Contribution
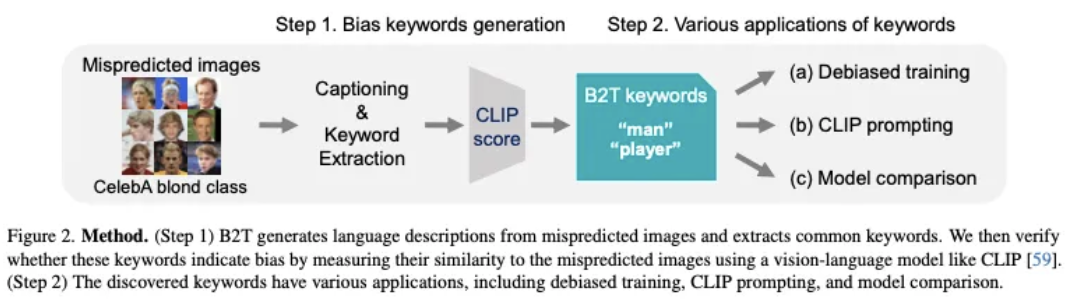
Bias-to-Text(B2T): 시각적 편향을 키워드로 추출 (잠재적 편향 검출)
⇒ 키워드 검증(CLIP score)을 통해 해당 키워드의 임베딩이 정답 캡션보다 이미지와 가까운지 여부를 판단
- 이미 잘 알려진 bias (CelebA, Waterbirds 등) 뿐만 아니라
새로운 bias도 찾아냄 ⇒ 꽃(flower)이 포함된 image에서 개미(ant)를 벌(bee)로 오인- 이렇게 찾아낸 bias keywords를 가지고 DRO와 같은 편향 제거 훈련에 이용하거나, CLIP prompting에 적용하거나, 다른 모델과 비교할 수 있음. 또한 잘못된 레이블을 검출할 수도 있음
Bias-to-Text (B2T) Framework
Problem formulation
image 에 대해서 클래스 를 예측하는 classifier가 있을 때,
자주 틀리는 속성 가 있을 경우 에 대한 bias으로 정의 ⇒ Keyword 설명 형식
*검출되는 bias에는 spurious correlation이나 distribution shifts가 있음
Bias Keywords
잘못 예측된 클래스의 이미지들의 caption에서 공통된 Keywords를 추출
⇒ Minority subgroups가 이 과정에서 자주 등장 (ex: Man - Blonde hair)
*Captioning Model로 ClipCap, Keywords Extraction Algorithm으로 YAKE 적용
CLIP score
추출한 kewords가 실제로 bias를 나타내는지 검증하기 위해 CLIP과 같은 vision-language scoring model 사용 ⇒ 편향된 컨셉과 관련된 keyword에서 높은 점수가 나타남
, 는 class-wise validation set 의 subset
keyword 와 dataset 사이의 similarity
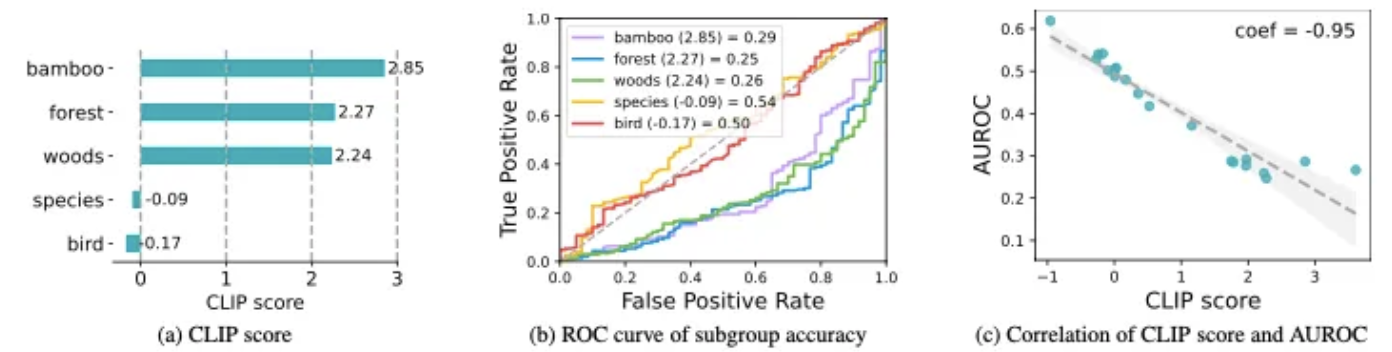
(a) ‘species’와 ‘bird’는 예측에 성공/실패한 이미지에서 공통적으로 나타나기 때문에 non-bias이고, 따라서 CLIP score도 낮게 나타남. ↔ ‘bamboo’, ‘forest’, ‘woods’는 잘못된 예측에서 더 높은 유사성을 보이므로 CLIP score도 높음.
(b) subgroup accuracy(AUROC) for keywords (c) CLIP score와 AUROC 간의 상관관계(-0.95)
Discovering Biases in Image Classifiers

Known Biases (a) gender bias in CelebA blond (b) background bias in Waterbirds (c) distribution shifts in ImageNet-R with different styles (d) ImageNet-C with natural corruptions
Novel Biases (e) spurious correlations between the keyword “cave” and wardrobe class indicating geographical bias (f) the keyword “flower” and ant class indicating contextual bias
known biases
Spurious correlation
(ERM) CelebA의 Blond 클래스에 대해 B2T가 “man” 키워드를, Waterbirds에 대해서 “forest”, “ocean”을 포착하여 성별, 배경 편향을 찾아냈을 뿐만 아니라 기존의 background annotation인 “land”에 비해 더 정확한 keyword인 “bamboo”를 찾아냄
Distribution shifts
(ResNet-50) B2T는 ImageNet-R에서 키워드 “illustration”, “drawing”, 좀 더 자세하게는
“hand-drawn”, “vector-art”를 찾아내었고, ImageNet-C 에서는 “snow”(snow corruption), “window”(frost-corruption)를 찾아냄.
Sample-wise bias labeling
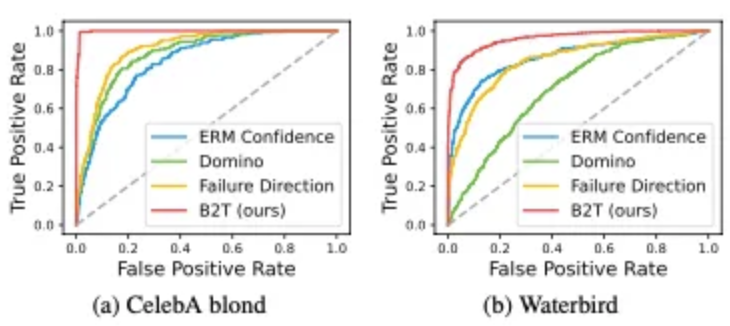
이렇게 찾아낸 keywords를 CLIP zero-shot classifier에 적용하여 샘플 단위로 편항을 라벨링 할 수 있음
“a photo of [group]”과 같이 bias keyword를 입력한 프롬프트를 통해 group labeling을 진행하고
ground-truth bias가 존재하는 CelebA, Waterbirds에 대해 기존 방법들과 비교 분석
⇒ 거의 최적에 가까운 결과를 보임
novel biases
Dollar Street(Figure4. e)은 다양한 소득 수준을 가진 국가들의 객체 이미지들을 포함. 이전의 연구들은 이미지 분류기가 저소득 국가에서 낮은 성능을 보인다는 것을 보임.
⇒ B2T를 Dollar Street Validation Set에서 ImageNet을 사용하여 이러한 편향을 분석하였음
몇가지 예시로
“cave” (동굴): “wardrobe” (옷장) 클래스에서 저소득 국가의 옷장이 어두운 곳에 있는 경우가 많아 동굴처럼 보이는 경향
“fire” (불): “stove” (난로) 클래스에서, 저소득 국가의 전통적인 디자인의 난로는 종종 불을 사용하는 방식
이러한 객체의 차이는 국가 간의 지리적 편향을 나타내며, 분류기가 고소득 국가의 객체는 잘 예측하지만 저소득 국가의 객체는 잘못 예측하는 원인을 설명
ImageNet(Figure4. f)에서는 여러 객체가 동시에 존재함으로 인해서 발생하는 contextual biases를 발견할 수 있었는데,
“flower”(꽃)과 함께 존재하는 “ant”(개미)를 “bee”(벌)로 예측하였다. 이는 벌이 개미보다 꽃과 더 강한 연관성을 가지고 있음을 시사한다.
- “playground”(놀이터)에서 “horizontal bar”(철봉)을 “swing”(그네)로 오인한다.
Applications of the B2T Keywords
B2T를 사용해서 얻어낸 키워드들은 학습, 프롬프팅, 모델 비교, 레이블 진단 등에 사용할 수 있다.
Debiased DRO training
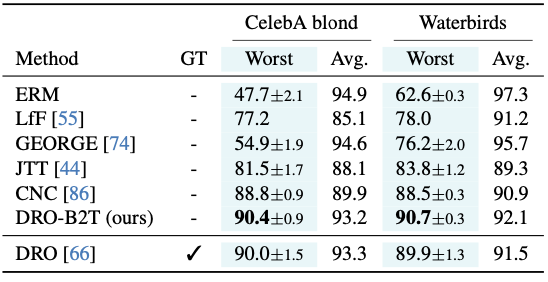
앞서 구한 Sample-wise bias label을 이용해서 DRO(distributionally robust optimization)의 group label로 적용한 DRO-B2T의 성능을 측정하였다.
가장 성능이 나쁜 그룹의 정확도를 나타내는 WGA(worst-group accuracy)가 오히려 기존 ground truth를 사용한 DRO보다 능가하였다.
CLIP zero-shot prompting
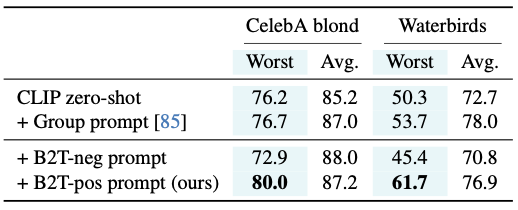
CLIP이 기본적으로 사용하는 “a photo of a [class]“ 프롬프트에 키워드를 추가하여 “a photo of a [class] in the [group]“와 같은 형식을 사용한다.
B2T 키워드 중에 앞서 구한 CLIP score를 가지고 B2T-pos(ex: “ocean”), B2T-neg(ex: “bird)를 [group]에 대입하여 실험한 결과 positive 키워드를 사용했을 때 worst-group accuracy, average accuracy 모두 향상되었고, 반대로 negative 키워드를 사용했을 때는 오히려 성능이 나빠진 것을 알 수 있다.
Model comparison
ResNet vs. ViT
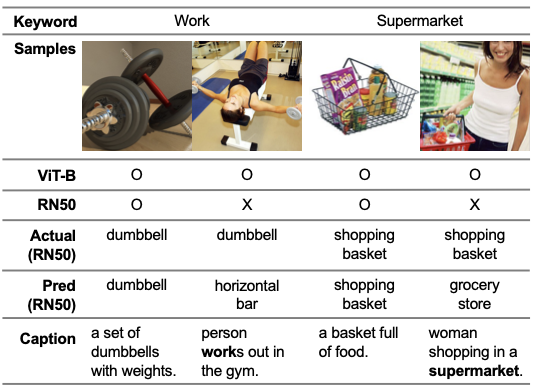
ViT는 ResNet보다 더 전반적인 문맥 이해와와 세밀한 클래스 분류에서 더 우수한 성능을 보임.
가령 ViT는 “work out”과 같은 추상적인 편향 키워드도 성공적으로 예측하였음
반면 ResNet은 “horizontal bar”를 “dumbbell”로, “shopping basket”을 “grocery store”로 잘못 예측하는 등 복잡한 이미지에서 어려움을 보임
ERM vs. DRO
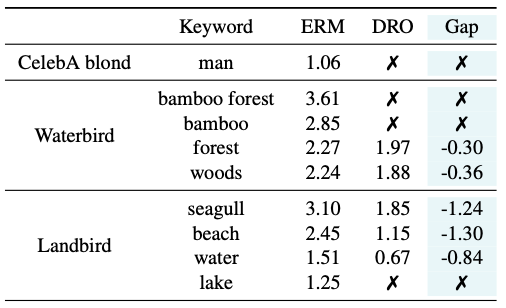
CelebA와 Waterbirds 데이터셋에서 ERM과 DRO를 비교하였을 때,
DRO는 편향 키워드를 줄이거나 거의 완전히 제거에 성공하였음, CelebA blond에서 “man” 키워드가 사라졌고 Waterbirds에서 “seagull”의 CLIP 점수가 3.10에서 1.85로 감소하였음.
Label diagnosis

B2T는 잘못된 레이블 및 레이블 모호성을 진단하는 데 사용할 수 있는데, ImageNet에 존재하는 레이블 오류를 발견하였음.
B2T를 통해 “bee”가 “fly”로, “boar”가 “pig”로 잘못 레이블링된 이미지를 발견하였고, 또한 “desk”, “market”과 같이 대체적으로 여러 객체가 한번에 포함되어 모호한 레이블도 판별 할 수 있음.
