Logistic Regression
Intro
이름은 regression이나 분류 알고리즘으로 주로 사용되는 알고리즘이 있다. 바로 로지스틱 회귀(Logistic Regression)이다. 로지스틱 회귀는 샘플이 특정 클래스에 속할 확률을 추정하는 방식으로 동작하는 이진 분류(Binary Classification) 모델이다.
Logistic Regression(로지스틱 회귀)
로지스틱 회귀(logistic regression)는 샘플이 특정 클래스에 속할 확률을 추정하는 데 널리 사용된다.(예를 들어 해당 이메일이 spam일 확률과 spam이 아닐 확률)
추정 확률이 50% 이상이면 모델은 그 샘플을 해당 클래스(label: 1)에 속한다고 예측하고 50%이하이면 클래스에 속하지 않는다고(label: 0) 예측한다.
확률 추정
기존 Regresion으로 분류문제를 해결하고자 할 경우 가장 큰 문제점은 바로 1이상 또는 0이하의 수로 나오는 예측값을 해석하는 일이다. 따라서 0과 1사이의 확률로 표현하여 0.5보다 크면 positive, 0.5보다 작으면 negative로 직관적으로 표현하고자 하는 것이 확률 추정이다.
어떤 사건이 일어날 확률은 아래와 같이 표현된다.
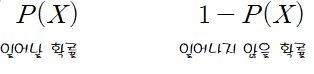
선형 회귀 모델과 같이 로지스틱 회귀 모델은 입력 특성의 가중치 합을 계산하고 편향을 더한다. 대신 선형 회귀처럼 바로 결과를 출력하지 않고 결괏값의 로지스틱(logistic)을 아래의 식을 통해 출력한다.
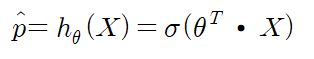
Logit Function
로짓 함수는 X의 값이 주어졌을 때 Y의 확률을 이용한 log odds이며 아래와 같이 나타낸다.
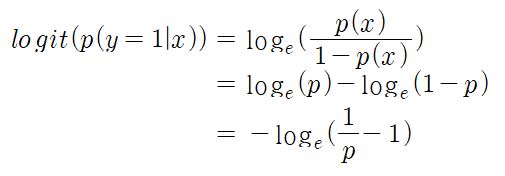
Sigmoid(=logistic) Fuction
로지스틱(또는 로짓)은 0과 1사이의 값을 출력하는 시그모이드 함수(Sigmoid Function)이다.(즉, S자 형태)
로지스틱 함수는 logit 함수의 역함수 형태로 z에 관환 확률을 산출하며 아래와 같은 식으로 표현된다.
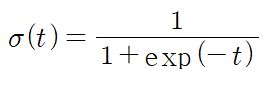
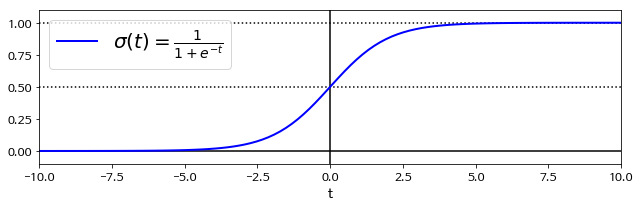
위 그래프와 같이 sigmoid function은 S자 형태로 이루어져 있으며 각 클래스에 속할 확률을 0.5를 기준으로 0.5이상이면 양성 클래스(1)로 예측하고, 0.5이하이면 음성 클래스(0)으로 예측한다.
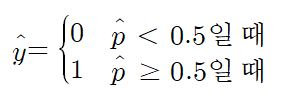
로지스틱 회귀의 비용 함수(Cost Function)
로지스틱 회귀 모델의 훈련 목적은 양성 샘플(y=1)에 대해서는 높은 확률을 추정하고 음생 샘플(y=0)에 대해서는 낮은 확률을 추정하는 모델의 파라미터 벡터 theta를 찾는 것이다.
전체 훈련 세트에 대한 비용 함수는 모든 훈련 샘플의 비용을 평균한 것이다. 이를 로그 손실(log loss)라고 부르며 아래와 같은 식으로 표현된다.
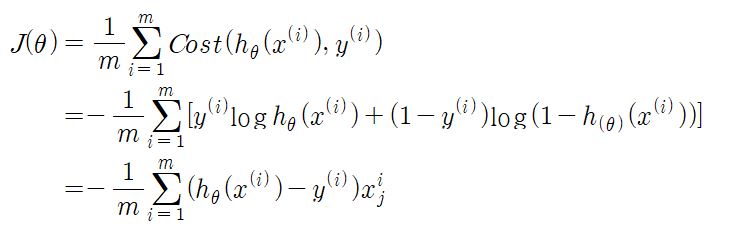
로지스틱 회귀 적용
breast cancer 데이터셋에 로지스틱 회귀를 적용해본다.
우선 breast cancer 데이터 셋은 총 30개의 features와 암 여부에 해당하는 1개의 y label값을 가지고 있다.
scikit-learn의 데이터 셋을 활용하였는데 이 데이터의 경우 이미 z-score 정규화가 되어있는 데이터 셋이다.
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
breast_cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state=42)
print(X_train.shape) # (426, 30)
print(y_train.shape) # (426, )훈련 셋과 테스트 셋을 나눈 데이터에 scikit-learn에서 제공하는 로지스틱 회귀 모델을 적용한다.
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression(C=0.01).fit(X_train, y_train)
print("train set score : ", logreg.score(X_train, y_train)) # 0.934
print("test set score : ", logreg.score(X_test, y_test)) # 0.930결과를 보았을 때 모델이 train set과 test set에 모두 93%의 정확도로 암을 분류하였는데, 실제로 잘 분류되었는지 test data 중 앞 10개만 실제 값과 비교해보았다.
pred_10 = logreg.predict(X_test)
print('실제 값: ',y_test[:10]) # 실제 값: [1 0 1 1 0 0 0 0 0 1]
print('예측 값: ',pred_10[:10]) # 예측 값: [1 0 1 1 1 0 1 0 0 1]두 개의 예측값만 빼고(암 아님을 암이라고 예측) 실제 값과 같은 예측결과를 보여준다.
Softmax Regression(소프트맥스 회귀)
로지스틱 회귀 모델은 여러 개의 이진 분류기를 훈련시켜 연결하지 않고도 직접 다중 클래스를 예측하도록 할 수 있다.
이를 소프트맥스 회귀(Softmax Regression) 또는 다항 로지스틱 회귀(Multinomial Logistic Regression)라고 한다.
- 샘플 x가 주어지면 소프트맥스 회귀 모델이 각 클래스 k에 대한 점수를 계산
- 그 점수에 소프트맥스 함수(softmax function)을 적용하여 각 클래스의 확률을 추정
- 로지스틱 회귀와 마찬가지로 추정 확률이 가장 큰 클래스를 선택
- 각 클래스가 될 확률 값을 모두 더하면 1이 됨
소프트맥스 함수
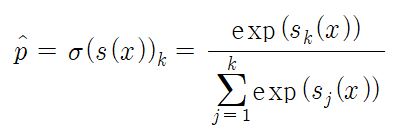
- k는 클래스의 수이며, s(x)는 샘플 x에 대한 각 클래스의 점수를 담고 있는 벡터
소프트맥스 회귀 분류기의 예측

크로스 엔트로피(cross-entropy) 비용 함수
- 크로스 엔트로피는 추정된 클래스의 확률이 타깃 클래스에 얼마나 잘 맞는지 측정하는 용도로 사용
Softmax Regression 적용
scikit-learn의 LogisticRegression() 클래스에 multi_class 매개변수를 "multinomial"로 바꾸면 소프트맥스 회귀를 사용
- 소프트맥스 회귀 사용 시 solver 매개변수를 "lbfgs" 지정
- C를 사용하여 l2규제 적용
from sklearn.linear_model import LogisticRegression
softmax_reg = LogisticRegression(multi_class='multinomial', solver='lbfgs', C=10)
spftmax_reg.fit(X_train, y_train).jpeg)