https://www.youtube.com/watch?v=ed4whd9B-xw&list=PLoR5VjrKytrCv-Vxnhp5UyS1UjZsXP0Kj&index=17
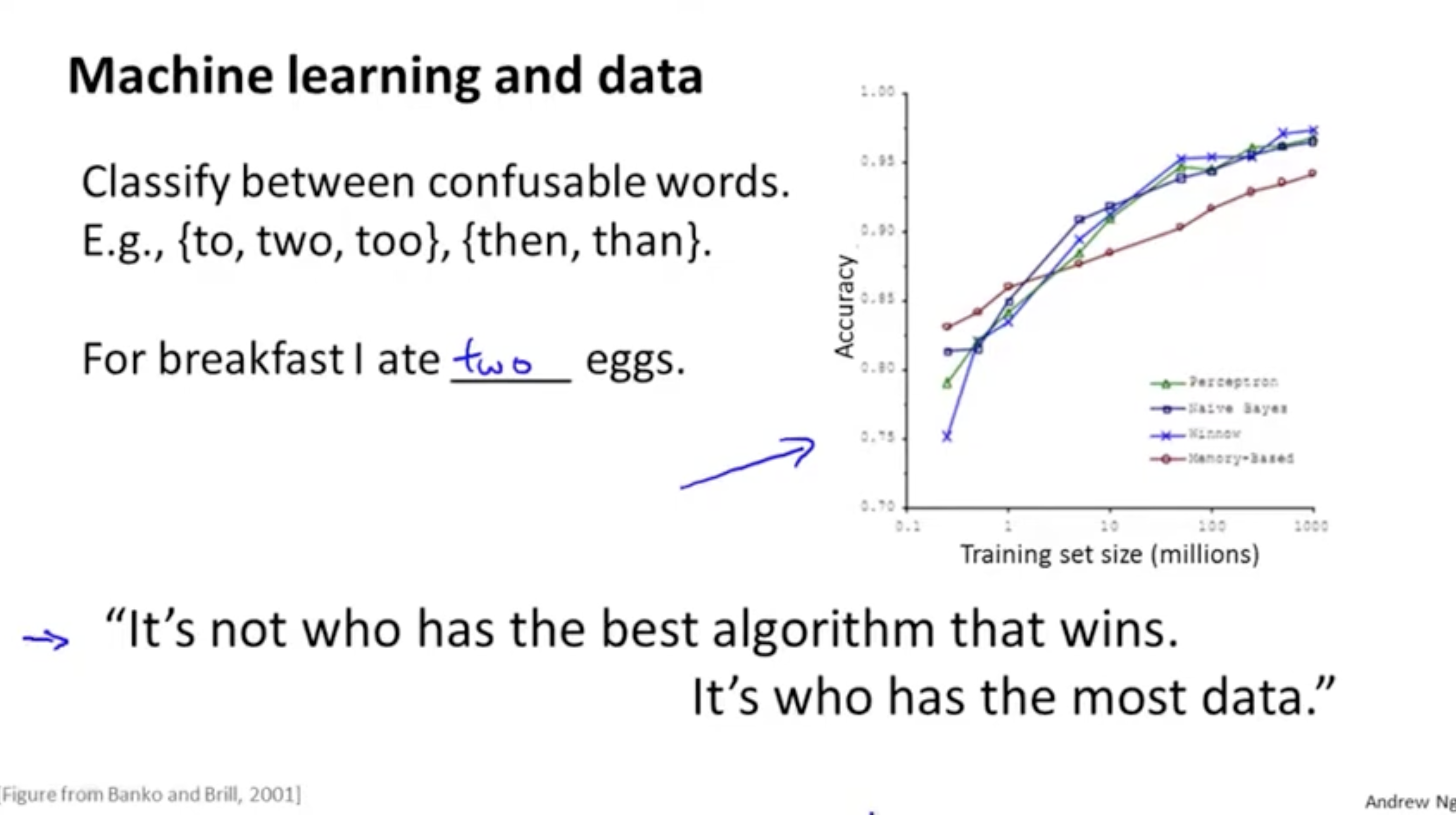
머신러닝에서는 좋은 알고리즘을 보유하는 사람이 이기는 게 아니라, 많은 데이터를 가지는 사람이 이긴다. 그 만큼 데이터가 중요하다.
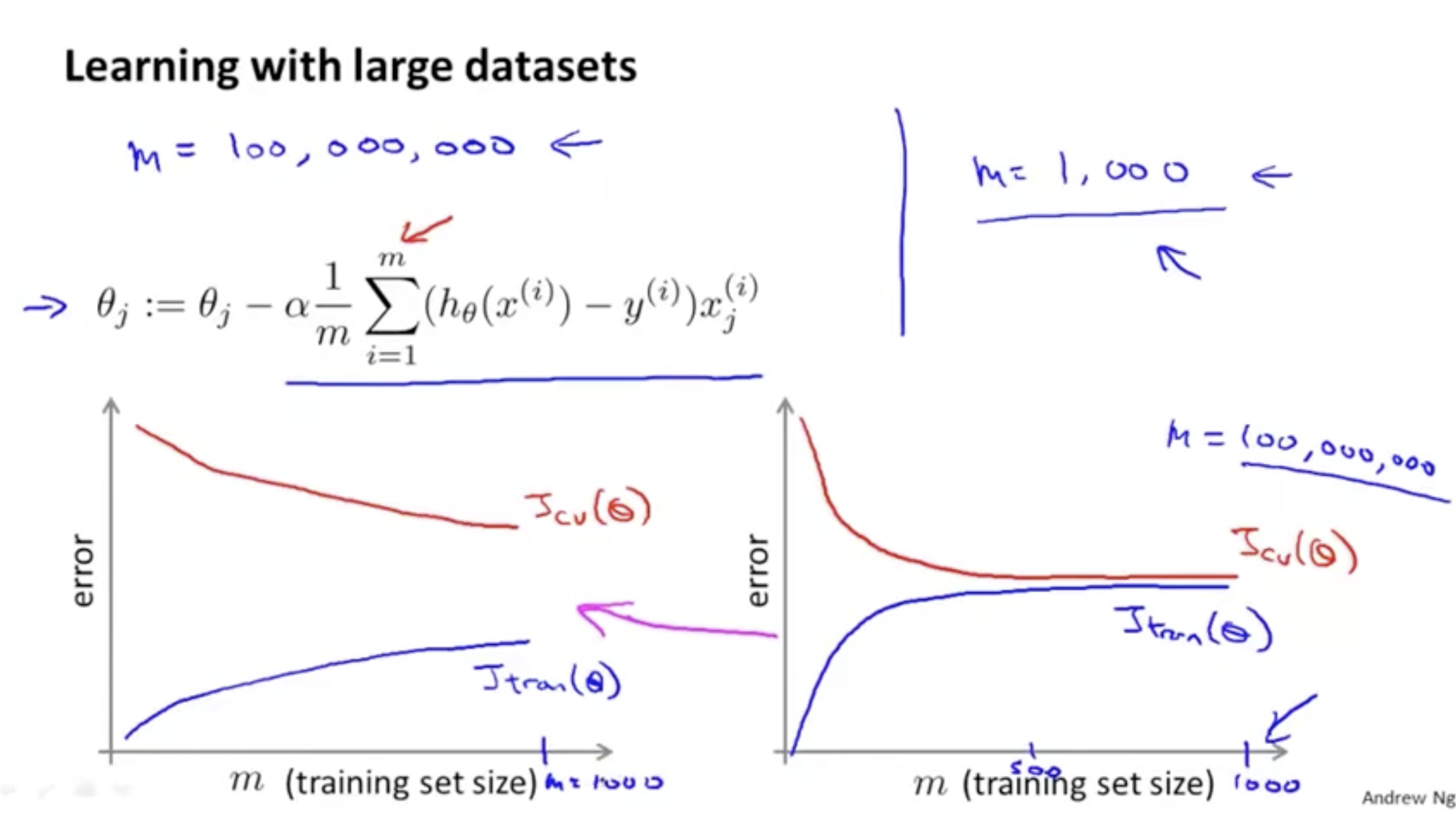
만약 데이터셋의 크기가 1억이라고 가정해보자. 모든 데이터에 대해서 gradient descent alg.을 적용하려면 계산 비용이 매우 많이 들 것이다. 따라서 이 데이터 중 일부만 (예를 들어 1000개만) 학습한다고 해보자.
- 학습 결과, 왼쪽 그래프처럼 나왔다면 데이터를 좀더 추가해서 학습하면 high-variance를 해결할 수 있을 것이다.
- 학습 결과, 오른쪽 그래프처럼 나왔다면 이는 충분히 괜찮아 보인다. 만약 여기에 데이터를 계속 추가하게 된다면 왼쪽과 같은 모양이 나올 수 있다.
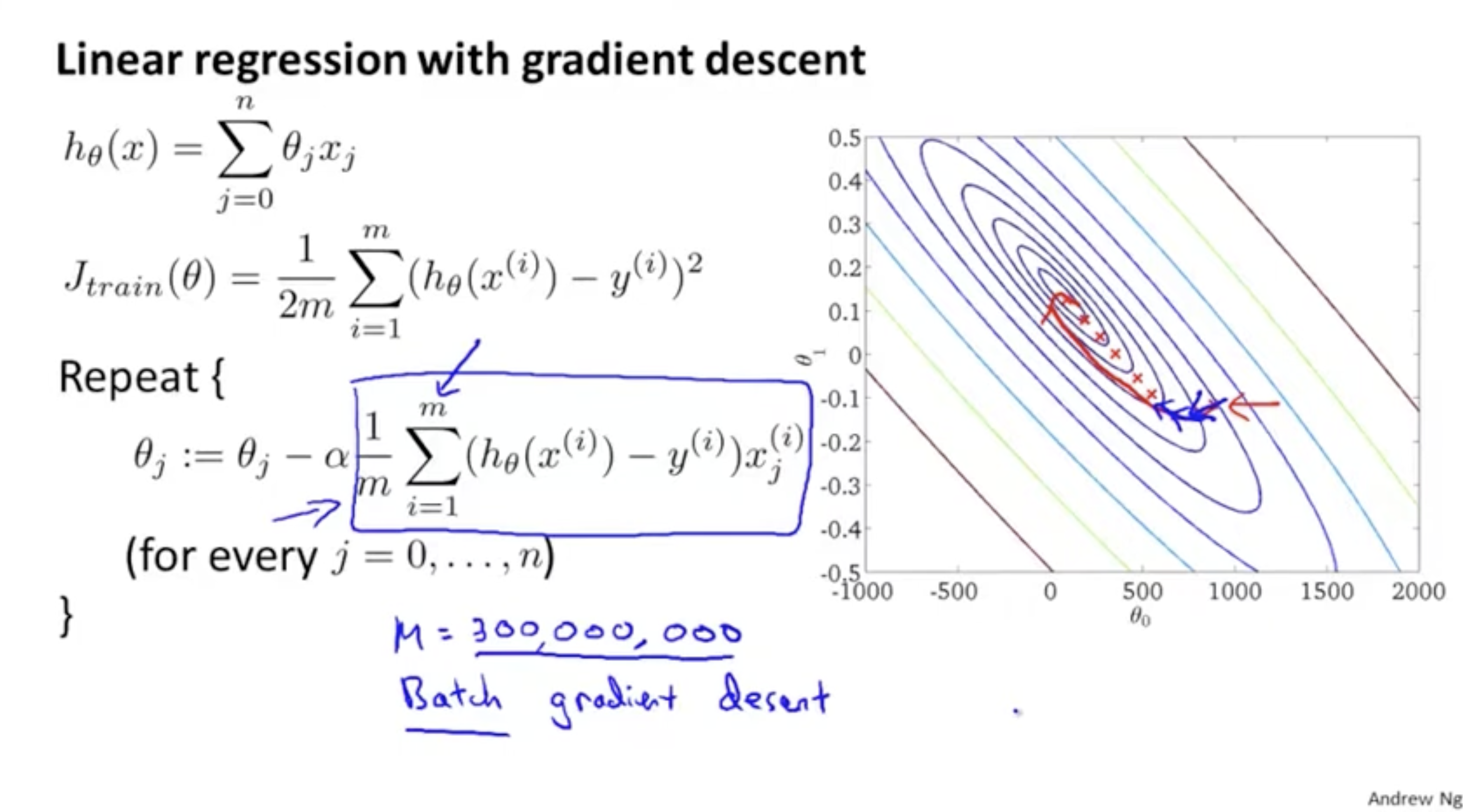
우리가 이전에 알던 gradient descent 방식은 정확히 표현하자면 "Batch gradient descent" 방법이다. 여기서 "Batch"는 전체 데이터에 대해서 적용한다는 의미이다.
- batch gradient descent를 적용할 경우, 우측 그래프처럼 global optima를 향해 올바른 방향으로 매우 천천히 나아갈 것이다.
- 하지만 연산때문에 전체 데이터셋의 크기 이 매우 클 경우, 연산 속도가 매우 떨어진다는 단점이 있다.
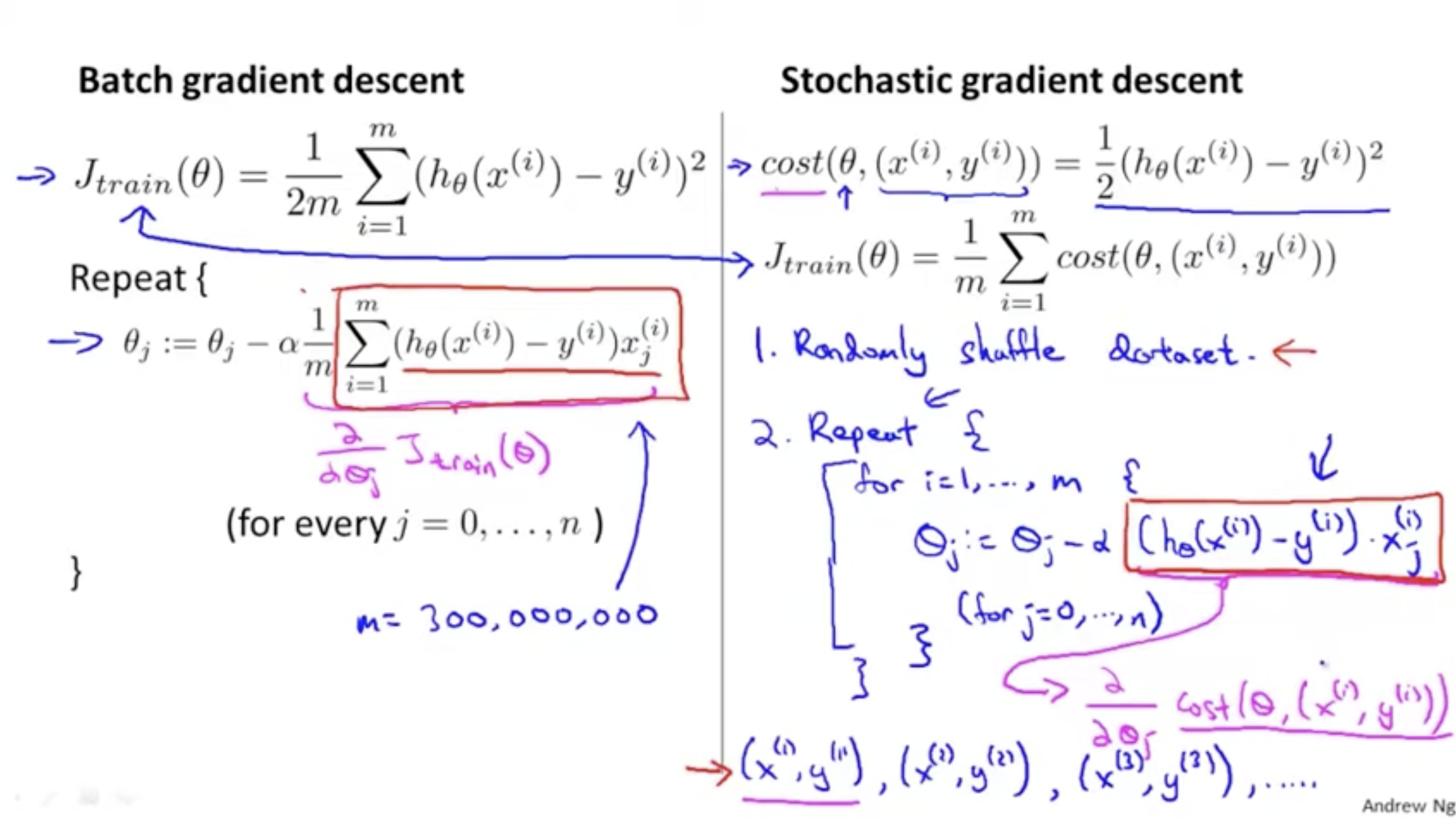
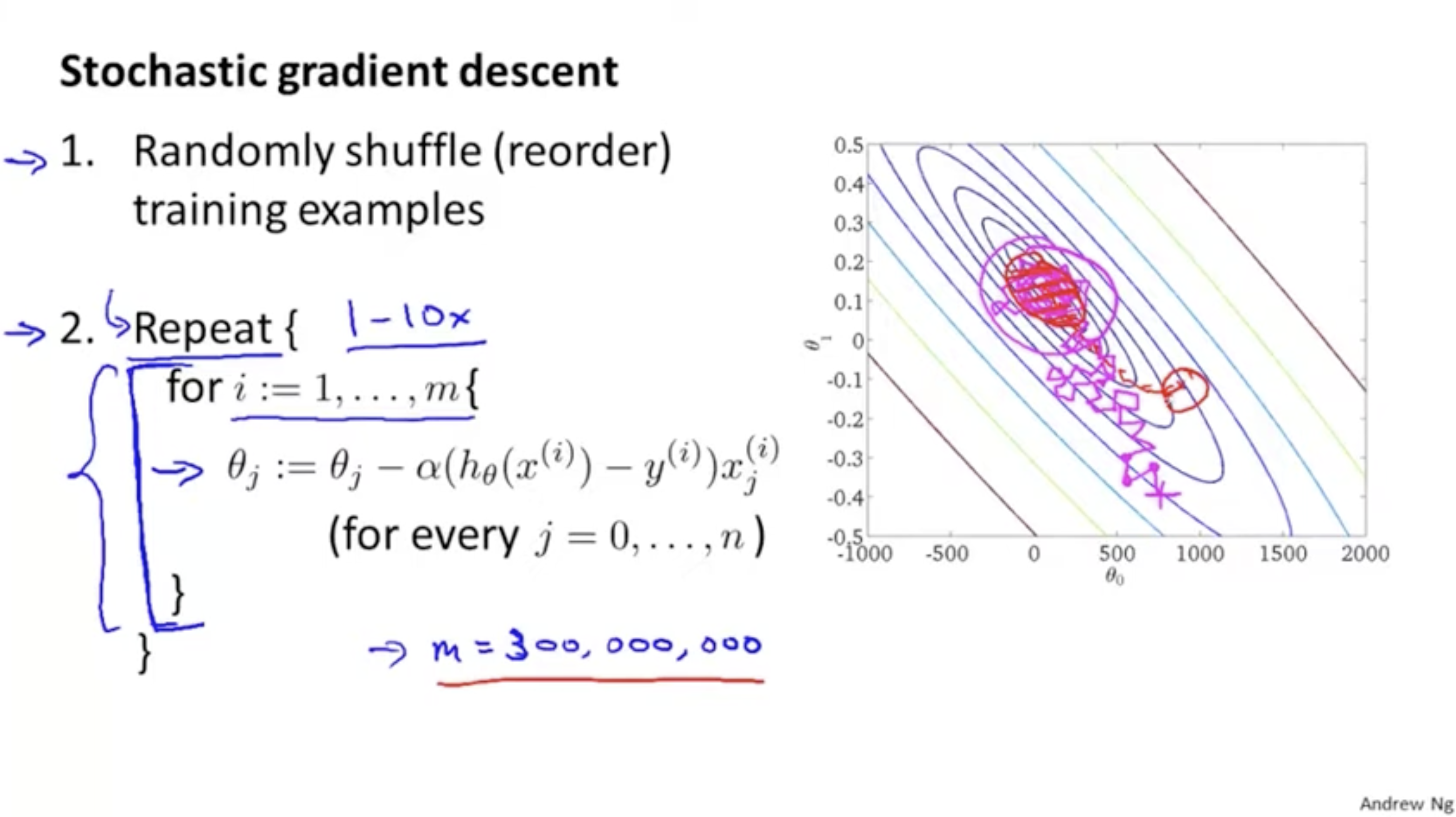
그래서 이를 보완하기 위해 "Stochastic gradient descent"라는 방식이 나왔다.
- batch gradient descent의 경우 모든 데이터셋에 대해서 cost function 을 적용했지만,
- stochastic gradient descent의 경우 하나의 데이터에 대해서 cost function 를 적용한다.
- 그리고 이 데이터는 랜덤하게 suffled된 데이터셋에서 가져온다.
- 따라서 stochastic gradient descent alg.을 적용하면 와 같이 하나의 데이터에 대해서만 gradient descent를 적용하면 된다.
- 요약하자면 batch gradient descent는 전체 데이터셋에 대해서 한번에 학습을 진행하지만, stochasitc gradient descent는 랜덤하게 섞인 개의 데이터셋에 대해서 한 번에 하나씩만 가져와서 하나의 데이터에 대한 학습을 여러 번 반복한다.
stochastic gradient descent alg.의 전체 cost function 값을 그래프로 그려보면 우측 그래프에서 핑크색 선과 같은 식으로 나온다. 하나의 데이터에 대해서 학습을 진행하기에 방향과 스텝의 크기가 중구난방일 수 있지만 결국에는 global optima와 가까운 영역에 도달하는 것을 알 수가 있다. (다만, 정확히 global optima에 도달한다는 보장은 못한다.)
그리고 "Mini-batch gradient descent"라는 방식도 존재한다.
- mini-batch gradient descent는 전체 데이터셋 보다 작고 보다 큰 개의 데이터를 가지고 학습을 진행하는 방식을 의미한다.

예시로 1000개의 데이터셋에 대해서 batch 크기를 10으로 두고 학습을 한다면 아래와 같은 방식으로 진행된다.
- 아래 식에서 식은 vectorization을 통해 실제 컴퓨터 연산에서 병렬 프로그래밍으로 구현할 수 있다. 따라서 속도가 빠르다는 이점이 존재한다.

그렇다면 어떻게 stochastic gradient descent alg.이 global optima 영역에 수렴한다는 것을 증명할 수 있을까?
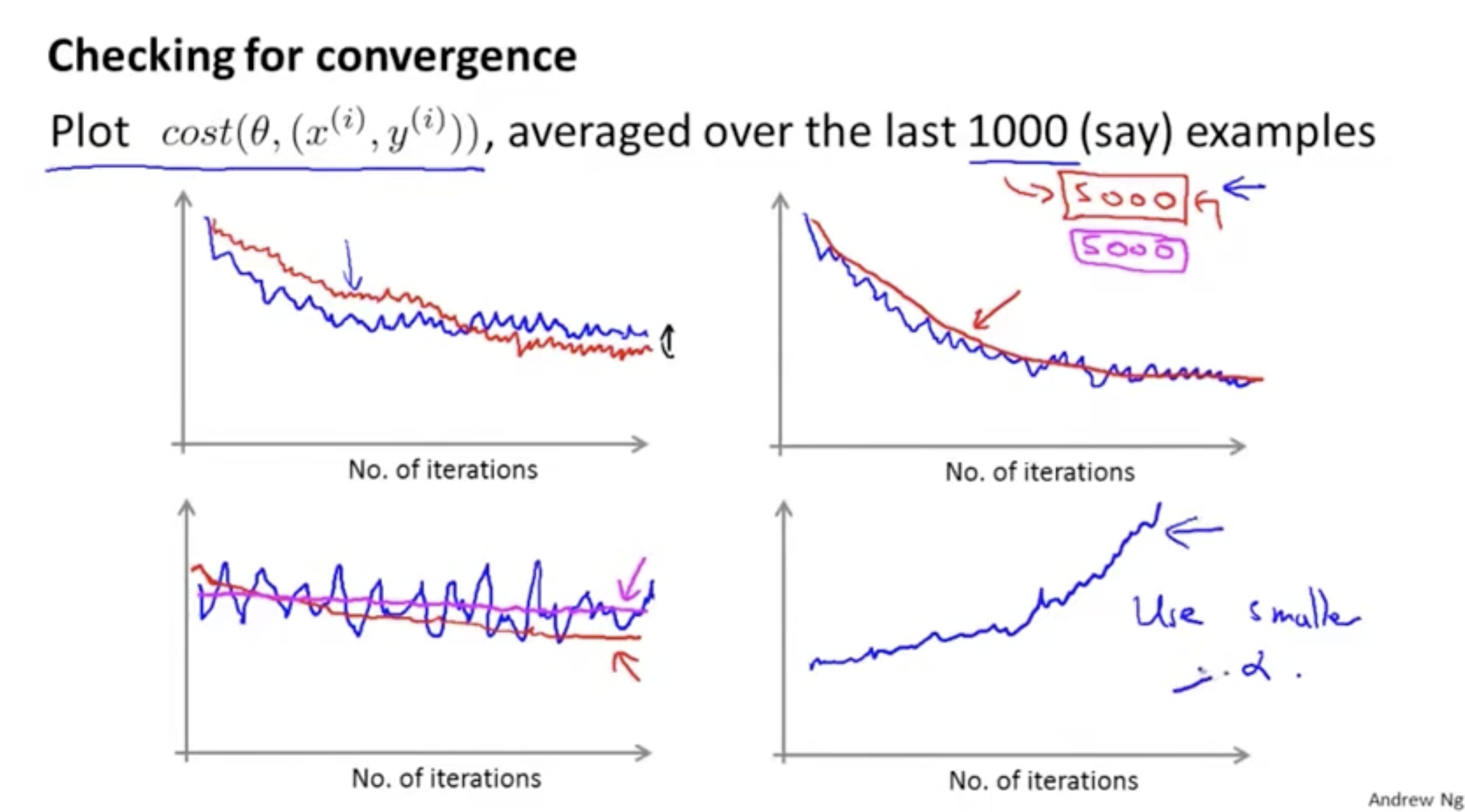
- 학습 동안 를 업데이트하기 전에 ""의 값을 저장해놓자.
- 그런 다음 1000번의 학습 동안, 의 평균값을 그려보자.

평균 값을 그려보면 아래와 같이 다양한 그래프가 나타날 수 있다.
- 좌측 상단 : 모델이 잘 학습되고 있음을 보여주는 예시로, 파란선은 learning rate가 보통인 경우를 의미하고 빨간선은 learning rate가 매우 작을 때를 보여준다. 결과적으로 둘다 global minimum으로 이동하고 있다.
- 우측 상단 : 마찬가지로 모델이 잘 학습되고 있음을 보여준다. 파란선은 1000번의 평균값을 의미하고 빨간선은 5000번의 평균값을 의미한다. 샘플 수가 많을 수록 완만한 그래프 모양을 보여준다.
- 좌측 하단 : 파란선은 하나의 데이터에 대해서 cost 값을 측정한 것으로, 파란선만 봤을 때는 모델이 잘 학습되고 있지 않은 것처럼 보일 수 있지만, 빨간선처럼 평균값을 기준으로 측정했을 때는 조금씩 cost 값이 내려가면서 모델이 잘 학습되고 있음을 보여준다. 하지만 만약 평균값으로 plot했을 때 분홍선처럼 나온다면, 이는 모델이 잘 학습되고 있지 않음을 의미한다.
- 우측 하단: 모델이 잘못 학습되고 있음을 보여준다. 오히려 cost 값이 발산하고 있으며, 이 경우 learning rate 값을 낮춰줘야할 필요가 있다.
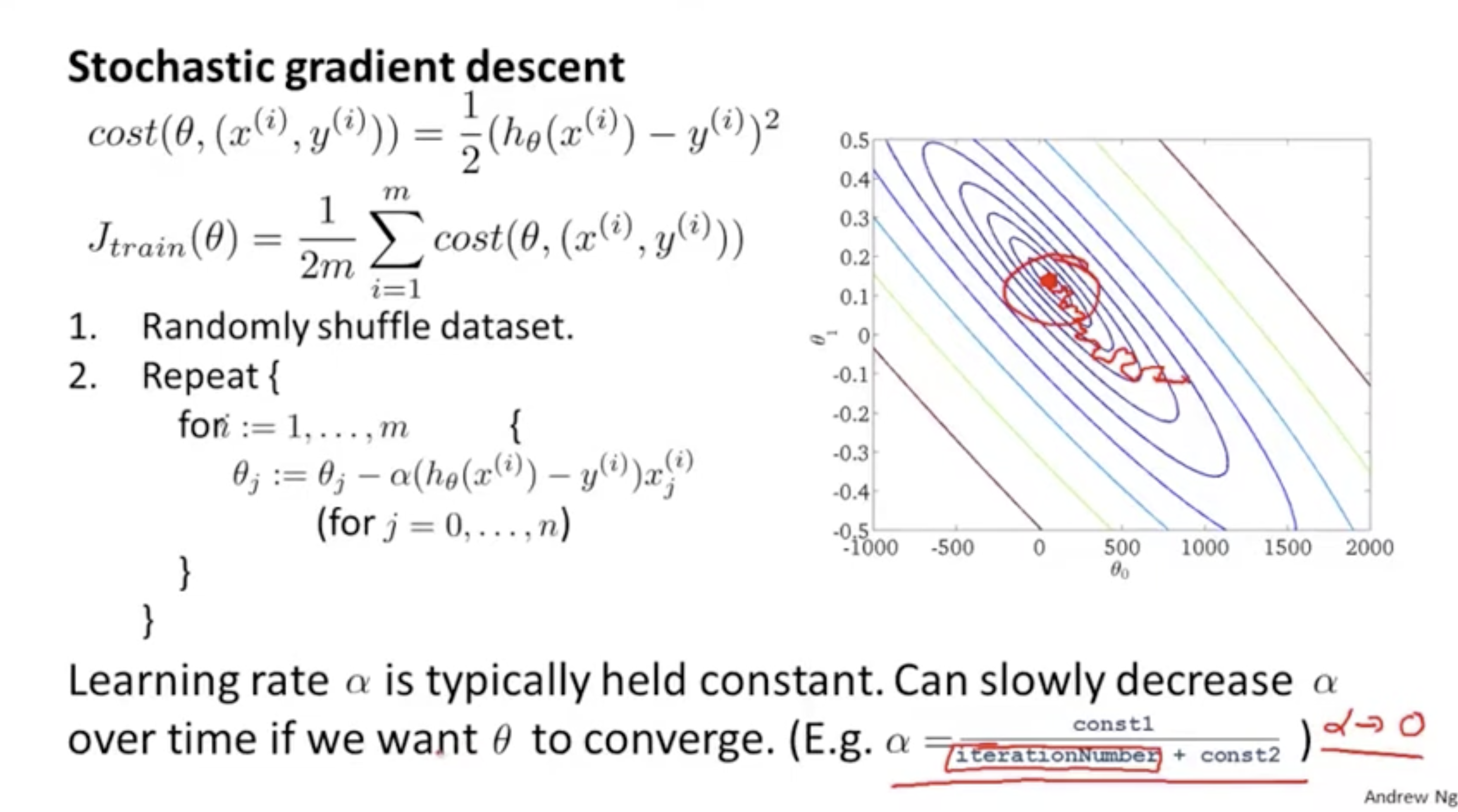
아까 batch와 stochastic gradient descent의 전체 cost function 값을 비교하는 과정에서 batch는 global minimum에 도달한다는 보장이 되지만, stocastic은 global minimum에 도달하지 못하고 주변을 배회하는 것을 볼 수 있었다.
- 하지만 아래와 같이 stochastic gradient descent 학습 과정이 반복될 수록 의 값이 줄어들도록 설정하면 stochastic gradient descent도 global minimum에 매우 근사하는 위치로 수렴할 수 있을 것이다.
온라인에서 머신러닝을 어떤 식으로 적용할 수 있을지 예시와 함께 살펴보자. (Online learning)
- 배달 서비스 웹사이트에서 배달 (출발지, 목적지, 가격) 정보를 제시하고 유저가 해당 배달을 구매하는지 안 하는지에 대한 데이터를 수집한다. (배달 서비스를 이용할 경우 : , 안 할 경우 : )
- 그런 다음 위 배달 데이터 정보 와 유저의 이용 정보 데이터를 가지고 모델을 학습한다.
- logistic regression 등을 활용해 를 학습함으로써 가격을 최적화한다. (예를 들어 (출발지, 목적지) 정보가 주어졌을 때 유저가 해당 서비스를 이용하려면() 최적의 가격이 얼마가 되어야 하는지를 선택한다.)
- (마치 유저의 데이터가 주어질 때마다 해당 데이터를 가지고 stochasitc gradient descent 과정을 적용하는 것 같다.)

