강화학습을 하는데 필요한 기초 용어들을 정리해 본 글이다.
강화학습이란
제어 과제 (control task)
주어진 조건에서 어떤 동작을 취해야 할지 결정하는 문제들을 일컫는 과제들
강화 학습 (reinforcement learning)
제어 과제의 표현 및 해결을 위한 틀(프레임워크)이다.
틀을 벗어나지 않는 한에서, 주어진 구체적인 과제에 맞는 특정한 알고리즘을 임의로 선택할 수 있는 것이 특징이다. (이 여러 알고리즘은 다음 글에서 다룰 예정이다.)
제어 과제에서는 이미지 처리 같은 과제들과는 다르게 시간이라는 차원이 추가되어 학습하게 된다.
(데이터를 동적으로 받아서 동작을 처리해야 지속적으로 어떤 동작을 취할지 결정할테니)
강화학습에서는 일반적인 기계학습처럼 정답 데이터(label data)를 필요로 하지 않고, 최종적인 목표, 피해야 할 상황, 행동의 결과에 따라 적절한 보상을 제공하지만 하면 된다.
-> 이것들을 체계적으로 정리한 용어들을 밑에 설명한다.
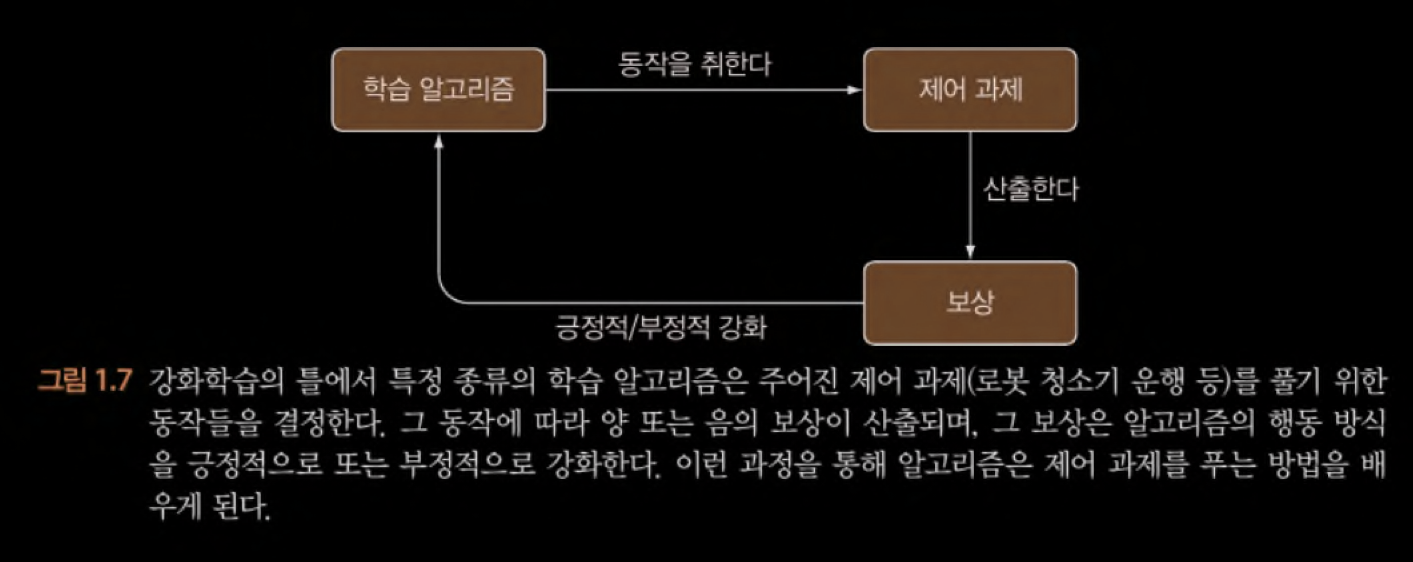
강화학습을 해결하는 방법
강화학습 과제(제어 과제)를 해결하는데 두 가지 방법이 있다.
-
동적 계획법
복잡한 고수준의 문제를(추가 정보 없이 풀 수 있을 정도로 작은 문제들로) 분해하고, 이 작은 문제들을 풀어서 전체적인 해답을 조립하는 알고리즘
단점으로는, 실제 문제에서는 적용 범위가 넓지 못 할 수 있다.
-
몬테카를로 방법
환경의 무작위 표집(random sampling, 확률 표집 | 시행착오)에서 시행착오 전략과 동적 계획법 전략을 적절히 섞은 접근 방식
강화학습 용어
- 목표(objective) : 과제에 필요로 하는 전체적인 목표를 정의해야 한다. → 목적함수(오차함수) 만들기
- 환경(environment) : 입력 데이터를 생성하는 환경
환경은 하나의 동적 과정(dynamic process) 즉, 시간의 함수이고, 크기와 형식이 다양한 데이터를 끊임없이 산출한다. - 상태(state) : 알고리즘 구현의 편의를 위해, 연속적인 환경 데이터 스트림을 일련의 이산적인 조각들로 나누고 묶는데, 이런 개별 데이터 조각
항상 일관된 형식으로 표현된다. - 보상(reward) : 알고리즘이 취한 후 학습 알고리즘에 제공되는 일종의 점수 (목표를 향해 학습 알고리즘이 얼마나 잘 나아가는지에 대한 지표)
긍정과 부정 모두 보상에 포함 - 에이전트(agent) : 동작을 취하거나 결정을 내리는 모든 학습 알고리즘
매개변수를 업데이트하는 어떤 알고리즘이 사용 가능하다.
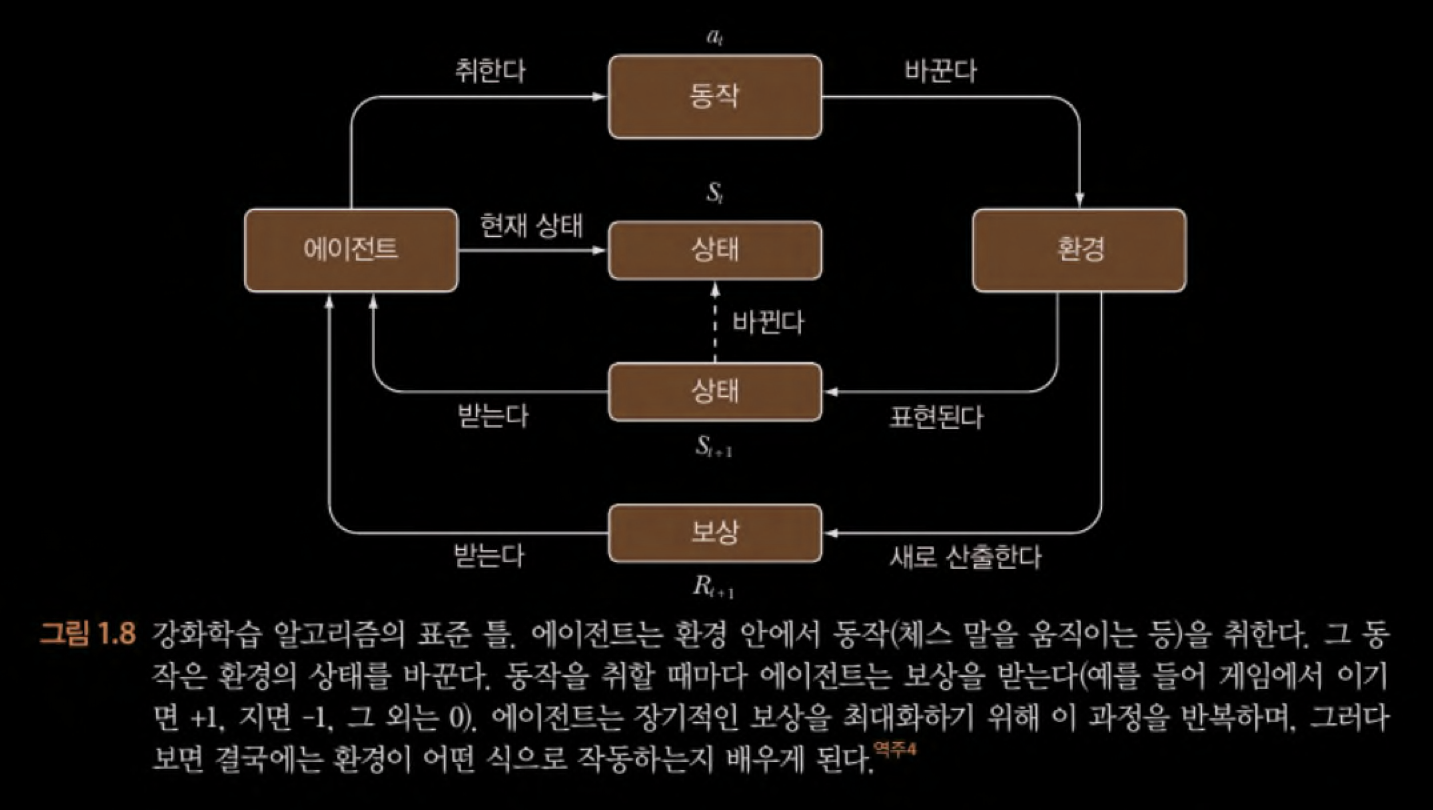
ref
- 심층 강화학습 인 액션 중 1챕터

Learning bunch, mostly computer and language