멀티 GPU로 TEI(Text Embeddings Inference) 성능 향상하기

RAG(Retrieval Augmented Generation)를 도입하려는 기업들이 늘어나며 LLM과 더불어 많은 관심을 받는 분야가 시맨틱 검색(Semantic search)입니다. 시맨틱 검색은 기존 키워드 검색의 한계를 넘는 문맥, 의미 기반의 검색을 의미합니다.
기존의 TF-IDF, BM25와 같은 Term-Frequency 기반의 알고리즘은 단어 그 자체만을 보기 때문에 앞뒤 문맥 뿐만 아니라 동의어도 구분할 수 없었습니다. 이후 Word2Vec, FastText 등의 워드 임베딩 알고리즘이 등장했지만, 이 또한 각 단어에 고정된 벡터를 부여하는 단어 수준의 임베딩이며 문맥을 반영하지 못한다는 한계가 존재했습니다. 이후 Transformer 아키텍처의 등장과 함께 문장 수준의 임베딩(Sentence Embedding)이 가능해지며, 문맥 기반의 표현이 가능해졌고 현재는 AI 검색 시장의 핵심 기술이 되었습니다.
현재 RAG의 도입과 함께 임베딩 모델에 대한 수요가 상당합니다. OpenAI, Cohere, Google 등 API 기반 상용 임베딩 모델을 사용하는 곳도 많지만, 오픈소스 임베딩 모델을 직접 서빙하여 활용하는 방안도 많이 존재합니다. 기업 단위의 큰 데이터가 있는 곳 혹은 RAG 서비스를 제공하는 곳에서 상용 API를 사용하기에는 비용적인 측면이 다소 부담이 될 것이며 최근에는 오히려 오픈소스 모델들이 더 좋은 성능을 내는 경우가 많기에 간단한 프로토타입 목적이 아니라면 오픈소스 모델 서빙이 더 효율적일 수 있습니다.
본 글에서는 임베딩 모델 서빙 프레임워크 중 가장 인기가 많고 성능이 좋은 것으로 알려진 허깅페이스의 Text Embeddings Inference에 대해 소개하고자 합니다. 또한 대규모 텍스트 임베딩 작업을 수행할 때, 단일 GPU로는 성능에 한계가 있습니다. 특히 많은 요청을 동시에 처리해야 하는 환경에서는 여러 GPU를 효율적으로 활용하는 멀티 GPU 설정이 필수입니다. 이와 관련하여 멀티 GPU 환경에서 TEI 서빙 방법과 이를 위한 Docker 및 Nginx 설정을 단계별로 설명합니다.
Text Embeddings Inference(TEI)
Text Embeddings Inference(TEI)은 오픈 소스 텍스트 임베딩 모델의 효율적인 배포 및 제공을 위해 설계된 포괄적인 툴킷입니다. FlagEmbedding, Ember, GTE, E5 등 가장 인기 있는 모델에 대한 고성능 추출을 가능하게 합니다.
TEI는 배포 프로세스를 최적화하고 전반적인 성능을 향상시키기 위해 맞춤화된 여러 기능을 제공합니다.
주요 기능:
- Streamlined Deployment: TEI eliminates the need for a model graph compilation step for an easier deployment process.
- Efficient Resource Utilization: Benefit from small Docker images and rapid boot times, allowing for true serverless capabilities.
- Dynamic Batching: TEI incorporates token-based dynamic batching thus optimizing resource utilization during inference.
- Optimized Inference: TEI leverages Flash Attention, Candle, and cuBLASLt by using optimized transformers code for inference.
- Safetensors weight loading: TEI loads Safetensors weights for faster boot times.
- Production-Ready: TEI supports distributed tracing through Open Telemetry and exports Prometheus metrics.
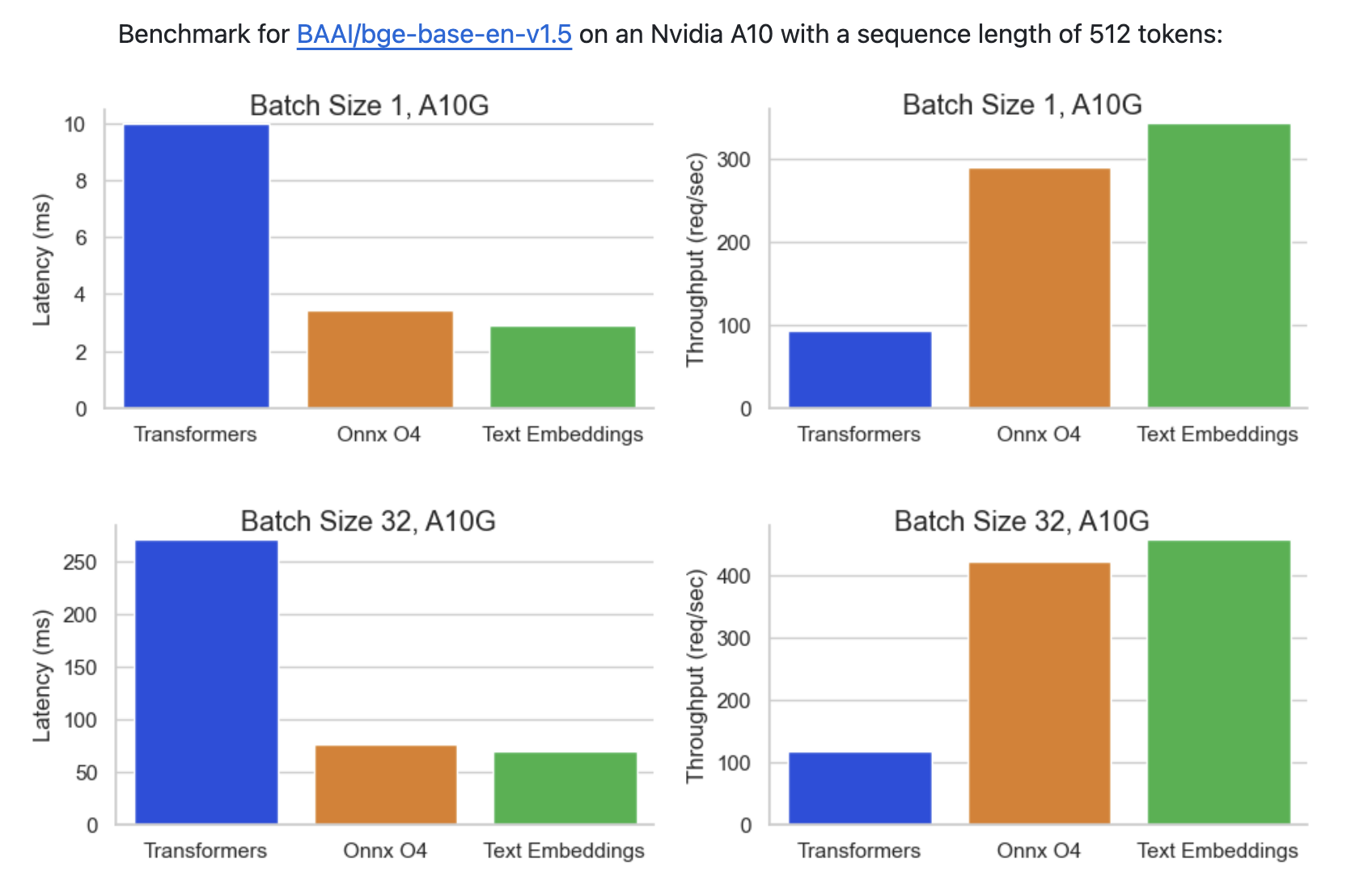
1. 멀티 GPU 환경 내 TEI 추론
기본적으로 TEI는 하나의 컨테이너에서 하나의 GPU만 사용할 수 있습니다. 즉, 2개의 GPU를 활용하고자 할 경우, 각 GPU에 별도의 TEI 컨테이너를 할당하여 총 2개의 TEI 컨테이너를 실행해야 합니다.
(참조: TEI utilizing only one GPU in single node multi gpu setup)
하지만 이렇게 구성할 경우, 동일한 모델이지만 각 컨테이너마다 서로 다른 포트(port)를 부여해야 합니다. 따라서 앞단에 로드밸런서와 같은 기능이 필요하며, 각 컨테이너를 하나의 프록시 패스로 묶어주기 위해 Nginx활용하여 멀티 GPU 환경에서의 로드밸런싱을 구현해보도록 하겠습니다.
전체 코드는 github 참조: https://github.com/jaehyeongAN/tei-multi-gpus-serving
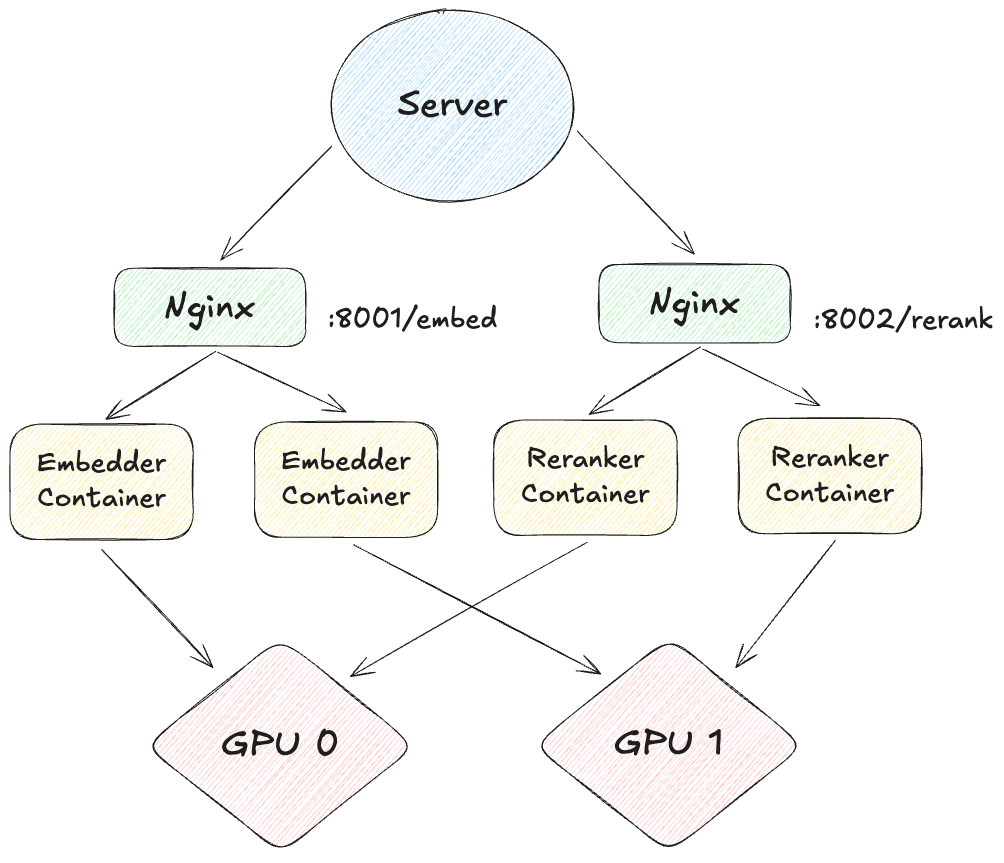
2. 멀티 GPU 로드 밸런싱 구성
Nginx를 사용하여 GPU별로 실행되는 각 TEI 컨테이너로 요청을 분산할 수 있습니다. 이를 통해 요청이 각 GPU로 고르게 전달되어 효율적인 로드 밸런싱이 이루어지게 됩니다.
해당 예제에서는 RAG에서 빠지지 않는 2가지 모델, Embedding 모델과 Reranker 모델을 각각 2개의 GPU 환경에 서빙하고자 합니다.
임베딩 모델은
BAAI/bge-m3, 리랭커 모델은BAAI/bge-reranker-v2-m3을 사용합니다.
2.1 Nginx Dockerfile 구성
먼저 Nginx의 기본 설정 파일을 수정하여, 각 요청이 특정 컨테이너로 전달되도록 Nginx를 설정합니다. 아래의 Dockerfile은 Nginx 컨테이너를 설정하기 위해 사용됩니다.
- Nginx Dockerfile (
./Dockerfile):
FROM nginx:latest
RUN rm /etc/nginx/conf.d/default.conf
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 802.2 Nginx Config 설정
Nginx의 설정 파일을 작성하여 로드 밸런싱을 수행합니다. 각각의 서비스에 대한 Nginx 설정 파일을 작성해 각 서비스에 대한 요청이 해당 GPU 컨테이너로 전달되도록 합니다.
- Embedder(
bge-m3) Nginx 설정 (./nginx-embedder.conf):
upstream bge-embedder-tei {
server bge-embedder-tei-0;
server bge-embedder-tei-1;
}
server {
listen 80;
location / {
proxy_pass http://bge-embedder-tei;
}
}- Reranker(
bge-reranker-v2-m3) 설정 (./nginx-reranker.conf):
upstream bge-reranker-tei {
server bge-reranker-tei-0;
server bge-reranker-tei-1;
}
server {
listen 80;
location / {
proxy_pass http://bge-reranker-tei;
}
}3. Docker 빌드 및 컨테이너 실행 스크립트
Docker와 Nginx 설정이 완료되었으면, 이를 실행할 스크립트를 작성합니다. 이 스크립트는 각 GPU마다 컨테이너를 실행하며, Nginx를 통해 로드 밸런싱을 설정합니다.
실행 스크립트 (./run.sh):
#!/bin/bash
# 공통 변수 설정
# 현재 디렉토리의 `data` 폴더를 Docker 컨테이너에 마운트할 볼륨 디렉토리로 지정
volume=$PWD/data
# 사용할 Docker 이미지 지정 (해당 예제에서는 Nvidia T4 기반의 이미지 활용)
image=ghcr.io/huggingface/text-embeddings-inference:turing-1.3 # Tesla T4
# 사용할 모델의 버전(revision)을 지정 (기본은 main 브랜치)
revision=main
# Docker 네트워크 생성
# `tei-net`이라는 네트워크를 생성하여 모델 컨테이너와 Nginx 로드 밸런서를 연결
# `|| true`는 이미 네트워크가 존재하는 경우 오류를 무시하고 진행
docker network create tei-net || true
# Docker 컨테이너 실행을 위한 함수 정의
# 이 함수는 세 개의 인자를 받음:
# - model: 실행할 모델의 이름 (Hugging Face 모델 허브에 등록된 모델 ID)
# - port: Nginx 로드 밸런서가 외부에 노출할 포트 번호
# - service_name: 모델 컨테이너와 Nginx 컨테이너의 서비스명을 구성하는데 사용
# - config_file: Nginx 로드 밸런서 설정 파일 경로
run_docker() {
local model=$1
local port=$2
local service_name=$3
local config_file=$4
# 모델 컨테이너 실행 (해당 예제에서는 두 개의 GPU 장치를 사용해 컨테이너를 각각 실행하며, GPU ID는 0과 1로 할당)
for i in $(seq 0 1); do
docker run --runtime=nvidia -d --gpus '"device='$i'"' \
--network tei-net --name ${service_name}-$i \
-v $volume:/data --pull always $image \
--model-id $model --revision $revision --auto-truncate
done
# Nginx 로드 밸런서 컨테이너 실행
# 모델에 따라 지정된 Nginx 설정 파일을 사용해 로드 밸런서 컨테이너를 시작
docker run -d --network tei-net --name nginx-${service_name}-lb \
-v $PWD/${config_file}:/etc/nginx/conf.d/default.conf:ro \
-p $port:80 nginx:latest
}
# 모델별 Docker 컨테이너 실행
# Text Embeddings 모델과 Re-ranker 모델의 컨테이너를 각각 실행하고, 각 모델에 대해 Nginx 로드 밸런서를 구성
# `bge-m3` 모델은 8001 포트를 통해 외부에 노출
# `bge-reranker-v2-m3` 모델은 8002 포트를 통해 외부에 노출
run_docker "BAAI/bge-m3" 8001 "bge-embedder-tei" "nginx-embedder.conf"
run_docker "BAAI/bge-reranker-v2-m3" 8002 "bge-reranker-tei" "nginx-reranker.conf"4. 실행 방법
위의 실행 스크립트를 통해 각 GPU마다 별도의 TEI 컨테이너를 실행하고, Nginx가 이를 관리하도록 합니다.
1. run.sh 스크립트를 실행하여 Nginx 로드 밸런서 및 Docker 컨테이너를 시작합니다:
./run.sh
2. 각 서비스는 설정된 포트 (8001, 8002)로 접근할 수 있습니다. Nginx가 로드 밸런싱을 수행하므로, 각각의 포트로 요청을 보내면 적절한 GPU로 요청이 전달됩니다.
- Docker 컨네이너 확인:
$ docker ps

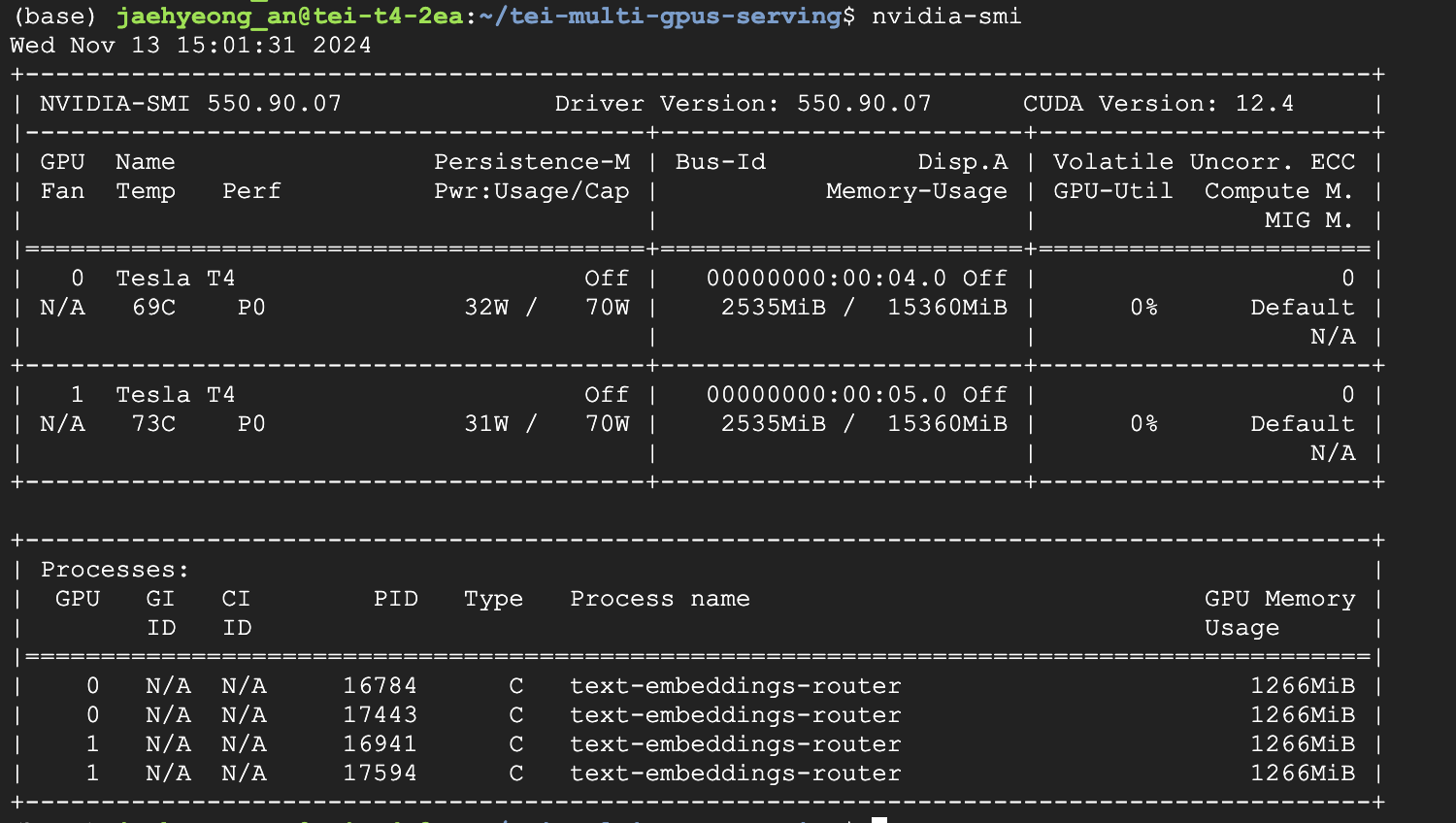
- nvidia-smi:
$ nvidia-smi
5. 결론
이 글에서는 멀티 GPU 환경에서 Text Embeddings Inference 성능을 향상시키기 위해 Nginx와 Docker를 활용한 로드 밸런싱 설정을 설명했습니다. 이를 통해 TEI가 멀티 GPU 환경에서 효율적으로 동작할 수 있게 하며, 대규모 데이터 처리를 보다 원활하게 수행할 수 있습니다.
.jpeg)

tei로 multi gpu inference 하는 방법 찾아봐도 잘 안나왔는데 쉽게 정리해주셨네요 감사합니다!