
Kafka Introduction
1. LinkedIn의 Kafka 개발 배경
카프카 개발 전 링크드인의 데이터 처리 시스템
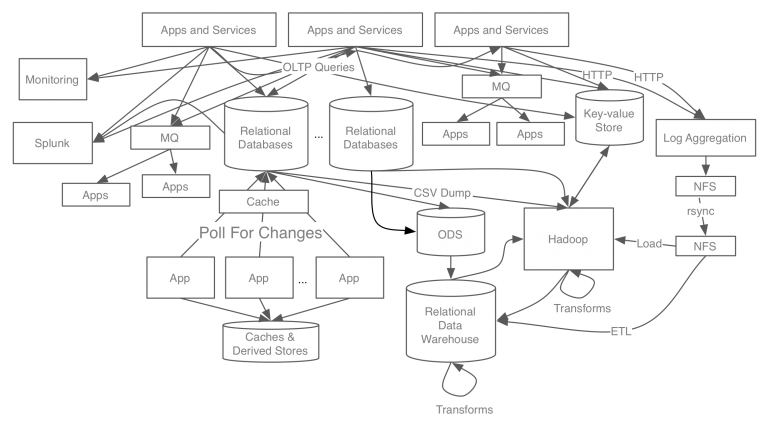
- 기존 링크드인의 데이터 처리 시스템은 각 파이프라인이 파편화되고 시스템 복잡도가 높아 새로운 시스템을 확장하기 어려운 상황이였음
- 기존 메시징 큐 시스템인 ActiveMQ를 사용했지만, 링크드인의 수많은 트래픽과 데이터를 처리하기에는 한계가 있었음
- 이로 인해 새로운 시스템의 개발 필요성이 높아졌고, 링크드인의 몇몇 개발자가 다음과 같은 목표를 가지고 새로운 시스템을 개발
- 프로듀서와 컨슈머의 분리
- 메시징 시스템과 같이 영구 메시지 데이터를 여러 컨슈머에게 허용
- 높은 처리량을 위한 메시지 최적화
- 데이터가 증가함에 따라 스케일아웃이 가능한 시스템
카프카를 개발 후 링크드인의 데이터 처리 시스템
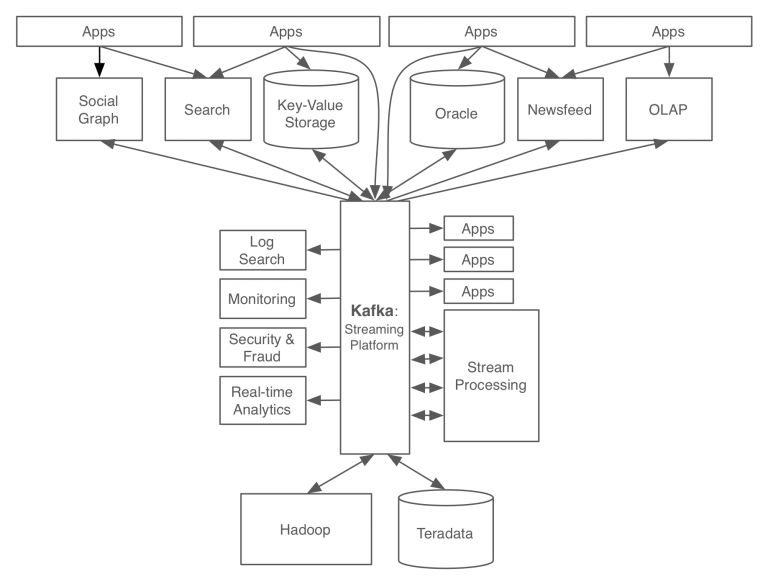
- 카프카를 적용함으로써 모든 이벤트/데이터의 흐름을 중앙에서 관리할 수 있게 되었으며,
- 서비스 아키텍처가 기존에 비해 관리하기 심플해졌음
2. 메시징 시스템
- Publisher와 Subscriber로 이루어진 비동기 메시징 전송 방식
- 메시지라고 불리는 데이터 단위를 보내는 측(Publisher/Producer)에서 메시지 시스템에 메시지를 저장하면 가져가는 측(Subscriber/Consumer)는 데이터를 수신
- 발신자의 메시지에는 수신자가 정해져 있지 않은 상태로 발행(Publish)
- 구독(Subscribe)을 신청한 수신자만이 정해진 메시지를 받음
- 수신자는 발신자 정보가 없어도 메시지 수신이 가능
일반적인 형태의 네트워크 통신의 문제점
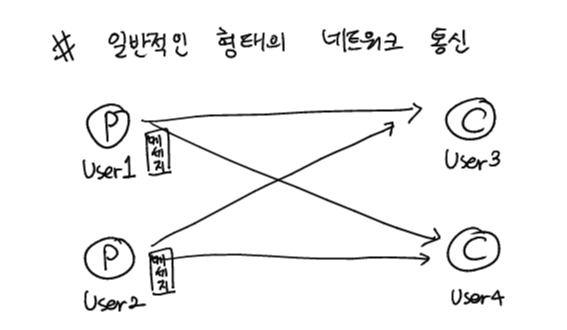
- N:N연결이므로 클라이언트 갑자기 많아질 경우 느려질 수 있고 이를 대응하기 위한 확장성이 떨어짐
- 특정 클라이언트가 다운되서 메시지를 받지 못하게 될 경우 메시지가 유실될 수 있음
Pub/Sub 모델
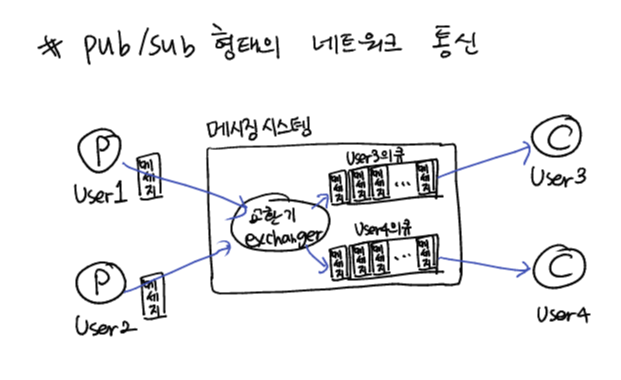
- 작동방식
- 프로듀서가 메시지를 컨슈머에게 직접 전달하는 것이 아니라, 중간의 메시징 시스템에 전달 (수신처 ID포함)
- 메시징 시스템의 교환기가 메시지의 수신처 ID값을 통해 컨슈머들의 큐에 메시지를 전달 (push)
- 컨슈머는 큐를 모니터링하다가 큐에 메시지가 있을 경우 값을 회수
- 장점
- 특정 개체가 수신불능 상태가 되더라도 메시징 시스템만 살아있다면 메시지가 유실되지 않음
- 메시징 시스템으로 연결되어있기 때문에 확장성이 용이
- 단점
- 직접 통신하지 않기 때문에 메시지가 잘 전달되었는지 파악하기 힘듬
- 중간에 메시징 시스템을 거치기 때문에 메시지 전달 속도가 빠르지 않음
3. 그래서 카프카(Kafka)는 무어냐 ?
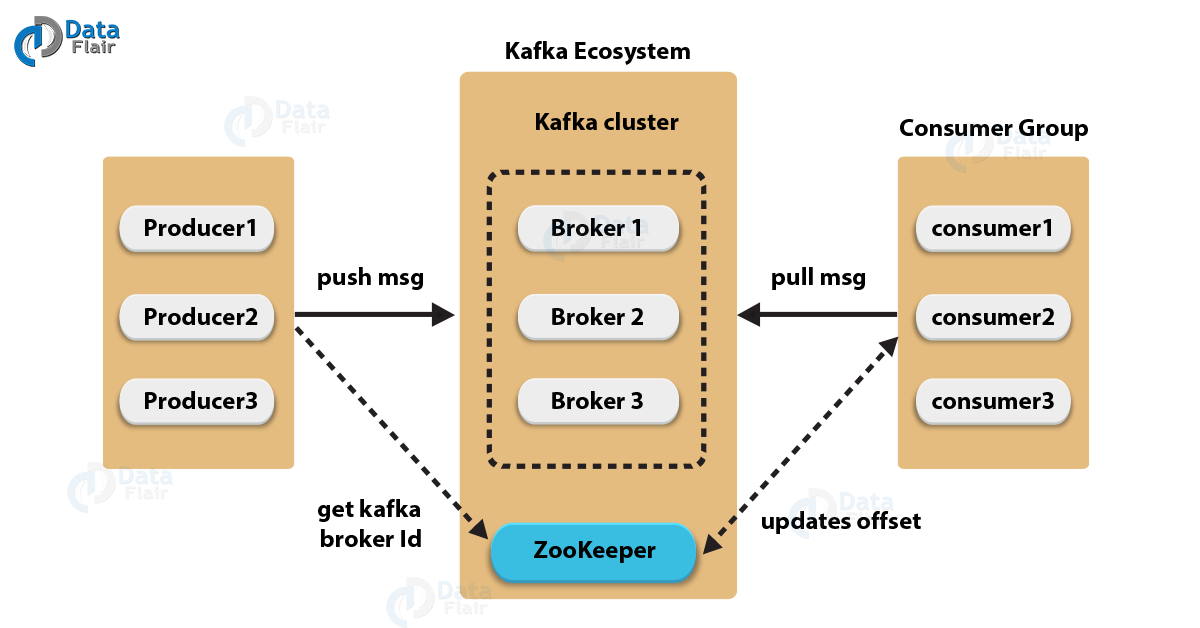
카프카 아키텍처
- 프로듀서(Producer)
- 메시지를 생산하여 브로커의 토픽으로 전달하는 역할
- 브로커(Broker)
- 카프카 애플리케이션이 설치되어 있는 서버 또는 노드를 지칭
- 컨슈머(Consumer)
- 브로커의 토픽으로부터 저장된 메시지를 전달받는 역할
- 주키퍼(Zookeeper)
- 분산 애플리케이션 관리를 위한 코디네이션 시스템
- 분산된 노드의 정보를 중앙에 집중하고 구성관리, 그룹 네이밍, 동기화 등의 서비스 수행
작동방식
- 프로듀서는 새 메시지를 카프카에 전달
- 전달된 메시지는 브로커의 토픽이라는 메시지 구분자에 저장
- 컨슈머는 구독한 토픽에 접근하여 메시지를 가져옴 (pull 방식)
기존 메시징 시스템과 다른 점
-
디스크에 메시지 저장
- 기존 메시징 시스템과 가장 큰 특징
- 기존 메시징 시스템은 컨슈머가 메시지를 소비하면 큐에서 바로 메시지를 삭제
- 하지만, 카프카는 컨슈머가 메시지를 소비하더라도 디스크에 메시지를 일정기간 보관하기 때문에 메시지의 손실이 없음 (영속성)
-
멀티 프로듀서, 멀티 컨슈머
- 카프카의 경우 디스크에 메시지를 저장하는 특징으로 인해,
- 프로듀서와 컨슈머 모두 하나 이상의 메시지를 주고 받을 수 있음
-
분산형 스트리밍 플랫폼
- 단일 시스템 대비 성능이 우수하며, 시스템 확장이 용이함
- 일부 노드가 죽더라도 다른 노드가 해당 일을 지속 (고가용성)
-
페이지 캐시
-
카프카는 잔여 메모리를 이용해 디스크 Read/Write 를 하지 않고 페이지 캐시를 통한 Read/Write으로 인해 처리속도가 매우 빠름
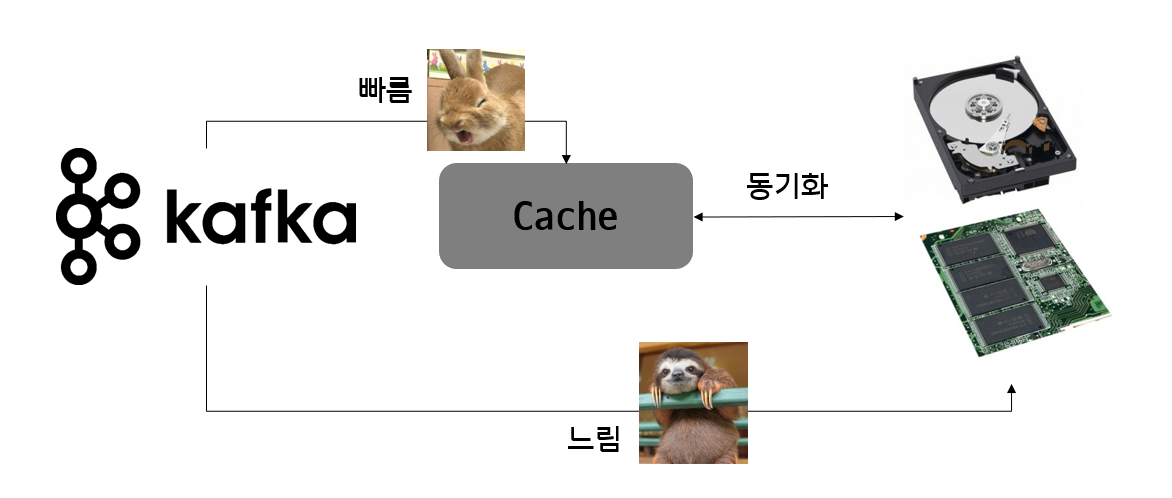
-
-
배치 전송 처리
- 서버와 클라이언트 사이에서 빈번하게 발생하는 메시지 통신을 하나씩 처리할 경우 그만큼 네트워크 왕복의 오버헤드가 발생
- 이로인해, 메시지를 작은 단위로 묶어 배치 처리를 함으로써 속도 향상에 큰 도움을 줌
4. 카프카 데이터 모델
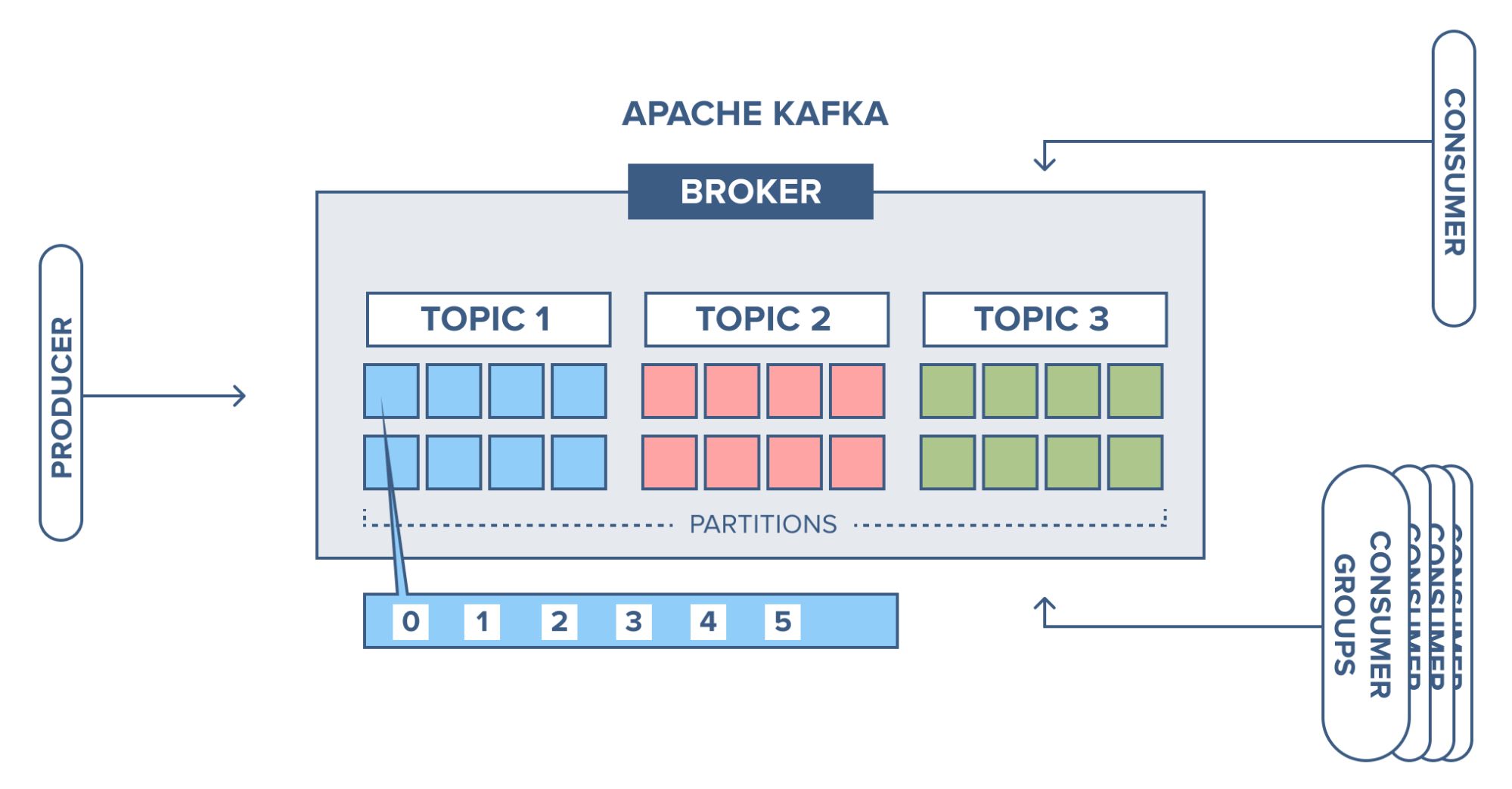
카프카는 기본적으로 토픽과 파티션이라는 데이터 모델이 존재
토픽(Topic)
-
메시지를 논리적으로 묶은 개념 (데이터베이스의 테이블 / 파일시스템의 폴더와 유사한 개념)
-
프로듀서가 메시지를 보낼경우 토픽에 메시지가 저장됨.
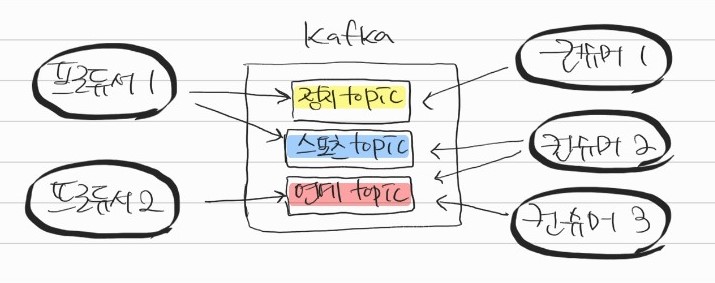
파티션(Partition)
- 토픽을 구성하는 데이터 저장소이며 메시지가 저장되는 위치

-
여러개의 프로듀서에서 한개의 파티션으로 메시지를 보낼 경우 병목이 생기고, 메시지의 순서를 보장할 수 없게 됨
-
그렇기에, 파티션을 여러개로 늘리고 그 수만큼 프로듀서도 늘려 하나의 파티션마다 하나의 프로듀서 메시지를 받으면 훨씬 빠름
-
그렇다면 파티션은 많을 수록 좋은가?
- 파일 핸들러의 낭비가 존재
- 각 파티션은 브로커의 디렉토리와 매핑되고 저장되는 데이터마다 2개의 파일(인덱스, 실제 파일)이 있기 때문에 너무 많은 파일 핸들이 생길 경우 리소스 낭비가 생김
- 장애 복구 시간이 증가할 수 있음
- 카프카는 리플리케이션(Replication)을 지원하고, 이를 통해 지속적으로 리더 파티션을 팔로워 파티션으로 리플리케이션을 하게됨
- 하지만 파티션 수가 너무 많을 경우 리플리케이션 수행이 느려져 장애복구시간이 증가할 수 있음
- 추후 파티션 수를 줄이는 것이 불가능
- 카프카에서 파티션 수를 늘리는 것은 아무때나 가능하지만 파티션 수를 줄이는 방법은 제공하지 않음. 만약 줄이고 싶다면 토픽 자체를 삭제하는 것 말고는 방법이 없음
- 파일 핸들러의 낭비가 존재
오프셋과 메시지순서
-
오프셋(offset)
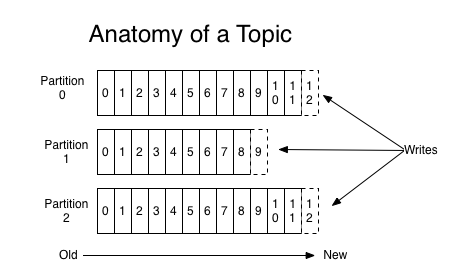
- 파티션마다 메시지가 저장되는 위치
- 파티션 내에서 순차적으로 유니크하게 증가하는 숫자 형태로서 동일 파티션 내 메시지의 순서를 보장해줌
- 컨슈머는 메시지를 가져올 때마다 오프셋 정보를 커밋(commit)함으로써 기존에 어디 위치까지 가져왔는지 알 수 있게 됨
파티션과 메시지순서
- 파티션을 여러개 지정할 경우
- 프로슈머가 메시지를 보낼 때, 파티션이 여러개인 경우 메시지는 각각의 파티션으로 순차적으로 배분 (Round-robin 방식)
- 메시지의 순서는 오로지 동일 파티션 내 오프셋을 기준으로만 보장되기 때문에,
- 여러개의 파티션을 사용할 경우 동일 파티션 내에서는 순서가 보장되지만, 파티션과 파티션 사이에서는 순서를 보장하지 못하기 때문에 전체 메시지를 출력할 경우 순서가 섞일 수 있음
- 전체 메시지의 순서를 보장하고 싶은 경우 partition을 1개로만 설정해야 함
- 하지만 파티션이 하나이므로 분산 처리가 불가능
리플리케이션
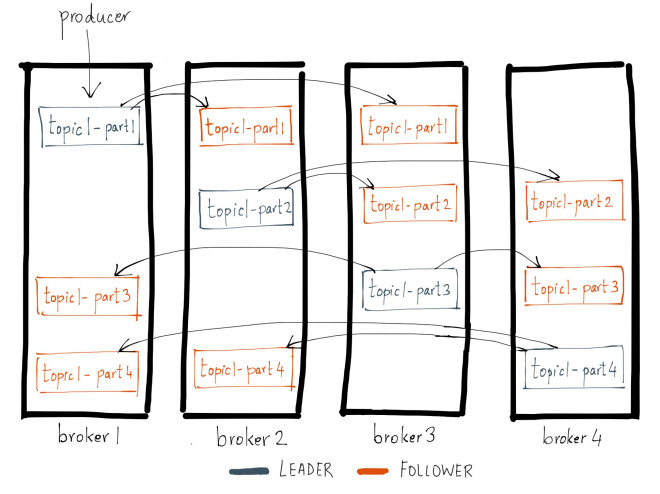
- 고가용성 및 데이터 유실을 막기 위해 replication을 수행
- 원본 파티션의 경우 '리더'가 되고, 복제 파티션의 경우 '팔로워'가 됨
- 만약 리더 파티션이 있는 브로커가 다운될 경우, 복제 파티션을 가진 브로커의 팔로워 파티션이 새로운 리더가 되어 정상적으로 프로듀서의 요청을 처리
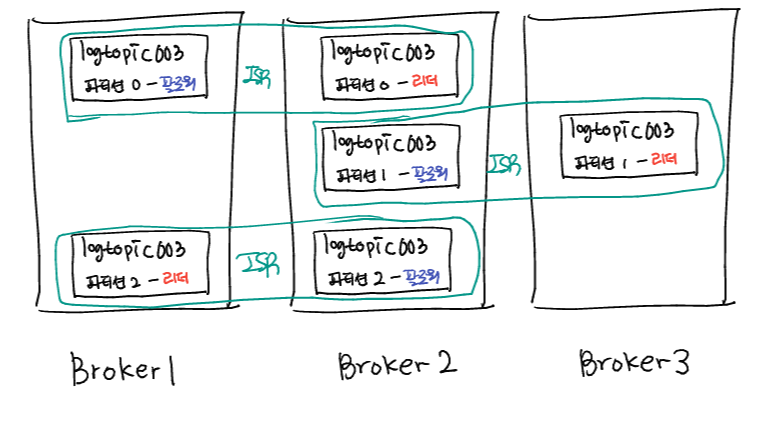
ISR(In Sync Replica)
- 리더와 팔로워로 이루어진 리플리케이션 그룹
- 리플리케이션 그룹 내 동기화 및 신뢰성 유지
- 팔로워는 Read/Write 권한이 없고 오로지 리더로부터 데이터를 복제하기 때문에 특정 팔로워가 다운되서 리플리케이션을 못할 경우 동기화 문제 발생
- 이러한 문제로 인해, 문제가 감지된 팔로워(설정된 일정주기(replica.lag.time.max.ms)만큼 요청이 오지 않는 팔로워)는 ISR 그룹에서 추방됨
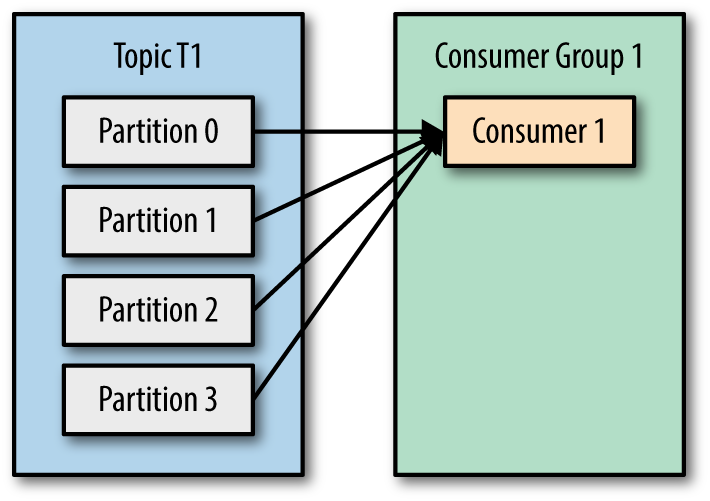
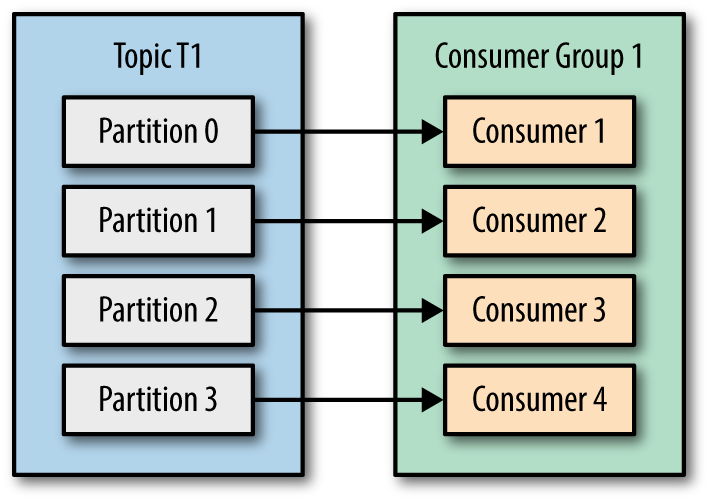
Consumer 그룹
-
컨슈머가 메시지를 소비하는 시간보다 프로듀서가 메시지를 전달하는 속도가 더 빨라서 메시지가 점점 쌓일 경우를 대비하여
-
동일 토픽에 대해 여러 컨슈머가 메시지를 가져갈 수 있도록 컨슈머 그룹이라는 기능을 제공
-
아래와 같이 하나의 consumer가 프로듀서의 메시지 전송 속도를 따라가지 못할 경우
-
아래와 같이 컨슈머를 확장하여 하나의 파티션 당 하나의 컨슈머가 연결되도록 할 수 있음 (리밸런스, rebalance)
-
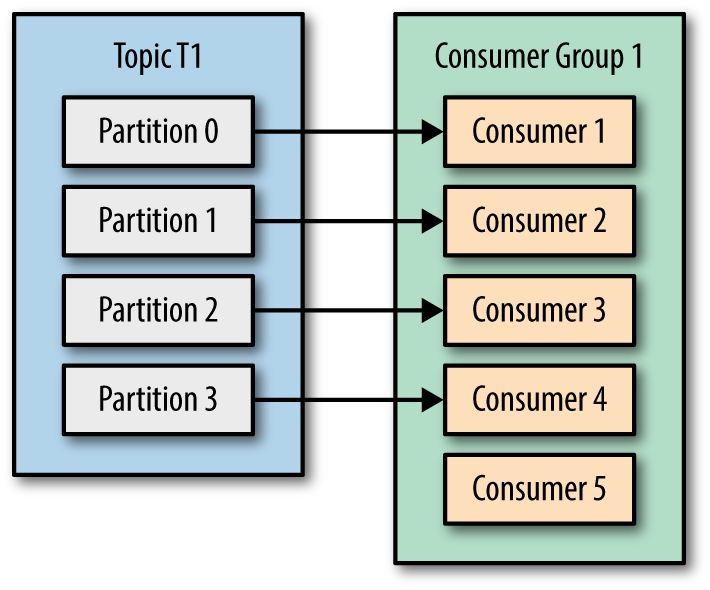
하나의 파티션 당 하나의 컨슈머가 1:1 연결되어야 하므로 아래와 같이 확장할 수는 없음
-
컨슈머 그룹은 컨슈머가 일정한 주기로 하는 하트비트(컨슈머가 poll()하거나 메시지의 오프셋을 커밋할때 보냄)를 통해 컨슈머가 메시지를 처리하고 있다는 것을 인지하며, 만약 오랫동안 하트비트가 없다면 해당 컨슈머의 세션이 타임아웃되고 리밸런스를 수행
-
카프카의 메시지 큐 시스템은 큐에서 메시지를 가져가도 사라지지 않기 때문에 여러 컨슈머 그룹이 동일 토픽에 붙을 수 있음
5. 카프카는 어떤 경우 필요한가?
Kafka vs RabbitMQ vs Google Cloud Pub/Sub
- 모두 비동기 통신을 제공하며, 프로듀서와 컨슈머가 분리되어 있음
RabbitMQ
- AMQP(Advanced Message Queuing Protocol, 클라이언트와 미들웨어간 메시지 교환 개방형 표준 프로토콜)을 위해 개발 되어 다른 AMQP 프로토콜 기반 MQ(ex. RabbitMQ, ActiveMQ, ZeroMQ)등과 데이터 교환이 수월
- 필요에 따라 동기/비동기 구현 가능
- 유연한 라우팅이 가능(exchanger가 메시지를 적절히 각각의 queue에 분배)하여 관리가 쉽고, 관리UI가 직관적이고 편리
- broker 중심적이며, producer와 consumer간 메시지 전달 보장에 초점을 맞추어 신뢰성이 높음
- 20k+/sec 처리 보장
Kafka
- 고성능, 고가용성, 확장성
- 분산 처리 시스템으로서, 확장성(scalability) 및 고가용성(high available)이 높음
- 따라서, 노드 장애에 대한 대응성이 높음
- 배치 처리가 가능해 네트워크 왕복 오버헤드를 줄일 수 있음
- 디스크 파일 시스템에 데이터를 저장함으로써 영속성(persistency)을 보장 (즉, 오류 시 복구가 가능)
- Producer 중심적이며, 메시지 전달 보장이 optional
- 메시지 전달 보장을 할 경우 처리속도가 느려져(리더와 팔로워 모두에게 ack(응답 승인)을 받야아 하므로) 카프카의 처리속도 측면의 장점이 상쇄
- 라우팅 기능이 없음 (producer가 직접 적절한 topic과 partion으로 보내줘야 함)
- 100k+/sec 처리 보장
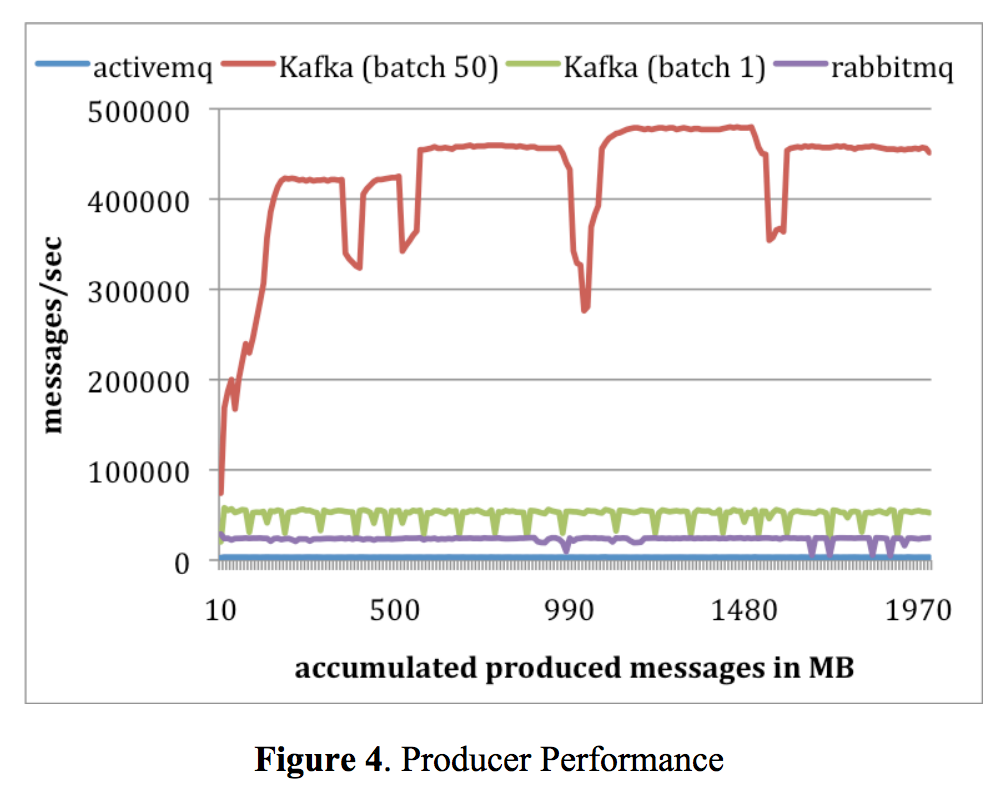
처리속도 비교
-
Producer의 메시지 배치 처리 성능 비교
-
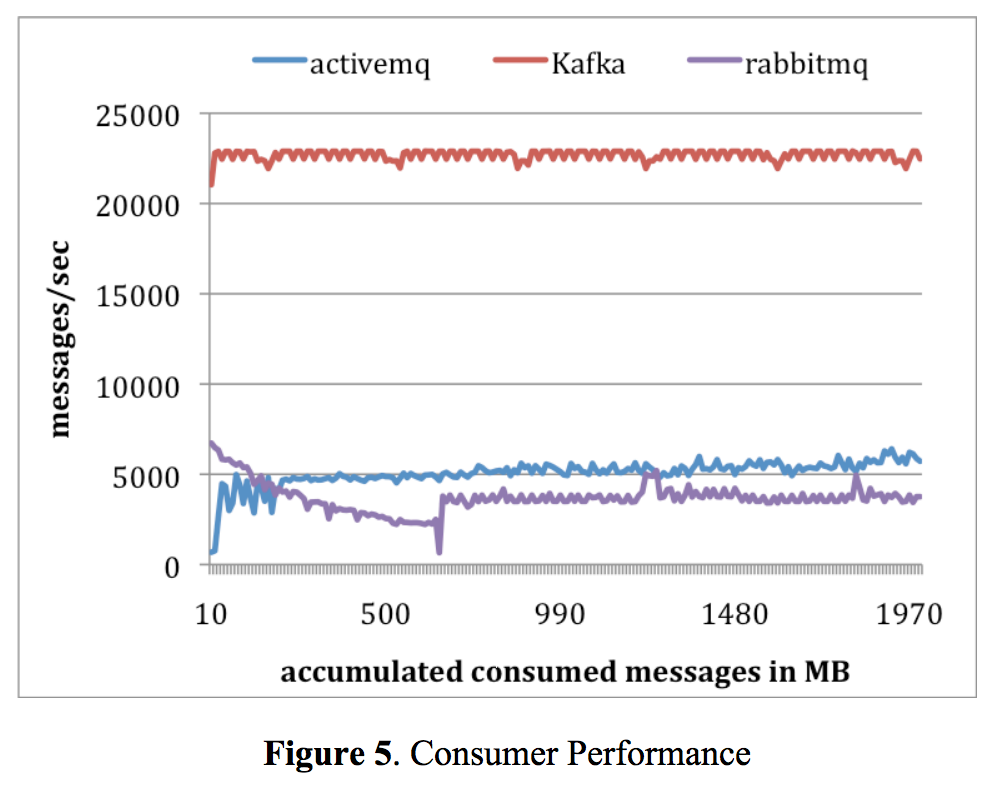
Consumer 메시지 수신 처리 성능 비교
Kafka
- 높은 처리량 및 고성능/분산/스케일 아웃이 중요한 경우
- 가용성(장애 대응)이 높아야 하는 경우
- 메시지 전달 보장이 필수적이지 않은 경우
- 메시지 처리 순서가 보장되어야 하는 경우
- 스트리밍 데이터 처리가 필요한 경우
- 메시지 영속성이 필요한 경우
RabbitMQ
- 빠르고 쉽게 메시지 큐 시스템을 구축하고자 하는 경우 (라우팅 기능이 유연함)
- 메시지 전달 보장이 필수적인 경우
- 메시치 처리 순서가 보장되지 않아도 되는 경우
- 메시지 영속성 X
Google Pub/Sub
- Kafka와 유사한 아키텍처 (topic 개념)
- 클라우드 서비스로서 별도의 설치나 운영이 필요없음
- 메시지 처리 순서 보장이 안됨(분산형 아키텍처)
- 메시지 영속성 X
(저장기간 최대 7일)
References
- 카프카, 데이터 플랫폼의 최강자: 실시간 비동기 스트리밍 솔루션 Kafka의 기본부터 확장 응용까지
- LINE에서 Kafka를 사용하는 방법
- 메시지큐(Message Queue) 알아보기
- MQ (Message Queue)란?
- 링크드인은 왜 카프카를 만들었나
- Apache kafka 개요
- [카프카] 페이지 캐시(Page Cache)
- [카프카] 토픽(Topic)과 파티션(Partition) 이해
- 구글 클라우드의 대용량 분산 큐 서비스인 Pub/Sub 소개 #1
- When to use RabbitMQ or Apache Kafka
- 카프카 VS RabbitMQ | RabbitMQ와 Kafka의 차이점
- [Kafka]Kafka vs RabbitMQ vs ActiveMQ
- [메시지 큐] Kafka, RabbitMQ 개념 및 비교
- Apache Kafka and Google Cloud Pub/Sub
.jpeg)

좋은 글 감사합니다! 글을 읽고 의문이 생겨서 댓글 남깁니다. 메시지 순서 부분을 보면 파티션에서 카프카는 메시지 순서를 보장하지 않는다고 써주셨습니다. 다른 블로그의 테스트 결과를 보니 정말로 순서가 뒤죽박죽 이더군요. 그런데 마지막 래빗과 카프카 등을 비교하는 문단에서 카프카에 메시지 처리 순서를 보장해야하는 경우 라고 써두셨는데, 모순되는 것 같아서.. 이게 맞는 걸까요? 제가 아직 파티션에 대한 이해가 부족한건지...