를 내릴 수 있다.
그리고 이렇게 정의를 내리면 와 같은 수식으로 고칠 수 있다.
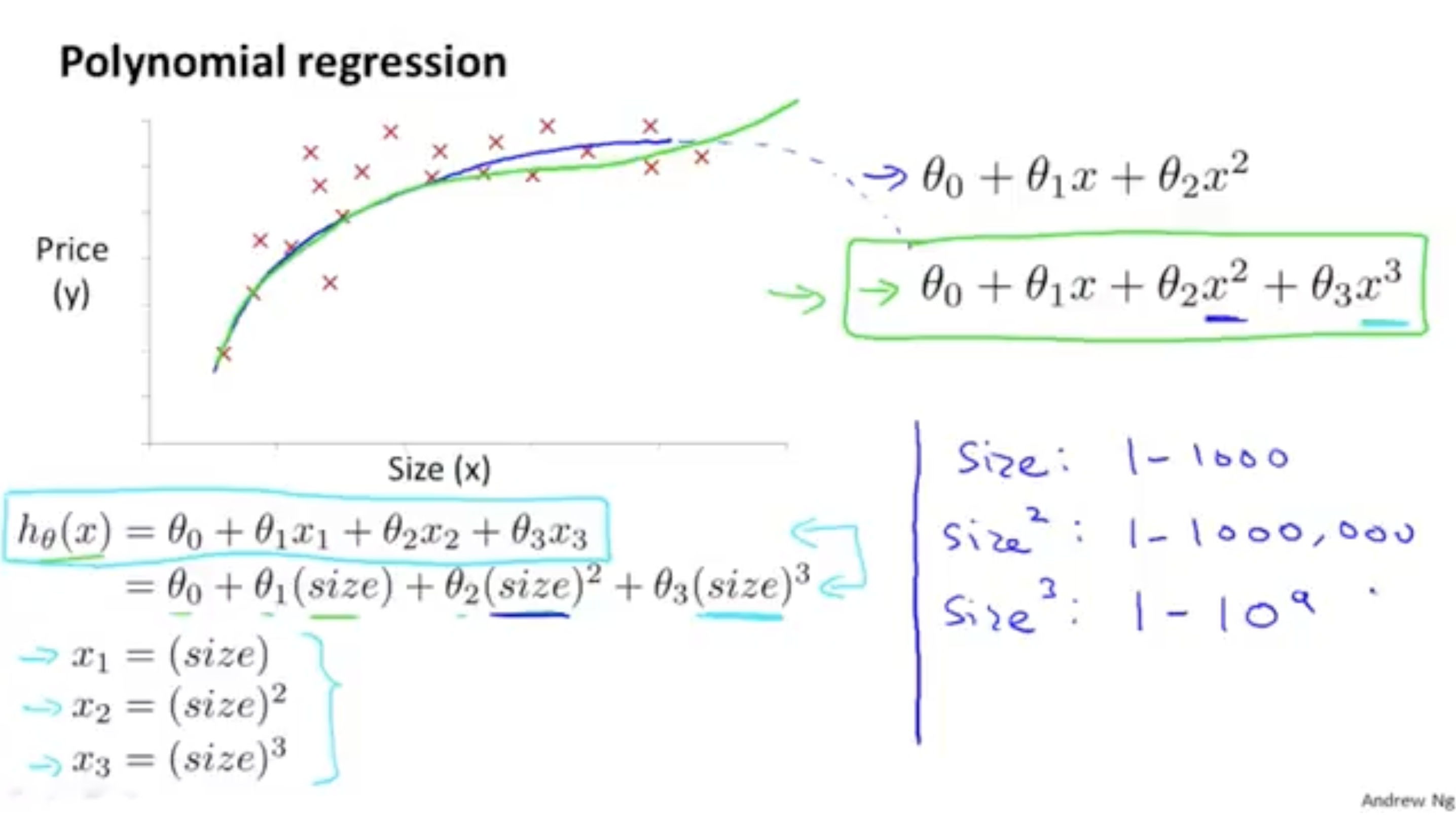
다음은 다항식에 대한 regression 모습을 보여준다.
에서 feature 의 차수를 어떻게 정의하냐에 따라 그래프 모양이 달라질 수 있다.
또한, 여기서 feature scaling이 중요한 이유도 알 수 있는데, 값의 범위가 1~1000인 feature에 대해서 제곱, 세제곱 등 차수에 대해서 연산을 하다 보면 값의 범위가 기하급수적으로 늘어날 것이다. 따라서 feature scaling이 중요하다.
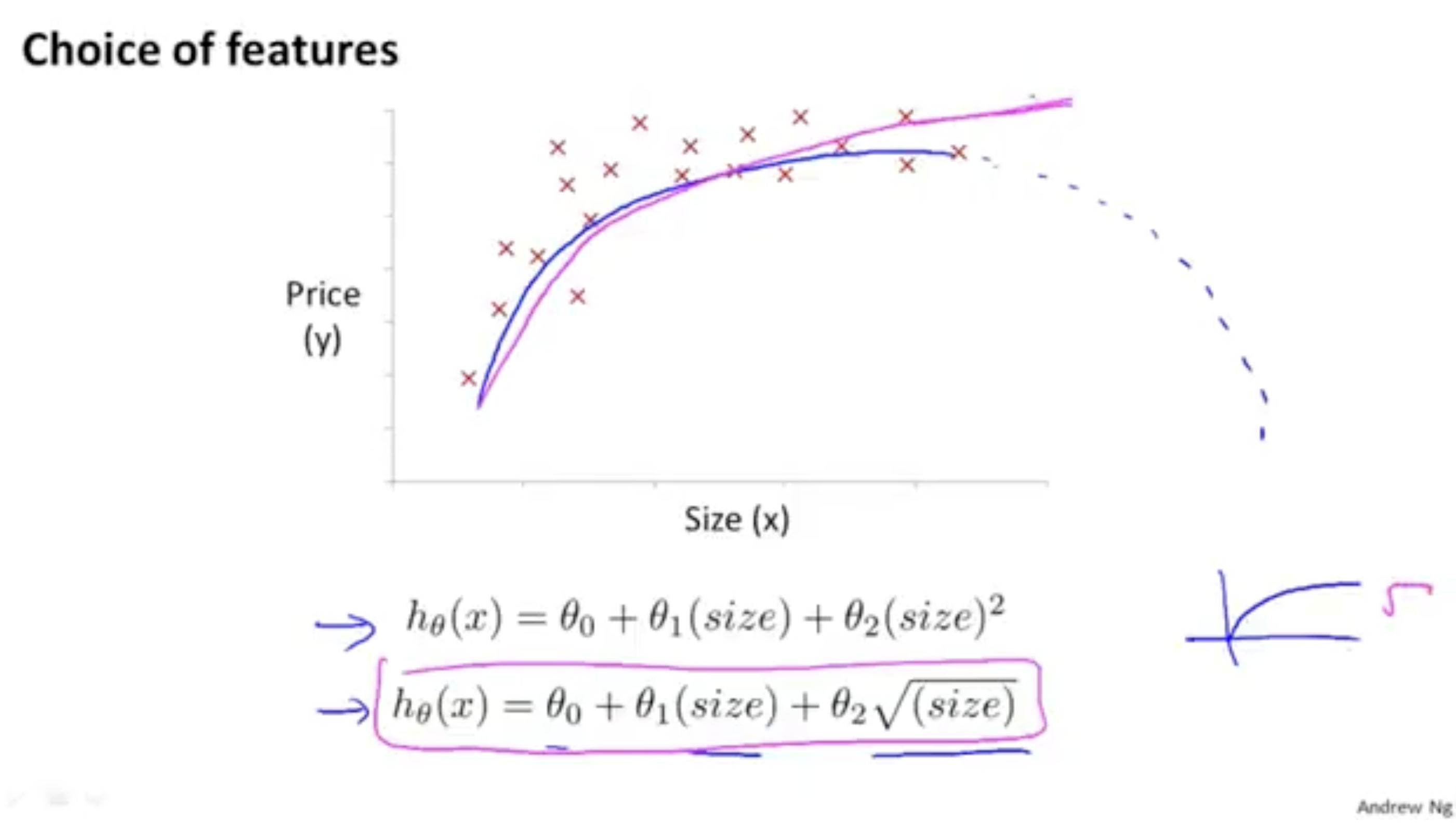
다항식의 예측 함수 를 어떻게 정의하느냐는 매우 다양하다.
아래 그림처럼 제곱 다항식으로 혹은 루트 다항식 등 다양하게 표현할 수 있다. 아래 그림의 경우 루트로 했을 때 데이터를 더 fit하는 그래프를 얻을 수 있을 것이다.
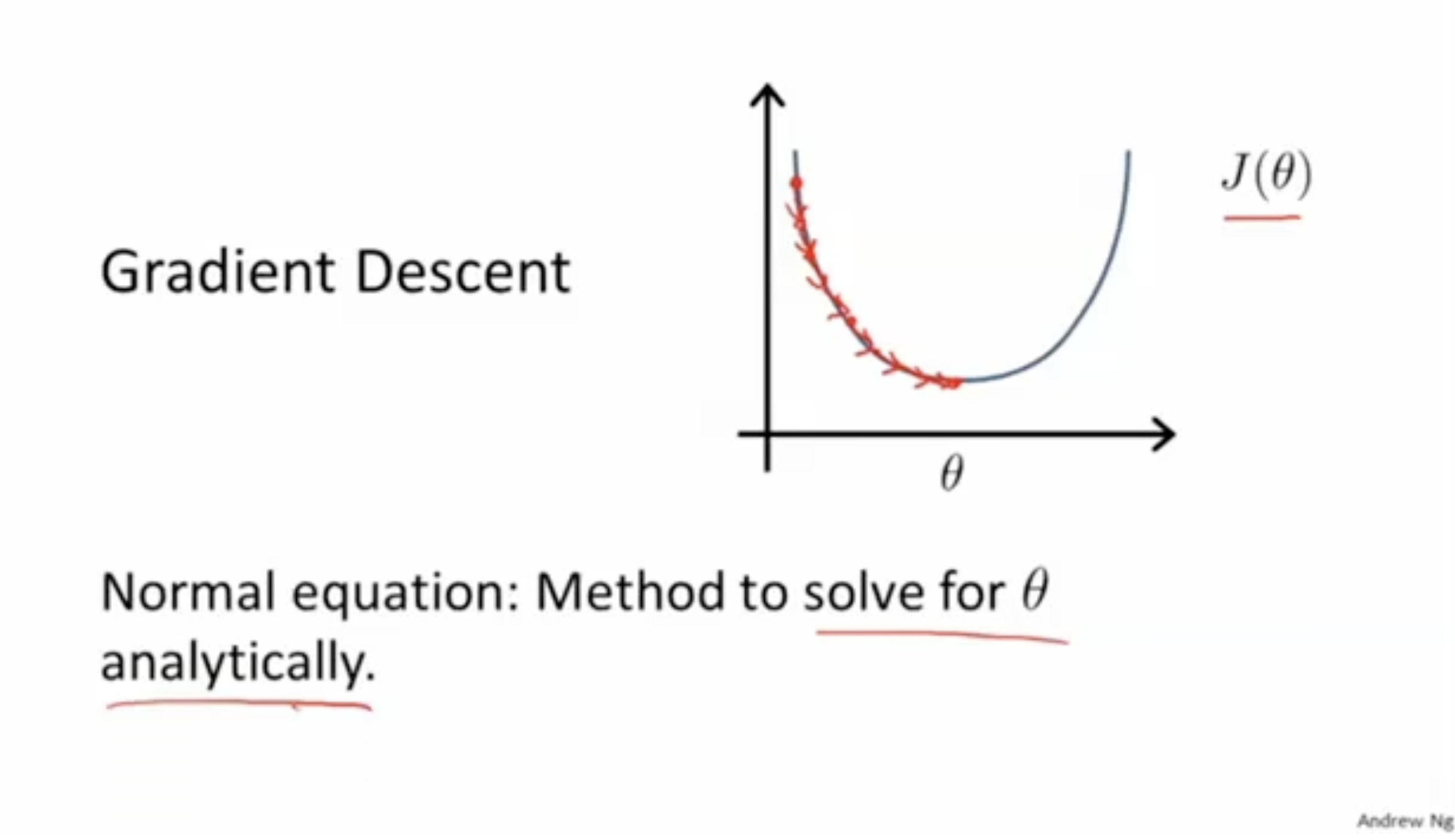
gradient descent는 반복을 통해서 cost function 의 값을 천천히 줄여나가며 최적의 를 찾는 방법이다.
반면에 "Norma equation"(정규 방정식)은 최적의 를 분석적인 방법으로 찾는 것을 의미한다.
다음으로 아래 그림은 normal euqation에서 어떻게 최적의 를 구하는지를 보여주고 있다.
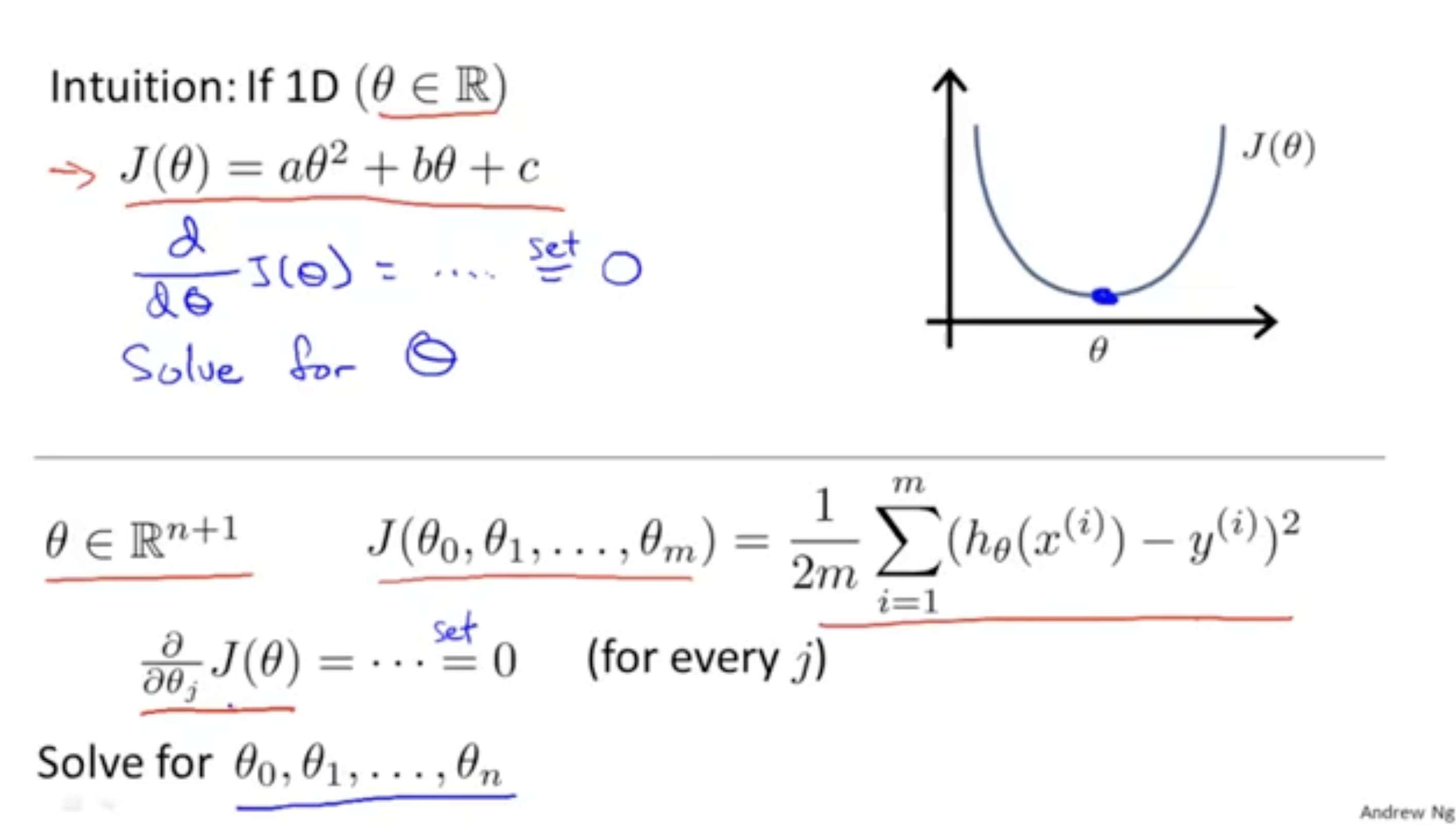
먼저, 단순하게 벡터가 1차원이라고 가정해보자. 윗부분의 수식처럼 cost function 을 미분하여 미분값이 0이 되는 값을 찾으면 되겠다.
그렇다면 아래 부분처럼 벡터의 차원이 차원이라고 가정해보자.
마찬가지로 모든 에 대해서 cost function 의 미분값이 0이 되는 를 찾으면 되겠다.
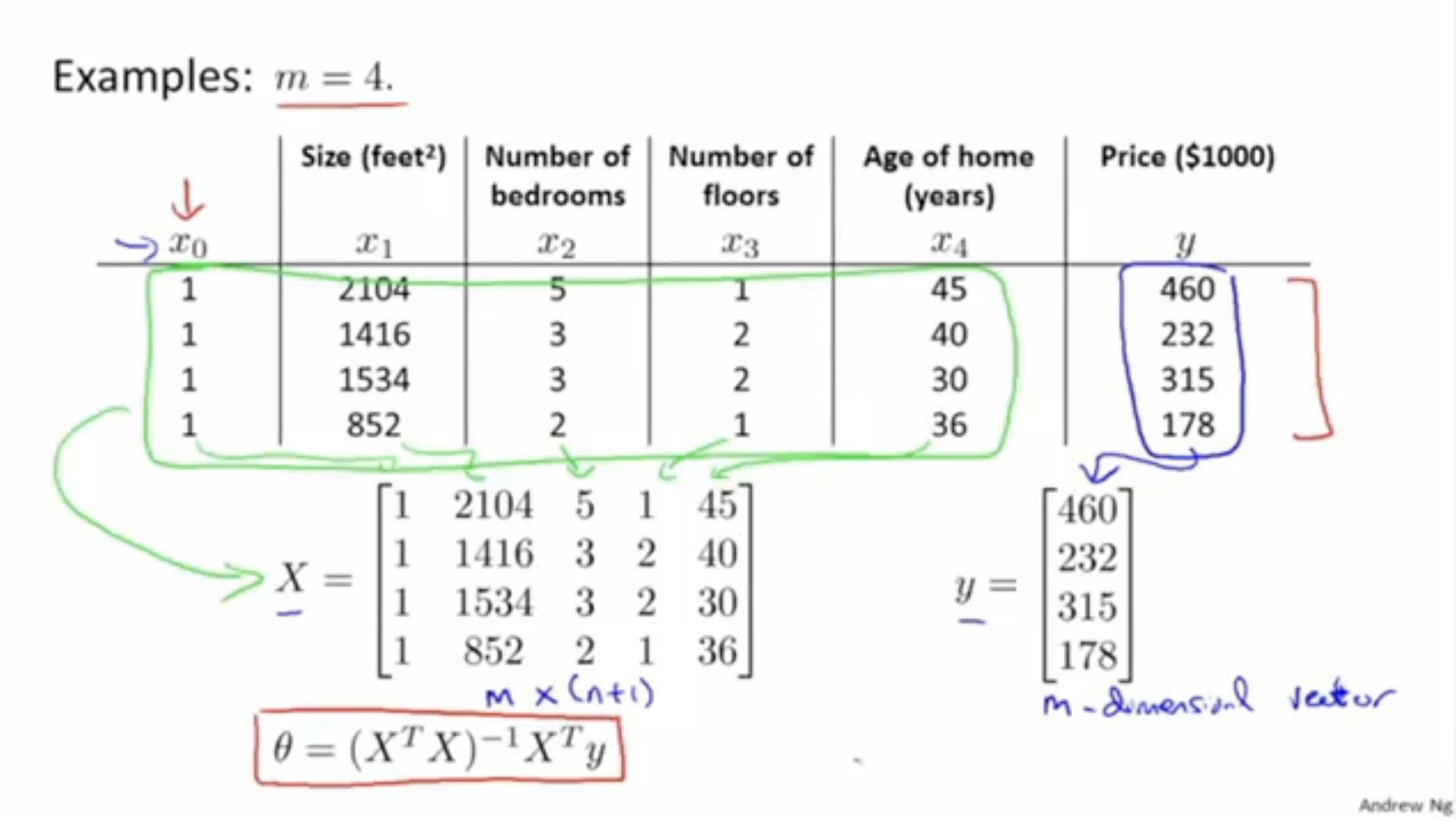
아래 그림과 같은 예시를 보자.
데이터 셋의 총 개수는 m=4개이며, feature의 종류는 n=4개이다.
그리고 이를 행렬로 표현하면 , 과 같이 나온다.
그리고 맨 아래 수식처럼 와 같은 수식으로 최적의 값을 찾을 수 있다.
아래 그림을 보자.
m개의 데이터셋과 n개의 features를 가정한다.
그리고 번째 데이터셋의 feature 벡터 는 처럼 나온다.
그리고 벡터 를 transpose하여 행렬을 만든다.
예시로, 만약 라고 해보자. 여기서 1은 의 값으로 에 대한 계수이다.
그러면 하단 우측 그림처럼 와 를 구할 수 있다. 에서 와 같이 표시했는데, 아마 오타인 것 같다.
올바르게 하면 와 같이 나올 것이다.
그리고 역시 수식으로 최적의 를 찾을 수 있다.

gradient descent와 noraml equation을 비교 정리하면 다음과 같다.
- gradient descent는 learning rate 를 잘 선택해야 하고, 반복 연산이 필요하다는 단점이 있다.
- 반면에 noraml equation은 값을 선택할 필요가 없고, 반복 연산이 필요없다는 장점이 있다.
- 하지만 feature 종류가 많을 때 (n이 매우 클 때) gradient descent는 잘 동작하지만, noraml equation은 n이 매우 클 때 연산 시간이 매우 오래 걸린다는 단점이 있다.

