https://www.youtube.com/watch?v=_GvMC0ZYvK8&list=PLoR5VjrKytrCv-Vxnhp5UyS1UjZsXP0Kj&index=18
OCR은 Optical Chacracter Recognition의 약자로, 이미지를 읽어서 텍스트 데이터로 추출하는 방법을 의미한다. 아래 예시는 이미지에서 text를 추출하는 예시이다.

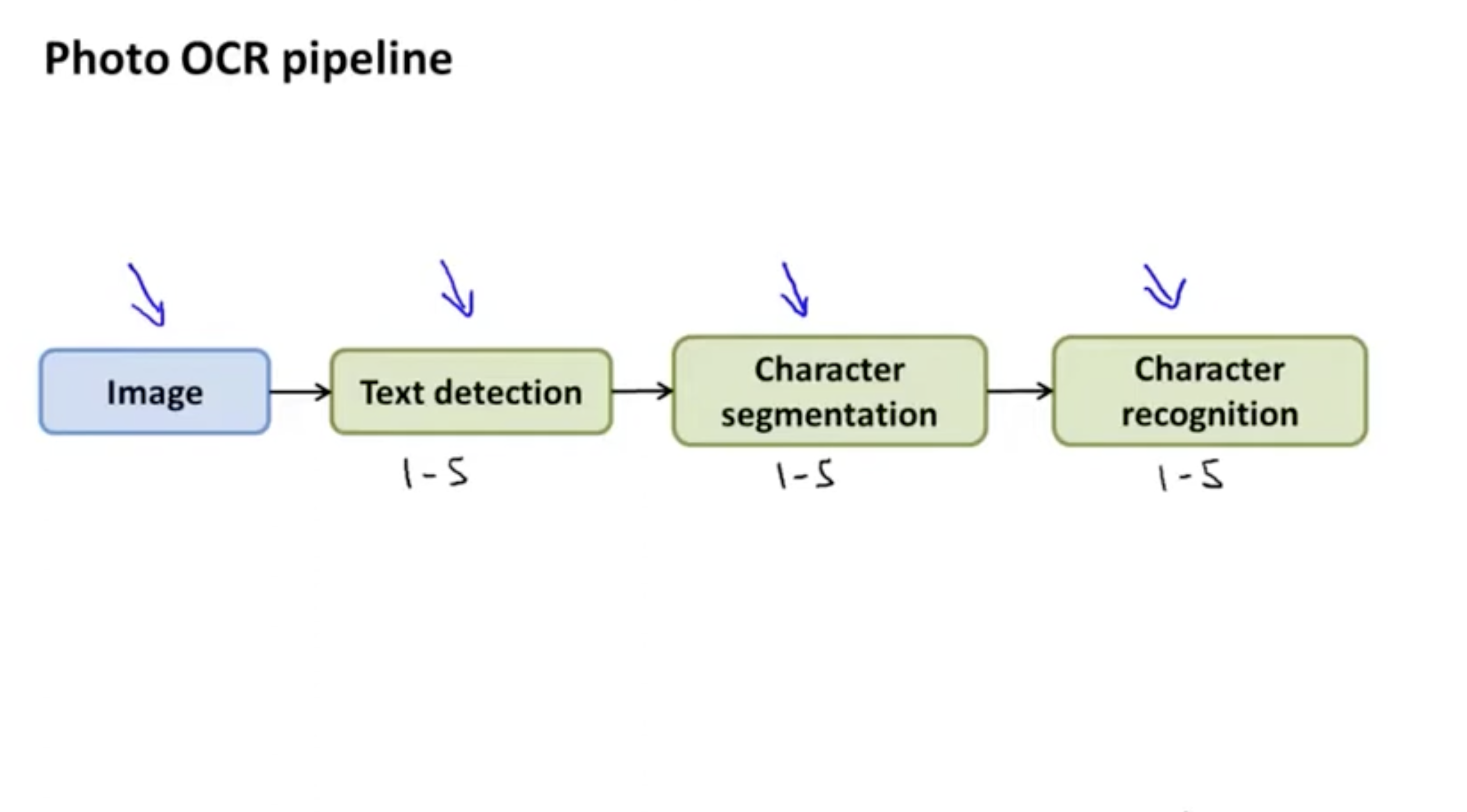
Photo OCR pipeline은 아래와 같다.
1. 텍스트 탐지
2. 문자 세그멘테이션 (각 문자를 하나의 객체로 분할)
3. 문자 분류

파이프라인을 쉽게 정리하면 아래와 같다.
- 이미지 입력 -> 텍스트 탐지 -> 문자 세그멘테이션 -> 문자 분류
- 그리고 보통 파이프라인의 각 단계는 1~5명으로 이루어진 팀에서 각각 이뤄진다.
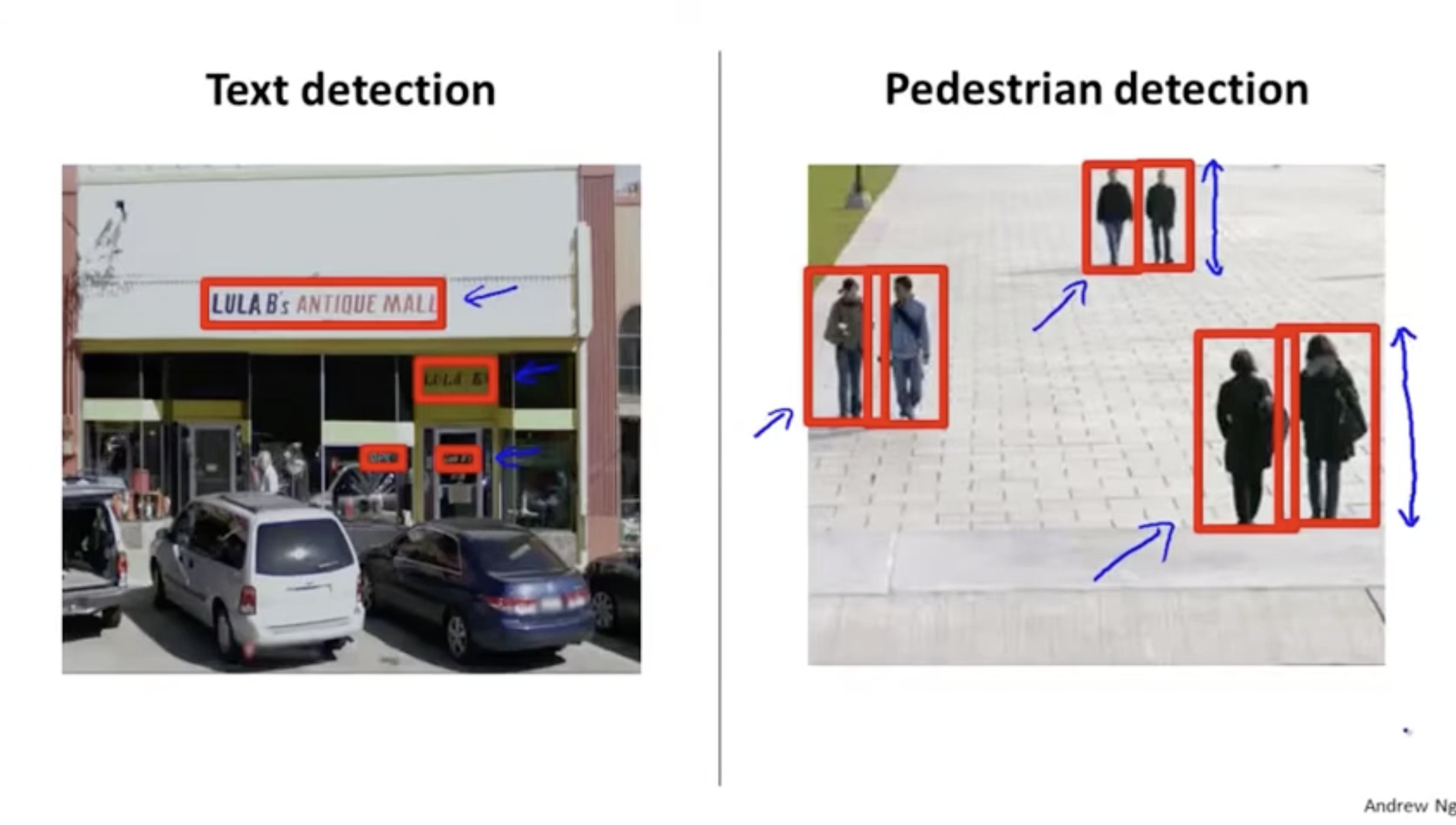
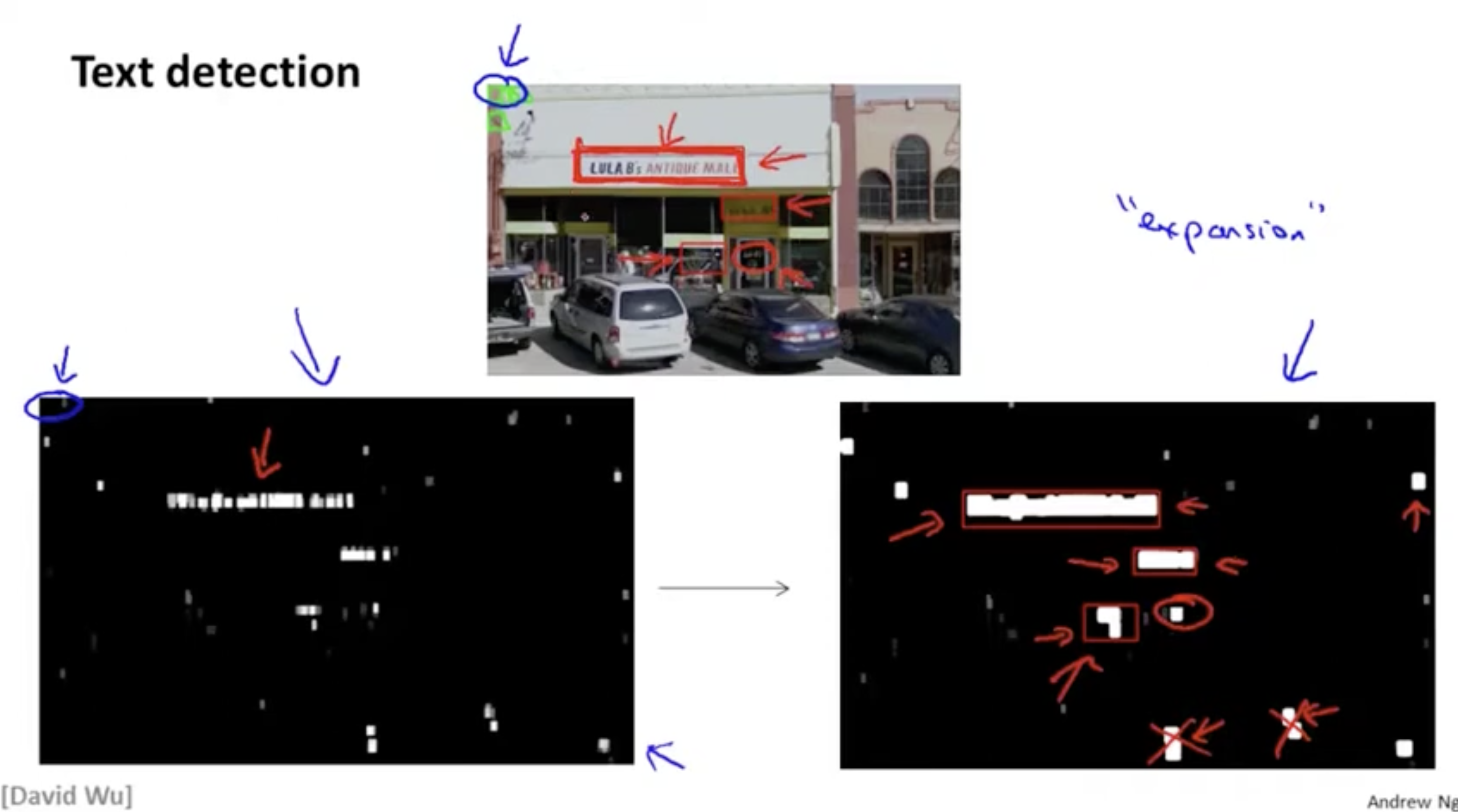
그렇다면 파이프라인 각 단계를 구체적으로 살펴보자. 먼저 텍스트 탐지이다.
텍스트 탐지는 우측과 같이 보행자 탐지에 적용하는 것과 같은 기술을 사용한다.
보행자 탐지는 supervised learning으로 같은 픽셀 사이즈를 같는 positive()에 해당하는 이미지 데이터들과 negative()에 해당하는 이미지 데이터들을 가지고 학습한다.

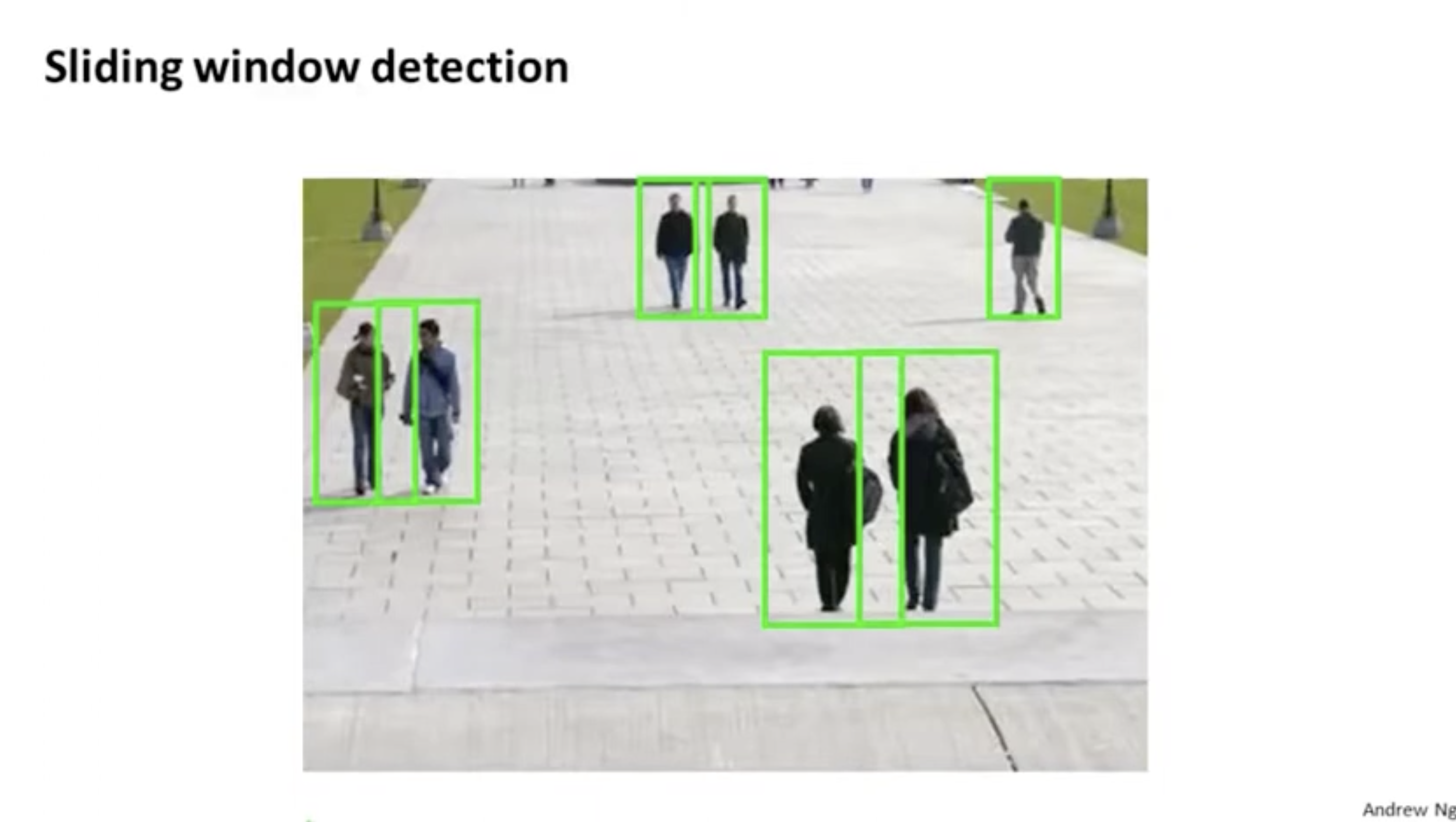
그런 다음 "sliding window detection" 방식으로 이미지에서 보행자 객체를 탐지한다.
sliding window detection은, 아래와 같이 이미지에서 그린색 윈도우를 step-size(stride)에 따라 움직이며 해당 윈도우 내에서 detection이 이뤄지는 것을 의미한다.

아래와 같이 윈도우 크기를 늘려서도 진행한다.

그렇게 작은 윈도우 및 큰 윈도우 등에 대해서 sliding window detection을 적용하면 아래와 같이 보행자에 해당하는 영역을 탐지할 수 있다.
위 보행자 탐지와 마찬가지로 텍스트 탐지도 똑같은 방식으로 적용하면 된다. positive()에 해당하는 텍스트 이미지와 negative()에 해당하는 이미지를 가지고 supervised learning 기반의 모델을 구축한다.

그런 다음 전체 이미지에서 sliding window detection 방법을 적용하여 text에 해당하는 부분들을 좌측 아래와 같이 하얀색으로 표시한다. 그런 다음, 해당 하얀색 주변 데이터들을 expansion하여 텍스트 탐지 영역을 늘린다. (이때, 다양한 텍스트 영역이 생길 수 있는데 보통 텍스트는 세로보다 가로 길이가 더 긴다는 특징을 이용하여 이에 해당하지 않는 영역은 제외할 수 있다.)
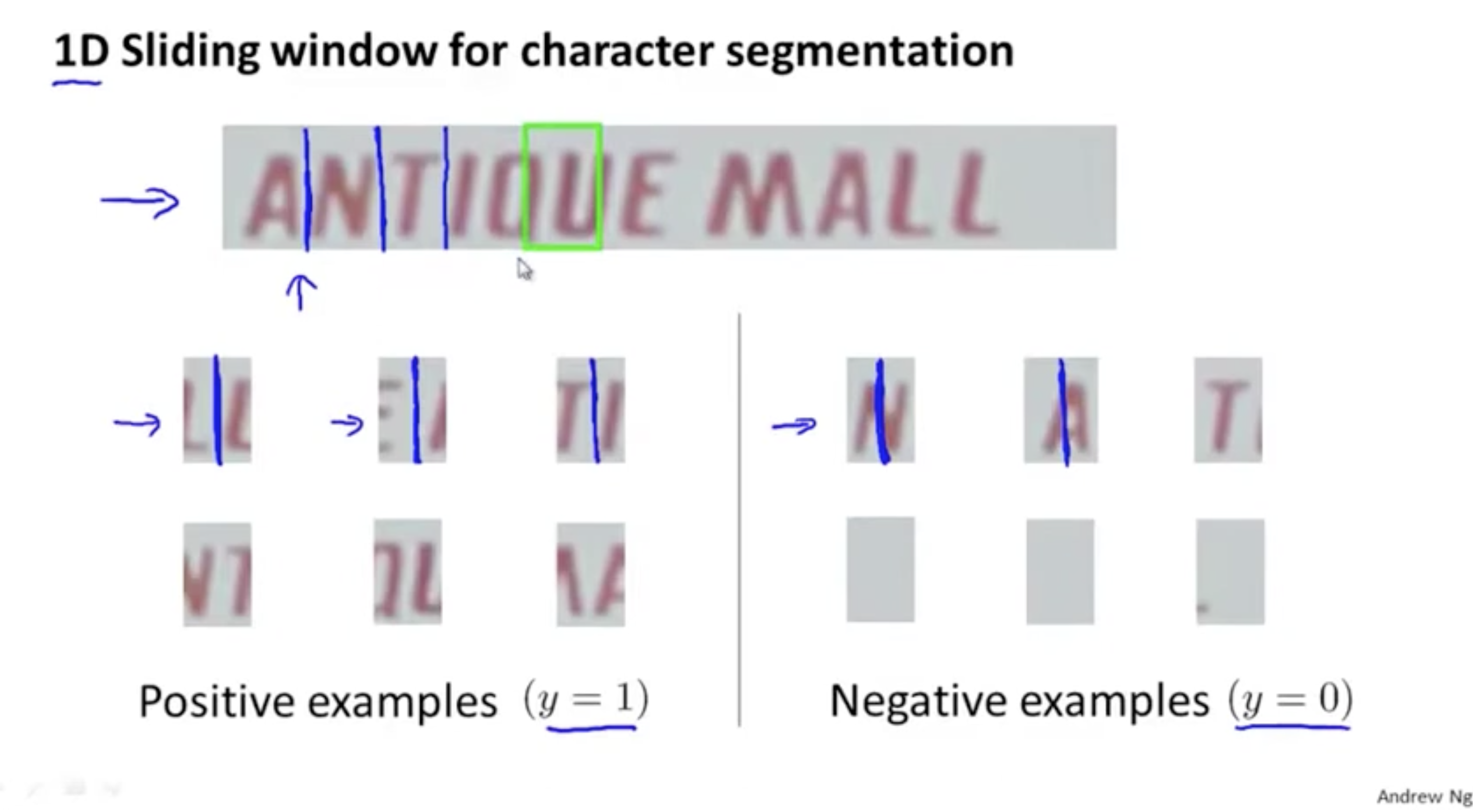
다음으로 문자 세그멘테이션 단계를 살펴보자. 아래 그림과 같이 supervised leraning 방식을 적용하며, 중간 세로선을 기준으로 두 문자가 나눠지는 positive() 이미지 데이터와 그렇지 않은 negative() 데이터를 가지고 세그멘테이션을 할 수 있는 모델을 구축한다.
- 그런 후 위에서 구한 텍스트 영역에 대한 sliding window를 진행하며 각 문자 객체를 분할한다.
따라서 다시 한 번 정리하면,
1. 텍스트 영역 탐지
2. 텍스트 영역 -> 문자 세그멘테이션
에서 1, 2 단계는 sliding window 방식을 통해 구현할 수 있었다.
그리고 이제 3. 문자 분류를 살펴 볼 예정이다.
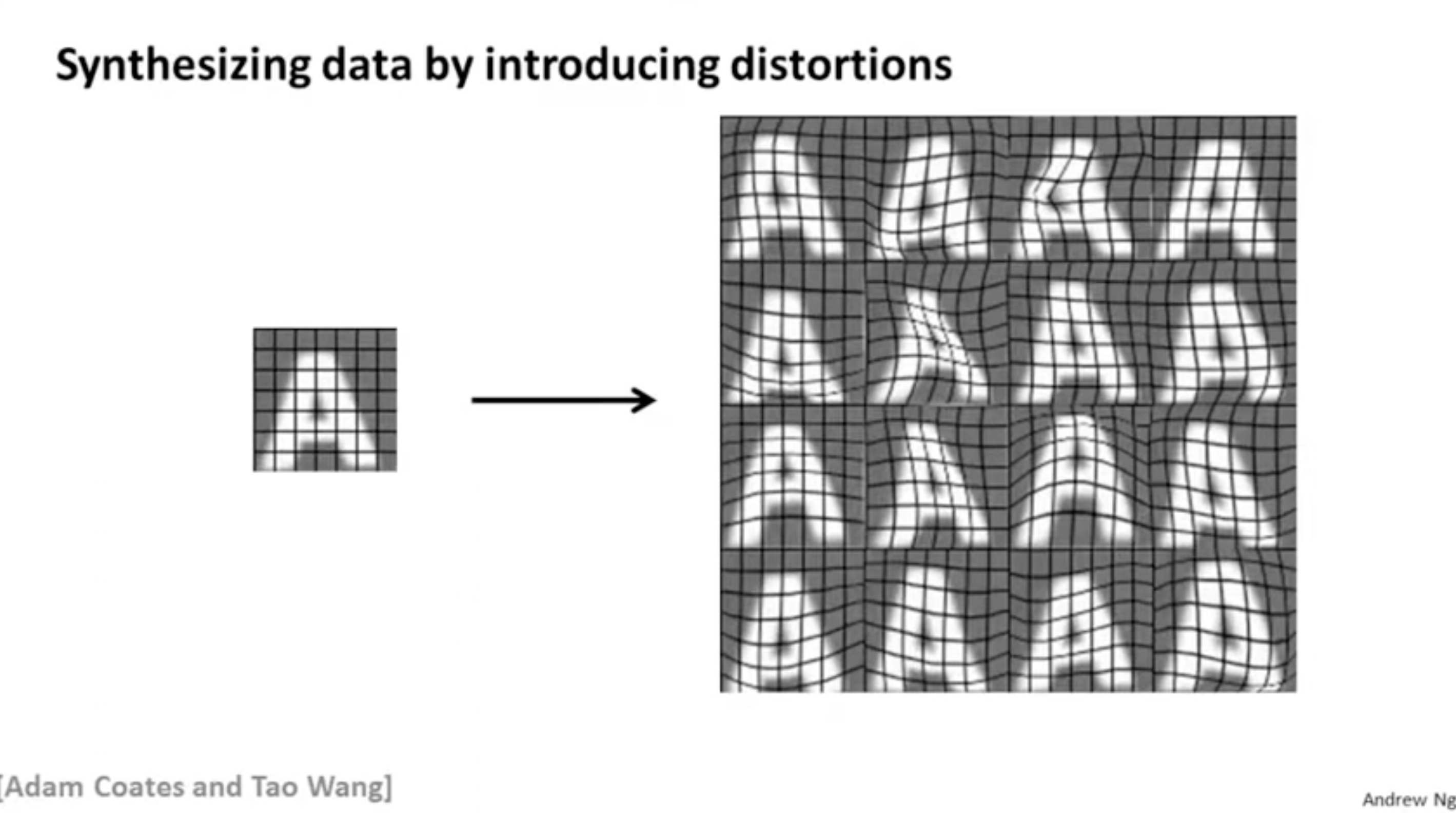
"data synthesis" 방식을 통해 아래와 같이 문자 인식을 할 예정이다.
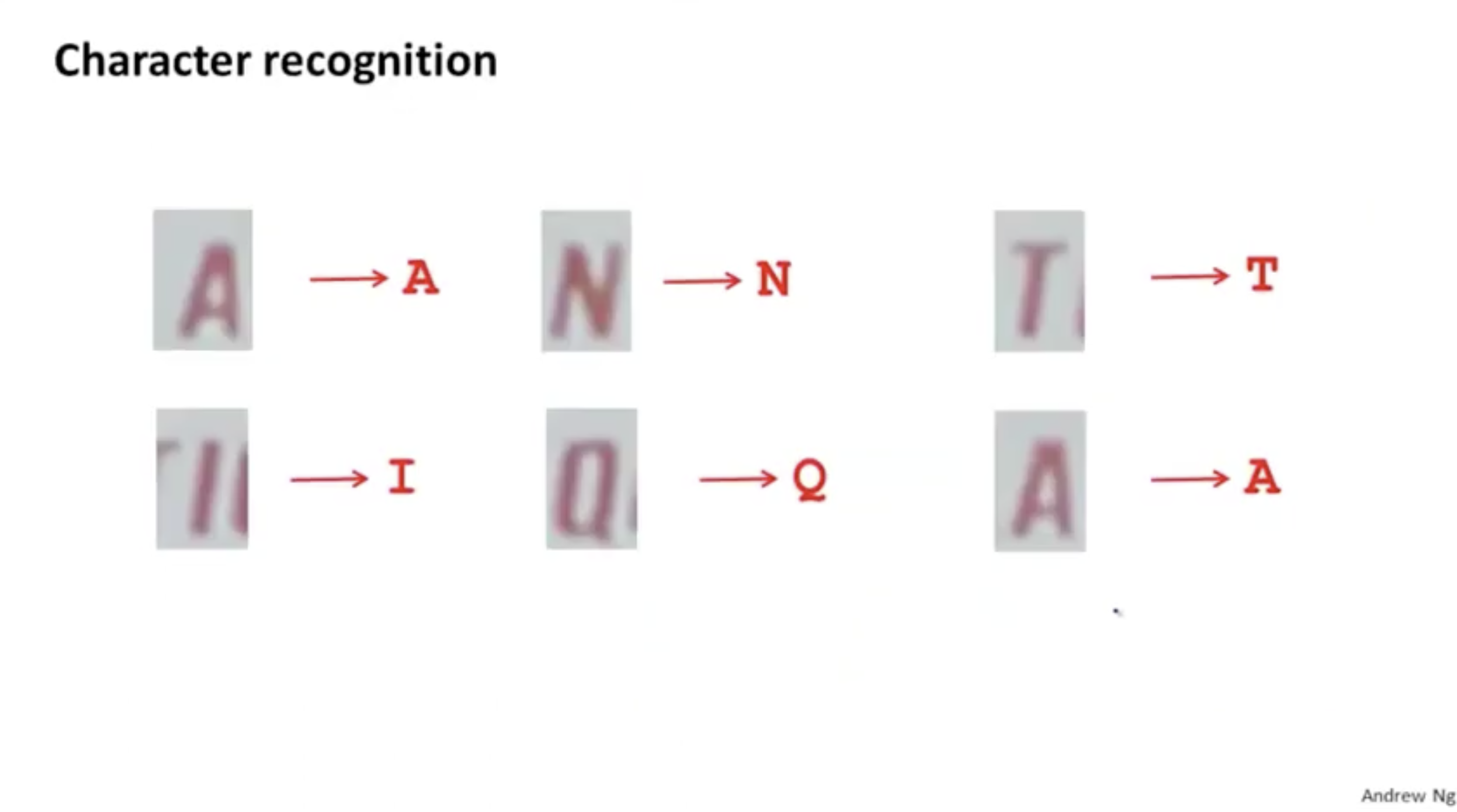
일반적으로 글자는 폰트에 따라 다양한 방식으로 표기된다. 따라서 이를 고려해야 한다.

블러 처리, 랜덤 폰트 적용 등을 통해서 (data synthesis를 통해서) 학습을 위한 새로운 데이터를 생성한다.

아래는 warping distortion을 통한 data synthesis의 예시이다. 원래 데이터에서 총 16개의 데이터를 뽑아내는 것을 보여 준다.