https://www.youtube.com/watch?v=OUy_46vy3yg&list=PLiPvV5TNogxIS4bHQVW4pMkj4CHA8COdX&index=9
먼저 이전 강의에 이어서 neural network에 대해서 간단히 살펴보자.
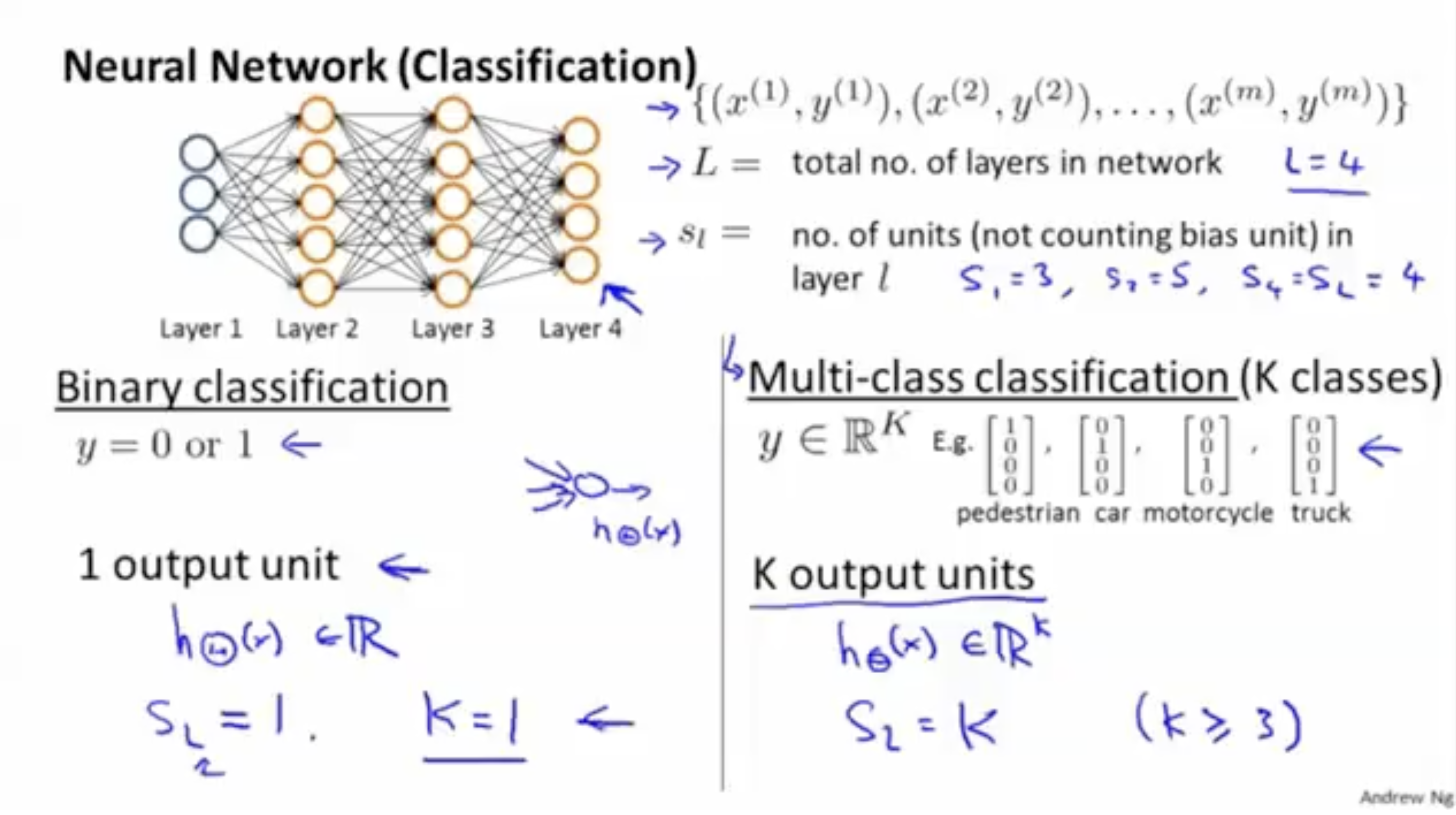
아래 그림에서 상단 그림은 classification에 대한 neural network의 예시이다.
- 학습 데이터셋의 크기는 으로, 과 같이 존재한다.
- 총 레이어의 개수 은 이다.
- 레이어 의 유닛 수 은 각각 와 같다.
- 그렇다면 binary classification의 경우는 어떨까.
- 예측값은 으로, 이 경우 정답 벡터의 차원은 1차원이다.
- 따라서, output layer인 번째 레이어의 유닛 수 은 로 나올 것이다.
- 다음으로 multi-class classification의 경우는 다음과 같다.
- k개의 클래스가 존재한다고 가정해보자.
- 이 경우 예측값은 벡터로 표현되며, 차원은 차원이다.
- 그리고 output layer에서는 총 k개의 output units이 나올 것이다.
- 따라서, output layer인 번째 레이어의 유닛 수 은 로 나올 것이다.
다음으로 neural network의 "cost function"을 알아보자. 먼저, logistic regression의 cost function은 아래와 같다.
여기서 중요한 점은 parameter regularization을 적용할 때 은 적용에서 제외된다는 점이다.
그리고 이를 neural network에 적용하면 수식은 아래와 같이 나온다.
- 의 의미는 번째 레이어에서, 레이어의 번째 유닛을 레이어의 번째 유닛으로 연산하는 데 필요한 weight를 의미한다.
- ex. ,
---> --->

그렇다면 이제 cost function 를 활용하여 neural network에 gradient descent 방식을 적용해보자. gradient descent의 전체적인 방식은 이전에 배웠던 regression과 유사하다.
- cost function 를 최소화하는 weight 를 찾는 게 목적이다.
- 따라서 cost function 와 각 레이어 l의 각 weight 에 대하여 편미분한 로, gradient descent를 적용한다.

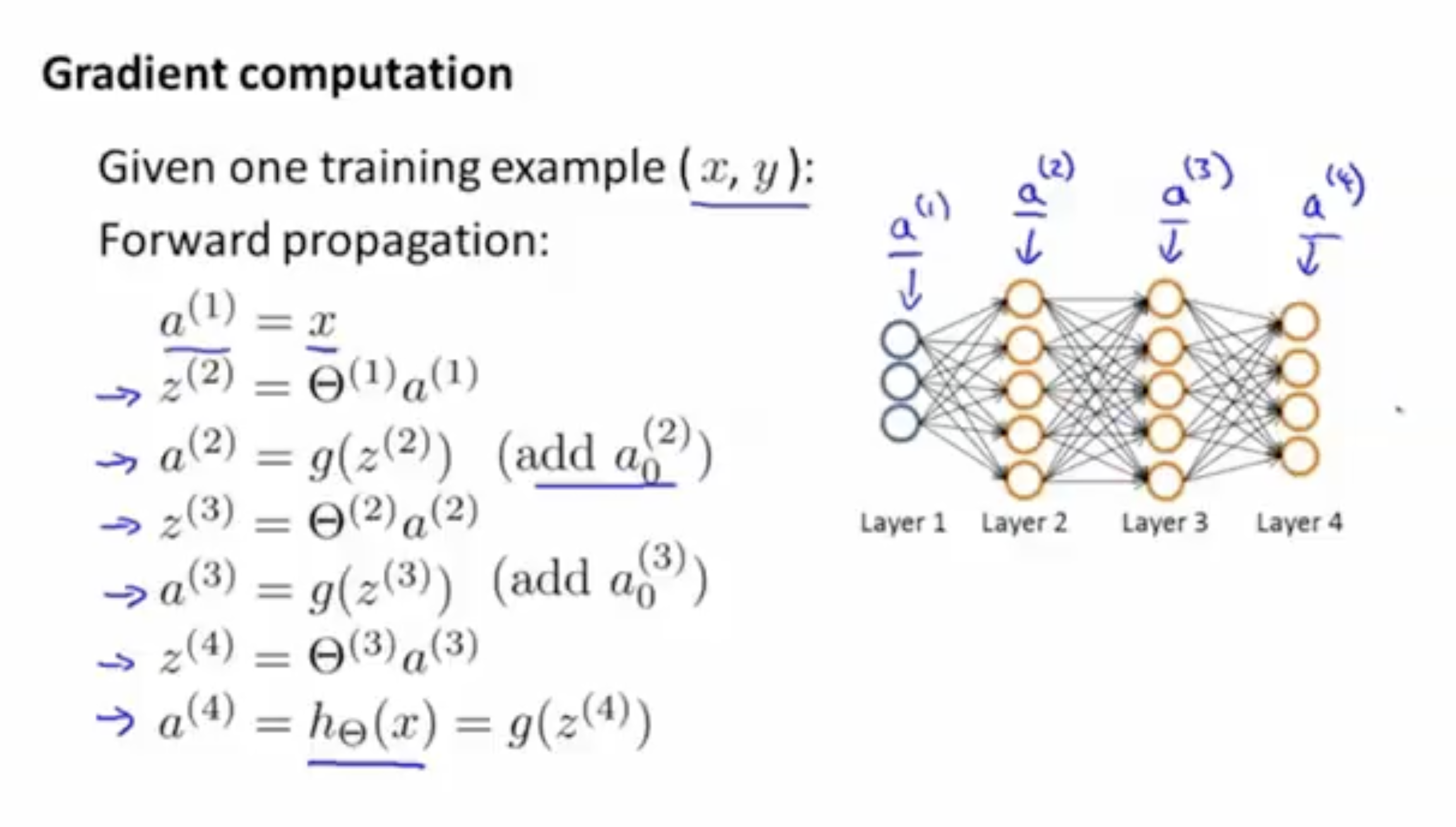
우선 forward propagation의 원리는 아래 그림과 같다.
- 먼저 layer 1에서 입력 를 으로 받는다.
- layer 2의 유닛 값들을 구하기 위해 의 값, 즉 값을 구한다.
- 해당 의 값을 activation func.에 적용하여 layer 2의 유닛 값 벡터 를 구한다.
- output layer에 도달할 때까지 위 과정을 반복한다.
- output layer에서도 마찬가지로 output units인 값을 구한다.
그러면 이제 "Backpropagation"을 적용하기 전 를 알아보자.
- 는 번째 레이어에 있는 번째 유닛의 오차를 의미한다.
- 그리고 이번에는 Forwardpropagation과 반대 방향으로, output layer부터 시작한다.
- 먼저, output layer의 번째 유닛에 대한 오차인 값을 구한다.
- 다음으로 다음 레이어의 유닛 벡터의 오차인 을 구한다.
- 여기서 ""은 element-wise 연산을 의미한다. 즉, 그냥 같은 행열의 원소끼리 곱한다는 의미이다.- 마찬가지로 input layer에 도달할 때까지 위 과정을 반복한다.
- input layer인 layer 1은 값을 갖지 않는다.

이제 Backpropagation에 대해서 알아보자.
- 먼저 모든 의 값을 0으로 세팅한다. 이는 을 나타내는 데 사용된다.
- 다음으로 범위에서 연산을 시작한다.
- 먼저 forwardpropagation을 하여 값들을 구한다.
- 그러고 나서 backpropagation을 하며 값들을 구한다.
- 그리고 각각의 weight에 대해 값들을 구한다.
- 그리고 의 값을 구하는데 이면 regularization parameter 와 weight를 곱한 값을 추가해주고, 아니면 해당 부분은 제외한다. (을 미분하면 로 되기 때문에 해당 수식 적용 가능.)
- 구한 값이 편미분 값을 의미한다. 이제 이 값으로 gradient descent를 적용하면 된다.

그럼 이제 위에서 배운 내용을 가지고 어떤 식으로 수식이 나오는지 알아보자.
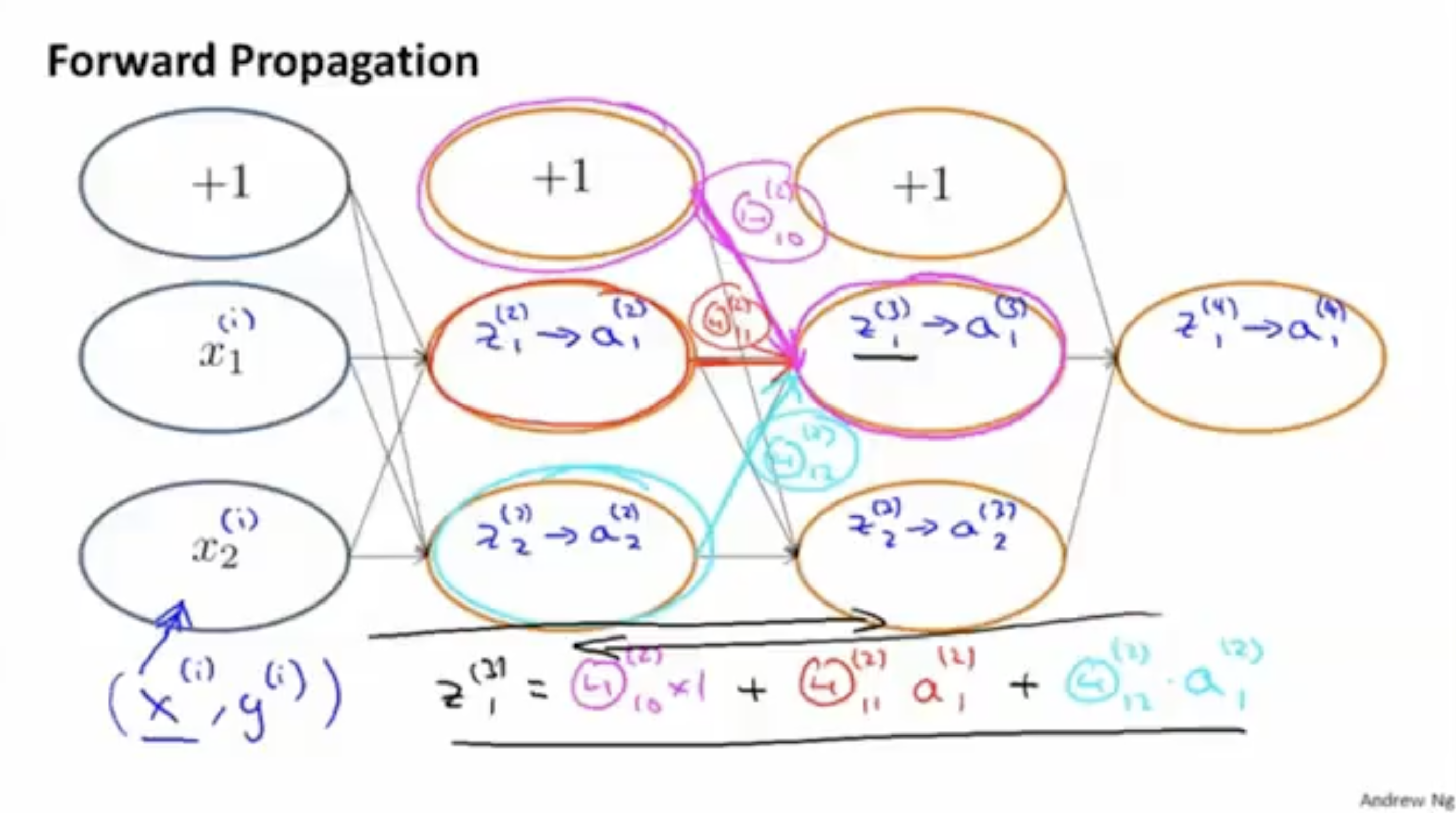
먼저 forwardpropagation은 다음 그림과 같다.
- 학습데이터 가 입력으로 주어진다.
- 그리고 각 레이어의 유닛수는 아래와 같으며, 각 레이어 마다 bias unit은 +1로 정의한다.
- 입력데이터 를 통해 값을 구한다. 그리고 값을 구한다.
- 예시는 다음과 같다:
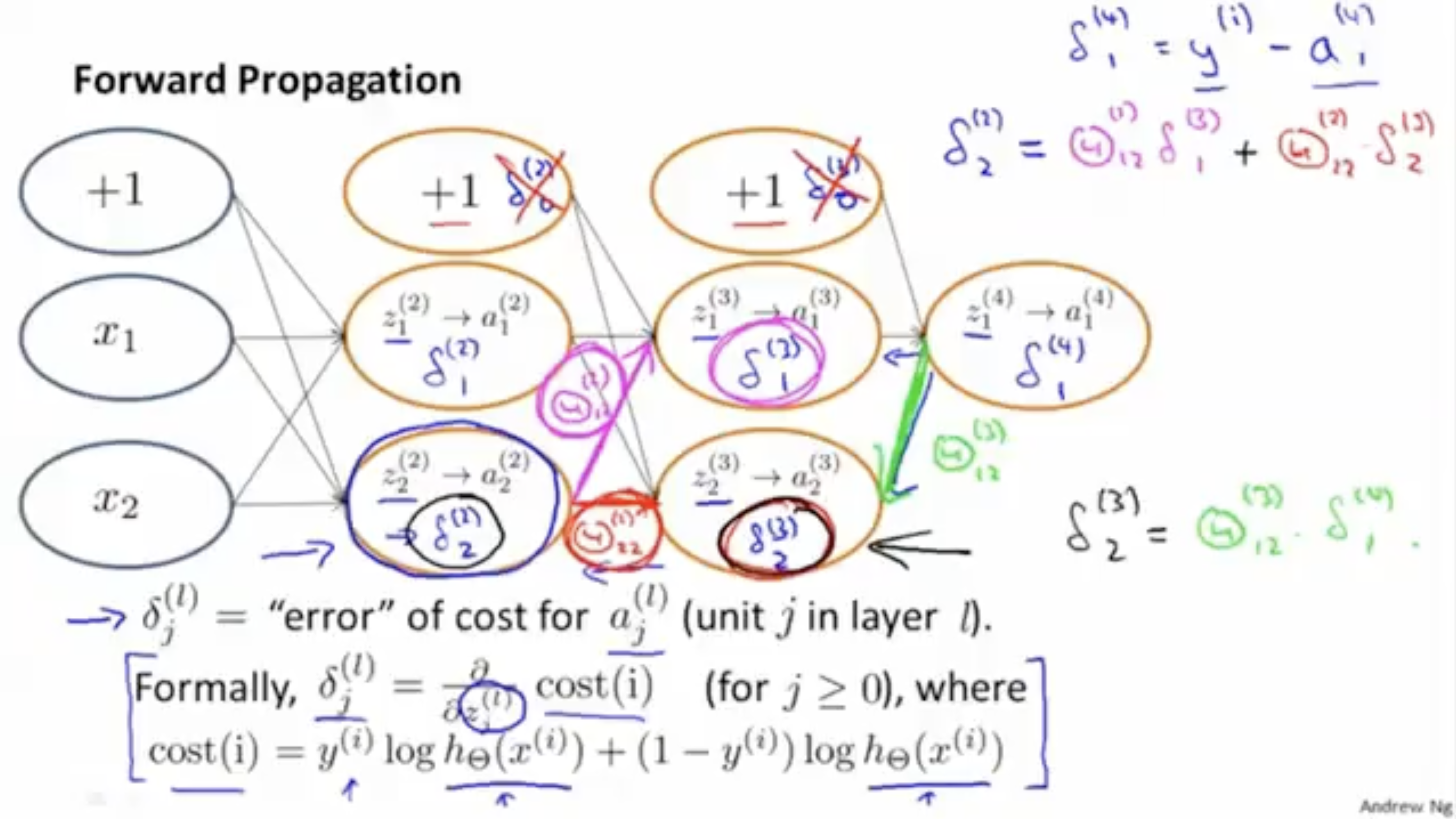
그렇다면 backpropagation은 어떨까. 아래 그림을 보자.
- 이해를 위해 output unit은 1개이며, weight regularization parameter 값 는 0이라고 가정한다.
- 그러면 cost function 는 일반적인 logistic regression의 cost function과 동일하게 나올 것이다.
- 물론 linear regression의 cost function처럼 로 생각할 수 있다. 어떤 가 뉴럴넷에 잘 작동되는지는 생각해보자.

backpropagation은 forwardpropagation이 끝나고 시작한다. 아까 봤던 forward propagation이 끝나고, 값을 구하며 backpropagation을 시작한다.
- 은 번째 레이어의 번째 유닛인 의 오차 정도를 의미한다.
- 그리고 은 공식을 이용해서 값을 구한다.
- 그리고 bias unit의 는 구하지 않는다.
- 예시:
- 예시:
그렇다면 backpropagation이 올바른 알고리즘이라는 것을 어떻게 증명할 수 있을까? 이를 위해 gradient(경사)를 수치적으로 추정하여 값을 비교해야 한다. 아래 그림을 보자.
- 파라미터 에 대해서 양 옆으로 매우 작은 값 만큼 떨어진 값들 과 이 있다고 가정하자.
- 그리고 에서의 기울기는 양 옆의 만큼 떨어진 값들의 기울기와 같다고 볼 수 있다.
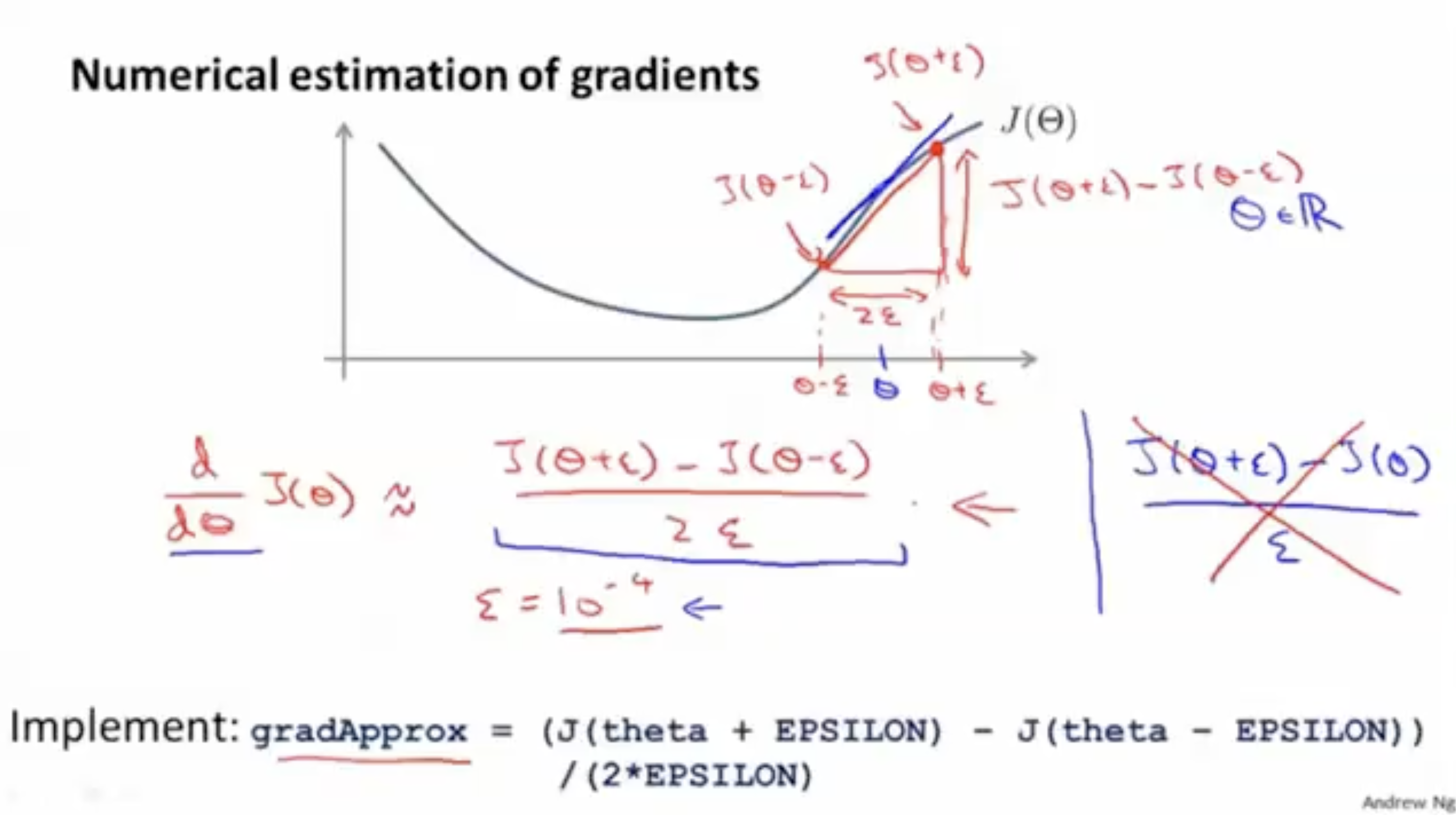
그리고 각각의 파라미터 에 대해서 편미분을 적용하면 아래 그림처럼 표현할 수 있다.

위 과정을 컴퓨터 프로그래밍 코드로 작성하면 다음과 같다.
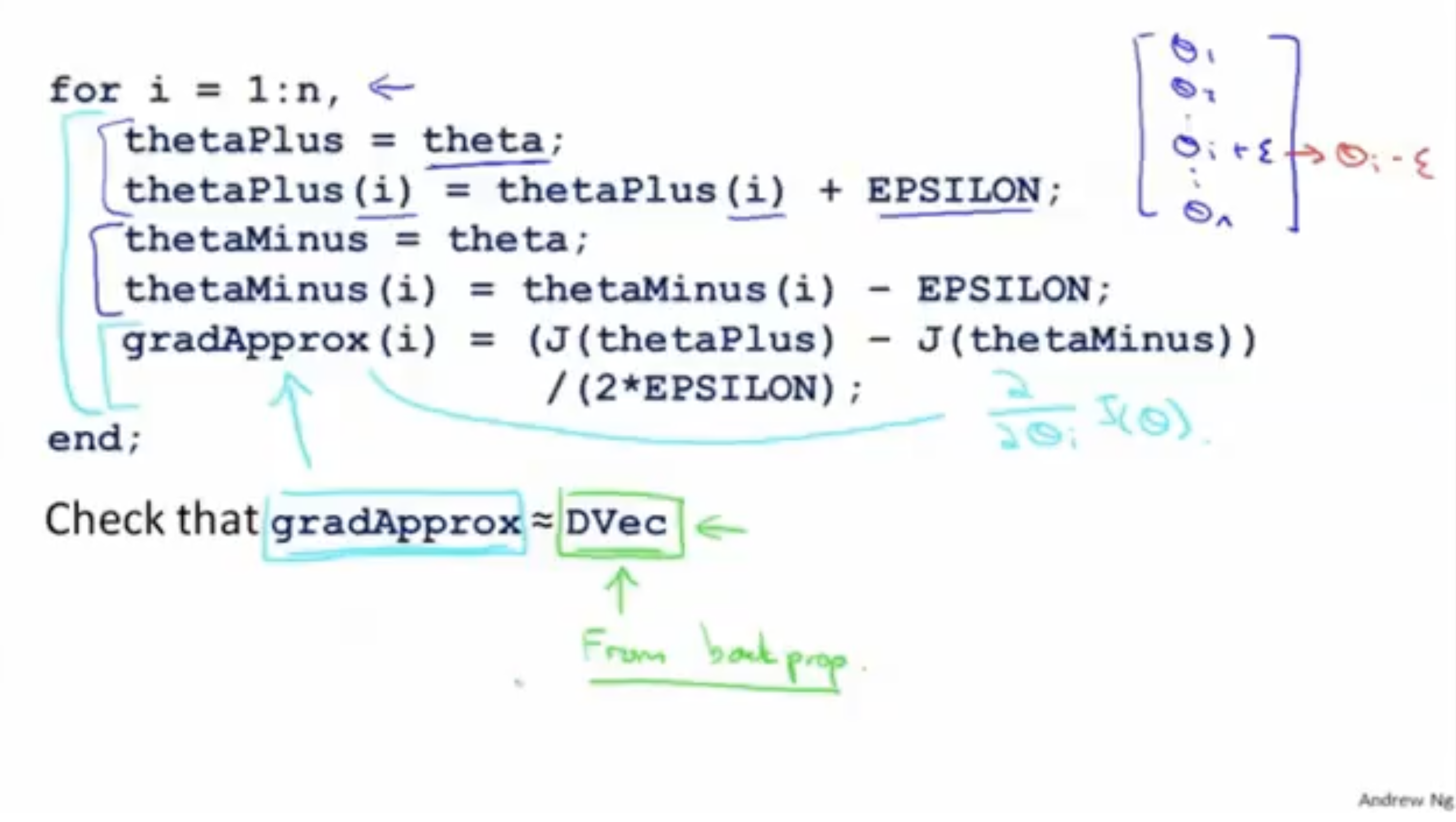
그래서 이전에 backpropagation 과정을 거쳐 얻은 벡터와 위 과정을 거쳐 얻은 와 값을 비교해보면 두 값이 유사하다는 것을 확인할 수 있다.
- 이로써 backpropagation이 올바른 알고리즘이라는 것을 증명할 수 있다.
- 그리고 gradient checking 코드는 학습된 뉴럴넷에 대해서 적용하여야 하며, 만약 학습할 때마다 매번 적용하면 연산 비용이 매우 많이 들 것이다.

그렇다면 weight 의 초기값은 어떻게 설정해야 할까? 그냥 0으로 세팅하고 시작하면 될까?

를 0으로 세팅한 상태에서 시작하는 예시는 다음과 같다. 이 경우 는 모두 0이 되어 각 레이어의 유닛들 간의 값의 차이가 없을 것이다. 그리고 이로 인해 값의 차이도 없게 되고, 기울기 값도 차이가 없을 것이다. 이렇게 되면 올바르게 최적의 를 찾지 못할 것이다. 즉, "Symmetry Problem (대칭 문제)"가 발생한다.
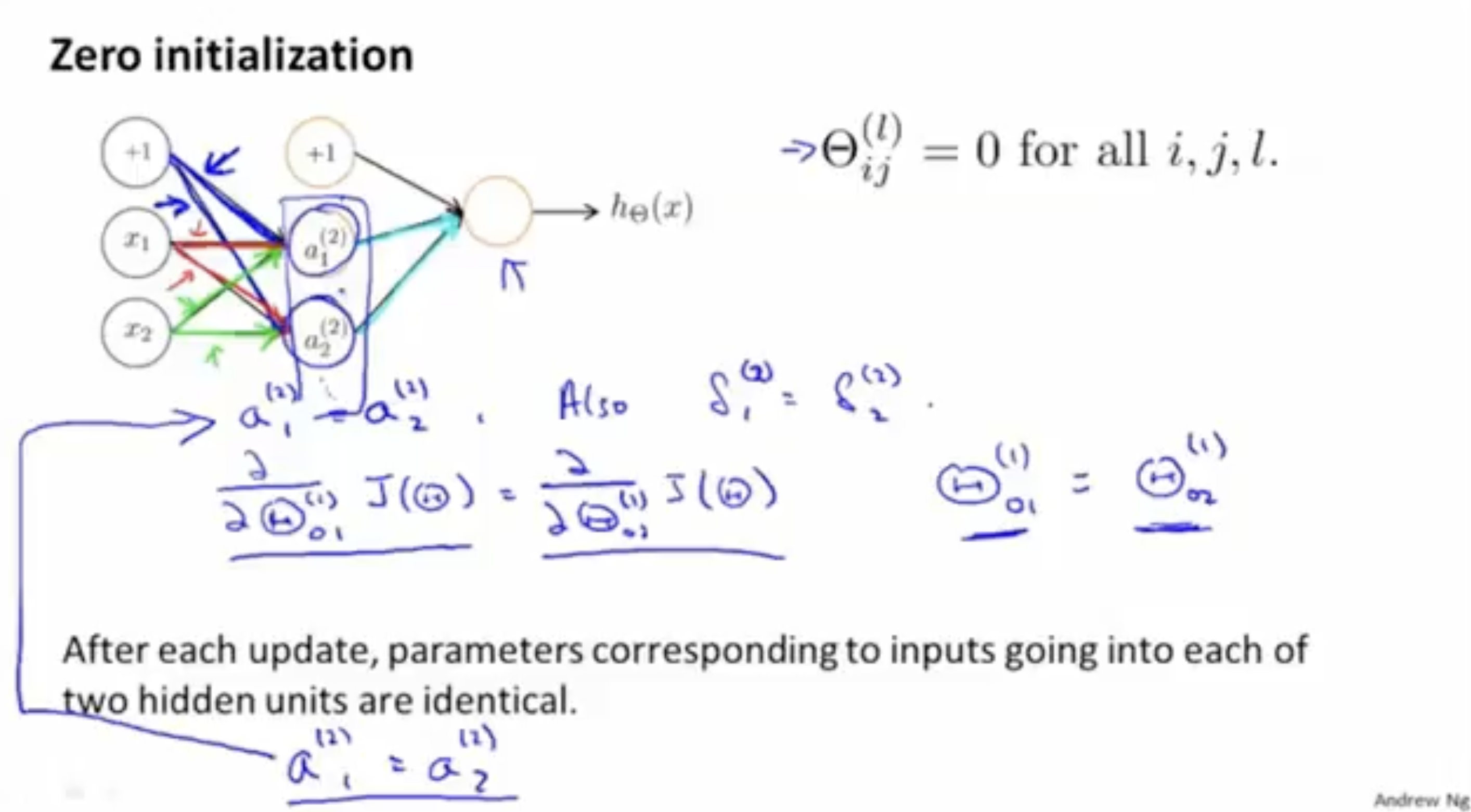
그렇다면 랜덤하게 값을 초기화하면 어떨까? 의 값을 매우 작은 범위의 랜덤값으로 세팅한다. 이렇게 되면 zero initialization에서 발생한 symmetry 문제를 해결할 수 있을 것이다.

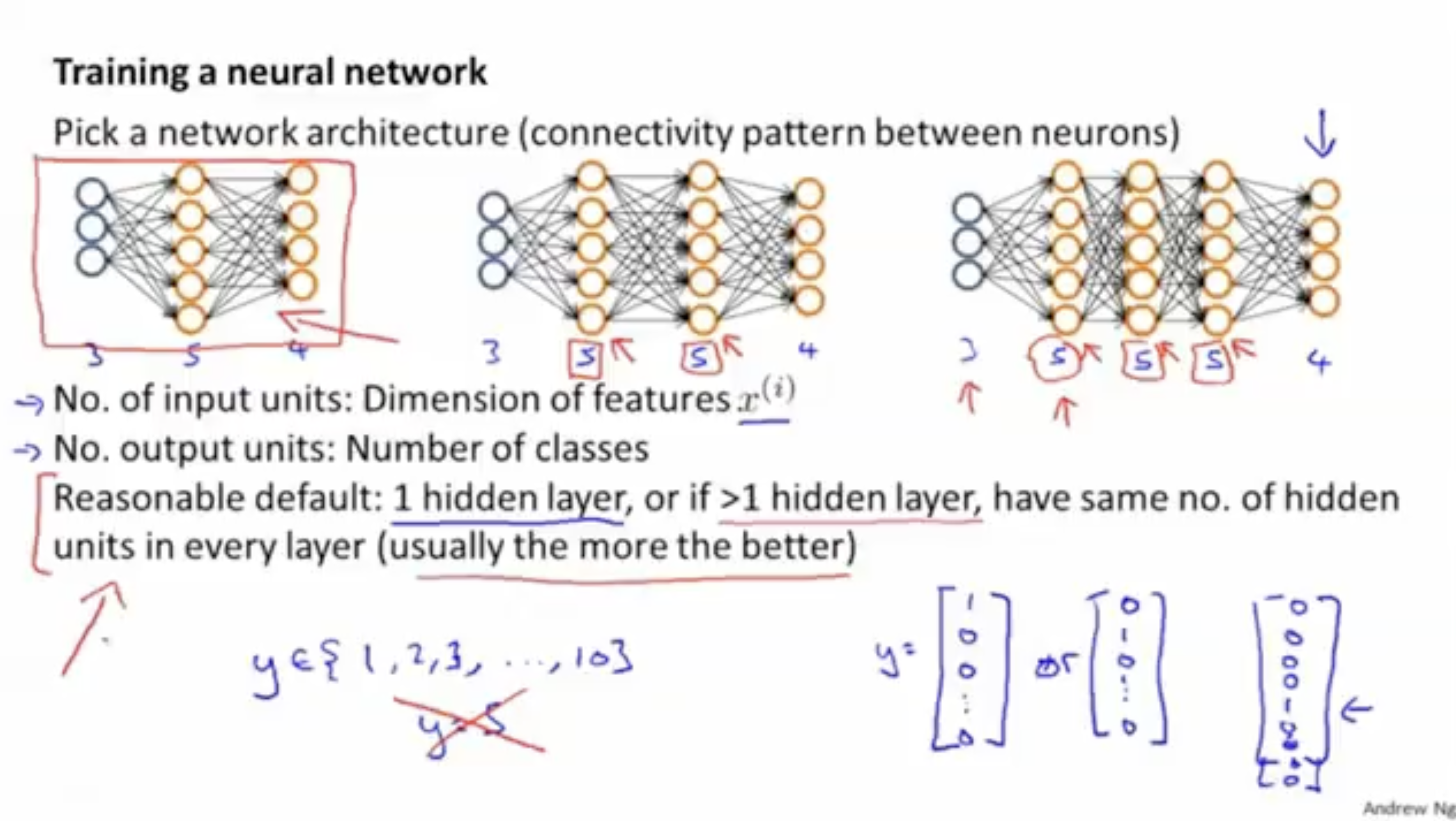
뉴럴넷의 구조에 대한 개요는 다음과 같다.
- 입력 유닛들의 수는 feature vector 의 차원에 따라 결정된다.
- 출력 유닛들의 수는 class들의 종류 수로 결정된다.
- 만약 히든 레이어가 1개일 경우, 특별히 유닛 수를 조정할 필요가 없다.
- 만약 히든 레이어가 2개 이상일 경우, 일반적으로 히든 레이어들의 유닛 수는 모두 동일하게 맞춰주는 편이 학습하는 데 효과적이다.
모델의 학습 과정은 다음과 같다.
1. 랜덤하게 초기 weights 값을 세팅한다.
2. forward propagation을 통해 입력 벡터 에 대한 결과값 의 값을 구한다.
3. 위에서 구한 유닛들의 값을 통해 cost function 를 구한다.
4. cost function 의 편미분 값을 계산하여 backpropagation을 진행한다.
5. gradient 값을 구한다. (보통 backpropagation을 사용한 방법으로 한다. )
6. gradient 값을 통해 gradient descent 방법을 적용하여 cost function 를 최소화하는 최적의 를 찾는다. (다만 뉴럴넷의 경우, local optima가 여러 개가 존재하는 non-convex 함수를 보여 준다.)


