문제
문제
올해 ACM-ICPC 대전 인터넷 예선에는 총 n개의 팀이 참가했다. 팀은 1번부터 n번까지 번호가 매겨져 있다. 놀랍게도 올해 참가하는 팀은 작년에 참가했던 팀과 동일하다.
올해는 인터넷 예선 본부에서는 최종 순위를 발표하지 않기로 했다. 그 대신에 작년에 비해서 상대적인 순위가 바뀐 팀의 목록만 발표하려고 한다. (작년에는 순위를 발표했다) 예를 들어, 작년에 팀 13이 팀 6 보다 순위가 높았는데, 올해 팀 6이 팀 13보다 순위가 높다면, (6, 13)을 발표할 것이다.
창영이는 이 정보만을 가지고 올해 최종 순위를 만들어보려고 한다. 작년 순위와 상대적인 순위가 바뀐 모든 팀의 목록이 주어졌을 때, 올해 순위를 만드는 프로그램을 작성하시오. 하지만, 본부에서 발표한 정보를 가지고 확실한 올해 순위를 만들 수 없는 경우가 있을 수도 있고, 일관성이 없는 잘못된 정보일 수도 있다. 이 두 경우도 모두 찾아내야 한다.
입력
첫째 줄에는 테스트 케이스의 개수가 주어진다. 테스트 케이스는 100개를 넘지 않는다. 각 테스트 케이스는 다음과 같이 이루어져 있다.
팀의 수 n을 포함하고 있는 한 줄. (2 ≤ n ≤ 500)
n개의 정수 ti를 포함하고 있는 한 줄. (1 ≤ ti ≤ n) ti는 작년에 i등을 한 팀의 번호이다. 1등이 가장 성적이 높은 팀이다. 모든 ti는 서로 다르다.
상대적인 등수가 바뀐 쌍의 수 m (0 ≤ m ≤ 25000)
두 정수 ai와 bi를 포함하고 있는 m줄. (1 ≤ ai < bi ≤ n) 상대적인 등수가 바뀐 두 팀이 주어진다. 같은 쌍이 여러 번 발표되는 경우는 없다.
출력
각 테스트 케이스에 대해서 다음을 출력한다.
n개의 정수를 한 줄에 출력한다. 출력하는 숫자는 올해 순위이며, 1등팀부터 순서대로 출력한다. 만약, 확실한 순위를 찾을 수 없다면 "?"를 출력한다. 데이터에 일관성이 없어서 순위를 정할 수 없는 경우에는 "IMPOSSIBLE"을 출력한다.
접근
각 팀의 작년 등수가 주어지고, 그로부터의 상대적인 순위의 변경이 주어진다.
이에 따라 작년 등수에 의한 각 팀의 관계를 DAG로 나타내면
다음과 같이 그려진다고 생각 할 수 있다.
예를 들어, 작년 등수가 1등부터 순서대로 5, 4, 3, 2, 1 이라고 하면,
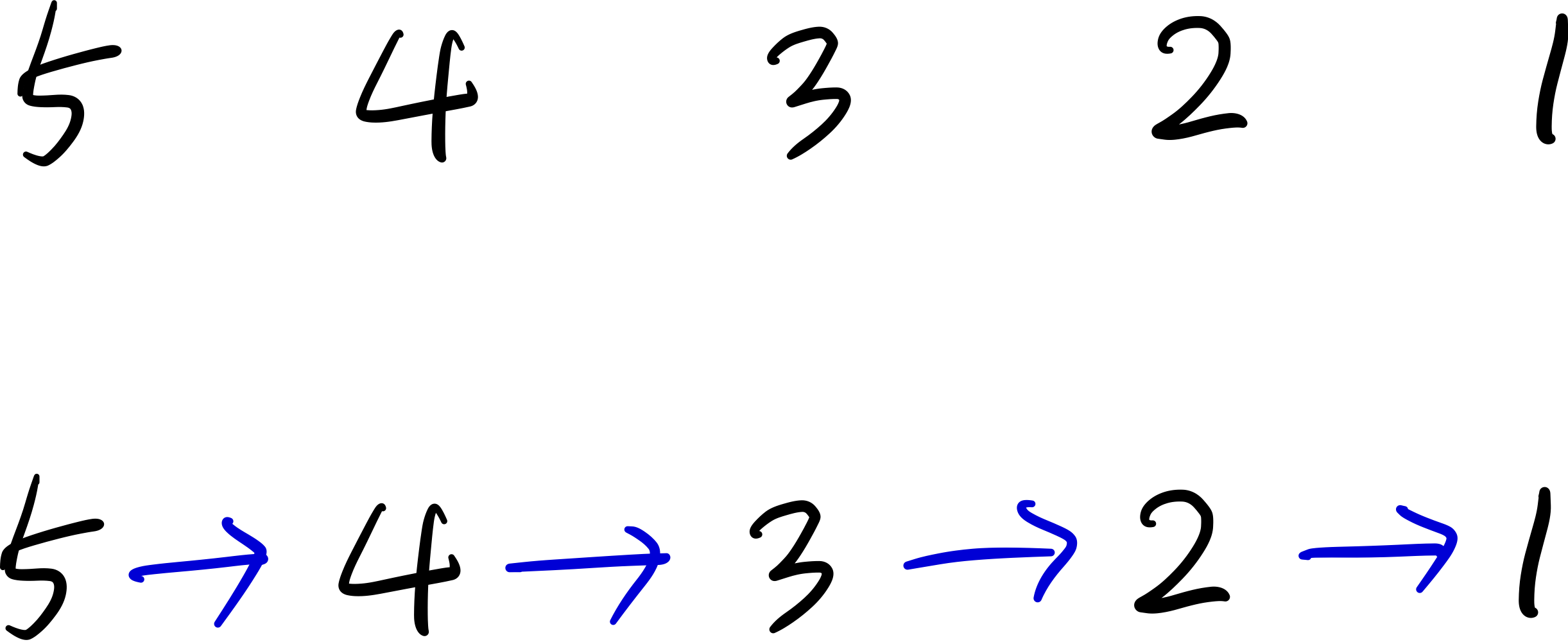
위와 같은 형태로 그래프를 그릴 수 있다.
하지만 이렇게 그리게 된다면, 변경된 상대적인 순위를 적용할 수 없다.
예를들어 올해에는 4팀보다 2팀이 등수가 높다는 입력이 주어졌을 때,
이를 정확하게 표현할 수 있는 방법이 위 그래프에서는 없다는 의미이다.
따라서, 다음과 같이 그려주도록 한다.

이렇게 표현 한다면, 변경된 순위에 대한 데이터는 위 그래프에서 해당하는 간선의 방향을 바꿔주고, 간선을 구성하는 두 정점의 진입 차수(in degree)를 증감하는 것으로 표현이 가능하다.
입출력 예시의 첫번째 테스트케이스에 주어진 대로,
(2, 4)와 (3, 4)의 상대적인 순위가 각각 달라졌다고 하면, 변경사항이 적용된 그래프는 다음과 같다.
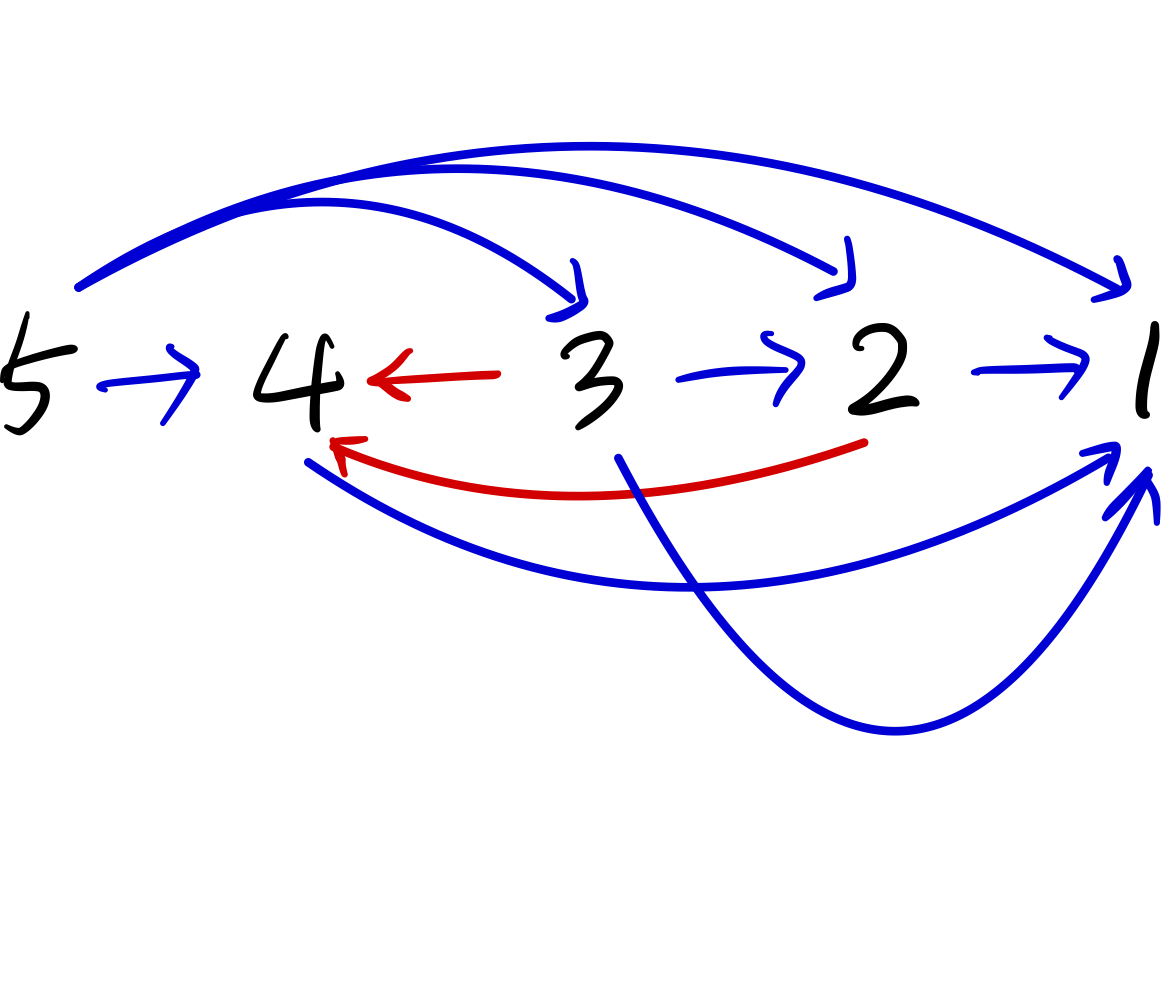
이제 위 그래프를 다시 위상정렬 하게되면 변경된 등수를 알아낼 수 있다.
예외
문제에서 두가지 예외에 대한 처리를 요구했다.
1. 확실한 순위를 찾을 수 없는 경우
2. 데이터에 일관성이 없어 순위를 정할 수 없는 경우
1. 확실한 순위를 찾을 수 없는 경우
이는 주어진 입력으로 DAG가 2개 이상 그려질 수 있는 경우를 의미한다.
이는 위상 정렬을 하기위한 한번의 순회에서, 진입차수(in degree)가 0이되는 정점이 2개 이상 존재한다는 것을 의미한다.
그러나 문제의 조건에서,
변경된 순위의 입력을 두 정수 , 의 쌍으로 줄 때
(1 ≤ < ≤ n) 이며, '같은 쌍이 여러 번 발표되는 경우는 없다'고 하였고,
우리는 모든 정점이 연결된 DAG에서 방향만을 전환하여 그래프를 수정할 것이기 때문에
사이클이 존재하는 경우를 제외하고는 두 정점의 진입차수가 같은 경우는 존재하지 않는다.
'사이클이 존재하는 경우'는 2번 예외에 해당하므로,
문제에서 제시한 '확실한 순위를 찾을 수 없는 경우'는 존재하지 않는다.
2. 데이터에 일관성이 없어 순위를 정할 수 없는 경우
이는 그래프에 사이클이 존재하는 경우를 의미한다.
사이클이 존재하는 그래프를 위상정렬 할 경우,
사이클에 포함된 정점의 진입 차수가 0이 되지 않기 때문에
해당 정점은 큐에 담기지 않고,
따라서 위상 정렬된 정점의 순서를 구하기 위한 배열에 담긴 정점의 갯수가
전체 정점의 개수보다 적을 것이다.
코드
from collections import deque
def solution(A: list, B: list):
N = len(A)
M = len(B)
adj_matrix = [[False] * (N+1) for _ in range(N+1)]
in_degree = [0] * (N+1)
for i in range(N):
in_degree[A[i]] = i
for j in range(i+1, N):
adj_matrix[A[i]][A[j]] = True
for i in range(M):
f = B[i][0]
r = B[i][1]
r, f = (r, f) if adj_matrix[r][f] else (f, r)
in_degree[f] -= 1
in_degree[r] += 1
adj_matrix[r][f] = False
adj_matrix[f][r] = True
start = 0
for i in range(1, len(in_degree)):
if in_degree[i] == 0:
start = i
return topological_sort(in_degree, adj_matrix, start)
def topological_sort(in_degree, adj_matrix, start):
queue = deque()
queue.append(start)
visited = [False] * (len(in_degree))
visited[0] = True
visited[start] = True
T = []
while queue:
cur = queue.popleft()
if len(queue) > 0:
return '?'
T.append(str(cur))
for i in range(1, len(adj_matrix)):
if adj_matrix[cur][i] and not visited[i]:
in_degree[i] -= 1
if in_degree[i] == 0:
visited[i] = True
queue.append(i)
if len(T) == len(adj_matrix)-1:
return ' '.join(T)
else:
return 'IMPOSSIBLE'
if __name__ == '__main__':
import sys
T = int(sys.stdin.readline().rstrip())
answers = []
while T > 0:
T -= 1
_ = int(sys.stdin.readline().rstrip())
A = list(map(int, sys.stdin.readline().split()))
B = []
for _ in range(int(sys.stdin.readline().rstrip())):
B.append(tuple(map(int, sys.stdin.readline().split())))
answers.append(solution(A, B))
for i in range(len(answers)):
sys.stdout.write(answers[i])
sys.stdout.write('\n')