https://www.youtube.com/watch?v=GmDkNjGygR8&list=PLiPvV5TNogxIS4bHQVW4pMkj4CHA8COdX&index=6
먼저 Classification에 대해서 알아보자.
아래와 같은 예시들이 classification이다.
- 이메일: 스팸인지 아닌지
- 온라인 거래: 사기인지 아닌지
- 종양: 악성 종양인지 아닌지
그리고 보통 Negative면 0, Positive면 1로 하여 값(target값)을 부여한다.
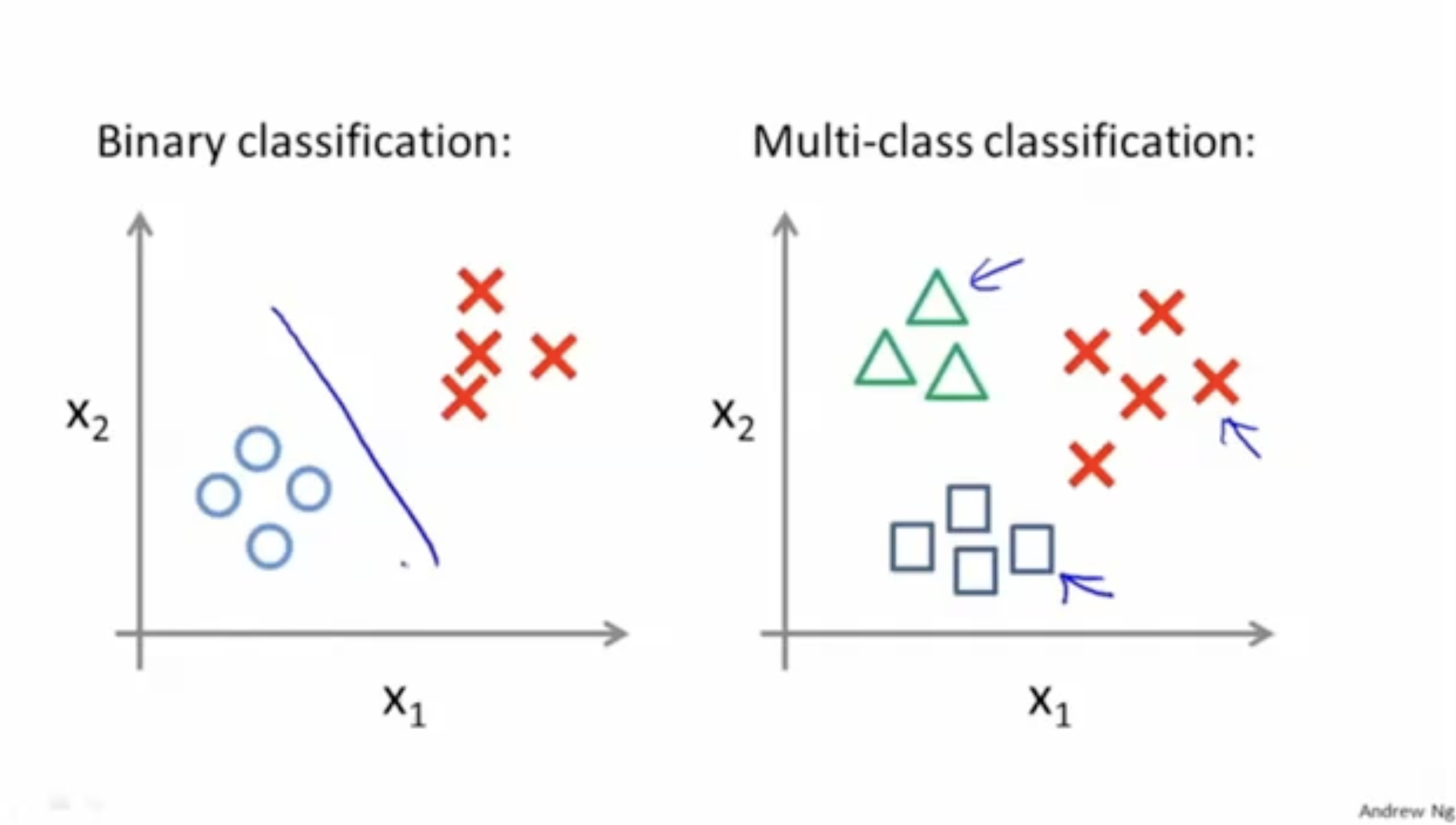
또한, 단순히 Yes or No와 같이 binary classification뿐만 아니라 처럼 여러 개의 class에 대한 분류도 있다.

그렇다면 linear regression으로 classification을 해보자.
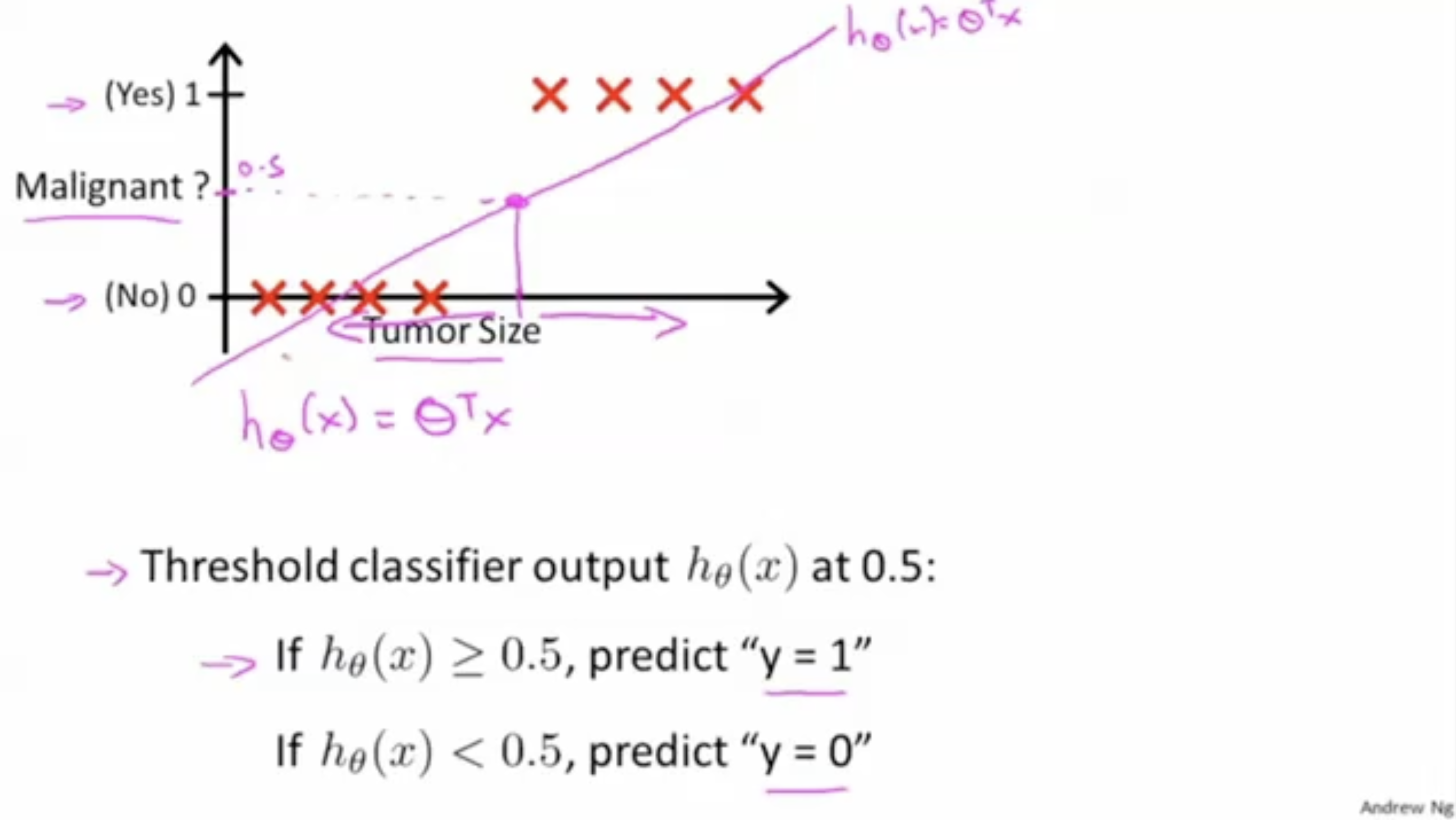
아래 그림에서는 linear regression으로 구한 가 꽤나 잘 분류하고 있는 걸 확인할 수가 있다.
- 면 (Yes),
- 면 (No) 와 같이 구분을 할 수가 있다.
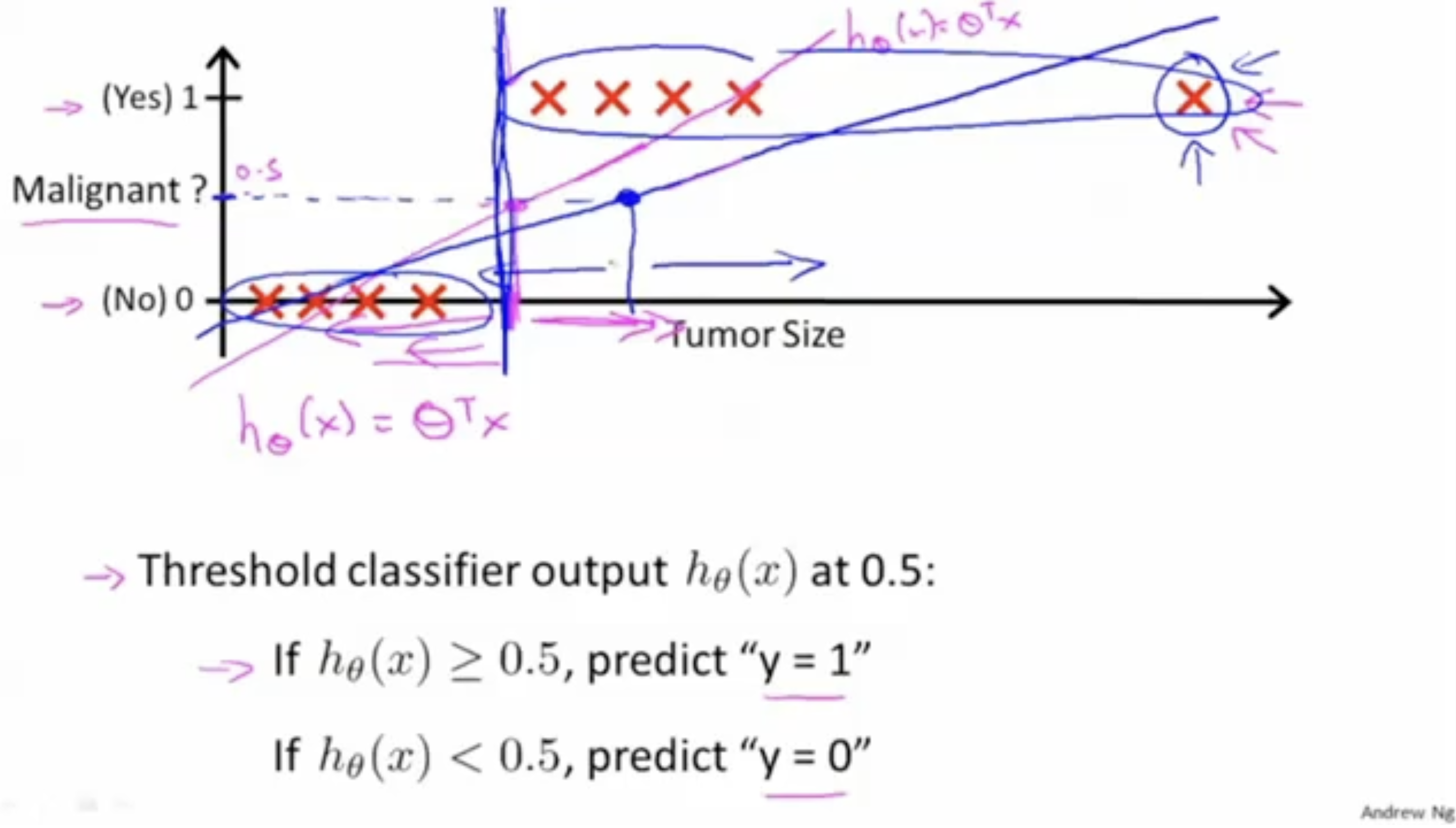
하지만 만약 새로운 학습 데이터가 추가된다면 어떨까? 아래 그림을 보자.
보다시피 기존의 인 분홍색 linear line에서 파란색 linear line으로 fit될 것이다.
그리고 똑같이 threshhold 값을 기준으로 분류를 했을 때, 올바르게 분류를 하지 못할 것이다.
아래 그림에서는 tumor size 데이터 중 XXXX "XX(해당 부분)"XX 부분이 실제로 Yes인데 아마 No라고 예측이 될 것이다.
그리고 classification은 과 같이 정의를 내리지만, 실제로 의 값은 그 범위를 벗어날 수 있다.
그래서 을 갖는 "Logistric Regression(Classification)"을 적용하여야 한다.

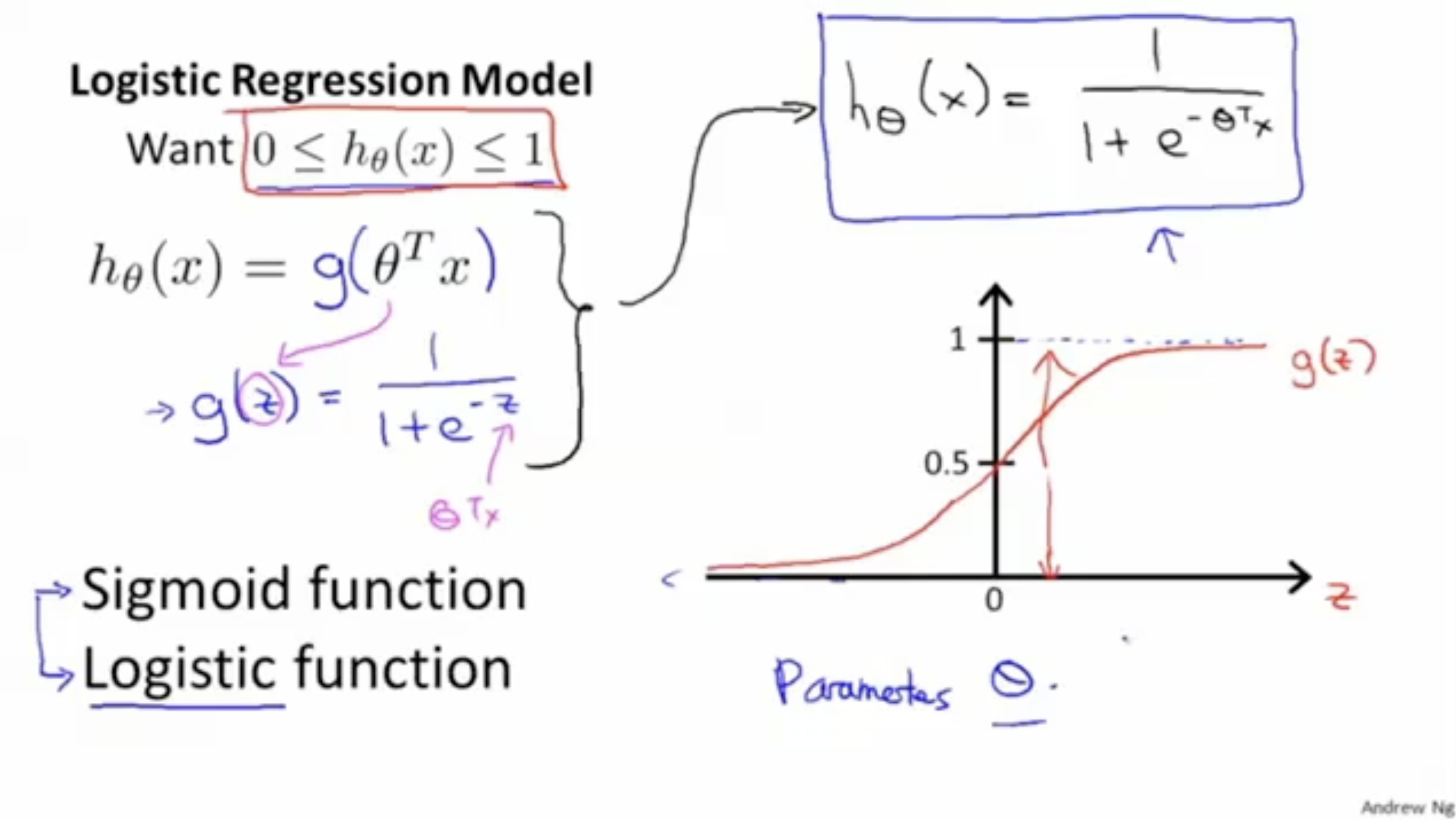
Logistric Regression의 모델은 아래 그림과 같다.
의 값의 범위가 0~1로 나오도록 하기 위해 특별한 함수를 적용한다.
이 함수의 명칭은 "Sigmoid function" 혹은 "Logistic frunction"이라고 부른다. 이 함수가 가질 수 있는 값의 범위는 오른쪽 그래프와 같다.
따라서 최종적으로 예측 함수는 로 정의된다.
예측 함수 는 입력값 에 대해 일 확률을 알려준다.
만약 악성 종양을 판단하는 예측 함수 에 종양 사이즈 를 넣었을 때 값이 0.7로 나왔다면, 이는 해당 종양 사이즈는 70% 확률로 악성 종양일 것이라는 것을 뜻한다.
- 그래서 를 정리하면 아래와 같다.
- : 입력값 와 파라미터 가 주어졌을 때 일 확률.
- 따라서 다음과 같이 정리할 수도 있다.

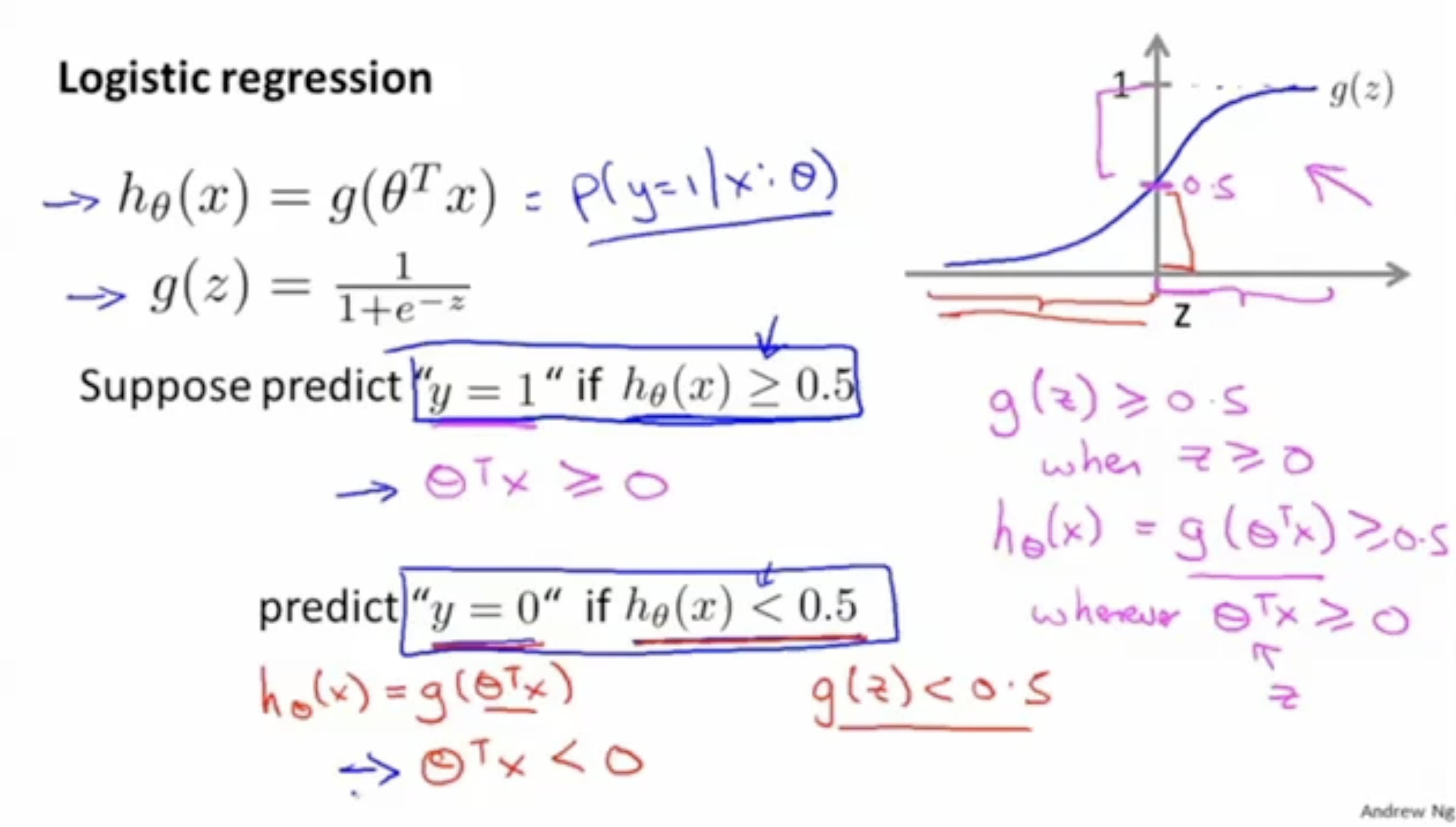
그렇다면 Logistic Regression을 어떤 식으로 할 수 있을까?
sigmoid 함수를 적용한 예측 함수 를 가지고,
- 면 이라고 예측한다.
- 이를 다른 식으로 표현하면 을 만족하면 이라고 예측한다.
- 그리고 로 예측하는 경우는 그 반대에 해당한다.
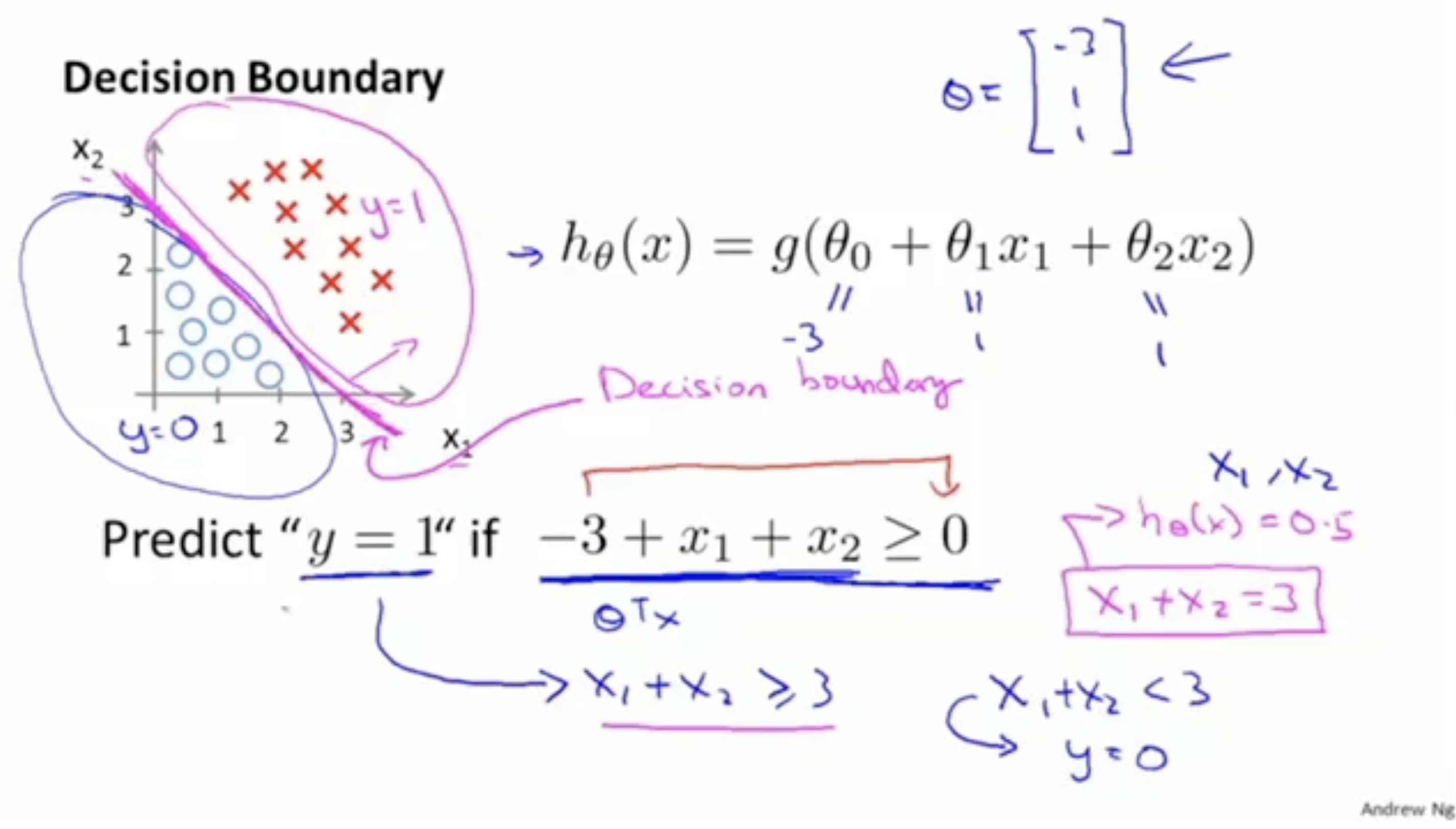
예시와 함께 살펴보자. 아래와 같이 예측 함수 이 주어졌다고 가정해보자. 그리고 파라미터 벡터는 처럼 주어졌다고 가정해보자.
- 이 경우 를 만족하면 이라고 예측할 것이다.
- 즉, 을 만족하는 데이터들에 대해서는 이라고 예측하고, 만족하지 못하는 데이터들에 대해서는 이라고 예측한다.
- 그리고 이라는 함수를 통해서 이를 구분할 수가 있으며, 이를 "Decision Boundary"라고 부른다.
- 해당 Decision Boundary를 기준으로 기준보다 크면 1로, 작으면 0으로 분류한다.
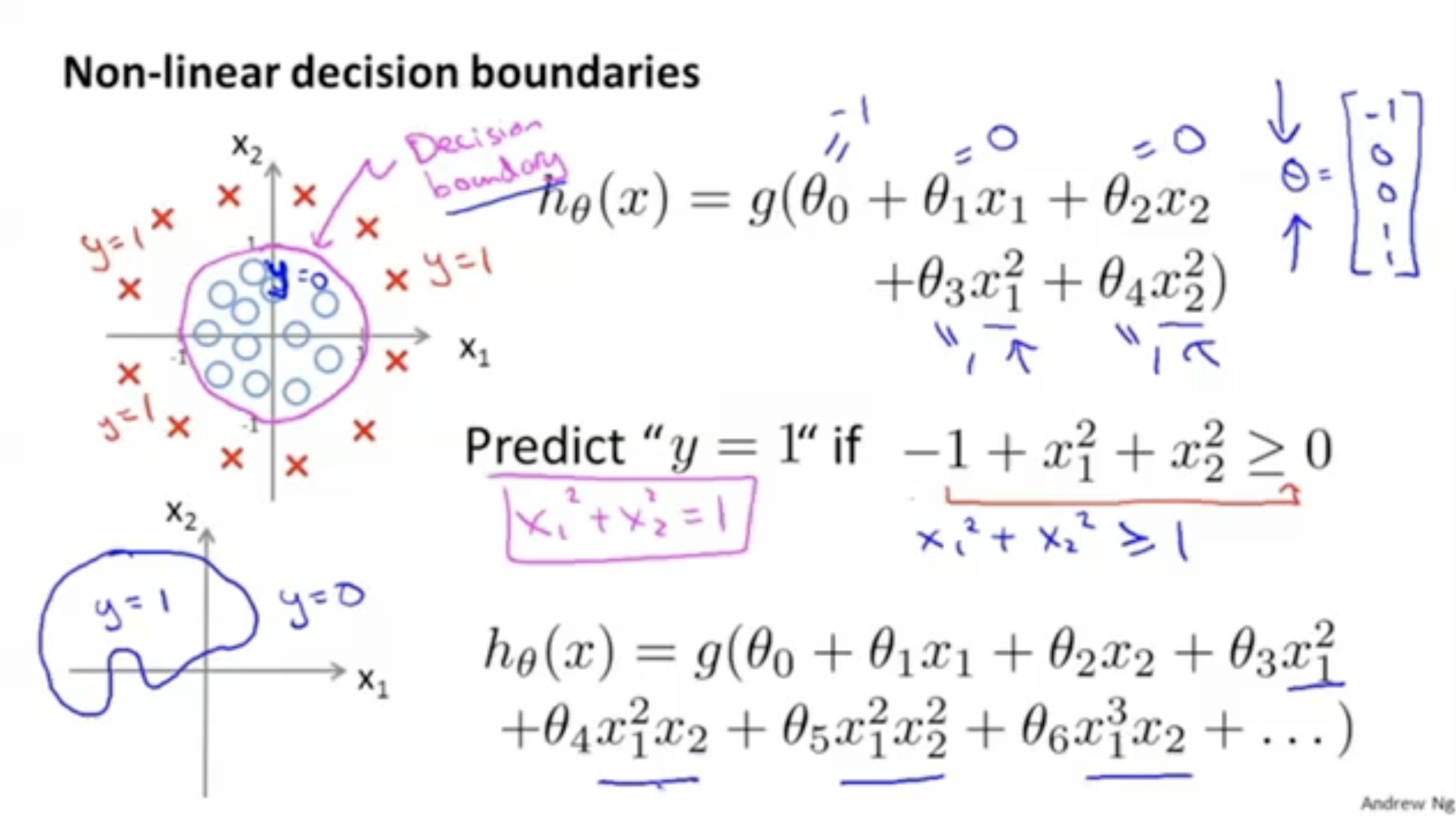
비선형 Decision Boundary도 존재할 수 있다. 아래 그림을 살펴보자.
- 이라는 예측 함수가 있다.
- 그리고 파라미터 벡터는 과 같다.
- 이 경우 인 의 값이 0 이상이어야 로 예측할 것이다. 그리고 해당 Decision Boundary를 그리면 왼쪽 위 그림과 같이 모양의 그래프가 그려질 것이다. 이와 같은 예시가 non-linear boundary decision이다.
- 그렇다면 만약 더 복잡한 함수가 주어진다면 어떨까? 아마 왼쪽 아래와 같이 특이한 Decision Boundary가 나올 것이다.
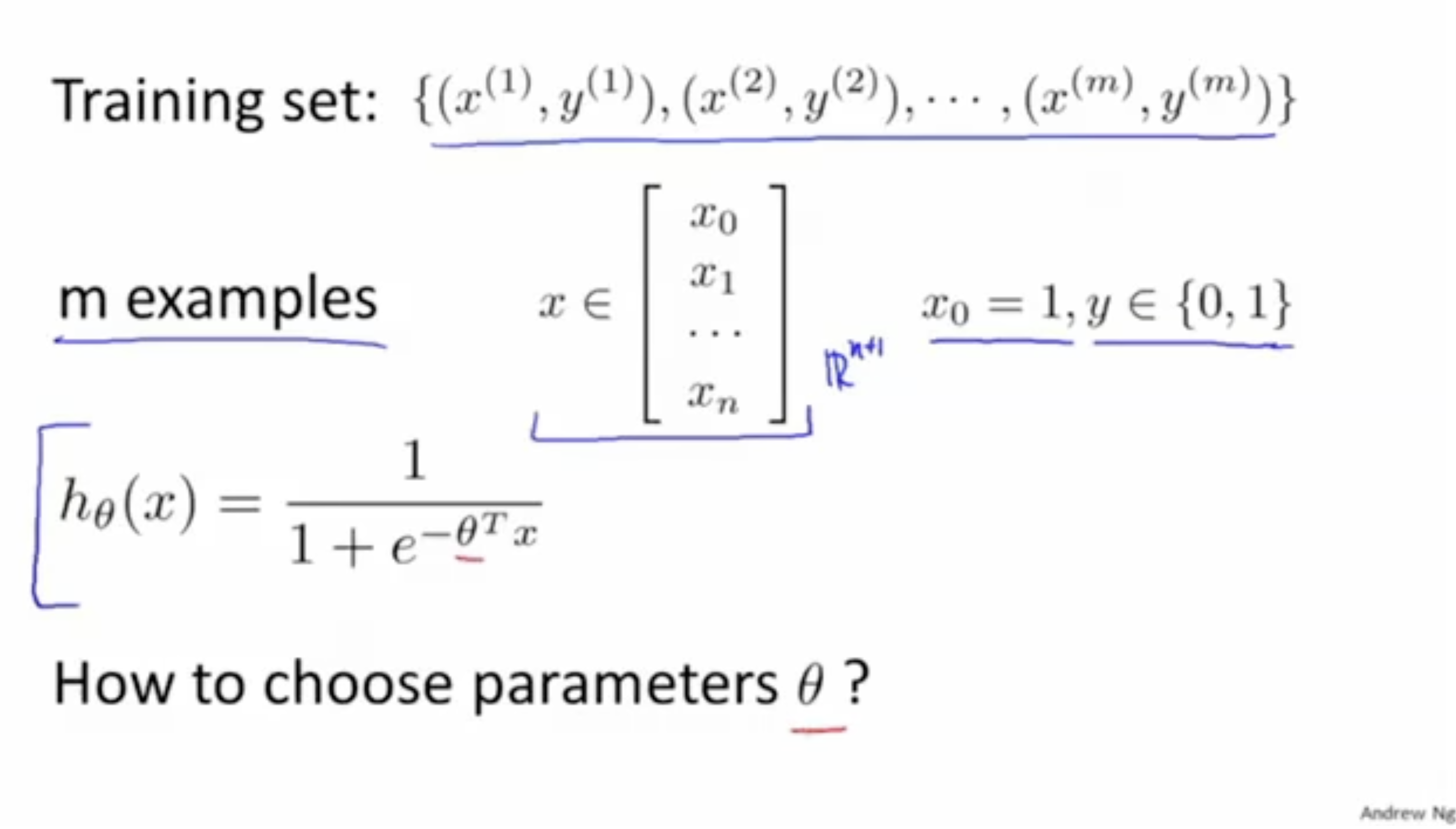
앞에서 Logistic Regression이 어떻게 이뤄지는지 배웠다. 그렇다면 이제 어떻게 최적의 파라미터 를 찾을 수 있을지 고민해보자.
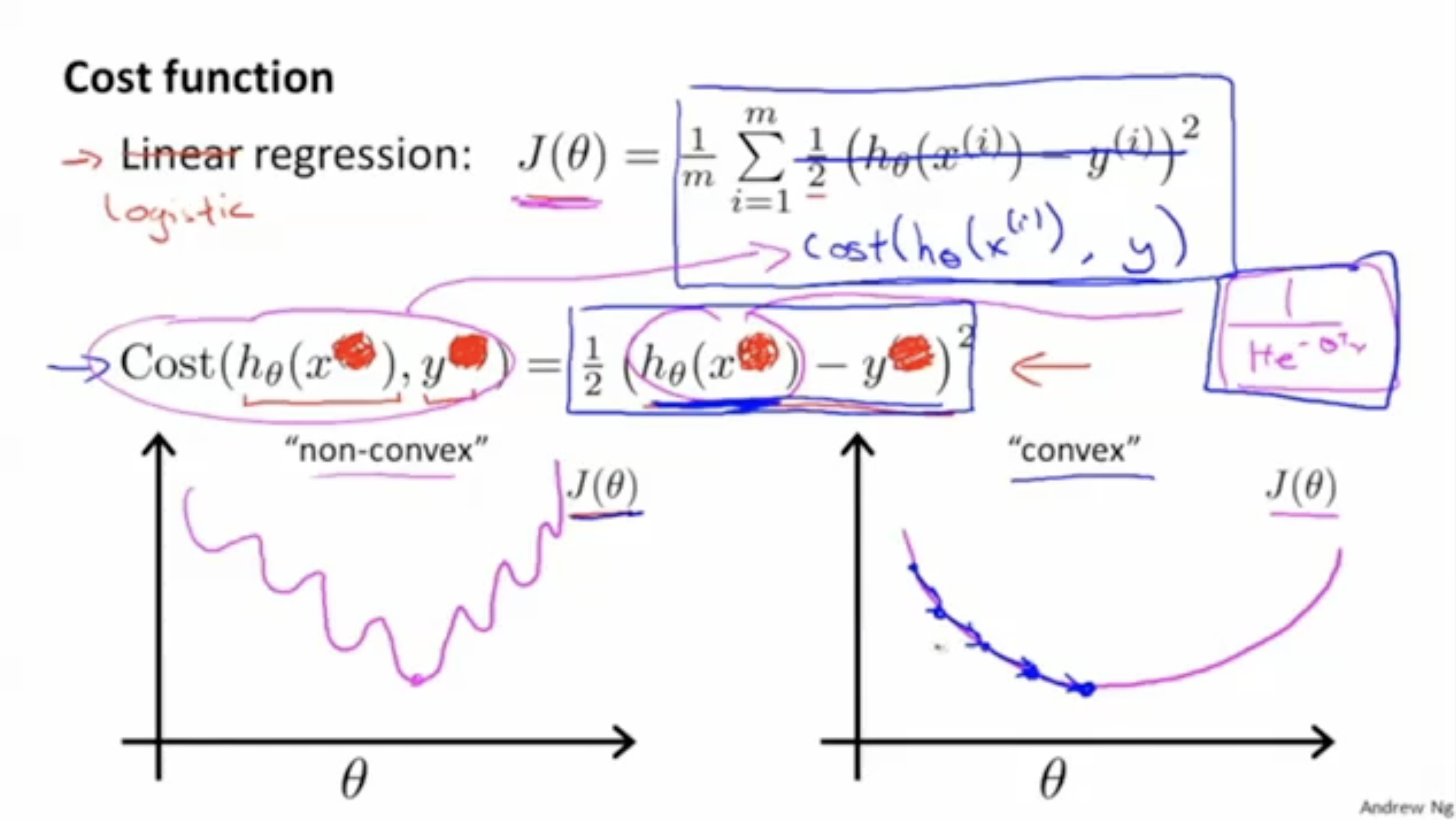
우선 Cost function을 보자.
기존의 linear regression 형태의 cost function인 과 같은 방식으로 적용하면 cost function은 왼쪽 그래프처럼 non-convex한(no global optima) 그래프가 나올 것이다. 따라서 오른쪽 그래프와 같이 나오는 cost function을 정의해야 한다.
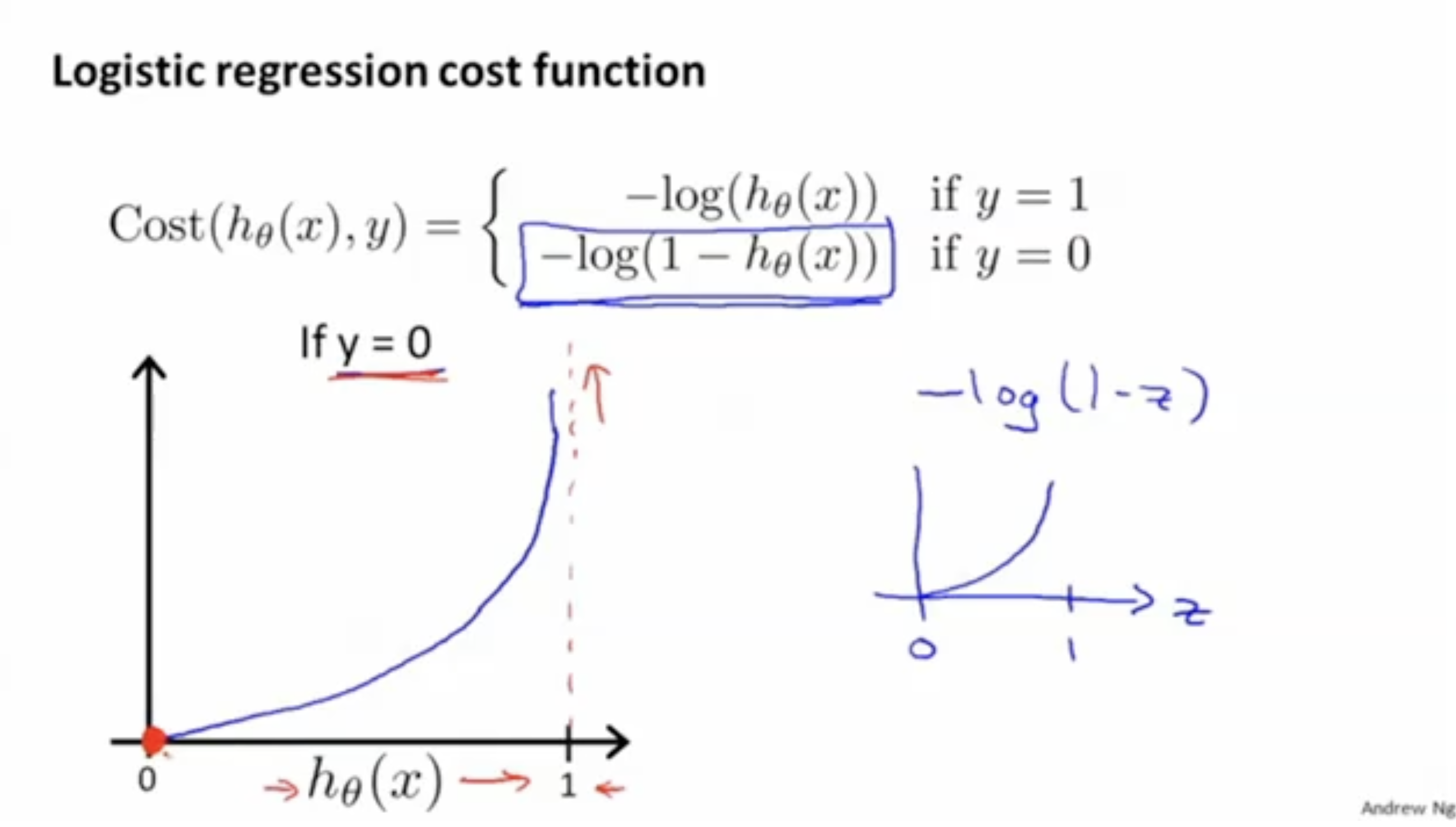
Logistic regression의 Cost(실제값과 예측값 간의 차)은 아래 그림과 같다.
- 만약 실제값(타겟값) 가 1이라면, 와 같이 적용하고,
- 가 0이라면, 와 같이 적용한다.
- 위 그래프를 보면 함수에 대한 그래프를 볼 수가 있다.
- 가 0에 가까워질수록 값이 매우 증가하고 1에 가까워질수록 값이 감소하는 것을 알 수 있다.
- 이는 인 경우에서 예측값이 1에 가까워질수록 해당 Cost의 값이 감소한다는 것을 보여준다. (학습하기에 적절한 cost이다.)

반면에 인 경우의 Cost 그래프는 아래 그림과 같다.
- 그래프는 을 나타낸다.
- 즉, 인 경우에, 예측값 의 값이 0에 가까워질수록 Cost의 값이 감소하고, 1에 가까워질수록 Cost의 값이 증가한다는 것을 알 수 있다.
그래서 Logistic Regression의 를 하나의 식으로 정리하면,
""
라는 식으로 표현할 수 있다.
- 실제값(타겟값) 가 1이면, 가 되어,
""만 남게 된다.- 반면에 실제값(타겟값) 가 0이면, 가 되어,
""만 남게 된다.

이제 Cost(실제값과 예측값 간의 차를 구하는 함수)를 가지고 cost function을 정리해보면 아래와 같이 나올 것이다.
- 그리고 이 cost function 를 최소화하는 값을 찾으면 우리가 원하는, classification을 잘하는 예측 함수 를 구할 수 있을 것이다.

cost function을 구했으니, 이제 gradient descent 방식을 적용해보자.
linear regression의 gradient descent 방식과 큰 차이는 없다.
- 모든 파라미터 에 대해서 cost function 를 편미분한 값을 learning rate에 따라서 연산해주면 된다.

linear regression의 gradient descent와 차이를 꼽자면, 예측 함수의 형태가 다르다는 점이다.
이 점을 빼고는 거의 유사하다.
- linear regression의 :
- logistic regression의 :

컴퓨터로 계산할 때는, , 등의 값을 연산하는 코드가 있어야 한다.

그리고 Gradient Descent 방식 뿐만 아니라 Conjugate gradient, BFGS, L-BFGS 등 다양한 최적화 알고리즘이 존재한다. 하지만 웬만하면 gradient descent가 가장 좋아 보인다.
그리고 위에서 봐왔던 binary classification(yes or no)뿐만 아니라 여러 개의 클래스를 갖는 "Multiclass classification"도 있다.
- 이메일 폴더링: 업무용/친구/가족/취미
- 병 진단: 정상/감기/플루
- 날씨: 화창한, 구름 많은, 비, 눈

하지만 binary classification에서는 하나의 decision boundary를 그림으로써 분류가 가능하였는데, multi-class classification에서는 어떻게 분류를 할 수 있을까?
방법은 간단하다. 각각의 클래스에 대해서 1 vs. others 로 총 n개 클래스 만큼의 decision boundary를 만들면 된다.
- class 1만 분류하는 boundary decision은 우측 첫 번째 그래프.
- class 2만 분류하는 boundary decision은 우측 두 번째 그래프.
- class 3만 분류하는 boundary decision은 우측 세 번째 그래프.
그리하여 각 클래스를 분류하는 예측함수 는 class의 종류만큼 생성한다.
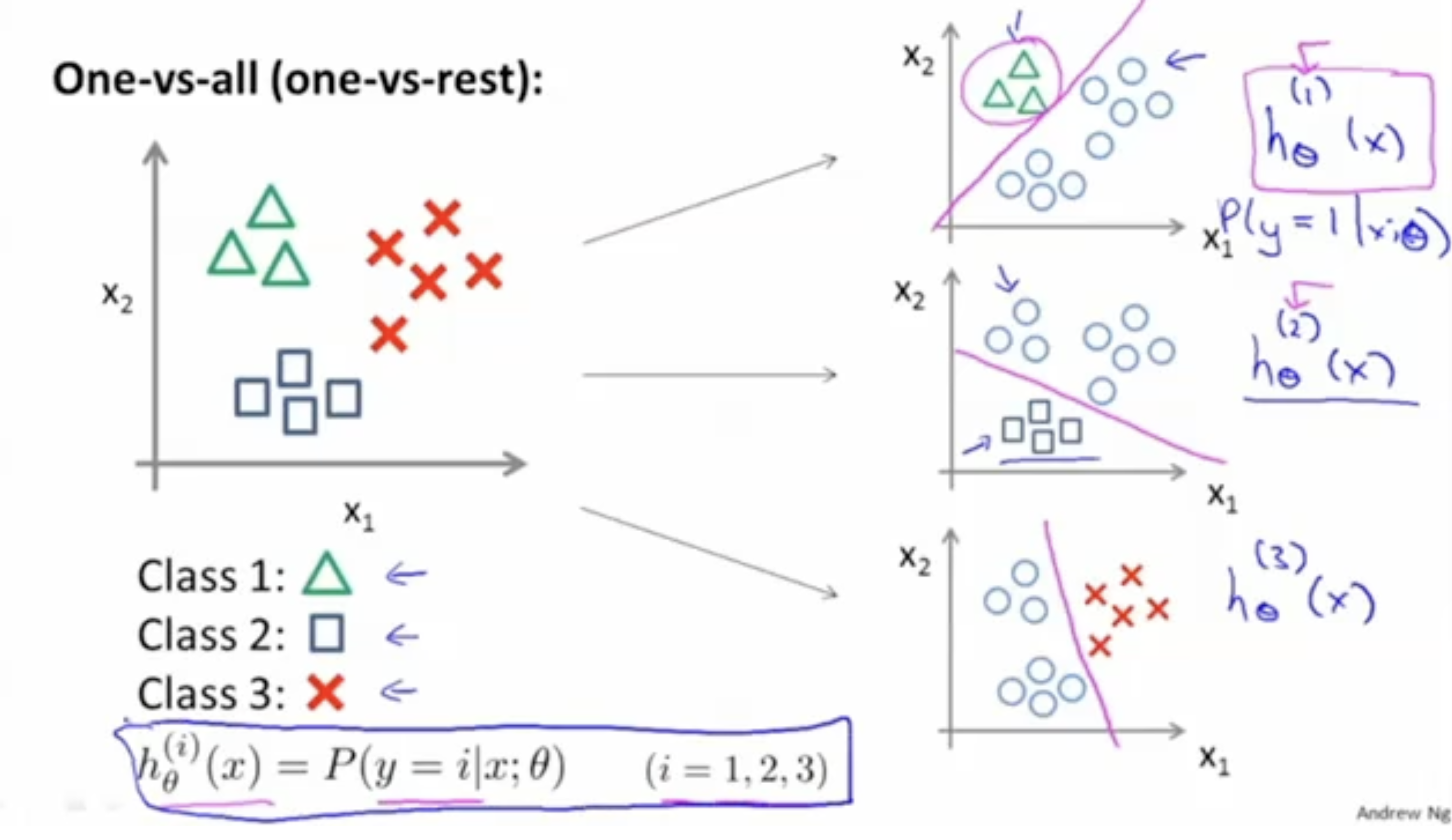
그래서 만약 학습 결과로 얻은 예측 함수 에 대해서 새로운 입력값 가 주어진다면,
각각의 예측 함수에 대해서 적용한 후, 가장 값(확률)이 높게 나오는 클래스로 분류하면 된다.
- Class of :

