
Intro
많은 경우 머신러닝 문제는 훈련 샘플이 수천 심지어 수백만 개의 특성을 가지고 있다. 이는 모델의 학습을 느리게 할 뿐만 아니라 정교한 모델을 만들기 어렵게 하는데 이러한 문제를 차원의 저주(curse of dimensionality)라고 한다.
그리고 이러한 차원의 저주를 해결하기 위해 차원 축소 기법이 이용된다.
차원의 저주(curse of dimensionality)
현재 우리는 3차원의 공간에 살고 있어 그 보다 큰 4차원, 5차원 이상의 공간을 머리속으로 떠올리기 힘들다.
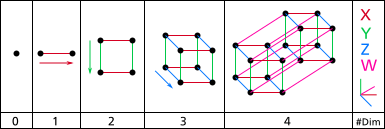
즉, 차원(Dimensionality)이라는 것은 공간을 뜻하고 위 그림과 같이 1개의 점인 0차원 부터 시작하여 4차원까지 공간은 몇 개의 점과 선을 그리느냐에 따라 무수히 많은 차원을 가지게 된다.
예를 들어, 단위 면적에서 임의의 두 점을 선택하였을 경우 두 점 사이의 거리는 대략 0.52가 된다. 이를 3차원 큐브에 나타낼 경우 두 점사이의 거리는 0.66정도가 된다. 하지만 만약 1,000,000차원의 초입방체에서 두 점을 무작위로 선택할 경우는 어떨까? 평균 거리는 대략 428.25가 된다.
차원의 높아짐으로써 두 점 사이를 표현하는 거리가 고무줄처럼 늘어나버렸는데, 이렇듯 고차원의 공간은 사실상 데이터 간 거리가 먼 굉장히 희박한 상태라 할 수 있다. 이것을 데이터 관점에서 보자면 데이터의 사이즈와 크기가 바로 차원이 되며, 데이터의 변수의 크기가 차원의 크기가 되며 변수가 많으면 많을수록 데이터의 차원은 계속해서 커지는 것이다.
고차원 데이터 셋의 모델 학습 문제
데이터를 표현하는 특징과 수가 많을 경우 모델이 더 잘 학습하는 것이 아닐까라는 생각이 들지만, 위에서 말했듯이 차원의 정도가 너무 클 경우 오히려 데이터의 주요 특징들이 희박해지는 현상이 발생하게 되어 모델이 과대적합하게 되는 문제가 발생한다.
이를 해결하기 위한 한가지 해결책은 훈련 샘플의 밀도가 충분히 높아질 때까지 훈련 세트를 키우는 것인데, 실제로는 일정 밀도에 도달하기 위해 필요한 훈련 샘플 수는 차원 수가 커짐에 따라 기하급수적으로 늘어나게되는 문제가 있다.
따라서, 다른 해결책으로 차원을 저차원 공간에 펼치는 투영(projection)이나 차원을 축소하는 주성분 분석(PCA)등이 이용된다.
차원 축소를 위한 방법
1. 투영(projection)
고차원 공간에 있는 훈렴 샘플을 저차원 공간으로 그대로 수직으로 투영하는 방법이며, 아래 그림과 같이 3차원 공간에 있는 샘플들은 사실 2차원 공간에 놓아도 데이터들의 특성이 많이 뭉개지지 않게 된다.
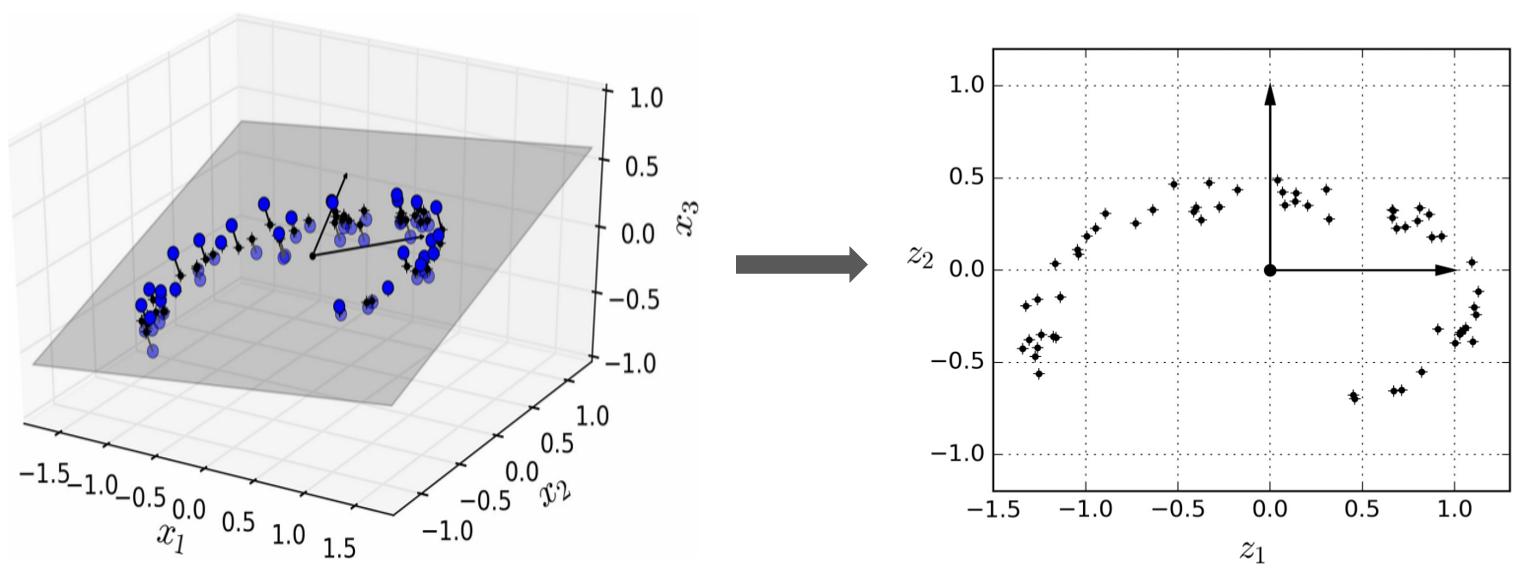
하지만, 투영하는 것이 모든 상황에 최적인 것은 아니다.
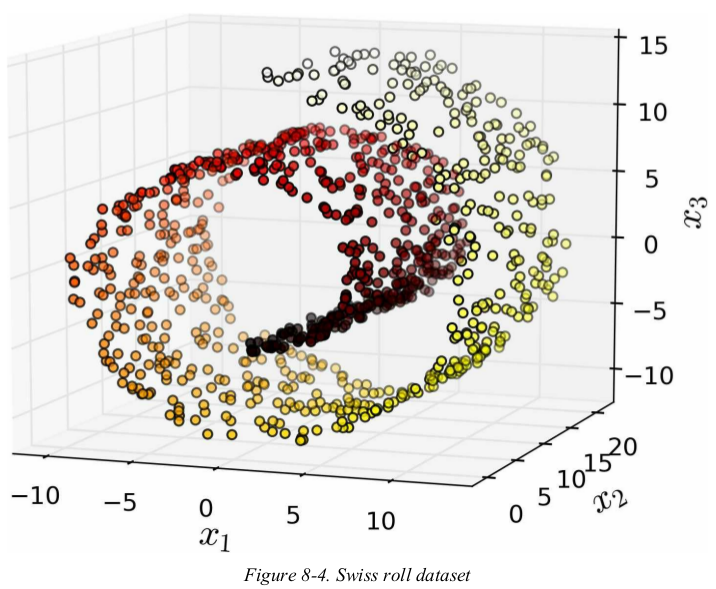
위 그림과 같이 데이터가 말려있을 경우 데이터를 그대로 투영하게 되면 어떻게 될까? 위 데이터 샘플을 그대로 수직으로 투영할 경우, 아래 왼쪽과 같은 그림이 된다.
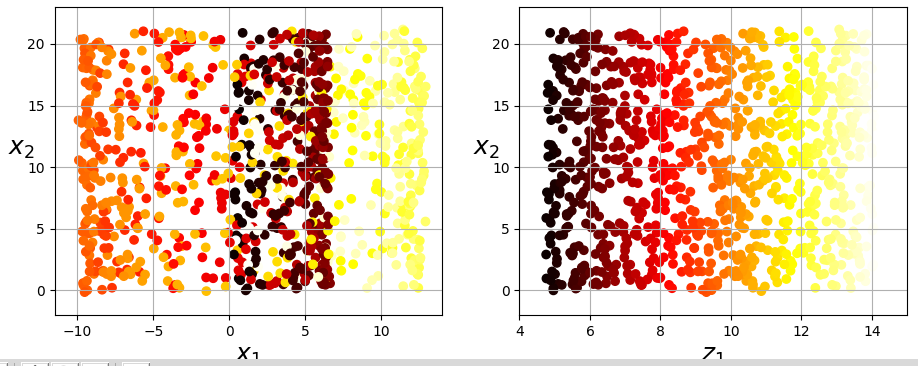
검정, 빨강, 노랑 샘플이 뭉개져버렸기 때문에 2차원에서는 표현을 잘 나타내지를 못하고 있다. 하지만 우리가 원하는 것은 바로 오른쪽과 같이 특성이 뭉개지지 않게 펼쳐진 그림일 것이다. 그리고 이렇게 구부려져 있는 데이터를 반듯이 펴기위해 사용되는 것이 바로 매니폴드 학습이다
2. 매니폴드 학습(manifold learning)
위에서 보았던 스위스 롤(swiss roll)데이터는 2D 매니폴드의 한 예였다. 한 가지 예를 더 들어 아래와 같은 데이터가 있다고 해보자.

위 데이터들 간의 거리를 직선상의 거리로 보았을 때 A와 C가 서로 가까울까, 아니면 A와 G가 서로 가까울까?
위 그림대로 보았을 때는 A와 C보다는 A와 G사이의 거리가 더 가까워 보인다. 하지만 위 데이터가 실은 아래의 그림을 구부려 놓은 그림이었다면 어떨까? 실제로는 어떤 점이 더 가까운가?

위와 같이, 저차원의 데이터가 고차원의 공간에서 휘어지거나 뒤틀려 있는 것을 매니폴드(manifold)라고 하며, 고차원 공간내에서 뒤틀려있는 데이터를 곧게 펴 유클리디안 거리(euclidean distance) 계산을 통해 데이터들 간의 거리를 찾는 학습을 매니폴드 학습(manifold learning)이라고 한다.
3. 주성분 분석(PCA)
주성분 분석(Principal Component Analysis)은 데이터의 차원을 축소하고자 할 떄 가장 인기 있게 사용되는 알고리즘이다.
주성분 분석이란 데이터를 가장 잘 표현하는 초평면을 찾아 분산을 최대로 보존하는 축을 찾는 것이다. 즉, 데이터를 가장 잘 표현하는 n개의 구간을 찾아 그것을 n개의 차원으로 축소하여 표현하는 방법이다.
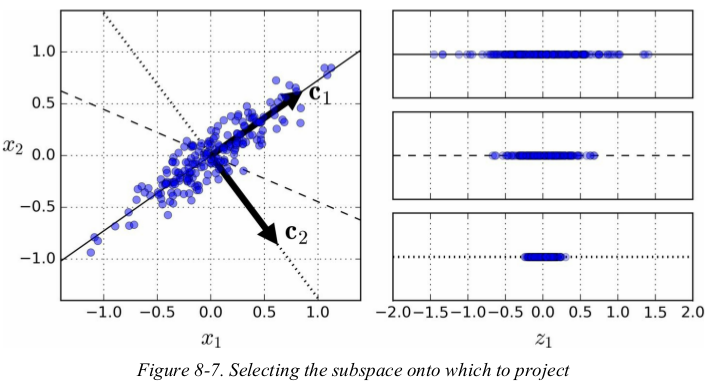
주성분을 찾는 과정
1. 데이터에 가장 가까운 초평면을 정의한 후, 데이터를 이 평면에 투영
2. 임의의 축을 선택 후, 데이터의 분산을 최대한 보존하는 축을 선택
3. 선택한 축을 기준으로 직교하는 축을 선택(두번째로 분산을 최대한 보존하는 축)
4. 위 과정을 반복하며 찾으려는 차원 수만큼 수행
위의 과정을 통해 찾은 i번째 축을 정의하는 단위 벡터를 i번째 주성분(PC, principal component)라고 하며, 이러한 주성분을 찾는 과정은 특이값 분해(SVD, Singular Value Decomposition)라는 표준 행렬 분해 기술을 통해 이루어 진다.
scikit-learn에서 PCA 사용하기
사이킷런에서 pca를 사용하기 위해서는 sklearn의 preprocessing모듈에서 PCA모델을 이용하면 된다.
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
data_3d = pca.fit_transform(data)PCA모델의 중요 파라미터는 n_components인데 이것이 바로 축소할 차원의 수이다. 위의 과정은 3차원으로 축소하게 된다.
breast cancer 데이터셋에 PCA를 적용
import pandas as pd
cancer = pd.read_csv('breast_caner.csv')
cancer.drop(['id','diagnosis'], axis=1, inplace=True) # 일단 필요없으므로 제외
print(cancer.shape)
print(cancer.head())
위 데이터는 총 30개의 차원을 가진 데이터셋이다. 이를 3개의 차원을 가진 데이터로 차원 축소를 해보려고 한다. 여기서 알아두어야 할 것은 보통 차원 축소를 하기 전에는 먼저 데이터를 정규화 한다는 것이다. 데이터 범위를 정규화 함으로써 데이터간 특성 비교를 쉽게하기 위해서다.
먼저 Standard Scaler를 통해 데이터를 정규화 한다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
cancer_scaled = pd.DataFrame(scaler.fit_transform(cancer), columns=cancer.columns)
print(cancer_scaled.head())
이제 PCA를 통해 3차원으로 축소 후 결과를 살펴본다.
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
cancer_pca = pca.fit_transform(cancer_scaled)
print(cancer_pca[:1]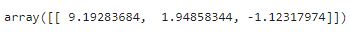
데이터가 numpy array 형태로 3개의 차원으로 축소가 된 것을 확인할 수 있다.
.jpeg)