https://www.youtube.com/watch?v=kX1yTdXq_Wc&list=PLiPvV5TNogxIS4bHQVW4pMkj4CHA8COdX&index=10
이제 머신러닝 알고리즘에 대해서 어떤 식으로 디버깅할 수 있는지 알아보자.
만약 학습된 머신러닝 알고리즘에서 큰 에러가 발생할 경우, 이를 어떻게 디버깅할 수 있을까?
아래는 여러 상황에 대한 해결책들이다.
- 학습 데이터를 더 추가한다.
- feature들의 집합을 축소한다.
- feature를 추가한다.
- 다항식 feature를 추가한다.
- regualrization parameter 값을 낮춘다.
- regualrization parameter 값을 높인다.

먼저, 우리가 개발한 머신러닝 알고리즘이 올바른지 아닌지 어떻게 판단할 수 있을까?
이를 위해 따로 알고리즘을 진단할 필요가 있다. 물론 진단에 비용이 들지만, 오히려 시간을 더 절약할 수 있다.

따라서 알고리즘의 정확도를 판단하기 위해, 전체 데이터셋을 "training set"(70%), "test set"(30%)으로 나눈다.
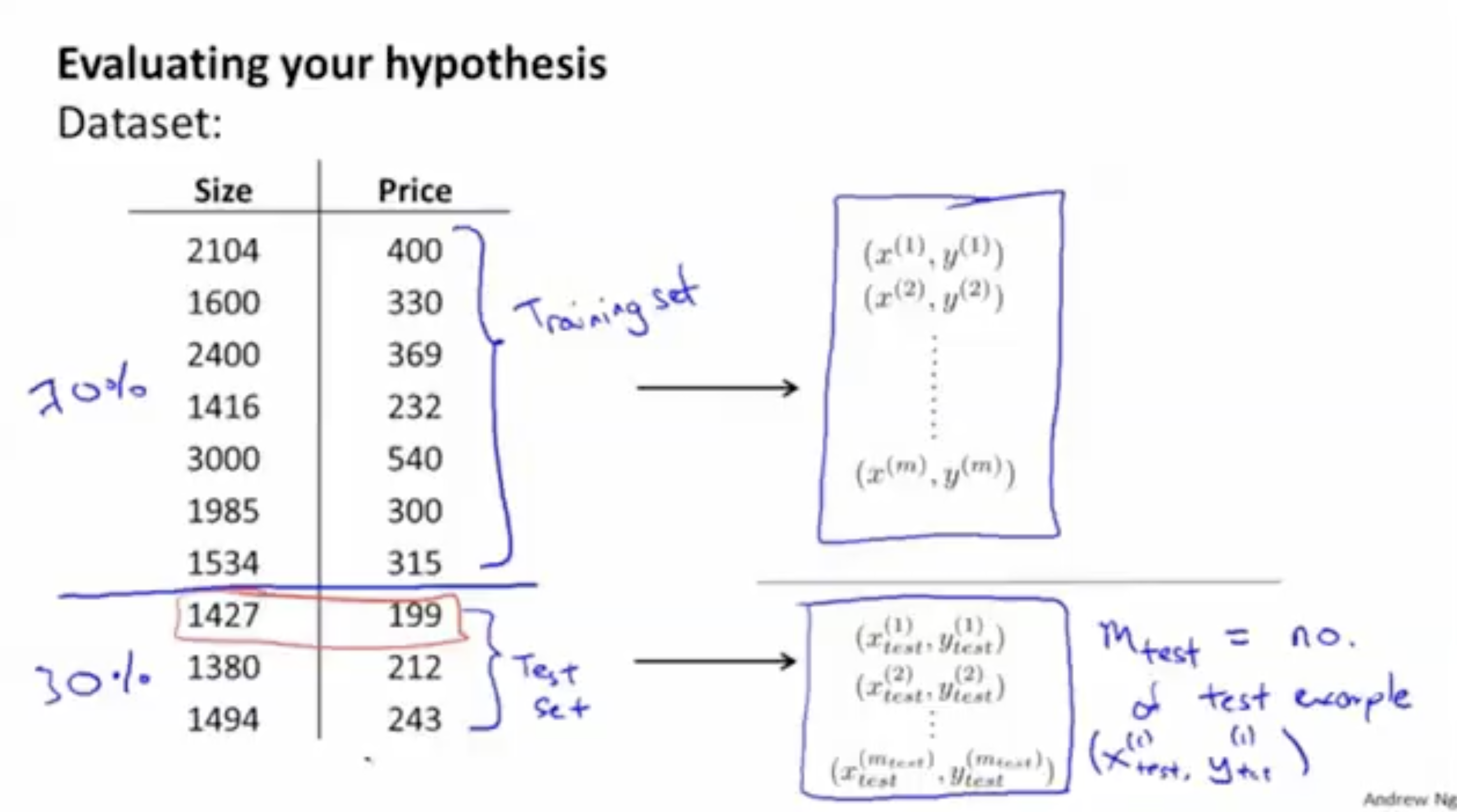
그런 다음, training set으로 를 최소화하는 최적의 파라미터를 찾으며, 학습을 한다.
그리고 test set으로 (오차 함수)의 값을 계산한다.
아래의 경우, linear regression에 대한 예시이다.

다음으로 logistic regression train/test 과정은 다음과 같다.
위와 유사하게 training set으로 최적의 파라미터 를 찾고 (학습하고), 이를 test set으로 계산하여 오차값을 구한다.
다만, linear regression과 달리 logistic regression은 (binary classification의 경우) 결과값이 0 또는 1이기 때문에, 잘못 분류된 개수를 기준으로 오차 정도를 측정한다.
- 만약 예측값이 1)"이고 실제값이 일 때" 혹은 2)"이고 실제값이 일 때", 이는 잘못 분류된 케이스로 카운트가 1이 된다.
- 반면에 잘 예측될 경우 카운트는 0이 된다.
- 따라서 이 경우 test error는 아래와 같다.

overfitting의 경우 training data set에 대해서는 값은 값보다 낮게 나올 것이다.

그렇다면 어떻게 모델을 잘 선택할 수 있을까? 아래 그림은 차수 에 따른 다양한 모델식을 보여준다.
각각의 차수 에 대해서 test를 한 결과, 식이 가장 정확도가 높게 나왔다고 가정해보자.
과연, 이 에 대한 모델은 정확도가 높다고 볼 수 있을까?
그렇지 않다. 왜냐하면 test set이 어떻게 구성되느냐에 따라 다른 를 갖는 모델이 test에 대한 정확도가 더 높게 나올 수 있기 때문에, 새로운 데이터에 대해서도 모델이 가장 높은 정확도를 보여준다고 장담하기 힘들다.

따라서, 이를 위해 "cross validation set (cv)"를 추가해줘야 한다.
전체 데이터셋은 일반적으로 다음과 같이 분할된다.
- train set : 60%
- cross validation set : 20%
- test set : 20%

마찬가지로 각 데이터셋에 대해서 error function 를 구해야 한다.

이제 아까의 과정을 똑같이 적용해서 모델이 가장 높은 정확도를 보여준다는 것을 얻었다고 가정해보자. 이 경우 cross validation set에 대한 오차를 기준으로 가장 잘 나왔기에, test set에 대한 오차를 계산함으로써 일반적인 generalization 오차를 추정할 수 있다.

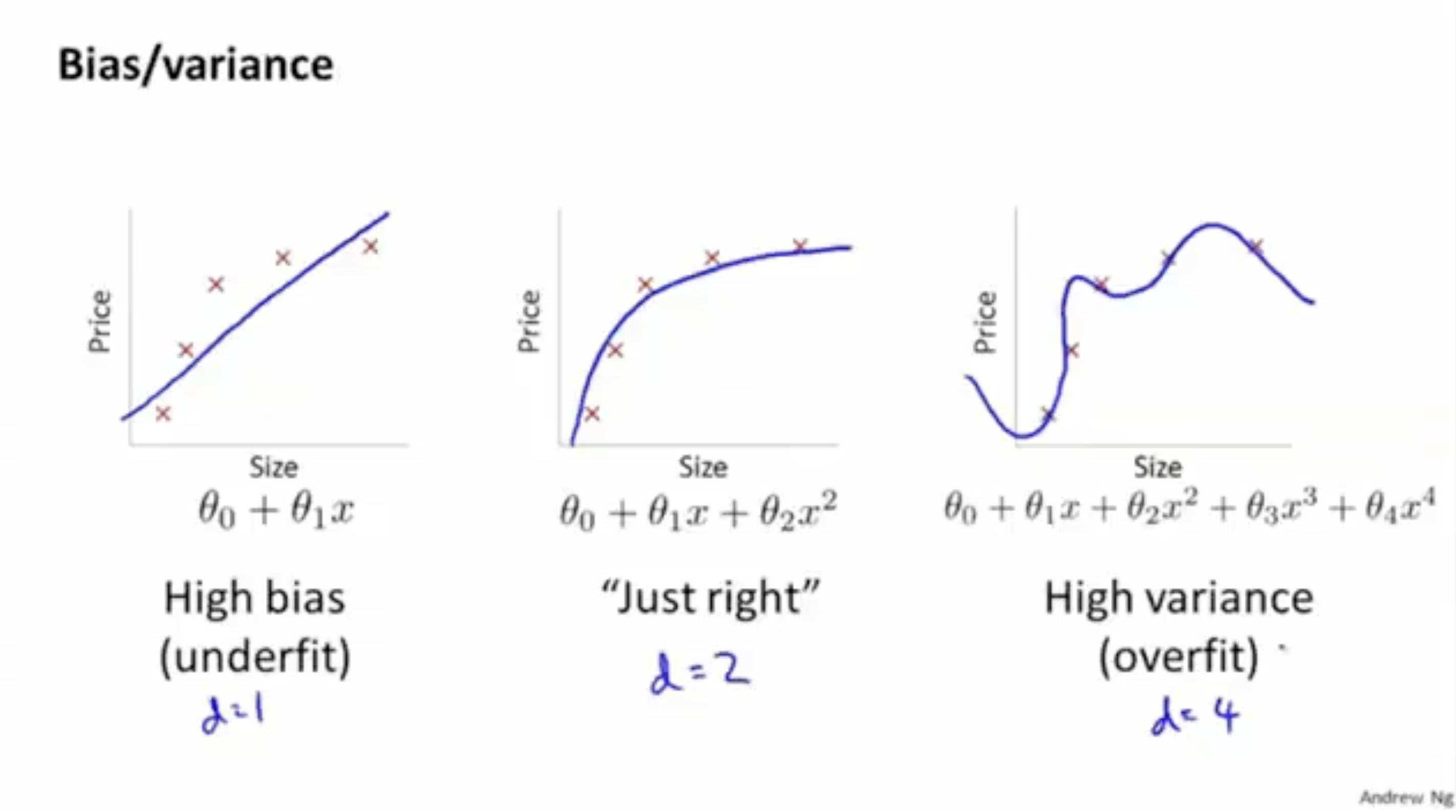
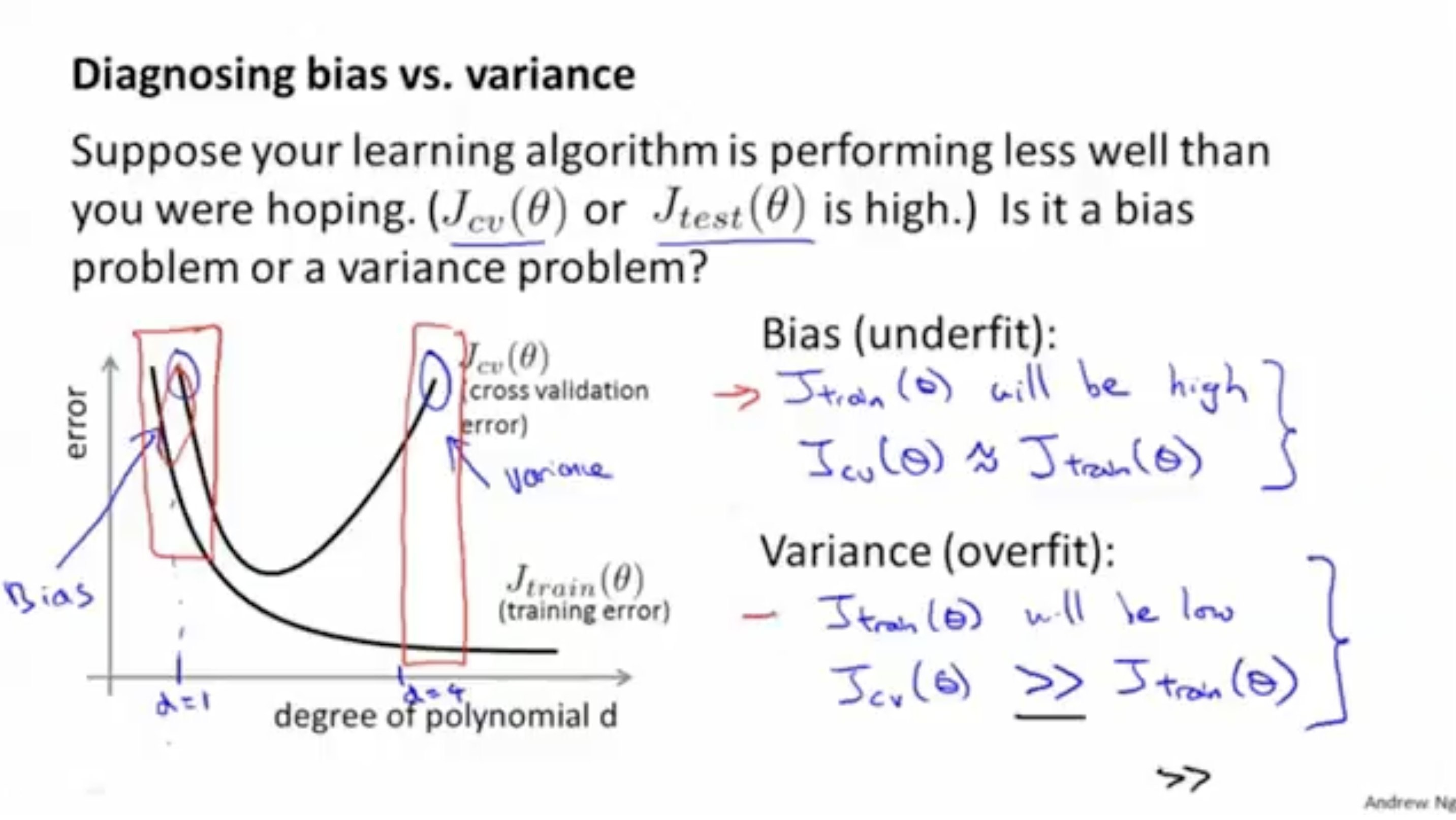
이제 bias와 variance에 대해서 복습해보자. 아래 그림은 각각의 예시를 보여준다.
차수 가 너무 낮으면 high bias (underfitting) 문제가 발생하고, 반대로 차수 가 너무 높으면 high variance (overfitting) 문제가 발생한다.
그리고 아래 그래프는 차수 에 따른 training error 와 cross validation error 값을 보여준다.
- train error 의 경우, 차수 가 커질수록 fit 정도가 커지고, 이로 인해 에러값은 낮아진다. 만약, 가 매우 커지면 overfitting 문제가 발생할 수 있다.
- cross validation error 의 경우, 차수 가 너무 작거나 (underfitting) 혹은 너무 크면 (overfitting) 에러값이 높아진다.
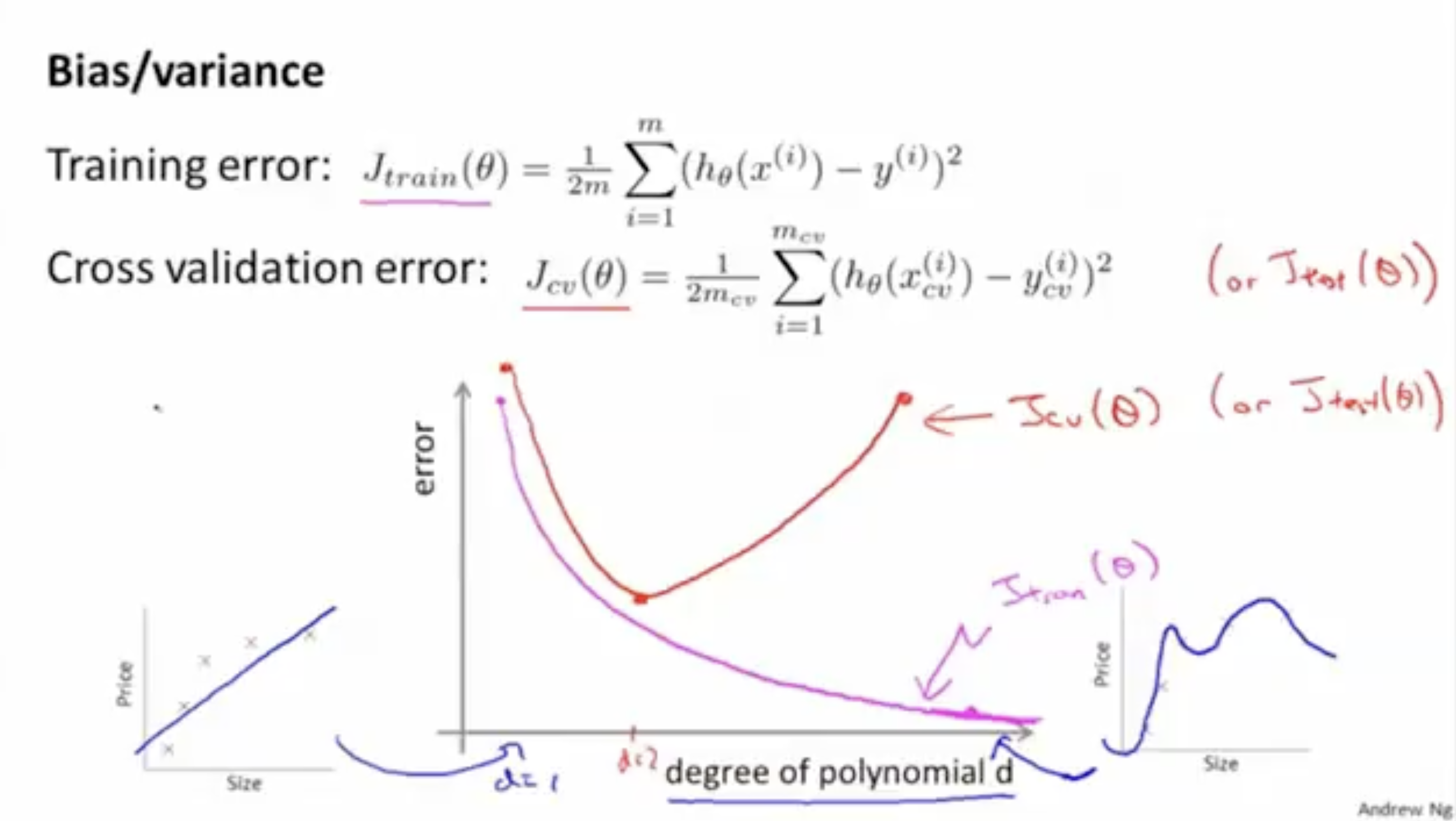
따라서 train error와 cross validation error 값을 보면서, 해당 차수 모델이 high-bias(underfitting)인지 high-variance(overfitting)인지 아니면 최적인지 등을 판단할 수 있다.
- 만약 high-bias라면, and 와 같은 결과가 나올 것이다.
- 만약 high-variance라면, and 와 같은 결과가 나올 것이다.
그렇다면 이제 regularization을 판단하는 방법을 알아보자.
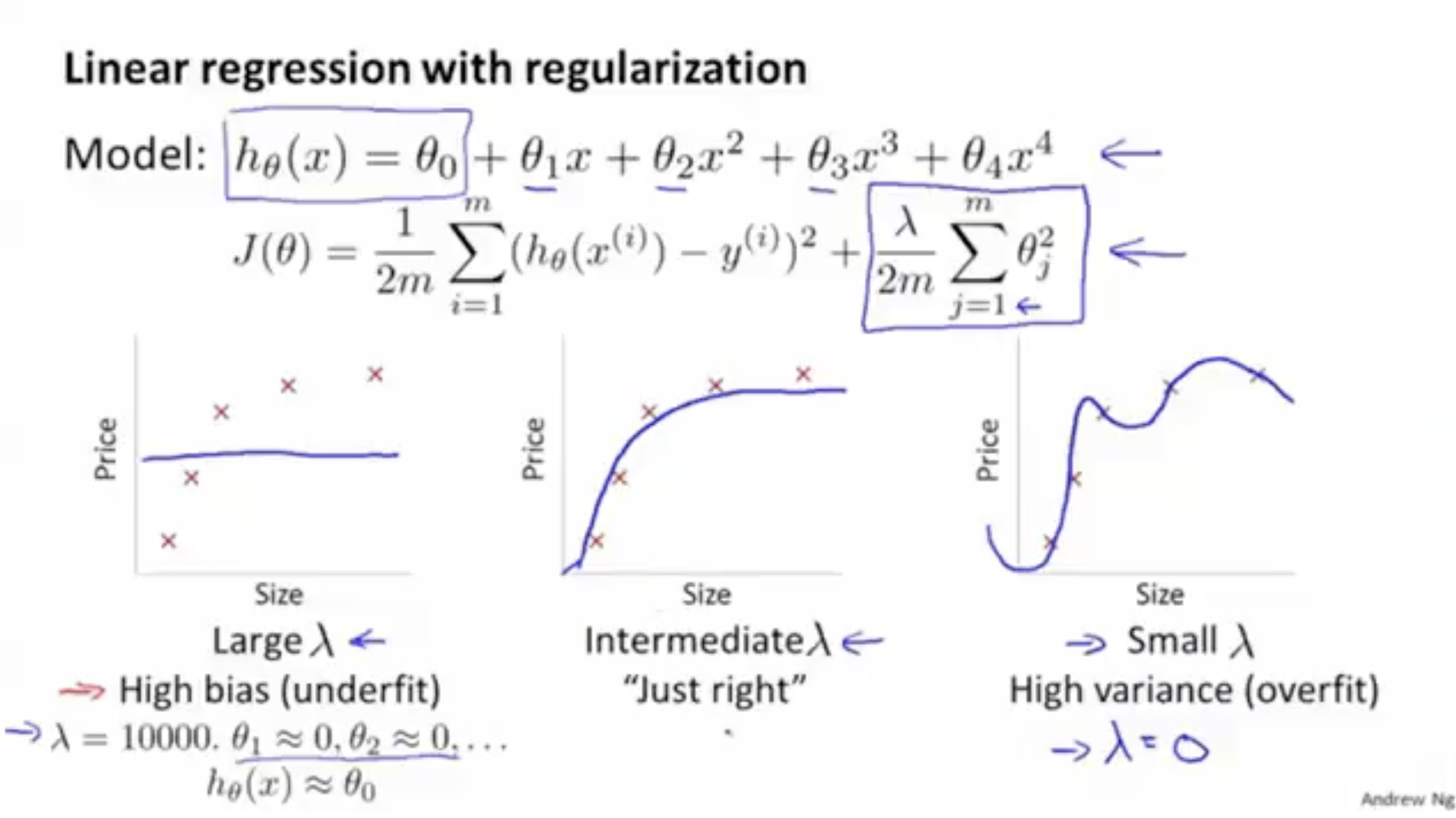
아래 그림은 linear regression에 대한 regularization의 예시이다.
- regularization parameter 가 너무 크면 모델은 와 같이 나올 것이고, 이는 high-bias를 의미한다.
- regularization parameter 가 너무 작으면 모델은 매우 많은 파라미터 들을 가질 것이고, 이는 high-variance를 의미한다.
구체적인 수식 예시는 다음과 같다. train, cross validation, test 데이터셋에 대해서 모두 적용한다.
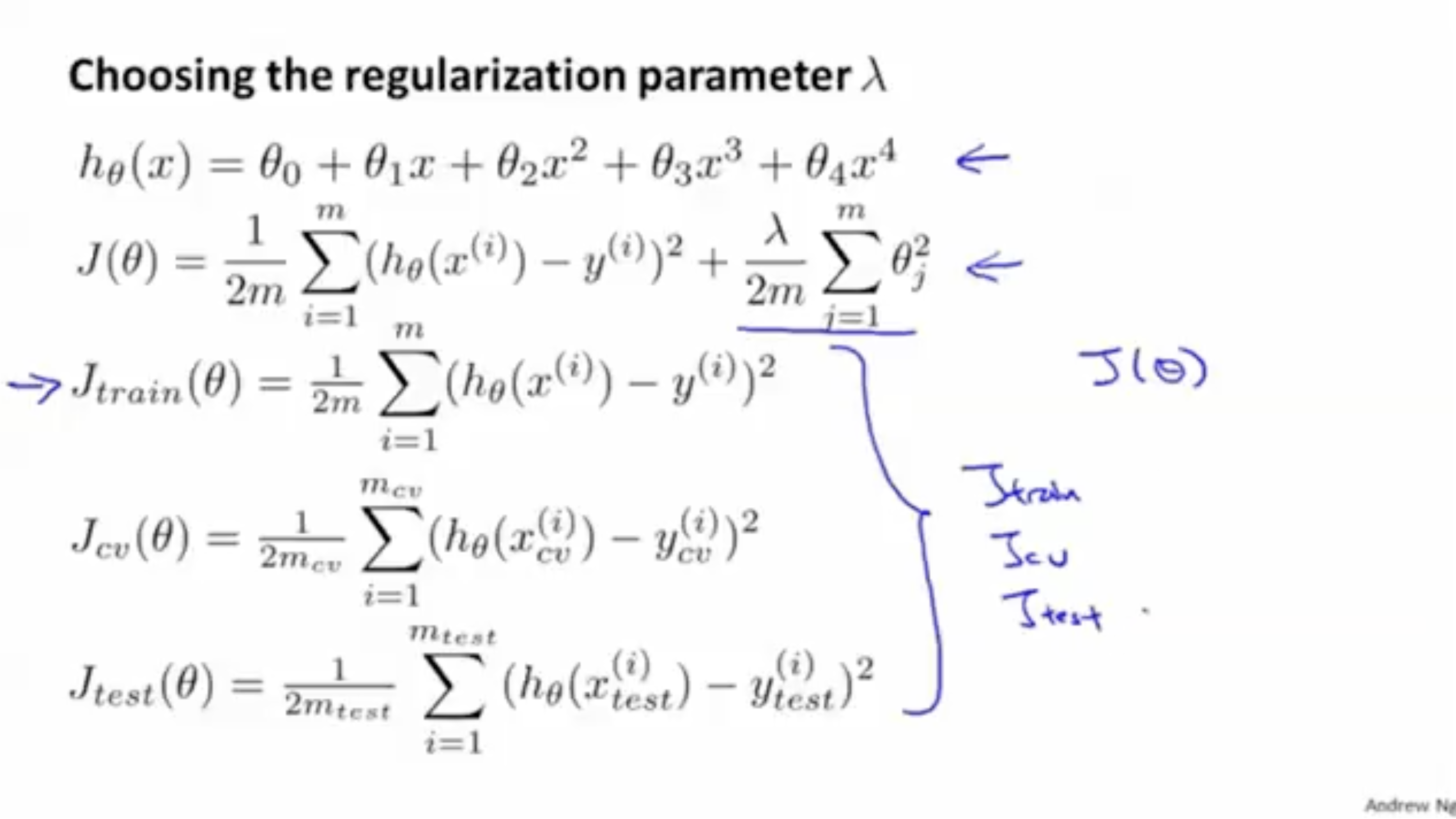
이제 값을 다양하게 하여 모델에 적용했을 때, cross validation error에 대해서 일 때가 가장 최적의 인 가 나왔다고 가정해보자. 그리고 해당 를 가지고 와 test error를 구한다.

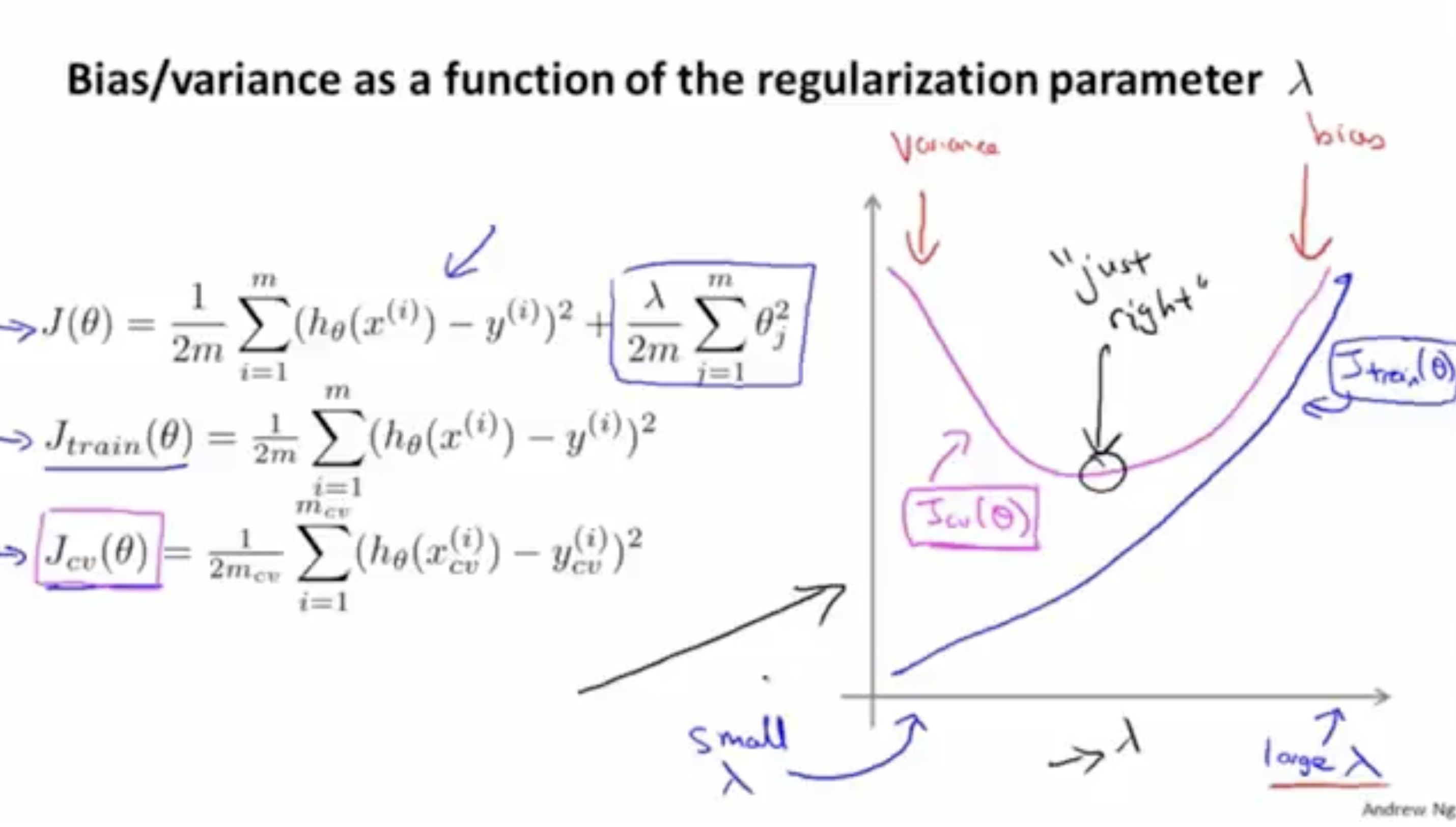
그리고 아래 그림을 통해 값에 따른 모델의 bias, variance 정도 그래프를 볼 수 있다.
- 의 경우,
값이 작을 때는 에러값이 낮지만(왜냐하면 높은 비중으로 적용되는 파라미터 수가 많기 때문에),
값이 클 때는 (파라미터 수가 적기 때문에) 에러값이 높아지는 것을 볼 수 있다.
따라서, 값이 작을 때는 high-bias, 값이 클 때는 high-variance 문제가 발생할 수 있다.- 의 경우,
값이 너무 작을 때와 너무 클 때 모두 에러값이 높게 나온다.
즉, 값이 너무 작을 때는 high-bias, 값이 너무 클 때는 high-variance 문제가 발생할 수 있다.
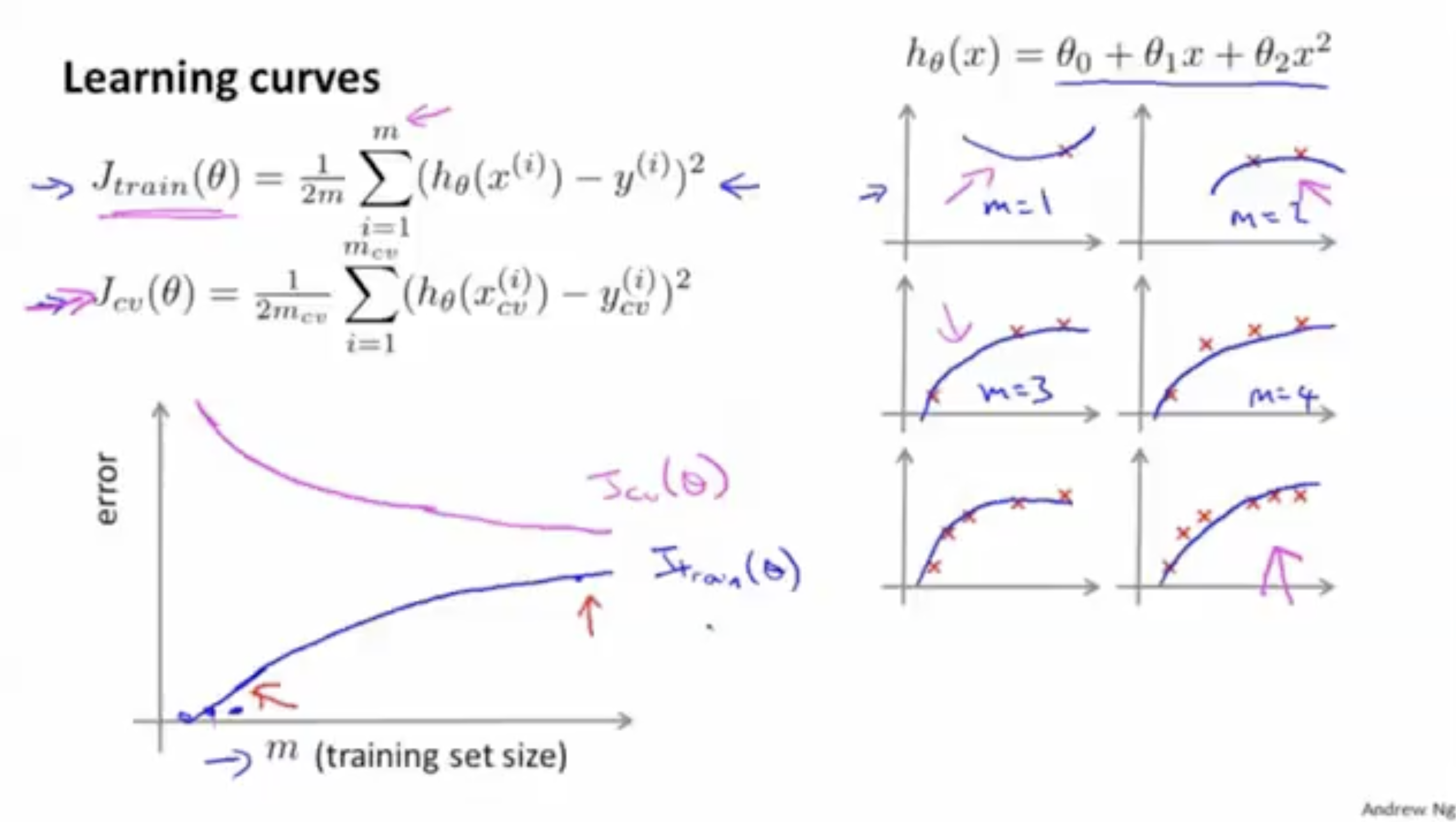
이제 learning curve에 대해서 알아보자. 아래 그림은 일반적인 경우의 learning curve를 보여준다.
- 는 학습 데이터셋인 training set의 크기 이 작을 때는 에러가 높지만, 이 커질수록 에러값이 낮아진다.
- 는 이 작을 때는 에러가 거의 없지만, 이 커질수록 에러값이 커진다.
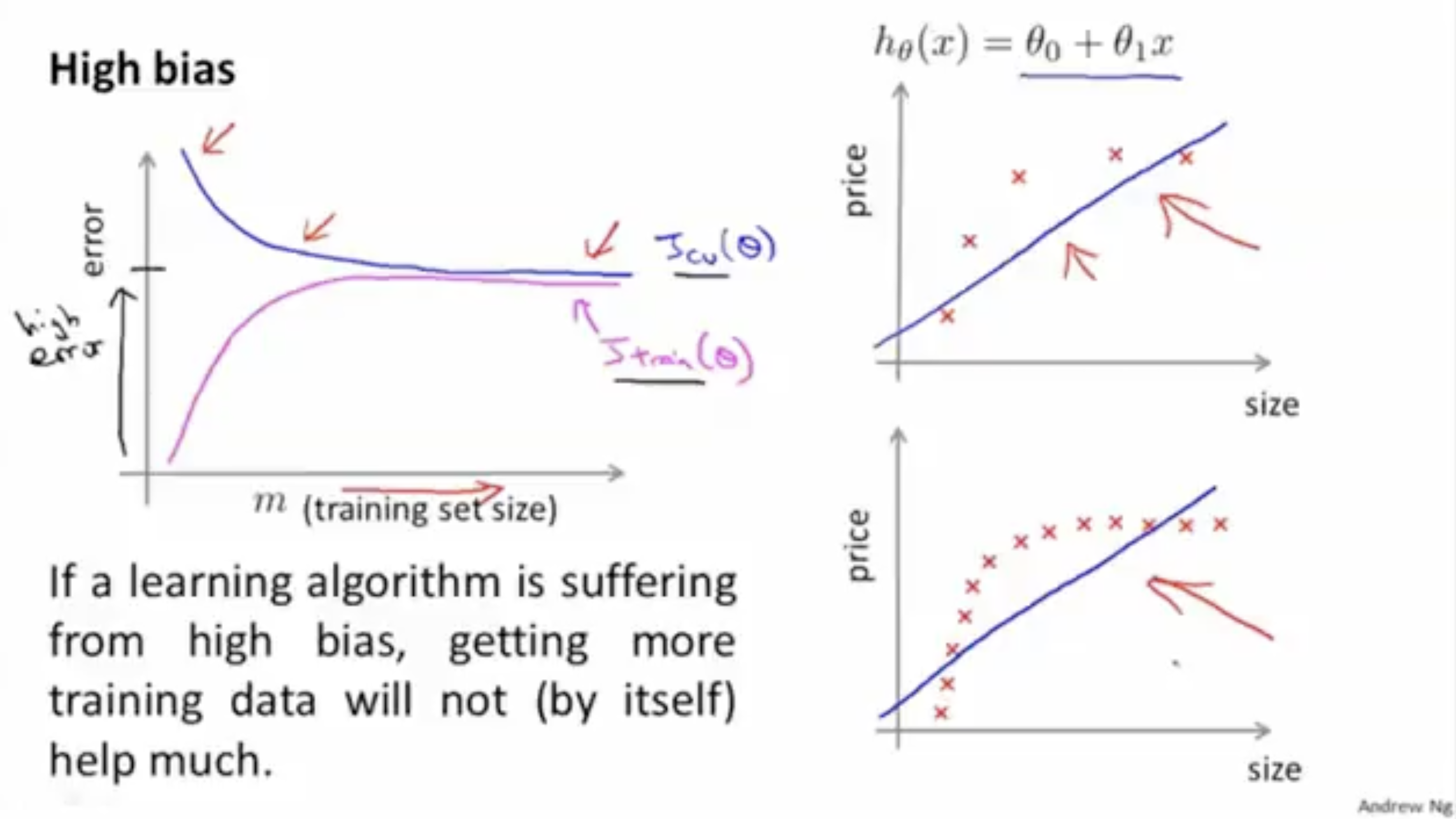
high-bias일 경우,
- 는 이 커져도 에러값이 높게 유지된다.
- 는 이 작을 때는 에러값이 낮지만, 이 커질 경우 에러값이 빠르게 높아지며, 와 값의 차이가 거의 없어진다.
- 그리고 training data set을 더 추가해도 문제는 해결되지 않는다.
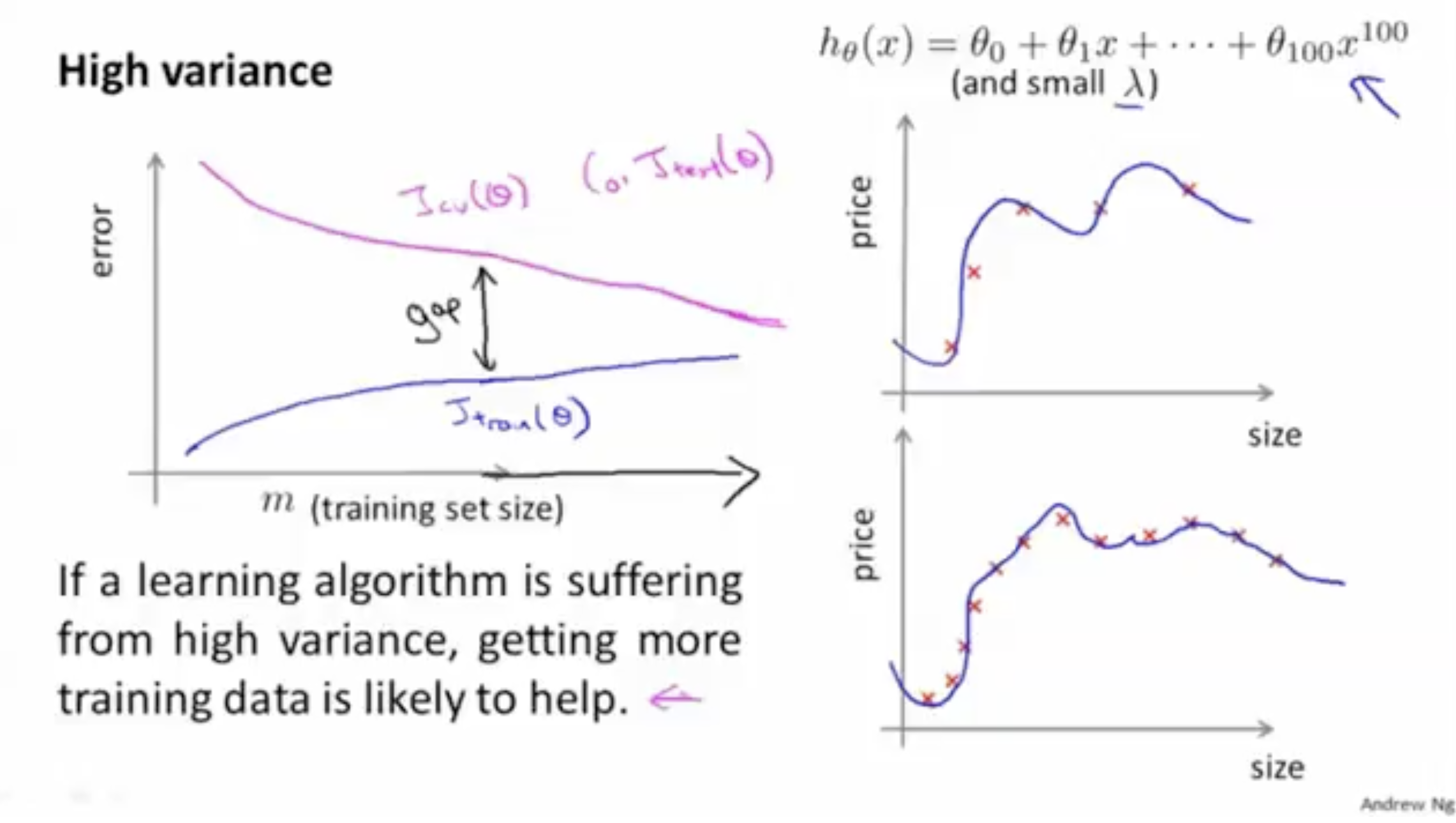
high-variance의 경우,
- 는 높은 에러값을 보이고,
- 는 낮은 에러값을 보여준다.
- 하지만 training data set을 추가할수록 (이 커질수록) 두 값의 차이는 점점 줄어들 것이다. 그리고 high-variance의 문제를 해결할 수 있을 것이다.
따라서 learning algrithm을 디버깅하는 방법들을 자세히 살펴보면 다음과 같다.
- 학습 데이터 추가 : high variance 문제 해결
- feature 수 줄이기 : high variance 문제 해결
- feature 추가 : high bias 문제 해결
- 다항식 feature 추가 : high bias 문제 해결
- regularization parameter 값 감소시키기 : high bias 문제 해결
- regularization parameter 값 증가시키기 : high variance 문제 해결

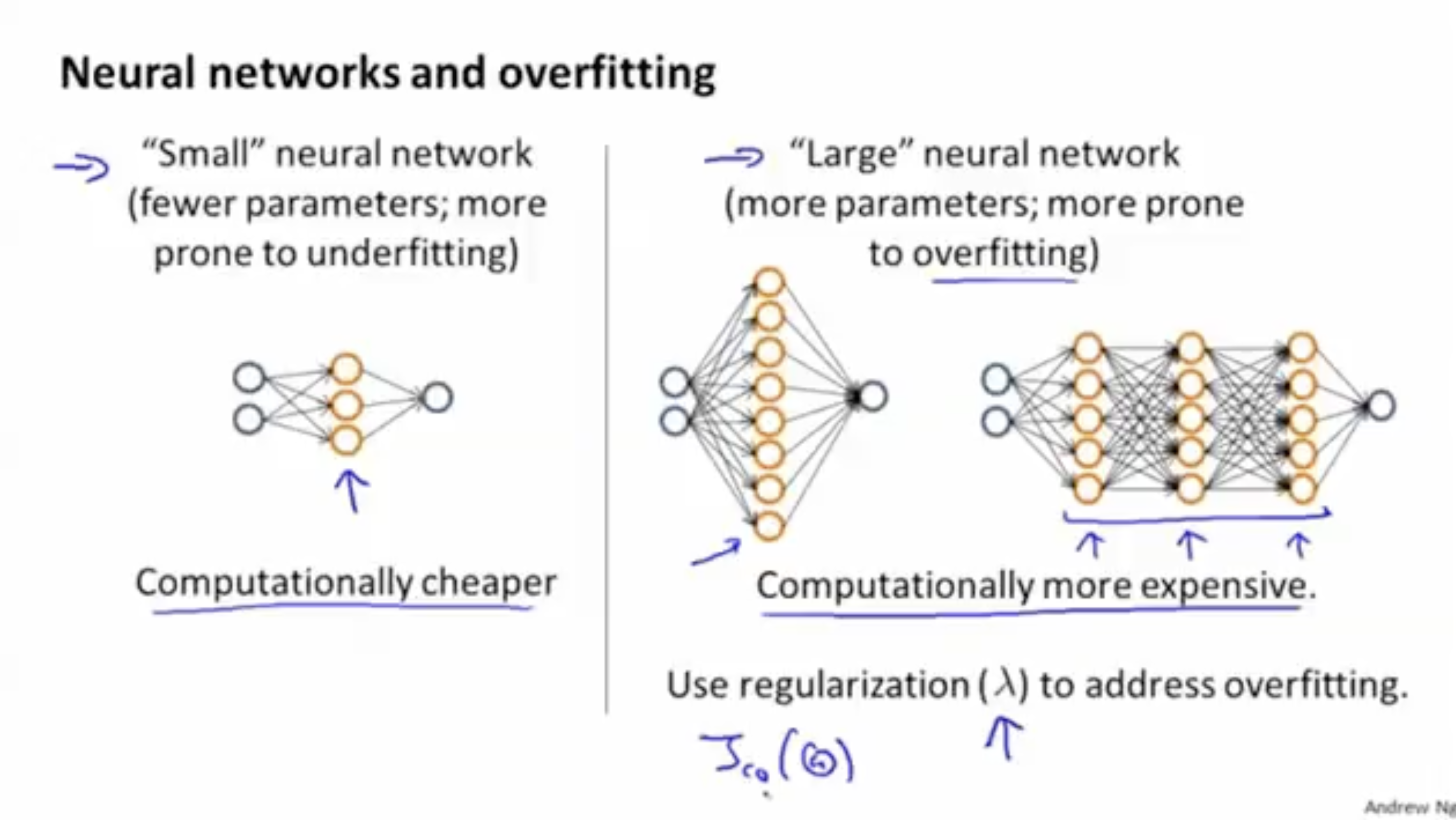
regression 방법과 마찬가지로 neural networks에서도 underfitting 문제와 overfitting 문제가 존재한다.
- 너무 적은 hidden layer 및 units는 underfitting 문제를 일으킬 수 있고, (다만 비용은 적게 들지만)
- 너무 많은 hidden layer 및 units는 overfitting 문제를 일으킬 수 있다. (비용이 많이 든다.)
따라서 이 경우, regularization parameter 값을 증가시킴으로써, overfitting 문제를 해결할 수 있을 것이다.