Audio-Visual Segmentation (ECCV 2022)
Source Code - GitHub
Introduction
본 논문에서는 이미지 프레임에서 소리를 내는 물체를 픽셀 단위로 구분하는 Task인 Audio-Visual Segmentation (AVS)를 제시한다. 기존에 존재하던 Task와의 차이점, 새로운 Dataset과 Baseline model 그리고 실험 결과에 대해 알아보자.
Related Field
AVC(Audio-Visual Correspondence)는 오디오와 이미지가 같은 scene에 해당하는지 판단하며, AVEL(Audio-Visual Event Localization)는 사전에 학습된 event label로 video segment를 분류한다. AVVP(Audio-Visual Video Parsing)는 비디오를 몇가지 event로 나누고 소리, 프레임, 또는 모두를 label에 따라 분류한다.
이러한 작업들은 프레임/시간 수준으로 제한되므로 새로운 Task는 소리가 나는 물체를 분류하는 것으로 범위를 줄인다.
SSL (Sound Source Localization)은 이중 가장 AVS와 가까운 작업으로, 프레임 내부에서 주어진 소리와 일치하는 영역을 찾아낸다.
그러나 SSL은 patch 단위로 이루어져있고, heat map으로 영역을 표시하므로 소리를 내는 객체의 모양을 정확히 표시하지는 않는다.
Audio-Visual Segmentation
AVS (Audio-Visual Segmentation)는 각 pixel이 해당 audio와 일치하는지 파악하여 sounding object와 겹치도록 mask를 생성한다.
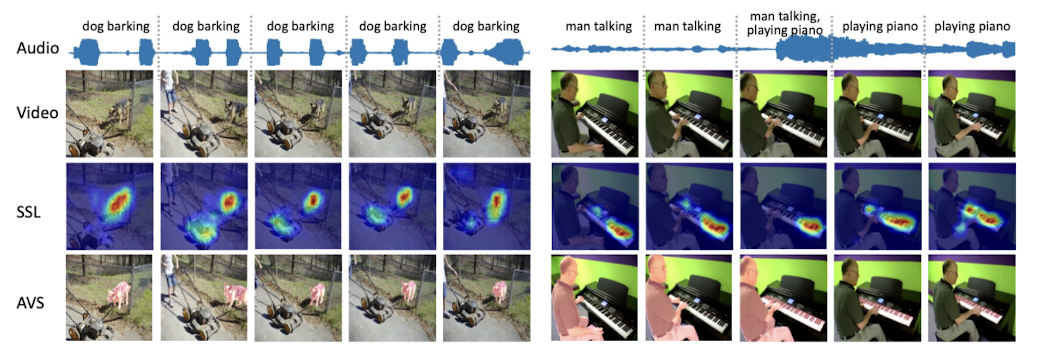
위 비디오 프레임 중 두 번째 행이 SSL, 세 번째 행이 AVS를 나타낸다. SSL은 patch 단위의 히트맵으로 표시된다. AVS는 pixel 단위로 물체를 표시하며, 이는 sounding object가 복수인 경우에도 마찬가지이다.
AVSBench
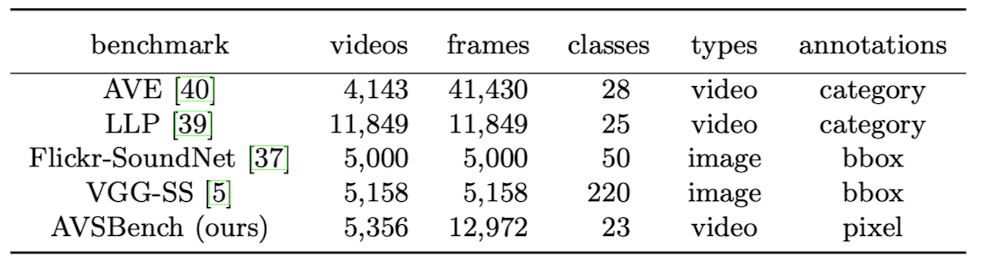
기존 데이터셋 중에서는 pixel 단위의 label를 제공하는 것이 없었다. frame에 대한 event만 분류하거나(AVE, LLP), target sound source의 outline이 되는 bounding box만 제공한다(Flickr-SoundNet, VGG-SS). 따라서 저자는 새로운 Task 학습에 적합한 Dataset인 AVSBench를 제시한다.
AVSBench는 sounding object의 수에 따라 Single-source와 Multi-sources로 구분한다.

각 데이터 셋은 5초 분량의 비디오가 1초 클립 5개로 나누어진 형태이며 label은 각 클립의 마지막 프레임에 제시된다. label은 binary mask 형태로 되어있으며, sounding object를 pixel-level로 표시하는 역할을 한다.
이 때 source 수에 따라 labeling 방식이 조금 다르다.
semi-supervised Single Sound Source Segmentation (S4)
Single-source의 학습 데이터 부분의 경우는 각 비디오의 5개의 클립 중 첫번째 클립에서만 label이 제공된다. 이는 single-source의 경우에는 one-shot annotation으로 충분하다는 가정에 의한 것이다.
fully-supervised Multiple Sound Source SEgmentation (MS3)
Multi-sources의 경우에는 좀 더 어려운 Task이기 때문에. 모든 학습 데이터의 클립에 label이 존재한다. 실제 데이터셋을 살펴보면 아래와 같다.

Baseline
논문에서는 AVS를 위한 End-to-End framework를 제시하는데, temporal pixel-wise audio-visual 상관관계를 인코딩하기 위한 TPAVI 모듈과 audio-visual correlation을 활용하기 위한 regularization loss가 포함되어있다.
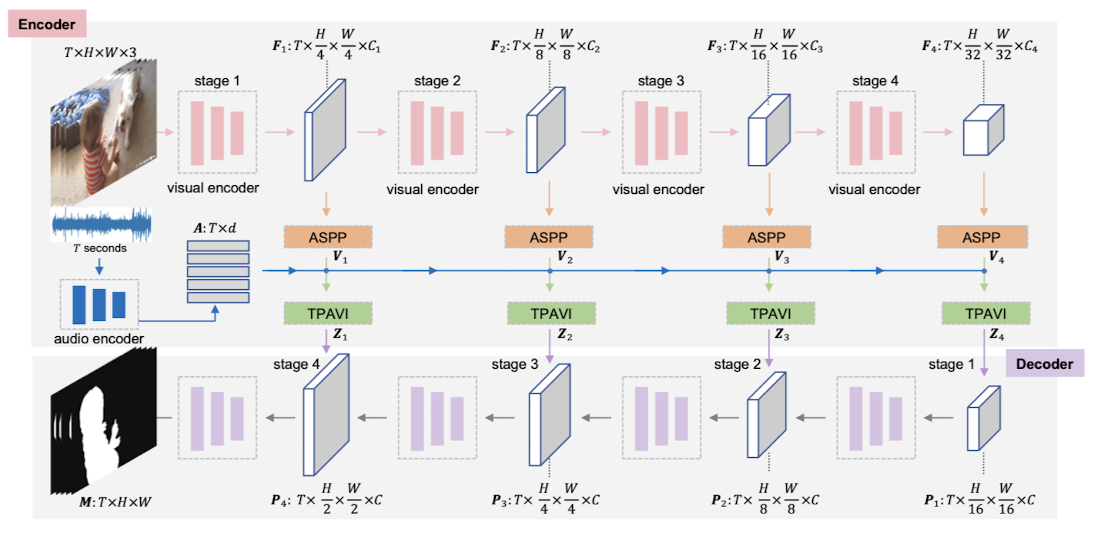
Encoder
Audio와 Video frame의 Encoding은 독립적으로 진행된다. 우선 auido clip은 short-time Fourier transform을 거친 후 VGGish를 통해 Txd 차원(d=128)의 audio feature가 추출된다. Visual feature의 경우는 convolution 또는 transformer 기반의 백본에 의해 처리된다.
Cross-Modal Fusion
앞서 추출된 visual feature를 후처리하기 위해서 Atrous Spatial Pyramid Pooling (ASPP)이 사용된다. 이러한 후처리는 병렬적으로 수행되는데, 이로 인해 서로 다른 크기의 receptive field를 갖는 객체를 인식할 수 있게 된다.
TPAVI
ASPP까지 거친 visual feature를 이제 audio의 feature와 mapping하는 작업이 필요하다. 이를 통해 어떤 물체가 소리를 내고 있는지 파악할 수 있기 때문이다. 이를 위해 Temporal Pixel-wise Audio-visual Interaction (TPVAI)을 인코딩하는 데, sound source의 소리와 모습이 항상 동시에 나타나지는 않기 때문에(예: 화면 밖에서 등장하는 경우) 한 video frame에 대해서 모든 audio signal을 고려하는 non-local neural networks 방식을 차용했다.
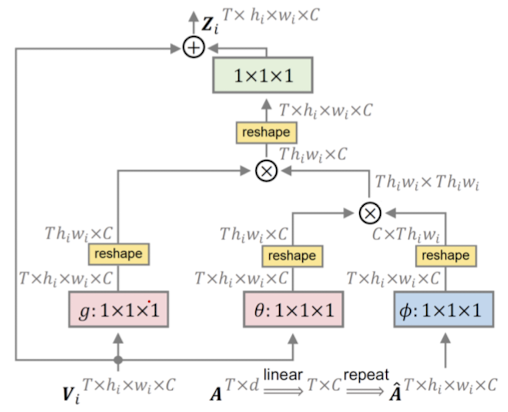
이때 audio feature는 visual feature와 같은 차원으로 변환된 후 hi * wi 만큼 복제후 재배열되는 방식으로 처리되어 TPAVI에 입력된다.
소리와 프레임 간의 관계를 나타내는 audio-visual interaction은 내적 연산에 의해 측정될 수 있다. 아래 식을 보자
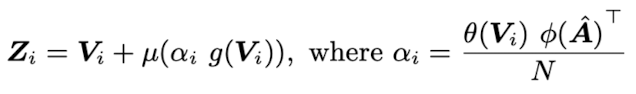
이때 θ, φ, g and μ는 1×1×1 convolution 연산이며, N은 T×hi×wi 크기의 Normalization factor, αi는 the audio-visual similarity이며 Zi는 RT×hi×wi×C의 크기를 갖는다. TPAVI 내에서 각각의 픽셀들은 전체 audio와 상호작용한다.
아래 사진은 실제로 audio와 pixel의 유사도를 나타낸 것으로 밝을 수록 유사도가 높은 구역이다.

Experiments
Comparison with methods from related tasks
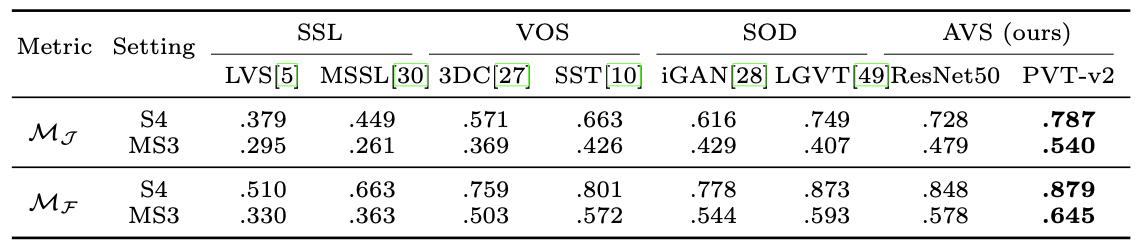
SOD method인 LGVT가 ResNet50 기반 AVS 모델을 Single-Source Set에 관한 지표에서 조금 앞섰지만 Multi-Source 지표에서는 훨씬 밀린다.
⇒ 이것은 SOD가 소리내는 물체는 바뀌지만 화면은 그대로인 경우를 감지하지 못하기 때문인 것으로 보인다.
⇒ 반면 AVS는 Audio 전체를 참고하기 때문에 Visual Frame에서 어떤 객체를 포착할지 알아챈다.
Single Source인 경우 조금 앞서는 것도 LGVT가 Swin-Transformer 기반이기 때문에 Backbone 자체의 성능이 좋아서 그런 것 같고, Transformer 기반의 PVT를 쓸 경우에는 두 지표에서 LGVT를 모두 앞선다.
Qualitative examples of the SSL methods and AVS

fully-supervised MS3 환경에서, SSL 메소드들(LVS, MSSL)은 대략적인 위치만 찾아냈지만, AVS는 객체의 더 정확한 pixel 단위의 모양을 구분해낼 수 있었다.
Qualitative examples of the VOS, SOD, and AVS

MS3 환경에서 VOS(Video Object Segmentation)의 SOTA mothod인 SST와 SOD(Sounding object Detection)의 method LGVT와 비교해보았을 때, AVS는 다른 두 방법과 달리 sounding object의 변화를 정확하게 잘 잡아내는 것을 알 수 있다. baby, dog 예시와 같이 중간에 소리를 내는 물체가 변화할 경우 SST와 LGVT는 계속 하나만 포착하거나, 두개를 포착하는 결과를 보여준다.
Comparison with a two-stage baseline method
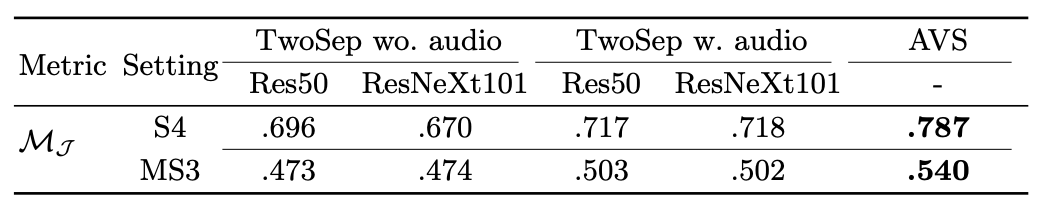
Two-Stage 구조에서 first-stage에 Mask R-CNN을 사용하여 segmentation quality를 증가시키더라도 AVS task 자체의 성능에 큰 영향을 미치지 않는다. 오히려 audio signal의 영향을 훨씬 많이 받는다.
Impact of audio signal and TPAVI
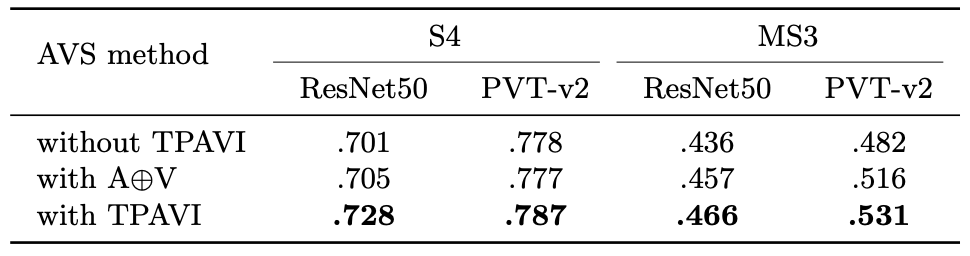
중간에 있는 row는 단순히 audio와 visual feature를 더한 것인데 이것만으로도 어느 정도 성능이 향상되었다.
Qualitative results under the semi-supervised S4 setting

TPAVI를 통해서 비디오에 존재하는 sounding object의 형태와 올바른 sound source를 학습하게 된다.
Qualitative results under the fully-supervised MS3 setting
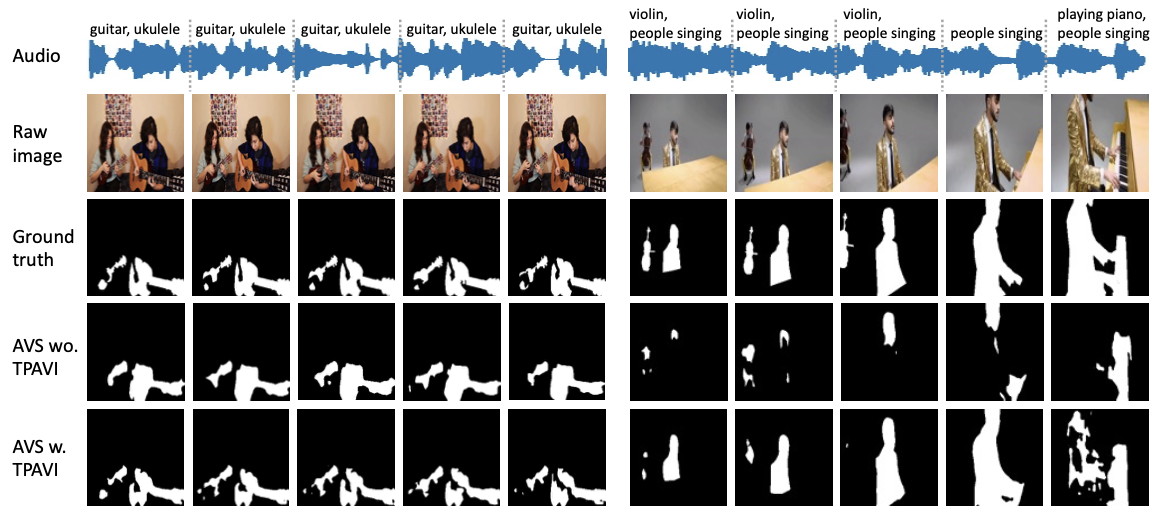
TPAVI를 적용한 모델이 사람의 손과 같이 소리와 직접적으로 관련이 없는 객체를 필터링하거나 노래 부르는 사람과 같이 더 정확한 객체를 포착하는등 더 뛰어난 성능을 보였다.
