
Intro
최근 몇 년간 Transformer 모델의 등장 이후 BERT, GPT, RoBERTa, XLNet, ELECTRA, BART 등과 같은 언어 모델(Language Model)이 매해 새로운 SOTA를 달성하며 등장하고 있다.
특히 언어모델의 경우 self-supervised learning으로 영어 뿐만 아니라 최근 다양한 언어로 학습된 모델이 등장하고 있고, 그 덕에 다양한 자연어 처리 태스크들에서 fine-tuning시 데이터가 많지 않더라도 좋은 성능을 보여주고 있다. 이러한 트렌드를 이끈 것은 Transformer의 역할이 크지만 그 전에 Transformer의 전신인 Sequence-to-Sequnce모델과 Attention mechanism에 대해 먼저 간단하게 살펴보려고 한다.
Sequnece-to-Sequence
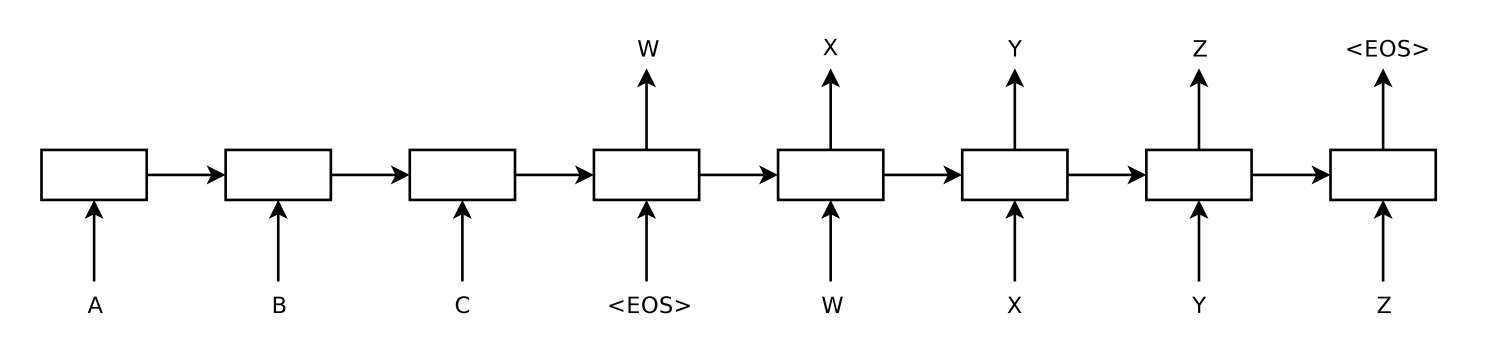
Sequence-to-Sequence(이하 seq2seq)모델은 2014년 구글에 의해 제안된 모델로서 이름 그대로 시퀀스 형태의 입력값을 받아 시퀀스 형태의 출력값을 만드는 모델이며, 기존 DNN모델이 입력과 출력 벡터의 차원이 고정되어있다는 한계를 극복하여 가변 길이의 출력을 가능하게 한 모델이다.
seq2seq모델은 기본적으로 RNN 모델을 기반으로 하며, 크게 인코더(Encoder)와 디코더(Decoder)로 구분된다.
1. Encoder
Encoder에서는 각 시퀀스마다 embedding vector를 입력으로 받아 입력 시퀀스의 마지막까지 순차적으로 weight을 업데이트한다.(RNN 학습 방법과 동일) 그렇게 되면 마지막 시퀀스의 hidden states는 이전 입력 시퀀스들을 정보를 순차적으로 반영하여 업데이트 된 상태이며, 입력 시퀀스의 전반적인 문맥을 반영하고 있다고 하여 컨텍스트 벡터(Context vector)라고 부른다.
2. Decoder
Decoder는 우선 Encoder의 전체적인 문맥이 학습된 context vector와 < SOS > (Start of Sentence) 토큰을 첫 입력으로 받아 출력 토큰을 예측한다.
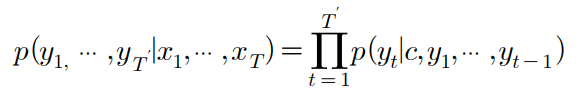
Decoder의 현재 시점(t)의 출력결과는 이전 시점(t1,...,t-1) 출력 결과의 조건부 확률로서, 이전 시점의 결과에 따라 현재 시점의 출력 결가 영향을 받게 되는 구조이며, 이렇게 예측된 출력값은 다시 다음 시퀀스의 예측을 위해 입력값으로 사용되고 이러한 과정이 < EOS > (End of Sentence) 토큰이 등장할 때 까지 반복된다.
Example (Machine Translation)
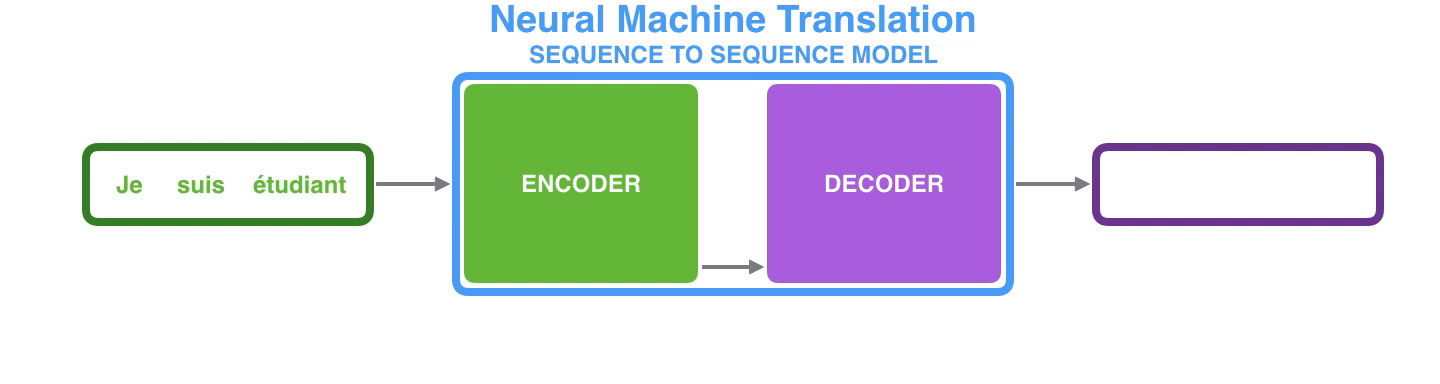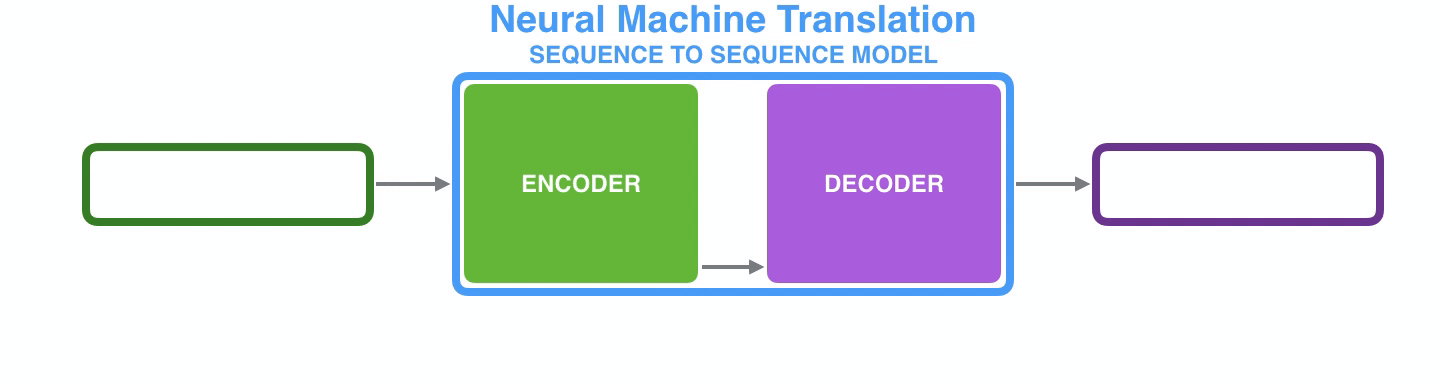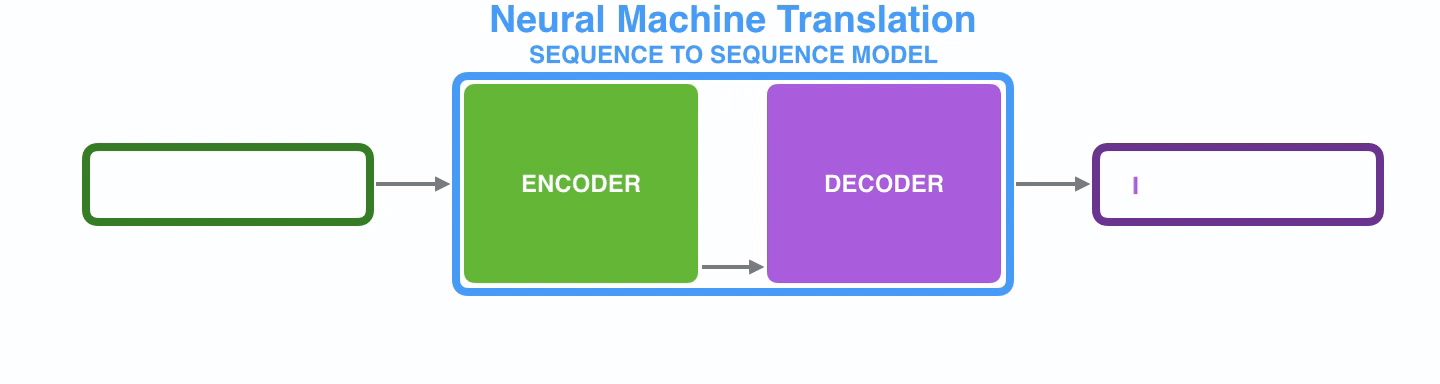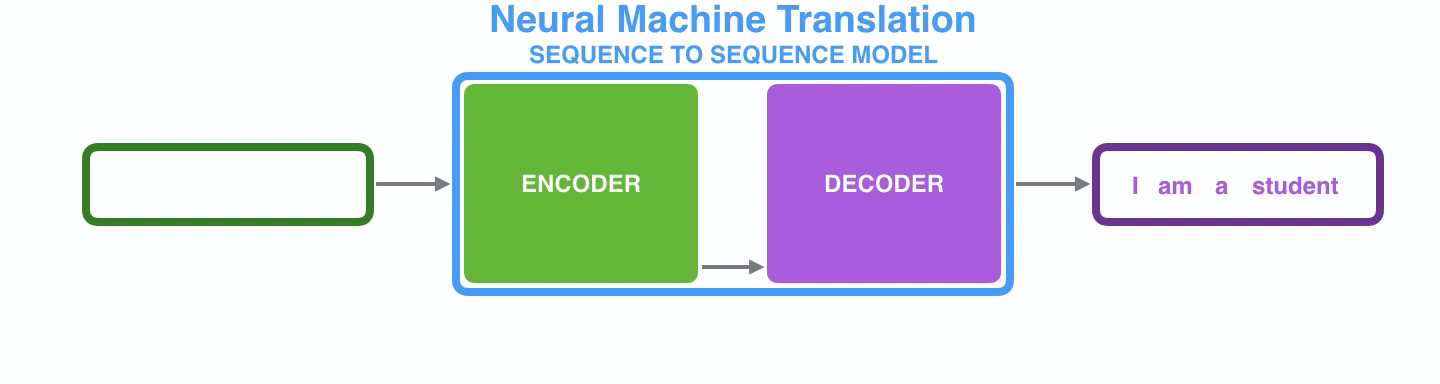
seq2seq를 기계번역에 적용할 시 위와 같이 프랑스어에 해당하는 입력 시퀀스들이 순차적으로 Encoder로 입력되어 마지막 시퀀스까지 weight을 업데이트하고 그렇게 업데이트 된 마지막 입력 시퀀스 즉, Context Vector를 Decoder의 입력으로 넘겨주어 영어로 출력하게 된다.
seq2seq의 한계
seq2seq는 출력 시퀀스의 가변 길이 출력이 가능해짐으로써 언어 모델의 발전을 가져왔지만 입력 시퀀스가 길어질 수 록 초기 입력 시퀀스의 정보를 잃게 되는 gradient vanishing 문제가 제기되었다. 아무래도 하나의 context vector에 입력 시퀀스의 모든 정보를 담다보니 전체 문맥 정보가 희미해질 수 밖에 없고 이는 RNN 계열의 모델(RNN, LSTM, GRU 등)에서 고질적으로 발생하는 문제이다.
Attention Mechanism
Attention mechanism은 위에서 언급한 seq2seq의 한계를 극복하기 위해 제안된 개념이다. Attention의 기본적인 아이디어는 Decoder에서 출력 토큰 예측 시 매 시점(time step)마다 입력 시퀀스의 토큰을 참조하여 연관성이 높은 토큰에 가중치를 높여 학습한다는 것이다.
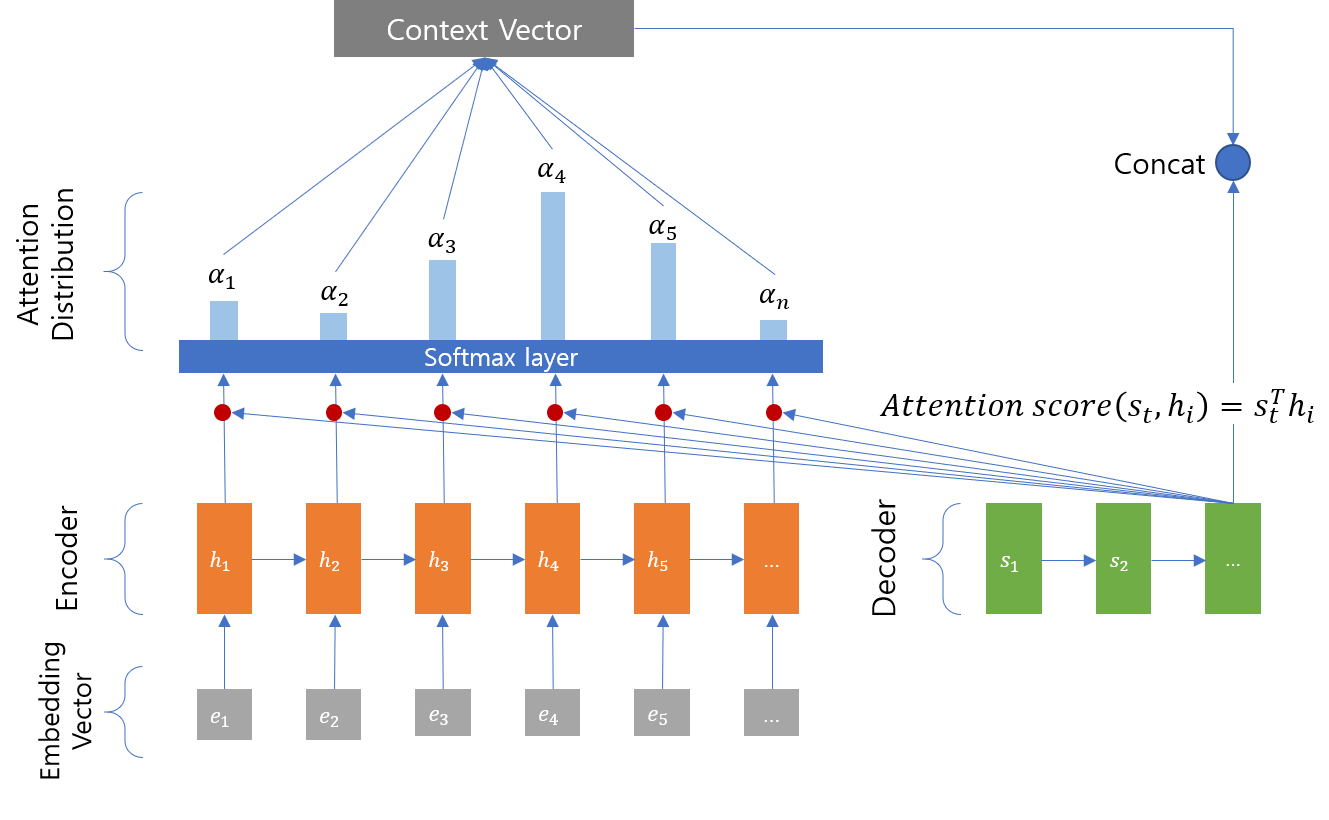
1. Query, Key, Value
Attention 계산은 Decoder 출력 토큰 예측 시 수행되며 아래와 같이 Query, Key, Value라는 개념이 사용된다.
Q(Query) : t 시점의 decoder셀의 hidden states
K(Key) : 모든 시점의 encoder셀의 hidden states
V(Value) : 모든 시점의 encoder셀의 hidden states
2. Attention Score
Attention Score란 Decoder에서 출력 토큰 예측 시 Encoder의 모든 시퀀스 정보를 참조(attention)하여 각각의 시퀀스가 얼마나 출력 토큰과 유사한지를 판단한 유사도 값이다.
이 과정에서 Decoder의 현재 t시점은 Query가 되고, 참조하고자 하는 Encoder의 모든 hidden states는 Key가 된다. 이때 Query는 전치(transpose) 후 모든 key에 대해 각각 내적(dot-product)연산을 수행하여 Encoder의 Key 갯수만큼의 Attention score를 계산한다.
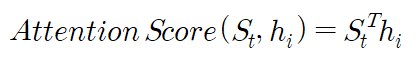
3. Attention Distribution
입력 시퀀스 갯수만큼 나온 Attention Score 리스트에 Softmax 함수를 적용한다. Softmax를 적용하게 되면 합이 1이되는 확률분포가 되는데 여기서 각각의 값들을 Attention weight라고 한다.
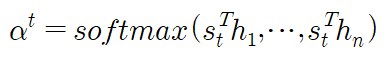
4. Attention Value
위에서 구한 Attention weight을 다시 각각의 Encoder의 hidden state와 곱셈연산을 하고, 이후 모든 값들을 더해주는 가중합(weighted sum)을 하여 최종 Attention Value(혹은 Context Value)를 구하여 이를 Decoder의 현재 t시점의 입력값으로 사용한다.
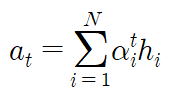
위의 과정을 거쳐 나온 최종 Attention value는 Decoder의 예측하려는 t 시점의 입력값으로 사용되고 매 시점 예측 시 마다 위와 같은 과정이 반복된다.
아래는 Attention 과정을 애니메이션으로 표현한 것이다.

Conclusion
사실 Transformer는 Sequence-to-Sequence와 같은 Encoder-Decoder 구조를 여러개 사용한 것이고, Transformer에서 사용되는 self-attention 및 multi-head attention 또한 기존 Attention mechanism을 응용한 것이기 때문에 Sequence-to-Sequence모델과 Attention 개념만 알아도 Transformer 아키텍처를 이해하는데 어렵지 않을 것이다. 또한 이후 등장한 모델들도 대부분 이와 같은 구조를 응용한 모델이라고 할 수 있기 때문에 확실히 이해하고 넘어가는 것이 좋을 듯 하다.
Tensorflow, Pytorch 공식 doc에서 seq-to-seq with attention모델 구현 tutorial이 준비되어 있으니 참고!
- Neural machine translation with attention
- NLP FROM SCRATCH: TRANSLATION WITH A SEQUENCE TO SEQUENCE NETWORK AND ATTENTION
Reference
.jpeg)